diff --git a/docs/notes/Git.md b/docs/notes/Git.md
index de8bbf35..06c52b54 100644
--- a/docs/notes/Git.md
+++ b/docs/notes/Git.md
@@ -24,7 +24,7 @@ Git 属于分布式版本控制系统,而 SVN 属于集中式。
集中式版本控制有安全性问题,当中心服务器挂了所有人都没办法工作了。
-集中式版本控制需要连网才能工作,如果网速过慢,那么提交一个文件的会慢的无法让人忍受。而分布式版本控制不需要连网就能工作。
+集中式版本控制需要连网才能工作,如果网速过慢,那么提交一个文件会慢的无法让人忍受。而分布式版本控制不需要连网就能工作。
分布式版本控制新建分支、合并分支操作速度非常快,而集中式版本控制新建一个分支相当于复制一份完整代码。
@@ -38,7 +38,7 @@ Github 就是一个中心服务器。
新建一个仓库之后,当前目录就成为了工作区,工作区下有一个隐藏目录 .git,它属于 Git 的版本库。
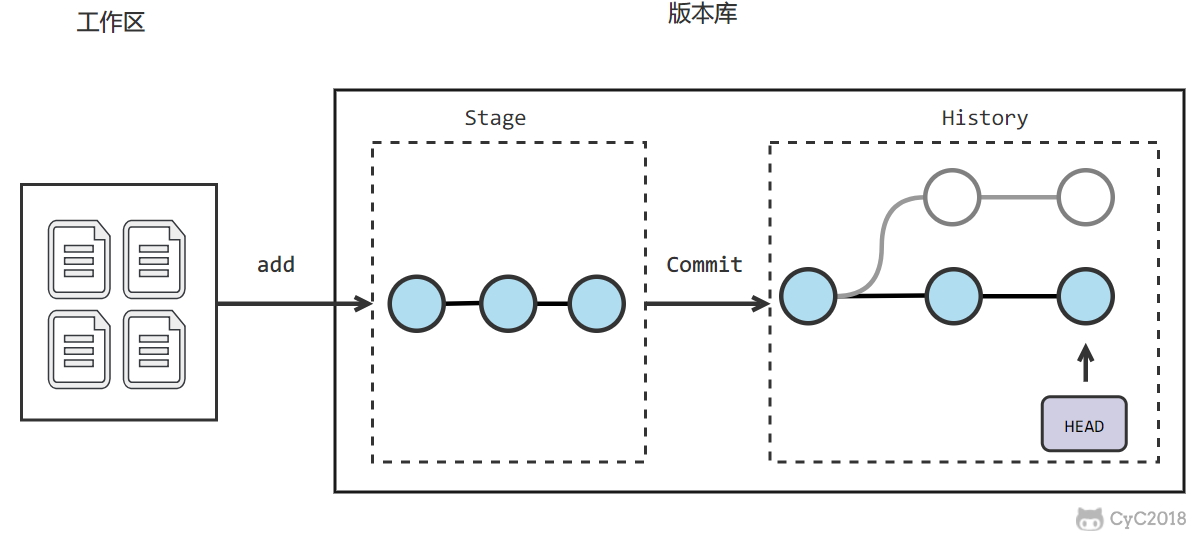
-Git 的版本库有一个称为 Stage 的暂存区以及最后的 History 版本库,History 中存有所有分支,使用一个 HEAD 指针指向当前分支。
+Git 的版本库有一个称为 Stage 的暂存区以及最后的 History 版本库,History 存储所有分支信息,使用一个 HEAD 指针指向当前分支。
@@ -62,7 +62,7 @@ Git 的版本库有一个称为 Stage 的暂存区以及最后的 History 版本
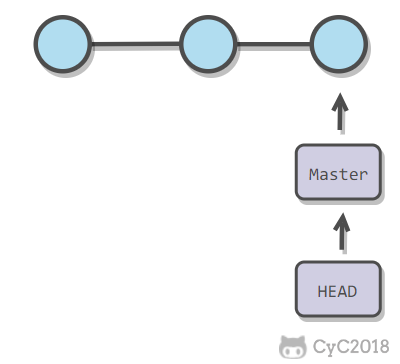
-新建分支是新建一个指针指向时间线的最后一个节点,并让 HEAD 指针指向新分支表示新分支成为当前分支。
+新建分支是新建一个指针指向时间线的最后一个节点,并让 HEAD 指针指向新分支,表示新分支成为当前分支。
@@ -114,7 +114,7 @@ master 分支应该是非常稳定的,只用来发布新版本;
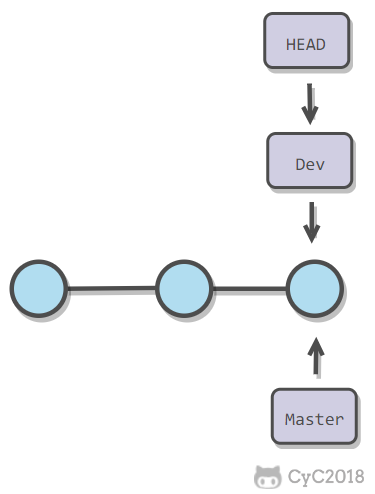
在一个分支上操作之后,如果还没有将修改提交到分支上,此时进行切换分支,那么另一个分支上也能看到新的修改。这是因为所有分支都共用一个工作区的缘故。
-可以使用 git stash 将当前分支的修改储藏起来,此时当前工作区的所有修改都会被存到栈上,也就是说当前工作区是干净的,没有任何未提交的修改。此时就可以安全的切换到其它分支上了。
+可以使用 git stash 将当前分支的修改储藏起来,此时当前工作区的所有修改都会被存到栈中,也就是说当前工作区是干净的,没有任何未提交的修改。此时就可以安全的切换到其它分支上了。
```
$ git stash
diff --git a/docs/notes/Leetcode-Database 题解.md b/docs/notes/Leetcode-Database 题解.md
index 7cc32aca..8b83690e 100644
--- a/docs/notes/Leetcode-Database 题解.md
+++ b/docs/notes/Leetcode-Database 题解.md
@@ -48,6 +48,8 @@ https://leetcode.com/problems/big-countries/description/
## SQL Schema
+SQL Schema 用于在本地环境下创建表结构并导入数据,从而方便在本地环境解答。
+
```sql
DROP TABLE
IF
@@ -125,6 +127,8 @@ VALUES
'm' ^ 'm' ^ 'f' = 'f'
```
+
+
```sql
UPDATE salary
