diff --git a/docs/notes/数据库系统原理.md b/docs/notes/数据库系统原理.md
index 8531af97..fabee396 100644
--- a/docs/notes/数据库系统原理.md
+++ b/docs/notes/数据库系统原理.md
@@ -19,9 +19,10 @@
* [可重复读(REPEATABLE READ)](#可重复读repeatable-read)
* [可串行化(SERIALIZABLE)](#可串行化serializable)
* [五、多版本并发控制](#五多版本并发控制)
+ * [基本思想](#基本思想)
+ * [Undo 日志](#undo-日志)
* [版本号](#版本号)
* [隐藏的列](#隐藏的列)
- * [Undo 日志](#undo-日志)
* [实现过程](#实现过程)
* [快照读与当前读](#快照读与当前读)
* [六、Next-Key Locks](#六next-key-locks)
@@ -189,7 +190,6 @@ MySQL 中提供了两种封锁粒度:行级锁以及表级锁。
-
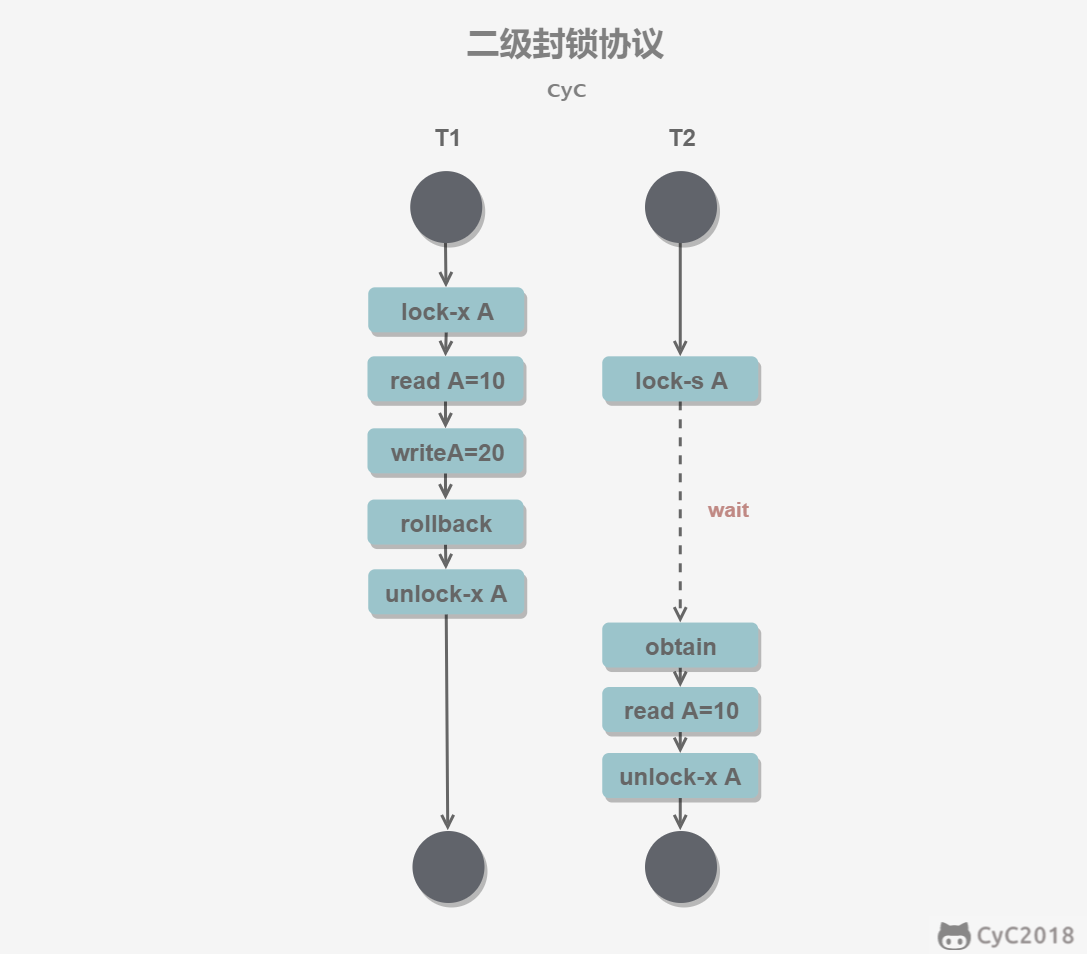
**三级封锁协议**
在二级的基础上,要求读取数据 A 时必须加 S 锁,直到事务结束了才能释放 S 锁。
@@ -249,20 +249,39 @@ SELECT ... FOR UPDATE;
----
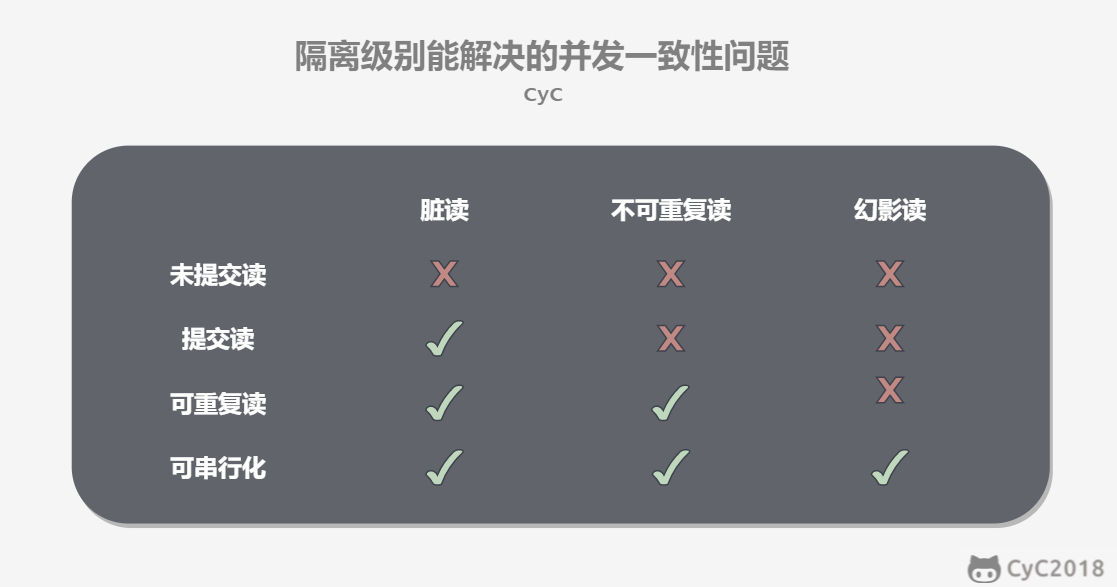
-| | 脏读 | 不可重复读 | 幻影读 |
-| :---: | :---: | :---:| :---: |
-| 未提交读 | √ | √ | √ |
-| 提交读 | × | √ | √ |
-| 可重复读 | × | × | √ |
-| 可串行化 | × | × | × |
+
# 五、多版本并发控制
多版本并发控制(Multi-Version Concurrency Control, MVCC)是 MySQL 的 InnoDB 存储引擎实现隔离级别的一种具体方式,用于实现提交读和可重复读这两种隔离级别。而未提交读隔离级别总是读取最新的数据行,要求很低,无需使用 MVCC。可串行化隔离级别需要对所有读取的行都加锁,单纯使用 MVCC 无法实现。
-## 版本号
+## 基本思想
-在封锁一节中提到,加锁能解决多个事务同时执行时出现的并发一致性问题。但是封锁操作代价很高,而多版本并发控制采用无锁机制,而是利用“版本”来解决并发一致性问题。它的基本思想是为每个数据行维护创建
+在封锁一节中提到,加锁能解决多个事务同时执行时出现的并发一致性问题。但是加锁操作代价很高,并且在实际场景中读多写少,所有事务都是只是进行读操作的话就没必要进行加锁。
+
+MVCC 的读操作不需要进行加锁,并且在可重复读隔离级别下能解决脏读和不可重复读问题。它的基本思想是为每个数据行维护多个版本的快照,多个事务可以同时去操作这个数据行。
+
+事务的修改操作(DELETE、INSERT、UPDATE)会去修改该事务对应版本的快照。
+
+脏读和不可重复读最根本的原因是事务读取到其它事务未提交的修改。在事务在进行读取操作时,为了解决脏读和不可重复读问题,读取的快照需要满足以下条件:快照在该事务开始之后没有被其它事务修改,否则会读取到其它事务的未提交的修改操作。
+
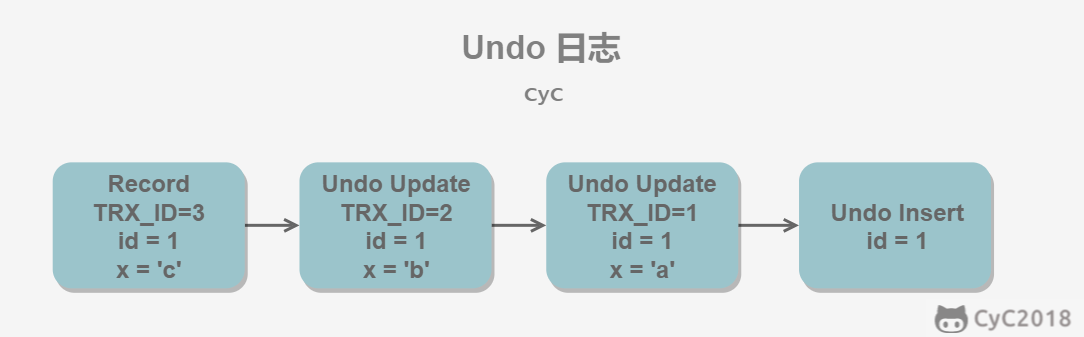
