Merge fa872a22b7f24e7062b0b679eab63cbe69764d91 into 2c31eddf3481a31ab5c10ebced395497c6bf9d61
This commit is contained in:
commit
ec74bac00a
144
README.md
144
README.md
@ -1,142 +1,2 @@
|
||||
<div align="center">
|
||||
<a href="https://www.cyc2018.xyz"> <img src="https://badgen.net/badge/CyC/%E5%9C%A8%E7%BA%BF%E9%98%85%E8%AF%BB?icon=sourcegraph&color=4ab8a1"></a>
|
||||
<a href="https://gitstar-ranking.com/repositories"> <img src="https://badgen.net/badge/Rank/13?icon=github&color=4ab8a1"></a>
|
||||
<a href="https://github.com/CyC2018/CS-Notes"> <img src="https://badgen.net/github/stars/CyC2018/CS-Notes?icon=github&color=4ab8a1"></a>
|
||||
<a href="https://github.com/CyC2018/CS-Notes"> <img src="https://badgen.net/github/forks/CyC2018/CS-Notes?icon=github&color=4ab8a1"></a>
|
||||
<!-- <a href="assets/download.md"> <img src="https://badgen.net/badge/OvO/%E7%A6%BB%E7%BA%BF%E4%B8%8B%E8%BD%BD?icon=telegram&color=4ab8a1"></a> -->
|
||||
<!-- <a href="assets/download.md"> <img src="https://badgen.net/badge/%e5%85%ac%e4%bc%97%e5%8f%b7/CyC2018?icon=rss&color=4ab8a1"></a> -->
|
||||
</div>
|
||||
<br>
|
||||
|
||||
| 算法 | 操作系统 | 网络 |面向对象| 数据库 | Java |系统设计| 工具 |编码实践| 后记 |
|
||||
| :---: | :----: | :---: | :----: | :----: | :----: | :----: | :----: | :----: | :----: |
|
||||
| [:pencil2:](#pencil2-算法) | [:computer:](#computer-操作系统) | [:cloud:](#cloud-网络) | [:art:](#art-面向对象) | [:floppy_disk:](#floppy_disk-数据库) |[:coffee:](#coffee-java)| [:bulb:](#bulb-系统设计) |[:wrench:](#wrench-工具)| [:watermelon:](#watermelon-编码实践) |[:memo:](#memo-后记)|
|
||||
|
||||
<br>
|
||||
|
||||
<div align="center">
|
||||
<img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/githubio/LogoMakr_0zpEzN.png" width="200px">
|
||||
</div>
|
||||
|
||||
<br>
|
||||
|
||||
## :pencil2: 算法
|
||||
|
||||
- [剑指 Offer 题解](https://github.com/CyC2018/CS-Notes/blob/master/notes/剑指%20Offer%20题解%20-%20目录.md)
|
||||
- [Leetcode 题解](https://github.com/CyC2018/CS-Notes/blob/master/notes/Leetcode%20题解%20-%20目录.md)
|
||||
- [算法](https://github.com/CyC2018/CS-Notes/blob/master/notes/算法%20-%20目录.md)
|
||||
- [字节跳动内推](assets/内推.md)
|
||||
|
||||
## :computer: 操作系统
|
||||
|
||||
- [计算机操作系统](https://github.com/CyC2018/CS-Notes/blob/master/notes/计算机操作系统%20-%20目录.md)
|
||||
- [Linux](https://github.com/CyC2018/CS-Notes/blob/master/notes/Linux.md)
|
||||
|
||||
## :cloud: 网络
|
||||
|
||||
- [计算机网络](https://github.com/CyC2018/CS-Notes/blob/master/notes/计算机网络%20-%20目录.md)
|
||||
- [HTTP](https://github.com/CyC2018/CS-Notes/blob/master/notes/HTTP.md)
|
||||
- [Socket](https://github.com/CyC2018/CS-Notes/blob/master/notes/Socket.md)
|
||||
|
||||
## :floppy_disk: 数据库
|
||||
|
||||
- [数据库系统原理](https://github.com/CyC2018/CS-Notes/blob/master/notes/数据库系统原理.md)
|
||||
- [SQL 语法](https://github.com/CyC2018/CS-Notes/blob/master/notes/SQL%20语法.md)
|
||||
- [SQL 练习](https://github.com/CyC2018/CS-Notes/blob/master/notes/SQL%20练习.md)
|
||||
- [MySQL](https://github.com/CyC2018/CS-Notes/blob/master/notes/MySQL.md)
|
||||
- [Redis](https://github.com/CyC2018/CS-Notes/blob/master/notes/Redis.md)
|
||||
|
||||
## :coffee: Java
|
||||
|
||||
- [Java 基础](https://github.com/CyC2018/CS-Notes/blob/master/notes/Java%20基础.md)
|
||||
- [Java 容器](https://github.com/CyC2018/CS-Notes/blob/master/notes/Java%20容器.md)
|
||||
- [Java 并发](https://github.com/CyC2018/CS-Notes/blob/master/notes/Java%20并发.md)
|
||||
- [Java 虚拟机](https://github.com/CyC2018/CS-Notes/blob/master/notes/Java%20虚拟机.md)
|
||||
- [Java I/O](https://github.com/CyC2018/CS-Notes/blob/master/notes/Java%20IO.md)
|
||||
|
||||
## :bulb: 系统设计
|
||||
|
||||
- [系统设计基础](https://github.com/CyC2018/CS-Notes/blob/master/notes/系统设计基础.md)
|
||||
- [分布式](https://github.com/CyC2018/CS-Notes/blob/master/notes/分布式.md)
|
||||
- [集群](https://github.com/CyC2018/CS-Notes/blob/master/notes/集群.md)
|
||||
- [攻击技术](https://github.com/CyC2018/CS-Notes/blob/master/notes/攻击技术.md)
|
||||
- [缓存](https://github.com/CyC2018/CS-Notes/blob/master/notes/缓存.md)
|
||||
- [消息队列](https://github.com/CyC2018/CS-Notes/blob/master/notes/消息队列.md)
|
||||
|
||||
## :art: 面向对象
|
||||
|
||||
- [面向对象思想](https://github.com/CyC2018/CS-Notes/blob/master/notes/面向对象思想.md)
|
||||
- [设计模式](https://github.com/CyC2018/CS-Notes/blob/master/notes/设计模式%20-%20目录.md)
|
||||
|
||||
## :wrench: 工具
|
||||
|
||||
- [Git](https://github.com/CyC2018/CS-Notes/blob/master/notes/Git.md)
|
||||
- [Docker](https://github.com/CyC2018/CS-Notes/blob/master/notes/Docker.md)
|
||||
- [构建工具](https://github.com/CyC2018/CS-Notes/blob/master/notes/构建工具.md)
|
||||
- [正则表达式](https://github.com/CyC2018/CS-Notes/blob/master/notes/正则表达式.md)
|
||||
|
||||
## :watermelon: 编码实践
|
||||
|
||||
- [代码可读性](https://github.com/CyC2018/CS-Notes/blob/master/notes/代码可读性.md)
|
||||
- [代码风格规范](https://github.com/CyC2018/CS-Notes/blob/master/notes/代码风格规范.md)
|
||||
|
||||
## :memo: 后记
|
||||
|
||||
### 排版
|
||||
|
||||
笔记内容按照 [中文文案排版指北](https://github.com/sparanoid/chinese-copywriting-guidelines/blob/master/README.zh-CN.md) 进行排版,以保证内容的可读性。
|
||||
|
||||
不使用 `![]()` 这种方式来引用图片,而是用 `<img>` 标签。一方面是为了能够控制图片以合适的大小显示,另一方面是因为 [GFM](https://github.github.com/gfm/) 不支持 `<center> ![]() </center>` 这种方法让图片居中显示,只能使用 `<div align="center"> <img src=""/> </div>` 达到居中的效果。
|
||||
|
||||
在线排版工具:[Text-Typesetting](https://github.com/CyC2018/Text-Typesetting)。
|
||||
|
||||
### License
|
||||
|
||||
本仓库的内容不是将网上的资料随意拼凑而来,除了少部分引用书上和技术文档的原文(这部分内容都在末尾的参考链接中加了出处),其余都是我的原创。在您引用本仓库内容或者对内容进行修改演绎时,请署名并以相同方式共享,谢谢。
|
||||
|
||||
转载文章请在开头明显处标明该页面地址,公众号等其它转载请联系 zhengyc101@163.com。
|
||||
|
||||
Logo:[logomakr](https://logomakr.com/)
|
||||
|
||||
<a rel="license" href="http://creativecommons.org/licenses/by-nc-sa/4.0/"><img alt="知识共享许可协议" style="border-width:0" src="https://i.creativecommons.org/l/by-nc-sa/4.0/88x31.png" /></a>
|
||||
|
||||
### 致谢
|
||||
|
||||
感谢以下人员对本仓库做出的贡献,当然不仅仅只有这些贡献者,这里就不一一列举了。如果你希望被添加到这个名单中,并且提交过 Issue 或者 PR,请与我联系。
|
||||
|
||||
<a href="https://github.com/linw7">
|
||||
<img src="https://avatars3.githubusercontent.com/u/21679154?s=400&v=4" width="50px">
|
||||
</a>
|
||||
<a href="https://github.com/g10guang">
|
||||
<img src="https://avatars1.githubusercontent.com/u/18458140?s=400&v=4" width="50px">
|
||||
</a>
|
||||
<a href="https://github.com/Sctwang">
|
||||
<img src="https://avatars3.githubusercontent.com/u/33345444?s=400&v=4" width="50px">
|
||||
</a>
|
||||
<a href="https://github.com/ResolveWang">
|
||||
<img src="https://avatars1.githubusercontent.com/u/8018776?s=400&v=4" width="50px">
|
||||
</a>
|
||||
<a href="https://github.com/crossoverJie">
|
||||
<img src="https://avatars1.githubusercontent.com/u/15684156?s=400&v=4" width="50px">
|
||||
</a>
|
||||
<a href="https://github.com/jy03078584">
|
||||
<img src="https://avatars2.githubusercontent.com/u/7719370?s=400&v=4" width="50px">
|
||||
</a>
|
||||
<a href="https://github.com/kwongtailau">
|
||||
<img src="https://avatars0.githubusercontent.com/u/22954582?s=400&v=4" width="50px">
|
||||
</a>
|
||||
<a href="https://github.com/xiangflight">
|
||||
<img src="https://avatars2.githubusercontent.com/u/10072416?s=400&v=4" width="50px">
|
||||
</a>
|
||||
<a href="https://github.com/mafulong">
|
||||
<img src="https://avatars1.githubusercontent.com/u/24795000?s=400&v=4" width="50px">
|
||||
</a>
|
||||
<a href="https://github.com/yanglbme">
|
||||
<img src="https://avatars1.githubusercontent.com/u/21008209?s=400&v=4" width="50px">
|
||||
</a>
|
||||
<a href="https://github.com/OOCZC">
|
||||
<img src="https://avatars1.githubusercontent.com/u/11623828?s=400&v=4" width="50px">
|
||||
</a>
|
||||
<a href="https://github.com/5renyuebing">
|
||||
<img src="https://avatars1.githubusercontent.com/u/32872430?s=400&v=4" width="50px">
|
||||
</a>
|
||||
# README
|
||||
|
||||
|
||||
179
SUMMARY.md
Normal file
179
SUMMARY.md
Normal file
@ -0,0 +1,179 @@
|
||||
# Table of contents
|
||||
|
||||
* [README](README.md)
|
||||
* [notes](notes/README.md)
|
||||
* [10.1 斐波那契数列](<notes/10.1 斐波那契数列.md>)
|
||||
* [10.2 矩形覆盖](<notes/10.2 矩形覆盖.md>)
|
||||
* [10.3 跳台阶](<notes/10.3 跳台阶.md>)
|
||||
* [10.4 变态跳台阶](<notes/10.4 变态跳台阶.md>)
|
||||
* [11. 旋转数组的最小数字](<notes/11. 旋转数组的最小数字.md>)
|
||||
* [12. 矩阵中的路径](<notes/12. 矩阵中的路径.md>)
|
||||
* [13. 机器人的运动范围](<notes/13. 机器人的运动范围.md>)
|
||||
* [14. 剪绳子](<notes/14. 剪绳子.md>)
|
||||
* [15. 二进制中 1 的个数](<notes/15. 二进制中 1 的个数.md>)
|
||||
* [16. 数值的整数次方](<notes/16. 数值的整数次方.md>)
|
||||
* [17. 打印从 1 到最大的 n 位数](<notes/17. 打印从 1 到最大的 n 位数.md>)
|
||||
* [18.1 在 O(1) 时间内删除链表节点](<notes/18.1 在 O(1) 时间内删除链表节点.md>)
|
||||
* [18.2 删除链表中重复的结点](<notes/18.2 删除链表中重复的结点.md>)
|
||||
* [19. 正则表达式匹配](<notes/19. 正则表达式匹配.md>)
|
||||
* [20. 表示数值的字符串](<notes/20. 表示数值的字符串.md>)
|
||||
* [21. 调整数组顺序使奇数位于偶数前面](<notes/21. 调整数组顺序使奇数位于偶数前面.md>)
|
||||
* [22. 链表中倒数第 K 个结点](<notes/22. 链表中倒数第 K 个结点.md>)
|
||||
* [23. 链表中环的入口结点](<notes/23. 链表中环的入口结点.md>)
|
||||
* [24. 反转链表](<notes/24. 反转链表.md>)
|
||||
* [25. 合并两个排序的链表](<notes/25. 合并两个排序的链表.md>)
|
||||
* [26. 树的子结构](<notes/26. 树的子结构.md>)
|
||||
* [27. 二叉树的镜像](<notes/27. 二叉树的镜像.md>)
|
||||
* [28. 对称的二叉树](<notes/28. 对称的二叉树.md>)
|
||||
* [29. 顺时针打印矩阵](<notes/29. 顺时针打印矩阵.md>)
|
||||
* [3. 数组中重复的数字](<notes/3. 数组中重复的数字.md>)
|
||||
* [30. 包含 min 函数的栈](<notes/30. 包含 min 函数的栈.md>)
|
||||
* [31. 栈的压入、弹出序列](<notes/31. 栈的压入、弹出序列.md>)
|
||||
* [32.1 从上往下打印二叉树](<notes/32.1 从上往下打印二叉树.md>)
|
||||
* [32.2 把二叉树打印成多行](<notes/32.2 把二叉树打印成多行.md>)
|
||||
* [32.3 按之字形顺序打印二叉树](<notes/32.3 按之字形顺序打印二叉树.md>)
|
||||
* [33. 二叉搜索树的后序遍历序列](<notes/33. 二叉搜索树的后序遍历序列.md>)
|
||||
* [34. 二叉树中和为某一值的路径](<notes/34. 二叉树中和为某一值的路径.md>)
|
||||
* [35. 复杂链表的复制](<notes/35. 复杂链表的复制.md>)
|
||||
* [36. 二叉搜索树与双向链表](<notes/36. 二叉搜索树与双向链表.md>)
|
||||
* [37. 序列化二叉树](<notes/37. 序列化二叉树.md>)
|
||||
* [38. 字符串的排列](<notes/38. 字符串的排列.md>)
|
||||
* [39. 数组中出现次数超过一半的数字](<notes/39. 数组中出现次数超过一半的数字.md>)
|
||||
* [4. 二维数组中的查找](<notes/4. 二维数组中的查找.md>)
|
||||
* [40. 最小的 K 个数](<notes/40. 最小的 K 个数.md>)
|
||||
* [41.1 数据流中的中位数](<notes/41.1 数据流中的中位数.md>)
|
||||
* [41.2 字符流中第一个不重复的字符](<notes/41.2 字符流中第一个不重复的字符.md>)
|
||||
* [42. 连续子数组的最大和](<notes/42. 连续子数组的最大和.md>)
|
||||
* [43. 从 1 到 n 整数中 1 出现的次数](<notes/43. 从 1 到 n 整数中 1 出现的次数.md>)
|
||||
* [44. 数字序列中的某一位数字](<notes/44. 数字序列中的某一位数字.md>)
|
||||
* [45. 把数组排成最小的数](<notes/45. 把数组排成最小的数.md>)
|
||||
* [46. 把数字翻译成字符串](<notes/46. 把数字翻译成字符串.md>)
|
||||
* [47. 礼物的最大价值](<notes/47. 礼物的最大价值.md>)
|
||||
* [48. 最长不含重复字符的子字符串](<notes/48. 最长不含重复字符的子字符串.md>)
|
||||
* [49. 丑数](<notes/49. 丑数.md>)
|
||||
* [5. 替换空格](<notes/5. 替换空格.md>)
|
||||
* [50. 第一个只出现一次的字符位置](<notes/50. 第一个只出现一次的字符位置.md>)
|
||||
* [51. 数组中的逆序对](<notes/51. 数组中的逆序对.md>)
|
||||
* [52. 两个链表的第一个公共结点](<notes/52. 两个链表的第一个公共结点.md>)
|
||||
* [53. 数字在排序数组中出现的次数](<notes/53. 数字在排序数组中出现的次数.md>)
|
||||
* [54. 二叉查找树的第 K 个结点](<notes/54. 二叉查找树的第 K 个结点.md>)
|
||||
* [55.1 二叉树的深度](<notes/55.1 二叉树的深度.md>)
|
||||
* [55.2 平衡二叉树](<notes/55.2 平衡二叉树.md>)
|
||||
* [56. 数组中只出现一次的数字](<notes/56. 数组中只出现一次的数字.md>)
|
||||
* [57.1 和为 S 的两个数字](<notes/57.1 和为 S 的两个数字.md>)
|
||||
* [57.2 和为 S 的连续正数序列](<notes/57.2 和为 S 的连续正数序列.md>)
|
||||
* [58.1 翻转单词顺序列](<notes/58.1 翻转单词顺序列.md>)
|
||||
* [58.2 左旋转字符串](<notes/58.2 左旋转字符串.md>)
|
||||
* [59. 滑动窗口的最大值](<notes/59. 滑动窗口的最大值.md>)
|
||||
* [6. 从尾到头打印链表](<notes/6. 从尾到头打印链表.md>)
|
||||
* [60. n 个骰子的点数](<notes/60. n 个骰子的点数.md>)
|
||||
* [61. 扑克牌顺子](<notes/61. 扑克牌顺子.md>)
|
||||
* [62. 圆圈中最后剩下的数](<notes/62. 圆圈中最后剩下的数.md>)
|
||||
* [63. 股票的最大利润](<notes/63. 股票的最大利润.md>)
|
||||
* [64. 求 1+2+3+...+n](<notes/64. 求 1+2+3+...+n.md>)
|
||||
* [65. 不用加减乘除做加法](<notes/65. 不用加减乘除做加法.md>)
|
||||
* [66. 构建乘积数组](<notes/66. 构建乘积数组.md>)
|
||||
* [67. 把字符串转换成整数](<notes/67. 把字符串转换成整数.md>)
|
||||
* [68. 树中两个节点的最低公共祖先](<notes/68. 树中两个节点的最低公共祖先.md>)
|
||||
* [7. 重建二叉树](<notes/7. 重建二叉树.md>)
|
||||
* [8. 二叉树的下一个结点](<notes/8. 二叉树的下一个结点.md>)
|
||||
* [9. 用两个栈实现队列](<notes/9. 用两个栈实现队列.md>)
|
||||
* [Docker](notes/Docker.md)
|
||||
* [Git](notes/Git.md)
|
||||
* [HTTP](notes/HTTP.md)
|
||||
* [Java IO](<notes/Java IO.md>)
|
||||
* [Java 基础](<notes/Java 基础.md>)
|
||||
* [Java 容器](<notes/Java 容器.md>)
|
||||
* [Java 并发](<notes/Java 并发.md>)
|
||||
* [Java 虚拟机](<notes/Java 虚拟机.md>)
|
||||
* [Leetcode 题解 - 二分查找](<notes/Leetcode 题解 - 二分查找.md>)
|
||||
* [Leetcode 题解 - 位运算](<notes/Leetcode 题解 - 位运算.md>)
|
||||
* [Leetcode 题解 - 分治](<notes/Leetcode 题解 - 分治.md>)
|
||||
* [Leetcode 题解 - 动态规划](<notes/Leetcode 题解 - 动态规划.md>)
|
||||
* [Leetcode 题解 - 双指针](<notes/Leetcode 题解 - 双指针.md>)
|
||||
* [Leetcode 题解 - 哈希表](<notes/Leetcode 题解 - 哈希表.md>)
|
||||
* [Leetcode 题解 - 图](<notes/Leetcode 题解 - 图.md>)
|
||||
* [Leetcode 题解 - 字符串](<notes/Leetcode 题解 - 字符串.md>)
|
||||
* [Leetcode 题解 - 排序](<notes/Leetcode 题解 - 排序.md>)
|
||||
* [Leetcode 题解 - 搜索](<notes/Leetcode 题解 - 搜索.md>)
|
||||
* [Leetcode 题解 - 数学](<notes/Leetcode 题解 - 数学.md>)
|
||||
* [Leetcode 题解 - 数组与矩阵](<notes/Leetcode 题解 - 数组与矩阵.md>)
|
||||
* [Leetcode 题解 - 栈和队列](<notes/Leetcode 题解 - 栈和队列.md>)
|
||||
* [Leetcode 题解 - 树](<notes/Leetcode 题解 - 树.md>)
|
||||
* [Leetcode 题解](<notes/Leetcode 题解 - 目录.md>)
|
||||
* [Leetcode 题解 - 贪心思想](<notes/Leetcode 题解 - 贪心思想.md>)
|
||||
* [Leetcode 题解 - 链表](<notes/Leetcode 题解 - 链表.md>)
|
||||
* [Leetcode 题解](<notes/Leetcode 题解.md>)
|
||||
* [Linux](notes/Linux.md)
|
||||
* [MySQL](notes/MySQL.md)
|
||||
* [Redis](notes/Redis.md)
|
||||
* [SQL 练习](<notes/SQL 练习.md>)
|
||||
* [SQL 语法](<notes/SQL 语法.md>)
|
||||
* [SQL](notes/SQL.md)
|
||||
* [Socket](notes/Socket.md)
|
||||
* [代码可读性](notes/代码可读性.md)
|
||||
* [代码风格规范](notes/代码风格规范.md)
|
||||
* [分布式](notes/分布式.md)
|
||||
* [剑指 Offer 题解](<notes/剑指 Offer 题解 - 目录.md>)
|
||||
* [剑指 offer 题解](<notes/剑指 offer 题解.md>)
|
||||
* [攻击技术](notes/攻击技术.md)
|
||||
* [数据库系统原理](notes/数据库系统原理.md)
|
||||
* [构建工具](notes/构建工具.md)
|
||||
* [正则表达式](notes/正则表达式.md)
|
||||
* [消息队列](notes/消息队列.md)
|
||||
* [算法 - 其它](<notes/算法 - 其它.md>)
|
||||
* [算法 - 并查集](<notes/算法 - 并查集.md>)
|
||||
* [算法 - 排序](<notes/算法 - 排序.md>)
|
||||
* [算法 - 栈和队列](<notes/算法 - 栈和队列.md>)
|
||||
* [算法目录](<notes/算法 - 目录.md>)
|
||||
* [算法 - 符号表](<notes/算法 - 符号表.md>)
|
||||
* [算法 - 算法分析](<notes/算法 - 算法分析.md>)
|
||||
* [算法](notes/算法.md)
|
||||
* [系统设计基础](notes/系统设计基础.md)
|
||||
* [缓存](notes/缓存.md)
|
||||
* [计算机操作系统 - 内存管理](<notes/计算机操作系统 - 内存管理.md>)
|
||||
* [计算机操作系统 - 概述](<notes/计算机操作系统 - 概述.md>)
|
||||
* [计算机操作系统 - 死锁](<notes/计算机操作系统 - 死锁.md>)
|
||||
* [计算机操作系统](<notes/计算机操作系统 - 目录.md>)
|
||||
* [计算机操作系统 - 设备管理](<notes/计算机操作系统 - 设备管理.md>)
|
||||
* [计算机操作系统 - 进程管理](<notes/计算机操作系统 - 进程管理.md>)
|
||||
* [计算机操作系统 - 链接](<notes/计算机操作系统 - 链接.md>)
|
||||
* [计算机操作系统](notes/计算机操作系统.md)
|
||||
* [计算机网络 - 传输层](<notes/计算机网络 - 传输层.md>)
|
||||
* [计算机网络 - 应用层](<notes/计算机网络 - 应用层.md>)
|
||||
* [计算机网络 - 概述](<notes/计算机网络 - 概述.md>)
|
||||
* [计算机网络 - 物理层](<notes/计算机网络 - 物理层.md>)
|
||||
* [计算机网络](<notes/计算机网络 - 目录.md>)
|
||||
* [计算机网络 - 网络层](<notes/计算机网络 - 网络层.md>)
|
||||
* [计算机网络 - 链路层](<notes/计算机网络 - 链路层.md>)
|
||||
* [计算机网络](notes/计算机网络.md)
|
||||
* [单例(Singleton)](<notes/设计模式 - 单例.md>)
|
||||
* [5. 中介者(Mediator)](<notes/设计模式 - 中介者.md>)
|
||||
* [享元(Flyweight)](<notes/设计模式 - 享元.md>)
|
||||
* [代理(Proxy)](<notes/设计模式 - 代理.md>)
|
||||
* [6. 原型模式(Prototype)](<notes/设计模式 - 原型模式.md>)
|
||||
* [2. 命令(Command)](<notes/设计模式 - 命令.md>)
|
||||
* [备忘录(Memento)](<notes/设计模式 - 备忘录.md>)
|
||||
* [外观(Facade)](<notes/设计模式 - 外观.md>)
|
||||
* [工厂方法(Factory Method)](<notes/设计模式 - 工厂方法.md>)
|
||||
* [4. 抽象工厂(Abstract Factory)](<notes/设计模式 - 抽象工厂.md>)
|
||||
* [桥接(Bridge)](<notes/设计模式 - 桥接.md>)
|
||||
* [模板方法(Template Method)](<notes/设计模式 - 模板方法.md>)
|
||||
* [8. 状态(State)](<notes/设计模式 - 状态.md>)
|
||||
* [5. 生成器(Builder)](<notes/设计模式 - 生成器.md>)
|
||||
* [设计模式目录](<notes/设计模式 - 目录.md>)
|
||||
* [设计模式 - 目录1](<notes/设计模式 - 目录1.md>)
|
||||
* [空对象(Null)](<notes/设计模式 - 空对象.md>)
|
||||
* [9. 策略(Strategy)](<notes/设计模式 - 策略.md>)
|
||||
* [简单工厂(Simple Factory)](<notes/设计模式 - 简单工厂.md>)
|
||||
* [组合(Composite)](<notes/设计模式 - 组合.md>)
|
||||
* [装饰(Decorator)](<notes/设计模式 - 装饰.md>)
|
||||
* [7. 观察者(Observer)](<notes/设计模式 - 观察者.md>)
|
||||
* [解释器(Interpreter)](<notes/设计模式 - 解释器.md>)
|
||||
* [访问者(Visitor)](<notes/设计模式 - 访问者.md>)
|
||||
* [责任链(Chain Of Responsibility)](<notes/设计模式 - 责任链.md>)
|
||||
* [迭代器(Iterator)](<notes/设计模式 - 迭代器.md>)
|
||||
* [1. 适配器(Adapter)](<notes/设计模式 - 适配器.md>)
|
||||
* [设计模式](notes/设计模式.md)
|
||||
* [集群](notes/集群.md)
|
||||
* [面向对象思想](notes/面向对象思想.md)
|
||||
@ -1,33 +0,0 @@
|
||||
# 目的
|
||||
|
||||
考虑到有部分读者的网络环境较差,有时候在线访问速度很慢,导致阅读体验不佳。另外,PDF 等格式的离线版本相比于网页在线版本更方便做笔记。因此提供离线阅读版本给大家下载。
|
||||
|
||||
# 内容
|
||||
|
||||
有三种格式的离线版本:PDF、Markdown 和 HTML 。
|
||||
|
||||
## PDF
|
||||
|
||||
优点是方便做笔记;缺点是不能显示 GIF 图片(所以“剑指 Offer 题解”不建议使用 PDF 进行阅读),以及显示效果不佳。
|
||||
|
||||

|
||||
|
||||
## Markdown
|
||||
|
||||
优点是能很好地显示 GIF 图片,显示效果也很好;缺点是由于将所有内容整合在同一个文件中,导致实时渲染有点卡顿。
|
||||
|
||||

|
||||
|
||||
## HTML
|
||||
|
||||
优点是和 Markdown 的显示效果几乎一致,同时不需要 Markdown 的实时渲染,因此浏览速度更快;缺点是目录功能还不是很完善。
|
||||
|
||||
如果想在安卓手机端阅读,推荐使用这种格式,将 html 文件和图片文件都复制到手机上,用浏览器打开 html 文件并存成书签,以后就可以快速地离线阅读。
|
||||
|
||||

|
||||
|
||||
# 如何下载
|
||||
|
||||
离线版本由公众号 **CyC2018** 发布,最新版本也会在上面及时发布,在后台回复 **CyC** 即可获取下载链接。
|
||||
|
||||
<div align="center"><img width="350px" src="公众号二维码-2.png"></img></div>
|
||||
33
assets/内推.md
33
assets/内推.md
@ -1,33 +0,0 @@
|
||||
# 内推群
|
||||
|
||||
加群可帮查内推进度,简历修改建议。如果投递我所在的深圳头条服务端团队,可加第一个群,其它的加第二个群。
|
||||
|
||||
<img src="内推群.png" width="350px">
|
||||
|
||||
# 校招
|
||||
|
||||
[校招岗位信息](https://jobs.bytedance.com/campus/position?keywords=&category=6704215862557018372&location=&project=&type=2%2C3&job_hot_flag=¤t=1&limit=10&referral_code=KHTRBTP)
|
||||
|
||||
直接进入上面的链接并投递,就算内推,然后加群即可查看内推进度。
|
||||
|
||||
# 国际化电商团队
|
||||
|
||||
<img src="国际化电商.png" width="350px">
|
||||
|
||||
# 社招
|
||||
|
||||
[社招岗位信息](https://jobs.bytedance.com/experienced/position?keywords=&category=&location=&project=&type=&job_hot_flag=¤t=1&limit=10)
|
||||
|
||||
先看好要投递的岗位,加群后再私聊我。
|
||||
|
||||
# 内推到我的部门
|
||||
|
||||
## 校招
|
||||
|
||||
[校招链接内推链接](https://jobs.bytedance.com/referral/pc/position/detail/?token=MTsxNjE2MDA2MzM2NzU2OzY3MTMzMjUzMjEwMTk2MDY1MzY7NjkwODkxNzY0NTIxMjkxMTg3OQ),备注“深圳头条服务端”。
|
||||
|
||||
## 社招
|
||||
|
||||
可直接把简历发送到 heliuxing@bytedance.com。
|
||||
|
||||
<img src="今日头条招聘海报.png" width="500px">
|
||||
@ -1,2 +0,0 @@
|
||||
# 😃 该网站已迁移至 >>> [www.cyc2018.xyz](http://www.cyc2018.xyz)
|
||||
|
||||
@ -1 +0,0 @@
|
||||
# 😃 该网站已迁移至 >>> [www.cyc2018.xyz](http://www.cyc2018.xyz)
|
||||
@ -1,11 +0,0 @@
|
||||
<img width="220px" src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/other/LogoMakr_0zpEzN.png">
|
||||
|
||||
|
||||
- 本项目包含了技术面试必备的基础知识,内容浅显易懂,你不需要花很长的时间去阅读和理解成堆的技术书籍就可以快速掌握这些知识,从而节省宝贵的面试复习时间。
|
||||
|
||||
<!--<span id="busuanzi_container_site_pv">Site View : <span id="busuanzi_value_site_pv">-->
|
||||
|
||||
[](https://github.com/CyC2018/CS-Notes) [](https://github.com/CyC2018/CS-Notes)
|
||||
|
||||
[开始阅读](http://www.cyc2018.xyz)
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@ -1,30 +0,0 @@
|
||||
# [Prism](http://prismjs.com/)
|
||||
|
||||
[](https://travis-ci.org/PrismJS/prism)
|
||||
|
||||
Prism is a lightweight, robust, elegant syntax highlighting library. It's a spin-off project from [Dabblet](http://dabblet.com/).
|
||||
|
||||
You can learn more on http://prismjs.com/.
|
||||
|
||||
Why another syntax highlighter?: http://lea.verou.me/2012/07/introducing-prism-an-awesome-new-syntax-highlighter/#more-1841
|
||||
|
||||
More themes for Prism: https://github.com/PrismJS/prism-themes
|
||||
|
||||
## Contribute to Prism!
|
||||
|
||||
Prism depends on community contributions to expand and cover a wider array of use cases. If you like it, considering giving back by sending a pull request. Here are a few tips:
|
||||
|
||||
- Read the [documentation](http://prismjs.com/extending.html). Prism was designed to be extensible.
|
||||
- Do not edit `prism.js`, it’s just the version of Prism used by the Prism website and is built automatically. Limit your changes to the unminified files in the components/ folder. The minified files are also generated automatically.
|
||||
- The build system uses [gulp](https://github.com/gulpjs/gulp) to minify the files and build `prism.js`. Having gulp installed, you just need to run the command `gulp`.
|
||||
- Please follow the code conventions used in the files already. For example, I use [tabs for indentation and spaces for alignment](http://lea.verou.me/2012/01/why-tabs-are-clearly-superior/). Opening braces are on the same line, closing braces on their own line regardless of construct. There is a space before the opening brace. etc etc.
|
||||
- Please try to err towards more smaller PRs rather than few huge PRs. If a PR includes changes I want to merge and changes I don't, handling it becomes difficult.
|
||||
- My time is very limited these days, so it might take a long time to review longer PRs (short ones are usually merged very quickly), especially those modifying the Prism Core. This doesn't mean your PR is rejected.
|
||||
- If you contribute a new language definition, you will be responsible for handling bug reports about that language definition.
|
||||
- If you add a new language definition, theme or plugin, you need to add it to `components.json` as well and rebuild Prism by running `gulp`, so that it becomes available to the download build page.
|
||||
|
||||
Thank you so much for contributing!!
|
||||
|
||||
## Translations
|
||||
|
||||
* [](http://www.awesomes.cn/repo/PrismJS/prism)
|
||||
@ -2,21 +2,21 @@
|
||||
|
||||
## 题目链接
|
||||
|
||||
[牛客网](https://www.nowcoder.com/practice/c6c7742f5ba7442aada113136ddea0c3?tpId=13&tqId=11160&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[牛客网](https://www.nowcoder.com/practice/c6c7742f5ba7442aada113136ddea0c3?tpId=13\&tqId=11160\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
求斐波那契数列的第 n 项,n \<= 39。
|
||||
求斐波那契数列的第 n 项,n <= 39。
|
||||
|
||||
<!--<div align="center"><img src="https://latex.codecogs.com/gif.latex?f(n)=\left\{\begin{array}{rcl}0&&{n=0}\\1&&{n=1}\\f(n-1)+f(n-2)&&{n>1}\end{array}\right." class="mathjax-pic"/></div> <br> -->
|
||||
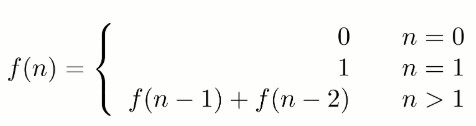\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/45be9587-6069-4ab7-b9ac-840db1a53744.jpg" width="330px"> </div><br>
|
||||
|
||||
## 解题思路
|
||||
|
||||
如果使用递归求解,会重复计算一些子问题。例如,计算 f(4) 需要计算 f(3) 和 f(2),计算 f(3) 需要计算 f(2) 和 f(1),可以看到 f(2) 被重复计算了。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/c13e2a3d-b01c-4a08-a69b-db2c4e821e09.png" width="350px"/> </div><br>
|
||||
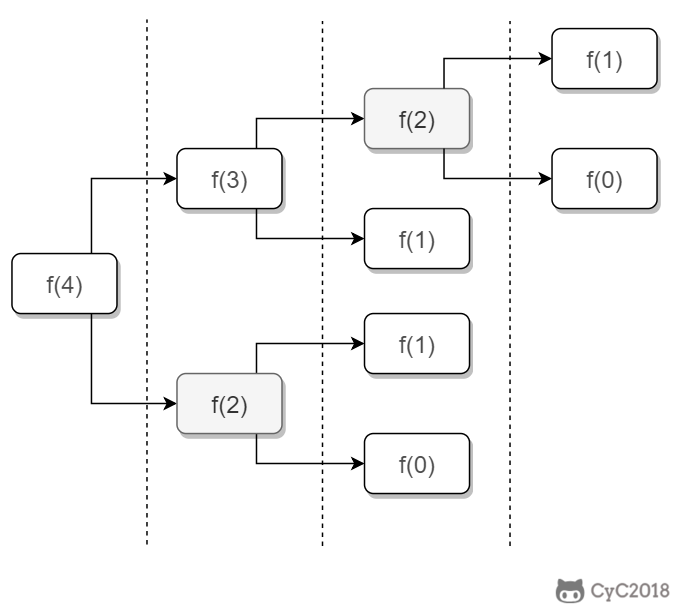\
|
||||
|
||||
|
||||
递归是将一个问题划分成多个子问题求解,动态规划也是如此,但是动态规划会把子问题的解缓存起来,从而避免重复求解子问题。
|
||||
|
||||
|
||||
@ -2,29 +2,31 @@
|
||||
|
||||
## 题目链接
|
||||
|
||||
[牛客网](https://www.nowcoder.com/practice/72a5a919508a4251859fb2cfb987a0e6?tpId=13&tqId=11163&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[牛客网](https://www.nowcoder.com/practice/72a5a919508a4251859fb2cfb987a0e6?tpId=13\&tqId=11163\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
我们可以用 2\*1 的小矩形横着或者竖着去覆盖更大的矩形。请问用 n 个 2\*1 的小矩形无重叠地覆盖一个 2\*n 的大矩形,总共有多少种方法?