SET sex = CHAR ( ASCII(sex) ^ ASCII( 'm' ) ^ ASCII( 'f' ) );
@@ -301,6 +305,8 @@ VALUES
## Solution
+对 Email 进行分组,如果相同 Email 的数量大于等于 2,则表示该 Email 重复。
+
```sql
SELECT
Email
@@ -324,9 +330,9 @@ https://leetcode.com/problems/delete-duplicate-emails/description/
+----+---------+
| Id | Email |
+----+---------+
-| 1 | a@b.com |
-| 2 | c@d.com |
-| 3 | a@b.com |
+| 1 | john@example.com |
+| 2 | bob@example.com |
+| 3 | john@example.com |
+----+---------+
```
@@ -347,6 +353,8 @@ https://leetcode.com/problems/delete-duplicate-emails/description/
## Solution
+只保留相同 Email 中 Id 最小的那一个,然后删除其它的。
+
连接:
```sql
@@ -437,7 +445,7 @@ VALUES
## Solution
-使用左外连接。
+涉及到 Person 和 Address 两个表,在对这两个表执行连接操作时,因为要保留 Person 表中的信息,即使在 Address 表中没有关联的信息也要保留。此时可以用左外连接,将 Person 表放在 LEFT JOIN 的左边。
```sql
SELECT
@@ -797,10 +805,43 @@ VALUES
## Solution
+要统计某个 score 的排名,只要统计大于该 score 的 score 数量,然后加 1。
+
+| score | 大于该 score 的 score 数量 | 排名 |
+| :---: | :---: | :---: |
+| 4.1 | 2 | 3 |
+| 4.2 | 1 | 2 |
+| 4.3 | 0 | 1 |
+
+但是在本题中,相同的 score 只算一个排名:
+
+| score | 排名 |
+| :---: | :---: |
+| 4.1 | 3 |
+| 4.1 | 3 |
+| 4.2 | 2 |
+| 4.2 | 2 |
+| 4.3 | 1 |
+| 4.3 | 1 |
+
+可以按 score 进行分组,将同一个分组中的 score 只当成一个。
+
+但是如果分组字段只有 score 的话,那么相同的 score 最后的结果只会有一个,例如上面的 6 个记录最后只取出 3 个。
+
+| score | 排名 |
+| :---: | :---: |
+| 4.1 | 3 |
+| 4.2 | 2 |
+| 4.3 | 1 |
+
+所以在分组中需要加入 Id,每个记录显示一个结果。综上,需要使用 score 和 id 两个分组字段。
+
+在下面的实现中,首先将 Scores 表根据 score 字段进行自连接,得到一个新表,然后在新表上对 id 和 score 进行分组。
+
```sql
SELECT
- S1.score,
- COUNT( DISTINCT S2.score ) Rank
+ S1.score 'Score',
+ COUNT( DISTINCT S2.score ) 'Rank'
FROM
Scores S1
INNER JOIN Scores S2
@@ -931,6 +972,8 @@ VALUES
使用多个 union。
```sql
+# 处理偶数 id,让 id 减 1
+# 例如 2,4,6,... 变成 1,3,5,...
