腾讯面试
This commit is contained in:
parent
667f850743
commit
d0a13478d4
@ -41,21 +41,27 @@ public class Test {
|
|||||||
private int a;
|
private int a;
|
||||||
|
|
||||||
public static void main(String[] args) {
|
public static void main(String[] args) {
|
||||||
//System.out.println(foo());
|
// //System.out.println(foo());
|
||||||
int r = new Test().foo();
|
// int r = new Test().foo();
|
||||||
System.out.println(r);
|
// //System.out.println(r);
|
||||||
PriorityBlockingQueue<Integer> aa;
|
// PriorityBlockingQueue<Integer> aa;
|
||||||
LinkedBlockingQueue<Integer> ss;
|
// LinkedBlockingQueue<Integer> ss;
|
||||||
ss = new LinkedBlockingQueue<>();
|
// ss = new LinkedBlockingQueue<>();
|
||||||
ss.add(1);
|
// ss.add(1);
|
||||||
ArrayBlockingQueue<Integer> s;
|
// ArrayBlockingQueue<Integer> s;
|
||||||
LinkedBlockingQueue<Integer> a;
|
// LinkedBlockingQueue<Integer> a;
|
||||||
FileInputStream fis;
|
// FileInputStream fis;
|
||||||
FileOutputStream fos;
|
// FileOutputStream fos;
|
||||||
InputStreamReader isr;
|
// InputStreamReader isr;
|
||||||
OutputStreamWriter osw;
|
// OutputStreamWriter osw;
|
||||||
float b = Math.round(11.5);
|
// float b = Math.round(11.5);
|
||||||
System.out.println(b);
|
// //System.out.println(b);
|
||||||
|
|
||||||
|
int[] t = new int[]{1,2};
|
||||||
|
int[] temp = t;
|
||||||
|
System.out.println(t[0]);
|
||||||
|
t[0]= 10;
|
||||||
|
System.out.println(temp[0]);
|
||||||
}
|
}
|
||||||
|
|
||||||
public int foo() {
|
public int foo() {
|
||||||
|
|||||||
@ -1,15 +1,9 @@
|
|||||||
package com.raorao.java;
|
package com.raorao.java;
|
||||||
|
|
||||||
import clojure.lang.Obj;
|
|
||||||
import com.google.common.collect.HashBasedTable;
|
|
||||||
import java.io.ObjectOutputStream;
|
|
||||||
import java.io.Serializable;
|
import java.io.Serializable;
|
||||||
import java.util.Enumeration;
|
import java.util.Enumeration;
|
||||||
import java.util.HashMap;
|
|
||||||
import java.util.Hashtable;
|
import java.util.Hashtable;
|
||||||
import java.util.Iterator;
|
import java.util.Iterator;
|
||||||
import java.util.LinkedHashMap;
|
|
||||||
import java.util.LinkedHashSet;
|
|
||||||
import java.util.Map.Entry;
|
import java.util.Map.Entry;