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/b903fda8-07d0-46a7-91a7-e803892895cf.gif" width="100px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
当 n 为 1 时,只有一种覆盖方法:
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/f6e146f1-57ad-411b-beb3-770a142164ef.png" width="100px"> </div><br>
|
||||
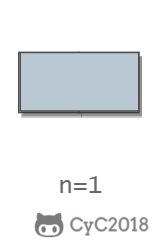\
|
||||
|
||||
|
||||
当 n 为 2 时,有两种覆盖方法:
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/fb3b8f7a-4293-4a38-aae1-62284db979a3.png" width="200px"> </div><br>
|
||||
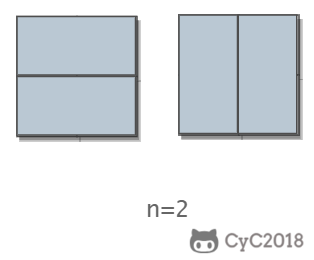\
|
||||
|
||||
|
||||
要覆盖 2\*n 的大矩形,可以先覆盖 2\*1 的矩形,再覆盖 2\*(n-1) 的矩形;或者先覆盖 2\*2 的矩形,再覆盖 2\*(n-2) 的矩形。而覆盖 2\*(n-1) 和 2\*(n-2) 的矩形可以看成子问题。该问题的递推公式如下:
|
||||
|
||||
<!-- <div align="center"><img src="https://latex.codecogs.com/gif.latex?f(n)=\left\{\begin{array}{rcl}1&&{n=1}\\2&&{n=2}\\f(n-1)+f(n-2)&&{n>1}\end{array}\right." class="mathjax-pic"/></div> <br> -->
|
||||
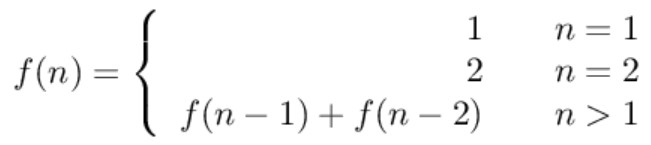\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/508c6e52-9f93-44ed-b6b9-e69050e14807.jpg" width="370px"> </div><br>
|
||||
|
||||
```java
|
||||
public int rectCover(int n) {
|
||||
|
||||
@ -2,27 +2,31 @@
|
||||
|
||||
## 题目链接
|
||||
|
||||
[牛客网](https://www.nowcoder.com/practice/8c82a5b80378478f9484d87d1c5f12a4?tpId=13&tqId=11161&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[牛客网](https://www.nowcoder.com/practice/8c82a5b80378478f9484d87d1c5f12a4?tpId=13\&tqId=11161\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
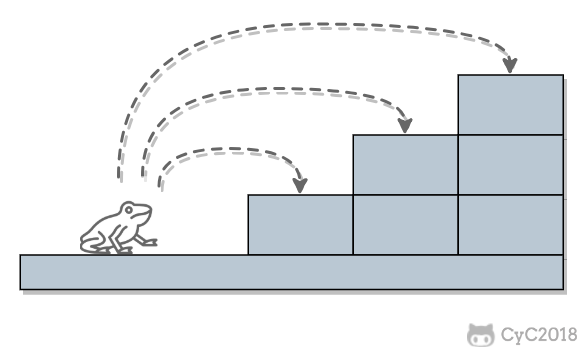
一只青蛙一次可以跳上 1 级台阶,也可以跳上 2 级。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/9dae7475-934f-42e5-b3b3-12724337170a.png" width="380px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
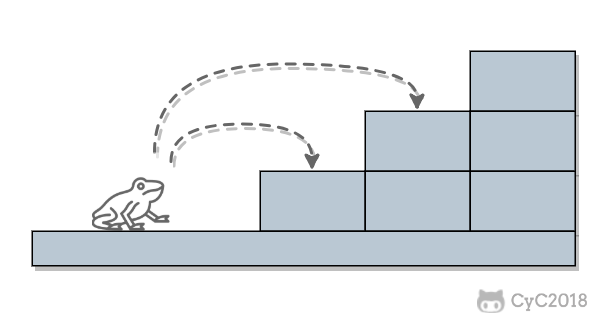
当 n = 1 时,只有一种跳法:
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/72aac98a-d5df-4bfa-a71a-4bb16a87474c.png" width="250px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
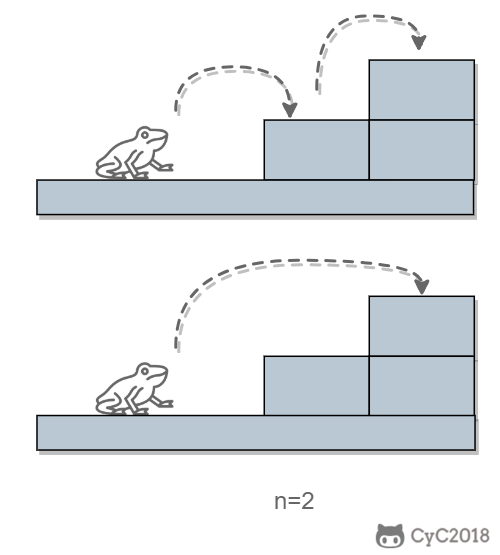
当 n = 2 时,有两种跳法:
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/1b80288d-1b35-4cd3-aa17-7e27ab9a2389.png" width="300px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
跳 n 阶台阶,可以先跳 1 阶台阶,再跳 n-1 阶台阶;或者先跳 2 阶台阶,再跳 n-2 阶台阶。而 n-1 和 n-2 阶台阶的跳法可以看成子问题,该问题的递推公式为:
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/508c6e52-9f93-44ed-b6b9-e69050e14807.jpg" width="350px"> </div><br>
|
||||
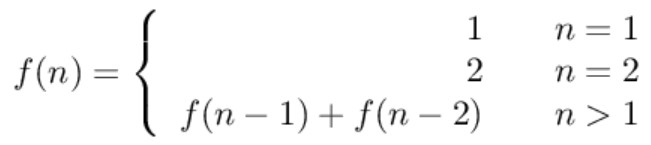\
|
||||
|
||||
|
||||
```java
|
||||
public int JumpFloor(int n) {
|
||||
|
||||
@ -2,13 +2,14 @@
|
||||
|
||||
## 题目链接
|
||||
|
||||
[牛客网](https://www.nowcoder.com/practice/22243d016f6b47f2a6928b4313c85387?tpId=13&tqId=11162&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[牛客网](https://www.nowcoder.com/practice/22243d016f6b47f2a6928b4313c85387?tpId=13\&tqId=11162\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
一只青蛙一次可以跳上 1 级台阶,也可以跳上 2 级... 它也可以跳上 n 级。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/cd411a94-3786-4c94-9e08-f28320e010d5.png" width="380px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
@ -53,7 +54,7 @@ f(n) = 2*f(n-1)
|
||||
|
||||
所以 f(n) 是一个等比数列
|
||||
|
||||
```source-java
|
||||
```
|
||||
public int JumpFloorII(int target) {
|
||||
return (int) Math.pow(2, target - 1);
|
||||
}
|
||||
|
||||
@ -2,26 +2,28 @@
|
||||
|
||||
## 题目链接
|
||||
|
||||
[牛客网](https://www.nowcoder.com/practice/9f3231a991af4f55b95579b44b7a01ba?tpId=13&tqId=11159&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[牛客网](https://www.nowcoder.com/practice/9f3231a991af4f55b95579b44b7a01ba?tpId=13\&tqId=11159\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
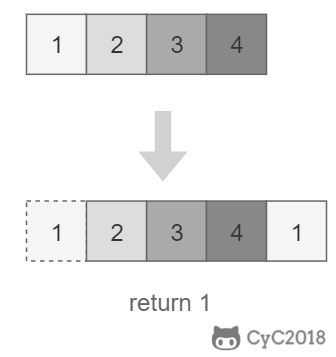
把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。输入一个非递减排序的数组的一个旋转,输出旋转数组的最小元素。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/0038204c-4b8a-42a5-921d-080f6674f989.png" width="210px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
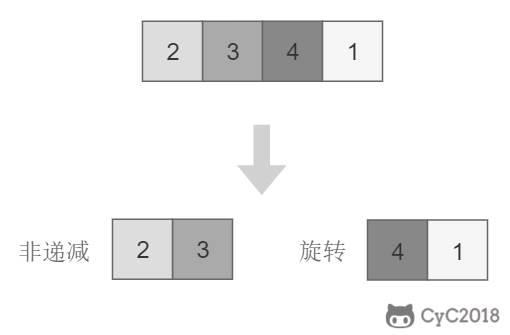
将旋转数组对半分可以得到一个包含最小元素的新旋转数组,以及一个非递减排序的数组。新的旋转数组的长度是原数组的一半,从而将问题规模减少了一半,这种折半性质的算法的时间复杂度为 O(log<sub>2</sub>N)。
|
||||
将旋转数组对半分可以得到一个包含最小元素的新旋转数组,以及一个非递减排序的数组。新的旋转数组的长度是原数组的一半,从而将问题规模减少了一半,这种折半性质的算法的时间复杂度为 O(log2N)。
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/424f34ab-a9fd-49a6-9969-d76b42251365.png" width="300px"> </div><br>
|
||||
|
||||
此时问题的关键在于确定对半分得到的两个数组哪一个是旋转数组,哪一个是非递减数组。我们很容易知道非递减数组的第一个元素一定小于等于最后一个元素。
|
||||
|
||||
通过修改二分查找算法进行求解(l 代表 low,m 代表 mid,h 代表 high):
|
||||
|
||||
- 当 nums[m] \<= nums[h] 时,表示 [m, h] 区间内的数组是非递减数组,[l, m] 区间内的数组是旋转数组,此时令 h = m;
|
||||
- 否则 [m + 1, h] 区间内的数组是旋转数组,令 l = m + 1。
|
||||
* 当 nums\[m] <= nums\[h] 时,表示 \[m, h] 区间内的数组是非递减数组,\[l, m] 区间内的数组是旋转数组,此时令 h = m;
|
||||
* 否则 \[m + 1, h] 区间内的数组是旋转数组,令 l = m + 1。
|
||||
|
||||
```java
|
||||
public int minNumberInRotateArray(int[] nums) {
|
||||
@ -39,7 +41,7 @@ public int minNumberInRotateArray(int[] nums) {
|
||||
}
|
||||
```
|
||||
|
||||
如果数组元素允许重复,会出现一个特殊的情况:nums[l] == nums[m] == nums[h],此时无法确定解在哪个区间,需要切换到顺序查找。例如对于数组 {1,1,1,0,1},l、m 和 h 指向的数都为 1,此时无法知道最小数字 0 在哪个区间。
|
||||
如果数组元素允许重复,会出现一个特殊的情况:nums\[l] == nums\[m] == nums\[h],此时无法确定解在哪个区间,需要切换到顺序查找。例如对于数组 {1,1,1,0,1},l、m 和 h 指向的数都为 1,此时无法知道最小数字 0 在哪个区间。
|
||||
|
||||
```java
|
||||
public int minNumberInRotateArray(int[] nums) {
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# 12. 矩阵中的路径
|
||||
|
||||
[牛客网](https://www.nowcoder.com/practice/69fe7a584f0a445da1b6652978de5c38?tpId=13&tqId=11218&tab=answerKey&from=cyc_github)
|
||||
[牛客网](https://www.nowcoder.com/practice/69fe7a584f0a445da1b6652978de5c38?tpId=13\&tqId=11218\&tab=answerKey\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
@ -8,13 +8,15 @@
|
||||
|
||||
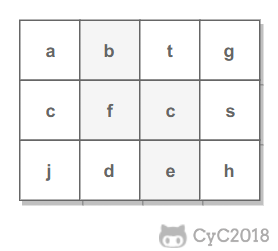
例如下面的矩阵包含了一条 bfce 路径。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/1db1c7ea-0443-478b-8df9-7e33b1336cc4.png" width="200px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
使用回溯法(backtracking)进行求解,它是一种暴力搜索方法,通过搜索所有可能的结果来求解问题。回溯法在一次搜索结束时需要进行回溯(回退),将这一次搜索过程中设置的状态进行清除,从而开始一次新的搜索过程。例如下图示例中,从 f 开始,下一步有 4 种搜索可能,如果先搜索 b,需要将 b 标记为已经使用,防止重复使用。在这一次搜索结束之后,需要将 b 的已经使用状态清除,并搜索 c。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/dc964b86-7a08-4bde-a3d9-e6ddceb29f98.png" width="200px"> </div><br>
|
||||
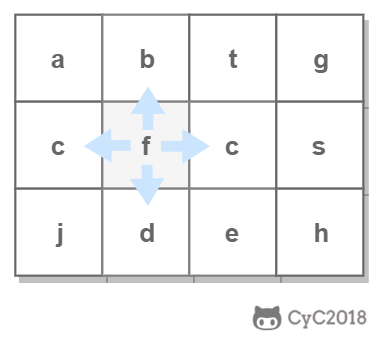\
|
||||
|
||||
|
||||
本题的输入是数组而不是矩阵(二维数组),因此需要先将数组转换成矩阵。
|
||||
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
|
||||
## 题目链接
|
||||
|
||||
[牛客网](https://www.nowcoder.com/practice/8ee967e43c2c4ec193b040ea7fbb10b8?tpId=13&tqId=11164&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[牛客网](https://www.nowcoder.com/practice/8ee967e43c2c4ec193b040ea7fbb10b8?tpId=13\&tqId=11164\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
@ -12,7 +12,7 @@
|
||||
|
||||
n&(n-1) 位运算可以将 n 的位级表示中最低的那一位 1 设置为 0。不断将 1 设置为 0,直到 n 为 0。时间复杂度:O(M),其中 M 表示 1 的个数。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20201105004127554.png" width="500px"> </div><br>
|
||||
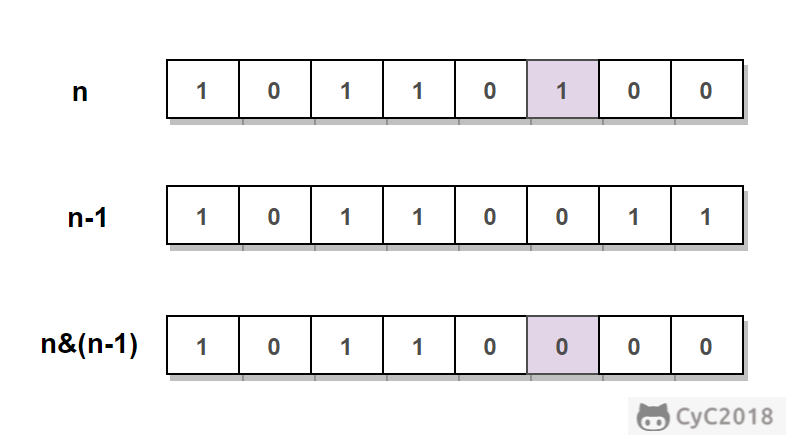\
|
||||
|
||||
|
||||
```java
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
|
||||
## 题目链接
|
||||
|
||||
[牛客网](https://www.nowcoder.com/practice/1a834e5e3e1a4b7ba251417554e07c00?tpId=13&tqId=11165&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[牛客网](https://www.nowcoder.com/practice/1a834e5e3e1a4b7ba251417554e07c00?tpId=13\&tqId=11165\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
@ -10,18 +10,14 @@
|
||||
|
||||
## 解题思路
|
||||
|
||||
<!-- <div align="center"><img src="https://latex.codecogs.com/gif.latex?x^n=\left\{\begin{array}{rcl}x^{n/2}*x^{n/2}&&{n\%2=0}\\x*(x^{n/2}*x^{n/2})&&{n\%2=1}\end{array}\right." class="mathjax-pic"/></div> <br> -->
|
||||
|
||||
最直观的解法是将 x 重复乘 n 次,x\*x\*x...\*x,那么时间复杂度为 O(N)。因为乘法是可交换的,所以可以将上述操作拆开成两半 (x\*x..\*x)\* (x\*x..\*x),两半的计算是一样的,因此只需要计算一次。而且对于新拆开的计算,又可以继续拆开。这就是分治思想,将原问题的规模拆成多个规模较小的子问题,最后子问题的解合并起来。
|
||||
|
||||
本题中子问题是 x<sup>n/2</sup>,在将子问题合并时将子问题的解乘于自身相乘即可。但如果 n 不为偶数,那么拆成两半还会剩下一个 x,在将子问题合并时还需要需要多乘于一个 x。
|
||||
本题中子问题是 xn/2,在将子问题合并时将子问题的解乘于自身相乘即可。但如果 n 不为偶数,那么拆成两半还会剩下一个 x,在将子问题合并时还需要需要多乘于一个 x。
|
||||
|
||||
\
|
||||
|
||||
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20201105012506187.png" width="400px"> </div><br>
|
||||
|
||||
|
||||
因为 (x\*x)<sup>n/2</sup> 可以通过递归求解,并且每次递归 n 都减小一半,因此整个算法的时间复杂度为 O(logN)。
|
||||
因为 (x\*x)n/2 可以通过递归求解,并且每次递归 n 都减小一半,因此整个算法的时间复杂度为 O(logN)。
|
||||
|
||||
```java
|
||||
public double Power(double x, int n) {
|
||||
@ -43,4 +39,3 @@ private double pow(double x, int n) {
|
||||
return res;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
@ -4,11 +4,13 @@
|
||||
|
||||
① 如果该节点不是尾节点,那么可以直接将下一个节点的值赋给该节点,然后令该节点指向下下个节点,再删除下一个节点,时间复杂度为 O(1)。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/1176f9e1-3442-4808-a47a-76fbaea1b806.png" width="600"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
② 否则,就需要先遍历链表,找到节点的前一个节点,然后让前一个节点指向 null,时间复杂度为 O(N)。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/4bf8d0ba-36f0-459e-83a0-f15278a5a157.png" width="600"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
综上,如果进行 N 次操作,那么大约需要操作节点的次数为 N-1+N=2N-1,其中 N-1 表示 N-1 个不是尾节点的每个节点以 O(1) 的时间复杂度操作节点的总次数,N 表示 1 个尾节点以 O(N) 的时间复杂度操作节点的总次数。(2N-1)/N \~ 2,因此该算法的平均时间复杂度为 O(1)。
|
||||
|
||||
|
||||
@ -1,10 +1,11 @@
|
||||
# 18.2 删除链表中重复的结点
|
||||
|
||||
[牛客网](https://www.nowcoder.com/practice/fc533c45b73a41b0b44ccba763f866ef?tpId=13&tqId=11209&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[牛客网](https://www.nowcoder.com/practice/fc533c45b73a41b0b44ccba763f866ef?tpId=13\&tqId=11209\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/17e301df-52e8-4886-b593-841a16d13e44.png" width="450"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 解题描述
|
||||
|
||||
|
||||
@ -2,13 +2,14 @@
|
||||
|
||||
## 题目链接
|
||||
|
||||
[牛客网](https://www.nowcoder.com/practice/ef1f53ef31ca408cada5093c8780f44b?tpId=13&tqId=11166&tab=answerKey&from=cyc_github)
|
||||
[牛客网](https://www.nowcoder.com/practice/ef1f53ef31ca408cada5093c8780f44b?tpId=13\&tqId=11166\&tab=answerKey\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
需要保证奇数和奇数,偶数和偶数之间的相对位置不变,这和书本不太一样。例如对于 [1,2,3,4,5],调整后得到 [1,3,5,2,4],而不能是 {5,1,3,4,2} 这种相对位置改变的结果。
|
||||
需要保证奇数和奇数,偶数和偶数之间的相对位置不变,这和书本不太一样。例如对于 \[1,2,3,4,5],调整后得到 \[1,3,5,2,4],而不能是 {5,1,3,4,2} 这种相对位置改变的结果。
|
||||
|
||||
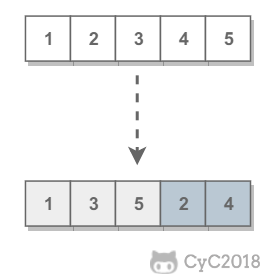\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/d03a2efa-ef19-4c96-97e8-ff61df8061d3.png" width="200px"> </div><br>
|
||||
|
||||
## 解题思路
|
||||
|
||||
@ -37,7 +38,7 @@ private boolean isEven(int x) {
|
||||
}
|
||||
```
|
||||
|
||||
方法二:使用冒泡思想,每次都将当前偶数上浮到当前最右边。时间复杂度 O(N<sup>2</sup>),空间复杂度 O(1),时间换空间。
|
||||
方法二:使用冒泡思想,每次都将当前偶数上浮到当前最右边。时间复杂度 O(N2),空间复杂度 O(1),时间换空间。
|
||||
|
||||
```java
|
||||
public int[] reOrderArray(int[] nums) {
|
||||
|
||||
@ -1,12 +1,13 @@
|
||||
# 22. 链表中倒数第 K 个结点
|
||||
|
||||
[牛客网](https://www.nowcoder.com/practice/886370fe658f41b498d40fb34ae76ff9?tpId=13&tqId=11167&tab=answerKey&from=cyc_github)
|
||||
[牛客网](https://www.nowcoder.com/practice/886370fe658f41b498d40fb34ae76ff9?tpId=13\&tqId=11167\&tab=answerKey\&from=cyc\_github)
|
||||
|
||||
## 解题思路
|
||||
|
||||
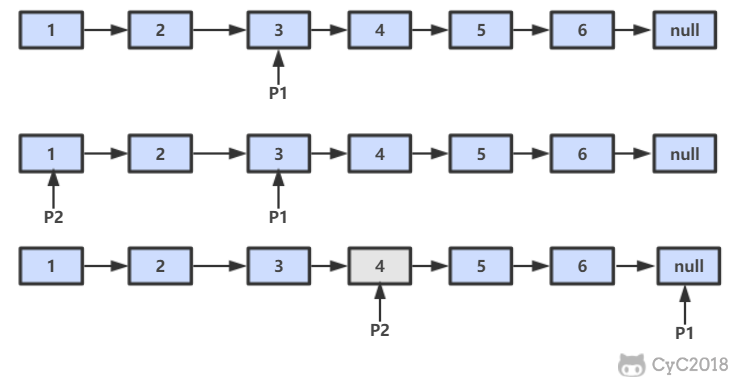
设链表的长度为 N。设置两个指针 P1 和 P2,先让 P1 移动 K 个节点,则还有 N - K 个节点可以移动。此时让 P1 和 P2 同时移动,可以知道当 P1 移动到链表结尾时,P2 移动到第 N - K 个节点处,该位置就是倒数第 K 个节点。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/6b504f1f-bf76-4aab-a146-a9c7a58c2029.png" width="500"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```java
|
||||
public ListNode FindKthToTail(ListNode head, int k) {
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# 23. 链表中环的入口结点
|
||||
|
||||
[NowCoder](https://www.nowcoder.com/practice/253d2c59ec3e4bc68da16833f79a38e4?tpId=13&tqId=11208&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[NowCoder](https://www.nowcoder.com/practice/253d2c59ec3e4bc68da16833f79a38e4?tpId=13\&tqId=11208\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
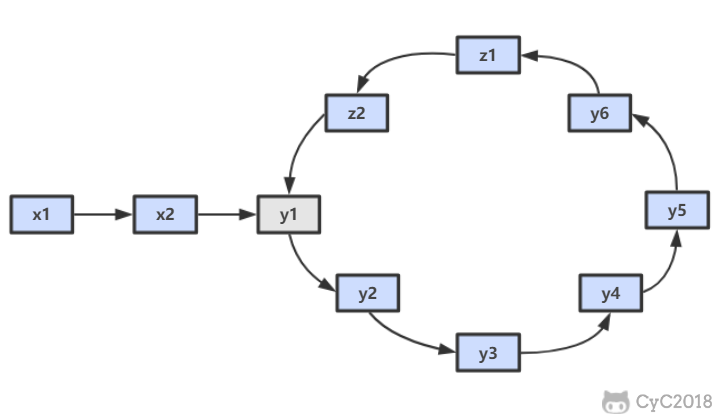
@ -12,7 +12,7 @@
|
||||
|
||||
假设环入口节点为 y1,相遇所在节点为 z1。
|
||||
|
||||
假设快指针 fast 在圈内绕了 N 圈,则总路径长度为 x+Ny+(N-1)z。z 为 (N-1) 倍是因为快慢指针最后已经在 z1 节点相遇了,后面就不需要再走了。
|
||||
假设快指针 fast 在圈内绕了 N 圈,则总路径长度为 x+Ny+(N-1)z。z 为 (N-1) 倍是因为快慢指针最后已经在 z1 节点相遇了,后面就不需要再走了。
|
||||
|
||||
而慢指针 slow 总路径长度为 x+y。
|
||||
|
||||
@ -22,7 +22,8 @@
|
||||
|
||||
上面的等值没有很强的规律,但是我们可以发现 y+z 就是圆环的总长度,因此我们将上面的等式再分解:x=(N-2)(y+z)+z。这个等式左边是从起点x1 到环入口节点 y1 的长度,而右边是在圆环中走过 (N-2) 圈,再从相遇点 z1 再走过长度为 z 的长度。此时我们可以发现如果让两个指针同时从起点 x1 和相遇点 z1 开始,每次只走过一个距离,那么最后他们会在环入口节点相遇。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/bb7fc182-98c2-4860-8ea3-630e27a5f29f.png" width="500"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```java
|
||||
public ListNode EntryNodeOfLoop(ListNode pHead) {
|
||||
|
||||
@ -1,10 +1,11 @@
|
||||
# 25. 合并两个排序的链表
|
||||
|
||||
[NowCoder](https://www.nowcoder.com/practice/d8b6b4358f774294a89de2a6ac4d9337?tpId=13&tqId=11169&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[NowCoder](https://www.nowcoder.com/practice/d8b6b4358f774294a89de2a6ac4d9337?tpId=13\&tqId=11169\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/c094d2bc-ec75-444b-af77-d369dfb6b3b4.png" width="400"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
|
||||
@ -2,11 +2,12 @@
|
||||
|
||||
## 题目链接
|
||||
|
||||
[牛客网](https://www.nowcoder.com/practice/6e196c44c7004d15b1610b9afca8bd88?tpId=13&tqId=11170&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[牛客网](https://www.nowcoder.com/practice/6e196c44c7004d15b1610b9afca8bd88?tpId=13\&tqId=11170\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/84a5b15a-86c5-4d8e-9439-d9fd5a4699a1.jpg" width="450"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
|
||||
@ -1,10 +1,11 @@
|
||||
# 27. 二叉树的镜像
|
||||
|
||||
[牛客网](https://www.nowcoder.com/practice/a9d0ecbacef9410ca97463e4a5c83be7?tpId=13&tqId=11171&tab=answerKey&from=cyc_github)
|
||||
[牛客网](https://www.nowcoder.com/practice/a9d0ecbacef9410ca97463e4a5c83be7?tpId=13\&tqId=11171\&tab=answerKey\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/0c12221f-729e-4c22-b0ba-0dfc909f8adf.jpg" width="300"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
|
||||
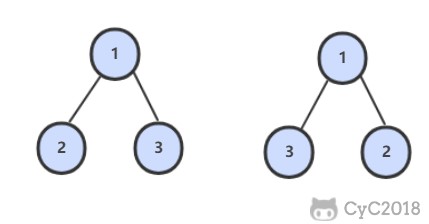
@ -1,10 +1,11 @@
|
||||
# 28. 对称的二叉树
|
||||
|
||||
[NowCoder](https://www.nowcoder.com/practice/ff05d44dfdb04e1d83bdbdab320efbcb?tpId=13&tqId=11211&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[NowCoder](https://www.nowcoder.com/practice/ff05d44dfdb04e1d83bdbdab320efbcb?tpId=13\&tqId=11211\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/0c12221f-729e-4c22-b0ba-0dfc909f8adf.jpg" width="300"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
|
||||
@ -2,21 +2,21 @@
|
||||
|
||||
## 题目链接
|
||||
|
||||
[牛客网](https://www.nowcoder.com/practice/9b4c81a02cd34f76be2659fa0d54342a?tpId=13&tqId=11172&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[牛客网](https://www.nowcoder.com/practice/9b4c81a02cd34f76be2659fa0d54342a?tpId=13\&tqId=11172\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
按顺时针的方向,从外到里打印矩阵的值。下图的矩阵打印结果为:1, 2, 3, 4, 8, 12, 16, 15, 14, 13, 9, 5, 6, 7, 11, 10
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20201104010349296.png" width="300px"> </div><br>
|
||||
|
||||
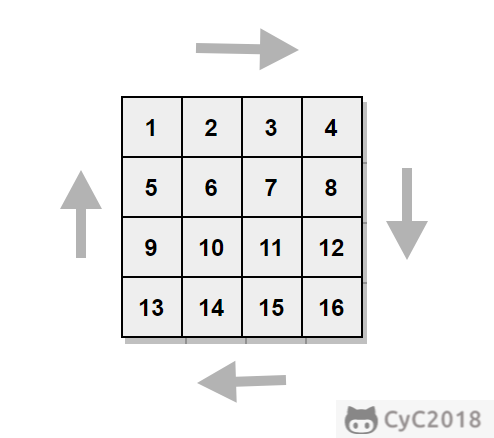\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
一层一层从外到里打印,观察可知每一层打印都有相同的处理步骤,唯一不同的是上下左右的边界不同了。因此使用四个变量 r1, r2, c1, c2 分别存储上下左右边界值,从而定义当前最外层。打印当前最外层的顺序:从左到右打印最上一行-\>从上到下打印最右一行-\>从右到左打印最下一行-\>从下到上打印最左一行。应当注意只有在 r1 != r2 时才打印最下一行,也就是在当前最外层的行数大于 1 时才打印最下一行,这是因为当前最外层只有一行时,继续打印最下一行,会导致重复打印。打印最左一行也要做同样处理。
|
||||
一层一层从外到里打印,观察可知每一层打印都有相同的处理步骤,唯一不同的是上下左右的边界不同了。因此使用四个变量 r1, r2, c1, c2 分别存储上下左右边界值,从而定义当前最外层。打印当前最外层的顺序:从左到右打印最上一行->从上到下打印最右一行->从右到左打印最下一行->从下到上打印最左一行。应当注意只有在 r1 != r2 时才打印最下一行,也就是在当前最外层的行数大于 1 时才打印最下一行,这是因为当前最外层只有一行时,继续打印最下一行,会导致重复打印。打印最左一行也要做同样处理。
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20201104010609223.png" width="500px"> </div><br>
|
||||
|
||||
```java
|
||||
public ArrayList<Integer> printMatrix(int[][] matrix) {
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
|
||||
## 题目链接
|
||||
|
||||
[牛客网](https://www.nowcoder.com/practice/6fe361ede7e54db1b84adc81d09d8524?tpId=13&tqId=11203&tab=answerKey&from=cyc_github)
|
||||
[牛客网](https://www.nowcoder.com/practice/6fe361ede7e54db1b84adc81d09d8524?tpId=13\&tqId=11203\&tab=answerKey\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
@ -20,11 +20,11 @@ Output:
|
||||
|
||||
要求时间复杂度 O(N),空间复杂度 O(1)。因此不能使用排序的方法,也不能使用额外的标记数组。
|
||||
|
||||
对于这种数组元素在 [0, n-1] 范围内的问题,可以将值为 i 的元素调整到第 i 个位置上进行求解。在调整过程中,如果第 i 位置上已经有一个值为 i 的元素,就可以知道 i 值重复。
|
||||
对于这种数组元素在 \[0, n-1] 范围内的问题,可以将值为 i 的元素调整到第 i 个位置上进行求解。在调整过程中,如果第 i 位置上已经有一个值为 i 的元素,就可以知道 i 值重复。
|
||||
|
||||
以 (2, 3, 1, 0, 2, 5) 为例,遍历到位置 4 时,该位置上的数为 2,但是第 2 个位置上已经有一个 2 的值了,因此可以知道 2 重复:
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/643b6f18-f933-4ac5-aa7a-e304dbd7fe49.gif" width="350px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```java
|
||||
@ -46,6 +46,4 @@ private void swap(int[] nums, int i, int j) {
|
||||
nums[i] = nums[j];
|
||||
nums[j] = t;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
|
||||
## 题目链接
|
||||
|
||||
[牛客网](https://www.nowcoder.com/practice/4c776177d2c04c2494f2555c9fcc1e49?tpId=13&tqId=11173&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[牛客网](https://www.nowcoder.com/practice/4c776177d2c04c2494f2555c9fcc1e49?tpId=13\&tqId=11173\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
@ -12,7 +12,8 @@
|
||||
|
||||
使用一个额外的 minStack,栈顶元素为当前栈中最小的值。在对栈进行 push 入栈和 pop 出栈操作时,同样需要对 minStack 进行入栈出栈操作,从而使 minStack 栈顶元素一直为当前栈中最小的值。在进行 push 操作时,需要比较入栈元素和当前栈中最小值,将值较小的元素 push 到 minStack 中。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20201104013936126.png" width="350px"> </div><br>
|
||||
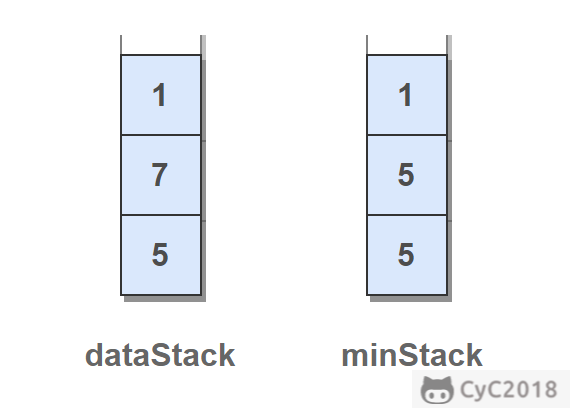\
|
||||
|
||||
|
||||
```java
|
||||
private Stack<Integer> dataStack = new Stack<>();
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# 32.1 从上往下打印二叉树
|
||||
|
||||
[NowCoder](https://www.nowcoder.com/practice/7fe2212963db4790b57431d9ed259701?tpId=13&tqId=11175&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[NowCoder](https://www.nowcoder.com/practice/7fe2212963db4790b57431d9ed259701?tpId=13\&tqId=11175\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
@ -8,7 +8,8 @@
|
||||
|
||||
例如,以下二叉树层次遍历的结果为:1,2,3,4,5,6,7
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/d5e838cf-d8a2-49af-90df-1b2a714ee676.jpg" width="250"/> </div><br>
|
||||
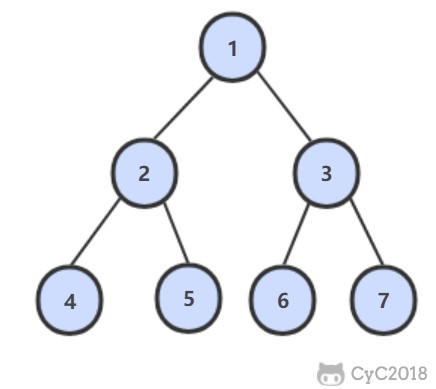\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# 33. 二叉搜索树的后序遍历序列
|
||||
|
||||
[NowCoder](https://www.nowcoder.com/practice/a861533d45854474ac791d90e447bafd?tpId=13&tqId=11176&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[NowCoder](https://www.nowcoder.com/practice/a861533d45854474ac791d90e447bafd?tpId=13\&tqId=11176\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
@ -8,7 +8,8 @@
|
||||
|
||||
例如,下图是后序遍历序列 1,3,2 所对应的二叉搜索树。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/13454fa1-23a8-4578-9663-2b13a6af564a.jpg" width="150"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# 34. 二叉树中和为某一值的路径
|
||||
|
||||
[NowCoder](https://www.nowcoder.com/practice/b736e784e3e34731af99065031301bca?tpId=13&tqId=11177&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[NowCoder](https://www.nowcoder.com/practice/b736e784e3e34731af99065031301bca?tpId=13\&tqId=11177\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
@ -8,7 +8,8 @@
|
||||
|
||||
下图的二叉树有两条和为 22 的路径:10, 5, 7 和 10, 12
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/ed77b0e6-38d9-4a34-844f-724f3ffa2c12.jpg" width="200"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# 35. 复杂链表的复制
|
||||
|
||||
[NowCoder](https://www.nowcoder.com/practice/f836b2c43afc4b35ad6adc41ec941dba?tpId=13&tqId=11178&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[NowCoder](https://www.nowcoder.com/practice/f836b2c43afc4b35ad6adc41ec941dba?tpId=13\&tqId=11178\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
@ -18,21 +18,25 @@ public class RandomListNode {
|
||||
}
|
||||
```
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/66a01953-5303-43b1-8646-0c77b825e980.png" width="300"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
第一步,在每个节点的后面插入复制的节点。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/dfd5d3f8-673c-486b-8ecf-d2082107b67b.png" width="600"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
第二步,对复制节点的 random 链接进行赋值。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/cafbfeb8-7dfe-4c0a-a3c9-750eeb824068.png" width="600"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
第三步,拆分。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/e151b5df-5390-4365-b66e-b130cd253c12.png" width="600"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```java
|
||||
public RandomListNode Clone(RandomListNode pHead) {
|
||||
|
||||
@ -1,12 +1,13 @@
|
||||
# 36. 二叉搜索树与双向链表
|
||||
|
||||
[NowCoder](https://www.nowcoder.com/practice/947f6eb80d944a84850b0538bf0ec3a5?tpId=13&tqId=11179&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[NowCoder](https://www.nowcoder.com/practice/947f6eb80d944a84850b0538bf0ec3a5?tpId=13\&tqId=11179\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的双向链表。要求不能创建任何新的结点,只能调整树中结点指针的指向。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/05a08f2e-9914-4a77-92ef-aebeaecf4f66.jpg" width="400"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
|
||||
## 题目链接
|
||||
|
||||
[牛客网](https://www.nowcoder.com/practice/abc3fe2ce8e146608e868a70efebf62e?tpId=13&tqId=11154&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[牛客网](https://www.nowcoder.com/practice/abc3fe2ce8e146608e868a70efebf62e?tpId=13\&tqId=11154\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
@ -28,7 +28,8 @@ Given target = 20, return false.
|
||||
|
||||
该二维数组中的一个数,小于它的数一定在其左边,大于它的数一定在其下边。因此,从右上角开始查找,就可以根据 target 和当前元素的大小关系来快速地缩小查找区间,每次减少一行或者一列的元素。当前元素的查找区间为左下角的所有元素。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/35a8c711-0dc0-4613-95f3-be96c6c6e104.gif" width="400px"> </div><br>
|
||||
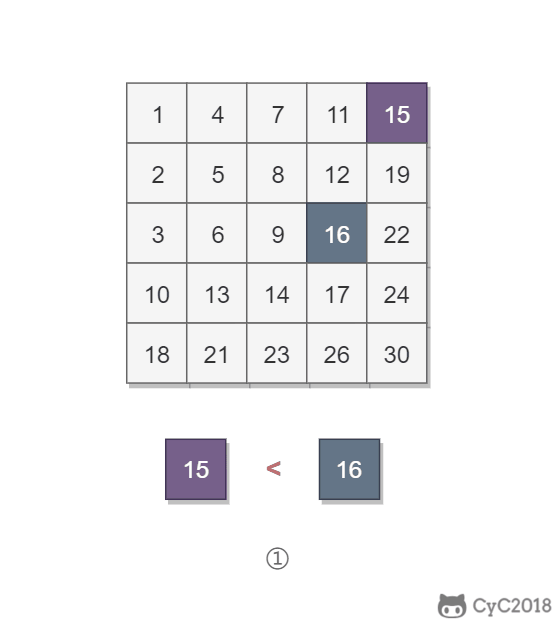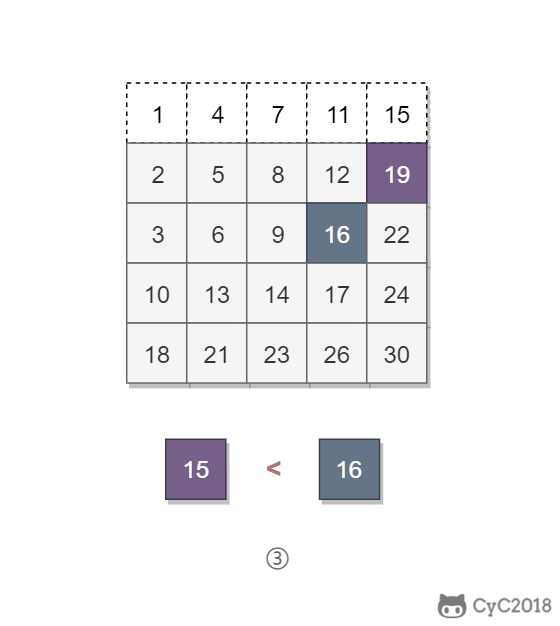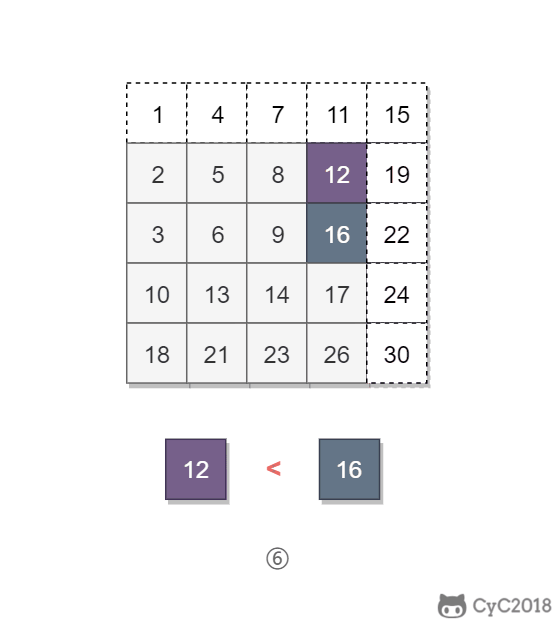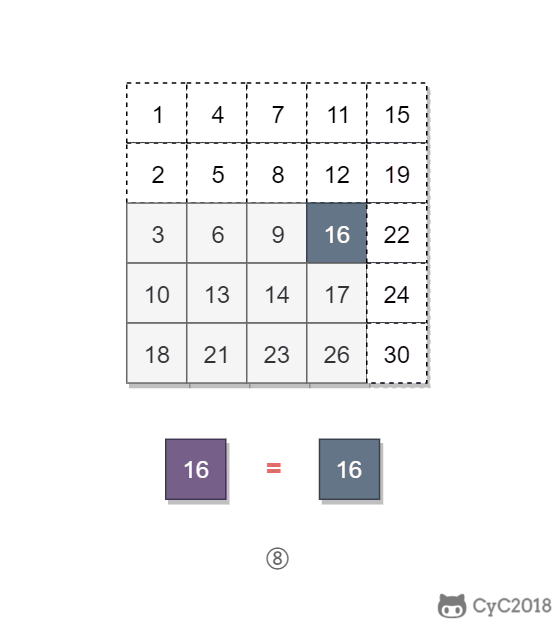\
|
||||
|
||||
|
||||
```java
|
||||
public boolean Find(int target, int[][] matrix) {
|
||||
|
||||
@ -2,14 +2,13 @@
|
||||
|
||||
## 题目链接
|
||||
|
||||
[牛客网](https://www.nowcoder.com/practice/0e26e5551f2b489b9f58bc83aa4b6c68?tpId=13&tqId=11155&tab=answerKey&from=cyc_github)
|
||||
[牛客网](https://www.nowcoder.com/practice/0e26e5551f2b489b9f58bc83aa4b6c68?tpId=13\&tqId=11155\&tab=answerKey\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
|
||||
将一个字符串中的空格替换成 "%20"。
|
||||
|
||||
```text
|
||||
```
|
||||
Input:
|
||||
"A B"
|
||||
|
||||
@ -23,12 +22,11 @@ Output:
|
||||
|
||||
② 令 P1 指向字符串原来的末尾位置,P2 指向字符串现在的末尾位置。P1 和 P2 从后向前遍历,当 P1 遍历到一个空格时,就需要令 P2 指向的位置依次填充 02%(注意是逆序的),否则就填充上 P1 指向字符的值。从后向前遍是为了在改变 P2 所指向的内容时,不会影响到 P1 遍历原来字符串的内容。
|
||||
|
||||
③ 当 P2 遇到 P1 时(P2 \<= P1),或者遍历结束(P1 \< 0),退出。
|
||||
③ 当 P2 遇到 P1 时(P2 <= P1),或者遍历结束(P1 < 0),退出。
|
||||
|
||||
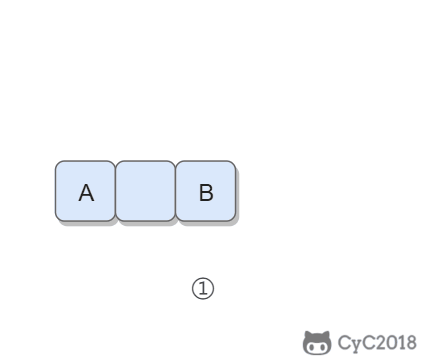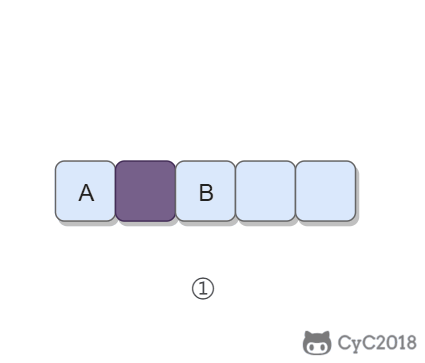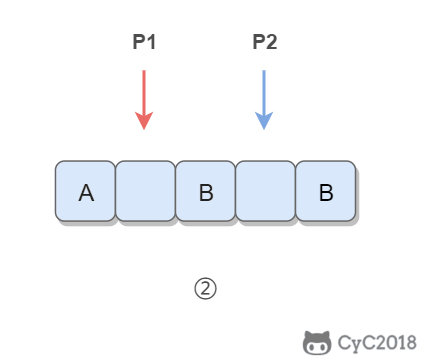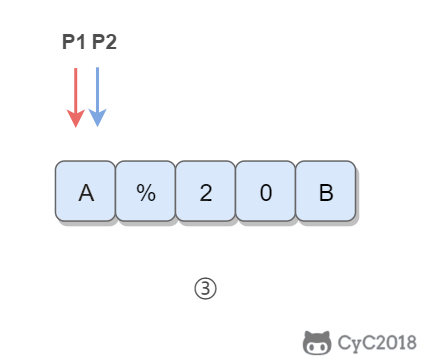\
|
||||
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/f7c1fea2-c1e7-4d31-94b5-0d9df85e093c.gif" width="350px"> </div><br>
|
||||
|
||||
```java
|
||||
public String replaceSpace(StringBuffer str) {
|
||||
int P1 = str.length() - 1;
|
||||
|
||||
@ -1,10 +1,11 @@
|
||||
# 52. 两个链表的第一个公共结点
|
||||
|
||||
[NowCoder](https://www.nowcoder.com/practice/6ab1d9a29e88450685099d45c9e31e46?tpId=13&tqId=11189&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[NowCoder](https://www.nowcoder.com/practice/6ab1d9a29e88450685099d45c9e31e46?tpId=13\&tqId=11189\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/5f1cb999-cb9a-4f6c-a0af-d90377295ab8.png" width="500"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