+## Undo 日志
+
+MVCC 的多版本指的是多个版本的快照,这个快照存储在 Undo 日志中,该日志通过回滚指针把一个数据行的所有快照连接起来。
+
+例如我们在 MySQL 创建一个表 t,包含主键 id 和一个字段 x。我们先插入一个数据行,然后对该数据行执行两次操作。
+
+```sql
+INSERT INTO t(id, x) VALUES(1, "a");
+UPDATE t SET x="b" WHERE id=1;
+UPDATE t SET x="c" WHERE id=1;
+```
+
+因为我们没有使用 `START TRANSACTION` 将上面的操作当成一个事务来执行,根据 MySQL 的 AUTOCOMMIT 机制,每个操作都会被当成一个事务来执行,所以上面总共涉及到三个事务。
+
+
+
+## 版本号
- 系统版本号:是一个递增的数字,每开始一个新的事务,系统版本号就会自动递增。
- 事务版本号:事务开始时的系统版本号。
@@ -274,17 +293,13 @@ MVCC 在每行记录后面都保存着两个隐藏的列,用来存储两个版
- 创建版本号:指示创建一个数据行的快照时的系统版本号;
- 删除版本号:如果该快照的删除版本未定义或删除版本号大于当前事务版本号表示该快照有效
-## Undo 日志
-MVCC 使用到的快照存储在 Undo 日志中,该日志通过回滚指针把一个数据行(Record)的所有快照连接起来。
-
-
## 实现过程
以下实现过程针对可重复读隔离级别。
-当开始一个事务时,该事务的版本号肯定大于当前所有数据行快照的创建版本号,理解这一点很关键。数据行快照的创建版本号是创建数据行快照时的系统版本号,系统版本号随着创建事务而递增,因此新创建一个事务时,这个事务的系统版本号比之前的系统版本号都大,也就是比所有数据行快照的创建版本号都大。
+当开始一个事务时,该事务的版本号肯定大于当前所有数据行快照的创建版本号。数据行快照的创建版本号是创建数据行快照时的系统版本号,系统版本号随着创建事务而递增,因此新创建一个事务时,这个事务的系统版本号比之前的系统版本号都大,也就是比所有数据行快照的创建版本号都大。
### 1. SELECT
@@ -308,22 +323,27 @@ MVCC 使用到的快照存储在 Undo 日志中,该日志通过回滚指针把
### 1. 快照读
-使用 MVCC 读取的是快照中的数据,这样可以减少加锁所带来的开销。
+MVCC 的 SELECT 操作是快照中的数据,不需要进行加锁操作。
```sql
-select * from table ...;
+SELECT * FROM table ...;
```
### 2. 当前读
-读取的是最新的数据,需要加锁。以下第一个语句需要加 S 锁,其它都需要加 X 锁。
+MVCC 其它会对数据库进行修改的操作(INSERT、UPDATE、DELETE)需要加锁操作,从而读取最新的数据。
```sql
-select * from table where ? lock in share mode;
-select * from table where ? for update;
-insert;
-update;
-delete;
+INSERT;
+UPDATE;
+DELETE;
+```
+
+在进行 SELECT 操作时,可以强制指定进行加锁操作。以下第一个语句需要加 S 锁,第二个需要加 X 锁。
+
+```sql