SELECT
s1.id - 1 AS id,
s1.student
@@ -938,6 +981,8 @@ FROM
seat s1
WHERE
s1.id MOD 2 = 0 UNION
+# 处理奇数 id,让 id 加 1。但是如果最大的 id 为奇数,则不做处理
+# 例如 1,3,5,... 变成 2,4,6,...
SELECT
s2.id + 1 AS id,
s2.student
@@ -946,6 +991,7 @@ FROM
WHERE
s2.id MOD 2 = 1
AND s2.id != ( SELECT max( s3.id ) FROM seat s3 ) UNION
+# 如果最大的 id 为奇数,单独取出这个数
SELECT
s4.id AS id,
s4.student
diff --git a/docs/notes/代码可读性.md b/docs/notes/代码可读性.md
index 462f7103..f6995f62 100644
--- a/docs/notes/代码可读性.md
+++ b/docs/notes/代码可读性.md
@@ -70,7 +70,7 @@ int c = 111; // 注释
# 五、为何编写注释
-阅读代码首先会注意到注释,如果注释没太大作用,那么就会浪费代码阅读的时间。那些能直接看出含义的代码不需要写注释,特别是并不需要为每个方法都加上注释,比如那些简单的 getter 和 setter 方法,为这些方法写注释反而让代码可读性更差。
+阅读代码首先会注意到注释,如果注释没太大作用,那么就会浪费代码阅读的时间。那些能直接看出含义的代码不需要写注释,特别是不需要为每个方法都加上注释,比如那些简单的 getter 和 setter 方法,为这些方法写注释反而让代码可读性更差。
不能因为有注释就随便起个名字,而是争取起个好名字而不写注释。
diff --git a/docs/notes/构建工具.md b/docs/notes/构建工具.md
index ab14eb64..d3d3f941 100644
--- a/docs/notes/构建工具.md
+++ b/docs/notes/构建工具.md
@@ -32,10 +32,10 @@
# 二、Java 主流构建工具
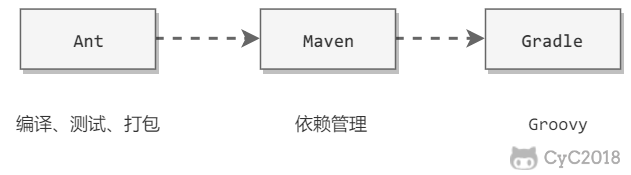
-主要包括 Ant、Maven 和 Gradle。
+Ant 具有编译、测试和打包功能,其后出现的 Maven 在 Ant 的功能基础上又新增了依赖管理功能,而最新的 Maven 又在 Maven 的功能基础上新增了对 Groovy 语言的支持。
-
+
Gradle 和 Maven 的区别是,它使用 Groovy 这种特定领域语言(DSL)来管理构建脚本,而不再使用 XML 这种标记性语言。因为项目如果庞大的话,XML 很容易就变得臃肿。
@@ -82,7 +82,7 @@ dependencies {
- 本地仓库用来存储项目的依赖库;
- 中央仓库是下载依赖库的默认位置;
-- 远程仓库,因为并非所有的库存储在中央仓库,或者中央仓库访问速度很慢,远程仓库是中央仓库的补充。
+- 远程仓库,因为并非所有的依赖库都在中央仓库,或者中央仓库访问速度很慢,远程仓库是中央仓库的补充。
## POM
@@ -99,7 +99,6 @@ POM 代表项目对象模型,它是一个 XML 文件,保存在项目根目
[groupId, artifactId, version, packaging, classifier] 称为一个项目的坐标,其中 groupId、artifactId、version 必须定义,packaging 可选(默认为 Jar),classifier 不能直接定义的,需要结合插件使用。
-
- groupId:项目组 Id,必须全球唯一;
- artifactId:项目 Id,即项目名;
- version:项目版本;
diff --git a/docs/notes/计算机操作系统 - 概述.md b/docs/notes/计算机操作系统 - 概述.md
index d2c12d92..4813d72b 100644
--- a/docs/notes/计算机操作系统 - 概述.md
+++ b/docs/notes/计算机操作系统 - 概述.md
@@ -36,15 +36,15 @@
有两种共享方式:互斥共享和同时共享。
-互斥共享的资源称为临界资源,例如打印机等,在同一时间只允许一个进程访问,需要用同步机制来实现对临界资源的访问。
+互斥共享的资源称为临界资源,例如打印机等,在同一时刻只允许一个进程访问,需要用同步机制来实现互斥访问。
## 3. 虚拟
虚拟技术把一个物理实体转换为多个逻辑实体。
-主要有两种虚拟技术:时分复用技术和空分复用技术。
+主要有两种虚拟技术:时(时间)分复用技术和空(空间)分复用技术。
-多个进程能在同一个处理器上并发执行使用了时分复用技术,让每个进程轮流占有处理器,每次只执行一小个时间片并快速切换。