|
||||
@ -1,12 +1,13 @@
|
||||
# 55.1 二叉树的深度
|
||||
|
||||
[NowCoder](https://www.nowcoder.com/practice/435fb86331474282a3499955f0a41e8b?tpId=13&tqId=11191&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[NowCoder](https://www.nowcoder.com/practice/435fb86331474282a3499955f0a41e8b?tpId=13\&tqId=11191\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
从根结点到叶结点依次经过的结点(含根、叶结点)形成树的一条路径,最长路径的长度为树的深度。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/ba355101-4a93-4c71-94fb-1da83639727b.jpg" width="350px"/> </div><br>
|
||||
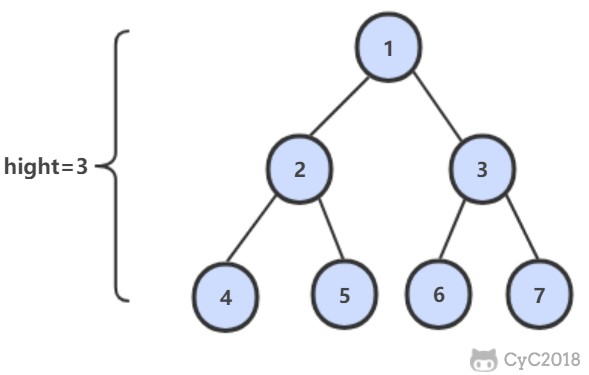\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
|
||||
@ -1,12 +1,13 @@
|
||||
# 55.2 平衡二叉树
|
||||
|
||||
[NowCoder](https://www.nowcoder.com/practice/8b3b95850edb4115918ecebdf1b4d222?tpId=13&tqId=11192&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[NowCoder](https://www.nowcoder.com/practice/8b3b95850edb4115918ecebdf1b4d222?tpId=13\&tqId=11192\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
平衡二叉树左右子树高度差不超过 1。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/af1d1166-63af-47b6-9aa3-2bf2bd37bd03.jpg" width="250px"/> </div><br>
|
||||
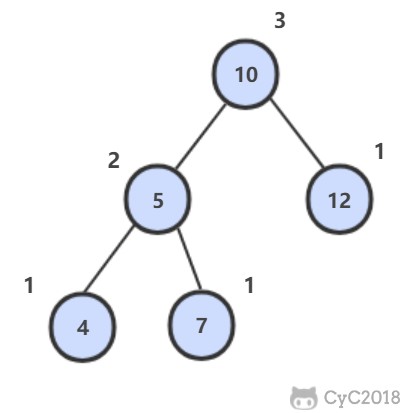\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
|
||||
## 题目链接
|
||||
|
||||
[牛客网](https://www.nowcoder.com/practice/1624bc35a45c42c0bc17d17fa0cba788?tpId=13&tqId=11217&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[牛客网](https://www.nowcoder.com/practice/1624bc35a45c42c0bc17d17fa0cba788?tpId=13\&tqId=11217\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
@ -10,13 +10,14 @@
|
||||
|
||||
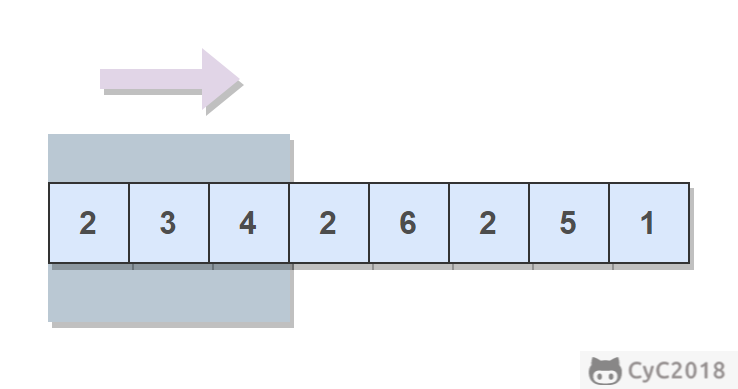
例如,如果输入数组 {2, 3, 4, 2, 6, 2, 5, 1} 及滑动窗口的大小 3,那么一共存在 6 个滑动窗口,他们的最大值分别为 {4, 4, 6, 6, 6, 5}。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20201104020702453.png" width="500px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
维护一个大小为窗口大小的大顶堆,顶堆元素则为当前窗口的最大值。
|
||||
|
||||
假设窗口的大小为 M,数组的长度为 N。在窗口向右移动时,需要先在堆中删除离开窗口的元素,并将新到达的元素添加到堆中,这两个操作的时间复杂度都为 log<sub>2</sub>M,因此算法的时间复杂度为 O(Nlog<sub>2</sub>M),空间复杂度为 O(M)。
|
||||
假设窗口的大小为 M,数组的长度为 N。在窗口向右移动时,需要先在堆中删除离开窗口的元素,并将新到达的元素添加到堆中,这两个操作的时间复杂度都为 log2M,因此算法的时间复杂度为 O(Nlog2M),空间复杂度为 O(M)。
|
||||
|
||||
```java
|
||||
public ArrayList<Integer> maxInWindows(int[] num, int size) {
|
||||
|
||||
@ -2,19 +2,20 @@
|
||||
|
||||
## 题目链接
|
||||
|
||||
[牛客网](https://www.nowcoder.com/practice/d0267f7f55b3412ba93bd35cfa8e8035?tpId=13&tqId=11156&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[牛客网](https://www.nowcoder.com/practice/d0267f7f55b3412ba93bd35cfa8e8035?tpId=13\&tqId=11156\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
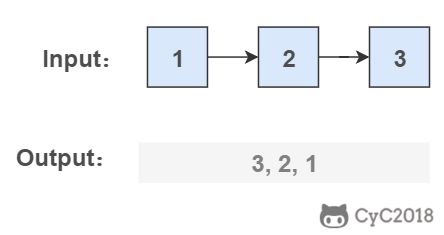
从尾到头反过来打印出每个结点的值。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/f5792051-d9b2-4ca4-a234-a4a2de3d5a57.png" width="300px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
### 1. 使用递归
|
||||
|
||||
要逆序打印链表 1-\>2-\>3(3,2,1),可以先逆序打印链表 2-\>3(3,2),最后再打印第一个节点 1。而链表 2-\>3 可以看成一个新的链表,要逆序打印该链表可以继续使用求解函数,也就是在求解函数中调用自己,这就是递归函数。
|
||||
要逆序打印链表 1->2->3(3,2,1),可以先逆序打印链表 2->3(3,2),最后再打印第一个节点 1。而链表 2->3 可以看成一个新的链表,要逆序打印该链表可以继续使用求解函数,也就是在求解函数中调用自己,这就是递归函数。
|
||||
|
||||
```java
|
||||
public ArrayList<Integer> printListFromTailToHead(ListNode listNode) {
|
||||
@ -39,13 +40,13 @@ node2.next = node3;
|
||||
node1.next = node2;
|
||||
```
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/58c8e370-3bec-4c2b-bf17-c8d34345dd17.gif" width="220px"> </div><br>
|
||||
|
||||
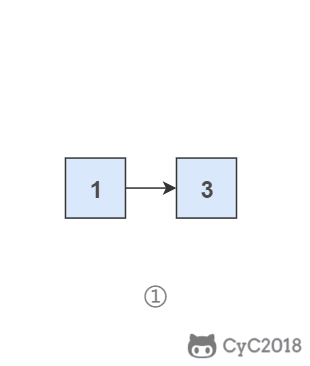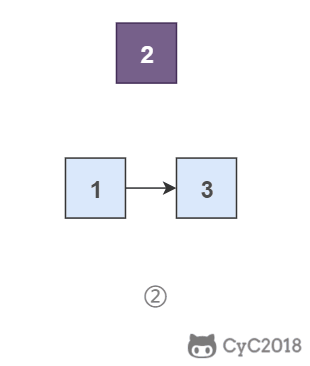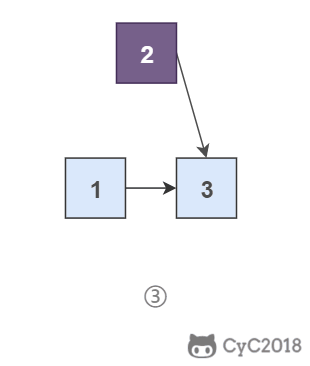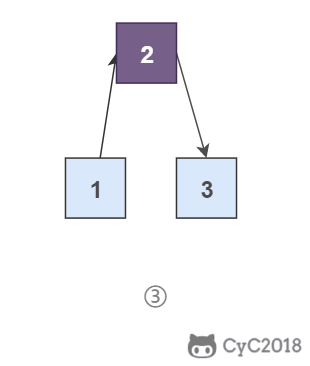\
|
||||
|
||||
|
||||
为了能将一个节点插入头部,我们引入了一个叫头结点的辅助节点,该节点不存储值,只是为了方便进行插入操作。不要将头结点与第一个节点混起来,第一个节点是链表中第一个真正存储值的节点。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/0dae7e93-cfd1-4bd3-97e8-325b032b716f-1572687622947.gif" width="420px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```java
|
||||
public ArrayList<Integer> printListFromTailToHead(ListNode listNode) {
|
||||
@ -72,7 +73,8 @@ public ArrayList<Integer> printListFromTailToHead(ListNode listNode) {
|
||||
|
||||
栈具有后进先出的特点,在遍历链表时将值按顺序放入栈中,最后出栈的顺序即为逆序。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/9d1deeba-4ae1-41dc-98f4-47d85b9831bc.gif" width="340px"> </div><br>
|
||||
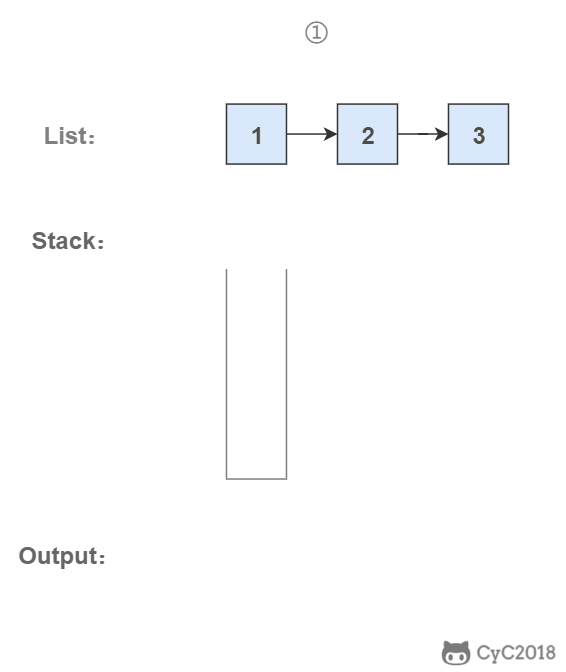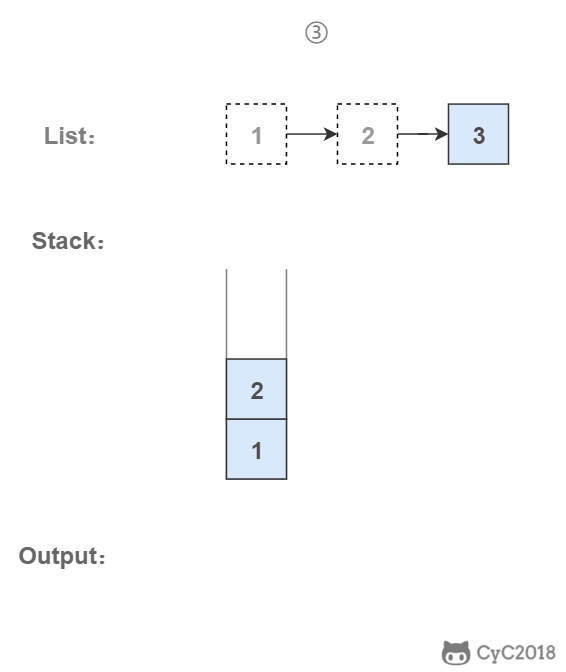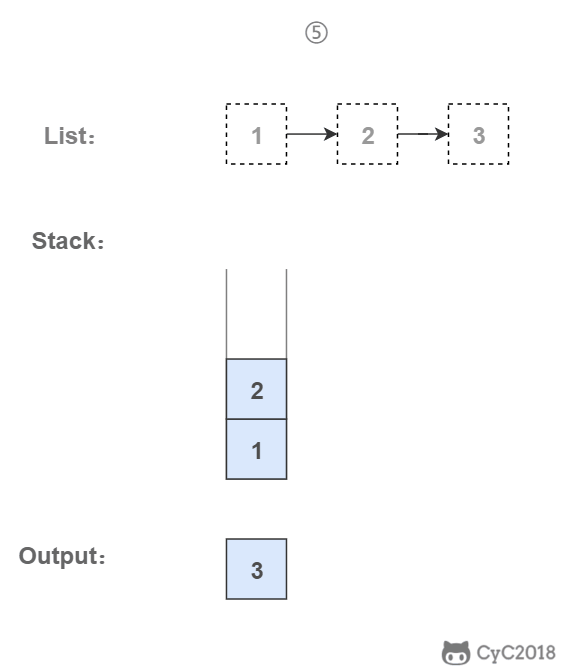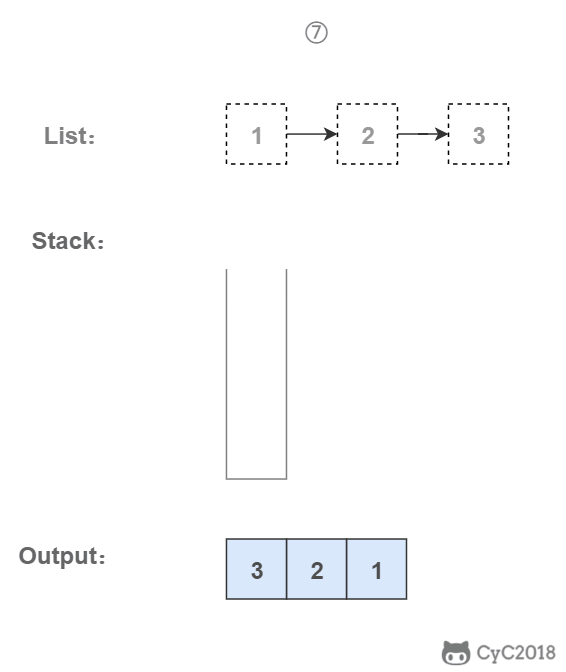\
|
||||
|
||||
|
||||
```java
|
||||
public ArrayList<Integer> printListFromTailToHead(ListNode listNode) {
|
||||
|
||||
@ -8,7 +8,8 @@
|
||||
|
||||
把 n 个骰子扔在地上,求点数和为 s 的概率。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/195f8693-5ec4-4987-8560-f25e365879dd.png" width="300px"> </div><br>
|
||||
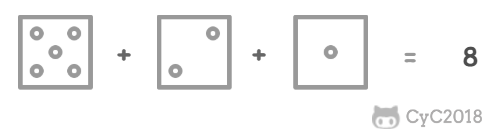\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
@ -16,7 +17,7 @@
|
||||
|
||||
使用一个二维数组 dp 存储点数出现的次数,其中 dp\[i]\[j] 表示前 i 个骰子产生点数 j 的次数。
|
||||
|
||||
空间复杂度:O(N<sup>2</sup>)
|
||||
空间复杂度:O(N2)
|
||||
|
||||
```java
|
||||
public List<Map.Entry<Integer, Double>> dicesSum(int n) {
|
||||
|
||||
@ -2,13 +2,13 @@
|
||||
|
||||
## 题目链接
|
||||
|
||||
[NowCoder](https://www.nowcoder.com/practice/762836f4d43d43ca9deb273b3de8e1f4?tpId=13&tqId=11198&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[NowCoder](https://www.nowcoder.com/practice/762836f4d43d43ca9deb273b3de8e1f4?tpId=13\&tqId=11198\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
五张牌,其中大小鬼为癞子,牌面为 0。判断这五张牌是否能组成顺子。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/eaa506b6-0747-4bee-81f8-3cda795d8154.png" width="350px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
@ -2,13 +2,14 @@
|
||||
|
||||
## 题目链接
|
||||
|
||||
[Leetcode:121. Best Time to Buy and Sell Stock ](https://leetcode.com/problems/best-time-to-buy-and-sell-stock/description/)
|
||||
[Leetcode:121. Best Time to Buy and Sell Stock](https://leetcode.com/problems/best-time-to-buy-and-sell-stock/description/)
|
||||
|
||||
## 题目描述
|
||||
|
||||
可以有一次买入和一次卖出,买入必须在前。求最大收益。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/42661013-750f-420b-b3c1-437e9a11fb65.png" width="220px"> </div><br>
|
||||
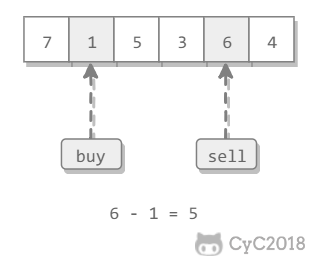\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
|
||||
@ -2,13 +2,13 @@
|
||||
|
||||
## 题目链接
|
||||
|
||||
[NowCoder](https://www.nowcoder.com/practice/94a4d381a68b47b7a8bed86f2975db46?tpId=13&tqId=11204&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[NowCoder](https://www.nowcoder.com/practice/94a4d381a68b47b7a8bed86f2975db46?tpId=13\&tqId=11204\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
给定一个数组 A[0, 1,..., n-1],请构建一个数组 B[0, 1,..., n-1],其中 B 中的元素 B[i]=A[0]\*A[1]\*...\*A[i-1]\*A[i+1]\*...\*A[n-1]。要求不能使用除法。
|
||||
给定一个数组 A\[0, 1,..., n-1],请构建一个数组 B\[0, 1,..., n-1],其中 B 中的元素 B\[i]=A\[0]\*A\[1]\*...\*A\[i-1]\*A\[i+1]\*...\*A\[n-1]。要求不能使用除法。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/4240a69f-4d51-4d16-b797-2dfe110f30bd.png" width="250px"> </div><br>
|
||||
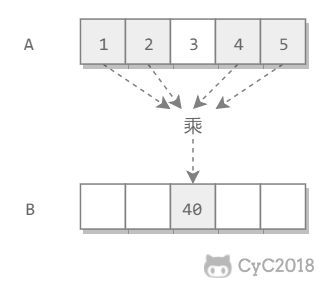\
|
||||
|
||||
|
||||
## 解题思路
|
||||
|
||||
@ -1,6 +1,5 @@
|
||||
# 68. 树中两个节点的最低公共祖先
|
||||
|
||||
|
||||
## 68.1 二叉查找树
|
||||
|
||||
### 题目链接
|
||||
@ -9,9 +8,10 @@
|
||||
|
||||
### 解题思路
|
||||
|
||||
在二叉查找树中,两个节点 p, q 的公共祖先 root 满足 root.val \>= p.val && root.val \<= q.val。
|
||||
在二叉查找树中,两个节点 p, q 的公共祖先 root 满足 root.val >= p.val && root.val <= q.val。
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/047faac4-a368-4565-8331-2b66253080d3.jpg" width="250"/> </div><br>
|
||||
|
||||
```java
|
||||
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
|
||||
@ -35,7 +35,8 @@ public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
|
||||
|
||||
在左右子树中查找是否存在 p 或者 q,如果 p 和 q 分别在两个子树中,那么就说明根节点就是最低公共祖先。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/d27c99f0-7881-4f2d-9675-c75cbdee3acd.jpg" width="250"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```java
|
||||
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
|
||||
|
||||
@ -2,21 +2,21 @@
|
||||
|
||||
## 题目链接
|
||||
|
||||
[牛客网](https://www.nowcoder.com/practice/8a19cbe657394eeaac2f6ea9b0f6fcf6?tpId=13&tqId=11157&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[牛客网](https://www.nowcoder.com/practice/8a19cbe657394eeaac2f6ea9b0f6fcf6?tpId=13\&tqId=11157\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
根据二叉树的前序遍历和中序遍历的结果,重建出该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。
|
||||
|
||||
\
|
||||
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191102210342488.png" width="400"/> </div><br>
|
||||
|
||||
## 解题思路
|
||||
|
||||
前序遍历的第一个值为根节点的值,使用这个值将中序遍历结果分成两部分,左部分为树的左子树中序遍历结果,右部分为树的右子树中序遍历的结果。然后分别对左右子树递归地求解。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/60c4a44c-7829-4242-b3a1-26c3b513aaf0.gif" width="430px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```java
|
||||
// 缓存中序遍历数组每个值对应的索引
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
|
||||
## 题目链接
|
||||
|
||||
[牛客网](https://www.nowcoder.com/practice/9023a0c988684a53960365b889ceaf5e?tpId=13&tqId=11210&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[牛客网](https://www.nowcoder.com/practice/9023a0c988684a53960365b889ceaf5e?tpId=13\&tqId=11210\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
@ -35,17 +35,18 @@ void traverse(TreeNode root) {
|
||||
}
|
||||
```
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/ad5cc8fc-d59b-45ce-8899-63a18320d97e.gif" width="300px"/> </div><br>
|
||||
|
||||
\
|
||||
|
||||
|
||||
① 如果一个节点的右子树不为空,那么该节点的下一个节点是右子树的最左节点;
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/7008dc2b-6f13-4174-a516-28b2d75b0152.gif" width="300px"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
② 否则,向上找第一个左链接指向的树包含该节点的祖先节点。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/094e3ac8-e080-4e94-9f0a-64c25abc695e.gif" width="300px"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```java
|
||||
public TreeLinkNode GetNext(TreeLinkNode pNode) {
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
|
||||
## 题目链接
|
||||
|
||||
[牛客网](https://www.nowcoder.com/practice/54275ddae22f475981afa2244dd448c6?tpId=13&tqId=11158&tPage=1&rp=1&ru=/ta/coding-interviews&qru=/ta/coding-interviews/question-ranking&from=cyc_github)
|
||||
[牛客网](https://www.nowcoder.com/practice/54275ddae22f475981afa2244dd448c6?tpId=13\&tqId=11158\&tPage=1\&rp=1\&ru=/ta/coding-interviews\&qru=/ta/coding-interviews/question-ranking\&from=cyc\_github)
|
||||
|
||||
## 题目描述
|
||||
|
||||
@ -12,7 +12,8 @@
|
||||
|
||||
in 栈用来处理入栈(push)操作,out 栈用来处理出栈(pop)操作。一个元素进入 in 栈之后,出栈的顺序被反转。当元素要出栈时,需要先进入 out 栈,此时元素出栈顺序再一次被反转,因此出栈顺序就和最开始入栈顺序是相同的,先进入的元素先退出,这就是队列的顺序。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/3ea280b5-be7d-471b-ac76-ff020384357c.gif" width="450"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```java
|
||||
Stack<Integer> in = new Stack<Integer>();
|
||||
|
||||
@ -1,14 +1,12 @@
|
||||
# Docker
|
||||
<!-- GFM-TOC -->
|
||||
* [Docker](#docker)
|
||||
* [一、解决的问题](#一解决的问题)
|
||||
* [二、与虚拟机的比较](#二与虚拟机的比较)
|
||||
* [三、优势](#三优势)
|
||||
* [四、使用场景](#四使用场景)
|
||||
* [五、镜像与容器](#五镜像与容器)
|
||||
* [参考资料](#参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [Docker](Docker.md#docker)
|
||||
* [一、解决的问题](Docker.md#一解决的问题)
|
||||
* [二、与虚拟机的比较](Docker.md#二与虚拟机的比较)
|
||||
* [三、优势](Docker.md#三优势)
|
||||
* [四、使用场景](Docker.md#四使用场景)
|
||||
* [五、镜像与容器](Docker.md#五镜像与容器)
|
||||
* [参考资料](Docker.md#参考资料)
|
||||
|
||||
## 一、解决的问题
|
||||
|
||||
@ -16,13 +14,15 @@
|
||||
|
||||
Docker 主要解决环境配置问题,它是一种虚拟化技术,对进程进行隔离,被隔离的进程独立于宿主操作系统和其它隔离的进程。使用 Docker 可以不修改应用程序代码,不需要开发人员学习特定环境下的技术,就能够将现有的应用程序部署在其它机器上。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/011f3ef6-d824-4d43-8b2c-36dab8eaaa72-1.png" width="400px"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 二、与虚拟机的比较
|
||||
|
||||
虚拟机也是一种虚拟化技术,它与 Docker 最大的区别在于它是通过模拟硬件,并在硬件上安装操作系统来实现。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/be608a77-7b7f-4f8e-87cc-f2237270bf69.png" width="500"/> </div><br>
|
||||
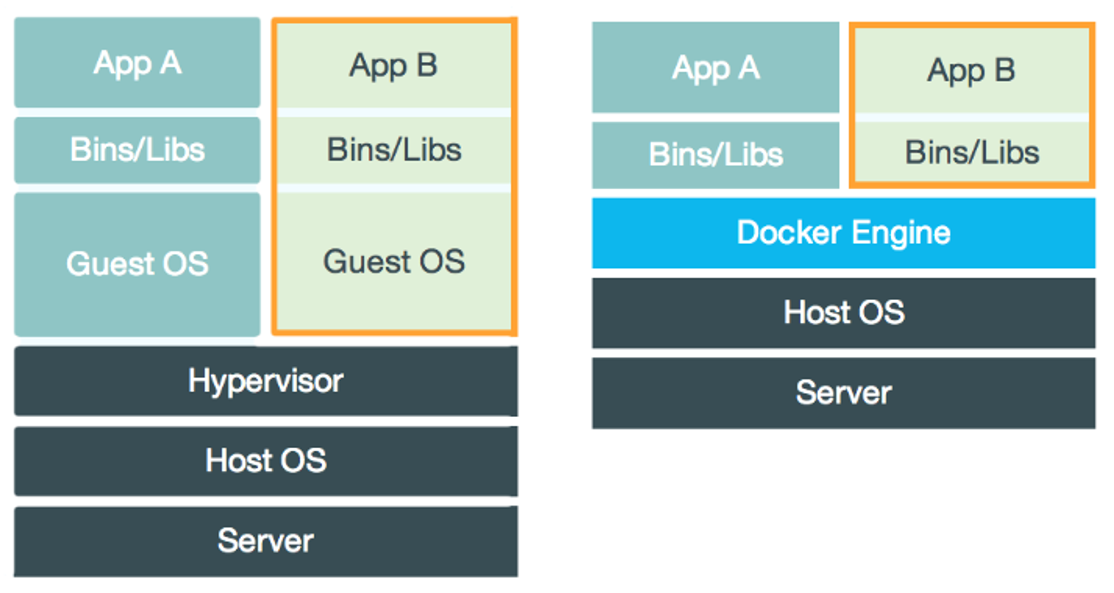\
|
||||
|
||||
|
||||
### 启动速度
|
||||
|
||||
@ -76,16 +76,16 @@ Docker 轻量级的特点使得它很适合用于部署、维护、组合微服
|
||||
|
||||
构建容器时,通过在镜像的基础上添加一个可写层(writable layer),用来保存着容器运行过程中的修改。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/docker-filesystems-busyboxrw.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [DOCKER 101: INTRODUCTION TO DOCKER WEBINAR RECAP](https://blog.docker.com/2017/08/docker-101-introduction-docker-webinar-recap/)
|
||||
- [Docker 入门教程](http://www.ruanyifeng.com/blog/2018/02/docker-tutorial.html)
|
||||
- [Docker container vs Virtual machine](http://www.bogotobogo.com/DevOps/Docker/Docker_Container_vs_Virtual_Machine.php)
|
||||
- [How to Create Docker Container using Dockerfile](https://linoxide.com/linux-how-to/dockerfile-create-docker-container/)
|
||||
- [理解 Docker(2):Docker 镜像](http://www.cnblogs.com/sammyliu/p/5877964.html)
|
||||
- [为什么要使用 Docker?](https://yeasy.gitbooks.io/docker_practice/introduction/why.html)
|
||||
- [What is Docker](https://www.docker.com/what-docker)
|
||||
- [持续集成是什么?](http://www.ruanyifeng.com/blog/2015/09/continuous-integration.html)
|
||||
|
||||
* [DOCKER 101: INTRODUCTION TO DOCKER WEBINAR RECAP](https://blog.docker.com/2017/08/docker-101-introduction-docker-webinar-recap/)
|
||||
* [Docker 入门教程](http://www.ruanyifeng.com/blog/2018/02/docker-tutorial.html)
|
||||
* [Docker container vs Virtual machine](http://www.bogotobogo.com/DevOps/Docker/Docker\_Container\_vs\_Virtual\_Machine.php)
|
||||
* [How to Create Docker Container using Dockerfile](https://linoxide.com/linux-how-to/dockerfile-create-docker-container/)
|
||||
* [理解 Docker(2):Docker 镜像](http://www.cnblogs.com/sammyliu/p/5877964.html)
|
||||
* [为什么要使用 Docker?](https://yeasy.gitbooks.io/docker\_practice/introduction/why.html)
|
||||
* [What is Docker](https://www.docker.com/what-docker)
|
||||
* [持续集成是什么?](http://www.ruanyifeng.com/blog/2015/09/continuous-integration.html)
|
||||
|
||||
91
notes/Git.md
91
notes/Git.md
@ -1,25 +1,24 @@
|
||||
# Git
|
||||
<!-- GFM-TOC -->
|
||||
* [Git](#git)
|
||||
* [集中式与分布式](#集中式与分布式)
|
||||
* [中心服务器](#中心服务器)
|
||||
* [工作流](#工作流)
|
||||
* [分支实现](#分支实现)
|
||||
* [冲突](#冲突)
|
||||
* [Fast forward](#fast-forward)
|
||||
* [储藏(Stashing)](#储藏stashing)
|
||||
* [SSH 传输设置](#ssh-传输设置)
|
||||
* [.gitignore 文件](#gitignore-文件)
|
||||
* [Git 命令一览](#git-命令一览)
|
||||
* [参考资料](#参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [Git](Git.md#git)
|
||||
* [集中式与分布式](Git.md#集中式与分布式)
|
||||
* [中心服务器](Git.md#中心服务器)
|
||||
* [工作流](Git.md#工作流)
|
||||
* [分支实现](Git.md#分支实现)
|
||||
* [冲突](Git.md#冲突)
|
||||
* [Fast forward](Git.md#fast-forward)
|
||||
* [储藏(Stashing)](Git.md#储藏stashing)
|
||||
* [SSH 传输设置](Git.md#ssh-传输设置)
|
||||
* [.gitignore 文件](Git.md#gitignore-文件)
|
||||
* [Git 命令一览](Git.md#git-命令一览)
|
||||
* [参考资料](Git.md#参考资料)
|
||||
|
||||
## 集中式与分布式
|
||||
|
||||
Git 属于分布式版本控制系统,而 SVN 属于集中式。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208200656794.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
集中式版本控制只有中心服务器拥有一份代码,而分布式版本控制每个人的电脑上就有一份完整的代码。
|
||||
|
||||
@ -41,47 +40,55 @@ Github 就是一个中心服务器。
|
||||
|
||||
Git 的版本库有一个称为 Stage 的暂存区以及最后的 History 版本库,History 存储所有分支信息,使用一个 HEAD 指针指向当前分支。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208195941661.png"/> </div><br>
|
||||
\
|
||||
|
||||
- git add files 把文件的修改添加到暂存区
|
||||
- git commit 把暂存区的修改提交到当前分支,提交之后暂存区就被清空了
|
||||
- git reset -- files 使用当前分支上的修改覆盖暂存区,用来撤销最后一次 git add files
|
||||
- git checkout -- files 使用暂存区的修改覆盖工作目录,用来撤销本地修改
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208200014395.png"/> </div><br>
|
||||
* git add files 把文件的修改添加到暂存区
|
||||
* git commit 把暂存区的修改提交到当前分支,提交之后暂存区就被清空了
|
||||
* git reset -- files 使用当前分支上的修改覆盖暂存区,用来撤销最后一次 git add files
|
||||
* git checkout -- files 使用暂存区的修改覆盖工作目录,用来撤销本地修改
|
||||
|
||||
\
|
||||
|
||||
|
||||
可以跳过暂存区域直接从分支中取出修改,或者直接提交修改到分支中。
|
||||
|
||||
- git commit -a 直接把所有文件的修改添加到暂存区然后执行提交
|
||||
- git checkout HEAD -- files 取出最后一次修改,可以用来进行回滚操作
|
||||
* git commit -a 直接把所有文件的修改添加到暂存区然后执行提交
|
||||
* git checkout HEAD -- files 取出最后一次修改,可以用来进行回滚操作
|
||||
|
||||
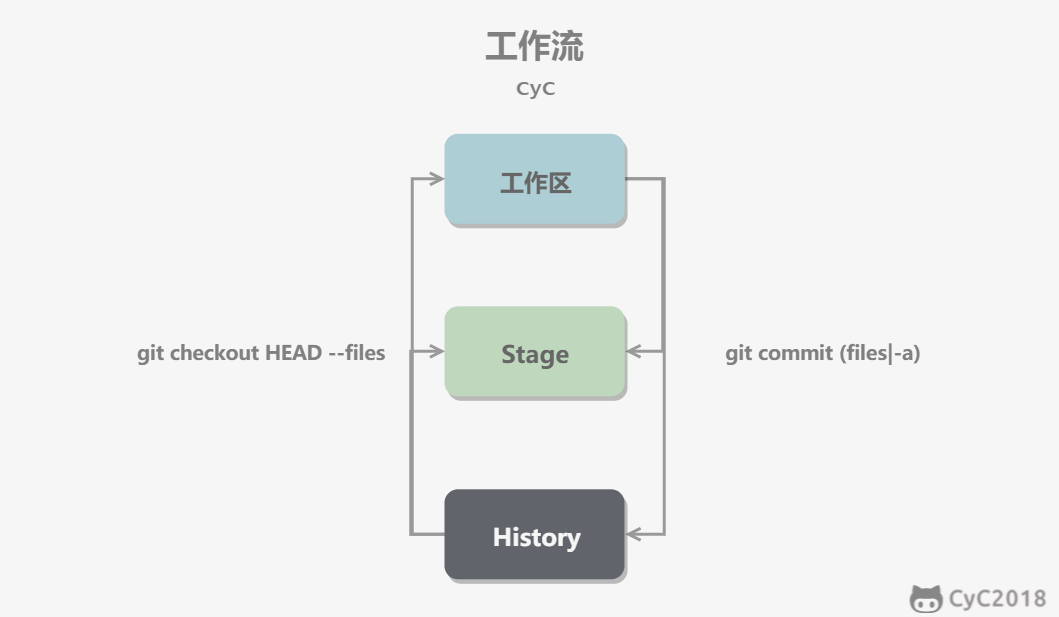\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208200543923.png"/> </div><br>
|
||||
|
||||
## 分支实现
|
||||
|
||||
使用指针将每个提交连接成一条时间线,HEAD 指针指向当前分支指针。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208203219927.png"/> </div><br>
|
||||
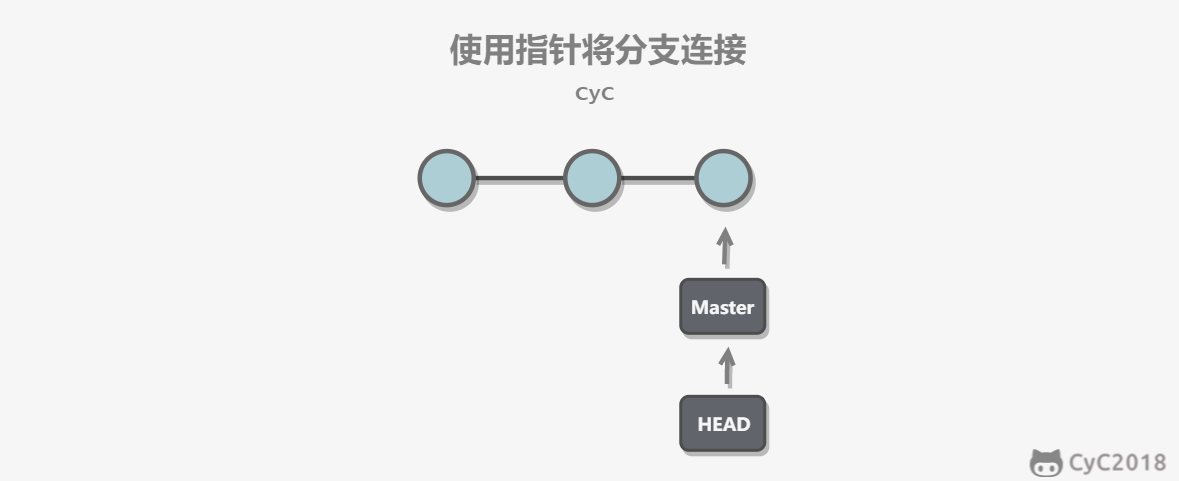\
|
||||
|
||||
|
||||
新建分支是新建一个指针指向时间线的最后一个节点,并让 HEAD 指针指向新分支,表示新分支成为当前分支。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208203142527.png"/> </div><br>
|
||||
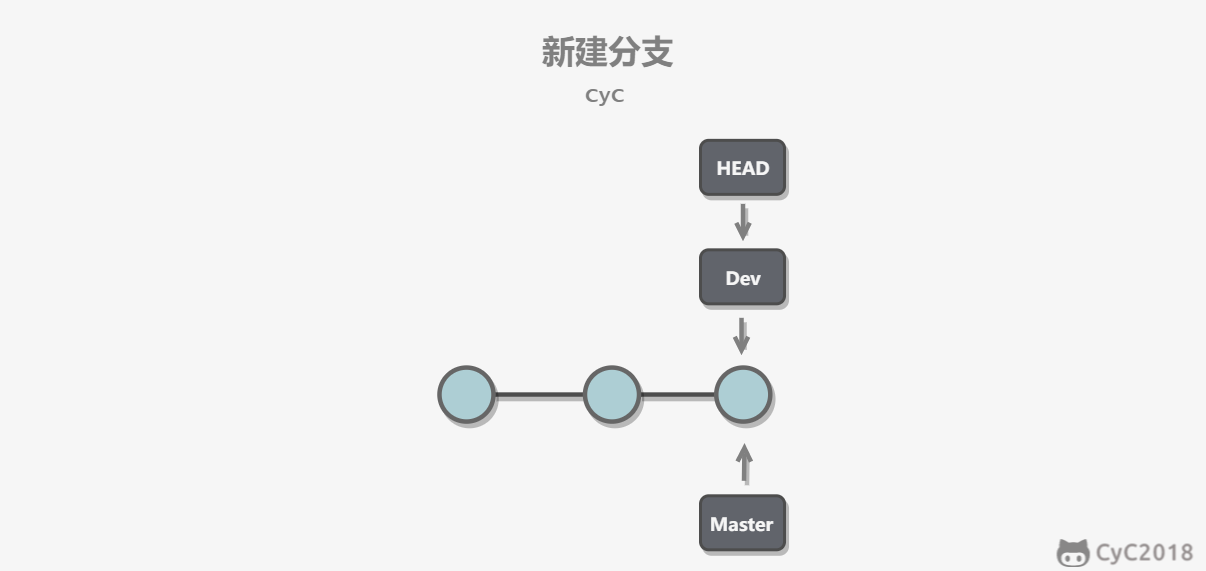\
|
||||
|
||||
|
||||
每次提交只会让当前分支指针向前移动,而其它分支指针不会移动。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208203112400.png"/> </div><br>
|
||||
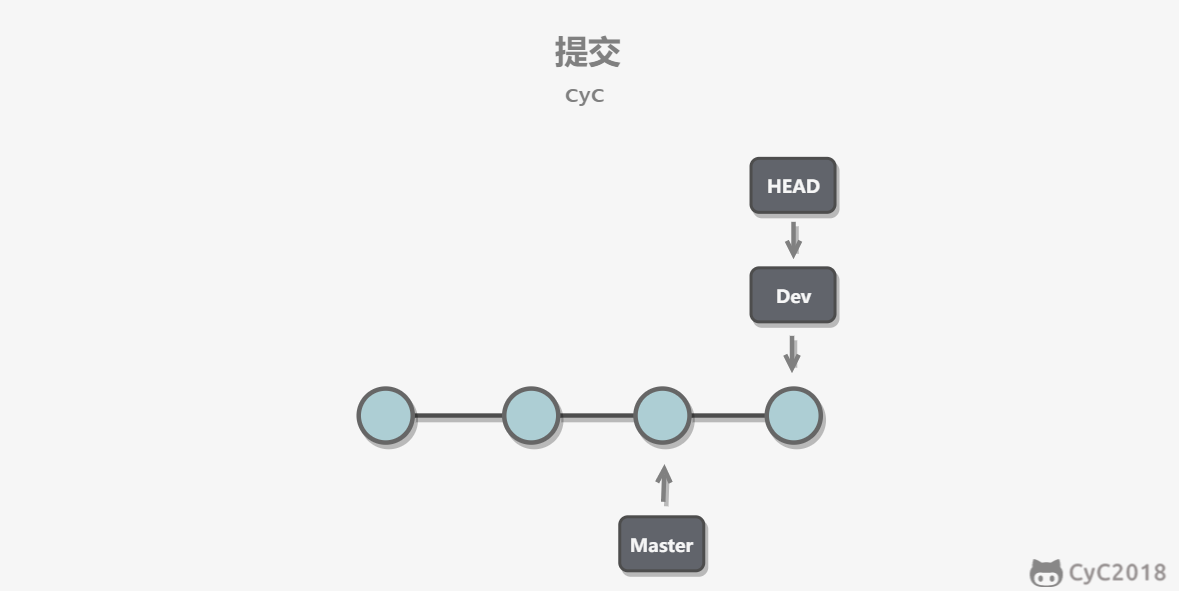\
|
||||
|
||||
|
||||
合并分支也只需要改变指针即可。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208203010540.png"/> </div><br>
|
||||
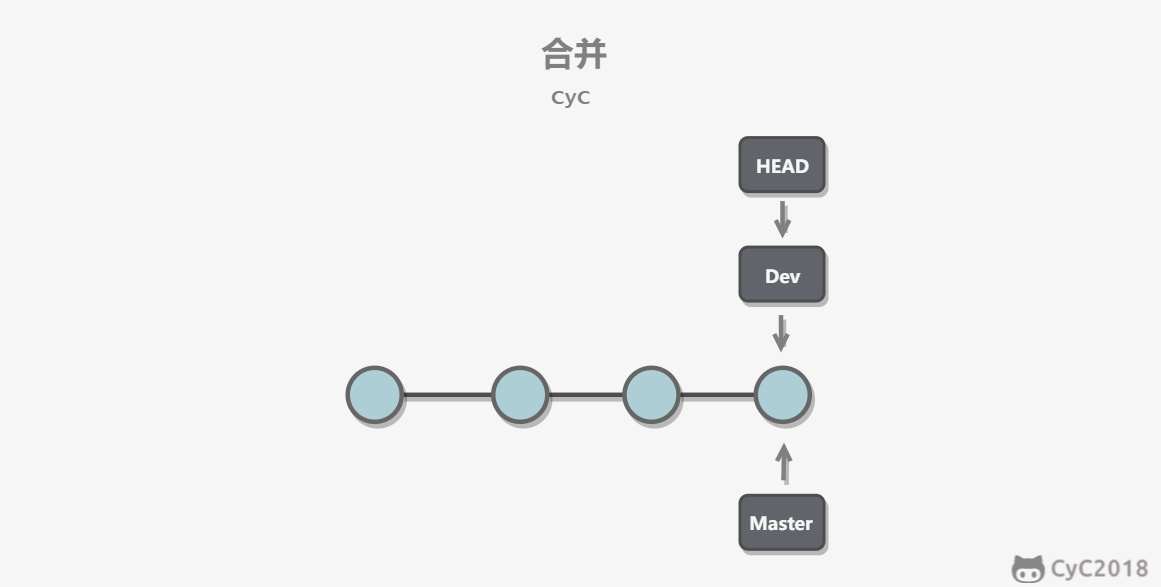\
|
||||
|
||||
|
||||
## 冲突
|
||||
|
||||
当两个分支都对同一个文件的同一行进行了修改,在分支合并时就会产生冲突。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208203034705.png"/> </div><br>
|
||||
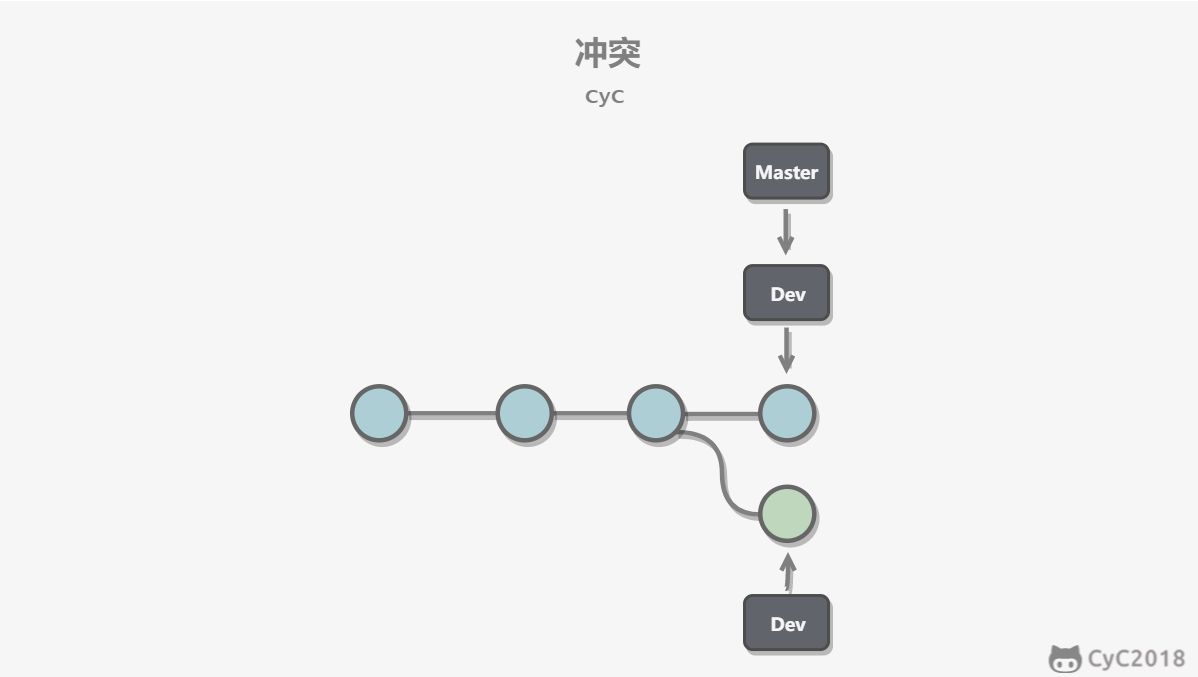\
|
||||
|
||||
Git 会使用 \<\<\<\<\<\<\< ,======= ,\>\>\>\>\>\>\> 标记出不同分支的内容,只需要把不同分支中冲突部分修改成一样就能解决冲突。
|
||||
|
||||
Git 会使用 <<<<<<< ,======= ,>>>>>>> 标记出不同分支的内容,只需要把不同分支中冲突部分修改成一样就能解决冲突。
|
||||
|
||||
```
|
||||
<<<<<<< HEAD
|
||||
@ -101,7 +108,8 @@ Creating a new branch is quick AND simple.
|
||||
$ git merge --no-ff -m "merge with no-ff" dev
|
||||
```
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208203639712.png"/> </div><br>
|
||||
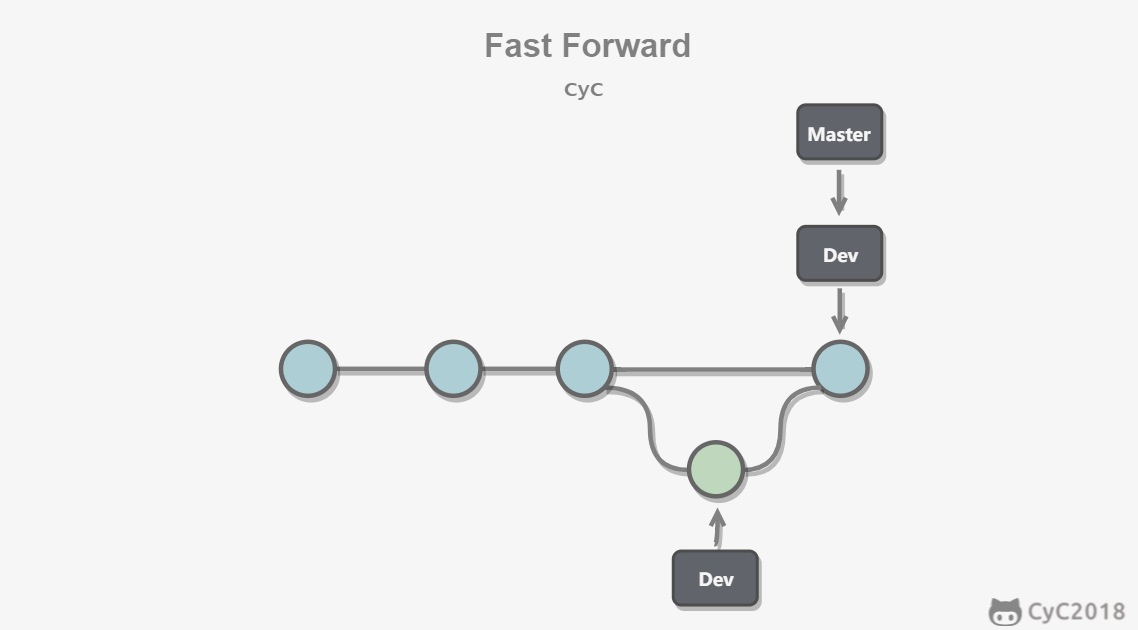\
|
||||
|
||||
|
||||
## 储藏(Stashing)
|
||||
|
||||
@ -121,33 +129,34 @@ HEAD is now at 049d078 added the index file (To restore them type "git stash app
|
||||
|
||||
Git 仓库和 Github 中心仓库之间的传输是通过 SSH 加密。
|
||||
|
||||
如果工作区下没有 .ssh 目录,或者该目录下没有 id_rsa 和 id_rsa.pub 这两个文件,可以通过以下命令来创建 SSH Key:
|
||||
如果工作区下没有 .ssh 目录,或者该目录下没有 id\_rsa 和 id\_rsa.pub 这两个文件,可以通过以下命令来创建 SSH Key:
|
||||
|
||||
```
|
||||
$ ssh-keygen -t rsa -C "youremail@example.com"
|
||||
```
|
||||
|
||||
然后把公钥 id_rsa.pub 的内容复制到 Github "Account settings" 的 SSH Keys 中。
|
||||
然后把公钥 id\_rsa.pub 的内容复制到 Github "Account settings" 的 SSH Keys 中。
|
||||
|
||||
## .gitignore 文件
|
||||
|
||||
忽略以下文件:
|
||||
|
||||
- 操作系统自动生成的文件,比如缩略图;
|
||||
- 编译生成的中间文件,比如 Java 编译产生的 .class 文件;
|
||||
- 自己的敏感信息,比如存放口令的配置文件。
|
||||
* 操作系统自动生成的文件,比如缩略图;
|
||||
* 编译生成的中间文件,比如 Java 编译产生的 .class 文件;
|
||||
* 自己的敏感信息,比如存放口令的配置文件。
|
||||
|
||||
不需要全部自己编写,可以到 [https://github.com/github/gitignore](https://github.com/github/gitignore) 中进行查询。
|
||||
|
||||
## Git 命令一览
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/7a29acce-f243-4914-9f00-f2988c528412.jpg" width=""> </div><br>
|
||||
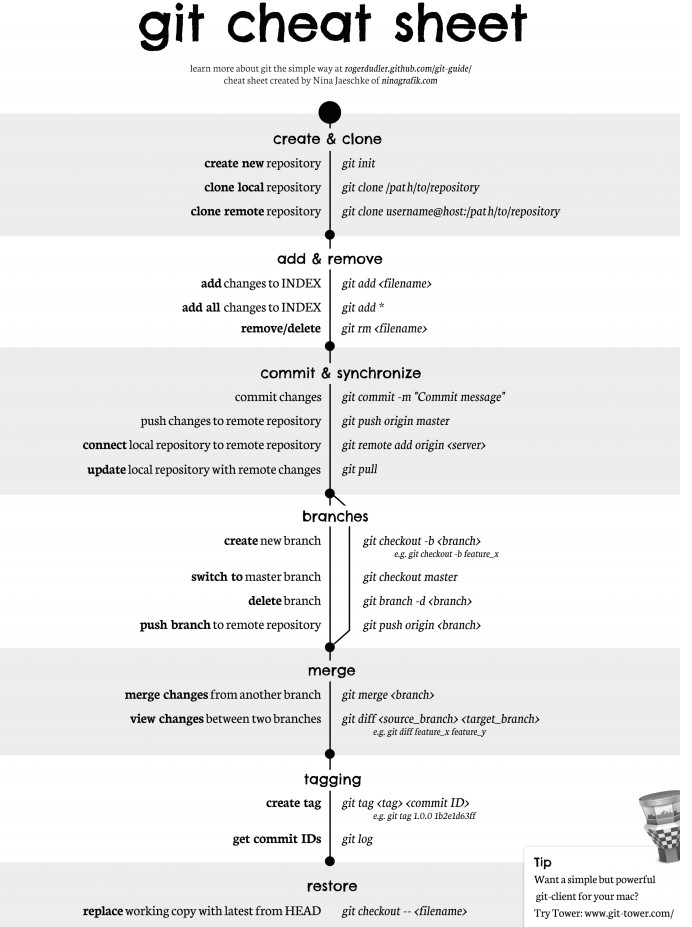\
|
||||
|
||||
|
||||
比较详细的地址:http://www.cheat-sheets.org/saved-copy/git-cheat-sheet.pdf
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [Git - 简明指南](http://rogerdudler.github.io/git-guide/index.zh.html)
|
||||
- [图解 Git](http://marklodato.github.io/visual-git-guide/index-zh-cn.html)
|
||||
- [廖雪峰 : Git 教程](https://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b000)
|
||||
- [Learn Git Branching](https://learngitbranching.js.org/)
|
||||
* [Git - 简明指南](http://rogerdudler.github.io/git-guide/index.zh.html)
|
||||
* [图解 Git](http://marklodato.github.io/visual-git-guide/index-zh-cn.html)
|
||||
* [廖雪峰 : Git 教程](https://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b000)
|
||||
* [Learn Git Branching](https://learngitbranching.js.org)
|
||||
|
||||
550
notes/HTTP.md
550
notes/HTTP.md
@ -1,62 +1,60 @@
|
||||
# HTTP
|
||||
<!-- GFM-TOC -->
|
||||
* [HTTP](#http)
|
||||
* [一 、基础概念](#一-基础概念)
|
||||
* [请求和响应报文](#请求和响应报文)
|
||||
* [URL](#url)
|
||||
* [二、HTTP 方法](#二http-方法)
|
||||
* [GET](#get)
|
||||
* [HEAD](#head)
|
||||
* [POST](#post)
|
||||
* [PUT](#put)
|
||||
* [PATCH](#patch)
|
||||
* [DELETE](#delete)
|
||||
* [OPTIONS](#options)
|
||||
* [CONNECT](#connect)
|
||||
* [TRACE](#trace)
|
||||
* [三、HTTP 状态码](#三http-状态码)
|
||||
* [1XX 信息](#1xx-信息)
|
||||
* [2XX 成功](#2xx-成功)
|
||||
* [3XX 重定向](#3xx-重定向)
|
||||
* [4XX 客户端错误](#4xx-客户端错误)
|
||||
* [5XX 服务器错误](#5xx-服务器错误)
|
||||
* [四、HTTP 首部](#四http-首部)
|
||||
* [通用首部字段](#通用首部字段)
|
||||
* [请求首部字段](#请求首部字段)
|
||||
* [响应首部字段](#响应首部字段)
|
||||
* [实体首部字段](#实体首部字段)
|
||||
* [五、具体应用](#五具体应用)
|
||||
* [连接管理](#连接管理)
|
||||
* [Cookie](#cookie)
|
||||
* [缓存](#缓存)
|
||||
* [内容协商](#内容协商)
|
||||
* [内容编码](#内容编码)
|
||||
* [范围请求](#范围请求)
|
||||
* [分块传输编码](#分块传输编码)
|
||||
* [多部分对象集合](#多部分对象集合)
|
||||
* [虚拟主机](#虚拟主机)
|
||||
* [通信数据转发](#通信数据转发)
|
||||
* [六、HTTPS](#六https)
|
||||
* [加密](#加密)
|
||||
* [认证](#认证)
|
||||
* [完整性保护](#完整性保护)
|
||||
* [HTTPS 的缺点](#https-的缺点)
|
||||
* [七、HTTP/2.0](#七http20)
|
||||
* [HTTP/1.x 缺陷](#http1x-缺陷)
|
||||
* [二进制分帧层](#二进制分帧层)
|
||||
* [服务端推送](#服务端推送)
|
||||
* [首部压缩](#首部压缩)
|
||||
* [八、HTTP/1.1 新特性](#八http11-新特性)
|
||||
* [九、GET 和 POST 比较](#九get-和-post-比较)
|
||||
* [作用](#作用)
|
||||
* [参数](#参数)
|
||||
* [安全](#安全)
|
||||
* [幂等性](#幂等性)
|
||||
* [可缓存](#可缓存)
|
||||
* [XMLHttpRequest](#xmlhttprequest)
|
||||
* [参考资料](#参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [HTTP](HTTP.md#http)
|
||||
* [一 、基础概念](HTTP.md#一-基础概念)
|
||||
* [请求和响应报文](HTTP.md#请求和响应报文)
|
||||
* [URL](HTTP.md#url)
|
||||
* [二、HTTP 方法](HTTP.md#二http-方法)
|
||||
* [GET](HTTP.md#get)
|
||||
* [HEAD](HTTP.md#head)
|
||||
* [POST](HTTP.md#post)
|
||||
* [PUT](HTTP.md#put)
|
||||
* [PATCH](HTTP.md#patch)
|
||||
* [DELETE](HTTP.md#delete)
|
||||
* [OPTIONS](HTTP.md#options)
|
||||
* [CONNECT](HTTP.md#connect)
|
||||
* [TRACE](HTTP.md#trace)
|
||||
* [三、HTTP 状态码](HTTP.md#三http-状态码)
|
||||
* [1XX 信息](HTTP.md#1xx-信息)
|
||||
* [2XX 成功](HTTP.md#2xx-成功)
|
||||
* [3XX 重定向](HTTP.md#3xx-重定向)
|
||||
* [4XX 客户端错误](HTTP.md#4xx-客户端错误)
|
||||
* [5XX 服务器错误](HTTP.md#5xx-服务器错误)
|
||||
* [四、HTTP 首部](HTTP.md#四http-首部)
|
||||
* [通用首部字段](HTTP.md#通用首部字段)
|
||||
* [请求首部字段](HTTP.md#请求首部字段)
|
||||
* [响应首部字段](HTTP.md#响应首部字段)
|
||||
* [实体首部字段](HTTP.md#实体首部字段)
|
||||
* [五、具体应用](HTTP.md#五具体应用)
|
||||
* [连接管理](HTTP.md#连接管理)
|
||||
* [Cookie](HTTP.md#cookie)
|
||||
* [缓存](HTTP.md#缓存)
|
||||
* [内容协商](HTTP.md#内容协商)
|
||||
* [内容编码](HTTP.md#内容编码)
|
||||
* [范围请求](HTTP.md#范围请求)
|
||||
* [分块传输编码](HTTP.md#分块传输编码)
|
||||
* [多部分对象集合](HTTP.md#多部分对象集合)
|
||||
* [虚拟主机](HTTP.md#虚拟主机)
|
||||
* [通信数据转发](HTTP.md#通信数据转发)
|
||||
* [六、HTTPS](HTTP.md#六https)
|
||||
* [加密](HTTP.md#加密)
|
||||
* [认证](HTTP.md#认证)
|
||||
* [完整性保护](HTTP.md#完整性保护)
|
||||
* [HTTPS 的缺点](HTTP.md#https-的缺点)
|
||||
* [七、HTTP/2.0](HTTP.md#七http20)
|
||||
* [HTTP/1.x 缺陷](HTTP.md#http1x-缺陷)
|
||||
* [二进制分帧层](HTTP.md#二进制分帧层)
|
||||
* [服务端推送](HTTP.md#服务端推送)
|
||||
* [首部压缩](HTTP.md#首部压缩)
|
||||
* [八、HTTP/1.1 新特性](HTTP.md#八http11-新特性)
|
||||
* [九、GET 和 POST 比较](HTTP.md#九get-和-post-比较)
|
||||
* [作用](HTTP.md#作用)
|
||||
* [参数](HTTP.md#参数)
|
||||
* [安全](HTTP.md#安全)
|
||||
* [幂等性](HTTP.md#幂等性)
|
||||
* [可缓存](HTTP.md#可缓存)
|
||||
* [XMLHttpRequest](HTTP.md#xmlhttprequest)
|
||||
* [参考资料](HTTP.md#参考资料)
|
||||
|
||||
## 一 、基础概念
|
||||
|
||||
@ -66,10 +64,10 @@
|
||||
|
||||
请求报文结构:
|
||||
|
||||
- 第一行是包含了请求方法、URL、协议版本;
|
||||
- 接下来的多行都是请求首部 Header,每个首部都有一个首部名称,以及对应的值。
|
||||
- 一个空行用来分隔首部和内容主体 Body
|
||||
- 最后是请求的内容主体
|
||||
* 第一行是包含了请求方法、URL、协议版本;
|
||||
* 接下来的多行都是请求首部 Header,每个首部都有一个首部名称,以及对应的值。
|
||||
* 一个空行用来分隔首部和内容主体 Body
|
||||
* 最后是请求的内容主体
|
||||
|
||||
```
|
||||
GET http://www.example.com/ HTTP/1.1
|
||||
@ -89,10 +87,10 @@ param1=1¶m2=2
|
||||
|
||||
响应报文结构:
|
||||
|
||||
- 第一行包含协议版本、状态码以及描述,最常见的是 200 OK 表示请求成功了
|
||||
- 接下来多行也是首部内容
|
||||
- 一个空行分隔首部和内容主体
|
||||
- 最后是响应的内容主体
|
||||
* 第一行包含协议版本、状态码以及描述,最常见的是 200 OK 表示请求成功了
|
||||
* 接下来多行也是首部内容
|
||||
* 一个空行分隔首部和内容主体
|
||||
* 最后是响应的内容主体
|
||||
|
||||
```
|
||||
HTTP/1.1 200 OK
|
||||
@ -119,23 +117,23 @@ X-Cache: HIT
|
||||
// 省略...