+SELECT * FROM table WHERE ? lock in share mode;
+SELECT * FROM table WHERE ? for update;
```
# 六、Next-Key Locks
@@ -348,14 +368,14 @@ SELECT c FROM t WHERE c BETWEEN 10 and 20 FOR UPDATE;
## Next-Key Locks
-它是 Record Locks 和 Gap Locks 的结合,不仅锁定一个记录上的索引,也锁定索引之间的间隙,是一个前开后闭区间。例如一个索引包含以下值:10, 11, 13, and 20,那么就需要锁定以下区间:
+它是 Record Locks 和 Gap Locks 的结合,不仅锁定一个记录上的索引,也锁定索引之间的间隙。它锁定一个前开后闭区间,例如一个索引包含以下值:10, 11, 13, and 20,那么就需要锁定以下区间:
```sql
(-∞, 10]
(10, 11]
(11, 13]
(13, 20]
-(20, +supremum)
+(20, +∞)
```
# 七、关系数据库设计理论
diff --git a/notes/pics/image-20191207223334985.png b/notes/pics/image-20191207223334985.png
new file mode 100644
index 00000000..74377d93
Binary files /dev/null and b/notes/pics/image-20191207223334985.png differ
diff --git a/notes/pics/image-20191207223400787.png b/notes/pics/image-20191207223400787.png
new file mode 100644
index 00000000..b716c84e
Binary files /dev/null and b/notes/pics/image-20191207223400787.png differ
diff --git a/notes/pics/image-20191208012527591.png b/notes/pics/image-20191208012527591.png
new file mode 100644
index 00000000..c0b36926
Binary files /dev/null and b/notes/pics/image-20191208012527591.png differ
diff --git a/notes/数据库系统原理.md b/notes/数据库系统原理.md
index 8531af97..fabee396 100644
--- a/notes/数据库系统原理.md
+++ b/notes/数据库系统原理.md
@@ -19,9 +19,10 @@
* [可重复读(REPEATABLE READ)](#可重复读repeatable-read)
* [可串行化(SERIALIZABLE)](#可串行化serializable)
* [五、多版本并发控制](#五多版本并发控制)
+ * [基本思想](#基本思想)
+ * [Undo 日志](#undo-日志)
* [版本号](#版本号)
* [隐藏的列](#隐藏的列)
- * [Undo 日志](#undo-日志)