+多个进程能在同一个处理器上并发执行使用了时分复用技术,让每个进程轮流占用处理器,每次只执行一小个时间片并快速切换。
虚拟内存使用了空分复用技术,它将物理内存抽象为地址空间,每个进程都有各自的地址空间。地址空间的页被映射到物理内存,地址空间的页并不需要全部在物理内存中,当使用到一个没有在物理内存的页时,执行页面置换算法,将该页置换到内存中。
diff --git a/docs/notes/设计模式.md b/docs/notes/设计模式.md
index bf448c41..e781102c 100644
--- a/docs/notes/设计模式.md
+++ b/docs/notes/设计模式.md
@@ -131,7 +131,7 @@ public class Singleton {
}
```
-考虑下面的实现,也就是只使用了一个 if 语句。在 uniqueInstance == null 的情况下,如果两个线程都执行了 if 语句,那么两个线程都会进入 if 语句块内。虽然在 if 语句块内有加锁操作,但是两个线程都会执行 `uniqueInstance = new Singleton();` 这条语句,只是先后的问题,那么就会进行两次实例化。因此必须使用双重校验锁,也就是需要使用两个 if 语句。
+考虑下面的实现,也就是只使用了一个 if 语句。在 uniqueInstance == null 的情况下,如果两个线程都执行了 if 语句,那么两个线程都会进入 if 语句块内。虽然在 if 语句块内有加锁操作,但是两个线程都会执行 `uniqueInstance = new Singleton();` 这条语句,只是先后的问题,那么就会进行两次实例化。因此必须使用双重校验锁,也就是需要使用两个 if 语句:第一个 if 语句用来避免 uniqueInstance 已经被实例化之后的加锁操作,而第二个 if 语句进行了加锁,所以只能有一个线程进入,就不会出现 uniqueInstance == null 时两个线程同时进行实例化操作。
```java
if (uniqueInstance == null) {
@@ -153,7 +153,7 @@ uniqueInstance 采用 volatile 关键字修饰也是很有必要的, `uniqueIn
#### Ⅴ 静态内部类实现
-当 Singleton 类加载时,静态内部类 SingletonHolder 没有被加载进内存。只有当调用 `getUniqueInstance()` 方法从而触发 `SingletonHolder.INSTANCE` 时 SingletonHolder 才会被加载,此时初始化 INSTANCE 实例,并且 JVM 能确保 INSTANCE 只被实例化一次。
+当 Singleton 类被加载时,静态内部类 SingletonHolder 没有被加载进内存。只有当调用 `getUniqueInstance()` 方法从而触发 `SingletonHolder.INSTANCE` 时 SingletonHolder 才会被加载,此时初始化 INSTANCE 实例,并且 JVM 能确保 INSTANCE 只被实例化一次。
这种方式不仅具有延迟初始化的好处,而且由 JVM 提供了对线程安全的支持。
@@ -224,10 +224,10 @@ secondName
secondName
```
-该实现在多次序列化再进行反序列化之后,不会得到多个实例。而其它实现需要使用 transient 修饰所有字段,并且实现序列化和反序列化的方法。
-
该实现可以防止反射攻击。在其它实现中,通过 setAccessible() 方法可以将私有构造函数的访问级别设置为 public,然后调用构造函数从而实例化对象,如果要防止这种攻击,需要在构造函数中添加防止多次实例化的代码。该实现是由 JVM 保证只会实例化一次,因此不会出现上述的反射攻击。
+该实现在多次序列化和序列化之后,不会得到多个实例。而其它实现需要使用 transient 修饰所有字段,并且实现序列化和反序列化的方法。
+
### Examples
- Logger Classes
diff --git a/docs/notes/面向对象思想.md b/docs/notes/面向对象思想.md
index a5af462c..d6910f48 100644
--- a/docs/notes/面向对象思想.md
+++ b/docs/notes/面向对象思想.md
@@ -21,13 +21,13 @@
## 封装
-利用抽象数据类型将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体。数据被保护在抽象数据类型的内部,尽可能地隐藏内部的细节,只保留一些对外接口使之与外部发生联系。用户无需知道对象内部的细节,但可以通过对象对外提供的接口来访问该对象。