|
||||||
|
|
||||||
public class Test implements Serializable {
|
public class Test implements Serializable {
|
||||||
@ -29,10 +23,10 @@ public class Test implements Serializable {
|
|||||||
hashMap.put(2, 20);
|
hashMap.put(2, 20);
|
||||||
hashMap.put(3, 30);
|
hashMap.put(3, 30);
|
||||||
hashMap.put(19, 30);
|
hashMap.put(19, 30);
|
||||||
hashMap.forEach((e1, e2)-> System.out.println( e1 + ":" + e2));
|
hashMap.forEach((e1, e2) -> System.out.println(e1 + ":" + e2));
|
||||||
Iterator<Entry<Integer, Integer>> iterator = hashMap.entrySet().iterator();
|
Iterator<Entry<Integer, Integer>> iterator = hashMap.entrySet().iterator();
|
||||||
Enumeration<Integer> enumeration = hashMap.elements();
|
Enumeration<Integer> enumeration = hashMap.elements();
|
||||||
while (enumeration.hasMoreElements()){
|
while (enumeration.hasMoreElements()) {
|
||||||
System.out.println(enumeration.nextElement());
|
System.out.println(enumeration.nextElement());
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|||||||
@ -16,6 +16,11 @@
|
|||||||
- [Linux 内核空间和用户空间](#linux-内核空间和用户空间)
|
- [Linux 内核空间和用户空间](#linux-内核空间和用户空间)
|
||||||
- [分布式](#分布式)
|
- [分布式](#分布式)
|
||||||
- [paxos 算法](#paxos-算法)
|
- [paxos 算法](#paxos-算法)
|
||||||
|
- [Linux](#linux-1)
|
||||||
|
- [Buffer和Cache的区别](#buffer和cache的区别)
|
||||||
|
- [个人理解](#个人理解)
|
||||||
|
- [计算机网络](#计算机网络)
|
||||||
|
- [UDP为什么不可靠](#udp为什么不可靠)
|
||||||
|
|
||||||
<!-- /TOC -->
|
<!-- /TOC -->
|
||||||
|
|
||||||
@ -147,7 +152,7 @@ B+树是一个平衡的多叉树,从根节点到每个叶子节点的高度差
|
|||||||
|
|
||||||
## Linux 内核空间和用户空间
|
## Linux 内核空间和用户空间
|
||||||
|
|
||||||
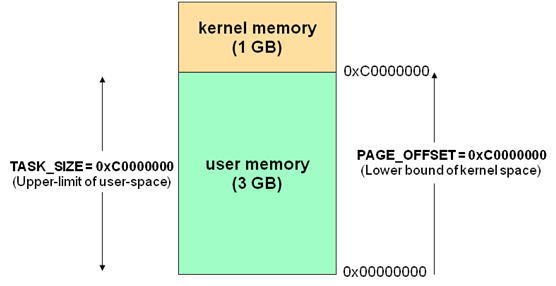
通常32位Linux内核地址空间划分0~3G为用户空间,3~4G为内核空间。注意这里是32位内核地址空间划分,64位内核地址空间划分是不同的。
|
通常32位Linux内核地址空间划分0\~3G为用户空间,3\~4G为内核空间。注意这里是32位内核地址空间划分,64位内核地址空间划分是不同的。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
@ -189,3 +194,52 @@ c. 外围设备的中断
|
|||||||
|
|
||||||
[通俗易懂](https://www.cnblogs.com/endsock/p/3480093.html)
|
[通俗易懂](https://www.cnblogs.com/endsock/p/3480093.html)
|
||||||
|
|
||||||
|
# Linux
|
||||||
|
|
||||||
|
## Buffer和Cache的区别
|
||||||
|
|
||||||
|
Buffer(缓冲区):
|
||||||
|
buffer就是写入到磁盘。buffer是为了提高内存和硬盘(或其他I/O设备)之间的数据交换的速度而设计的。buffer将数据缓冲下来,解决速度慢和快的交接问题;速度快的需要通过缓冲区将数据一点一点传给速度慢的区域。例如:从内存中将数据往硬盘中写入,并不是直接写入,而是缓冲到一定大小之后刷入硬盘中。