|
||||
</body>
|
||||
</html>
|
||||
|
||||
```
|
||||
|
||||
### URL
|
||||
|
||||
HTTP 使用 URL( **U** niform **R**esource **L**ocator,统一资源定位符)来定位资源,它是 URI(**U**niform **R**esource **I**dentifier,统一资源标识符)的子集,URL 在 URI 的基础上增加了定位能力。URI 除了包含 URL,还包含 URN(Uniform Resource Name,统一资源名称),它只是用来定义一个资源的名称,并不具备定位该资源的能力。例如 urn:isbn:0451450523 用来定义一个书籍名称,但是却没有表示怎么找到这本书。
|
||||
HTTP 使用 URL( **U** niform **R**esource **L**ocator,统一资源定位符)来定位资源,它是 URI(**U**niform **R**esource **I**dentifier,统一资源标识符)的子集,URL 在 URI 的基础上增加了定位能力。URI 除了包含 URL,还包含 URN(Uniform Resource Name,统一资源名称),它只是用来定义一个资源的名称,并不具备定位该资源的能力。例如 urn:isbn:0451450523 用来定义一个书籍名称,但是却没有表示怎么找到这本书。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/8441b2c4-dca7-4d6b-8efb-f22efccaf331.png" width="500px"> </div><br>
|
||||
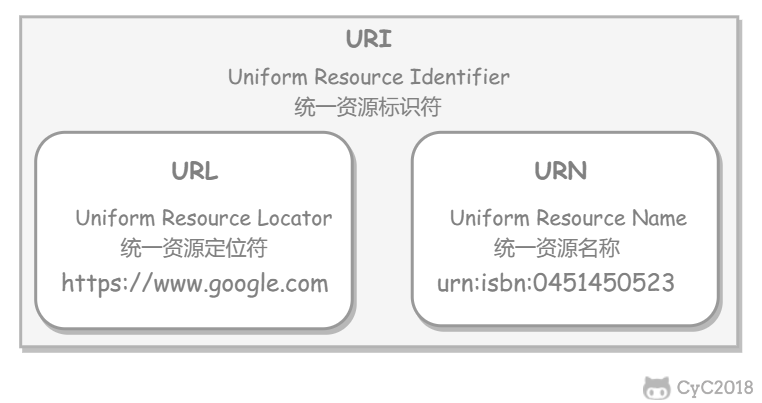\
|
||||
|
||||
- [wikipedia:统一资源标志符](https://zh.wikipedia.org/wiki/统一资源标志符)
|
||||
- [wikipedia: URL](https://en.wikipedia.org/wiki/URL)
|
||||
- [rfc2616:3.2.2 http URL](https://www.w3.org/Protocols/rfc2616/rfc2616-sec3.html#sec3.2.2)
|
||||
- [What is the difference between a URI, a URL and a URN?](https://stackoverflow.com/questions/176264/what-is-the-difference-between-a-uri-a-url-and-a-urn)
|
||||
|
||||
* [wikipedia:统一资源标志符](https://zh.wikipedia.org/wiki/%E7%BB%9F%E4%B8%80%E8%B5%84%E6%BA%90%E6%A0%87%E5%BF%97%E7%AC%A6)
|
||||
* [wikipedia: URL](https://en.wikipedia.org/wiki/URL)
|
||||
* [rfc2616:3.2.2 http URL](https://www.w3.org/Protocols/rfc2616/rfc2616-sec3.html#sec3.2.2)
|
||||
* [What is the difference between a URI, a URL and a URN?](https://stackoverflow.com/questions/176264/what-is-the-difference-between-a-uri-a-url-and-a-urn)
|
||||
|
||||
## 二、HTTP 方法
|
||||
|
||||
客户端发送的 **请求报文** 第一行为请求行,包含了方法字段。
|
||||
客户端发送的 **请求报文** 第一行为请求行,包含了方法字段。
|
||||
|
||||
### GET
|
||||
|
||||
@ -218,7 +216,8 @@ DELETE /file.html HTTP/1.1
|
||||
CONNECT www.example.com:443 HTTP/1.1
|
||||
```
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/dc00f70e-c5c8-4d20-baf1-2d70014a97e3.jpg" width=""/> </div><br>
|
||||
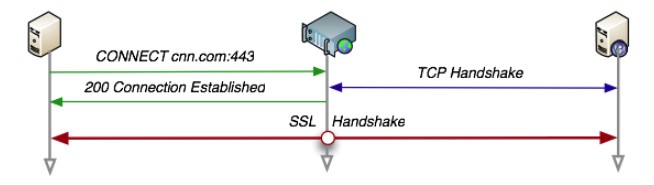\
|
||||
|
||||
|
||||
### TRACE
|
||||
|
||||
@ -230,61 +229,50 @@ CONNECT www.example.com:443 HTTP/1.1
|
||||
|
||||
通常不会使用 TRACE,并且它容易受到 XST 攻击(Cross-Site Tracing,跨站追踪)。
|
||||
|
||||
- [rfc2616:9 Method Definitions](https://www.w3.org/Protocols/rfc2616/rfc2616-sec9.html)
|
||||
* [rfc2616:9 Method Definitions](https://www.w3.org/Protocols/rfc2616/rfc2616-sec9.html)
|
||||
|
||||
## 三、HTTP 状态码
|
||||
|
||||
服务器返回的 **响应报文** 中第一行为状态行,包含了状态码以及原因短语,用来告知客户端请求的结果。
|
||||
服务器返回的 **响应报文** 中第一行为状态行,包含了状态码以及原因短语,用来告知客户端请求的结果。
|
||||
|
||||
| 状态码 | 类别 | 含义 |
|
||||
| :---: | :---: | :---: |
|
||||
| 1XX | Informational(信息性状态码) | 接收的请求正在处理 |
|
||||
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
|
||||
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
|
||||
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
|
||||
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
|
||||
| 状态码 | 类别 | 含义 |
|
||||
| :-: | :--------------------: | :-----------: |
|
||||
| 1XX | Informational(信息性状态码) | 接收的请求正在处理 |
|
||||
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
|
||||
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
|
||||
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
|
||||
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
|
||||
|
||||
### 1XX 信息
|
||||
|
||||
- **100 Continue** :表明到目前为止都很正常,客户端可以继续发送请求或者忽略这个响应。
|
||||
* **100 Continue** :表明到目前为止都很正常,客户端可以继续发送请求或者忽略这个响应。
|
||||
|
||||
### 2XX 成功
|
||||
|
||||
- **200 OK**
|
||||
|
||||
- **204 No Content** :请求已经成功处理,但是返回的响应报文不包含实体的主体部分。一般在只需要从客户端往服务器发送信息,而不需要返回数据时使用。
|
||||
|
||||
- **206 Partial Content** :表示客户端进行了范围请求,响应报文包含由 Content-Range 指定范围的实体内容。
|
||||
* **200 OK**
|
||||
* **204 No Content** :请求已经成功处理,但是返回的响应报文不包含实体的主体部分。一般在只需要从客户端往服务器发送信息,而不需要返回数据时使用。
|
||||
* **206 Partial Content** :表示客户端进行了范围请求,响应报文包含由 Content-Range 指定范围的实体内容。
|
||||
|
||||
### 3XX 重定向
|
||||
|
||||
- **301 Moved Permanently** :永久性重定向
|
||||
|
||||
- **302 Found** :临时性重定向
|
||||
|
||||
- **303 See Other** :和 302 有着相同的功能,但是 303 明确要求客户端应该采用 GET 方法获取资源。
|
||||
|
||||
- 注:虽然 HTTP 协议规定 301、302 状态下重定向时不允许把 POST 方法改成 GET 方法,但是大多数浏览器都会在 301、302 和 303 状态下的重定向把 POST 方法改成 GET 方法。
|
||||
|
||||
- **304 Not Modified** :如果请求报文首部包含一些条件,例如:If-Match,If-Modified-Since,If-None-Match,If-Range,If-Unmodified-Since,如果不满足条件,则服务器会返回 304 状态码。
|
||||
|
||||
- **307 Temporary Redirect** :临时重定向,与 302 的含义类似,但是 307 要求浏览器不会把重定向请求的 POST 方法改成 GET 方法。
|
||||
* **301 Moved Permanently** :永久性重定向
|
||||
* **302 Found** :临时性重定向
|
||||
* **303 See Other** :和 302 有着相同的功能,但是 303 明确要求客户端应该采用 GET 方法获取资源。
|
||||
* 注:虽然 HTTP 协议规定 301、302 状态下重定向时不允许把 POST 方法改成 GET 方法,但是大多数浏览器都会在 301、302 和 303 状态下的重定向把 POST 方法改成 GET 方法。
|
||||
* **304 Not Modified** :如果请求报文首部包含一些条件,例如:If-Match,If-Modified-Since,If-None-Match,If-Range,If-Unmodified-Since,如果不满足条件,则服务器会返回 304 状态码。
|
||||
* **307 Temporary Redirect** :临时重定向,与 302 的含义类似,但是 307 要求浏览器不会把重定向请求的 POST 方法改成 GET 方法。
|
||||
|
||||
### 4XX 客户端错误
|
||||
|
||||
- **400 Bad Request** :请求报文中存在语法错误。
|
||||
|
||||
- **401 Unauthorized** :该状态码表示发送的请求需要有认证信息(BASIC 认证、DIGEST 认证)。如果之前已进行过一次请求,则表示用户认证失败。
|
||||
|
||||
- **403 Forbidden** :请求被拒绝。
|
||||
|
||||
- **404 Not Found**
|
||||
* **400 Bad Request** :请求报文中存在语法错误。
|
||||
* **401 Unauthorized** :该状态码表示发送的请求需要有认证信息(BASIC 认证、DIGEST 认证)。如果之前已进行过一次请求,则表示用户认证失败。
|
||||
* **403 Forbidden** :请求被拒绝。
|
||||
* **404 Not Found**
|
||||
|
||||
### 5XX 服务器错误
|
||||
|
||||
- **500 Internal Server Error** :服务器正在执行请求时发生错误。
|
||||
|
||||
- **503 Service Unavailable** :服务器暂时处于超负载或正在进行停机维护,现在无法处理请求。
|
||||
* **500 Internal Server Error** :服务器正在执行请求时发生错误。
|
||||
* **503 Service Unavailable** :服务器暂时处于超负载或正在进行停机维护,现在无法处理请求。
|
||||
|
||||
## 四、HTTP 首部
|
||||
|
||||
@ -294,76 +282,77 @@ CONNECT www.example.com:443 HTTP/1.1
|
||||
|
||||
### 通用首部字段
|
||||
|
||||
| 首部字段名 | 说明 |
|
||||
| :--: | :--: |
|
||||
| Cache-Control | 控制缓存的行为 |
|
||||
| Connection | 控制不再转发给代理的首部字段、管理持久连接|
|
||||
| Date | 创建报文的日期时间 |
|
||||
| Pragma | 报文指令 |
|
||||
| Trailer | 报文末端的首部一览 |
|
||||
| Transfer-Encoding | 指定报文主体的传输编码方式 |
|
||||
| Upgrade | 升级为其他协议 |
|
||||
| Via | 代理服务器的相关信息 |
|
||||
| Warning | 错误通知 |
|
||||
| 首部字段名 | 说明 |
|
||||
| :---------------: | :-------------------: |
|
||||
| Cache-Control | 控制缓存的行为 |
|
||||
| Connection | 控制不再转发给代理的首部字段、管理持久连接 |
|
||||
| Date | 创建报文的日期时间 |
|
||||
| Pragma | 报文指令 |
|
||||
| Trailer | 报文末端的首部一览 |
|
||||
| Transfer-Encoding | 指定报文主体的传输编码方式 |
|
||||
| Upgrade | 升级为其他协议 |
|
||||
| Via | 代理服务器的相关信息 |
|
||||
| Warning | 错误通知 |
|
||||
|
||||
### 请求首部字段
|
||||
|
||||
| 首部字段名 | 说明 |
|
||||
| :--: | :--: |
|
||||
| Accept | 用户代理可处理的媒体类型 |
|
||||
| Accept-Charset | 优先的字符集 |
|
||||
| Accept-Encoding | 优先的内容编码 |
|
||||
| Accept-Language | 优先的语言(自然语言) |
|
||||
| Authorization | Web 认证信息 |
|
||||
| Expect | 期待服务器的特定行为 |
|
||||
| From | 用户的电子邮箱地址 |
|
||||
| Host | 请求资源所在服务器 |
|
||||
| If-Match | 比较实体标记(ETag) |
|
||||
| If-Modified-Since | 比较资源的更新时间 |
|
||||
| If-None-Match | 比较实体标记(与 If-Match 相反) |
|
||||
| If-Range | 资源未更新时发送实体 Byte 的范围请求 |
|
||||
| 首部字段名 | 说明 |
|
||||
| :-----------------: | :-------------------------------: |
|
||||
| Accept | 用户代理可处理的媒体类型 |
|
||||
| Accept-Charset | 优先的字符集 |
|
||||
| Accept-Encoding | 优先的内容编码 |
|
||||
| Accept-Language | 优先的语言(自然语言) |
|
||||
| Authorization | Web 认证信息 |
|
||||
| Expect | 期待服务器的特定行为 |
|
||||
| From | 用户的电子邮箱地址 |
|
||||
| Host | 请求资源所在服务器 |
|
||||
| If-Match | 比较实体标记(ETag) |
|
||||
| If-Modified-Since | 比较资源的更新时间 |
|
||||
| If-None-Match | 比较实体标记(与 If-Match 相反) |
|
||||
| If-Range | 资源未更新时发送实体 Byte 的范围请求 |
|
||||
| If-Unmodified-Since | 比较资源的更新时间(与 If-Modified-Since 相反) |
|
||||
| Max-Forwards | 最大传输逐跳数 |
|
||||
| Proxy-Authorization | 代理服务器要求客户端的认证信息 |
|
||||
| Range | 实体的字节范围请求 |
|
||||
| Referer | 对请求中 URI 的原始获取方 |
|
||||
| TE | 传输编码的优先级 |
|
||||
| User-Agent | HTTP 客户端程序的信息 |
|
||||
| Max-Forwards | 最大传输逐跳数 |
|
||||
| Proxy-Authorization | 代理服务器要求客户端的认证信息 |
|
||||
| Range | 实体的字节范围请求 |
|
||||
| Referer | 对请求中 URI 的原始获取方 |
|
||||
| TE | 传输编码的优先级 |
|
||||
| User-Agent | HTTP 客户端程序的信息 |
|
||||
|
||||
### 响应首部字段
|
||||
|
||||
| 首部字段名 | 说明 |
|
||||
| :--: | :--: |
|
||||
| Accept-Ranges | 是否接受字节范围请求 |
|
||||
| Age | 推算资源创建经过时间 |
|
||||
| ETag | 资源的匹配信息 |
|
||||
| Location | 令客户端重定向至指定 URI |
|
||||
| 首部字段名 | 说明 |
|
||||
| :----------------: | :------------: |
|
||||
| Accept-Ranges | 是否接受字节范围请求 |
|
||||
| Age | 推算资源创建经过时间 |
|
||||
| ETag | 资源的匹配信息 |
|
||||
| Location | 令客户端重定向至指定 URI |
|
||||
| Proxy-Authenticate | 代理服务器对客户端的认证信息 |
|
||||
| Retry-After | 对再次发起请求的时机要求 |
|
||||
| Server | HTTP 服务器的安装信息 |
|
||||
| Vary | 代理服务器缓存的管理信息 |
|
||||
| WWW-Authenticate | 服务器对客户端的认证信息 |
|
||||
| Retry-After | 对再次发起请求的时机要求 |
|
||||
| Server | HTTP 服务器的安装信息 |
|
||||
| Vary | 代理服务器缓存的管理信息 |
|
||||
| WWW-Authenticate | 服务器对客户端的认证信息 |
|
||||
|
||||
### 实体首部字段
|
||||
|
||||
| 首部字段名 | 说明 |
|
||||
| :--: | :--: |
|
||||
| Allow | 资源可支持的 HTTP 方法 |
|
||||
| Content-Encoding | 实体主体适用的编码方式 |
|
||||
| Content-Language | 实体主体的自然语言 |
|
||||
| Content-Length | 实体主体的大小 |
|
||||
| Content-Location | 替代对应资源的 URI |
|
||||
| Content-MD5 | 实体主体的报文摘要 |
|
||||
| Content-Range | 实体主体的位置范围 |
|
||||
| Content-Type | 实体主体的媒体类型 |
|
||||
| Expires | 实体主体过期的日期时间 |
|
||||
| Last-Modified | 资源的最后修改日期时间 |
|
||||
| 首部字段名 | 说明 |
|
||||
| :--------------: | :------------: |
|
||||
| Allow | 资源可支持的 HTTP 方法 |
|
||||
| Content-Encoding | 实体主体适用的编码方式 |
|
||||
| Content-Language | 实体主体的自然语言 |
|
||||
| Content-Length | 实体主体的大小 |
|
||||
| Content-Location | 替代对应资源的 URI |
|
||||
| Content-MD5 | 实体主体的报文摘要 |
|
||||
| Content-Range | 实体主体的位置范围 |
|
||||
| Content-Type | 实体主体的媒体类型 |
|
||||
| Expires | 实体主体过期的日期时间 |
|
||||
| Last-Modified | 资源的最后修改日期时间 |
|
||||
|
||||
## 五、具体应用
|
||||
|
||||
### 连接管理
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/HTTP1_x_Connections.png" width="800"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
#### 1. 短连接与长连接
|
||||
|
||||
@ -371,8 +360,8 @@ CONNECT www.example.com:443 HTTP/1.1
|
||||
|
||||
长连接只需要建立一次 TCP 连接就能进行多次 HTTP 通信。
|
||||
|
||||
- 从 HTTP/1.1 开始默认是长连接的,如果要断开连接,需要由客户端或者服务器端提出断开,使用 `Connection : close`;
|
||||
- 在 HTTP/1.1 之前默认是短连接的,如果需要使用长连接,则使用 `Connection : Keep-Alive`。
|
||||
* 从 HTTP/1.1 开始默认是长连接的,如果要断开连接,需要由客户端或者服务器端提出断开,使用 `Connection : close`;
|
||||
* 在 HTTP/1.1 之前默认是短连接的,如果需要使用长连接,则使用 `Connection : Keep-Alive`。
|
||||
|
||||
#### 2. 流水线
|
||||
|
||||
@ -390,9 +379,9 @@ Cookie 曾一度用于客户端数据的存储,因为当时并没有其它合
|
||||
|
||||
#### 1. 用途
|
||||
|
||||
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
|
||||
- 个性化设置(如用户自定义设置、主题等)
|
||||
- 浏览器行为跟踪(如跟踪分析用户行为等)
|
||||
* 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
|
||||
* 个性化设置(如用户自定义设置、主题等)
|
||||
* 浏览器行为跟踪(如跟踪分析用户行为等)
|
||||
|
||||
#### 2. 创建过程
|
||||
|
||||
@ -417,8 +406,8 @@ Cookie: yummy_cookie=choco; tasty_cookie=strawberry
|
||||
|
||||
#### 3. 分类
|
||||
|
||||
- 会话期 Cookie:浏览器关闭之后它会被自动删除,也就是说它仅在会话期内有效。
|
||||
- 持久性 Cookie:指定过期时间(Expires)或有效期(max-age)之后就成为了持久性的 Cookie。
|
||||
* 会话期 Cookie:浏览器关闭之后它会被自动删除,也就是说它仅在会话期内有效。
|
||||
* 持久性 Cookie:指定过期时间(Expires)或有效期(max-age)之后就成为了持久性的 Cookie。
|
||||
|
||||
```html
|
||||
Set-Cookie: id=a3fWa; Expires=Wed, 21 Oct 2015 07:28:00 GMT;
|
||||
@ -430,9 +419,9 @@ Domain 标识指定了哪些主机可以接受 Cookie。如果不指定,默认
|
||||
|
||||
Path 标识指定了主机下的哪些路径可以接受 Cookie(该 URL 路径必须存在于请求 URL 中)。以字符 %x2F ("/") 作为路径分隔符,子路径也会被匹配。例如,设置 Path=/docs,则以下地址都会匹配:
|
||||
|
||||
- /docs
|
||||
- /docs/Web/
|
||||
- /docs/Web/HTTP
|
||||
* /docs
|
||||
* /docs/Web/
|
||||
* /docs/Web/HTTP
|
||||
|
||||
#### 5. JavaScript
|
||||
|
||||
@ -464,10 +453,10 @@ Session 可以存储在服务器上的文件、数据库或者内存中。也可
|
||||
|
||||
使用 Session 维护用户登录状态的过程如下:
|
||||
|
||||
- 用户进行登录时,用户提交包含用户名和密码的表单,放入 HTTP 请求报文中;
|
||||
- 服务器验证该用户名和密码,如果正确则把用户信息存储到 Redis 中,它在 Redis 中的 Key 称为 Session ID;
|
||||
- 服务器返回的响应报文的 Set-Cookie 首部字段包含了这个 Session ID,客户端收到响应报文之后将该 Cookie 值存入浏览器中;
|
||||
- 客户端之后对同一个服务器进行请求时会包含该 Cookie 值,服务器收到之后提取出 Session ID,从 Redis 中取出用户信息,继续之前的业务操作。
|
||||
* 用户进行登录时,用户提交包含用户名和密码的表单,放入 HTTP 请求报文中;
|
||||
* 服务器验证该用户名和密码,如果正确则把用户信息存储到 Redis 中,它在 Redis 中的 Key 称为 Session ID;
|
||||
* 服务器返回的响应报文的 Set-Cookie 首部字段包含了这个 Session ID,客户端收到响应报文之后将该 Cookie 值存入浏览器中;
|
||||
* 客户端之后对同一个服务器进行请求时会包含该 Cookie 值,服务器收到之后提取出 Session ID,从 Redis 中取出用户信息,继续之前的业务操作。
|
||||
|
||||
应该注意 Session ID 的安全性问题,不能让它被恶意攻击者轻易获取,那么就不能产生一个容易被猜到的 Session ID 值。此外,还需要经常重新生成 Session ID。在对安全性要求极高的场景下,例如转账等操作,除了使用 Session 管理用户状态之外,还需要对用户进行重新验证,比如重新输入密码,或者使用短信验证码等方式。
|
||||
|
||||
@ -477,27 +466,27 @@ Session 可以存储在服务器上的文件、数据库或者内存中。也可
|
||||
|
||||
#### 10. Cookie 与 Session 选择
|
||||
|
||||
- Cookie 只能存储 ASCII 码字符串,而 Session 则可以存储任何类型的数据,因此在考虑数据复杂性时首选 Session;
|
||||
- Cookie 存储在浏览器中,容易被恶意查看。如果非要将一些隐私数据存在 Cookie 中,可以将 Cookie 值进行加密,然后在服务器进行解密;
|
||||
- 对于大型网站,如果用户所有的信息都存储在 Session 中,那么开销是非常大的,因此不建议将所有的用户信息都存储到 Session 中。
|
||||
* Cookie 只能存储 ASCII 码字符串,而 Session 则可以存储任何类型的数据,因此在考虑数据复杂性时首选 Session;
|
||||
* Cookie 存储在浏览器中,容易被恶意查看。如果非要将一些隐私数据存在 Cookie 中,可以将 Cookie 值进行加密,然后在服务器进行解密;
|
||||
* 对于大型网站,如果用户所有的信息都存储在 Session 中,那么开销是非常大的,因此不建议将所有的用户信息都存储到 Session 中。
|
||||
|
||||
### 缓存
|
||||
|
||||
#### 1. 优点
|
||||
|
||||
- 缓解服务器压力;
|
||||
- 降低客户端获取资源的延迟:缓存通常位于内存中,读取缓存的速度更快。并且缓存服务器在地理位置上也有可能比源服务器来得近,例如浏览器缓存。
|
||||
* 缓解服务器压力;
|
||||
* 降低客户端获取资源的延迟:缓存通常位于内存中,读取缓存的速度更快。并且缓存服务器在地理位置上也有可能比源服务器来得近,例如浏览器缓存。
|
||||
|
||||
#### 2. 实现方法
|
||||
|
||||
- 让代理服务器进行缓存;
|
||||
- 让客户端浏览器进行缓存。
|
||||
* 让代理服务器进行缓存;
|
||||
* 让客户端浏览器进行缓存。
|
||||
|
||||
#### 3. Cache-Control
|
||||
|
||||
HTTP/1.1 通过 Cache-Control 首部字段来控制缓存。
|
||||
|
||||
**3.1 禁止进行缓存**
|
||||
**3.1 禁止进行缓存**
|
||||
|
||||
no-store 指令规定不能对请求或响应的任何一部分进行缓存。
|
||||
|
||||
@ -505,7 +494,7 @@ no-store 指令规定不能对请求或响应的任何一部分进行缓存。
|
||||
Cache-Control: no-store
|
||||
```
|
||||
|
||||
**3.2 强制确认缓存**
|
||||
**3.2 强制确认缓存**
|
||||
|
||||
no-cache 指令规定缓存服务器需要先向源服务器验证缓存资源的有效性,只有当缓存资源有效时才能使用该缓存对客户端的请求进行响应。
|
||||
|
||||
@ -513,7 +502,7 @@ no-cache 指令规定缓存服务器需要先向源服务器验证缓存资源
|
||||
Cache-Control: no-cache
|
||||
```
|
||||
|
||||
**3.3 私有缓存和公共缓存**
|
||||
**3.3 私有缓存和公共缓存**
|
||||
|
||||
private 指令规定了将资源作为私有缓存,只能被单独用户使用,一般存储在用户浏览器中。
|
||||
|
||||
@ -527,7 +516,7 @@ public 指令规定了将资源作为公共缓存,可以被多个用户使用
|
||||
Cache-Control: public
|
||||
```
|
||||
|
||||
**3.4 缓存过期机制**
|
||||
**3.4 缓存过期机制**
|
||||
|
||||
max-age 指令出现在请求报文,并且缓存资源的缓存时间小于该指令指定的时间,那么就能接受该缓存。
|
||||
|
||||
@ -543,8 +532,8 @@ Expires 首部字段也可以用于告知缓存服务器该资源什么时候会
|
||||
Expires: Wed, 04 Jul 2012 08:26:05 GMT
|
||||
```
|
||||
|
||||
- 在 HTTP/1.1 中,会优先处理 max-age 指令;
|
||||
- 在 HTTP/1.0 中,max-age 指令会被忽略掉。
|
||||
* 在 HTTP/1.1 中,会优先处理 max-age 指令;
|
||||
* 在 HTTP/1.0 中,max-age 指令会被忽略掉。
|
||||
|
||||
#### 4. 缓存验证
|
||||
|
||||
@ -576,17 +565,17 @@ If-Modified-Since: Wed, 21 Oct 2015 07:28:00 GMT
|
||||
|
||||
#### 1. 类型
|
||||
|
||||
**1.1 服务端驱动型**
|
||||
**1.1 服务端驱动型**
|
||||
|
||||
客户端设置特定的 HTTP 首部字段,例如 Accept、Accept-Charset、Accept-Encoding、Accept-Language,服务器根据这些字段返回特定的资源。
|
||||
|
||||
它存在以下问题:
|
||||
|
||||
- 服务器很难知道客户端浏览器的全部信息;
|
||||
- 客户端提供的信息相当冗长(HTTP/2 协议的首部压缩机制缓解了这个问题),并且存在隐私风险(HTTP 指纹识别技术);
|
||||
- 给定的资源需要返回不同的展现形式,共享缓存的效率会降低,而服务器端的实现会越来越复杂。
|
||||
* 服务器很难知道客户端浏览器的全部信息;
|
||||
* 客户端提供的信息相当冗长(HTTP/2 协议的首部压缩机制缓解了这个问题),并且存在隐私风险(HTTP 指纹识别技术);
|
||||
* 给定的资源需要返回不同的展现形式,共享缓存的效率会降低,而服务器端的实现会越来越复杂。
|
||||
|
||||
**1.2 代理驱动型**
|
||||
**1.2 代理驱动型**
|
||||
|
||||
服务器返回 300 Multiple Choices 或者 406 Not Acceptable,客户端从中选出最合适的那个资源。
|
||||
|
||||
@ -642,9 +631,9 @@ Accept-Ranges: bytes
|
||||
|
||||
#### 3. 响应状态码
|
||||
|
||||
- 在请求成功的情况下,服务器会返回 206 Partial Content 状态码。
|
||||
- 在请求的范围越界的情况下,服务器会返回 416 Requested Range Not Satisfiable 状态码。
|
||||
- 在不支持范围请求的情况下,服务器会返回 200 OK 状态码。
|
||||
* 在请求成功的情况下,服务器会返回 206 Partial Content 状态码。
|
||||
* 在请求的范围越界的情况下,服务器会返回 416 Requested Range Not Satisfiable 状态码。
|
||||
* 在不支持范围请求的情况下,服务器会返回 200 OK 状态码。
|
||||
|
||||
### 分块传输编码
|
||||
|
||||
@ -683,20 +672,22 @@ HTTP/1.1 使用虚拟主机技术,使得一台服务器拥有多个域名,
|
||||
|
||||
使用代理的主要目的是:
|
||||
|
||||
- 缓存
|
||||
- 负载均衡
|
||||
- 网络访问控制
|
||||
- 访问日志记录
|
||||
* 缓存
|
||||
* 负载均衡
|
||||
* 网络访问控制
|
||||
* 访问日志记录
|
||||
|
||||
代理服务器分为正向代理和反向代理两种:
|
||||
|
||||
- 用户察觉得到正向代理的存在。
|
||||
* 用户察觉得到正向代理的存在。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/a314bb79-5b18-4e63-a976-3448bffa6f1b.png" width=""/> </div><br>
|
||||
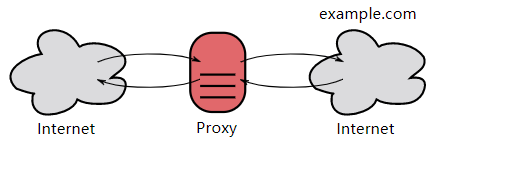\
|
||||
|
||||
- 而反向代理一般位于内部网络中,用户察觉不到。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/2d09a847-b854-439c-9198-b29c65810944.png" width=""/> </div><br>
|
||||
* 而反向代理一般位于内部网络中,用户察觉不到。
|
||||
|
||||
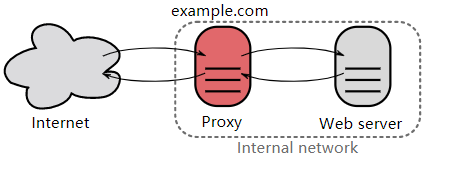\
|
||||
|
||||
|
||||
#### 2. 网关
|
||||
|
||||
@ -710,15 +701,16 @@ HTTP/1.1 使用虚拟主机技术,使得一台服务器拥有多个域名,
|
||||
|
||||
HTTP 有以下安全性问题:
|
||||
|
||||
- 使用明文进行通信,内容可能会被窃听;
|
||||
- 不验证通信方的身份,通信方的身份有可能遭遇伪装;
|
||||
- 无法证明报文的完整性,报文有可能遭篡改。
|
||||
* 使用明文进行通信,内容可能会被窃听;
|
||||
* 不验证通信方的身份,通信方的身份有可能遭遇伪装;
|
||||
* 无法证明报文的完整性,报文有可能遭篡改。
|
||||
|
||||
HTTPS 并不是新协议,而是让 HTTP 先和 SSL(Secure Sockets Layer)通信,再由 SSL 和 TCP 通信,也就是说 HTTPS 使用了隧道进行通信。
|
||||
|
||||
通过使用 SSL,HTTPS 具有了加密(防窃听)、认证(防伪装)和完整性保护(防篡改)。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/ssl-offloading.jpg" width="700"/> </div><br>
|
||||
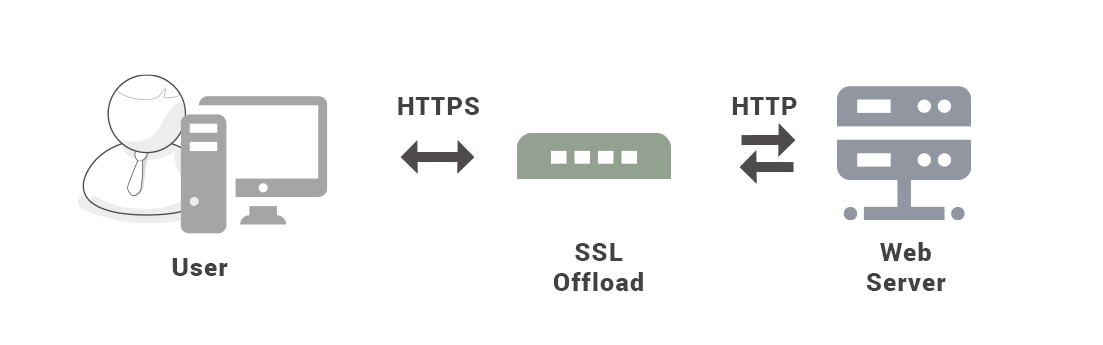\
|
||||
|
||||
|
||||
### 加密
|
||||
|
||||
@ -726,10 +718,11 @@ HTTPS 并不是新协议,而是让 HTTP 先和 SSL(Secure Sockets Layer)
|
||||
|
||||
对称密钥加密(Symmetric-Key Encryption),加密和解密使用同一密钥。
|
||||
|
||||
- 优点:运算速度快;
|
||||
- 缺点:无法安全地将密钥传输给通信方。
|
||||
* 优点:运算速度快;
|
||||
* 缺点:无法安全地将密钥传输给通信方。
|
||||
|
||||
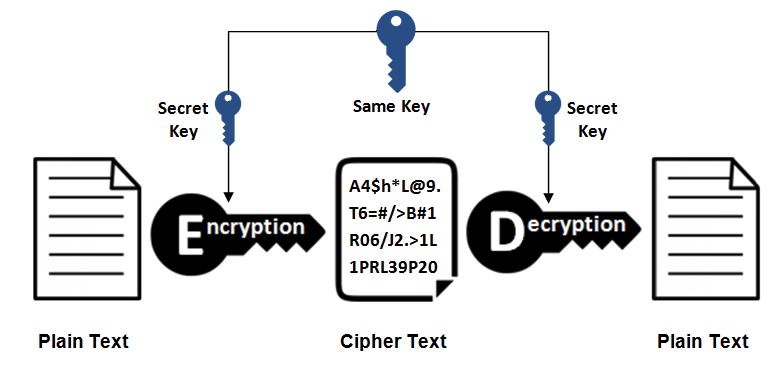\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/7fffa4b8-b36d-471f-ad0c-a88ee763bb76.png" width="600"/> </div><br>
|
||||
|
||||
#### 2.非对称密钥加密
|
||||
|
||||
@ -739,23 +732,25 @@ HTTPS 并不是新协议,而是让 HTTP 先和 SSL(Secure Sockets Layer)
|
||||
|
||||
非对称密钥除了用来加密,还可以用来进行签名。因为私有密钥无法被其他人获取,因此通信发送方使用其私有密钥进行签名,通信接收方使用发送方的公开密钥对签名进行解密,就能判断这个签名是否正确。
|
||||
|
||||
- 优点:可以更安全地将公开密钥传输给通信发送方;
|
||||
- 缺点:运算速度慢。
|
||||
* 优点:可以更安全地将公开密钥传输给通信发送方;
|
||||
* 缺点:运算速度慢。
|
||||
|
||||
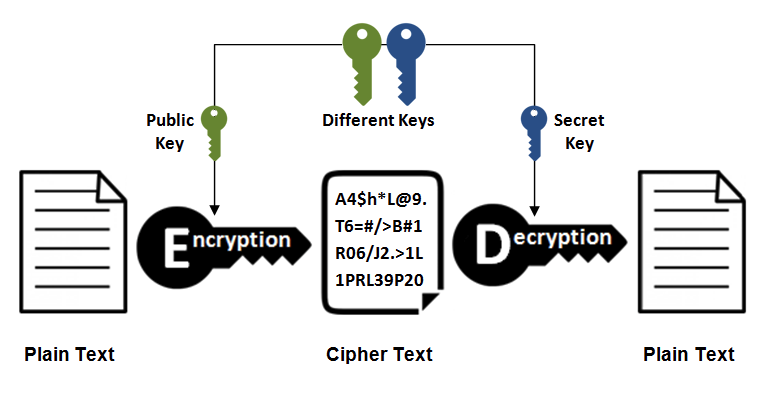\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/39ccb299-ee99-4dd1-b8b4-2f9ec9495cb4.png" width="600"/> </div><br>
|
||||
|
||||
#### 3. HTTPS 采用的加密方式
|
||||
|
||||
上面提到对称密钥加密方式的传输效率更高,但是无法安全地将密钥 Secret Key 传输给通信方。而非对称密钥加密方式可以保证传输的安全性,因此我们可以利用非对称密钥加密方式将 Secret Key 传输给通信方。HTTPS 采用混合的加密机制,正是利用了上面提到的方案:
|
||||
上面提到对称密钥加密方式的传输效率更高,但是无法安全地将密钥 Secret Key 传输给通信方。而非对称密钥加密方式可以保证传输的安全性,因此我们可以利用非对称密钥加密方式将 Secret Key 传输给通信方。HTTPS 采用混合的加密机制,正是利用了上面提到的方案:
|
||||
|
||||
- 使用非对称密钥加密方式,传输对称密钥加密方式所需要的 Secret Key,从而保证安全性;
|
||||
- 获取到 Secret Key 后,再使用对称密钥加密方式进行通信,从而保证效率。(下图中的 Session Key 就是 Secret Key)
|
||||
* 使用非对称密钥加密方式,传输对称密钥加密方式所需要的 Secret Key,从而保证安全性;
|
||||
* 获取到 Secret Key 后,再使用对称密钥加密方式进行通信,从而保证效率。(下图中的 Session Key 就是 Secret Key)
|
||||
|
||||
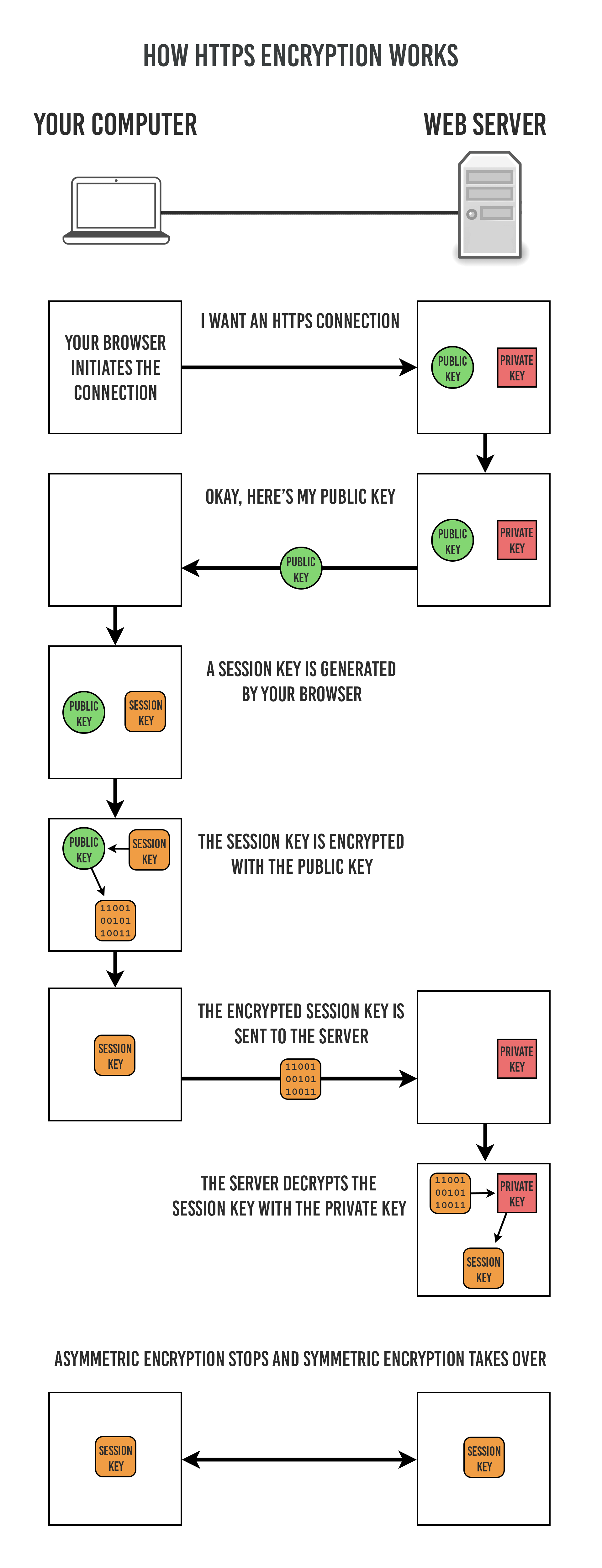\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/How-HTTPS-Works.png" width="600"/> </div><br>
|
||||
|
||||
### 认证
|
||||
|
||||
通过使用 **证书** 来对通信方进行认证。
|
||||
通过使用 **证书** 来对通信方进行认证。
|
||||
|
||||
数字证书认证机构(CA,Certificate Authority)是客户端与服务器双方都可信赖的第三方机构。
|
||||
|
||||
@ -763,7 +758,8 @@ HTTPS 并不是新协议,而是让 HTTP 先和 SSL(Secure Sockets Layer)
|
||||
|
||||
进行 HTTPS 通信时,服务器会把证书发送给客户端。客户端取得其中的公开密钥之后,先使用数字签名进行验证,如果验证通过,就可以开始通信了。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/2017-06-11-ca.png" width=""/> </div><br>
|
||||
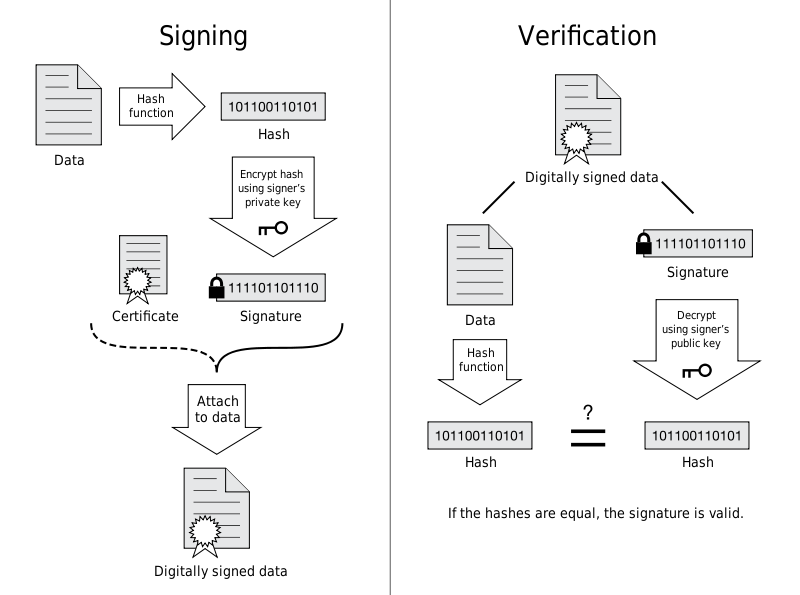\
|
||||
|
||||
|
||||
### 完整性保护
|
||||
|
||||
@ -775,8 +771,8 @@ HTTPS 的报文摘要功能之所以安全,是因为它结合了加密和认
|
||||
|
||||
### HTTPS 的缺点
|
||||
|
||||
- 因为需要进行加密解密等过程,因此速度会更慢;
|
||||
- 需要支付证书授权的高额费用。
|
||||
* 因为需要进行加密解密等过程,因此速度会更慢;
|
||||
* 需要支付证书授权的高额费用。
|
||||
|
||||
## 七、HTTP/2.0
|
||||
|
||||
@ -784,29 +780,32 @@ HTTPS 的报文摘要功能之所以安全,是因为它结合了加密和认
|
||||
|
||||
HTTP/1.x 实现简单是以牺牲性能为代价的:
|
||||
|
||||
- 客户端需要使用多个连接才能实现并发和缩短延迟;
|
||||
- 不会压缩请求和响应首部,从而导致不必要的网络流量;
|
||||
- 不支持有效的资源优先级,致使底层 TCP 连接的利用率低下。
|
||||
* 客户端需要使用多个连接才能实现并发和缩短延迟;
|
||||
* 不会压缩请求和响应首部,从而导致不必要的网络流量;
|
||||
* 不支持有效的资源优先级,致使底层 TCP 连接的利用率低下。
|
||||
|
||||
### 二进制分帧层
|
||||
|
||||
HTTP/2.0 将报文分成 HEADERS 帧和 DATA 帧,它们都是二进制格式的。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/86e6a91d-a285-447a-9345-c5484b8d0c47.png" width="400"/> </div><br>
|
||||
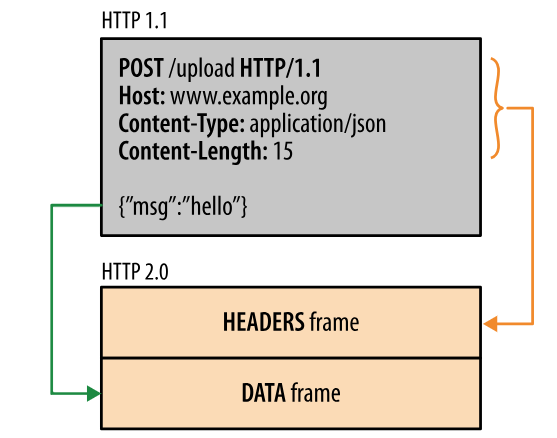\
|
||||
|
||||
|
||||
在通信过程中,只会有一个 TCP 连接存在,它承载了任意数量的双向数据流(Stream)。
|
||||
|
||||
- 一个数据流(Stream)都有一个唯一标识符和可选的优先级信息,用于承载双向信息。
|
||||
- 消息(Message)是与逻辑请求或响应对应的完整的一系列帧。
|
||||
- 帧(Frame)是最小的通信单位,来自不同数据流的帧可以交错发送,然后再根据每个帧头的数据流标识符重新组装。
|
||||
* 一个数据流(Stream)都有一个唯一标识符和可选的优先级信息,用于承载双向信息。
|
||||
* 消息(Message)是与逻辑请求或响应对应的完整的一系列帧。
|
||||
* 帧(Frame)是最小的通信单位,来自不同数据流的帧可以交错发送,然后再根据每个帧头的数据流标识符重新组装。
|
||||
|
||||
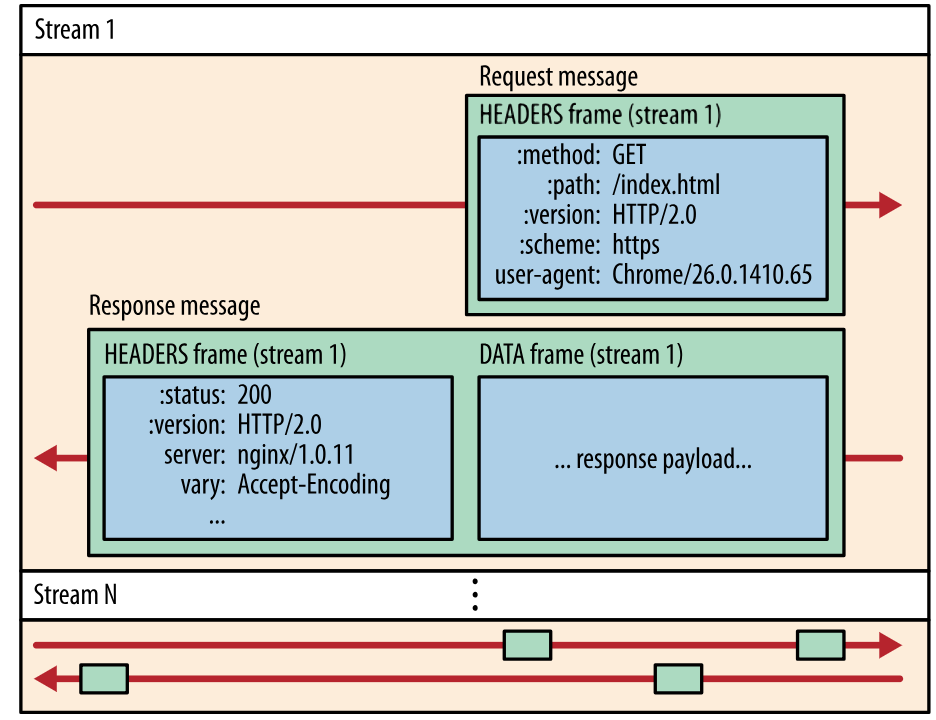\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/af198da1-2480-4043-b07f-a3b91a88b815.png" width="600"/> </div><br>
|
||||
|
||||
### 服务端推送
|
||||
|
||||
HTTP/2.0 在客户端请求一个资源时,会把相关的资源一起发送给客户端,客户端就不需要再次发起请求了。例如客户端请求 page.html 页面,服务端就把 script.js 和 style.css 等与之相关的资源一起发给客户端。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/e3f1657c-80fc-4dfa-9643-bf51abd201c6.png" width="800"/> </div><br>
|
||||
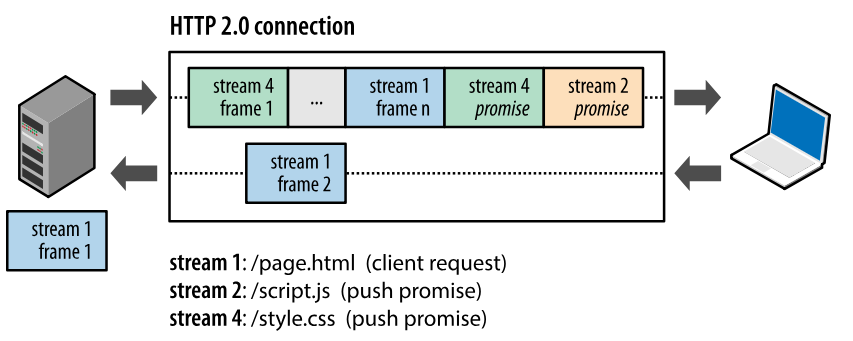\
|
||||
|
||||
|
||||
### 首部压缩
|
||||
|
||||
@ -816,19 +815,20 @@ HTTP/2.0 要求客户端和服务器同时维护和更新一个包含之前见
|
||||
|
||||
不仅如此,HTTP/2.0 也使用 Huffman 编码对首部字段进行压缩。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/_u4E0B_u8F7D.png" width="600"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 八、HTTP/1.1 新特性
|
||||
|
||||
详细内容请见上文
|
||||
|
||||
- 默认是长连接
|
||||
- 支持流水线
|
||||
- 支持同时打开多个 TCP 连接
|
||||
- 支持虚拟主机
|
||||
- 新增状态码 100
|
||||
- 支持分块传输编码
|
||||
- 新增缓存处理指令 max-age
|
||||
* 默认是长连接
|
||||
* 支持流水线
|
||||
* 支持同时打开多个 TCP 连接
|
||||
* 支持虚拟主机
|
||||
* 新增状态码 100
|
||||
* 支持分块传输编码
|
||||
* 新增缓存处理指令 max-age
|
||||
|
||||
## 九、GET 和 POST 比较
|
||||
|
||||
@ -879,7 +879,7 @@ GET /pageX HTTP/1.1
|
||||
GET /pageX HTTP/1.1
|
||||
```
|
||||
|
||||
POST /add_row HTTP/1.1 不是幂等的,如果调用多次,就会增加多行记录:
|
||||
POST /add\_row HTTP/1.1 不是幂等的,如果调用多次,就会增加多行记录:
|
||||
|
||||
```
|
||||
POST /add_row HTTP/1.1 -> Adds a 1nd row
|
||||
@ -899,9 +899,9 @@ DELETE /idX/delete HTTP/1.1 -> Returns 404
|
||||
|
||||
如果要对响应进行缓存,需要满足以下条件:
|
||||
|
||||
- 请求报文的 HTTP 方法本身是可缓存的,包括 GET 和 HEAD,但是 PUT 和 DELETE 不可缓存,POST 在多数情况下不可缓存的。
|
||||
- 响应报文的状态码是可缓存的,包括:200, 203, 204, 206, 300, 301, 404, 405, 410, 414, and 501。
|
||||
- 响应报文的 Cache-Control 首部字段没有指定不进行缓存。
|
||||
* 请求报文的 HTTP 方法本身是可缓存的,包括 GET 和 HEAD,但是 PUT 和 DELETE 不可缓存,POST 在多数情况下不可缓存的。
|
||||
* 响应报文的状态码是可缓存的,包括:200, 203, 204, 206, 300, 301, 404, 405, 410, 414, and 501。
|
||||
* 响应报文的 Cache-Control 首部字段没有指定不进行缓存。
|
||||
|
||||
### XMLHttpRequest
|
||||
|
||||
@ -909,35 +909,35 @@ DELETE /idX/delete HTTP/1.1 -> Returns 404
|
||||
|
||||
> XMLHttpRequest 是一个 API,它为客户端提供了在客户端和服务器之间传输数据的功能。它提供了一个通过 URL 来获取数据的简单方式,并且不会使整个页面刷新。这使得网页只更新一部分页面而不会打扰到用户。XMLHttpRequest 在 AJAX 中被大量使用。
|
||||
|
||||
- 在使用 XMLHttpRequest 的 POST 方法时,浏览器会先发送 Header 再发送 Data。但并不是所有浏览器会这么做,例如火狐就不会。
|
||||
- 而 GET 方法 Header 和 Data 会一起发送。
|
||||
* 在使用 XMLHttpRequest 的 POST 方法时,浏览器会先发送 Header 再发送 Data。但并不是所有浏览器会这么做,例如火狐就不会。
|
||||
* 而 GET 方法 Header 和 Data 会一起发送。
|
||||
|
||||
## 参考资料
|
||||
|
||||
- 上野宣. 图解 HTTP[M]. 人民邮电出版社, 2014.