+利用抽象数据类型将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体。数据被保护在抽象数据类型的内部,尽可能地隐藏内部的细节,只保留一些对外的接口使其与外部发生联系。用户无需关心对象内部的细节,但可以通过对象对外提供的接口来访问该对象。
优点:
- 减少耦合:可以独立地开发、测试、优化、使用、理解和修改
- 减轻维护的负担:可以更容易被程序员理解,并且在调试的时候可以不影响其他模块
-- 有效地调节性能:可以通过剖析确定哪些模块影响了系统的性能
+- 有效地调节性能:可以通过剖析来确定哪些模块影响了系统的性能
- 提高软件的可重用性
- 降低了构建大型系统的风险:即使整个系统不可用,但是这些独立的模块却有可能是可用的
@@ -94,21 +94,27 @@ public class Instrument {
System.out.println("Instument is playing...");
}
}
+```
+```java
public class Wind extends Instrument {
public void play() {
System.out.println("Wind is playing...");
}
}
+```
+```java
public class Percussion extends Instrument {
public void play() {
System.out.println("Percussion is playing...");
}
}
+```
+```java
public class Music {
public static void main(String[] args) {
@@ -122,6 +128,11 @@ public class Music {
}
```
+```
+Wind is playing...
+Percussion is playing...
+```
+
# 二、类图
以下类图使用 [PlantUML](https://www.planttext.com/) 绘制,更多语法及使用请参考:http://plantuml.com/ 。
diff --git a/notes/Git.md b/notes/Git.md
index bb50bf57..21781af7 100644
--- a/notes/Git.md
+++ b/notes/Git.md
@@ -24,7 +24,7 @@ Git 属于分布式版本控制系统,而 SVN 属于集中式。
集中式版本控制有安全性问题,当中心服务器挂了所有人都没办法工作了。
-集中式版本控制需要连网才能工作,如果网速过慢,那么提交一个文件的会慢的无法让人忍受。而分布式版本控制不需要连网就能工作。
+集中式版本控制需要连网才能工作,如果网速过慢,那么提交一个文件会慢的无法让人忍受。而分布式版本控制不需要连网就能工作。
分布式版本控制新建分支、合并分支操作速度非常快,而集中式版本控制新建一个分支相当于复制一份完整代码。
@@ -38,7 +38,7 @@ Github 就是一个中心服务器。
新建一个仓库之后,当前目录就成为了工作区,工作区下有一个隐藏目录 .git,它属于 Git 的版本库。
-Git 的版本库有一个称为 Stage 的暂存区以及最后的 History 版本库,History 中存有所有分支,使用一个 HEAD 指针指向当前分支。
+Git 的版本库有一个称为 Stage 的暂存区以及最后的 History 版本库,History 存储所有分支信息,使用一个 HEAD 指针指向当前分支。
@@ -62,7 +62,7 @@ Git 的版本库有一个称为 Stage 的暂存区以及最后的 History 版本
-新建分支是新建一个指针指向时间线的最后一个节点,并让 HEAD 指针指向新分支表示新分支成为当前分支。
+新建分支是新建一个指针指向时间线的最后一个节点,并让 HEAD 指针指向新分支,表示新分支成为当前分支。
@@ -114,7 +114,7 @@ master 分支应该是非常稳定的,只用来发布新版本;
在一个分支上操作之后,如果还没有将修改提交到分支上,此时进行切换分支,那么另一个分支上也能看到新的修改。这是因为所有分支都共用一个工作区的缘故。
-可以使用 git stash 将当前分支的修改储藏起来,此时当前工作区的所有修改都会被存到栈上,也就是说当前工作区是干净的,没有任何未提交的修改。此时就可以安全的切换到其它分支上了。
+可以使用 git stash 将当前分支的修改储藏起来,此时当前工作区的所有修改都会被存到栈中,也就是说当前工作区是干净的,没有任何未提交的修改。此时就可以安全的切换到其它分支上了。
```
$ git stash
diff --git a/notes/Leetcode-Database 题解.md b/notes/Leetcode-Database 题解.md
index 7cc32aca..8b83690e 100644