|
||||||
|
|
||||||
|
Cache(缓存区):
|
||||||
|
cache就是从磁盘读取数据然后存起来方便以后使用。cache实现数据的重复使用,速度慢的设备需要通过缓存将经常要用到的数据缓存起来,缓存下来的数据可以提供高速的传输速度给速度快的设备。例如:将硬盘中的数据读取出来放在内存的缓存区中,这样以后再次访问同一个资源,速度会快很多。
|
||||||
|
|
||||||
|
buffer和cache的特点:
|
||||||
|
|
||||||
|
共性:
|
||||||
|
都属于内存,数据都是临时的,一旦关机数据都会丢失。
|
||||||
|
|
||||||
|
差异:(先理解前两点,后两点有兴趣可以了解)
|
||||||
|
A.buffer是要写入数据;cache是已读取数据。
|
||||||
|
B.buffer数据丢失会影响数据完整性,源数据不受影响;cache数据丢失不会影响数据完整性,但会影响性能。
|
||||||
|
C.一般来说cache越大,性能越好,超过一定程度,导致命中率太低之后才会越大性能越低。buffer来说,空间越大性能影响不大,够用就行。cache过小,或者没有cache,不影响程序逻辑(高并发cache过小或者丢失导致系统忙死除外)。buffer过小有时候会影响程序逻辑,如导致网络丢包。
|
||||||
|
D.cache可以做到应用透明,编写应用的可以不用管是否有cache,可以在应用做好之后再上cache。当然开发者显式使用cache也行。buffer需要编写应用的人设计,是程序的一部分。
|
||||||
|
|
||||||
|
### 个人理解
|
||||||
|
|
||||||
|
Buffer就是写磁盘的时候先缓冲到内存,然后一次性写入。
|
||||||
|
Cache就是加快读取的速度,分为磁盘缓存和CPU缓存。
|
||||||
|
|
||||||
|
1、Cache是高速存储区域,而Buffer是RAM的临时存储的正常存储区域。
|
||||||
|
|
||||||
|
2、Cache是由静态RAM构成的,它比Buffer较慢的动态RAM更快。
|
||||||
|
|
||||||
|
3、Buffer主要用于输入/输出过程,而Cache则用于从磁盘读取和写入进程。
|
||||||
|
|
||||||
|
4、Cache也可以是磁盘的一部分,而Buffer只是RAM的一部分。
|
||||||
|
|
||||||
|
5、在Cache不能使用的情况下,可以在键盘中使用Buffer来编辑打字错误。
|
||||||
|
|
||||||
|
动态RAM: 计算机内存。
|
||||||
|
静态RAM: CPU高速缓存。
|
||||||
|
|
||||||
|
# 计算机网络
|
||||||
|
|
||||||
|
## UDP为什么不可靠
|
||||||
|
|
||||||
|
UDP只有一个socket接受缓冲区,没有socket发送缓冲区,即只要有数据就发,不管对方是否可以正确接受。而在对方的socket接受缓冲区满了之后,新来的数据报无法进入到socket接受缓冲区,此数据报就会被丢弃,udp是没有流量控制的,故UDP的数据传输是不可靠的。
|
||||||
|
|
||||||
|
⑴当客户发送请求报文后,等待服务器的应答,客户进程收到一个应答后,就将其存放到该套接字的接收缓冲区中,此时,如果刚好有其他进程给该客户的这个端口地址发送了一个数据报,则客户的套接字会误以为是服务器的应答,也会将其存放到这个接收缓冲区中。这样在客户的接收缓冲区中会出现噪声数据。
|
||||||
|
⑵当客户发送请求报文后,等待服务器的应答,但是由于UDP协议是不可靠的,数据在网络中传输有可能会丢失。
|
||||||
|
⑶由于通信前没有事先建立联系,客户在发送请求时不知道服务器的状态。
|
||||||
|
⑷由于通信前双方的处理能力未知且没有流量控制机制,发送端发送数据是并不清楚接收端的接收能力,如果快速设备无限制地向慢速设备发送UDP数据报,可能会由于接收方的接收缓冲区溢出而丢失大量数据,而且这种丢失对于通信双方而言都是不清楚的。
|
||||||
168
interview/database/mysql.md
Normal file
168
interview/database/mysql.md
Normal file
@ -0,0 +1,168 @@
|
|||||||
|
<!-- TOC -->
|
||||||
|
|
||||||
|
- [mysql 分区](#mysql-分区)
|
||||||
|
- [分区语法](#分区语法)
|
||||||
|
- [分区类型](#分区类型)
|
||||||
|
- [分区优点](#分区优点)
|
||||||
|
- [根据range(范围)分区](#根据range范围分区)
|
||||||
|
- [根据List分区](#根据list分区)
|
||||||
|