|
||||
- [MDN : HTTP](https://developer.mozilla.org/en-US/docs/Web/HTTP)
|
||||
- [HTTP/2 简介](https://developers.google.com/web/fundamentals/performance/http2/?hl=zh-cn)
|
||||
- [htmlspecialchars](http://php.net/manual/zh/function.htmlspecialchars.php)
|
||||
- [Difference between file URI and URL in java](http://java2db.com/java-io/how-to-get-and-the-difference-between-file-uri-and-url-in-java)
|
||||
- [How to Fix SQL Injection Using Java PreparedStatement & CallableStatement](https://software-security.sans.org/developer-how-to/fix-sql-injection-in-java-using-prepared-callable-statement)
|
||||
- [浅谈 HTTP 中 Get 与 Post 的区别](https://www.cnblogs.com/hyddd/archive/2009/03/31/1426026.html)
|
||||
- [Are http:// and www really necessary?](https://www.webdancers.com/are-http-and-www-necesary/)
|
||||
- [HTTP (HyperText Transfer Protocol)](https://www.ntu.edu.sg/home/ehchua/programming/webprogramming/HTTP_Basics.html)
|
||||
- [Web-VPN: Secure Proxies with SPDY & Chrome](https://www.igvita.com/2011/12/01/web-vpn-secure-proxies-with-spdy-chrome/)
|
||||
- [File:HTTP persistent connection.svg](http://en.wikipedia.org/wiki/File:HTTP_persistent_connection.svg)
|
||||
- [Proxy server](https://en.wikipedia.org/wiki/Proxy_server)
|
||||
- [What Is This HTTPS/SSL Thing And Why Should You Care?](https://www.x-cart.com/blog/what-is-https-and-ssl.html)
|
||||
- [What is SSL Offloading?](https://securebox.comodo.com/ssl-sniffing/ssl-offloading/)
|
||||
- [Sun Directory Server Enterprise Edition 7.0 Reference - Key Encryption](https://docs.oracle.com/cd/E19424-01/820-4811/6ng8i26bn/index.html)
|
||||
- [An Introduction to Mutual SSL Authentication](https://www.codeproject.com/Articles/326574/An-Introduction-to-Mutual-SSL-Authentication)
|
||||
- [The Difference Between URLs and URIs](https://danielmiessler.com/study/url-uri/)
|
||||
- [Cookie 与 Session 的区别](https://juejin.im/entry/5766c29d6be3ff006a31b84e#comment)
|
||||
- [COOKIE 和 SESSION 有什么区别](https://www.zhihu.com/question/19786827)
|
||||
- [Cookie/Session 的机制与安全](https://harttle.land/2015/08/10/cookie-session.html)
|
||||
- [HTTPS 证书原理](https://shijianan.com/2017/06/11/https/)
|
||||
- [What is the difference between a URI, a URL and a URN?](https://stackoverflow.com/questions/176264/what-is-the-difference-between-a-uri-a-url-and-a-urn)
|
||||
- [XMLHttpRequest](https://developer.mozilla.org/zh-CN/docs/Web/API/XMLHttpRequest)
|
||||
- [XMLHttpRequest (XHR) Uses Multiple Packets for HTTP POST?](https://blog.josephscott.org/2009/08/27/xmlhttprequest-xhr-uses-multiple-packets-for-http-post/)
|
||||
- [Symmetric vs. Asymmetric Encryption – What are differences?](https://www.ssl2buy.com/wiki/symmetric-vs-asymmetric-encryption-what-are-differences)
|
||||
- [Web 性能优化与 HTTP/2](https://www.kancloud.cn/digest/web-performance-http2)
|
||||
- [HTTP/2 简介](https://developers.google.com/web/fundamentals/performance/http2/?hl=zh-cn)
|
||||
* 上野宣. 图解 HTTP\[M]. 人民邮电出版社, 2014.
|
||||
* [MDN : HTTP](https://developer.mozilla.org/en-US/docs/Web/HTTP)
|
||||
* [HTTP/2 简介](https://developers.google.com/web/fundamentals/performance/http2/?hl=zh-cn)
|
||||
* [htmlspecialchars](http://php.net/manual/zh/function.htmlspecialchars.php)
|
||||
* [Difference between file URI and URL in java](http://java2db.com/java-io/how-to-get-and-the-difference-between-file-uri-and-url-in-java)
|
||||
* [How to Fix SQL Injection Using Java PreparedStatement & CallableStatement](https://software-security.sans.org/developer-how-to/fix-sql-injection-in-java-using-prepared-callable-statement)
|
||||
* [浅谈 HTTP 中 Get 与 Post 的区别](https://www.cnblogs.com/hyddd/archive/2009/03/31/1426026.html)
|
||||
* [Are http:// and www really necessary?](https://www.webdancers.com/are-http-and-www-necesary/)
|
||||
* [HTTP (HyperText Transfer Protocol)](https://www.ntu.edu.sg/home/ehchua/programming/webprogramming/HTTP\_Basics.html)
|
||||
* [Web-VPN: Secure Proxies with SPDY & Chrome](https://www.igvita.com/2011/12/01/web-vpn-secure-proxies-with-spdy-chrome/)
|
||||
* [File:HTTP persistent connection.svg](http://en.wikipedia.org/wiki/File:HTTP\_persistent\_connection.svg)
|
||||
* [Proxy server](https://en.wikipedia.org/wiki/Proxy\_server)
|
||||
* [What Is This HTTPS/SSL Thing And Why Should You Care?](https://www.x-cart.com/blog/what-is-https-and-ssl.html)
|
||||
* [What is SSL Offloading?](https://securebox.comodo.com/ssl-sniffing/ssl-offloading/)
|
||||
* [Sun Directory Server Enterprise Edition 7.0 Reference - Key Encryption](https://docs.oracle.com/cd/E19424-01/820-4811/6ng8i26bn/index.html)
|
||||
* [An Introduction to Mutual SSL Authentication](https://www.codeproject.com/Articles/326574/An-Introduction-to-Mutual-SSL-Authentication)
|
||||
* [The Difference Between URLs and URIs](https://danielmiessler.com/study/url-uri/)
|
||||
* [Cookie 与 Session 的区别](https://juejin.im/entry/5766c29d6be3ff006a31b84e#comment)
|
||||
* [COOKIE 和 SESSION 有什么区别](https://www.zhihu.com/question/19786827)
|
||||
* [Cookie/Session 的机制与安全](https://harttle.land/2015/08/10/cookie-session.html)
|
||||
* [HTTPS 证书原理](https://shijianan.com/2017/06/11/https/)
|
||||
* [What is the difference between a URI, a URL and a URN?](https://stackoverflow.com/questions/176264/what-is-the-difference-between-a-uri-a-url-and-a-urn)
|
||||
* [XMLHttpRequest](https://developer.mozilla.org/zh-CN/docs/Web/API/XMLHttpRequest)
|
||||
* [XMLHttpRequest (XHR) Uses Multiple Packets for HTTP POST?](https://blog.josephscott.org/2009/08/27/xmlhttprequest-xhr-uses-multiple-packets-for-http-post/)
|
||||
* [Symmetric vs. Asymmetric Encryption – What are differences?](https://www.ssl2buy.com/wiki/symmetric-vs-asymmetric-encryption-what-are-differences)
|
||||
* [Web 性能优化与 HTTP/2](https://www.kancloud.cn/digest/web-performance-http2)
|
||||
* [HTTP/2 简介](https://developers.google.com/web/fundamentals/performance/http2/?hl=zh-cn)
|
||||
|
||||
198
notes/Java IO.md
198
notes/Java IO.md
@ -1,48 +1,46 @@
|
||||
# Java IO
|
||||
<!-- GFM-TOC -->
|
||||
* [Java IO](#java-io)
|
||||
* [一、概览](#一概览)
|
||||
* [二、磁盘操作](#二磁盘操作)
|
||||
* [三、字节操作](#三字节操作)
|
||||
* [实现文件复制](#实现文件复制)
|
||||
* [装饰者模式](#装饰者模式)
|
||||
* [四、字符操作](#四字符操作)
|
||||
* [编码与解码](#编码与解码)
|
||||
* [String 的编码方式](#string-的编码方式)
|
||||
* [Reader 与 Writer](#reader-与-writer)
|
||||
* [实现逐行输出文本文件的内容](#实现逐行输出文本文件的内容)
|
||||
* [五、对象操作](#五对象操作)
|
||||
* [序列化](#序列化)
|
||||
* [Serializable](#serializable)
|
||||
* [transient](#transient)
|
||||
* [六、网络操作](#六网络操作)
|
||||
* [InetAddress](#inetaddress)
|
||||
* [URL](#url)
|
||||
* [Sockets](#sockets)
|
||||
* [Datagram](#datagram)
|
||||
* [七、NIO](#七nio)
|
||||
* [流与块](#流与块)
|
||||
* [通道与缓冲区](#通道与缓冲区)
|
||||
* [缓冲区状态变量](#缓冲区状态变量)
|
||||
* [文件 NIO 实例](#文件-nio-实例)
|
||||
* [选择器](#选择器)
|
||||
* [套接字 NIO 实例](#套接字-nio-实例)
|
||||
* [内存映射文件](#内存映射文件)
|
||||
* [对比](#对比)
|
||||
* [八、参考资料](#八参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [Java IO](<Java IO.md#java-io>)
|
||||
* [一、概览](<Java IO.md#一概览>)
|
||||
* [二、磁盘操作](<Java IO.md#二磁盘操作>)
|
||||
* [三、字节操作](<Java IO.md#三字节操作>)
|
||||
* [实现文件复制](<Java IO.md#实现文件复制>)
|
||||
* [装饰者模式](<Java IO.md#装饰者模式>)
|
||||
* [四、字符操作](<Java IO.md#四字符操作>)
|
||||
* [编码与解码](<Java IO.md#编码与解码>)
|
||||
* [String 的编码方式](<Java IO.md#string-的编码方式>)
|
||||
* [Reader 与 Writer](<Java IO.md#reader-与-writer>)
|
||||
* [实现逐行输出文本文件的内容](<Java IO.md#实现逐行输出文本文件的内容>)
|
||||
* [五、对象操作](<Java IO.md#五对象操作>)
|
||||
* [序列化](<Java IO.md#序列化>)
|
||||
* [Serializable](<Java IO.md#serializable>)
|
||||
* [transient](<Java IO.md#transient>)
|
||||
* [六、网络操作](<Java IO.md#六网络操作>)
|
||||
* [InetAddress](<Java IO.md#inetaddress>)
|
||||
* [URL](<Java IO.md#url>)
|
||||
* [Sockets](<Java IO.md#sockets>)
|
||||
* [Datagram](<Java IO.md#datagram>)
|
||||
* [七、NIO](<Java IO.md#七nio>)
|
||||
* [流与块](<Java IO.md#流与块>)
|
||||
* [通道与缓冲区](<Java IO.md#通道与缓冲区>)
|
||||
* [缓冲区状态变量](<Java IO.md#缓冲区状态变量>)
|
||||
* [文件 NIO 实例](<Java IO.md#文件-nio-实例>)
|
||||
* [选择器](<Java IO.md#选择器>)
|
||||
* [套接字 NIO 实例](<Java IO.md#套接字-nio-实例>)
|
||||
* [内存映射文件](<Java IO.md#内存映射文件>)
|
||||
* [对比](<Java IO.md#对比>)
|
||||
* [八、参考资料](<Java IO.md#八参考资料>)
|
||||
|
||||
## 一、概览
|
||||
|
||||
Java 的 I/O 大概可以分成以下几类:
|
||||
|
||||
- 磁盘操作:File
|
||||
- 字节操作:InputStream 和 OutputStream
|
||||
- 字符操作:Reader 和 Writer
|
||||
- 对象操作:Serializable
|
||||
- 网络操作:Socket
|
||||
- 新的输入/输出:NIO
|
||||
* 磁盘操作:File
|
||||
* 字节操作:InputStream 和 OutputStream
|
||||
* 字符操作:Reader 和 Writer
|
||||
* 对象操作:Serializable
|
||||
* 网络操作:Socket
|
||||
* 新的输入/输出:NIO
|
||||
|
||||
## 二、磁盘操作
|
||||
|
||||
@ -95,11 +93,12 @@ public static void copyFile(String src, String dist) throws IOException {
|
||||
|
||||
Java I/O 使用了装饰者模式来实现。以 InputStream 为例,
|
||||
|
||||
- InputStream 是抽象组件;
|
||||
- FileInputStream 是 InputStream 的子类,属于具体组件,提供了字节流的输入操作;
|
||||
- FilterInputStream 属于抽象装饰者,装饰者用于装饰组件,为组件提供额外的功能。例如 BufferedInputStream 为 FileInputStream 提供缓存的功能。
|
||||
* InputStream 是抽象组件;
|
||||
* FileInputStream 是 InputStream 的子类,属于具体组件,提供了字节流的输入操作;
|
||||
* FilterInputStream 属于抽象装饰者,装饰者用于装饰组件,为组件提供额外的功能。例如 BufferedInputStream 为 FileInputStream 提供缓存的功能。
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/9709694b-db05-4cce-8d2f-1c8b09f4d921.png" width="650px"> </div><br>
|
||||
|
||||
实例化一个具有缓存功能的字节流对象时,只需要在 FileInputStream 对象上再套一层 BufferedInputStream 对象即可。
|
||||
|
||||
@ -118,9 +117,9 @@ DataInputStream 装饰者提供了对更多数据类型进行输入的操作,
|
||||
|
||||
如果编码和解码过程使用不同的编码方式那么就出现了乱码。
|
||||
|
||||
- GBK 编码中,中文字符占 2 个字节,英文字符占 1 个字节;
|
||||
- UTF-8 编码中,中文字符占 3 个字节,英文字符占 1 个字节;
|
||||
- UTF-16be 编码中,中文字符和英文字符都占 2 个字节。
|
||||
* GBK 编码中,中文字符占 2 个字节,英文字符占 1 个字节;
|
||||
* UTF-8 编码中,中文字符占 3 个字节,英文字符占 1 个字节;
|
||||
* UTF-16be 编码中,中文字符和英文字符都占 2 个字节。
|
||||
|
||||
UTF-16be 中的 be 指的是 Big Endian,也就是大端。相应地也有 UTF-16le,le 指的是 Little Endian,也就是小端。
|
||||
|
||||
@ -137,7 +136,7 @@ String str2 = new String(bytes, "UTF-8");
|
||||
System.out.println(str2);
|
||||
```
|
||||
|
||||
在调用无参数 getBytes() 方法时,默认的编码方式不是 UTF-16be。双字节编码的好处是可以使用一个 char 存储中文和英文,而将 String 转为 bytes[] 字节数组就不再需要这个好处,因此也就不再需要双字节编码。getBytes() 的默认编码方式与平台有关,一般为 UTF-8。
|
||||
在调用无参数 getBytes() 方法时,默认的编码方式不是 UTF-16be。双字节编码的好处是可以使用一个 char 存储中文和英文,而将 String 转为 bytes\[] 字节数组就不再需要这个好处,因此也就不再需要双字节编码。getBytes() 的默认编码方式与平台有关,一般为 UTF-8。
|
||||
|
||||
```java
|
||||
byte[] bytes = str1.getBytes();
|
||||
@ -147,8 +146,8 @@ byte[] bytes = str1.getBytes();
|
||||
|
||||
不管是磁盘还是网络传输,最小的存储单元都是字节,而不是字符。但是在程序中操作的通常是字符形式的数据,因此需要提供对字符进行操作的方法。
|
||||
|
||||
- InputStreamReader 实现从字节流解码成字符流;
|
||||
- OutputStreamWriter 实现字符流编码成为字节流。
|
||||
* InputStreamReader 实现从字节流解码成字符流;
|
||||
* OutputStreamWriter 实现字符流编码成为字节流。
|
||||
|
||||
### 实现逐行输出文本文件的内容
|
||||
|
||||
@ -176,8 +175,8 @@ public static void readFileContent(String filePath) throws IOException {
|
||||
|
||||
序列化就是将一个对象转换成字节序列,方便存储和传输。
|
||||
|
||||
- 序列化:ObjectOutputStream.writeObject()
|
||||
- 反序列化:ObjectInputStream.readObject()
|
||||
* 序列化:ObjectOutputStream.writeObject()
|
||||
* 反序列化:ObjectInputStream.readObject()
|
||||
|
||||
不会对静态变量进行序列化,因为序列化只是保存对象的状态,静态变量属于类的状态。
|
||||
|
||||
@ -232,10 +231,10 @@ private transient Object[] elementData;
|
||||
|
||||
Java 中的网络支持:
|
||||
|
||||
- InetAddress:用于表示网络上的硬件资源,即 IP 地址;
|
||||
- URL:统一资源定位符;
|
||||
- Sockets:使用 TCP 协议实现网络通信;
|
||||
- Datagram:使用 UDP 协议实现网络通信。
|
||||
* InetAddress:用于表示网络上的硬件资源,即 IP 地址;
|
||||
* URL:统一资源定位符;
|
||||
* Sockets:使用 TCP 协议实现网络通信;
|
||||
* Datagram:使用 UDP 协议实现网络通信。
|
||||
|
||||
### InetAddress
|
||||
|
||||
@ -275,16 +274,17 @@ public static void main(String[] args) throws IOException {
|
||||
|
||||
### Sockets
|
||||
|
||||
- ServerSocket:服务器端类
|
||||
- Socket:客户端类
|
||||
- 服务器和客户端通过 InputStream 和 OutputStream 进行输入输出。
|
||||
* ServerSocket:服务器端类
|
||||
* Socket:客户端类
|
||||
* 服务器和客户端通过 InputStream 和 OutputStream 进行输入输出。
|
||||
|
||||
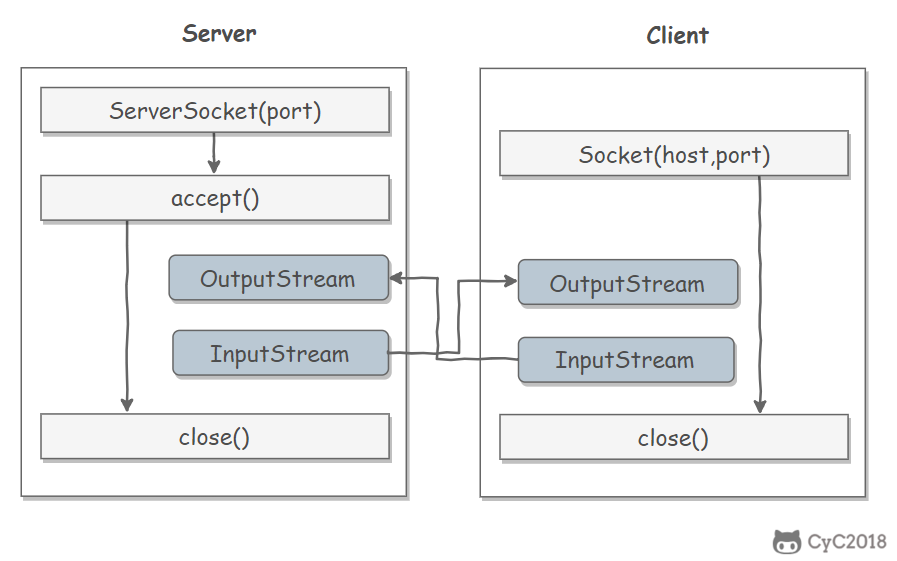\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/1e6affc4-18e5-4596-96ef-fb84c63bf88a.png" width="550px"> </div><br>
|
||||
|
||||
### Datagram
|
||||
|
||||
- DatagramSocket:通信类
|
||||
- DatagramPacket:数据包类
|
||||
* DatagramSocket:通信类
|
||||
* DatagramPacket:数据包类
|
||||
|
||||
## 七、NIO
|
||||
|
||||
@ -310,10 +310,10 @@ I/O 包和 NIO 已经很好地集成了,java.io.\* 已经以 NIO 为基础重
|
||||
|
||||
通道包括以下类型:
|
||||
|
||||
- FileChannel:从文件中读写数据;
|
||||
- DatagramChannel:通过 UDP 读写网络中数据;
|
||||
- SocketChannel:通过 TCP 读写网络中数据;
|
||||
- ServerSocketChannel:可以监听新进来的 TCP 连接,对每一个新进来的连接都会创建一个 SocketChannel。
|
||||
* FileChannel:从文件中读写数据;
|
||||
* DatagramChannel:通过 UDP 读写网络中数据;
|
||||
* SocketChannel:通过 TCP 读写网络中数据;
|
||||
* ServerSocketChannel:可以监听新进来的 TCP 连接,对每一个新进来的连接都会创建一个 SocketChannel。
|
||||
|
||||
#### 2. 缓冲区
|
||||
|
||||
@ -323,41 +323,46 @@ I/O 包和 NIO 已经很好地集成了,java.io.\* 已经以 NIO 为基础重
|
||||
|
||||
缓冲区包括以下类型:
|
||||
|
||||
- ByteBuffer
|
||||
- CharBuffer
|
||||
- ShortBuffer
|
||||
- IntBuffer
|
||||
- LongBuffer
|
||||
- FloatBuffer
|
||||
- DoubleBuffer
|
||||
* ByteBuffer
|
||||
* CharBuffer
|
||||
* ShortBuffer
|
||||
* IntBuffer
|
||||
* LongBuffer
|
||||
* FloatBuffer
|
||||
* DoubleBuffer
|
||||
|
||||
### 缓冲区状态变量
|
||||
|
||||
- capacity:最大容量;
|
||||
- position:当前已经读写的字节数;
|
||||
- limit:还可以读写的字节数。
|
||||
* capacity:最大容量;
|
||||
* position:当前已经读写的字节数;
|
||||
* limit:还可以读写的字节数。
|
||||
|
||||
状态变量的改变过程举例:
|
||||
|
||||
① 新建一个大小为 8 个字节的缓冲区,此时 position 为 0,而 limit = capacity = 8。capacity 变量不会改变,下面的讨论会忽略它。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/1bea398f-17a7-4f67-a90b-9e2d243eaa9a.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
② 从输入通道中读取 5 个字节数据写入缓冲区中,此时 position 为 5,limit 保持不变。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/80804f52-8815-4096-b506-48eef3eed5c6.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
③ 在将缓冲区的数据写到输出通道之前,需要先调用 flip() 方法,这个方法将 limit 设置为当前 position,并将 position 设置为 0。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/952e06bd-5a65-4cab-82e4-dd1536462f38.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
④ 从缓冲区中取 4 个字节到输出缓冲中,此时 position 设为 4。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/b5bdcbe2-b958-4aef-9151-6ad963cb28b4.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
⑤ 最后需要调用 clear() 方法来清空缓冲区,此时 position 和 limit 都被设置为最初位置。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/67bf5487-c45d-49b6-b9c0-a058d8c68902.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### 文件 NIO 实例
|
||||
|
||||
@ -415,7 +420,8 @@ NIO 实现了 IO 多路复用中的 Reactor 模型,一个线程 Thread 使用
|
||||
|
||||
应该注意的是,只有套接字 Channel 才能配置为非阻塞,而 FileChannel 不能,为 FileChannel 配置非阻塞也没有意义。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/093f9e57-429c-413a-83ee-c689ba596cef.png" width="350px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
#### 1. 创建选择器
|
||||
|
||||
@ -435,10 +441,10 @@ ssChannel.register(selector, SelectionKey.OP_ACCEPT);
|
||||
|
||||
在将通道注册到选择器上时,还需要指定要注册的具体事件,主要有以下几类:
|
||||
|
||||
- SelectionKey.OP_CONNECT
|
||||
- SelectionKey.OP_ACCEPT
|
||||
- SelectionKey.OP_READ
|
||||
- SelectionKey.OP_WRITE
|
||||
* SelectionKey.OP\_CONNECT
|
||||
* SelectionKey.OP\_ACCEPT
|
||||
* SelectionKey.OP\_READ
|
||||
* SelectionKey.OP\_WRITE
|
||||
|
||||
它们在 SelectionKey 的定义如下:
|
||||
|
||||
@ -605,18 +611,18 @@ MappedByteBuffer mbb = fc.map(FileChannel.MapMode.READ_WRITE, 0, 1024);
|
||||
|
||||
NIO 与普通 I/O 的区别主要有以下两点:
|
||||
|
||||
- NIO 是非阻塞的;
|
||||
- NIO 面向块,I/O 面向流。
|
||||
* NIO 是非阻塞的;
|
||||
* NIO 面向块,I/O 面向流。
|
||||
|
||||
## 八、参考资料
|
||||
|
||||
- Eckel B, 埃克尔, 昊鹏, 等. Java 编程思想 [M]. 机械工业出版社, 2002.
|
||||
- [IBM: NIO 入门](https://www.ibm.com/developerworks/cn/education/java/j-nio/j-nio.html)
|
||||
- [Java NIO Tutorial](http://tutorials.jenkov.com/java-nio/index.html)
|
||||
- [Java NIO 浅析](https://tech.meituan.com/nio.html)
|
||||
- [IBM: 深入分析 Java I/O 的工作机制](https://www.ibm.com/developerworks/cn/java/j-lo-javaio/index.html)
|
||||
- [IBM: 深入分析 Java 中的中文编码问题](https://www.ibm.com/developerworks/cn/java/j-lo-chinesecoding/index.html)
|
||||
- [IBM: Java 序列化的高级认识](https://www.ibm.com/developerworks/cn/java/j-lo-serial/index.html)
|
||||
- [NIO 与传统 IO 的区别](http://blog.csdn.net/shimiso/article/details/24990499)
|
||||
- [Decorator Design Pattern](http://stg-tud.github.io/sedc/Lecture/ws13-14/5.3-Decorator.html#mode=document)
|
||||
- [Socket Multicast](http://labojava.blogspot.com/2012/12/socket-multicast.html)
|
||||
* Eckel B, 埃克尔, 昊鹏, 等. Java 编程思想 \[M]. 机械工业出版社, 2002.
|
||||
* [IBM: NIO 入门](https://www.ibm.com/developerworks/cn/education/java/j-nio/j-nio.html)
|
||||
* [Java NIO Tutorial](http://tutorials.jenkov.com/java-nio/index.html)
|
||||
* [Java NIO 浅析](https://tech.meituan.com/nio.html)
|
||||
* [IBM: 深入分析 Java I/O 的工作机制](https://www.ibm.com/developerworks/cn/java/j-lo-javaio/index.html)
|
||||
* [IBM: 深入分析 Java 中的中文编码问题](https://www.ibm.com/developerworks/cn/java/j-lo-chinesecoding/index.html)
|
||||
* [IBM: Java 序列化的高级认识](https://www.ibm.com/developerworks/cn/java/j-lo-serial/index.html)
|
||||
* [NIO 与传统 IO 的区别](http://blog.csdn.net/shimiso/article/details/24990499)
|
||||
* [Decorator Design Pattern](http://stg-tud.github.io/sedc/Lecture/ws13-14/5.3-Decorator.html#mode=document)
|
||||
* [Socket Multicast](http://labojava.blogspot.com/2012/12/socket-multicast.html)
|
||||
|
||||
373
notes/Java 基础.md
373
notes/Java 基础.md
@ -1,64 +1,62 @@
|
||||
# Java 基础
|
||||
<!-- GFM-TOC -->
|
||||
* [Java 基础](#java-基础)
|
||||
* [一、数据类型](#一数据类型)
|
||||
* [基本类型](#基本类型)
|
||||
* [包装类型](#包装类型)
|
||||
* [缓存池](#缓存池)
|
||||
* [二、String](#二string)
|
||||
* [概览](#概览)
|
||||
* [不可变的好处](#不可变的好处)
|
||||
* [String, StringBuffer and StringBuilder ](#string-stringbuffer-and-stringbuilder )
|
||||
* [String Pool](#string-pool)
|
||||
* [new String("abc")](#new-stringabc)
|
||||
* [三、运算](#三运算)
|
||||
* [参数传递](#参数传递)
|
||||
* [float 与 double](#float-与-double)
|
||||
* [隐式类型转换](#隐式类型转换)
|
||||
* [switch](#switch)
|
||||
* [四、关键字](#四关键字)
|
||||
* [final](#final)
|
||||
* [static](#static)
|
||||
* [五、Object 通用方法](#五object-通用方法)
|
||||
* [概览](#概览)
|
||||
* [equals()](#equals)
|
||||
* [hashCode()](#hashcode)
|
||||
* [toString()](#tostring)
|
||||
* [clone()](#clone)
|
||||
* [六、继承](#六继承)
|
||||
* [访问权限](#访问权限)
|
||||
* [抽象类与接口](#抽象类与接口)
|
||||
* [super](#super)
|
||||
* [重写与重载](#重写与重载)
|
||||
* [七、反射](#七反射)
|
||||
* [八、异常](#八异常)
|
||||
* [九、泛型](#九泛型)
|
||||
* [十、注解](#十注解)
|
||||
* [十一、特性](#十一特性)
|
||||
* [Java 各版本的新特性](#java-各版本的新特性)
|
||||
* [Java 与 C++ 的区别](#java-与-c-的区别)
|
||||
* [JRE or JDK](#jre-or-jdk)
|
||||
* [参考资料](#参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [Java 基础](<Java 基础.md#java-基础>)
|
||||
* [一、数据类型](<Java 基础.md#一数据类型>)
|
||||
* [基本类型](<Java 基础.md#基本类型>)
|
||||
* [包装类型](<Java 基础.md#包装类型>)
|
||||
* [缓存池](<Java 基础.md#缓存池>)
|
||||
* [二、String](<Java 基础.md#二string>)
|
||||
* [概览](<Java 基础.md#概览>)
|
||||
* [不可变的好处](<Java 基础.md#不可变的好处>)
|
||||
* [String, StringBuffer and StringBuilder](<Java 基础.md#string-stringbuffer-and-stringbuilder>)
|
||||
* [String Pool](<Java 基础.md#string-pool>)
|
||||
* [new String("abc")](<Java 基础.md#new-stringabc>)
|
||||
* [三、运算](<Java 基础.md#三运算>)
|
||||
* [参数传递](<Java 基础.md#参数传递>)
|
||||
* [float 与 double](<Java 基础.md#float-与-double>)
|
||||
* [隐式类型转换](<Java 基础.md#隐式类型转换>)
|
||||
* [switch](<Java 基础.md#switch>)
|
||||
* [四、关键字](<Java 基础.md#四关键字>)
|
||||
* [final](<Java 基础.md#final>)
|
||||
* [static](<Java 基础.md#static>)
|
||||
* [五、Object 通用方法](<Java 基础.md#五object-通用方法>)
|
||||
* [概览](<Java 基础.md#概览>)
|
||||
* [equals()](<Java 基础.md#equals>)
|
||||
* [hashCode()](<Java 基础.md#hashcode>)
|
||||
* [toString()](<Java 基础.md#tostring>)
|
||||
* [clone()](<Java 基础.md#clone>)
|
||||
* [六、继承](<Java 基础.md#六继承>)
|
||||
* [访问权限](<Java 基础.md#访问权限>)
|
||||
* [抽象类与接口](<Java 基础.md#抽象类与接口>)
|
||||
* [super](<Java 基础.md#super>)
|
||||
* [重写与重载](<Java 基础.md#重写与重载>)
|
||||
* [七、反射](<Java 基础.md#七反射>)
|
||||
* [八、异常](<Java 基础.md#八异常>)
|
||||
* [九、泛型](<Java 基础.md#九泛型>)
|
||||
* [十、注解](<Java 基础.md#十注解>)
|
||||
* [十一、特性](<Java 基础.md#十一特性>)
|
||||
* [Java 各版本的新特性](<Java 基础.md#java-各版本的新特性>)
|
||||
* [Java 与 C++ 的区别](<Java 基础.md#java-与-c-的区别>)
|
||||
* [JRE or JDK](<Java 基础.md#jre-or-jdk>)
|
||||
* [参考资料](<Java 基础.md#参考资料>)
|
||||
|
||||
## 一、数据类型
|
||||
|
||||
### 基本类型
|
||||
|
||||
- byte/8
|
||||
- char/16
|
||||
- short/16
|
||||
- int/32
|
||||
- float/32
|
||||
- long/64
|
||||
- double/64
|
||||
- boolean/\~
|
||||
* byte/8
|
||||
* char/16
|
||||
* short/16
|
||||
* int/32
|
||||
* float/32
|
||||
* long/64
|
||||
* double/64
|
||||
* boolean/\~
|
||||
|
||||
boolean 只有两个值:true、false,可以使用 1 bit 来存储,但是具体大小没有明确规定。JVM 会在编译时期将 boolean 类型的数据转换为 int,使用 1 来表示 true,0 表示 false。JVM 支持 boolean 数组,但是是通过读写 byte 数组来实现的。
|
||||
|
||||
- [Primitive Data Types](https://docs.oracle.com/javase/tutorial/java/nutsandbolts/datatypes.html)
|
||||
- [The Java® Virtual Machine Specification](https://docs.oracle.com/javase/specs/jvms/se8/jvms8.pdf)
|
||||
* [Primitive Data Types](https://docs.oracle.com/javase/tutorial/java/nutsandbolts/datatypes.html)
|
||||
* [The Java® Virtual Machine Specification](https://docs.oracle.com/javase/specs/jvms/se8/jvms8.pdf)
|
||||
|
||||
### 包装类型
|
||||
|
||||
@ -69,14 +67,14 @@ Integer x = 2; // 装箱 调用了 Integer.valueOf(2)
|
||||
int y = x; // 拆箱 调用了 X.intValue()
|
||||
```
|
||||
|
||||
- [Autoboxing and Unboxing](https://docs.oracle.com/javase/tutorial/java/data/autoboxing.html)
|
||||
* [Autoboxing and Unboxing](https://docs.oracle.com/javase/tutorial/java/data/autoboxing.html)
|
||||
|
||||
### 缓存池
|
||||
|
||||
new Integer(123) 与 Integer.valueOf(123) 的区别在于:
|
||||
|
||||
- new Integer(123) 每次都会新建一个对象;
|
||||
- Integer.valueOf(123) 会使用缓存池中的对象,多次调用会取得同一个对象的引用。
|
||||
* new Integer(123) 每次都会新建一个对象;
|
||||
* Integer.valueOf(123) 会使用缓存池中的对象,多次调用会取得同一个对象的引用。
|
||||
|
||||
```java
|
||||
Integer x = new Integer(123);
|
||||
@ -141,18 +139,17 @@ System.out.println(m == n); // true
|
||||
|
||||
基本类型对应的缓冲池如下:
|
||||
|
||||
- boolean values true and false
|
||||
- all byte values
|
||||
- short values between -128 and 127
|
||||
- int values between -128 and 127
|
||||
- char in the range \u0000 to \u007F
|
||||
* boolean values true and false
|
||||
* all byte values
|
||||
* short values between -128 and 127
|
||||
* int values between -128 and 127
|
||||
* char in the range \u0000 to \u007F
|
||||
|
||||
在使用这些基本类型对应的包装类型时,如果该数值范围在缓冲池范围内,就可以直接使用缓冲池中的对象。
|
||||
|
||||
在 jdk 1.8 所有的数值类缓冲池中,Integer 的缓冲池 IntegerCache 很特殊,这个缓冲池的下界是 - 128,上界默认是 127,但是这个上界是可调的,在启动 jvm 的时候,通过 -XX:AutoBoxCacheMax=<size> 来指定这个缓冲池的大小,该选项在 JVM 初始化的时候会设定一个名为 java.lang.IntegerCache.high 系统属性,然后 IntegerCache 初始化的时候就会读取该系统属性来决定上界。
|
||||
在 jdk 1.8 所有的数值类缓冲池中,Integer 的缓冲池 IntegerCache 很特殊,这个缓冲池的下界是 - 128,上界默认是 127,但是这个上界是可调的,在启动 jvm 的时候,通过 -XX:AutoBoxCacheMax=\<size> 来指定这个缓冲池的大小,该选项在 JVM 初始化的时候会设定一个名为 java.lang.IntegerCache.high 系统属性,然后 IntegerCache 初始化的时候就会读取该系统属性来决定上界。
|
||||
|
||||
[StackOverflow : Differences between new Integer(123), Integer.valueOf(123) and just 123
|
||||
](https://stackoverflow.com/questions/9030817/differences-between-new-integer123-integer-valueof123-and-just-123)
|
||||
[StackOverflow : Differences between new Integer(123), Integer.valueOf(123) and just 123](https://stackoverflow.com/questions/9030817/differences-between-new-integer123-integer-valueof123-and-just-123)
|
||||
|
||||
## 二、String
|
||||
|
||||
@ -187,38 +184,39 @@ value 数组被声明为 final,这意味着 value 数组初始化之后就不
|
||||
|
||||
### 不可变的好处
|
||||
|
||||
**1. 可以缓存 hash 值**
|
||||
**1. 可以缓存 hash 值**
|
||||
|
||||
因为 String 的 hash 值经常被使用,例如 String 用做 HashMap 的 key。不可变的特性可以使得 hash 值也不可变,因此只需要进行一次计算。
|
||||
|
||||
**2. String Pool 的需要**
|
||||
**2. String Pool 的需要**
|
||||
|
||||
如果一个 String 对象已经被创建过了,那么就会从 String Pool 中取得引用。只有 String 是不可变的,才可能使用 String Pool。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191210004132894.png"/> </div><br>
|
||||
\
|
||||
|
||||
**3. 安全性**
|
||||
|
||||
**3. 安全性**
|
||||
|
||||
String 经常作为参数,String 不可变性可以保证参数不可变。例如在作为网络连接参数的情况下如果 String 是可变的,那么在网络连接过程中,String 被改变,改变 String 的那一方以为现在连接的是其它主机,而实际情况却不一定是。
|
||||
|
||||
**4. 线程安全**
|
||||
**4. 线程安全**
|
||||
|
||||
String 不可变性天生具备线程安全,可以在多个线程中安全地使用。
|
||||
|
||||
[Program Creek : Why String is immutable in Java?](https://www.programcreek.com/2013/04/why-string-is-immutable-in-java/)
|
||||
|
||||
### String, StringBuffer and StringBuilder
|
||||
### String, StringBuffer and StringBuilder
|
||||
|
||||
**1. 可变性**
|
||||
**1. 可变性**
|
||||
|
||||
- String 不可变
|
||||
- StringBuffer 和 StringBuilder 可变
|
||||
* String 不可变
|
||||
* StringBuffer 和 StringBuilder 可变
|
||||
|
||||
**2. 线程安全**
|
||||
**2. 线程安全**
|
||||
|
||||
- String 不可变,因此是线程安全的
|
||||
- StringBuilder 不是线程安全的
|
||||
- StringBuffer 是线程安全的,内部使用 synchronized 进行同步
|
||||
* String 不可变,因此是线程安全的
|
||||
* StringBuilder 不是线程安全的
|
||||
* StringBuffer 是线程安全的,内部使用 synchronized 进行同步
|
||||
|
||||
[StackOverflow : String, StringBuffer, and StringBuilder](https://stackoverflow.com/questions/2971315/string-stringbuffer-and-stringbuilder)
|
||||
|
||||
@ -249,15 +247,15 @@ System.out.println(s5 == s6); // true
|
||||
|
||||
在 Java 7 之前,String Pool 被放在运行时常量池中,它属于永久代。而在 Java 7,String Pool 被移到堆中。这是因为永久代的空间有限,在大量使用字符串的场景下会导致 OutOfMemoryError 错误。
|
||||
|
||||
- [StackOverflow : What is String interning?](https://stackoverflow.com/questions/10578984/what-is-string-interning)
|
||||
- [深入解析 String#intern](https://tech.meituan.com/in_depth_understanding_string_intern.html)
|
||||
* [StackOverflow : What is String interning?](https://stackoverflow.com/questions/10578984/what-is-string-interning)
|
||||
* [深入解析 String#intern](https://tech.meituan.com/in\_depth\_understanding\_string\_intern.html)
|
||||
|
||||
### new String("abc")
|
||||
|
||||
使用这种方式一共会创建两个字符串对象(前提是 String Pool 中还没有 "abc" 字符串对象)。
|
||||
|
||||
- "abc" 属于字符串字面量,因此编译时期会在 String Pool 中创建一个字符串对象,指向这个 "abc" 字符串字面量;
|
||||
- 而使用 new 的方式会在堆中创建一个字符串对象。
|
||||
* "abc" 属于字符串字面量,因此编译时期会在 String Pool 中创建一个字符串对象,指向这个 "abc" 字符串字面量;
|
||||
* 而使用 new 的方式会在堆中创建一个字符串对象。
|
||||
|
||||
创建一个测试类,其 main 方法中使用这种方式来创建字符串对象。
|
||||
|
||||
@ -414,7 +412,7 @@ s1++;
|
||||
s1 = (short) (s1 + 1);
|
||||
```
|
||||
|
||||
[StackOverflow : Why don't Java's +=, -=, *=, /= compound assignment operators require casting?](https://stackoverflow.com/questions/8710619/why-dont-javas-compound-assignment-operators-require-casting)
|
||||
[StackOverflow : Why don't Java's +=, -=, \*=, /= compound assignment operators require casting?](https://stackoverflow.com/questions/8710619/why-dont-javas-compound-assignment-operators-require-casting)
|
||||
|
||||
### switch
|
||||
|
||||
@ -448,17 +446,16 @@ switch 不支持 long、float、double,是因为 switch 的设计初衷是对
|
||||
|
||||
[StackOverflow : Why can't your switch statement data type be long, Java?](https://stackoverflow.com/questions/2676210/why-cant-your-switch-statement-data-type-be-long-java)
|
||||
|
||||
|
||||
## 四、关键字
|
||||
|
||||
### final
|
||||
|
||||
**1. 数据**
|
||||
**1. 数据**
|
||||
|
||||
声明数据为常量,可以是编译时常量,也可以是在运行时被初始化后不能被改变的常量。
|
||||
|
||||
- 对于基本类型,final 使数值不变;
|
||||
- 对于引用类型,final 使引用不变,也就不能引用其它对象,但是被引用的对象本身是可以修改的。
|
||||
* 对于基本类型,final 使数值不变;
|
||||
* 对于引用类型,final 使引用不变,也就不能引用其它对象,但是被引用的对象本身是可以修改的。
|
||||
|
||||
```java
|
||||
final int x = 1;
|
||||
@ -467,22 +464,22 @@ final A y = new A();
|
||||
y.a = 1;
|
||||
```
|
||||
|
||||
**2. 方法**
|
||||
**2. 方法**
|
||||
|
||||
声明方法不能被子类重写。
|
||||
|
||||
private 方法隐式地被指定为 final,如果在子类中定义的方法和基类中的一个 private 方法签名相同,此时子类的方法不是重写基类方法,而是在子类中定义了一个新的方法。
|
||||
|
||||
**3. 类**
|
||||
**3. 类**
|
||||
|
||||
声明类不允许被继承。
|
||||
|
||||
### static
|
||||
|
||||
**1. 静态变量**
|
||||
**1. 静态变量**
|
||||
|
||||
- 静态变量:又称为类变量,也就是说这个变量属于类的,类所有的实例都共享静态变量,可以直接通过类名来访问它。静态变量在内存中只存在一份。
|
||||
- 实例变量:每创建一个实例就会产生一个实例变量,它与该实例同生共死。
|
||||
* 静态变量:又称为类变量,也就是说这个变量属于类的,类所有的实例都共享静态变量,可以直接通过类名来访问它。静态变量在内存中只存在一份。
|
||||
* 实例变量:每创建一个实例就会产生一个实例变量,它与该实例同生共死。
|
||||
|
||||
```java
|
||||
public class A {
|
||||
@ -499,7 +496,7 @@ public class A {
|
||||
}
|
||||
```
|
||||
|
||||
**2. 静态方法**
|
||||
**2. 静态方法**
|
||||
|
||||
静态方法在类加载的时候就存在了,它不依赖于任何实例。所以静态方法必须有实现,也就是说它不能是抽象方法。
|
||||
|
||||
@ -527,7 +524,7 @@ public class A {
|
||||
}
|
||||
```
|
||||
|
||||
**3. 静态语句块**
|
||||
**3. 静态语句块**
|
||||
|
||||
静态语句块在类初始化时运行一次。
|
||||
|
||||
@ -548,7 +545,7 @@ public class A {