--- a/notes/Leetcode-Database 题解.md
+++ b/notes/Leetcode-Database 题解.md
@@ -48,6 +48,8 @@ https://leetcode.com/problems/big-countries/description/
## SQL Schema
+SQL Schema 用于在本地环境下创建表结构并导入数据,从而方便在本地环境解答。
+
```sql
DROP TABLE
IF
@@ -125,6 +127,8 @@ VALUES
'm' ^ 'm' ^ 'f' = 'f'
```
+
+
```sql
UPDATE salary
SET sex = CHAR ( ASCII(sex) ^ ASCII( 'm' ) ^ ASCII( 'f' ) );
@@ -301,6 +305,8 @@ VALUES
## Solution
+对 Email 进行分组,如果相同 Email 的数量大于等于 2,则表示该 Email 重复。
+
```sql
SELECT
Email
@@ -324,9 +330,9 @@ https://leetcode.com/problems/delete-duplicate-emails/description/
+----+---------+
| Id | Email |
+----+---------+
-| 1 | a@b.com |
-| 2 | c@d.com |
-| 3 | a@b.com |
+| 1 | john@example.com |
+| 2 | bob@example.com |
+| 3 | john@example.com |
+----+---------+
```
@@ -347,6 +353,8 @@ https://leetcode.com/problems/delete-duplicate-emails/description/
## Solution
+只保留相同 Email 中 Id 最小的那一个,然后删除其它的。
+
连接:
```sql
@@ -437,7 +445,7 @@ VALUES
## Solution
-使用左外连接。
+涉及到 Person 和 Address 两个表,在对这两个表执行连接操作时,因为要保留 Person 表中的信息,即使在 Address 表中没有关联的信息也要保留。此时可以用左外连接,将 Person 表放在 LEFT JOIN 的左边。
```sql
SELECT
@@ -797,10 +805,43 @@ VALUES
## Solution
+要统计某个 score 的排名,只要统计大于该 score 的 score 数量,然后加 1。
+
+| score | 大于该 score 的 score 数量 | 排名 |
+| :---: | :---: | :---: |
+| 4.1 | 2 | 3 |
+| 4.2 | 1 | 2 |
+| 4.3 | 0 | 1 |
+
+但是在本题中,相同的 score 只算一个排名:
+
+| score | 排名 |
+| :---: | :---: |
+| 4.1 | 3 |
+| 4.1 | 3 |
+| 4.2 | 2 |
+| 4.2 | 2 |
+| 4.3 | 1 |
+| 4.3 | 1 |
+
+可以按 score 进行分组,将同一个分组中的 score 只当成一个。
+
+但是如果分组字段只有 score 的话,那么相同的 score 最后的结果只会有一个,例如上面的 6 个记录最后只取出 3 个。
+
+| score | 排名 |
+| :---: | :---: |
+| 4.1 | 3 |
+| 4.2 | 2 |
+| 4.3 | 1 |
+
+所以在分组中需要加入 Id,每个记录显示一个结果。综上,需要使用 score 和 id 两个分组字段。
+
+在下面的实现中,首先将 Scores 表根据 score 字段进行自连接,得到一个新表,然后在新表上对 id 和 score 进行分组。
+
```sql
SELECT
- S1.score,
- COUNT( DISTINCT S2.score ) Rank
+ S1.score 'Score',
+ COUNT( DISTINCT S2.score ) 'Rank'
FROM
Scores S1
INNER JOIN Scores S2
@@ -931,6 +972,8 @@ VALUES
使用多个 union。
```sql
+# 处理偶数 id,让 id 减 1
+# 例如 2,4,6,... 变成 1,3,5,...
SELECT
s1.id - 1 AS id,
s1.student
@@ -938,6 +981,8 @@ FROM
seat s1
WHERE
s1.id MOD 2 = 0 UNION
+# 处理奇数 id,让 id 加 1。但是如果最大的 id 为奇数,则不做处理
+# 例如 1,3,5,... 变成 2,4,6,...