- [根据哈希分区](#根据哈希分区)
|
||||||
|
- [修改分区](#修改分区)
|
||||||
|
- [事务管理](#事务管理)
|
||||||
|
- [MySQL 事务特性和隔离级别](#mysql-事务特性和隔离级别)
|
||||||
|
- [事务的基本要素(ACID):](#事务的基本要素acid)
|
||||||
|
- [事务的并发问题:](#事务的并发问题)
|
||||||
|
- [Mysql事务隔离级别:](#mysql事务隔离级别)
|
||||||
|
|
||||||
|
<!-- /TOC -->
|
||||||
|
|
||||||
|
# mysql 分区
|
||||||
|
|
||||||
|
使用 partition by 来实现表的分区。
|
||||||
|
|
||||||
|
## 分区语法
|
||||||
|
|
||||||
|
``` sql
|
||||||
|
create table t(id int,name varchar(20)) engine=myisam partition by range(id);
|
||||||
|
```
|
||||||
|
|
||||||
|
## 分区类型
|
||||||
|
|
||||||
|
分区具有如下4种类型:
|
||||||
|
|
||||||
|
- Range分区:是对一个连续性的行值,按范围进行分区;比如:id小于100;id大于100小于200;
|
||||||
|
- List分区:跟range分区类似,不过它存放的是一个离散值的集合。
|
||||||
|
- Hash分区:对用户定义的表达式所返回的值来进行分区。可以写partitions (分区数目),或直接使用分区语句,比如partition p0 values in…..。
|
||||||
|
- Key分区:与hash分区类似,只不过分区支持一列或多列,并且MySQL服务器自身提供hash函数。
|
||||||
|
|
||||||
|
## 分区优点
|
||||||
|
|
||||||
|
1. 可以提高数据库的性能;
|
||||||
|
2. 对大表(行较多)的维护更快、更容易,因为数据分布在不同的逻辑文件上;
|
||||||
|
3. 删除分区或它的数据是容易的,因为它不影响其他表。
|
||||||
|
|
||||||
|
## 根据range(范围)分区
|
||||||
|
|
||||||
|
``` sql
|
||||||
|
create table orders_range
|
||||||
|
(
|
||||||
|
id int auto_increment primary key,
|
||||||
|
customer_surname varchar (30),
|
||||||
|
store_id int,
|
||||||
|
salesperson_id int,
|
||||||
|
order_Date date,
|
||||||
|
note varchar(500)
|
||||||
|
) engine=myisam
|
||||||
|
partition by range(id)
|
||||||
|
(
|
||||||
|
partition p0 values less than(5),
|
||||||
|
partition p1 values less than(10),
|
||||||
|
partition p3 values less than(15)
|
||||||
|
);
|
||||||
|
```
|
||||||
|
|
||||||
|
## 根据List分区
|
||||||
|
|
||||||
|
``` sql
|
||||||
|
create table orders_list
|
||||||
|
(
|
||||||
|
id int auto_increment,
|
||||||
|
customer_surname varchar(30),
|
||||||
|
store_id int,
|
||||||
|
salesperson_id int,
|
||||||
|
order_Date date,
|
||||||
|
note varchar(500),
|
||||||
|
index idx(id)
|
||||||
|
) engine=myisam partition by list(store_id)
|
||||||
|
(
|
||||||
|
partition p0 values in(1,3),
|
||||||
|
partition p1 values in2,4,6),
|
||||||
|
partition p3 values in(10)
|
||||||
|
);
|
||||||
|
```
|
||||||
|
|
||||||
|
## 根据哈希分区
|
||||||
|
|
||||||
|
``` sql
|
||||||
|
按hash进行分区:
|
||||||
