diff --git a/docs/notes/缓存.md b/docs/notes/缓存.md
index 314176c3..9187dba9 100644
--- a/docs/notes/缓存.md
+++ b/docs/notes/缓存.md
@@ -1,5 +1,4 @@
-* [点击阅读面试进阶指南 ](https://github.com/CyC2018/Backend-Interview-Guide)
-
+
* [一、缓存特征](#一缓存特征)
* [二、LRU](#二lru)
* [三、缓存位置](#三缓存位置)
@@ -8,7 +7,7 @@
* [六、数据分布](#六数据分布)
* [七、一致性哈希](#七一致性哈希)
* [参考资料](#参考资料)
-
+
# 一、缓存特征
@@ -31,6 +30,8 @@
- LRU(Least Recently Used):最近最久未使用策略,优先淘汰最久未使用的数据,也就是上次被访问时间距离现在最久的数据。该策略可以保证内存中的数据都是热点数据,也就是经常被访问的数据,从而保证缓存命中率。
+- LFU(Least Frequently Used):最不经常使用策略,优先淘汰一段时间内使用次数最少的数据。
+
# 二、LRU
以下是基于 双向链表 + HashMap 的 LRU 算法实现,对算法的解释如下:
@@ -211,7 +212,7 @@ CDN 主要有以下优点:
- 通过部署多台服务器,从而提高系统整体的带宽性能;
- 多台服务器可以看成是一种冗余机制,从而具有高可用性。
-
+
# 五、缓存问题
@@ -260,6 +261,8 @@ CDN 主要有以下优点:
- 减少网络通信次数;
- 降低接入成本,使用长连/连接池,NIO 等。
+
+
# 六、数据分布
## 哈希分布
@@ -285,11 +288,11 @@ Distributed Hash Table(DHT) 是一种哈希分布方式,其目的是为了
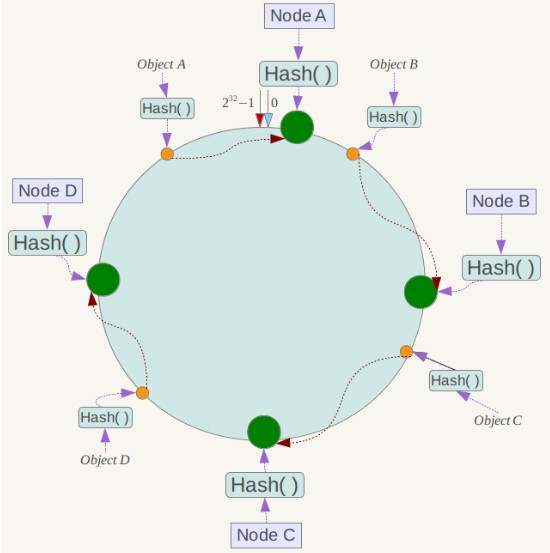
将哈希空间 [0, 2n-1] 看成一个哈希环,每个服务器节点都配置到哈希环上。每个数据对象通过哈希取模得到哈希值之后,存放到哈希环中顺时针方向第一个大于等于该哈希值的节点上。
-
+
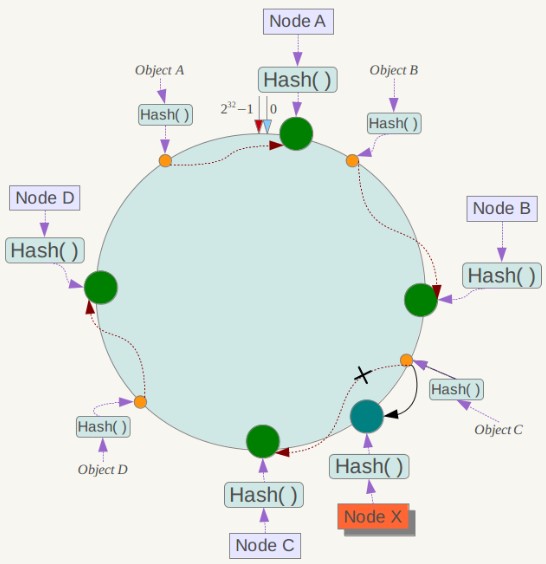
一致性哈希在增加或者删除节点时只会影响到哈希环中相邻的节点,例如下图中新增节点 X,只需要将它前一个节点 C 上的数据重新进行分布即可,对于节点 A、B、D 都没有影响。
-
+
## 虚拟节点
@@ -306,3 +309,9 @@ Distributed Hash Table(DHT) 是一种哈希分布方式,其目的是为了
- [一致性哈希算法](https://my.oschina.net/jayhu/blog/732849)
- [内容分发网络](https://zh.wikipedia.org/wiki/%E5%85%A7%E5%AE%B9%E5%82%B3%E9%81%9E%E7%B6%B2%E8%B7%AF)
- [How Aspiration CDN helps to improve your website loading speed?](https://www.aspirationhosting.com/aspiration-cdn/)
+
+
+
+
+💡 更多精彩内容将发布在公众号 **CyC2018**,公众号提供了该项目的离线阅读版本,后台回复"下载" 即可领取。也提供了一份技术面试复习思维导图,不仅系统整理了面试知识点,而且标注了各个知识点的重要程度,从而帮你理清多而杂的面试知识点,后台回复"资料" 即可领取。我基本是按照这个思维导图来进行复习的,对我拿到了 BAT 头条等 Offer 起到很大的帮助。你们完全可以和我一样根据思维导图上列的知识点来进行复习,就不用看很多不重要的内容,也可以知道哪些内容很重要从而多安排一些复习时间。
+