SELECT
s2.id + 1 AS id,
s2.student
@@ -946,6 +991,7 @@ FROM
WHERE
s2.id MOD 2 = 1
AND s2.id != ( SELECT max( s3.id ) FROM seat s3 ) UNION
+# 如果最大的 id 为奇数,单独取出这个数
SELECT
s4.id AS id,
s4.student
diff --git a/notes/代码可读性.md b/notes/代码可读性.md
index 0be113e9..0ed55a6b 100644
--- a/notes/代码可读性.md
+++ b/notes/代码可读性.md
@@ -70,7 +70,7 @@ int c = 111; // 注释
# 五、为何编写注释
-阅读代码首先会注意到注释,如果注释没太大作用,那么就会浪费代码阅读的时间。那些能直接看出含义的代码不需要写注释,特别是并不需要为每个方法都加上注释,比如那些简单的 getter 和 setter 方法,为这些方法写注释反而让代码可读性更差。
+阅读代码首先会注意到注释,如果注释没太大作用,那么就会浪费代码阅读的时间。那些能直接看出含义的代码不需要写注释,特别是不需要为每个方法都加上注释,比如那些简单的 getter 和 setter 方法,为这些方法写注释反而让代码可读性更差。
不能因为有注释就随便起个名字,而是争取起个好名字而不写注释。
diff --git a/notes/构建工具.md b/notes/构建工具.md
index bf287fd9..588755c1 100644
--- a/notes/构建工具.md
+++ b/notes/构建工具.md
@@ -32,10 +32,10 @@
# 二、Java 主流构建工具
-主要包括 Ant、Maven 和 Gradle。
+Ant 具有编译、测试和打包功能,其后出现的 Maven 在 Ant 的功能基础上又新增了依赖管理功能,而最新的 Maven 又在 Maven 的功能基础上新增了对 Groovy 语言的支持。
-
+
Gradle 和 Maven 的区别是,它使用 Groovy 这种特定领域语言(DSL)来管理构建脚本,而不再使用 XML 这种标记性语言。因为项目如果庞大的话,XML 很容易就变得臃肿。
@@ -82,7 +82,7 @@ dependencies {
- 本地仓库用来存储项目的依赖库;
- 中央仓库是下载依赖库的默认位置;
-- 远程仓库,因为并非所有的库存储在中央仓库,或者中央仓库访问速度很慢,远程仓库是中央仓库的补充。
+- 远程仓库,因为并非所有的依赖库都在中央仓库,或者中央仓库访问速度很慢,远程仓库是中央仓库的补充。
## POM
@@ -99,7 +99,6 @@ POM 代表项目对象模型,它是一个 XML 文件,保存在项目根目
[groupId, artifactId, version, packaging, classifier] 称为一个项目的坐标,其中 groupId、artifactId、version 必须定义,packaging 可选(默认为 Jar),classifier 不能直接定义的,需要结合插件使用。
-
- groupId:项目组 Id,必须全球唯一;
- artifactId:项目 Id,即项目名;
- version:项目版本;
diff --git a/notes/计算机操作系统 - 概述.md b/notes/计算机操作系统 - 概述.md
index 2528750d..dec63667 100644
--- a/notes/计算机操作系统 - 概述.md
+++ b/notes/计算机操作系统 - 概述.md
@@ -36,15 +36,15 @@
有两种共享方式:互斥共享和同时共享。
-互斥共享的资源称为临界资源,例如打印机等,在同一时间只允许一个进程访问,需要用同步机制来实现对临界资源的访问。
+互斥共享的资源称为临界资源,例如打印机等,在同一时刻只允许一个进程访问,需要用同步机制来实现互斥访问。
## 3. 虚拟
虚拟技术把一个物理实体转换为多个逻辑实体。
-主要有两种虚拟技术:时分复用技术和空分复用技术。
+主要有两种虚拟技术:时(时间)分复用技术和空(空间)分复用技术。
-多个进程能在同一个处理器上并发执行使用了时分复用技术,让每个进程轮流占有处理器,每次只执行一小个时间片并快速切换。
+多个进程能在同一个处理器上并发执行使用了时分复用技术,让每个进程轮流占用处理器,每次只执行一小个时间片并快速切换。
虚拟内存使用了空分复用技术,它将物理内存抽象为地址空间,每个进程都有各自的地址空间。地址空间的页被映射到物理内存,地址空间的页并不需要全部在物理内存中,当使用到一个没有在物理内存的页时,执行页面置换算法,将该页置换到内存中。
diff --git a/notes/设计模式.md b/notes/设计模式.md
index 2c4ebc5f..cddc1d34 100644
--- a/notes/设计模式.md
+++ b/notes/设计模式.md
@@ -131,7 +131,7 @@ public class Singleton {
}
```
-考虑下面的实现,也就是只使用了一个 if 语句。在 uniqueInstance == null 的情况下,如果两个线程都执行了 if 语句,那么两个线程都会进入 if 语句块内。虽然在 if 语句块内有加锁操作,但是两个线程都会执行 `uniqueInstance = new Singleton();` 这条语句,只是先后的问题,那么就会进行两次实例化。因此必须使用双重校验锁,也就是需要使用两个 if 语句。