|
create table orders_hash
|
||||||
|
(
|
||||||
|
id int auto_increment primary key,
|
||||||
|
cutomer_surname varchar(30),
|
||||||
|
store_id int,
|
||||||
|
salesperon_id int,
|
||||||
|
order_date date,
|
||||||
|
note varcahr(500)
|
||||||
|
) engine=myisam partition by hash(id) partitions 4;
|
||||||
|
```
|
||||||
|
|
||||||
|
## 修改分区
|
||||||
|
|
||||||
|
使用alter命令来修改表的分区
|
||||||
|
|
||||||
|
``` sql
|
||||||
|
|
||||||
|
// 添加分区
|
||||||
|
Alter
|
||||||
|
table
|
||||||
|
orders_range
|
||||||
|
add
|
||||||
|
partition
|
||||||
|
(
|
||||||
|
Partition p5 values less than(maxvalue)
|
||||||
|
)
|
||||||
|
|
||||||
|
// 删除分区
|
||||||
|
Alter table orders_range remove partitioning;
|
||||||
|
```
|
||||||
|
|
||||||
|
参考链接:
|
||||||
|
- [MYSQL之水平分区----MySQL partition分区I(5.1)](https://www.cnblogs.com/aipiaoborensheng/p/6394702.html)
|
||||||
|
|
||||||
|
# 事务管理
|
||||||
|
|
||||||
|
- 事务(transaction)指一组 SQL 语句;
|
||||||
|
- 回退(rollback)指撤销指定 SQL 语句的过程;
|
||||||
|
- 提交(commit)指将未存储的 SQL 语句结果写入数据库表;
|
||||||
|
- 保留点(savepoint)指事务处理中设置的临时占位符(placeholder),你可以对它发布回退(与回退整个事务处理不同)。
|
||||||
|
|
||||||
|
不能回退 SELECT 语句,回退 SELECT 语句也没意义;也不能回退 CREATE 和 DROP 语句。
|
||||||
|
|
||||||
|
MySQL 的事务提交默认是隐式提交,每执行一条语句就把这条语句当成一个事务然后进行提交。当出现 START TRANSACTION 语句时,会关闭隐式提交;当 COMMIT 或 ROLLBACK 语句执行后,事务会自动关闭,重新恢复隐式提交。
|
||||||
|
|
||||||
|
通过设置 autocommit 为 0 可以取消自动提交;autocommit 标记是针对每个连接而不是针对服务器的。
|
||||||
|
|
||||||
|
如果没有设置保留点,ROLLBACK 会回退到 START TRANSACTION 语句处;如果设置了保留点,并且在 ROLLBACK 中指定该保留点,则会回退到该保留点。
|
||||||
|
|
||||||
|
# MySQL 事务特性和隔离级别
|
||||||
|
|
||||||
|
## 事务的基本要素(ACID):
|
||||||
|
|
||||||
|
1. 原子性(Atomicity): 事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环节。事务执行过程中出错,会回滚到事务开始前的状态,所有的操作就像没有发生一样。也就是说事务是一个不可分割的整体,就像化学中学过的原子,是物质构成的基本单位。
|
||||||
|
|
||||||
|
2. 一致性(Consistency):事务开始前和结束后,数据库的完整性约束没有被破坏 。比如A向B转账,不可能A扣了钱,B却没收到。
|
||||||
|
|
||||||
|
3. 隔离性(Isolation):同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。比如A正在从一张银行卡中取钱,在A取钱的过程结束前,B不能向这张卡转账。
|
||||||
|
|
||||||
|
4. 持久性(Durability):事务完成后,事务对数据库的所有更新将被保存到数据库,不能回滚。
|
||||||
|
|
||||||
|
## 事务的并发问题:
|
||||||
|
|
||||||
|
0、丢失修改:T1 和 T2 两个事务都对一个数据进行修改,T1 先修改,T2 随后修改,T2 的修改覆盖了 T1 的修改。
|
||||||
|
|
||||||
|