* [实现过程](#实现过程)
* [快照读与当前读](#快照读与当前读)
* [六、Next-Key Locks](#六next-key-locks)
@@ -189,7 +190,6 @@ MySQL 中提供了两种封锁粒度:行级锁以及表级锁。
-
**三级封锁协议**
在二级的基础上,要求读取数据 A 时必须加 S 锁,直到事务结束了才能释放 S 锁。
@@ -249,20 +249,39 @@ SELECT ... FOR UPDATE;
----
-| | 脏读 | 不可重复读 | 幻影读 |
-| :---: | :---: | :---:| :---: |
-| 未提交读 | √ | √ | √ |
-| 提交读 | × | √ | √ |
-| 可重复读 | × | × | √ |
-| 可串行化 | × | × | × |
+
# 五、多版本并发控制
多版本并发控制(Multi-Version Concurrency Control, MVCC)是 MySQL 的 InnoDB 存储引擎实现隔离级别的一种具体方式,用于实现提交读和可重复读这两种隔离级别。而未提交读隔离级别总是读取最新的数据行,要求很低,无需使用 MVCC。可串行化隔离级别需要对所有读取的行都加锁,单纯使用 MVCC 无法实现。
-## 版本号
+## 基本思想
-在封锁一节中提到,加锁能解决多个事务同时执行时出现的并发一致性问题。但是封锁操作代价很高,而多版本并发控制采用无锁机制,而是利用“版本”来解决并发一致性问题。它的基本思想是为每个数据行维护创建
+在封锁一节中提到,加锁能解决多个事务同时执行时出现的并发一致性问题。但是加锁操作代价很高,并且在实际场景中读多写少,所有事务都是只是进行读操作的话就没必要进行加锁。
+
+MVCC 的读操作不需要进行加锁,并且在可重复读隔离级别下能解决脏读和不可重复读问题。它的基本思想是为每个数据行维护多个版本的快照,多个事务可以同时去操作这个数据行。
+
+事务的修改操作(DELETE、INSERT、UPDATE)会去修改该事务对应版本的快照。
+
+脏读和不可重复读最根本的原因是事务读取到其它事务未提交的修改。在事务在进行读取操作时,为了解决脏读和不可重复读问题,读取的快照需要满足以下条件:快照在该事务开始之后没有被其它事务修改,否则会读取到其它事务的未提交的修改操作。
+
+## Undo 日志
+
+MVCC 的多版本指的是多个版本的快照,这个快照存储在 Undo 日志中,该日志通过回滚指针把一个数据行的所有快照连接起来。
+
+例如我们在 MySQL 创建一个表 t,包含主键 id 和一个字段 x。我们先插入一个数据行,然后对该数据行执行两次操作。
+
+```sql
+INSERT INTO t(id, x) VALUES(1, "a");
+UPDATE t SET x="b" WHERE id=1;
+UPDATE t SET x="c" WHERE id=1;
+```
+
+因为我们没有使用 `START TRANSACTION` 将上面的操作当成一个事务来执行,根据 MySQL 的 AUTOCOMMIT 机制,每个操作都会被当成一个事务来执行,所以上面总共涉及到三个事务。
+
+
+
+## 版本号
- 系统版本号:是一个递增的数字,每开始一个新的事务,系统版本号就会自动递增。
- 事务版本号:事务开始时的系统版本号。
@@ -274,17 +293,13 @@ MVCC 在每行记录后面都保存着两个隐藏的列,用来存储两个版