+考虑下面的实现,也就是只使用了一个 if 语句。在 uniqueInstance == null 的情况下,如果两个线程都执行了 if 语句,那么两个线程都会进入 if 语句块内。虽然在 if 语句块内有加锁操作,但是两个线程都会执行 `uniqueInstance = new Singleton();` 这条语句,只是先后的问题,那么就会进行两次实例化。因此必须使用双重校验锁,也就是需要使用两个 if 语句:第一个 if 语句用来避免 uniqueInstance 已经被实例化之后的加锁操作,而第二个 if 语句进行了加锁,所以只能有一个线程进入,就不会出现 uniqueInstance == null 时两个线程同时进行实例化操作。
```java
if (uniqueInstance == null) {
@@ -153,7 +153,7 @@ uniqueInstance 采用 volatile 关键字修饰也是很有必要的, `uniqueIn
#### Ⅴ 静态内部类实现
-当 Singleton 类加载时,静态内部类 SingletonHolder 没有被加载进内存。只有当调用 `getUniqueInstance()` 方法从而触发 `SingletonHolder.INSTANCE` 时 SingletonHolder 才会被加载,此时初始化 INSTANCE 实例,并且 JVM 能确保 INSTANCE 只被实例化一次。
+当 Singleton 类被加载时,静态内部类 SingletonHolder 没有被加载进内存。只有当调用 `getUniqueInstance()` 方法从而触发 `SingletonHolder.INSTANCE` 时 SingletonHolder 才会被加载,此时初始化 INSTANCE 实例,并且 JVM 能确保 INSTANCE 只被实例化一次。
这种方式不仅具有延迟初始化的好处,而且由 JVM 提供了对线程安全的支持。
@@ -224,10 +224,10 @@ secondName
secondName
```
-该实现在多次序列化再进行反序列化之后,不会得到多个实例。而其它实现需要使用 transient 修饰所有字段,并且实现序列化和反序列化的方法。
-
该实现可以防止反射攻击。在其它实现中,通过 setAccessible() 方法可以将私有构造函数的访问级别设置为 public,然后调用构造函数从而实例化对象,如果要防止这种攻击,需要在构造函数中添加防止多次实例化的代码。该实现是由 JVM 保证只会实例化一次,因此不会出现上述的反射攻击。
+该实现在多次序列化和序列化之后,不会得到多个实例。而其它实现需要使用 transient 修饰所有字段,并且实现序列化和反序列化的方法。
+
### Examples
- Logger Classes
diff --git a/notes/面向对象思想.md b/notes/面向对象思想.md
index 1c44cb89..19ec6e8b 100644
--- a/notes/面向对象思想.md
+++ b/notes/面向对象思想.md
@@ -21,13 +21,13 @@
## 封装
-利用抽象数据类型将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体。数据被保护在抽象数据类型的内部,尽可能地隐藏内部的细节,只保留一些对外接口使之与外部发生联系。用户无需知道对象内部的细节,但可以通过对象对外提供的接口来访问该对象。
+利用抽象数据类型将数据和基于数据的操作封装在一起,使其构成一个不可分割的独立实体。数据被保护在抽象数据类型的内部,尽可能地隐藏内部的细节,只保留一些对外的接口使其与外部发生联系。用户无需关心对象内部的细节,但可以通过对象对外提供的接口来访问该对象。
优点:
- 减少耦合:可以独立地开发、测试、优化、使用、理解和修改
- 减轻维护的负担:可以更容易被程序员理解,并且在调试的时候可以不影响其他模块
-- 有效地调节性能:可以通过剖析确定哪些模块影响了系统的性能
+- 有效地调节性能:可以通过剖析来确定哪些模块影响了系统的性能
- 提高软件的可重用性
- 降低了构建大型系统的风险:即使整个系统不可用,但是这些独立的模块却有可能是可用的
@@ -94,21 +94,27 @@ public class Instrument {
System.out.println("Instument is playing...");
}
}
+```
+```java
public class Wind extends Instrument {
public void play() {
System.out.println("Wind is playing...");
}
}
+```
+```java
public class Percussion extends Instrument {
public void play() {
System.out.println("Percussion is playing...");
}
}
+```
+```java
public class Music {
public static void main(String[] args) {
@@ -122,6 +128,11 @@ public class Music {
}
```
+```
+Wind is playing...
+Percussion is playing...
+```
+
# 二、类图
以下类图使用 [PlantUML](https://www.planttext.com/) 绘制,更多语法及使用请参考:http://plantuml.com/ 。