|
||||
123
|
||||
```
|
||||
|
||||
**4. 静态内部类**
|
||||
**4. 静态内部类**
|
||||
|
||||
非静态内部类依赖于外部类的实例,也就是说需要先创建外部类实例,才能用这个实例去创建非静态内部类。而静态内部类不需要。
|
||||
|
||||
@ -572,7 +569,7 @@ public class OuterClass {
|
||||
|
||||
静态内部类不能访问外部类的非静态的变量和方法。
|
||||
|
||||
**5. 静态导包**
|
||||
**5. 静态导包**
|
||||
|
||||
在使用静态变量和方法时不用再指明 ClassName,从而简化代码,但可读性大大降低。
|
||||
|
||||
@ -580,7 +577,7 @@ public class OuterClass {
|
||||
import static com.xxx.ClassName.*
|
||||
```
|
||||
|
||||
**6. 初始化顺序**
|
||||
**6. 初始化顺序**
|
||||
|
||||
静态变量和静态语句块优先于实例变量和普通语句块,静态变量和静态语句块的初始化顺序取决于它们在代码中的顺序。
|
||||
|
||||
@ -614,19 +611,18 @@ public InitialOrderTest() {
|
||||
|
||||
存在继承的情况下,初始化顺序为:
|
||||
|
||||
- 父类(静态变量、静态语句块)
|
||||
- 子类(静态变量、静态语句块)
|
||||
- 父类(实例变量、普通语句块)
|
||||
- 父类(构造函数)
|
||||
- 子类(实例变量、普通语句块)
|
||||
- 子类(构造函数)
|
||||
* 父类(静态变量、静态语句块)
|
||||
* 子类(静态变量、静态语句块)
|
||||
* 父类(实例变量、普通语句块)
|
||||
* 父类(构造函数)
|
||||
* 子类(实例变量、普通语句块)
|
||||
* 子类(构造函数)
|
||||
|
||||
## 五、Object 通用方法
|
||||
|
||||
### 概览
|
||||
|
||||
```java
|
||||
|
||||
public native int hashCode()
|
||||
|
||||
public boolean equals(Object obj)
|
||||
@ -652,7 +648,7 @@ public final void wait() throws InterruptedException
|
||||
|
||||
### equals()
|
||||
|
||||
**1. 等价关系**
|
||||
**1. 等价关系**
|
||||
|
||||
两个对象具有等价关系,需要满足以下五个条件:
|
||||
|
||||
@ -691,10 +687,10 @@ x.equals(y) == x.equals(y); // true
|
||||
x.equals(null); // false;
|
||||
```
|
||||
|
||||
**2. 等价与相等**
|
||||
**2. 等价与相等**
|
||||
|
||||
- 对于基本类型,== 判断两个值是否相等,基本类型没有 equals() 方法。
|
||||
- 对于引用类型,== 判断两个变量是否引用同一个对象,而 equals() 判断引用的对象是否等价。
|
||||
* 对于基本类型,== 判断两个值是否相等,基本类型没有 equals() 方法。
|
||||
* 对于引用类型,== 判断两个变量是否引用同一个对象,而 equals() 判断引用的对象是否等价。
|
||||
|
||||
```java
|
||||
Integer x = new Integer(1);
|
||||
@ -703,12 +699,12 @@ System.out.println(x.equals(y)); // true
|
||||
System.out.println(x == y); // false
|
||||
```
|
||||
|
||||
**3. 实现**
|
||||
**3. 实现**
|
||||
|
||||
- 检查是否为同一个对象的引用,如果是直接返回 true;
|
||||
- 检查是否是同一个类型,如果不是,直接返回 false;
|
||||
- 将 Object 对象进行转型;
|
||||
- 判断每个关键域是否相等。
|
||||
* 检查是否为同一个对象的引用,如果是直接返回 true;
|
||||
* 检查是否是同一个类型,如果不是,直接返回 false;
|
||||
* 将 Object 对象进行转型;
|
||||
* 判断每个关键域是否相等。
|
||||
|
||||
```java
|
||||
public class EqualExample {
|
||||
@ -743,7 +739,7 @@ hashCode() 返回哈希值,而 equals() 是用来判断两个对象是否等
|
||||
|
||||
在覆盖 equals() 方法时应当总是覆盖 hashCode() 方法,保证等价的两个对象哈希值也相等。
|
||||
|
||||
HashSet 和 HashMap 等集合类使用了 hashCode() 方法来计算对象应该存储的位置,因此要将对象添加到这些集合类中,需要让对应的类实现 hashCode() 方法。
|
||||
HashSet 和 HashMap 等集合类使用了 hashCode() 方法来计算对象应该存储的位置,因此要将对象添加到这些集合类中,需要让对应的类实现 hashCode() 方法。
|
||||
|
||||
下面的代码中,新建了两个等价的对象,并将它们添加到 HashSet 中。我们希望将这两个对象当成一样的,只在集合中添加一个对象。但是 EqualExample 没有实现 hashCode() 方法,因此这两个对象的哈希值是不同的,最终导致集合添加了两个等价的对象。
|
||||
|
||||
@ -798,7 +794,7 @@ ToStringExample@4554617c
|
||||
|
||||
### clone()
|
||||
|
||||
**1. cloneable**
|
||||
**1. cloneable**
|
||||
|
||||
clone() 是 Object 的 protected 方法,它不是 public,一个类不显式去重写 clone(),其它类就不能直接去调用该类实例的 clone() 方法。
|
||||
|
||||
@ -857,7 +853,7 @@ public class CloneExample implements Cloneable {
|
||||
}
|
||||
```
|
||||
|
||||
**2. 浅拷贝**
|
||||
**2. 浅拷贝**
|
||||
|
||||
拷贝对象和原始对象的引用类型引用同一个对象。
|
||||
|
||||
@ -900,7 +896,7 @@ e1.set(2, 222);
|
||||
System.out.println(e2.get(2)); // 222
|
||||
```
|
||||
|
||||
**3. 深拷贝**
|
||||
**3. 深拷贝**
|
||||
|
||||
拷贝对象和原始对象的引用类型引用不同对象。
|
||||
|
||||
@ -948,7 +944,7 @@ e1.set(2, 222);
|
||||
System.out.println(e2.get(2)); // 2
|
||||
```
|
||||
|
||||
**4. clone() 的替代方案**
|
||||
**4. clone() 的替代方案**
|
||||
|
||||
使用 clone() 方法来拷贝一个对象即复杂又有风险,它会抛出异常,并且还需要类型转换。Effective Java 书上讲到,最好不要去使用 clone(),可以使用拷贝构造函数或者拷贝工厂来拷贝一个对象。
|
||||
|
||||
@ -996,8 +992,8 @@ Java 中有三个访问权限修饰符:private、protected 以及 public,如
|
||||
|
||||
可以对类或类中的成员(字段和方法)加上访问修饰符。
|
||||
|
||||
- 类可见表示其它类可以用这个类创建实例对象。
|
||||
- 成员可见表示其它类可以用这个类的实例对象访问到该成员;
|
||||
* 类可见表示其它类可以用这个类创建实例对象。
|
||||
* 成员可见表示其它类可以用这个类的实例对象访问到该成员;
|
||||
|
||||
protected 用于修饰成员,表示在继承体系中成员对于子类可见,但是这个访问修饰符对于类没有意义。
|
||||
|
||||
@ -1053,7 +1049,7 @@ public class AccessWithInnerClassExample {
|
||||
|
||||
### 抽象类与接口
|
||||
|
||||
**1. 抽象类**
|
||||
**1. 抽象类**
|
||||
|
||||
抽象类和抽象方法都使用 abstract 关键字进行声明。如果一个类中包含抽象方法,那么这个类必须声明为抽象类。
|
||||
|
||||
@ -1088,7 +1084,7 @@ AbstractClassExample ac2 = new AbstractExtendClassExample();
|
||||
ac2.func1();
|
||||
```
|
||||
|
||||
**2. 接口**
|
||||
**2. 接口**
|
||||
|
||||
接口是抽象类的延伸,在 Java 8 之前,它可以看成是一个完全抽象的类,也就是说它不能有任何的方法实现。
|
||||
|
||||
@ -1132,38 +1128,37 @@ ie2.func1();
|
||||
System.out.println(InterfaceExample.x);
|
||||
```
|
||||
|
||||
**3. 比较**
|
||||
**3. 比较**
|
||||
|
||||
- 从设计层面上看,抽象类提供了一种 IS-A 关系,需要满足里式替换原则,即子类对象必须能够替换掉所有父类对象。而接口更像是一种 LIKE-A 关系,它只是提供一种方法实现契约,并不要求接口和实现接口的类具有 IS-A 关系。
|
||||
- 从使用上来看,一个类可以实现多个接口,但是不能继承多个抽象类。
|
||||
- 接口的字段只能是 static 和 final 类型的,而抽象类的字段没有这种限制。
|
||||
- 接口的成员只能是 public 的,而抽象类的成员可以有多种访问权限。
|
||||
* 从设计层面上看,抽象类提供了一种 IS-A 关系,需要满足里式替换原则,即子类对象必须能够替换掉所有父类对象。而接口更像是一种 LIKE-A 关系,它只是提供一种方法实现契约,并不要求接口和实现接口的类具有 IS-A 关系。
|
||||
* 从使用上来看,一个类可以实现多个接口,但是不能继承多个抽象类。
|
||||
* 接口的字段只能是 static 和 final 类型的,而抽象类的字段没有这种限制。
|
||||
* 接口的成员只能是 public 的,而抽象类的成员可以有多种访问权限。
|
||||
|
||||
**4. 使用选择**
|
||||
**4. 使用选择**
|
||||
|
||||
使用接口:
|
||||
|
||||
- 需要让不相关的类都实现一个方法,例如不相关的类都可以实现 Comparable 接口中的 compareTo() 方法;
|
||||
- 需要使用多重继承。
|
||||
* 需要让不相关的类都实现一个方法,例如不相关的类都可以实现 Comparable 接口中的 compareTo() 方法;
|
||||
* 需要使用多重继承。
|
||||
|
||||
使用抽象类:
|
||||
|
||||
- 需要在几个相关的类中共享代码。
|
||||
- 需要能控制继承来的成员的访问权限,而不是都为 public。
|
||||
- 需要继承非静态和非常量字段。
|
||||
* 需要在几个相关的类中共享代码。
|
||||
* 需要能控制继承来的成员的访问权限,而不是都为 public。
|
||||
* 需要继承非静态和非常量字段。
|
||||
|
||||
在很多情况下,接口优先于抽象类。因为接口没有抽象类严格的类层次结构要求,可以灵活地为一个类添加行为。并且从 Java 8 开始,接口也可以有默认的方法实现,使得修改接口的成本也变的很低。
|
||||
|
||||
- [Abstract Methods and Classes](https://docs.oracle.com/javase/tutorial/java/IandI/abstract.html)
|
||||
- [深入理解 abstract class 和 interface](https://www.ibm.com/developerworks/cn/java/l-javainterface-abstract/)
|
||||
- [When to Use Abstract Class and Interface](https://dzone.com/articles/when-to-use-abstract-class-and-intreface)
|
||||
- [Java 9 Private Methods in Interfaces](https://www.journaldev.com/12850/java-9-private-methods-interfaces)
|
||||
|
||||
* [Abstract Methods and Classes](https://docs.oracle.com/javase/tutorial/java/IandI/abstract.html)
|
||||
* [深入理解 abstract class 和 interface](https://www.ibm.com/developerworks/cn/java/l-javainterface-abstract/)
|
||||
* [When to Use Abstract Class and Interface](https://dzone.com/articles/when-to-use-abstract-class-and-intreface)
|
||||
* [Java 9 Private Methods in Interfaces](https://www.journaldev.com/12850/java-9-private-methods-interfaces)
|
||||
|
||||
### super
|
||||
|
||||
- 访问父类的构造函数:可以使用 super() 函数访问父类的构造函数,从而委托父类完成一些初始化的工作。应该注意到,子类一定会调用父类的构造函数来完成初始化工作,一般是调用父类的默认构造函数,如果子类需要调用父类其它构造函数,那么就可以使用 super() 函数。
|
||||
- 访问父类的成员:如果子类重写了父类的某个方法,可以通过使用 super 关键字来引用父类的方法实现。
|
||||
* 访问父类的构造函数:可以使用 super() 函数访问父类的构造函数,从而委托父类完成一些初始化的工作。应该注意到,子类一定会调用父类的构造函数来完成初始化工作,一般是调用父类的默认构造函数,如果子类需要调用父类其它构造函数,那么就可以使用 super() 函数。
|
||||
* 访问父类的成员:如果子类重写了父类的某个方法,可以通过使用 super 关键字来引用父类的方法实现。
|
||||
|
||||
```java
|
||||
public class SuperExample {
|
||||
@ -1214,24 +1209,24 @@ SuperExtendExample.func()
|
||||
|
||||
### 重写与重载
|
||||
|
||||
**1. 重写(Override)**
|
||||
**1. 重写(Override)**
|
||||
|
||||
存在于继承体系中,指子类实现了一个与父类在方法声明上完全相同的一个方法。
|
||||
|
||||
为了满足里式替换原则,重写有以下三个限制:
|
||||
|
||||
- 子类方法的访问权限必须大于等于父类方法;
|
||||
- 子类方法的返回类型必须是父类方法返回类型或为其子类型。
|
||||
- 子类方法抛出的异常类型必须是父类抛出异常类型或为其子类型。
|
||||
* 子类方法的访问权限必须大于等于父类方法;
|
||||
* 子类方法的返回类型必须是父类方法返回类型或为其子类型。
|
||||
* 子类方法抛出的异常类型必须是父类抛出异常类型或为其子类型。
|
||||
|
||||
使用 @Override 注解,可以让编译器帮忙检查是否满足上面的三个限制条件。
|
||||
|
||||
下面的示例中,SubClass 为 SuperClass 的子类,SubClass 重写了 SuperClass 的 func() 方法。其中:
|
||||
|
||||
- 子类方法访问权限为 public,大于父类的 protected。
|
||||
- 子类的返回类型为 ArrayList\<Integer\>,是父类返回类型 List\<Integer\> 的子类。
|
||||
- 子类抛出的异常类型为 Exception,是父类抛出异常 Throwable 的子类。
|
||||
- 子类重写方法使用 @Override 注解,从而让编译器自动检查是否满足限制条件。
|
||||
* 子类方法访问权限为 public,大于父类的 protected。
|
||||
* 子类的返回类型为 ArrayList\<Integer>,是父类返回类型 List\<Integer> 的子类。
|
||||
* 子类抛出的异常类型为 Exception,是父类抛出异常 Throwable 的子类。
|
||||
* 子类重写方法使用 @Override 注解,从而让编译器自动检查是否满足限制条件。
|
||||
|
||||
```java
|
||||
class SuperClass {
|
||||
@ -1250,11 +1245,10 @@ class SubClass extends SuperClass {
|
||||
|
||||
在调用一个方法时,先从本类中查找看是否有对应的方法,如果没有再到父类中查看,看是否从父类继承来。否则就要对参数进行转型,转成父类之后看是否有对应的方法。总的来说,方法调用的优先级为:
|
||||
|
||||
- this.func(this)
|
||||
- super.func(this)
|
||||
- this.func(super)
|
||||
- super.func(super)
|
||||
|
||||
* this.func(this)
|
||||
* super.func(this)
|
||||
* this.func(super)
|
||||
* super.func(super)
|
||||
|
||||
```java
|
||||
/*
|
||||
@ -1318,7 +1312,7 @@ public static void main(String[] args) {
|
||||
}
|
||||
```
|
||||
|
||||
**2. 重载(Overload)**
|
||||
**2. 重载(Overload)**
|
||||
|
||||
存在于同一个类中,指一个方法与已经存在的方法名称上相同,但是参数类型、个数、顺序至少有一个不同。
|
||||
|
||||
@ -1346,7 +1340,7 @@ public static void main(String[] args) {
|
||||
|
||||
## 七、反射
|
||||
|
||||
每个类都有一个 **Class** 对象,包含了与类有关的信息。当编译一个新类时,会产生一个同名的 .class 文件,该文件内容保存着 Class 对象。
|
||||
每个类都有一个 **Class** 对象,包含了与类有关的信息。当编译一个新类时,会产生一个同名的 .class 文件,该文件内容保存着 Class 对象。
|
||||
|
||||
类加载相当于 Class 对象的加载,类在第一次使用时才动态加载到 JVM 中。也可以使用 `Class.forName("com.mysql.jdbc.Driver")` 这种方式来控制类的加载,该方法会返回一个 Class 对象。
|
||||
|
||||
@ -1354,41 +1348,38 @@ public static void main(String[] args) {
|
||||
|
||||
Class 和 java.lang.reflect 一起对反射提供了支持,java.lang.reflect 类库主要包含了以下三个类:
|
||||
|
||||
- **Field** :可以使用 get() 和 set() 方法读取和修改 Field 对象关联的字段;
|
||||
- **Method** :可以使用 invoke() 方法调用与 Method 对象关联的方法;
|
||||
- **Constructor** :可以用 Constructor 的 newInstance() 创建新的对象。
|
||||
* **Field** :可以使用 get() 和 set() 方法读取和修改 Field 对象关联的字段;
|
||||
* **Method** :可以使用 invoke() 方法调用与 Method 对象关联的方法;
|
||||
* **Constructor** :可以用 Constructor 的 newInstance() 创建新的对象。
|
||||
|
||||
**反射的优点:**
|
||||
**反射的优点:**
|
||||
|
||||
- **可扩展性** :应用程序可以利用全限定名创建可扩展对象的实例,来使用来自外部的用户自定义类。
|
||||
- **类浏览器和可视化开发环境** :一个类浏览器需要可以枚举类的成员。可视化开发环境(如 IDE)可以从利用反射中可用的类型信息中受益,以帮助程序员编写正确的代码。
|
||||
- **调试器和测试工具** : 调试器需要能够检查一个类里的私有成员。测试工具可以利用反射来自动地调用类里定义的可被发现的 API 定义,以确保一组测试中有较高的代码覆盖率。
|
||||
* **可扩展性** :应用程序可以利用全限定名创建可扩展对象的实例,来使用来自外部的用户自定义类。
|
||||
* **类浏览器和可视化开发环境** :一个类浏览器需要可以枚举类的成员。可视化开发环境(如 IDE)可以从利用反射中可用的类型信息中受益,以帮助程序员编写正确的代码。
|
||||
* **调试器和测试工具** : 调试器需要能够检查一个类里的私有成员。测试工具可以利用反射来自动地调用类里定义的可被发现的 API 定义,以确保一组测试中有较高的代码覆盖率。
|
||||
|
||||
**反射的缺点:**
|
||||
**反射的缺点:**
|
||||
|
||||
尽管反射非常强大,但也不能滥用。如果一个功能可以不用反射完成,那么最好就不用。在我们使用反射技术时,下面几条内容应该牢记于心。
|
||||
|
||||
- **性能开销** :反射涉及了动态类型的解析,所以 JVM 无法对这些代码进行优化。因此,反射操作的效率要比那些非反射操作低得多。我们应该避免在经常被执行的代码或对性能要求很高的程序中使用反射。
|
||||
|
||||
- **安全限制** :使用反射技术要求程序必须在一个没有安全限制的环境中运行。如果一个程序必须在有安全限制的环境中运行,如 Applet,那么这就是个问题了。
|
||||
|
||||
- **内部暴露** :由于反射允许代码执行一些在正常情况下不被允许的操作(比如访问私有的属性和方法),所以使用反射可能会导致意料之外的副作用,这可能导致代码功能失调并破坏可移植性。反射代码破坏了抽象性,因此当平台发生改变的时候,代码的行为就有可能也随着变化。
|
||||
|
||||
- [Trail: The Reflection API](https://docs.oracle.com/javase/tutorial/reflect/index.html)
|
||||
- [深入解析 Java 反射(1)- 基础](http://www.sczyh30.com/posts/Java/java-reflection-1/)
|
||||
* **性能开销** :反射涉及了动态类型的解析,所以 JVM 无法对这些代码进行优化。因此,反射操作的效率要比那些非反射操作低得多。我们应该避免在经常被执行的代码或对性能要求很高的程序中使用反射。
|
||||
* **安全限制** :使用反射技术要求程序必须在一个没有安全限制的环境中运行。如果一个程序必须在有安全限制的环境中运行,如 Applet,那么这就是个问题了。
|
||||
* **内部暴露** :由于反射允许代码执行一些在正常情况下不被允许的操作(比如访问私有的属性和方法),所以使用反射可能会导致意料之外的副作用,这可能导致代码功能失调并破坏可移植性。反射代码破坏了抽象性,因此当平台发生改变的时候,代码的行为就有可能也随着变化。
|
||||
* [Trail: The Reflection API](https://docs.oracle.com/javase/tutorial/reflect/index.html)
|
||||
* [深入解析 Java 反射(1)- 基础](http://www.sczyh30.com/posts/Java/java-reflection-1/)
|
||||
|
||||
## 八、异常
|
||||
|
||||
Throwable 可以用来表示任何可以作为异常抛出的类,分为两种: **Error** 和 **Exception**。其中 Error 用来表示 JVM 无法处理的错误,Exception 分为两种:
|
||||
Throwable 可以用来表示任何可以作为异常抛出的类,分为两种: **Error** 和 **Exception**。其中 Error 用来表示 JVM 无法处理的错误,Exception 分为两种:
|
||||
|
||||
- **受检异常** :需要用 try...catch... 语句捕获并进行处理,并且可以从异常中恢复;
|
||||
- **非受检异常** :是程序运行时错误,例如除 0 会引发 Arithmetic Exception,此时程序崩溃并且无法恢复。
|
||||
* **受检异常** :需要用 try...catch... 语句捕获并进行处理,并且可以从异常中恢复;
|
||||
* **非受检异常** :是程序运行时错误,例如除 0 会引发 Arithmetic Exception,此时程序崩溃并且无法恢复。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/PPjwP.png" width="600"/> </div><br>
|
||||
\
|
||||
|
||||
- [Java Exception Interview Questions and Answers](https://www.journaldev.com/2167/java-exception-interview-questions-and-answersl)
|
||||
|
||||
- [Java提高篇——Java 异常处理](https://www.cnblogs.com/Qian123/p/5715402.html)
|
||||
* [Java Exception Interview Questions and Answers](https://www.journaldev.com/2167/java-exception-interview-questions-and-answersl)
|
||||
* [Java提高篇——Java 异常处理](https://www.cnblogs.com/Qian123/p/5715402.html)
|
||||
|
||||
## 九、泛型
|
||||
|
||||
@ -1401,8 +1392,8 @@ public class Box<T> {
|
||||
}
|
||||
```
|
||||
|
||||
- [Java 泛型详解](https://www.cnblogs.com/Blue-Keroro/p/8875898.html)
|
||||
- [10 道 Java 泛型面试题](https://cloud.tencent.com/developer/article/1033693)
|
||||
* [Java 泛型详解](https://www.cnblogs.com/Blue-Keroro/p/8875898.html)
|
||||
* [10 道 Java 泛型面试题](https://cloud.tencent.com/developer/article/1033693)
|
||||
|
||||
## 十、注解
|
||||
|
||||
@ -1414,7 +1405,7 @@ Java 注解是附加在代码中的一些元信息,用于一些工具在编译
|
||||
|
||||
### Java 各版本的新特性
|
||||
|
||||
**New highlights in Java SE 8**
|
||||
**New highlights in Java SE 8**
|
||||
|
||||
1. Lambda Expressions
|
||||
2. Pipelines and Streams
|
||||
@ -1426,7 +1417,7 @@ Java 注解是附加在代码中的一些元信息,用于一些工具在编译
|
||||
8. Parallel operations
|
||||
9. PermGen Error Removed
|
||||
|
||||
**New highlights in Java SE 7**
|
||||
**New highlights in Java SE 7**
|
||||
|
||||
1. Strings in Switch Statement
|
||||
2. Type Inference for Generic Instance Creation
|
||||
@ -1437,27 +1428,27 @@ Java 注解是附加在代码中的一些元信息,用于一些工具在编译
|
||||
7. Binary Literals, Underscore in literals
|
||||
8. Diamond Syntax
|
||||
|
||||
- [Difference between Java 1.8 and Java 1.7?](http://www.selfgrowth.com/articles/difference-between-java-18-and-java-17)
|
||||
- [Java 8 特性](http://www.importnew.com/19345.html)
|
||||
* [Difference between Java 1.8 and Java 1.7?](http://www.selfgrowth.com/articles/difference-between-java-18-and-java-17)
|
||||
* [Java 8 特性](http://www.importnew.com/19345.html)
|
||||
|
||||
### Java 与 C++ 的区别
|
||||
|
||||
- Java 是纯粹的面向对象语言,所有的对象都继承自 java.lang.Object,C++ 为了兼容 C 即支持面向对象也支持面向过程。
|
||||
- Java 通过虚拟机从而实现跨平台特性,但是 C++ 依赖于特定的平台。
|
||||
- Java 没有指针,它的引用可以理解为安全指针,而 C++ 具有和 C 一样的指针。
|
||||
- Java 支持自动垃圾回收,而 C++ 需要手动回收。
|
||||
- Java 不支持多重继承,只能通过实现多个接口来达到相同目的,而 C++ 支持多重继承。
|
||||
- Java 不支持操作符重载,虽然可以对两个 String 对象执行加法运算,但是这是语言内置支持的操作,不属于操作符重载,而 C++ 可以。
|
||||
- Java 的 goto 是保留字,但是不可用,C++ 可以使用 goto。
|
||||
* Java 是纯粹的面向对象语言,所有的对象都继承自 java.lang.Object,C++ 为了兼容 C 即支持面向对象也支持面向过程。
|
||||
* Java 通过虚拟机从而实现跨平台特性,但是 C++ 依赖于特定的平台。
|
||||
* Java 没有指针,它的引用可以理解为安全指针,而 C++ 具有和 C 一样的指针。
|
||||
* Java 支持自动垃圾回收,而 C++ 需要手动回收。
|
||||
* Java 不支持多重继承,只能通过实现多个接口来达到相同目的,而 C++ 支持多重继承。
|
||||
* Java 不支持操作符重载,虽然可以对两个 String 对象执行加法运算,但是这是语言内置支持的操作,不属于操作符重载,而 C++ 可以。
|
||||
* Java 的 goto 是保留字,但是不可用,C++ 可以使用 goto。
|
||||
|
||||
[What are the main differences between Java and C++?](http://cs-fundamentals.com/tech-interview/java/differences-between-java-and-cpp.php)
|
||||
|
||||
### JRE or JDK
|
||||
|
||||
- JRE:Java Runtime Environment,Java 运行环境的简称,为 Java 的运行提供了所需的环境。它是一个 JVM 程序,主要包括了 JVM 的标准实现和一些 Java 基本类库。
|
||||
- JDK:Java Development Kit,Java 开发工具包,提供了 Java 的开发及运行环境。JDK 是 Java 开发的核心,集成了 JRE 以及一些其它的工具,比如编译 Java 源码的编译器 javac 等。
|
||||
* JRE:Java Runtime Environment,Java 运行环境的简称,为 Java 的运行提供了所需的环境。它是一个 JVM 程序,主要包括了 JVM 的标准实现和一些 Java 基本类库。
|
||||
* JDK:Java Development Kit,Java 开发工具包,提供了 Java 的开发及运行环境。JDK 是 Java 开发的核心,集成了 JRE 以及一些其它的工具,比如编译 Java 源码的编译器 javac 等。
|
||||
|
||||
## 参考资料
|
||||
|
||||
- Eckel B. Java 编程思想[M]. 机械工业出版社, 2002.
|
||||
- Bloch J. Effective java[M]. Addison-Wesley Professional, 2017.
|
||||
* Eckel B. Java 编程思想\[M]. 机械工业出版社, 2002.
|
||||
* Bloch J. Effective java\[M]. Addison-Wesley Professional, 2017.
|
||||
|
||||
192
notes/Java 容器.md
192
notes/Java 容器.md
@ -1,24 +1,22 @@
|
||||
# Java 容器
|
||||
<!-- GFM-TOC -->
|
||||
* [Java 容器](#java-容器)
|
||||
* [一、概览](#一概览)
|
||||
* [Collection](#collection)
|
||||
* [Map](#map)
|
||||
* [二、容器中的设计模式](#二容器中的设计模式)
|
||||
* [迭代器模式](#迭代器模式)
|
||||
* [适配器模式](#适配器模式)
|
||||
* [三、源码分析](#三源码分析)
|
||||
* [ArrayList](#arraylist)
|
||||
* [Vector](#vector)
|
||||
* [CopyOnWriteArrayList](#copyonwritearraylist)
|
||||
* [LinkedList](#linkedlist)
|
||||
* [HashMap](#hashmap)
|
||||
* [ConcurrentHashMap](#concurrenthashmap)
|
||||
* [LinkedHashMap](#linkedhashmap)
|
||||
* [WeakHashMap](#weakhashmap)
|
||||
* [参考资料](#参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [Java 容器](<Java 容器.md#java-容器>)
|
||||
* [一、概览](<Java 容器.md#一概览>)
|
||||
* [Collection](<Java 容器.md#collection>)
|
||||
* [Map](<Java 容器.md#map>)
|
||||
* [二、容器中的设计模式](<Java 容器.md#二容器中的设计模式>)
|
||||
* [迭代器模式](<Java 容器.md#迭代器模式>)
|
||||
* [适配器模式](<Java 容器.md#适配器模式>)
|
||||
* [三、源码分析](<Java 容器.md#三源码分析>)
|
||||
* [ArrayList](<Java 容器.md#arraylist>)
|
||||
* [Vector](<Java 容器.md#vector>)
|
||||
* [CopyOnWriteArrayList](<Java 容器.md#copyonwritearraylist>)
|
||||
* [LinkedList](<Java 容器.md#linkedlist>)
|
||||
* [HashMap](<Java 容器.md#hashmap>)
|
||||
* [ConcurrentHashMap](<Java 容器.md#concurrenthashmap>)
|
||||
* [LinkedHashMap](<Java 容器.md#linkedhashmap>)
|
||||
* [WeakHashMap](<Java 容器.md#weakhashmap>)
|
||||
* [参考资料](<Java 容器.md#参考资料>)
|
||||
|
||||
## 一、概览
|
||||
|
||||
@ -26,48 +24,42 @@
|
||||
|
||||
### Collection
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208220948084.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
#### 1. Set
|
||||
|
||||
- TreeSet:基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为 O(logN)。
|
||||
|
||||
- HashSet:基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。
|
||||
|
||||
- LinkedHashSet:具有 HashSet 的查找效率,并且内部使用双向链表维护元素的插入顺序。
|
||||
* TreeSet:基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为 O(logN)。
|
||||
* HashSet:基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。
|
||||
* LinkedHashSet:具有 HashSet 的查找效率,并且内部使用双向链表维护元素的插入顺序。
|
||||
|
||||
#### 2. List
|
||||
|
||||
- ArrayList:基于动态数组实现,支持随机访问。
|
||||
|
||||
- Vector:和 ArrayList 类似,但它是线程安全的。
|
||||
|
||||
- LinkedList:基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList 还可以用作栈、队列和双向队列。
|
||||
* ArrayList:基于动态数组实现,支持随机访问。
|
||||
* Vector:和 ArrayList 类似,但它是线程安全的。
|
||||
* LinkedList:基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList 还可以用作栈、队列和双向队列。
|
||||
|
||||
#### 3. Queue
|
||||
|
||||
- LinkedList:可以用它来实现双向队列。
|
||||
|
||||
- PriorityQueue:基于堆结构实现,可以用它来实现优先队列。
|
||||
* LinkedList:可以用它来实现双向队列。
|
||||
* PriorityQueue:基于堆结构实现,可以用它来实现优先队列。
|
||||
|
||||
### Map
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20201101234335837.png"/> </div><br>
|
||||
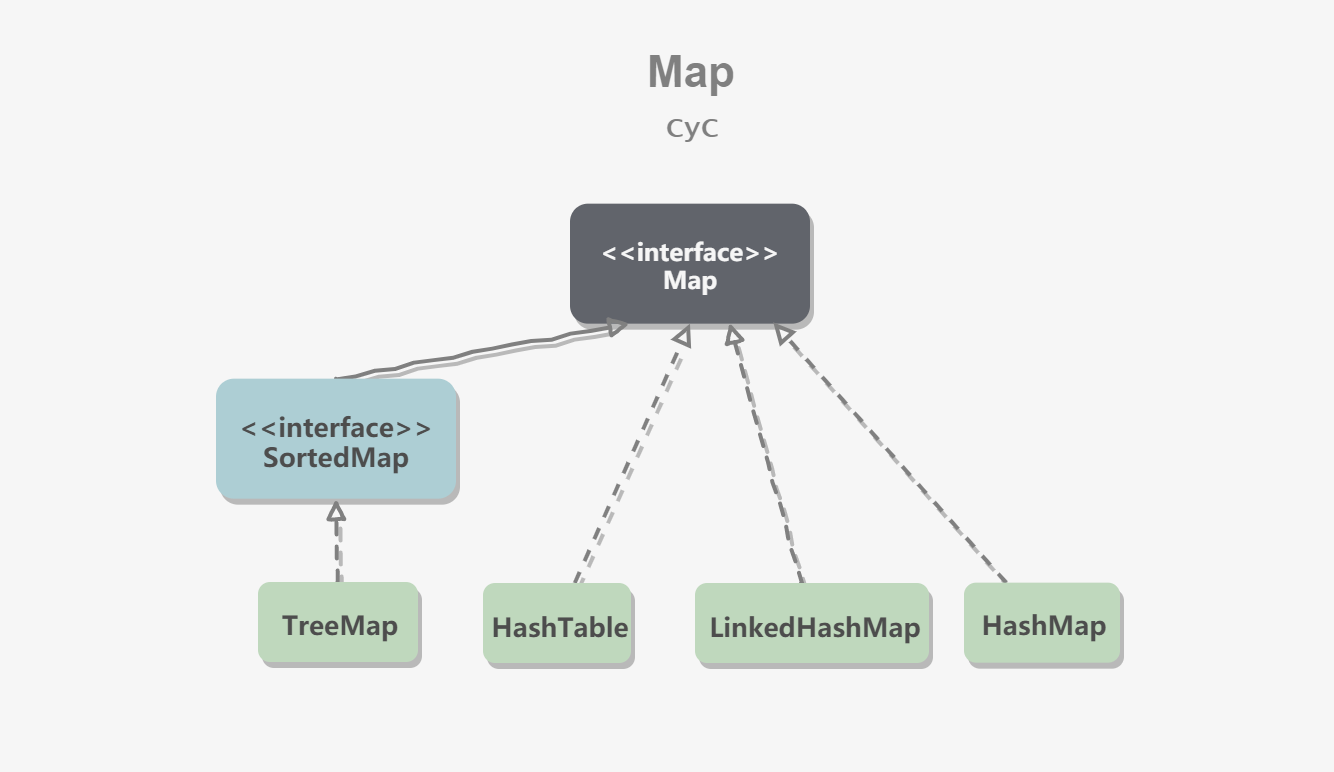\
|
||||
|
||||
- TreeMap:基于红黑树实现。
|
||||
|
||||
- HashMap:基于哈希表实现。
|
||||
|
||||
- HashTable:和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程同时写入 HashTable 不会导致数据不一致。它是遗留类,不应该去使用它,而是使用 ConcurrentHashMap 来支持线程安全,ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。
|
||||
|
||||
- LinkedHashMap:使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
|
||||
|
||||
* TreeMap:基于红黑树实现。
|
||||
* HashMap:基于哈希表实现。
|
||||
* HashTable:和 HashMap 类似,但它是线程安全的,这意味着同一时刻多个线程同时写入 HashTable 不会导致数据不一致。它是遗留类,不应该去使用它,而是使用 ConcurrentHashMap 来支持线程安全,ConcurrentHashMap 的效率会更高,因为 ConcurrentHashMap 引入了分段锁。
|
||||
* LinkedHashMap:使用双向链表来维护元素的顺序,顺序为插入顺序或者最近最少使用(LRU)顺序。
|
||||
|
||||
## 二、容器中的设计模式
|
||||
|
||||
### 迭代器模式
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208225301973.png"/> </div><br>
|
||||
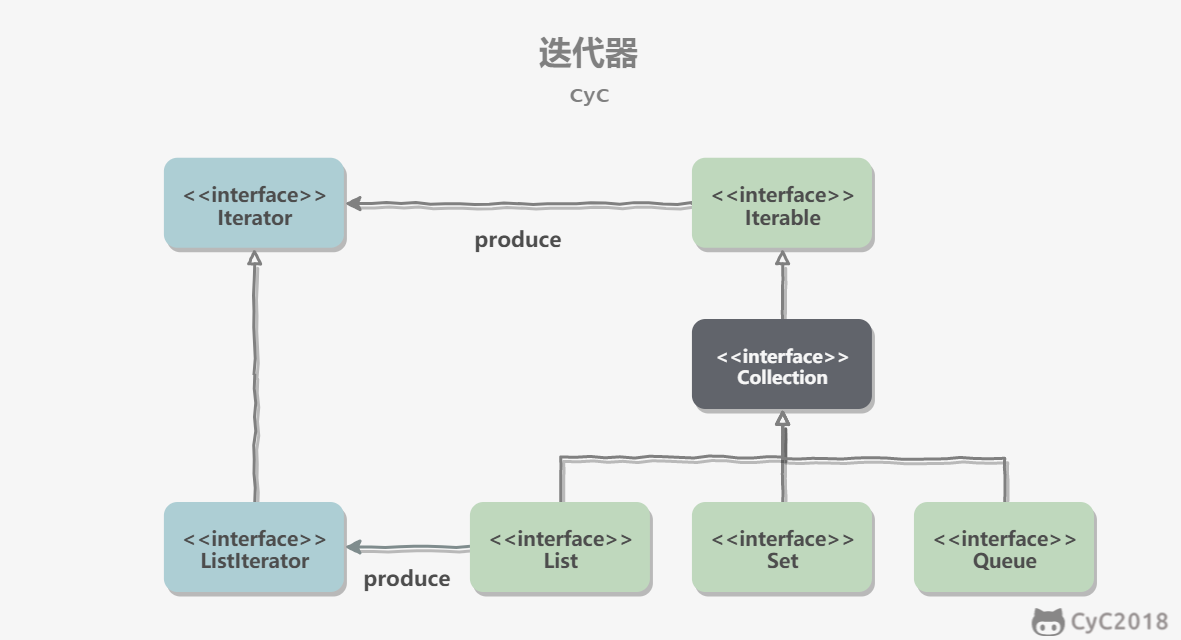\
|
||||
|
||||
|
||||
Collection 继承了 Iterable 接口,其中的 iterator() 方法能够产生一个 Iterator 对象,通过这个对象就可以迭代遍历 Collection 中的元素。
|
||||
|
||||
@ -112,7 +104,6 @@ List list = Arrays.asList(1, 2, 3);
|
||||
|
||||
### ArrayList
|
||||
|
||||
|
||||
#### 1. 概览
|
||||
|
||||
因为 ArrayList 是基于数组实现的,所以支持快速随机访问。RandomAccess 接口标识着该类支持快速随机访问。
|
||||
@ -128,7 +119,8 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
private static final int DEFAULT_CAPACITY = 10;
|
||||
```
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208232221265.png"/> </div><br>
|
||||
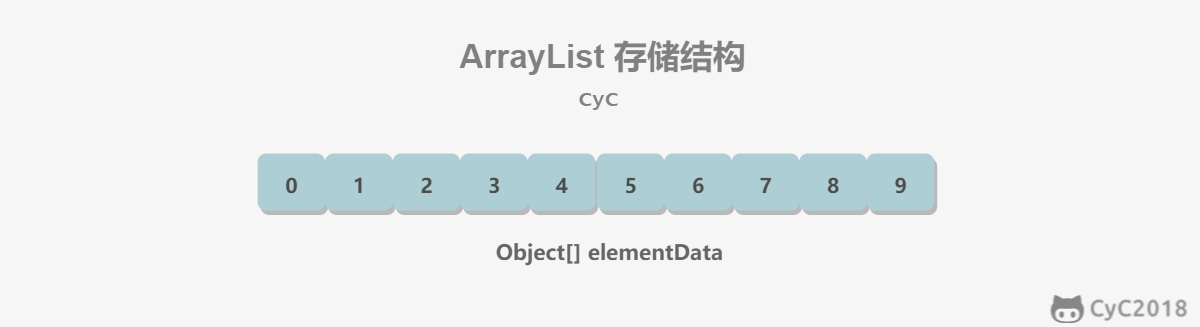\
|
||||
|
||||
|
||||
#### 2. 扩容
|
||||
|
||||
@ -258,7 +250,6 @@ modCount 用来记录 ArrayList 结构发生变化的次数。结构发生变化
|
||||
|
||||
在进行序列化或者迭代等操作时,需要比较操作前后 modCount 是否改变,如果改变了需要抛出 ConcurrentModificationException。代码参考上节序列化中的 writeObject() 方法。
|
||||
|
||||
|
||||
### Vector
|
||||
|
||||
#### 1. 同步
|
||||
@ -324,8 +315,8 @@ public Vector() {
|
||||
|
||||
#### 3. 与 ArrayList 的比较
|
||||
|
||||
- Vector 是同步的,因此开销就比 ArrayList 要大,访问速度更慢。最好使用 ArrayList 而不是 Vector,因为同步操作完全可以由程序员自己来控制;
|
||||
- Vector 每次扩容请求其大小的 2 倍(也可以通过构造函数设置增长的容量),而 ArrayList 是 1.5 倍。
|
||||
* Vector 是同步的,因此开销就比 ArrayList 要大,访问速度更慢。最好使用 ArrayList 而不是 Vector,因为同步操作完全可以由程序员自己来控制;
|
||||
* Vector 每次扩容请求其大小的 2 倍(也可以通过构造函数设置增长的容量),而 ArrayList 是 1.5 倍。
|
||||
|
||||
#### 4. 替代方案
|
||||
|
||||
@ -386,8 +377,8 @@ CopyOnWriteArrayList 在写操作的同时允许读操作,大大提高了读
|
||||
|
||||
但是 CopyOnWriteArrayList 有其缺陷:
|
||||
|
||||
- 内存占用:在写操作时需要复制一个新的数组,使得内存占用为原来的两倍左右;
|
||||
- 数据不一致:读操作不能读取实时性的数据,因为部分写操作的数据还未同步到读数组中。
|
||||
* 内存占用:在写操作时需要复制一个新的数组,使得内存占用为原来的两倍左右;
|
||||
* 数据不一致:读操作不能读取实时性的数据,因为部分写操作的数据还未同步到读数组中。
|
||||
|
||||
所以 CopyOnWriteArrayList 不适合内存敏感以及对实时性要求很高的场景。
|
||||
|
||||
@ -412,14 +403,15 @@ transient Node<E> first;
|
||||
transient Node<E> last;
|
||||
```
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208233940066.png"/> </div><br>
|
||||
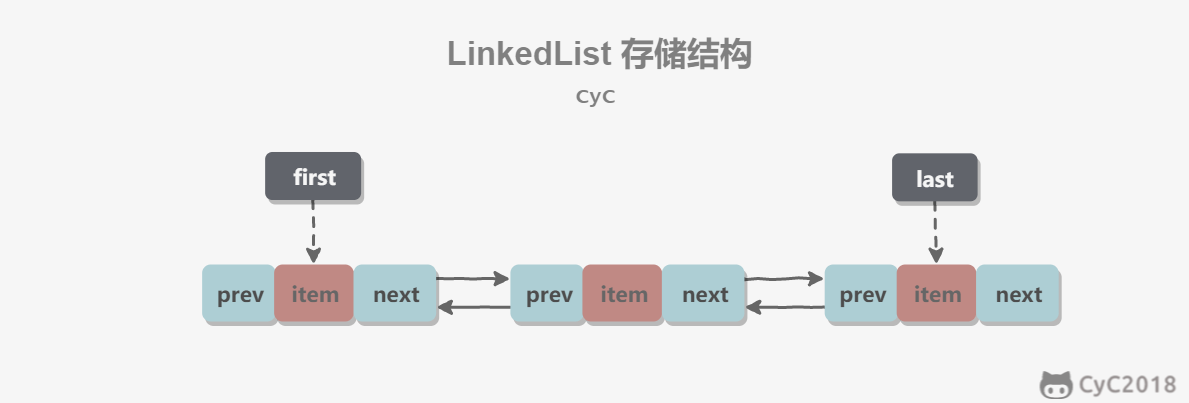\
|
||||
|
||||
|
||||
#### 2. 与 ArrayList 的比较
|
||||
|
||||
ArrayList 基于动态数组实现,LinkedList 基于双向链表实现。ArrayList 和 LinkedList 的区别可以归结为数组和链表的区别:
|
||||
|
||||
- 数组支持随机访问,但插入删除的代价很高,需要移动大量元素;
|
||||
- 链表不支持随机访问,但插入删除只需要改变指针。
|
||||
* 数组支持随机访问,但插入删除的代价很高,需要移动大量元素;
|
||||
* 链表不支持随机访问,但插入删除只需要改变指针。
|
||||
|
||||
### HashMap
|
||||
|
||||
@ -429,7 +421,8 @@ ArrayList 基于动态数组实现,LinkedList 基于双向链表实现。Array
|
||||
|
||||
内部包含了一个 Entry 类型的数组 table。Entry 存储着键值对。它包含了四个字段,从 next 字段我们可以看出 Entry 是一个链表。即数组中的每个位置被当成一个桶,一个桶存放一个链表。HashMap 使用拉链法来解决冲突,同一个链表中存放哈希值和散列桶取模运算结果相同的 Entry。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208234948205.png"/> </div><br>
|
||||
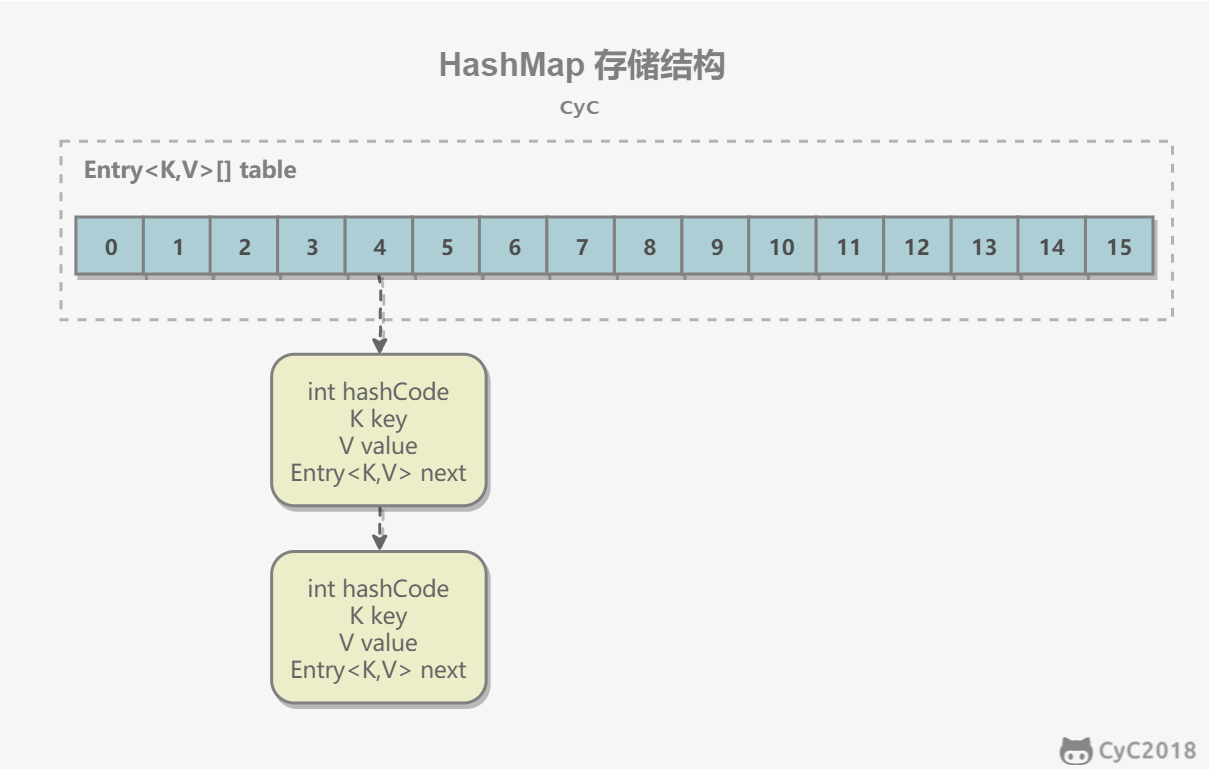\
|
||||
|
||||
|
||||
```java
|
||||
transient Entry[] table;
|
||||
@ -497,19 +490,20 @@ map.put("K2", "V2");
|
||||
map.put("K3", "V3");
|
||||
```
|
||||
|
||||
- 新建一个 HashMap,默认大小为 16;
|
||||
- 插入 <K1,V1\> 键值对,先计算 K1 的 hashCode 为 115,使用除留余数法得到所在的桶下标 115%16=3。
|
||||
- 插入 <K2,V2\> 键值对,先计算 K2 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6。
|
||||
- 插入 <K3,V3\> 键值对,先计算 K3 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6,插在 <K2,V2\> 前面。
|
||||
* 新建一个 HashMap,默认大小为 16;
|
||||
* 插入 \<K1,V1> 键值对,先计算 K1 的 hashCode 为 115,使用除留余数法得到所在的桶下标 115%16=3。
|
||||
* 插入 \<K2,V2> 键值对,先计算 K2 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6。
|
||||
* 插入 \<K3,V3> 键值对,先计算 K3 的 hashCode 为 118,使用除留余数法得到所在的桶下标 118%16=6,插在 \<K2,V2> 前面。
|
||||
|
||||
应该注意到链表的插入是以头插法方式进行的,例如上面的 <K3,V3\> 不是插在 <K2,V2\> 后面,而是插入在链表头部。
|
||||
应该注意到链表的插入是以头插法方式进行的,例如上面的 \<K3,V3> 不是插在 \<K2,V2> 后面,而是插入在链表头部。
|
||||
|
||||
查找需要分成两步进行:
|
||||
|
||||
- 计算键值对所在的桶;
|
||||
- 在链表上顺序查找,时间复杂度显然和链表的长度成正比。
|
||||
* 计算键值对所在的桶;
|
||||
* 在链表上顺序查找,时间复杂度显然和链表的长度成正比。
|
||||
|
||||
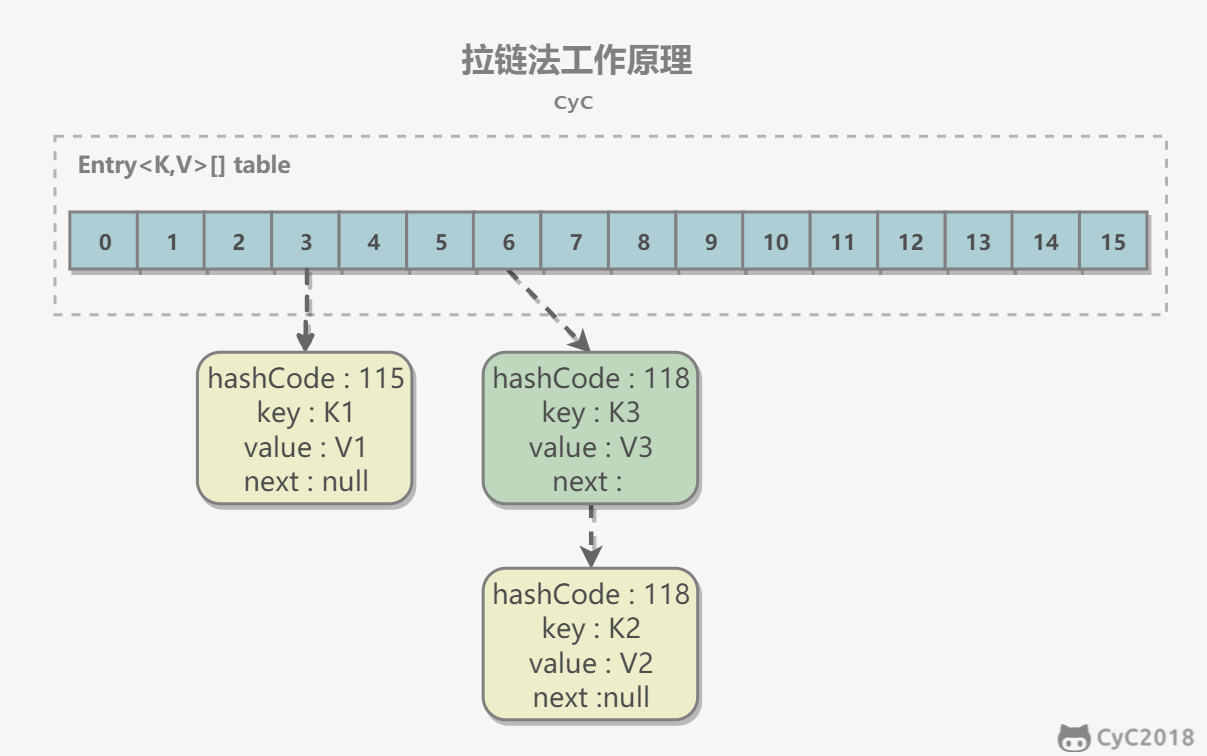\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208235258643.png"/> </div><br>
|
||||
|
||||
#### 3. put 操作
|
||||
|
||||
@ -599,7 +593,7 @@ int hash = hash(key);
|
||||
int i = indexFor(hash, table.length);
|
||||
```
|
||||
|
||||
**4.1 计算 hash 值**
|
||||
**4.1 计算 hash 值**
|
||||
|
||||
```java
|
||||
final int hash(Object k) {
|
||||
@ -624,9 +618,9 @@ public final int hashCode() {
|
||||
}
|
||||
```
|
||||
|
||||
**4.2 取模**
|
||||
**4.2 取模**
|
||||
|
||||
令 x = 1\<\<4,即 x 为 2 的 4 次方,它具有以下性质:
|
||||
令 x = 1<<4,即 x 为 2 的 4 次方,它具有以下性质:
|
||||
|
||||
```
|
||||
x : 00010000
|
||||
@ -665,14 +659,14 @@ static int indexFor(int h, int length) {
|
||||
|
||||
为了让查找的成本降低,应该使 N/M 尽可能小,因此需要保证 M 尽可能大,也就是说 table 要尽可能大。HashMap 采用动态扩容来根据当前的 N 值来调整 M 值,使得空间效率和时间效率都能得到保证。
|
||||
|
||||
和扩容相关的参数主要有:capacity、size、threshold 和 load_factor。
|
||||
和扩容相关的参数主要有:capacity、size、threshold 和 load\_factor。
|
||||
|
||||
| 参数 | 含义 |
|
||||
| :--: | :-- |
|
||||
| capacity | table 的容量大小,默认为 16。需要注意的是 capacity 必须保证为 2 的 n 次方。|
|
||||
| size | 键值对数量。 |
|
||||
| threshold | size 的临界值,当 size 大于等于 threshold 就必须进行扩容操作。 |
|
||||
| loadFactor | 装载因子,table 能够使用的比例,threshold = (int)(capacity* loadFactor)。 |
|
||||
| 参数 | 含义 |
|
||||
| :--------: | ------------------------------------------------------------ |
|
||||
| capacity | table 的容量大小,默认为 16。需要注意的是 capacity 必须保证为 2 的 n 次方。 |
|
||||
| size | 键值对数量。 |
|
||||
| threshold | size 的临界值,当 size 大于等于 threshold 就必须进行扩容操作。 |
|
||||
| loadFactor | 装载因子,table 能够使用的比例,threshold = (int)(capacity\* loadFactor)。 |
|
||||
|
||||
```java
|
||||
static final int DEFAULT_INITIAL_CAPACITY = 16;
|
||||
@ -751,8 +745,8 @@ new capacity : 00100000
|
||||
|
||||
对于一个 Key,它的哈希值 hash 在第 5 位:
|
||||
|
||||
- 为 0,那么 hash%00010000 = hash%00100000,桶位置和原来一致;
|
||||
- 为 1,hash%00010000 = hash%00100000 + 16,桶位置是原位置 + 16。
|
||||
* 为 0,那么 hash%00010000 = hash%00100000,桶位置和原来一致;
|
||||
* 为 1,hash%00010000 = hash%00100000 + 16,桶位置是原位置 + 16。
|
||||
|
||||
#### 7. 计算数组容量
|
||||
|
||||
@ -793,16 +787,17 @@ static final int tableSizeFor(int cap) {
|
||||
|
||||
#### 9. 与 Hashtable 的比较
|
||||
|
||||
- Hashtable 使用 synchronized 来进行同步。
|
||||
- HashMap 可以插入键为 null 的 Entry。
|
||||
- HashMap 的迭代器是 fail-fast 迭代器。
|
||||
- HashMap 不能保证随着时间的推移 Map 中的元素次序是不变的。
|
||||
* Hashtable 使用 synchronized 来进行同步。
|
||||
* HashMap 可以插入键为 null 的 Entry。
|
||||
* HashMap 的迭代器是 fail-fast 迭代器。
|
||||
* HashMap 不能保证随着时间的推移 Map 中的元素次序是不变的。
|
||||
|
||||
### ConcurrentHashMap
|
||||
|
||||
#### 1. 存储结构
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191209001038024.png"/> </div><br>
|
||||
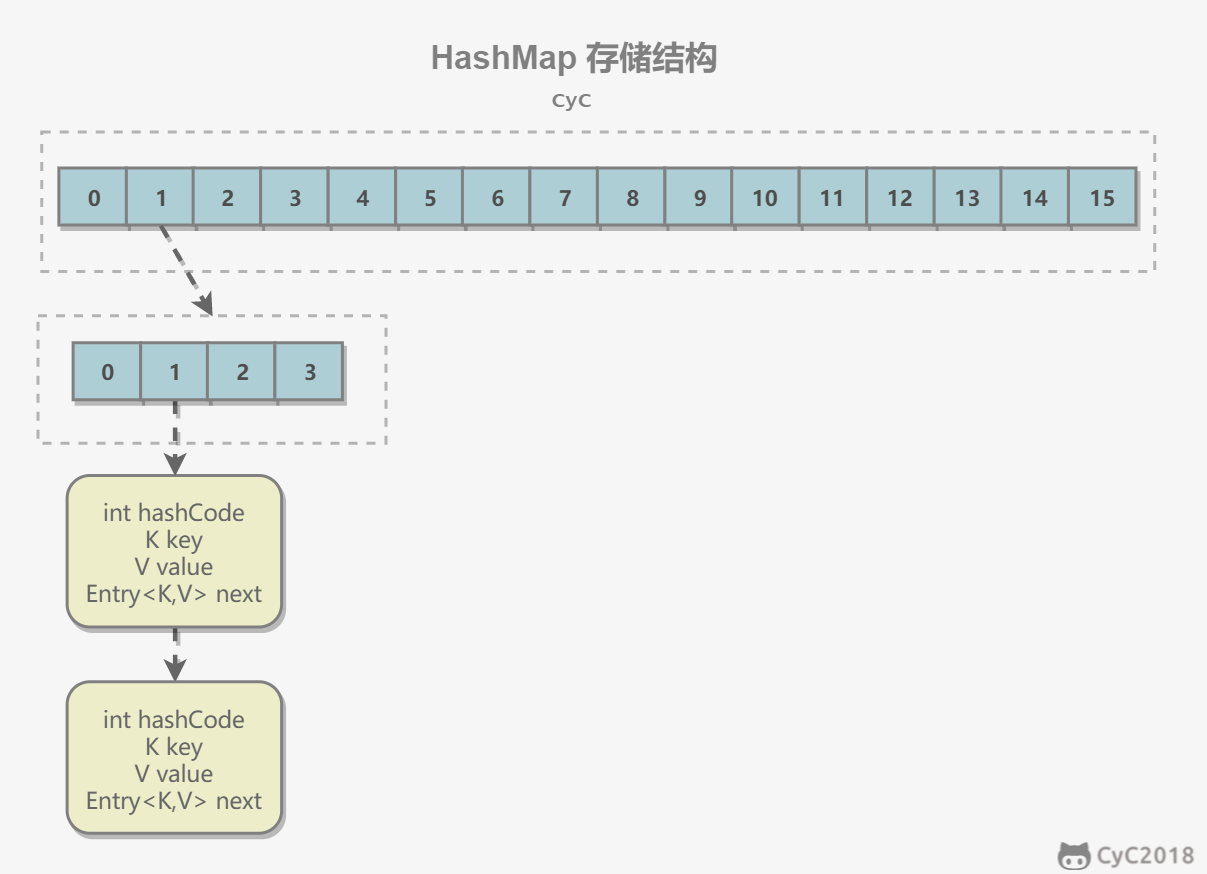\
|
||||
|
||||
|
||||
```java
|
||||
static final class HashEntry<K,V> {
|
||||
@ -863,12 +858,11 @@ transient int count;
|
||||
|
||||
ConcurrentHashMap 在执行 size 操作时先尝试不加锁,如果连续两次不加锁操作得到的结果一致,那么可以认为这个结果是正确的。
|
||||
|
||||
尝试次数使用 RETRIES_BEFORE_LOCK 定义,该值为 2,retries 初始值为 -1,因此尝试次数为 3。
|
||||
尝试次数使用 RETRIES\_BEFORE\_LOCK 定义,该值为 2,retries 初始值为 -1,因此尝试次数为 3。
|
||||
|
||||
如果尝试的次数超过 3 次,就需要对每个 Segment 加锁。
|
||||
|
||||
```java
|
||||
|
||||
/**
|
||||
* Number of unsynchronized retries in size and containsValue
|
||||
* methods before resorting to locking. This is used to avoid
|
||||
@ -1024,9 +1018,9 @@ protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
|
||||
|
||||
以下是使用 LinkedHashMap 实现的一个 LRU 缓存:
|
||||
|
||||
- 设定最大缓存空间 MAX_ENTRIES 为 3;
|
||||
- 使用 LinkedHashMap 的构造函数将 accessOrder 设置为 true,开启 LRU 顺序;
|
||||
- 覆盖 removeEldestEntry() 方法实现,在节点多于 MAX_ENTRIES 就会将最近最久未使用的数据移除。
|
||||
* 设定最大缓存空间 MAX\_ENTRIES 为 3;
|
||||
* 使用 LinkedHashMap 的构造函数将 accessOrder 设置为 true,开启 LRU 顺序;
|
||||
* 覆盖 removeEldestEntry() 方法实现,在节点多于 MAX\_ENTRIES 就会将最近最久未使用的数据移除。
|
||||
|
||||
```java
|
||||
class LRUCache<K, V> extends LinkedHashMap<K, V> {
|
||||
@ -1076,10 +1070,10 @@ Tomcat 中的 ConcurrentCache 使用了 WeakHashMap 来实现缓存功能。
|
||||
|
||||
ConcurrentCache 采取的是分代缓存:
|
||||
|
||||
- 经常使用的对象放入 eden 中,eden 使用 ConcurrentHashMap 实现,不用担心会被回收(伊甸园);
|
||||
- 不常用的对象放入 longterm,longterm 使用 WeakHashMap 实现,这些老对象会被垃圾收集器回收。
|
||||
- 当调用 get() 方法时,会先从 eden 区获取,如果没有找到的话再到 longterm 获取,当从 longterm 获取到就把对象放入 eden 中,从而保证经常被访问的节点不容易被回收。
|
||||
- 当调用 put() 方法时,如果 eden 的大小超过了 size,那么就将 eden 中的所有对象都放入 longterm 中,利用虚拟机回收掉一部分不经常使用的对象。
|
||||
* 经常使用的对象放入 eden 中,eden 使用 ConcurrentHashMap 实现,不用担心会被回收(伊甸园);
|
||||
* 不常用的对象放入 longterm,longterm 使用 WeakHashMap 实现,这些老对象会被垃圾收集器回收。
|
||||
* 当调用 get() 方法时,会先从 eden 区获取,如果没有找到的话再到 longterm 获取,当从 longterm 获取到就把对象放入 eden 中,从而保证经常被访问的节点不容易被回收。
|
||||
* 当调用 put() 方法时,如果 eden 的大小超过了 size,那么就将 eden 中的所有对象都放入 longterm 中,利用虚拟机回收掉一部分不经常使用的对象。
|
||||
|
||||
```java
|
||||
public final class ConcurrentCache<K, V> {
|
||||
@ -1116,18 +1110,16 @@ public final class ConcurrentCache<K, V> {
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
## 参考资料
|
||||
|
||||
- Eckel B. Java 编程思想 [M]. 机械工业出版社, 2002.