1、脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
|
||||||
|
|
||||||
|
2、不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果不一致。
|
||||||
|
|
||||||
|
3、幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
|
||||||
|
|
||||||
|
小结:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
|
||||||
|
|
||||||
|
## Mysql事务隔离级别:
|
||||||
|
|
||||||
|
事务隔离级别 | 脏读 | 不可重复读 | 幻读
|
||||||
|
---|---|---|---
|
||||||
|
读未提交(read-uncommitted) | 是 | 是 | 是
|
||||||
|
不可重复读(read-committed) | 否 | 是 | 是
|
||||||
|
可重复读(repeatable-read) | 否 | 否 | 是
|
||||||
|
串行化(serializable) | 否 | 否 | 否
|
||||||
12
interview/experience/tencent.md
Normal file
12
interview/experience/tencent.md
Normal file
@ -0,0 +1,12 @@
|
|||||||
|
# 腾讯面试问题===2018.08.24
|
||||||
|
|
||||||
|
1. 解释下CAP
|
||||||
|
|
||||||
|
2. 解释下ACID
|
||||||
|
|
||||||
|
3. Linux 如何查找一个进程的CPU和内存占用过高的原因
|
||||||
|
|
||||||
|
4. Linux buffer/cache 的区别
|
||||||
|
|
||||||
|
5. UDP为什么不可靠
|
||||||
|
|
||||||
@ -52,6 +52,9 @@
|
|||||||
- [java线程调度](#java线程调度)
|
- [java线程调度](#java线程调度)
|
||||||
- [状态转换](#状态转换)
|
- [状态转换](#状态转换)
|
||||||
- [java 线程安全和锁优化](#java-线程安全和锁优化)
|
- [java 线程安全和锁优化](#java-线程安全和锁优化)
|
||||||
|
- [java的符号引用和直接引用](#java的符号引用和直接引用)
|
||||||
|
- [符号引用](#符号引用)
|
||||||
|
- [直接引用](#直接引用)
|
||||||
|
|
||||||
<!-- /TOC -->
|
<!-- /TOC -->
|
||||||
|
|
||||||
@ -897,3 +900,17 @@ java定义了5中线程状态,在任意一个时间点,一个线程只能有
|
|||||||
|
|
||||||
- [线程安全](https://github.com/xiongraorao/Interview-Notebook/blob/master/notes/Java%20%E5%B9%B6%E5%8F%91.md#%E5%8D%81%E4%B8%80%E7%BA%BF%E7%A8%8B%E5%AE%89%E5%85%A8)
|
- [线程安全](https://github.com/xiongraorao/Interview-Notebook/blob/master/notes/Java%20%E5%B9%B6%E5%8F%91.md#%E5%8D%81%E4%B8%80%E7%BA%BF%E7%A8%8B%E5%AE%89%E5%85%A8)
|
||||||
- [锁优化](https://github.com/xiongraorao/Interview-Notebook/blob/master/notes/Java%20%E5%B9%B6%E5%8F%91.md#%E5%8D%81%E4%BA%8C%E9%94%81%E4%BC%98%E5%8C%96)
|
- [锁优化](https://github.com/xiongraorao/Interview-Notebook/blob/master/notes/Java%20%E5%B9%B6%E5%8F%91.md#%E5%8D%81%E4%BA%8C%E9%94%81%E4%BC%98%E5%8C%96)
|
||||||
|
|
||||||
|
# java的符号引用和直接引用
|
||||||
|
|
||||||
|
## 符号引用
|
||||||
|
|
||||||
|
符号引用以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能够无歧义的定位到目标即可。例如,在Class文件中它以CONSTANT_Class_info、CONSTANT_Fieldref_info、CONSTANT_Methodref_info等类型的常量出现。