- 创建版本号:指示创建一个数据行的快照时的系统版本号;
- 删除版本号:如果该快照的删除版本未定义或删除版本号大于当前事务版本号表示该快照有效
-## Undo 日志
-MVCC 使用到的快照存储在 Undo 日志中,该日志通过回滚指针把一个数据行(Record)的所有快照连接起来。
-
-
## 实现过程
以下实现过程针对可重复读隔离级别。
-当开始一个事务时,该事务的版本号肯定大于当前所有数据行快照的创建版本号,理解这一点很关键。数据行快照的创建版本号是创建数据行快照时的系统版本号,系统版本号随着创建事务而递增,因此新创建一个事务时,这个事务的系统版本号比之前的系统版本号都大,也就是比所有数据行快照的创建版本号都大。
+当开始一个事务时,该事务的版本号肯定大于当前所有数据行快照的创建版本号。数据行快照的创建版本号是创建数据行快照时的系统版本号,系统版本号随着创建事务而递增,因此新创建一个事务时,这个事务的系统版本号比之前的系统版本号都大,也就是比所有数据行快照的创建版本号都大。
### 1. SELECT
@@ -308,22 +323,27 @@ MVCC 使用到的快照存储在 Undo 日志中,该日志通过回滚指针把
### 1. 快照读
-使用 MVCC 读取的是快照中的数据,这样可以减少加锁所带来的开销。
+MVCC 的 SELECT 操作是快照中的数据,不需要进行加锁操作。
```sql
-select * from table ...;
+SELECT * FROM table ...;
```
### 2. 当前读
-读取的是最新的数据,需要加锁。以下第一个语句需要加 S 锁,其它都需要加 X 锁。
+MVCC 其它会对数据库进行修改的操作(INSERT、UPDATE、DELETE)需要加锁操作,从而读取最新的数据。
```sql
-select * from table where ? lock in share mode;
-select * from table where ? for update;
-insert;
-update;
-delete;
+INSERT;
+UPDATE;
+DELETE;
+```
+
+在进行 SELECT 操作时,可以强制指定进行加锁操作。以下第一个语句需要加 S 锁,第二个需要加 X 锁。
+
+```sql
+SELECT * FROM table WHERE ? lock in share mode;
+SELECT * FROM table WHERE ? for update;
```
# 六、Next-Key Locks
@@ -348,14 +368,14 @@ SELECT c FROM t WHERE c BETWEEN 10 and 20 FOR UPDATE;
## Next-Key Locks
-它是 Record Locks 和 Gap Locks 的结合,不仅锁定一个记录上的索引,也锁定索引之间的间隙,是一个前开后闭区间。例如一个索引包含以下值:10, 11, 13, and 20,那么就需要锁定以下区间:
+它是 Record Locks 和 Gap Locks 的结合,不仅锁定一个记录上的索引,也锁定索引之间的间隙。它锁定一个前开后闭区间,例如一个索引包含以下值:10, 11, 13, and 20,那么就需要锁定以下区间:
```sql
(-∞, 10]
(10, 11]
(11, 13]
(13, 20]
-(20, +supremum)
+(20, +∞)
```
# 七、关系数据库设计理论