|
||||
- [Java Collection Framework](https://www.w3resource.com/java-tutorial/java-collections.php)
|
||||
- [Iterator 模式](https://openhome.cc/Gossip/DesignPattern/IteratorPattern.htm)
|
||||
- [Java 8 系列之重新认识 HashMap](https://tech.meituan.com/java_hashmap.html)
|
||||
- [What is difference between HashMap and Hashtable in Java?](http://javarevisited.blogspot.hk/2010/10/difference-between-hashmap-and.html)
|
||||
- [Java 集合之 HashMap](http://www.zhangchangle.com/2018/02/07/Java%E9%9B%86%E5%90%88%E4%B9%8BHashMap/)
|
||||
- [The principle of ConcurrentHashMap analysis](http://www.programering.com/a/MDO3QDNwATM.html)
|
||||
- [探索 ConcurrentHashMap 高并发性的实现机制](https://www.ibm.com/developerworks/cn/java/java-lo-concurrenthashmap/)
|
||||
- [HashMap 相关面试题及其解答](https://www.jianshu.com/p/75adf47958a7)
|
||||
- [Java 集合细节(二):asList 的缺陷](http://wiki.jikexueyuan.com/project/java-enhancement/java-thirtysix.html)
|
||||
- [Java Collection Framework – The LinkedList Class](http://javaconceptoftheday.com/java-collection-framework-linkedlist-class/)
|
||||
|
||||
* Eckel B. Java 编程思想 \[M]. 机械工业出版社, 2002.
|
||||
* [Java Collection Framework](https://www.w3resource.com/java-tutorial/java-collections.php)
|
||||
* [Iterator 模式](https://openhome.cc/Gossip/DesignPattern/IteratorPattern.htm)
|
||||
* [Java 8 系列之重新认识 HashMap](https://tech.meituan.com/java\_hashmap.html)
|
||||
* [What is difference between HashMap and Hashtable in Java?](http://javarevisited.blogspot.hk/2010/10/difference-between-hashmap-and.html)
|
||||
* [Java 集合之 HashMap](http://www.zhangchangle.com/2018/02/07/Java%E9%9B%86%E5%90%88%E4%B9%8BHashMap/)
|
||||
* [The principle of ConcurrentHashMap analysis](http://www.programering.com/a/MDO3QDNwATM.html)
|
||||
* [探索 ConcurrentHashMap 高并发性的实现机制](https://www.ibm.com/developerworks/cn/java/java-lo-concurrenthashmap/)
|
||||
* [HashMap 相关面试题及其解答](https://www.jianshu.com/p/75adf47958a7)
|
||||
* [Java 集合细节(二):asList 的缺陷](http://wiki.jikexueyuan.com/project/java-enhancement/java-thirtysix.html)
|
||||
* [Java Collection Framework – The LinkedList Class](http://javaconceptoftheday.com/java-collection-framework-linkedlist-class/)
|
||||
|
||||
333
notes/Java 并发.md
333
notes/Java 并发.md
@ -1,74 +1,71 @@
|
||||
# Java 并发
|
||||
<!-- GFM-TOC -->
|
||||
* [Java 并发](#java-并发)
|
||||
* [一、使用线程](#一使用线程)
|
||||
* [实现 Runnable 接口](#实现-runnable-接口)
|
||||
* [实现 Callable 接口](#实现-callable-接口)
|
||||
* [继承 Thread 类](#继承-thread-类)
|
||||
* [实现接口 VS 继承 Thread](#实现接口-vs-继承-thread)
|
||||
* [二、基础线程机制](#二基础线程机制)
|
||||
* [Executor](#executor)
|
||||
* [Daemon](#daemon)
|
||||
* [sleep()](#sleep)
|
||||
* [yield()](#yield)
|
||||
* [三、中断](#三中断)
|
||||
* [InterruptedException](#interruptedexception)
|
||||
* [interrupted()](#interrupted)
|
||||
* [Executor 的中断操作](#executor-的中断操作)
|
||||
* [四、互斥同步](#四互斥同步)
|
||||
* [synchronized](#synchronized)
|
||||
* [ReentrantLock](#reentrantlock)
|
||||
* [比较](#比较)
|
||||
* [使用选择](#使用选择)
|
||||
* [五、线程之间的协作](#五线程之间的协作)
|
||||
* [join()](#join)
|
||||
* [wait() notify() notifyAll()](#wait-notify-notifyall)
|
||||
* [await() signal() signalAll()](#await-signal-signalall)
|
||||
* [六、线程状态](#六线程状态)
|
||||
* [新建(NEW)](#新建new)
|
||||
* [可运行(RUNABLE)](#可运行runable)
|
||||
* [阻塞(BLOCKED)](#阻塞blocked)
|
||||
* [无限期等待(WAITING)](#无限期等待waiting)
|
||||
* [限期等待(TIMED_WAITING)](#限期等待timed_waiting)
|
||||
* [死亡(TERMINATED)](#死亡terminated)
|
||||
* [七、J.U.C - AQS](#七juc---aqs)
|
||||
* [CountDownLatch](#countdownlatch)
|
||||
* [CyclicBarrier](#cyclicbarrier)
|
||||
* [Semaphore](#semaphore)
|
||||
* [八、J.U.C - 其它组件](#八juc---其它组件)
|
||||
* [FutureTask](#futuretask)
|
||||
* [BlockingQueue](#blockingqueue)
|
||||
* [ForkJoin](#forkjoin)
|
||||
* [九、线程不安全示例](#九线程不安全示例)
|
||||
* [十、Java 内存模型](#十java-内存模型)
|
||||
* [主内存与工作内存](#主内存与工作内存)
|
||||
* [内存间交互操作](#内存间交互操作)
|
||||
* [内存模型三大特性](#内存模型三大特性)
|
||||
* [先行发生原则](#先行发生原则)
|
||||
* [十一、线程安全](#十一线程安全)
|
||||
* [不可变](#不可变)
|
||||
* [互斥同步](#互斥同步)
|
||||
* [非阻塞同步](#非阻塞同步)
|
||||
* [无同步方案](#无同步方案)
|
||||
* [十二、锁优化](#十二锁优化)
|
||||
* [自旋锁](#自旋锁)
|
||||
* [锁消除](#锁消除)
|
||||
* [锁粗化](#锁粗化)
|
||||
* [轻量级锁](#轻量级锁)
|
||||
* [偏向锁](#偏向锁)
|
||||
* [十三、多线程开发良好的实践](#十三多线程开发良好的实践)
|
||||
* [参考资料](#参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
|
||||
* [Java 并发](<Java 并发.md#java-并发>)
|
||||
* [一、使用线程](<Java 并发.md#一使用线程>)
|
||||
* [实现 Runnable 接口](<Java 并发.md#实现-runnable-接口>)
|
||||
* [实现 Callable 接口](<Java 并发.md#实现-callable-接口>)
|
||||
* [继承 Thread 类](<Java 并发.md#继承-thread-类>)
|
||||
* [实现接口 VS 继承 Thread](<Java 并发.md#实现接口-vs-继承-thread>)
|
||||
* [二、基础线程机制](<Java 并发.md#二基础线程机制>)
|
||||
* [Executor](<Java 并发.md#executor>)
|
||||
* [Daemon](<Java 并发.md#daemon>)
|
||||
* [sleep()](<Java 并发.md#sleep>)
|
||||
* [yield()](<Java 并发.md#yield>)
|
||||
* [三、中断](<Java 并发.md#三中断>)
|
||||
* [InterruptedException](<Java 并发.md#interruptedexception>)
|
||||
* [interrupted()](<Java 并发.md#interrupted>)
|
||||
* [Executor 的中断操作](<Java 并发.md#executor-的中断操作>)
|
||||
* [四、互斥同步](<Java 并发.md#四互斥同步>)
|
||||
* [synchronized](<Java 并发.md#synchronized>)
|
||||
* [ReentrantLock](<Java 并发.md#reentrantlock>)
|
||||
* [比较](<Java 并发.md#比较>)
|
||||
* [使用选择](<Java 并发.md#使用选择>)
|
||||
* [五、线程之间的协作](<Java 并发.md#五线程之间的协作>)
|
||||
* [join()](<Java 并发.md#join>)
|
||||
* [wait() notify() notifyAll()](<Java 并发.md#wait-notify-notifyall>)
|
||||
* [await() signal() signalAll()](<Java 并发.md#await-signal-signalall>)
|
||||
* [六、线程状态](<Java 并发.md#六线程状态>)
|
||||
* [新建(NEW)](<Java 并发.md#新建new>)
|
||||
* [可运行(RUNABLE)](<Java 并发.md#可运行runable>)
|
||||
* [阻塞(BLOCKED)](<Java 并发.md#阻塞blocked>)
|
||||
* [无限期等待(WAITING)](<Java 并发.md#无限期等待waiting>)
|
||||
* [限期等待(TIMED\_WAITING)](<Java 并发.md#限期等待timed\_waiting>)
|
||||
* [死亡(TERMINATED)](<Java 并发.md#死亡terminated>)
|
||||
* [七、J.U.C - AQS](<Java 并发.md#七juc---aqs>)
|
||||
* [CountDownLatch](<Java 并发.md#countdownlatch>)
|
||||
* [CyclicBarrier](<Java 并发.md#cyclicbarrier>)
|
||||
* [Semaphore](<Java 并发.md#semaphore>)
|
||||
* [八、J.U.C - 其它组件](<Java 并发.md#八juc---其它组件>)
|
||||
* [FutureTask](<Java 并发.md#futuretask>)
|
||||
* [BlockingQueue](<Java 并发.md#blockingqueue>)
|
||||
* [ForkJoin](<Java 并发.md#forkjoin>)
|
||||
* [九、线程不安全示例](<Java 并发.md#九线程不安全示例>)
|
||||
* [十、Java 内存模型](<Java 并发.md#十java-内存模型>)
|
||||
* [主内存与工作内存](<Java 并发.md#主内存与工作内存>)
|
||||
* [内存间交互操作](<Java 并发.md#内存间交互操作>)
|
||||
* [内存模型三大特性](<Java 并发.md#内存模型三大特性>)
|
||||
* [先行发生原则](<Java 并发.md#先行发生原则>)
|
||||
* [十一、线程安全](<Java 并发.md#十一线程安全>)
|
||||
* [不可变](<Java 并发.md#不可变>)
|
||||
* [互斥同步](<Java 并发.md#互斥同步>)
|
||||
* [非阻塞同步](<Java 并发.md#非阻塞同步>)
|
||||
* [无同步方案](<Java 并发.md#无同步方案>)
|
||||
* [十二、锁优化](<Java 并发.md#十二锁优化>)
|
||||
* [自旋锁](<Java 并发.md#自旋锁>)
|
||||
* [锁消除](<Java 并发.md#锁消除>)
|
||||
* [锁粗化](<Java 并发.md#锁粗化>)
|
||||
* [轻量级锁](<Java 并发.md#轻量级锁>)
|
||||
* [偏向锁](<Java 并发.md#偏向锁>)
|
||||
* [十三、多线程开发良好的实践](<Java 并发.md#十三多线程开发良好的实践>)
|
||||
* [参考资料](<Java 并发.md#参考资料>)
|
||||
|
||||
## 一、使用线程
|
||||
|
||||
有三种使用线程的方法:
|
||||
|
||||
- 实现 Runnable 接口;
|
||||
- 实现 Callable 接口;
|
||||
- 继承 Thread 类。
|
||||
* 实现 Runnable 接口;
|
||||
* 实现 Callable 接口;
|
||||
* 继承 Thread 类。
|
||||
|
||||
实现 Runnable 和 Callable 接口的类只能当做一个可以在线程中运行的任务,不是真正意义上的线程,因此最后还需要通过 Thread 来调用。可以理解为任务是通过线程驱动从而执行的。
|
||||
|
||||
@ -142,8 +139,8 @@ public static void main(String[] args) {
|
||||
|
||||
实现接口会更好一些,因为:
|
||||
|
||||
- Java 不支持多重继承,因此继承了 Thread 类就无法继承其它类,但是可以实现多个接口;
|
||||
- 类可能只要求可执行就行,继承整个 Thread 类开销过大。
|
||||
* Java 不支持多重继承,因此继承了 Thread 类就无法继承其它类,但是可以实现多个接口;
|
||||
* 类可能只要求可执行就行,继承整个 Thread 类开销过大。
|
||||
|
||||
## 二、基础线程机制
|
||||
|
||||
@ -153,9 +150,9 @@ Executor 管理多个异步任务的执行,而无需程序员显式地管理
|
||||
|
||||
主要有三种 Executor:
|
||||
|
||||
- CachedThreadPool:一个任务创建一个线程;
|
||||
- FixedThreadPool:所有任务只能使用固定大小的线程;
|
||||
- SingleThreadExecutor:相当于大小为 1 的 FixedThreadPool。
|
||||
* CachedThreadPool:一个任务创建一个线程;
|
||||
* FixedThreadPool:所有任务只能使用固定大小的线程;
|
||||
* SingleThreadExecutor:相当于大小为 1 的 FixedThreadPool。
|
||||
|
||||
```java
|
||||
public static void main(String[] args) {
|
||||
@ -321,7 +318,7 @@ java.lang.InterruptedException: sleep interrupted
|
||||
at java.lang.Thread.run(Thread.java:745)
|
||||
```
|
||||
|
||||
如果只想中断 Executor 中的一个线程,可以通过使用 submit() 方法来提交一个线程,它会返回一个 Future\<?\> 对象,通过调用该对象的 cancel(true) 方法就可以中断线程。
|
||||
如果只想中断 Executor 中的一个线程,可以通过使用 submit() 方法来提交一个线程,它会返回一个 Future\<?> 对象,通过调用该对象的 cancel(true) 方法就可以中断线程。
|
||||
|
||||
```java
|
||||
Future<?> future = executorService.submit(() -> {
|
||||
@ -336,7 +333,7 @@ Java 提供了两种锁机制来控制多个线程对共享资源的互斥访问
|
||||
|
||||
### synchronized
|
||||
|
||||
**1. 同步一个代码块**
|
||||
**1. 同步一个代码块**
|
||||
|
||||
```java
|
||||
public void func() {
|
||||
@ -392,8 +389,7 @@ public static void main(String[] args) {
|
||||
0 0 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9
|
||||
```
|
||||
|
||||
|
||||
**2. 同步一个方法**
|
||||
**2. 同步一个方法**
|
||||
|
||||
```java
|
||||
public synchronized void func () {
|
||||
@ -403,7 +399,7 @@ public synchronized void func () {
|
||||
|
||||
它和同步代码块一样,作用于同一个对象。
|
||||
|
||||
**3. 同步一个类**
|
||||
**3. 同步一个类**
|
||||
|
||||
```java
|
||||
public void func() {
|
||||
@ -442,7 +438,7 @@ public static void main(String[] args) {
|
||||
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9
|
||||
```
|
||||
|
||||
**4. 同步一个静态方法**
|
||||
**4. 同步一个静态方法**
|
||||
|
||||
```java
|
||||
public synchronized static void fun() {
|
||||
@ -487,30 +483,29 @@ public static void main(String[] args) {
|
||||
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9
|
||||
```
|
||||
|
||||
|
||||
### 比较
|
||||
|
||||
**1. 锁的实现**
|
||||
**1. 锁的实现**
|
||||
|
||||
synchronized 是 JVM 实现的,而 ReentrantLock 是 JDK 实现的。
|
||||
|
||||
**2. 性能**
|
||||
**2. 性能**
|
||||
|
||||
新版本 Java 对 synchronized 进行了很多优化,例如自旋锁等,synchronized 与 ReentrantLock 大致相同。
|
||||
|
||||
**3. 等待可中断**
|
||||
**3. 等待可中断**
|
||||
|
||||
当持有锁的线程长期不释放锁的时候,正在等待的线程可以选择放弃等待,改为处理其他事情。
|
||||
|
||||
ReentrantLock 可中断,而 synchronized 不行。
|
||||
|
||||
**4. 公平锁**
|
||||
**4. 公平锁**
|
||||
|
||||
公平锁是指多个线程在等待同一个锁时,必须按照申请锁的时间顺序来依次获得锁。
|
||||
|
||||
synchronized 中的锁是非公平的,ReentrantLock 默认情况下也是非公平的,但是也可以是公平的。
|
||||
|
||||
**5. 锁绑定多个条件**
|
||||
**5. 锁绑定多个条件**
|
||||
|
||||
一个 ReentrantLock 可以同时绑定多个 Condition 对象。
|
||||
|
||||
@ -621,10 +616,10 @@ before
|
||||
after
|
||||
```
|
||||
|
||||
**wait() 和 sleep() 的区别**
|
||||
**wait() 和 sleep() 的区别**
|
||||
|
||||
- wait() 是 Object 的方法,而 sleep() 是 Thread 的静态方法;
|
||||
- wait() 会释放锁,sleep() 不会。
|
||||
* wait() 是 Object 的方法,而 sleep() 是 Thread 的静态方法;
|
||||
* wait() 会释放锁,sleep() 不会。
|
||||
|
||||
### await() signal() signalAll()
|
||||
|
||||
@ -698,25 +693,25 @@ after
|
||||
|
||||
等待其它线程显式地唤醒。
|
||||
|
||||
阻塞和等待的区别在于,阻塞是被动的,它是在等待获取 monitor lock。而等待是主动的,通过调用 Object.wait() 等方法进入。
|
||||
阻塞和等待的区别在于,阻塞是被动的,它是在等待获取 monitor lock。而等待是主动的,通过调用 Object.wait() 等方法进入。
|
||||
|
||||
| 进入方法 | 退出方法 |
|
||||
| --- | --- |
|
||||
| 进入方法 | 退出方法 |
|
||||
| --------------------------------- | ------------------------------------ |
|
||||
| 没有设置 Timeout 参数的 Object.wait() 方法 | Object.notify() / Object.notifyAll() |
|
||||
| 没有设置 Timeout 参数的 Thread.join() 方法 | 被调用的线程执行完毕 |
|
||||
| LockSupport.park() 方法 | LockSupport.unpark(Thread) |
|
||||
| 没有设置 Timeout 参数的 Thread.join() 方法 | 被调用的线程执行完毕 |
|
||||
| LockSupport.park() 方法 | LockSupport.unpark(Thread) |
|
||||
|
||||
### 限期等待(TIMED_WAITING)
|
||||
### 限期等待(TIMED\_WAITING)
|
||||
|
||||
无需等待其它线程显式地唤醒,在一定时间之后会被系统自动唤醒。
|
||||
|
||||
| 进入方法 | 退出方法 |
|
||||
| --- | --- |
|
||||
| Thread.sleep() 方法 | 时间结束 |
|
||||
| 设置了 Timeout 参数的 Object.wait() 方法 | 时间结束 / Object.notify() / Object.notifyAll() |
|
||||
| 设置了 Timeout 参数的 Thread.join() 方法 | 时间结束 / 被调用的线程执行完毕 |
|
||||
| LockSupport.parkNanos() 方法 | LockSupport.unpark(Thread) |
|
||||
| LockSupport.parkUntil() 方法 | LockSupport.unpark(Thread) |
|
||||
| 进入方法 | 退出方法 |
|
||||
| -------------------------------- | ------------------------------------------- |
|
||||
| Thread.sleep() 方法 | 时间结束 |
|
||||
| 设置了 Timeout 参数的 Object.wait() 方法 | 时间结束 / Object.notify() / Object.notifyAll() |
|
||||
| 设置了 Timeout 参数的 Thread.join() 方法 | 时间结束 / 被调用的线程执行完毕 |
|
||||
| LockSupport.parkNanos() 方法 | LockSupport.unpark(Thread) |
|
||||
| LockSupport.parkUntil() 方法 | LockSupport.unpark(Thread) |
|
||||
|
||||
调用 Thread.sleep() 方法使线程进入限期等待状态时,常常用“使一个线程睡眠”进行描述。调用 Object.wait() 方法使线程进入限期等待或者无限期等待时,常常用“挂起一个线程”进行描述。睡眠和挂起是用来描述行为,而阻塞和等待用来描述状态。
|
||||
|
||||
@ -736,7 +731,8 @@ java.util.concurrent(J.U.C)大大提高了并发性能,AQS 被认为是 J.
|
||||
|
||||
维护了一个计数器 cnt,每次调用 countDown() 方法会让计数器的值减 1,减到 0 的时候,那些因为调用 await() 方法而在等待的线程就会被唤醒。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/ba078291-791e-4378-b6d1-ece76c2f0b14.png" width="300px"> </div><br>
|
||||
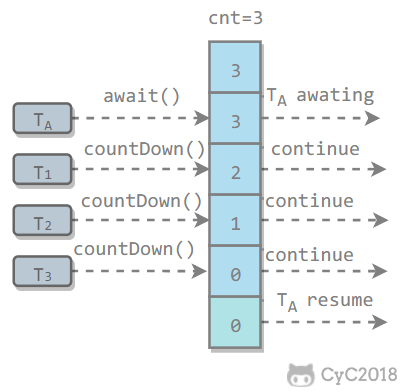\
|
||||
|
||||
|
||||
```java
|
||||
public class CountdownLatchExample {
|
||||
@ -785,7 +781,8 @@ public CyclicBarrier(int parties) {
|
||||
}
|
||||
```
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/f71af66b-0d54-4399-a44b-f47b58321984.png" width="300px"> </div><br>
|
||||
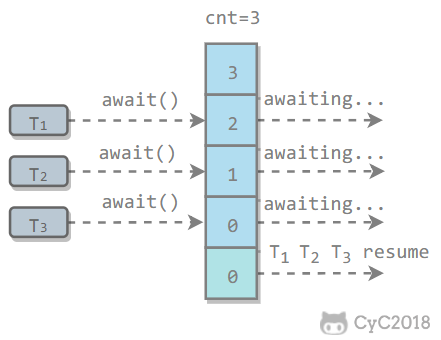\
|
||||
|
||||
|
||||
```java
|
||||
public class CyclicBarrierExample {
|
||||
@ -853,7 +850,7 @@ public class SemaphoreExample {
|
||||
|
||||
### FutureTask
|
||||
|
||||
在介绍 Callable 时我们知道它可以有返回值,返回值通过 Future\<V\> 进行封装。FutureTask 实现了 RunnableFuture 接口,该接口继承自 Runnable 和 Future\<V\> 接口,这使得 FutureTask 既可以当做一个任务执行,也可以有返回值。
|
||||
在介绍 Callable 时我们知道它可以有返回值,返回值通过 Future\<V> 进行封装。FutureTask 实现了 RunnableFuture 接口,该接口继承自 Runnable 和 Future\<V> 接口,这使得 FutureTask 既可以当做一个任务执行,也可以有返回值。
|
||||
|
||||
```java
|
||||
public class FutureTask<V> implements RunnableFuture<V>
|
||||
@ -907,12 +904,12 @@ other task is running...
|
||||
|
||||
java.util.concurrent.BlockingQueue 接口有以下阻塞队列的实现:
|
||||
|
||||
- **FIFO 队列** :LinkedBlockingQueue、ArrayBlockingQueue(固定长度)
|
||||
- **优先级队列** :PriorityBlockingQueue
|
||||
* **FIFO 队列** :LinkedBlockingQueue、ArrayBlockingQueue(固定长度)
|
||||
* **优先级队列** :PriorityBlockingQueue
|
||||
|
||||
提供了阻塞的 take() 和 put() 方法:如果队列为空 take() 将阻塞,直到队列中有内容;如果队列为满 put() 将阻塞,直到队列有空闲位置。
|
||||
|
||||
**使用 BlockingQueue 实现生产者消费者问题**
|
||||
**使用 BlockingQueue 实现生产者消费者问题**
|
||||
|
||||
```java
|
||||
public class ProducerConsumer {
|
||||
@ -1022,7 +1019,8 @@ public class ForkJoinPool extends AbstractExecutorService
|
||||
|
||||
ForkJoinPool 实现了工作窃取算法来提高 CPU 的利用率。每个线程都维护了一个双端队列,用来存储需要执行的任务。工作窃取算法允许空闲的线程从其它线程的双端队列中窃取一个任务来执行。窃取的任务必须是最晚的任务,避免和队列所属线程发生竞争。例如下图中,Thread2 从 Thread1 的队列中拿出最晚的 Task1 任务,Thread1 会拿出 Task2 来执行,这样就避免发生竞争。但是如果队列中只有一个任务时还是会发生竞争。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/e42f188f-f4a9-4e6f-88fc-45f4682072fb.png" width="300px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 九、线程不安全示例
|
||||
|
||||
@ -1077,28 +1075,31 @@ Java 内存模型试图屏蔽各种硬件和操作系统的内存访问差异,
|
||||
|
||||
加入高速缓存带来了一个新的问题:缓存一致性。如果多个缓存共享同一块主内存区域,那么多个缓存的数据可能会不一致,需要一些协议来解决这个问题。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/942ca0d2-9d5c-45a4-89cb-5fd89b61913f.png" width="600px"> </div><br>
|
||||
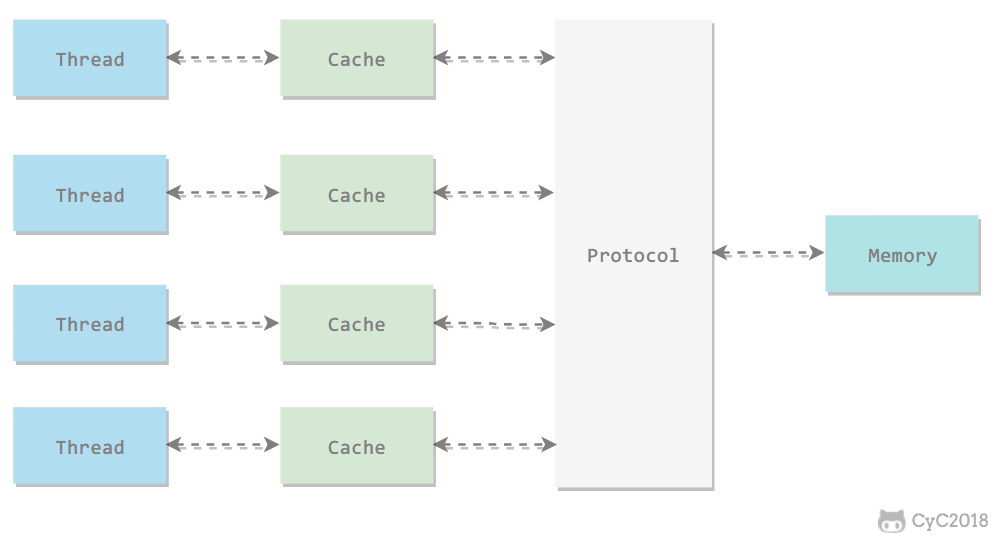\
|
||||
|
||||
|
||||
所有的变量都存储在主内存中,每个线程还有自己的工作内存,工作内存存储在高速缓存或者寄存器中,保存了该线程使用的变量的主内存副本拷贝。
|
||||
|
||||
线程只能直接操作工作内存中的变量,不同线程之间的变量值传递需要通过主内存来完成。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/15851555-5abc-497d-ad34-efed10f43a6b.png" width="600px"> </div><br>
|
||||
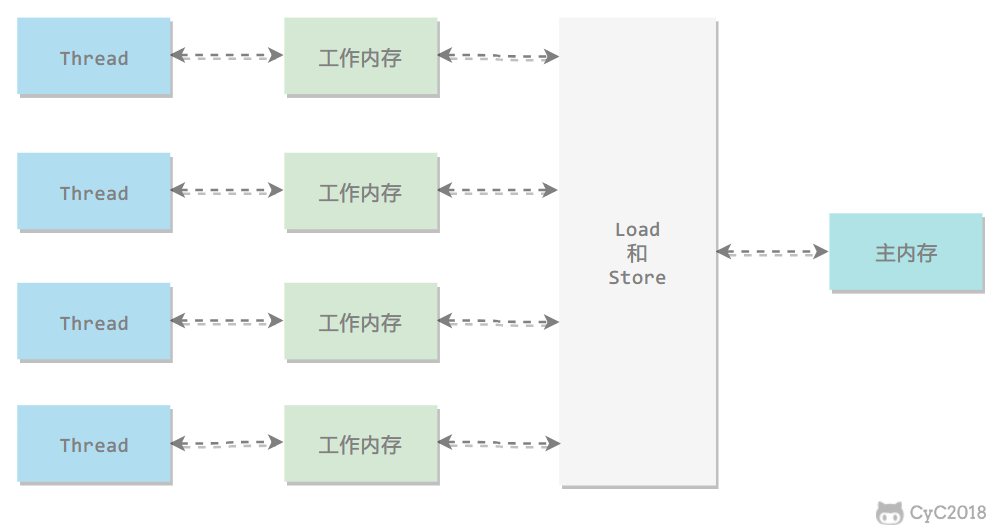\
|
||||
|
||||
|
||||
### 内存间交互操作
|
||||
|
||||
Java 内存模型定义了 8 个操作来完成主内存和工作内存的交互操作。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/8b7ebbad-9604-4375-84e3-f412099d170c.png" width="450px"> </div><br>
|
||||
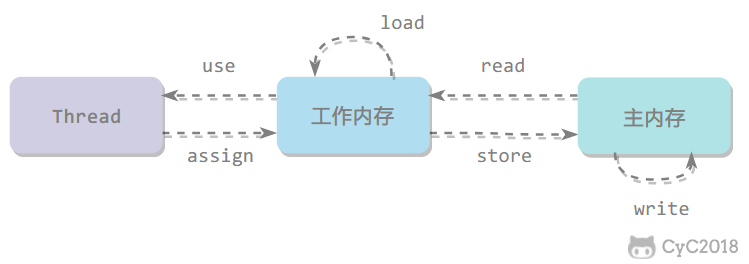\
|
||||
|
||||
- read:把一个变量的值从主内存传输到工作内存中
|
||||
- load:在 read 之后执行,把 read 得到的值放入工作内存的变量副本中
|
||||
- use:把工作内存中一个变量的值传递给执行引擎
|
||||
- assign:把一个从执行引擎接收到的值赋给工作内存的变量
|
||||
- store:把工作内存的一个变量的值传送到主内存中
|
||||
- write:在 store 之后执行,把 store 得到的值放入主内存的变量中
|
||||
- lock:作用于主内存的变量
|
||||
- unlock
|
||||
|
||||
* read:把一个变量的值从主内存传输到工作内存中
|
||||
* load:在 read 之后执行,把 read 得到的值放入工作内存的变量副本中
|
||||
* use:把工作内存中一个变量的值传递给执行引擎
|
||||
* assign:把一个从执行引擎接收到的值赋给工作内存的变量
|
||||
* store:把工作内存的一个变量的值传送到主内存中
|
||||
* write:在 store 之后执行,把 store 得到的值放入主内存的变量中
|
||||
* lock:作用于主内存的变量
|
||||
* unlock
|
||||
|
||||
### 内存模型三大特性
|
||||
|
||||
@ -1112,11 +1113,13 @@ Java 内存模型保证了 read、load、use、assign、store、write、lock 和
|
||||
|
||||
下图演示了两个线程同时对 cnt 进行操作,load、assign、store 这一系列操作整体上看不具备原子性,那么在 T1 修改 cnt 并且还没有将修改后的值写入主内存,T2 依然可以读入旧值。可以看出,这两个线程虽然执行了两次自增运算,但是主内存中 cnt 的值最后为 1 而不是 2。因此对 int 类型读写操作满足原子性只是说明 load、assign、store 这些单个操作具备原子性。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/2797a609-68db-4d7b-8701-41ac9a34b14f.jpg" width="300px"> </div><br>
|
||||
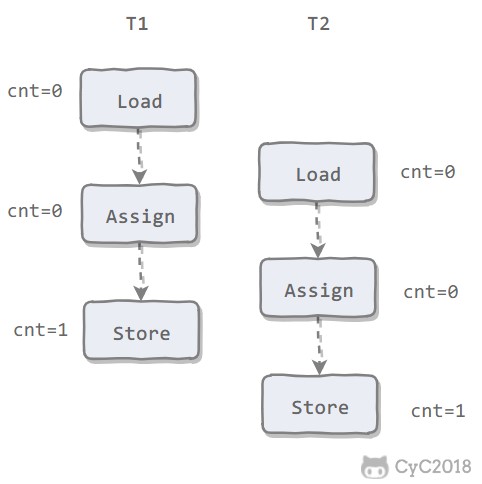\
|
||||
|
||||
|
||||
AtomicInteger 能保证多个线程修改的原子性。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/dd563037-fcaa-4bd8-83b6-b39d93a12c77.jpg" width="300px"> </div><br>
|
||||
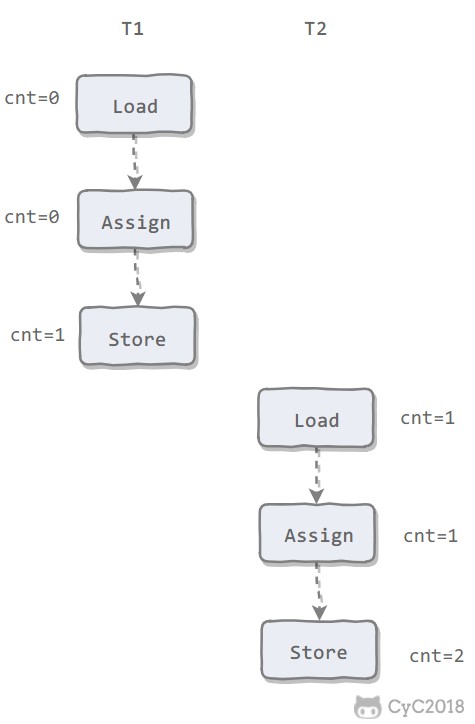\
|
||||
|
||||
|
||||
使用 AtomicInteger 重写之前线程不安全的代码之后得到以下线程安全实现:
|
||||
|
||||
@ -1200,9 +1203,9 @@ public static void main(String[] args) throws InterruptedException {
|
||||
|
||||
主要有三种实现可见性的方式:
|
||||
|
||||
- volatile
|
||||
- synchronized,对一个变量执行 unlock 操作之前,必须把变量值同步回主内存。
|
||||
- final,被 final 关键字修饰的字段在构造器中一旦初始化完成,并且没有发生 this 逃逸(其它线程通过 this 引用访问到初始化了一半的对象),那么其它线程就能看见 final 字段的值。
|
||||
* volatile
|
||||
* synchronized,对一个变量执行 unlock 操作之前,必须把变量值同步回主内存。
|
||||
* final,被 final 关键字修饰的字段在构造器中一旦初始化完成,并且没有发生 this 逃逸(其它线程通过 this 引用访问到初始化了一半的对象),那么其它线程就能看见 final 字段的值。
|
||||
|
||||
对前面的线程不安全示例中的 cnt 变量使用 volatile 修饰,不能解决线程不安全问题,因为 volatile 并不能保证操作的原子性。
|
||||
|
||||
@ -1224,7 +1227,8 @@ volatile 关键字通过添加内存屏障的方式来禁止指令重排,即
|
||||
|
||||
在一个线程内,在程序前面的操作先行发生于后面的操作。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/874b3ff7-7c5c-4e7a-b8ab-a82a3e038d20.png" width="180px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
#### 2. 管程锁定规则
|
||||
|
||||
@ -1232,7 +1236,8 @@ volatile 关键字通过添加内存屏障的方式来禁止指令重排,即
|
||||
|
||||
一个 unlock 操作先行发生于后面对同一个锁的 lock 操作。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/8996a537-7c4a-4ec8-a3b7-7ef1798eae26.png" width="350px"> </div><br>
|
||||
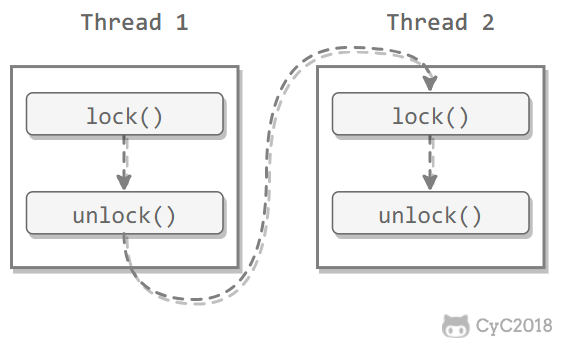\
|
||||
|
||||
|
||||
#### 3. volatile 变量规则
|
||||
|
||||
@ -1240,7 +1245,8 @@ volatile 关键字通过添加内存屏障的方式来禁止指令重排,即
|
||||
|
||||
对一个 volatile 变量的写操作先行发生于后面对这个变量的读操作。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/942f33c9-8ad9-4987-836f-007de4c21de0.png" width="400px"> </div><br>
|
||||
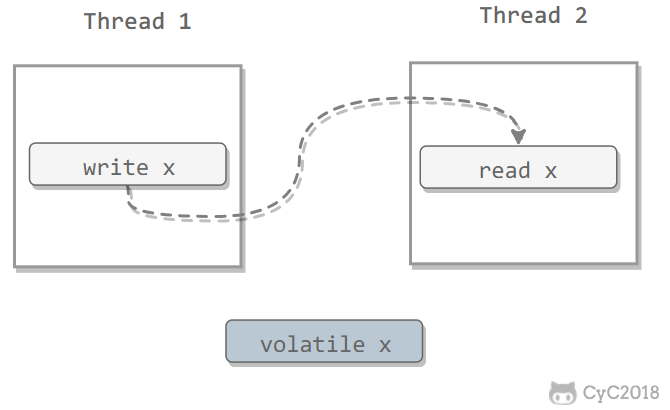\
|
||||
|
||||
|
||||
#### 4. 线程启动规则
|
||||
|
||||
@ -1248,7 +1254,8 @@ volatile 关键字通过添加内存屏障的方式来禁止指令重排,即
|
||||
|
||||
Thread 对象的 start() 方法调用先行发生于此线程的每一个动作。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/6270c216-7ec0-4db7-94de-0003bce37cd2.png" width="380px"> </div><br>
|
||||
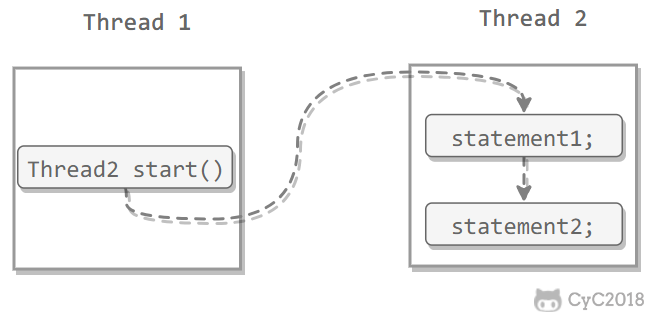\
|
||||
|
||||
|
||||
#### 5. 线程加入规则
|
||||
|
||||
@ -1256,7 +1263,8 @@ Thread 对象的 start() 方法调用先行发生于此线程的每一个动作
|
||||
|
||||
Thread 对象的结束先行发生于 join() 方法返回。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/233f8d89-31d7-413f-9c02-042f19c46ba1.png" width="400px"> </div><br>
|
||||
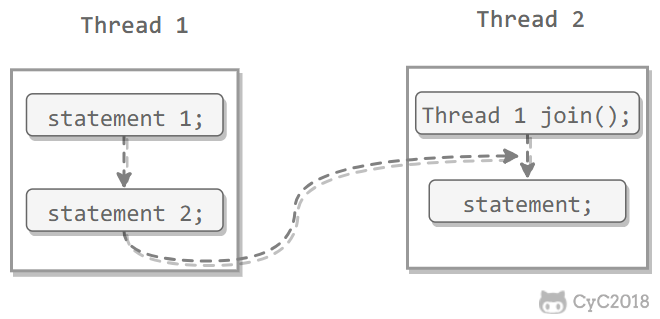\
|
||||
|
||||
|
||||
#### 6. 线程中断规则
|
||||
|
||||
@ -1288,10 +1296,10 @@ Thread 对象的结束先行发生于 join() 方法返回。
|
||||
|
||||
不可变的类型:
|
||||
|
||||
- final 关键字修饰的基本数据类型
|
||||
- String
|
||||
- 枚举类型
|
||||
- Number 部分子类,如 Long 和 Double 等数值包装类型,BigInteger 和 BigDecimal 等大数据类型。但同为 Number 的原子类 AtomicInteger 和 AtomicLong 则是可变的。
|
||||
* final 关键字修饰的基本数据类型
|
||||
* String
|
||||
* 枚举类型
|
||||
* Number 部分子类,如 Long 和 Double 等数值包装类型,BigInteger 和 BigDecimal 等大数据类型。但同为 Number 的原子类 AtomicInteger 和 AtomicLong 则是可变的。
|
||||
|
||||
对于集合类型,可以使用 Collections.unmodifiableXXX() 方法来获取一个不可变的集合。
|
||||
|
||||
@ -1474,7 +1482,8 @@ public class ThreadLocalExample1 {
|
||||
|
||||
它所对应的底层结构图为:
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/6782674c-1bfe-4879-af39-e9d722a95d39.png" width="500px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
每个 Thread 都有一个 ThreadLocal.ThreadLocalMap 对象。
|
||||
|
||||
@ -1484,7 +1493,7 @@ public class ThreadLocalExample1 {
|
||||
ThreadLocal.ThreadLocalMap threadLocals = null;
|
||||
```
|
||||
|
||||
当调用一个 ThreadLocal 的 set(T value) 方法时,先得到当前线程的 ThreadLocalMap 对象,然后将 ThreadLocal-\>value 键值对插入到该 Map 中。
|
||||
当调用一个 ThreadLocal 的 set(T value) 方法时,先得到当前线程的 ThreadLocalMap 对象,然后将 ThreadLocal->value 键值对插入到该 Map 中。
|
||||
|
||||
```java
|
||||
public void set(T value) {
|
||||
@ -1577,17 +1586,20 @@ JDK 1.6 引入了偏向锁和轻量级锁,从而让锁拥有了四个状态:
|
||||
|
||||
以下是 HotSpot 虚拟机对象头的内存布局,这些数据被称为 Mark Word。其中 tag bits 对应了五个状态,这些状态在右侧的 state 表格中给出。除了 marked for gc 状态,其它四个状态已经在前面介绍过了。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/bb6a49be-00f2-4f27-a0ce-4ed764bc605c.png" width="500"/> </div><br>
|
||||
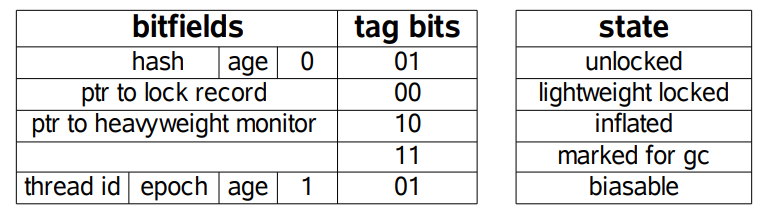\
|
||||
|
||||
|
||||
下图左侧是一个线程的虚拟机栈,其中有一部分称为 Lock Record 的区域,这是在轻量级锁运行过程创建的,用于存放锁对象的 Mark Word。而右侧就是一个锁对象,包含了 Mark Word 和其它信息。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/051e436c-0e46-4c59-8f67-52d89d656182.png" width="500"/> </div><br>
|
||||
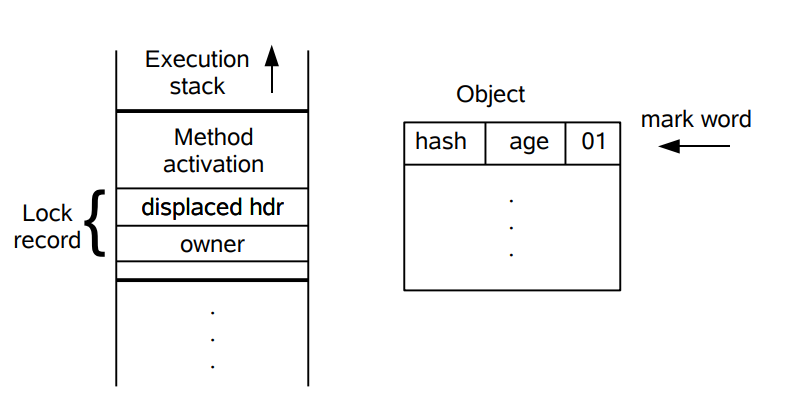\
|
||||
|
||||
|
||||
轻量级锁是相对于传统的重量级锁而言,它使用 CAS 操作来避免重量级锁使用互斥量的开销。对于绝大部分的锁,在整个同步周期内都是不存在竞争的,因此也就不需要都使用互斥量进行同步,可以先采用 CAS 操作进行同步,如果 CAS 失败了再改用互斥量进行同步。
|
||||
|
||||
当尝试获取一个锁对象时,如果锁对象标记为 0 01,说明锁对象的锁未锁定(unlocked)状态。此时虚拟机在当前线程的虚拟机栈中创建 Lock Record,然后使用 CAS 操作将对象的 Mark Word 更新为 Lock Record 指针。如果 CAS 操作成功了,那么线程就获取了该对象上的锁,并且对象的 Mark Word 的锁标记变为 00,表示该对象处于轻量级锁状态。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/baaa681f-7c52-4198-a5ae-303b9386cf47.png" width="400"/> </div><br>
|
||||
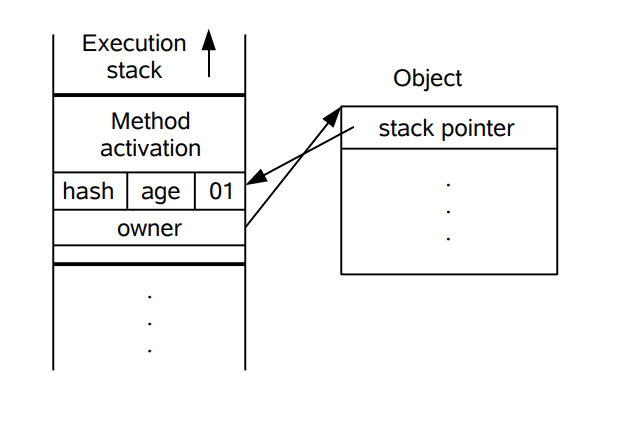\
|
||||
|
||||
|
||||
如果 CAS 操作失败了,虚拟机首先会检查对象的 Mark Word 是否指向当前线程的虚拟机栈,如果是的话说明当前线程已经拥有了这个锁对象,那就可以直接进入同步块继续执行,否则说明这个锁对象已经被其他线程线程抢占了。如果有两条以上的线程争用同一个锁,那轻量级锁就不再有效,要膨胀为重量级锁。
|
||||
|
||||
@ -1599,38 +1611,33 @@ JDK 1.6 引入了偏向锁和轻量级锁,从而让锁拥有了四个状态:
|
||||
|
||||
当有另外一个线程去尝试获取这个锁对象时,偏向状态就宣告结束,此时撤销偏向(Revoke Bias)后恢复到未锁定状态或者轻量级锁状态。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/390c913b-5f31-444f-bbdb-2b88b688e7ce.jpg" width="600"/> </div><br>
|
||||
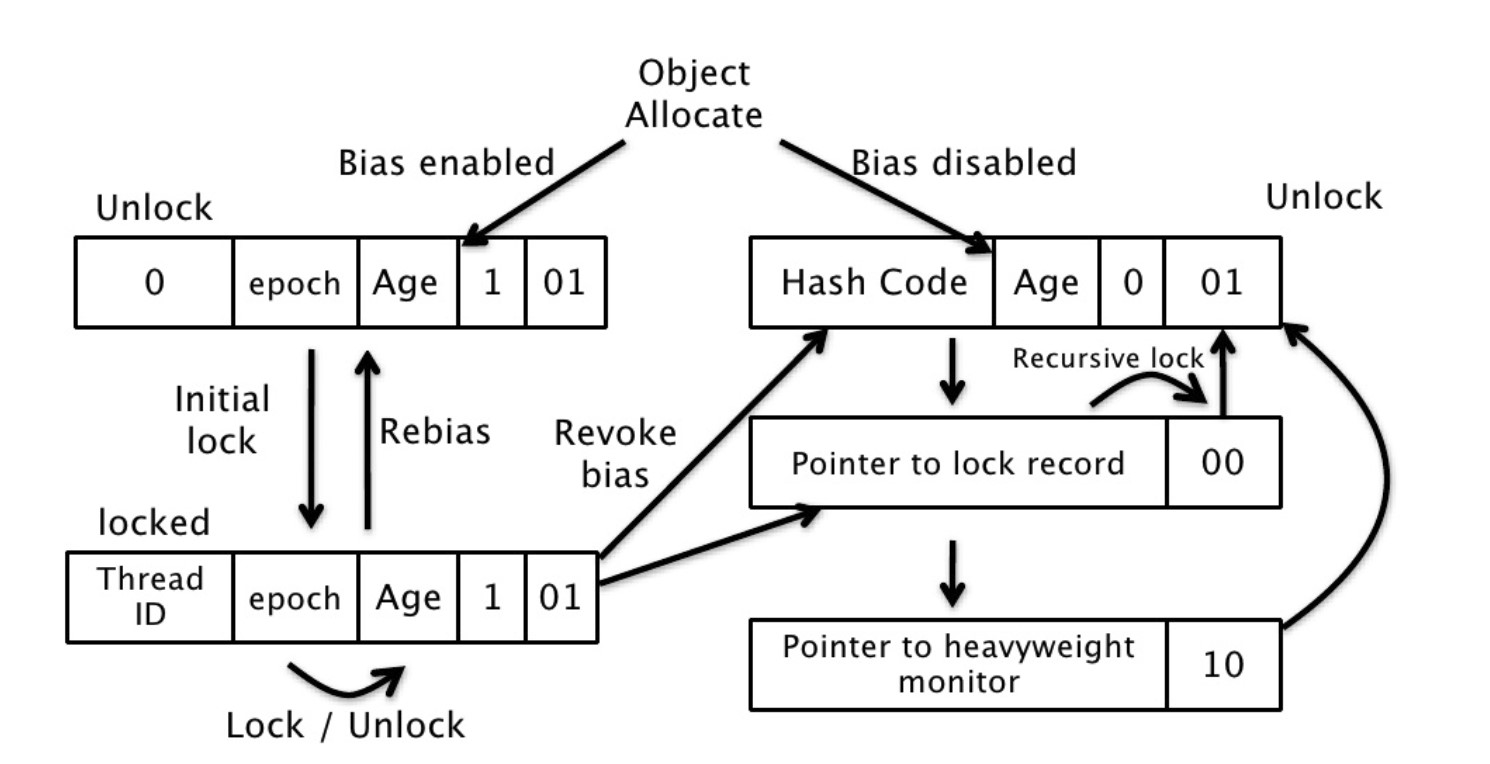\
|
||||
|
||||
|
||||
## 十三、多线程开发良好的实践
|
||||
|
||||
- 给线程起个有意义的名字,这样可以方便找 Bug。
|
||||
|
||||
- 缩小同步范围,从而减少锁争用。例如对于 synchronized,应该尽量使用同步块而不是同步方法。
|
||||
|
||||
- 多用同步工具少用 wait() 和 notify()。首先,CountDownLatch, CyclicBarrier, Semaphore 和 Exchanger 这些同步类简化了编码操作,而用 wait() 和 notify() 很难实现复杂控制流;其次,这些同步类是由最好的企业编写和维护,在后续的 JDK 中还会不断优化和完善。
|
||||
|
||||
- 使用 BlockingQueue 实现生产者消费者问题。
|
||||
|
||||
- 多用并发集合少用同步集合,例如应该使用 ConcurrentHashMap 而不是 Hashtable。
|
||||
|
||||
- 使用本地变量和不可变类来保证线程安全。
|
||||
|
||||
- 使用线程池而不是直接创建线程,这是因为创建线程代价很高,线程池可以有效地利用有限的线程来启动任务。
|
||||
* 给线程起个有意义的名字,这样可以方便找 Bug。
|
||||
* 缩小同步范围,从而减少锁争用。例如对于 synchronized,应该尽量使用同步块而不是同步方法。
|
||||
* 多用同步工具少用 wait() 和 notify()。首先,CountDownLatch, CyclicBarrier, Semaphore 和 Exchanger 这些同步类简化了编码操作,而用 wait() 和 notify() 很难实现复杂控制流;其次,这些同步类是由最好的企业编写和维护,在后续的 JDK 中还会不断优化和完善。
|
||||
* 使用 BlockingQueue 实现生产者消费者问题。
|
||||
* 多用并发集合少用同步集合,例如应该使用 ConcurrentHashMap 而不是 Hashtable。
|
||||
* 使用本地变量和不可变类来保证线程安全。
|
||||
* 使用线程池而不是直接创建线程,这是因为创建线程代价很高,线程池可以有效地利用有限的线程来启动任务。
|
||||
|
||||
## 参考资料
|
||||
|
||||
- BruceEckel. Java 编程思想: 第 4 版 [M]. 机械工业出版社, 2007.