|
||||||
|
|
||||||
|
## 直接引用
|
||||||
|
|
||||||
|
直接引用可以是
|
||||||
|
(1)直接指向目标的指针(比如,指向“类型”【Class对象】、类变量、类方法的直接引用可能是指向方法区的指针)
|
||||||
|
(2)相对偏移量(比如,指向实例变量、实例方法的直接引用都是偏移量)
|
||||||
|
(3)一个能间接定位到目标的句柄
|
||||||
|
直接引用是和虚拟机的布局相关的,同一个符号引用在不同的虚拟机实例上翻译出来的直接引用一般不会相同。如果有了直接引用,那引用的目标必定已经被加载入内存中了。
|
||||||
@ -42,6 +42,7 @@ Java后端开发(大数据、分布式应用等)
|
|||||||
百度 | 8.22 | 8.22(新投递) |
|
百度 | 8.22 | 8.22(新投递) |
|
||||||
网易 | 8.22 | 8.22(新投递) |
|
网易 | 8.22 | 8.22(新投递) |
|
||||||
腾讯 | 8.22 | 8.22(新投递)
|
腾讯 | 8.22 | 8.22(新投递)
|
||||||
|
Intel | 8.23 | 8.23(新投递) | 电面 | 8.24一面
|
||||||
|
|
||||||
|
|
||||||
# 2 复习内容
|
# 2 复习内容
|
||||||
|
|||||||
@ -3,3 +3,7 @@
|
|||||||
比如求10亿个数中的最大的前10个数,时时构建只有10个元素的小顶堆,如果比堆顶小,则不处理;如果比堆顶大,则替换堆顶,然后依次下沉到适当的位置。
|
比如求10亿个数中的最大的前10个数,时时构建只有10个元素的小顶堆,如果比堆顶小,则不处理;如果比堆顶大,则替换堆顶,然后依次下沉到适当的位置。
|
||||||
|
|
||||||
比如求10亿个数中的最小的前10个数,时时构建只有10个元素的大顶堆,如果比堆顶大,则不处理;如果比堆顶小,则替换堆顶,然后依次下沉到适当的位置。
|
比如求10亿个数中的最小的前10个数,时时构建只有10个元素的大顶堆,如果比堆顶大,则不处理;如果比堆顶小,则替换堆顶,然后依次下沉到适当的位置。
|
||||||
|
|
||||||
|
# 堆排序的原理
|
||||||
|
|
||||||
|
- [图解排序算法(三)之堆排序](https://www.cnblogs.com/chengxiao/p/6129630.html)
|
||||||
@ -14,6 +14,7 @@
|
|||||||
- [B*树](#b树)
|
- [B*树](#b树)
|
||||||
- [B B- B+ B* 树总结](#b-b--b-b-树总结)
|
- [B B- B+ B* 树总结](#b-b--b-b-树总结)
|
||||||
- [B+/B*Tree应用](#bbtree应用)
|
- [B+/B*Tree应用](#bbtree应用)
|
||||||
|
- [Mysql中B+树索引](#mysql中b树索引)
|
||||||
- [参考链接](#参考链接)
|
- [参考链接](#参考链接)
|
||||||
|
|
||||||
<!-- /TOC -->
|
<!-- /TOC -->
|
||||||
@ -234,6 +235,13 @@ B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点
|
|||||||
|
|
||||||
参考链接:[B-树和B+树的应用:数据搜索和数据库索引](http://blog.csdn.net/hguisu/article/details/7786014)
|
参考链接:[B-树和B+树的应用:数据搜索和数据库索引](http://blog.csdn.net/hguisu/article/details/7786014)
|
||||||
|
|
||||||
|
# Mysql中B+树索引
|
||||||
|
|
||||||
|
参考文档:
|
||||||
|
- [经典查找算法 --- B+树](https://blog.csdn.net/sjyttkl/article/details/70198504)
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
# 参考链接
|
# 参考链接
|
||||||
|
|
||||||
- [数据结构](https://blog.csdn.net/qq_31196849/article/details/78529724)
|
- [数据结构](https://blog.csdn.net/qq_31196849/article/details/78529724)
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user