|
||||
- 周志明. 深入理解 Java 虚拟机 [M]. 机械工业出版社, 2011.
|
||||
- [Threads and Locks](https://docs.oracle.com/javase/specs/jvms/se6/html/Threads.doc.html)
|
||||
- [线程通信](http://ifeve.com/thread-signaling/#missed_signal)
|
||||
- [Java 线程面试题 Top 50](http://www.importnew.com/12773.html)
|
||||
- [BlockingQueue](http://tutorials.jenkov.com/java-util-concurrent/blockingqueue.html)
|
||||
- [thread state java](https://stackoverflow.com/questions/11265289/thread-state-java)
|
||||
- [CSC 456 Spring 2012/ch7 MN](http://wiki.expertiza.ncsu.edu/index.php/CSC_456_Spring_2012/ch7_MN)
|
||||
- [Java - Understanding Happens-before relationship](https://www.logicbig.com/tutorials/core-java-tutorial/java-multi-threading/happens-before.html)
|
||||
- [6장 Thread Synchronization](https://www.slideshare.net/novathinker/6-thread-synchronization)
|
||||
- [How is Java's ThreadLocal implemented under the hood?](https://stackoverflow.com/questions/1202444/how-is-javas-threadlocal-implemented-under-the-hood/15653015)
|
||||
- [Concurrent](https://sites.google.com/site/webdevelopart/21-compile/06-java/javase/concurrent?tmpl=%2Fsystem%2Fapp%2Ftemplates%2Fprint%2F&showPrintDialog=1)
|
||||
- [JAVA FORK JOIN EXAMPLE](http://www.javacreed.com/java-fork-join-example/ "Java Fork Join Example")
|
||||
- [聊聊并发(八)——Fork/Join 框架介绍](http://ifeve.com/talk-concurrency-forkjoin/)
|
||||
- [Eliminating SynchronizationRelated Atomic Operations with Biased Locking and Bulk Rebiasing](http://www.oracle.com/technetwork/java/javase/tech/biasedlocking-oopsla2006-preso-150106.pdf)
|
||||
* BruceEckel. Java 编程思想: 第 4 版 \[M]. 机械工业出版社, 2007.
|
||||
* 周志明. 深入理解 Java 虚拟机 \[M]. 机械工业出版社, 2011.
|
||||
* [Threads and Locks](https://docs.oracle.com/javase/specs/jvms/se6/html/Threads.doc.html)
|
||||
* [线程通信](http://ifeve.com/thread-signaling/#missed\_signal)
|
||||
* [Java 线程面试题 Top 50](http://www.importnew.com/12773.html)
|
||||
* [BlockingQueue](http://tutorials.jenkov.com/java-util-concurrent/blockingqueue.html)
|
||||
* [thread state java](https://stackoverflow.com/questions/11265289/thread-state-java)
|
||||
* [CSC 456 Spring 2012/ch7 MN](http://wiki.expertiza.ncsu.edu/index.php/CSC\_456\_Spring\_2012/ch7\_MN)
|
||||
* [Java - Understanding Happens-before relationship](https://www.logicbig.com/tutorials/core-java-tutorial/java-multi-threading/happens-before.html)
|
||||
* [6장 Thread Synchronization](https://www.slideshare.net/novathinker/6-thread-synchronization)
|
||||
* [How is Java's ThreadLocal implemented under the hood?](https://stackoverflow.com/questions/1202444/how-is-javas-threadlocal-implemented-under-the-hood/15653015)
|
||||
* [Concurrent](https://sites.google.com/site/webdevelopart/21-compile/06-java/javase/concurrent?tmpl=%2Fsystem%2Fapp%2Ftemplates%2Fprint%2F\&showPrintDialog=1)
|
||||
* [JAVA FORK JOIN EXAMPLE](http://www.javacreed.com/java-fork-join-example/)
|
||||
* [聊聊并发(八)——Fork/Join 框架介绍](http://ifeve.com/talk-concurrency-forkjoin/)
|
||||
* [Eliminating SynchronizationRelated Atomic Operations with Biased Locking and Bulk Rebiasing](http://www.oracle.com/technetwork/java/javase/tech/biasedlocking-oopsla2006-preso-150106.pdf)
|
||||
|
||||
@ -1,40 +1,39 @@
|
||||
# Java 虚拟机
|
||||
<!-- GFM-TOC -->
|
||||
* [Java 虚拟机](#java-虚拟机)
|
||||
* [一、运行时数据区域](#一运行时数据区域)
|
||||
* [程序计数器](#程序计数器)
|
||||
* [Java 虚拟机栈](#java-虚拟机栈)
|
||||
* [本地方法栈](#本地方法栈)
|
||||
* [堆](#堆)
|
||||
* [方法区](#方法区)
|
||||
* [运行时常量池](#运行时常量池)
|
||||
* [直接内存](#直接内存)
|
||||
* [二、垃圾收集](#二垃圾收集)
|
||||
* [判断一个对象是否可被回收](#判断一个对象是否可被回收)
|
||||
* [引用类型](#引用类型)
|
||||
* [垃圾收集算法](#垃圾收集算法)
|
||||
* [垃圾收集器](#垃圾收集器)
|
||||
* [三、内存分配与回收策略](#三内存分配与回收策略)
|
||||
* [Minor GC 和 Full GC](#minor-gc-和-full-gc)
|
||||
* [内存分配策略](#内存分配策略)
|
||||
* [Full GC 的触发条件](#full-gc-的触发条件)
|
||||
* [四、类加载机制](#四类加载机制)
|
||||
* [类的生命周期](#类的生命周期)
|
||||
* [类加载过程](#类加载过程)
|
||||
* [类初始化时机](#类初始化时机)
|
||||
* [类与类加载器](#类与类加载器)
|
||||
* [类加载器分类](#类加载器分类)
|
||||
* [双亲委派模型](#双亲委派模型)
|
||||
* [自定义类加载器实现](#自定义类加载器实现)
|
||||
* [参考资料](#参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [Java 虚拟机](<Java 虚拟机.md#java-虚拟机>)
|
||||
* [一、运行时数据区域](<Java 虚拟机.md#一运行时数据区域>)
|
||||
* [程序计数器](<Java 虚拟机.md#程序计数器>)
|
||||
* [Java 虚拟机栈](<Java 虚拟机.md#java-虚拟机栈>)
|
||||
* [本地方法栈](<Java 虚拟机.md#本地方法栈>)
|
||||
* [堆](<Java 虚拟机.md#堆>)
|
||||
* [方法区](<Java 虚拟机.md#方法区>)
|
||||
* [运行时常量池](<Java 虚拟机.md#运行时常量池>)
|
||||
* [直接内存](<Java 虚拟机.md#直接内存>)
|
||||
* [二、垃圾收集](<Java 虚拟机.md#二垃圾收集>)
|
||||
* [判断一个对象是否可被回收](<Java 虚拟机.md#判断一个对象是否可被回收>)
|
||||
* [引用类型](<Java 虚拟机.md#引用类型>)
|
||||
* [垃圾收集算法](<Java 虚拟机.md#垃圾收集算法>)
|
||||
* [垃圾收集器](<Java 虚拟机.md#垃圾收集器>)
|
||||
* [三、内存分配与回收策略](<Java 虚拟机.md#三内存分配与回收策略>)
|
||||
* [Minor GC 和 Full GC](<Java 虚拟机.md#minor-gc-和-full-gc>)
|
||||
* [内存分配策略](<Java 虚拟机.md#内存分配策略>)
|
||||
* [Full GC 的触发条件](<Java 虚拟机.md#full-gc-的触发条件>)
|
||||
* [四、类加载机制](<Java 虚拟机.md#四类加载机制>)
|
||||
* [类的生命周期](<Java 虚拟机.md#类的生命周期>)
|
||||
* [类加载过程](<Java 虚拟机.md#类加载过程>)
|
||||
* [类初始化时机](<Java 虚拟机.md#类初始化时机>)
|
||||
* [类与类加载器](<Java 虚拟机.md#类与类加载器>)
|
||||
* [类加载器分类](<Java 虚拟机.md#类加载器分类>)
|
||||
* [双亲委派模型](<Java 虚拟机.md#双亲委派模型>)
|
||||
* [自定义类加载器实现](<Java 虚拟机.md#自定义类加载器实现>)
|
||||
* [参考资料](<Java 虚拟机.md#参考资料>)
|
||||
|
||||
本文大部分内容参考 **周志明《深入理解 Java 虚拟机》** ,想要深入学习的话请看原书。
|
||||
本文大部分内容参考 **周志明《深入理解 Java 虚拟机》** ,想要深入学习的话请看原书。
|
||||
|
||||
## 一、运行时数据区域
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/5778d113-8e13-4c53-b5bf-801e58080b97.png" width="400px"> </div><br>
|
||||
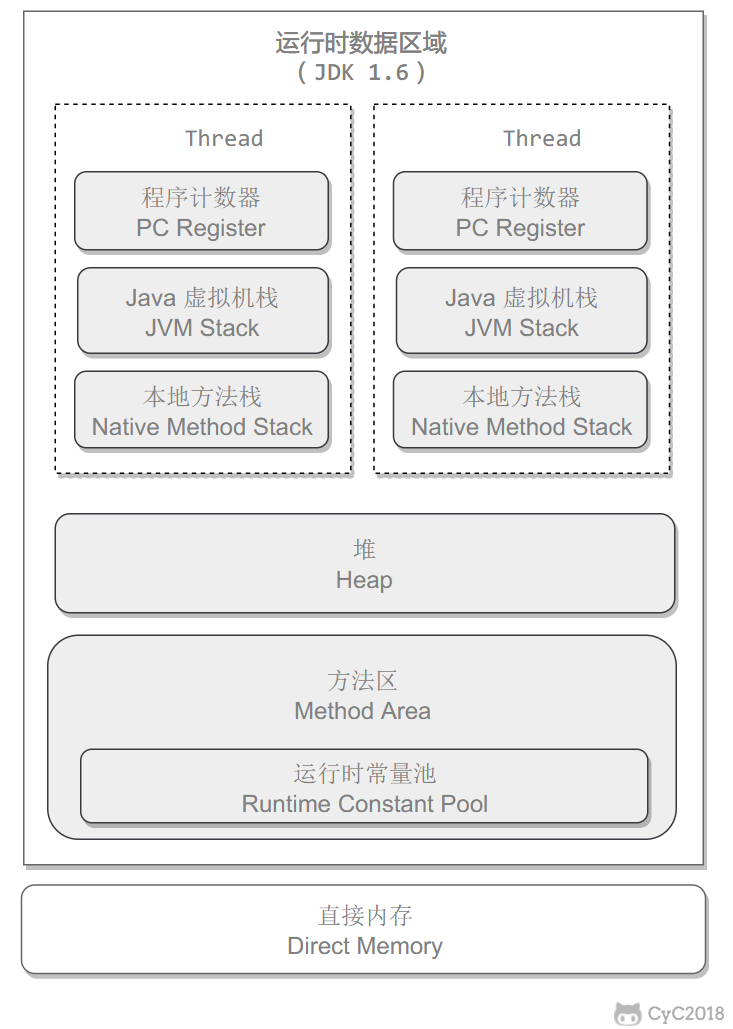\
|
||||
|
||||
|
||||
### 程序计数器
|
||||
|
||||
@ -44,7 +43,8 @@
|
||||
|
||||
每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、常量池引用等信息。从方法调用直至执行完成的过程,对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/8442519f-0b4d-48f4-8229-56f984363c69.png" width="400px"> </div><br>
|
||||
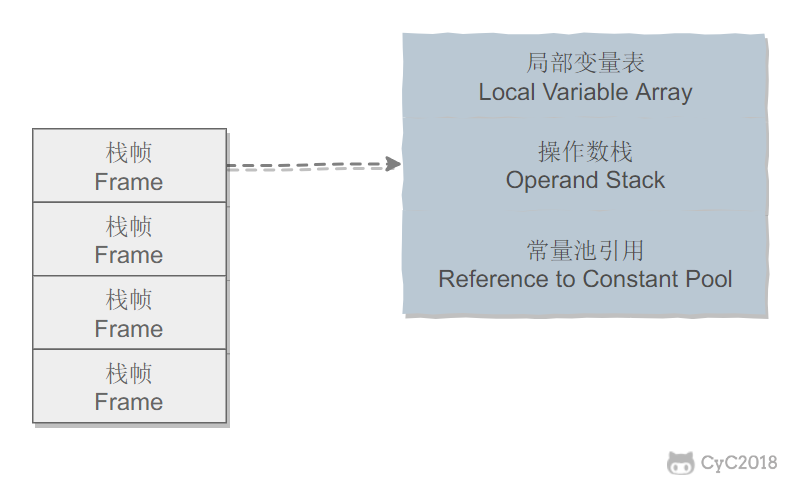\
|
||||
|
||||
|
||||
可以通过 -Xss 这个虚拟机参数来指定每个线程的 Java 虚拟机栈内存大小,在 JDK 1.4 中默认为 256K,而在 JDK 1.5+ 默认为 1M:
|
||||
|
||||
@ -54,8 +54,8 @@ java -Xss2M HackTheJava
|
||||
|
||||
该区域可能抛出以下异常:
|
||||
|
||||
- 当线程请求的栈深度超过最大值,会抛出 StackOverflowError 异常;
|
||||
- 栈进行动态扩展时如果无法申请到足够内存,会抛出 OutOfMemoryError 异常。
|
||||
* 当线程请求的栈深度超过最大值,会抛出 StackOverflowError 异常;
|
||||
* 栈进行动态扩展时如果无法申请到足够内存,会抛出 OutOfMemoryError 异常。
|
||||
|
||||
### 本地方法栈
|
||||
|
||||
@ -63,7 +63,8 @@ java -Xss2M HackTheJava
|
||||
|
||||
本地方法一般是用其它语言(C、C++ 或汇编语言等)编写的,并且被编译为基于本机硬件和操作系统的程序,对待这些方法需要特别处理。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/66a6899d-c6b0-4a47-8569-9d08f0baf86c.png" width="300px"> </div><br>
|
||||
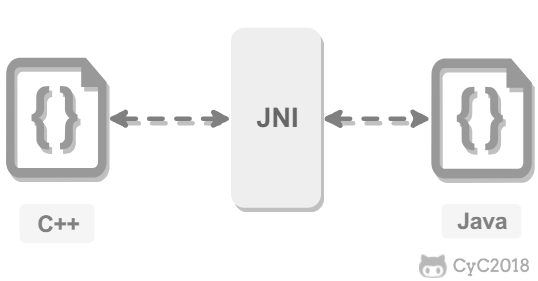\
|
||||
|
||||
|
||||
### 堆
|
||||
|
||||
@ -71,8 +72,8 @@ java -Xss2M HackTheJava
|
||||
|
||||
现代的垃圾收集器基本都是采用分代收集算法,其主要的思想是针对不同类型的对象采取不同的垃圾回收算法。可以将堆分成两块:
|
||||
|
||||
- 新生代(Young Generation)
|
||||
- 老年代(Old Generation)
|
||||
* 新生代(Young Generation)
|
||||
* 老年代(Old Generation)
|
||||
|
||||
堆不需要连续内存,并且可以动态增加其内存,增加失败会抛出 OutOfMemoryError 异常。
|
||||
|
||||
@ -143,12 +144,12 @@ public class Test {
|
||||
|
||||
Java 虚拟机使用该算法来判断对象是否可被回收,GC Roots 一般包含以下内容:
|
||||
|
||||
- 虚拟机栈中局部变量表中引用的对象
|
||||
- 本地方法栈中 JNI 中引用的对象
|
||||
- 方法区中类静态属性引用的对象
|
||||
- 方法区中的常量引用的对象
|
||||
* 虚拟机栈中局部变量表中引用的对象
|
||||
* 本地方法栈中 JNI 中引用的对象
|
||||
* 方法区中类静态属性引用的对象
|
||||
* 方法区中的常量引用的对象
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/83d909d2-3858-4fe1-8ff4-16471db0b180.png" width="350px"> </div><br>
|
||||
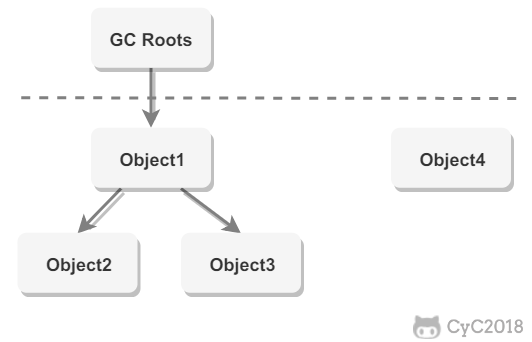\
|
||||
|
||||
|
||||
#### 3. 方法区的回收
|
||||
@ -161,9 +162,9 @@ Java 虚拟机使用该算法来判断对象是否可被回收,GC Roots 一般
|
||||
|
||||
类的卸载条件很多,需要满足以下三个条件,并且满足了条件也不一定会被卸载:
|
||||
|
||||
- 该类所有的实例都已经被回收,此时堆中不存在该类的任何实例。
|
||||
- 加载该类的 ClassLoader 已经被回收。
|
||||
- 该类对应的 Class 对象没有在任何地方被引用,也就无法在任何地方通过反射访问该类方法。
|
||||
* 该类所有的实例都已经被回收,此时堆中不存在该类的任何实例。
|
||||
* 加载该类的 ClassLoader 已经被回收。
|
||||
* 该类对应的 Class 对象没有在任何地方被引用,也就无法在任何地方通过反射访问该类方法。
|
||||
|
||||
#### 4. finalize()
|
||||
|
||||
@ -229,7 +230,8 @@ obj = null;
|
||||
|
||||
#### 1. 标记 - 清除
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/005b481b-502b-4e3f-985d-d043c2b330aa.png" width="400px"> </div><br>
|
||||
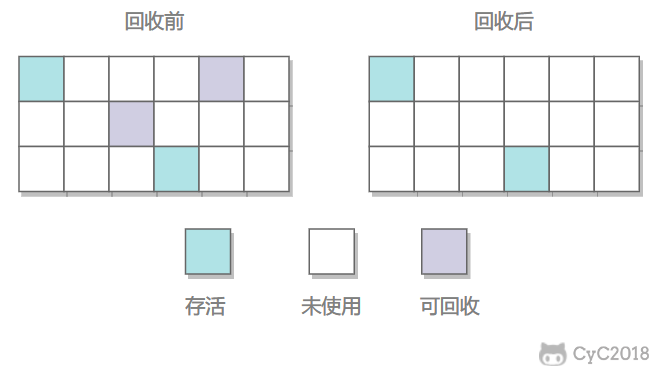\
|
||||
|
||||
|
||||
在标记阶段,程序会检查每个对象是否为活动对象,如果是活动对象,则程序会在对象头部打上标记。
|
||||
|
||||
@ -239,26 +241,28 @@ obj = null;
|
||||
|
||||
不足:
|
||||
|
||||
- 标记和清除过程效率都不高;
|
||||
- 会产生大量不连续的内存碎片,导致无法给大对象分配内存。
|
||||
* 标记和清除过程效率都不高;
|
||||
* 会产生大量不连续的内存碎片,导致无法给大对象分配内存。
|
||||
|
||||
#### 2. 标记 - 整理
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/ccd773a5-ad38-4022-895c-7ac318f31437.png" width="400px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
|
||||
|
||||
优点:
|
||||
|
||||
- 不会产生内存碎片
|
||||
* 不会产生内存碎片
|
||||
|
||||
不足:
|
||||
|
||||
- 需要移动大量对象,处理效率比较低。
|
||||
* 需要移动大量对象,处理效率比较低。
|
||||
|
||||
#### 3. 复制
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/b2b77b9e-958c-4016-8ae5-9c6edd83871e.png" width="400px"> </div><br>
|
||||
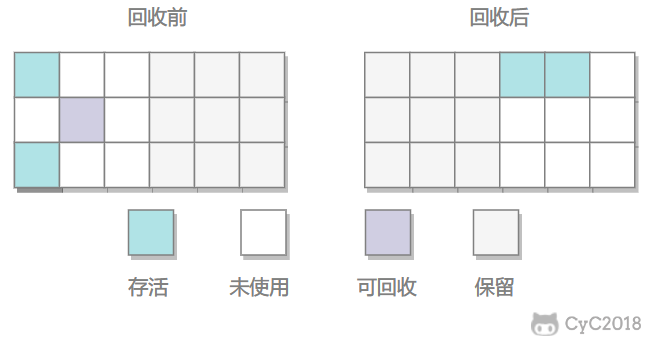\
|
||||
|
||||
|
||||
将内存划分为大小相等的两块,每次只使用其中一块,当这一块内存用完了就将还存活的对象复制到另一块上面,然后再把使用过的内存空间进行一次清理。
|
||||
|
||||
@ -274,21 +278,23 @@ HotSpot 虚拟机的 Eden 和 Survivor 大小比例默认为 8:1,保证了内
|
||||
|
||||
一般将堆分为新生代和老年代。
|
||||
|
||||
- 新生代使用:复制算法
|
||||
- 老年代使用:标记 - 清除 或者 标记 - 整理 算法
|
||||
* 新生代使用:复制算法
|
||||
* 老年代使用:标记 - 清除 或者 标记 - 整理 算法
|
||||
|
||||
### 垃圾收集器
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/c625baa0-dde6-449e-93df-c3a67f2f430f.jpg" width=""/> </div><br>
|
||||
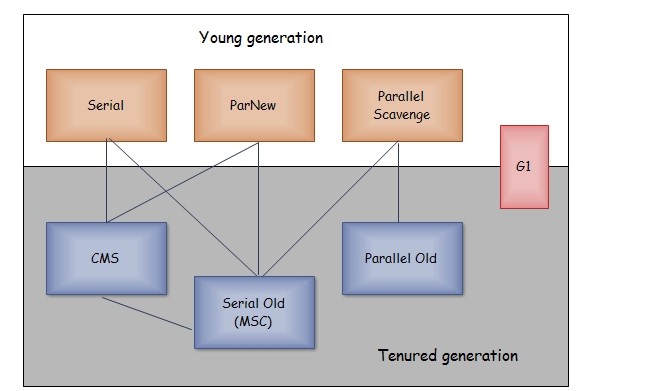\
|
||||
|
||||
|
||||
以上是 HotSpot 虚拟机中的 7 个垃圾收集器,连线表示垃圾收集器可以配合使用。
|
||||
|
||||
- 单线程与多线程:单线程指的是垃圾收集器只使用一个线程,而多线程使用多个线程;
|
||||
- 串行与并行:串行指的是垃圾收集器与用户程序交替执行,这意味着在执行垃圾收集的时候需要停顿用户程序;并行指的是垃圾收集器和用户程序同时执行。除了 CMS 和 G1 之外,其它垃圾收集器都是以串行的方式执行。
|
||||
* 单线程与多线程:单线程指的是垃圾收集器只使用一个线程,而多线程使用多个线程;
|
||||
* 串行与并行:串行指的是垃圾收集器与用户程序交替执行,这意味着在执行垃圾收集的时候需要停顿用户程序;并行指的是垃圾收集器和用户程序同时执行。除了 CMS 和 G1 之外,其它垃圾收集器都是以串行的方式执行。
|
||||
|
||||
#### 1. Serial 收集器
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/22fda4ae-4dd5-489d-ab10-9ebfdad22ae0.jpg" width=""/> </div><br>
|
||||
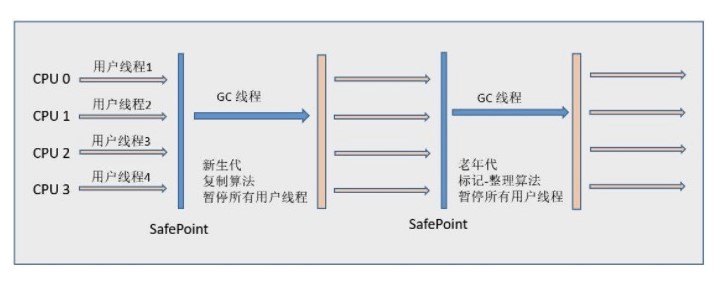\
|
||||
|
||||
|
||||
Serial 翻译为串行,也就是说它以串行的方式执行。
|
||||
|
||||
@ -300,7 +306,8 @@ Serial 翻译为串行,也就是说它以串行的方式执行。
|
||||
|
||||
#### 2. ParNew 收集器
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/81538cd5-1bcf-4e31-86e5-e198df1e013b.jpg" width=""/> </div><br>
|
||||
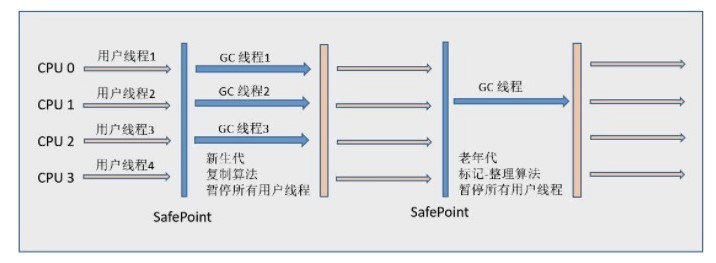\
|
||||
|
||||
|
||||
它是 Serial 收集器的多线程版本。
|
||||
|
||||
@ -320,16 +327,18 @@ Serial 翻译为串行,也就是说它以串行的方式执行。
|
||||
|
||||
#### 4. Serial Old 收集器
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/08f32fd3-f736-4a67-81ca-295b2a7972f2.jpg" width=""/> </div><br>
|
||||
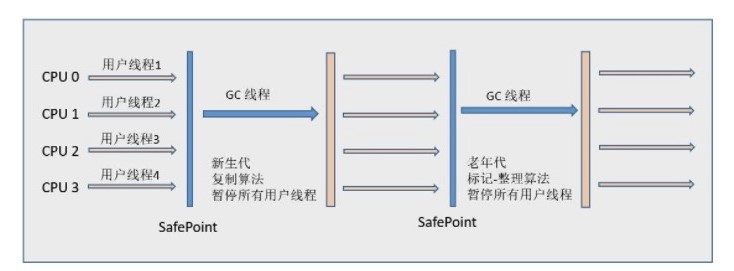\
|
||||
|
||||
|
||||
是 Serial 收集器的老年代版本,也是给 Client 场景下的虚拟机使用。如果用在 Server 场景下,它有两大用途:
|
||||
|
||||
- 在 JDK 1.5 以及之前版本(Parallel Old 诞生以前)中与 Parallel Scavenge 收集器搭配使用。
|
||||
- 作为 CMS 收集器的后备预案,在并发收集发生 Concurrent Mode Failure 时使用。
|
||||
* 在 JDK 1.5 以及之前版本(Parallel Old 诞生以前)中与 Parallel Scavenge 收集器搭配使用。
|
||||
* 作为 CMS 收集器的后备预案,在并发收集发生 Concurrent Mode Failure 时使用。
|
||||
|
||||
#### 5. Parallel Old 收集器
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/278fe431-af88-4a95-a895-9c3b80117de3.jpg" width=""/> </div><br>
|
||||
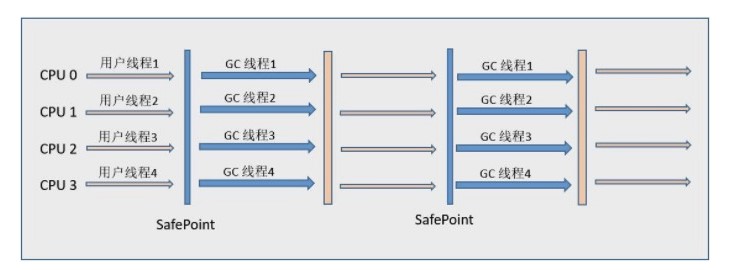\
|
||||
|
||||
|
||||
是 Parallel Scavenge 收集器的老年代版本。
|
||||
|
||||
@ -337,24 +346,25 @@ Serial 翻译为串行,也就是说它以串行的方式执行。
|
||||
|
||||
#### 6. CMS 收集器
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/62e77997-6957-4b68-8d12-bfd609bb2c68.jpg" width=""/> </div><br>
|
||||
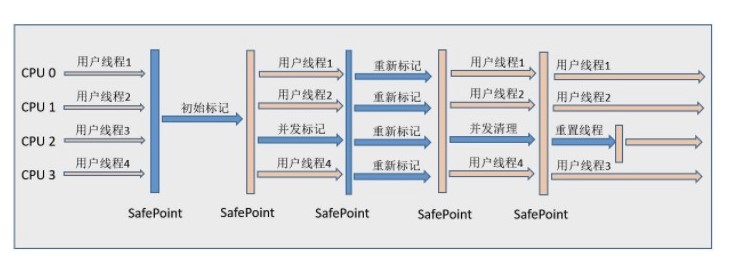\
|
||||
|
||||
|
||||
CMS(Concurrent Mark Sweep),Mark Sweep 指的是标记 - 清除算法。
|
||||
|
||||
分为以下四个流程:
|
||||
|
||||
- 初始标记:仅仅只是标记一下 GC Roots 能直接关联到的对象,速度很快,需要停顿。
|
||||
- 并发标记:进行 GC Roots Tracing 的过程,它在整个回收过程中耗时最长,不需要停顿。
|
||||
- 重新标记:为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,需要停顿。
|
||||
- 并发清除:不需要停顿。
|
||||
* 初始标记:仅仅只是标记一下 GC Roots 能直接关联到的对象,速度很快,需要停顿。
|
||||
* 并发标记:进行 GC Roots Tracing 的过程,它在整个回收过程中耗时最长,不需要停顿。
|
||||
* 重新标记:为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,需要停顿。
|
||||
* 并发清除:不需要停顿。
|
||||
|
||||
在整个过程中耗时最长的并发标记和并发清除过程中,收集器线程都可以与用户线程一起工作,不需要进行停顿。
|
||||
|
||||
具有以下缺点:
|
||||
|
||||
- 吞吐量低:低停顿时间是以牺牲吞吐量为代价的,导致 CPU 利用率不够高。
|
||||
- 无法处理浮动垃圾,可能出现 Concurrent Mode Failure。浮动垃圾是指并发清除阶段由于用户线程继续运行而产生的垃圾,这部分垃圾只能到下一次 GC 时才能进行回收。由于浮动垃圾的存在,因此需要预留出一部分内存,意味着 CMS 收集不能像其它收集器那样等待老年代快满的时候再回收。如果预留的内存不够存放浮动垃圾,就会出现 Concurrent Mode Failure,这时虚拟机将临时启用 Serial Old 来替代 CMS。
|
||||
- 标记 - 清除算法导致的空间碎片,往往出现老年代空间剩余,但无法找到足够大连续空间来分配当前对象,不得不提前触发一次 Full GC。
|
||||
* 吞吐量低:低停顿时间是以牺牲吞吐量为代价的,导致 CPU 利用率不够高。
|
||||
* 无法处理浮动垃圾,可能出现 Concurrent Mode Failure。浮动垃圾是指并发清除阶段由于用户线程继续运行而产生的垃圾,这部分垃圾只能到下一次 GC 时才能进行回收。由于浮动垃圾的存在,因此需要预留出一部分内存,意味着 CMS 收集不能像其它收集器那样等待老年代快满的时候再回收。如果预留的内存不够存放浮动垃圾,就会出现 Concurrent Mode Failure,这时虚拟机将临时启用 Serial Old 来替代 CMS。
|
||||
* 标记 - 清除算法导致的空间碎片,往往出现老年代空间剩余,但无法找到足够大连续空间来分配当前对象,不得不提前触发一次 Full GC。
|
||||
|
||||
#### 7. G1 收集器
|
||||
|
||||
@ -362,37 +372,39 @@ G1(Garbage-First),它是一款面向服务端应用的垃圾收集器,
|
||||
|
||||
堆被分为新生代和老年代,其它收集器进行收集的范围都是整个新生代或者老年代,而 G1 可以直接对新生代和老年代一起回收。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/4cf711a8-7ab2-4152-b85c-d5c226733807.png" width="600"/> </div><br>
|
||||
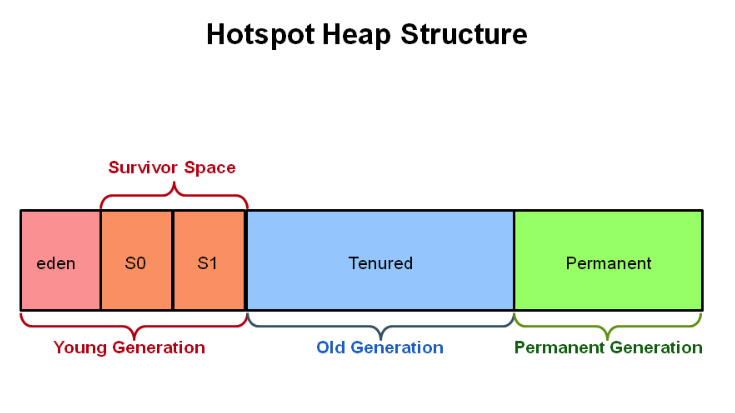\
|
||||
|
||||
|
||||
G1 把堆划分成多个大小相等的独立区域(Region),新生代和老年代不再物理隔离。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/9bbddeeb-e939-41f0-8e8e-2b1a0aa7e0a7.png" width="600"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
通过引入 Region 的概念,从而将原来的一整块内存空间划分成多个的小空间,使得每个小空间可以单独进行垃圾回收。这种划分方法带来了很大的灵活性,使得可预测的停顿时间模型成为可能。通过记录每个 Region 垃圾回收时间以及回收所获得的空间(这两个值是通过过去回收的经验获得),并维护一个优先列表,每次根据允许的收集时间,优先回收价值最大的 Region。
|
||||
|
||||
每个 Region 都有一个 Remembered Set,用来记录该 Region 对象的引用对象所在的 Region。通过使用 Remembered Set,在做可达性分析的时候就可以避免全堆扫描。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/f99ee771-c56f-47fb-9148-c0036695b5fe.jpg" width=""/> </div><br>
|
||||
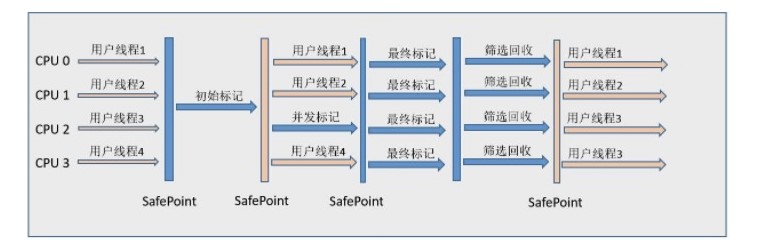\
|
||||
|
||||
|
||||
如果不计算维护 Remembered Set 的操作,G1 收集器的运作大致可划分为以下几个步骤:
|
||||
|
||||
- 初始标记
|
||||
- 并发标记
|
||||
- 最终标记:为了修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程的 Remembered Set Logs 里面,最终标记阶段需要把 Remembered Set Logs 的数据合并到 Remembered Set 中。这阶段需要停顿线程,但是可并行执行。
|
||||
- 筛选回收:首先对各个 Region 中的回收价值和成本进行排序,根据用户所期望的 GC 停顿时间来制定回收计划。此阶段其实也可以做到与用户程序一起并发执行,但是因为只回收一部分 Region,时间是用户可控制的,而且停顿用户线程将大幅度提高收集效率。
|
||||
* 初始标记
|
||||
* 并发标记
|
||||
* 最终标记:为了修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录,虚拟机将这段时间对象变化记录在线程的 Remembered Set Logs 里面,最终标记阶段需要把 Remembered Set Logs 的数据合并到 Remembered Set 中。这阶段需要停顿线程,但是可并行执行。
|
||||
* 筛选回收:首先对各个 Region 中的回收价值和成本进行排序,根据用户所期望的 GC 停顿时间来制定回收计划。此阶段其实也可以做到与用户程序一起并发执行,但是因为只回收一部分 Region,时间是用户可控制的,而且停顿用户线程将大幅度提高收集效率。
|
||||
|
||||
具备如下特点:
|
||||
|
||||
- 空间整合:整体来看是基于“标记 - 整理”算法实现的收集器,从局部(两个 Region 之间)上来看是基于“复制”算法实现的,这意味着运行期间不会产生内存空间碎片。
|
||||
- 可预测的停顿:能让使用者明确指定在一个长度为 M 毫秒的时间片段内,消耗在 GC 上的时间不得超过 N 毫秒。
|
||||
* 空间整合:整体来看是基于“标记 - 整理”算法实现的收集器,从局部(两个 Region 之间)上来看是基于“复制”算法实现的,这意味着运行期间不会产生内存空间碎片。
|
||||
* 可预测的停顿:能让使用者明确指定在一个长度为 M 毫秒的时间片段内,消耗在 GC 上的时间不得超过 N 毫秒。
|
||||
|
||||
## 三、内存分配与回收策略
|
||||
|
||||
### Minor GC 和 Full GC
|
||||
|
||||
- Minor GC:回收新生代,因为新生代对象存活时间很短,因此 Minor GC 会频繁执行,执行的速度一般也会比较快。
|
||||
|
||||
- Full GC:回收老年代和新生代,老年代对象其存活时间长,因此 Full GC 很少执行,执行速度会比 Minor GC 慢很多。
|
||||
* Minor GC:回收新生代,因为新生代对象存活时间很短,因此 Minor GC 会频繁执行,执行的速度一般也会比较快。
|
||||
* Full GC:回收老年代和新生代,老年代对象其存活时间长,因此 Full GC 很少执行,执行速度会比 Minor GC 慢很多。
|
||||
|
||||
### 内存分配策略
|
||||
|
||||
@ -406,13 +418,13 @@ G1 把堆划分成多个大小相等的独立区域(Region),新生代和
|
||||
|
||||
经常出现大对象会提前触发垃圾收集以获取足够的连续空间分配给大对象。
|
||||
|
||||
-XX:PretenureSizeThreshold,大于此值的对象直接在老年代分配,避免在 Eden 和 Survivor 之间的大量内存复制。
|
||||
\-XX:PretenureSizeThreshold,大于此值的对象直接在老年代分配,避免在 Eden 和 Survivor 之间的大量内存复制。
|
||||
|
||||
#### 3. 长期存活的对象进入老年代
|
||||
|
||||
为对象定义年龄计数器,对象在 Eden 出生并经过 Minor GC 依然存活,将移动到 Survivor 中,年龄就增加 1 岁,增加到一定年龄则移动到老年代中。
|
||||
|
||||
-XX:MaxTenuringThreshold 用来定义年龄的阈值。
|
||||
\-XX:MaxTenuringThreshold 用来定义年龄的阈值。
|
||||
|
||||
#### 4. 动态对象年龄判定
|
||||
|
||||
@ -460,17 +472,18 @@ G1 把堆划分成多个大小相等的独立区域(Region),新生代和
|
||||
|
||||
### 类的生命周期
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/335fe19c-4a76-45ab-9320-88c90d6a0d7e.png" width="600px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
包括以下 7 个阶段:
|
||||
|
||||
- **加载(Loading)**
|
||||
- **验证(Verification)**
|
||||
- **准备(Preparation)**
|
||||
- **解析(Resolution)**
|
||||
- **初始化(Initialization)**
|
||||
- 使用(Using)
|
||||
- 卸载(Unloading)
|
||||
* **加载(Loading)**
|
||||
* **验证(Verification)**
|
||||
* **准备(Preparation)**
|
||||
* **解析(Resolution)**
|
||||
* **初始化(Initialization)**
|
||||
* 使用(Using)
|
||||
* 卸载(Unloading)
|
||||
|
||||
### 类加载过程
|
||||
|
||||
@ -482,17 +495,16 @@ G1 把堆划分成多个大小相等的独立区域(Region),新生代和
|
||||
|
||||
加载过程完成以下三件事:
|
||||
|
||||
- 通过类的完全限定名称获取定义该类的二进制字节流。
|
||||
- 将该字节流表示的静态存储结构转换为方法区的运行时存储结构。
|
||||
- 在内存中生成一个代表该类的 Class 对象,作为方法区中该类各种数据的访问入口。
|
||||
|
||||
* 通过类的完全限定名称获取定义该类的二进制字节流。
|
||||
* 将该字节流表示的静态存储结构转换为方法区的运行时存储结构。
|
||||
* 在内存中生成一个代表该类的 Class 对象,作为方法区中该类各种数据的访问入口。
|
||||
|
||||
其中二进制字节流可以从以下方式中获取:
|
||||
|
||||
- 从 ZIP 包读取,成为 JAR、EAR、WAR 格式的基础。
|
||||
- 从网络中获取,最典型的应用是 Applet。
|
||||
- 运行时计算生成,例如动态代理技术,在 java.lang.reflect.Proxy 使用 ProxyGenerator.generateProxyClass 的代理类的二进制字节流。
|
||||
- 由其他文件生成,例如由 JSP 文件生成对应的 Class 类。
|
||||
* 从 ZIP 包读取,成为 JAR、EAR、WAR 格式的基础。
|
||||
* 从网络中获取,最典型的应用是 Applet。
|
||||
* 运行时计算生成,例如动态代理技术,在 java.lang.reflect.Proxy 使用 ProxyGenerator.generateProxyClass 的代理类的二进制字节流。
|
||||
* 由其他文件生成,例如由 JSP 文件生成对应的 Class 类。
|
||||
|
||||
#### 2. 验证
|
||||
|
||||
@ -524,10 +536,9 @@ public static final int value = 123;
|
||||
|
||||
#### 5. 初始化
|
||||
|
||||
<div data="modify -->"></div>
|
||||
初始化阶段才真正开始执行类中定义的 Java 程序代码。初始化阶段是虚拟机执行类构造器 <clinit\>() 方法的过程。在准备阶段,类变量已经赋过一次系统要求的初始值,而在初始化阶段,根据程序员通过程序制定的主观计划去初始化类变量和其它资源。
|
||||
初始化阶段才真正开始执行类中定义的 Java 程序代码。初始化阶段是虚拟机执行类构造器 \<clinit\\>() 方法的过程。在准备阶段,类变量已经赋过一次系统要求的初始值,而在初始化阶段,根据程序员通过程序制定的主观计划去初始化类变量和其它资源。
|
||||
|
||||
<clinit\>() 是由编译器自动收集类中所有类变量的赋值动作和静态语句块中的语句合并产生的,编译器收集的顺序由语句在源文件中出现的顺序决定。特别注意的是,静态语句块只能访问到定义在它之前的类变量,定义在它之后的类变量只能赋值,不能访问。例如以下代码:
|
||||
\<clinit>() 是由编译器自动收集类中所有类变量的赋值动作和静态语句块中的语句合并产生的,编译器收集的顺序由语句在源文件中出现的顺序决定。特别注意的是,静态语句块只能访问到定义在它之前的类变量,定义在它之后的类变量只能赋值,不能访问。例如以下代码:
|
||||
|
||||
```java
|
||||
public class Test {
|
||||
@ -539,7 +550,7 @@ public class Test {
|
||||
}
|
||||
```
|
||||
|
||||
由于父类的 <clinit\>() 方法先执行,也就意味着父类中定义的静态语句块的执行要优先于子类。例如以下代码:
|
||||
由于父类的 \<clinit>() 方法先执行,也就意味着父类中定义的静态语句块的执行要优先于子类。例如以下代码:
|
||||
|
||||
```java
|
||||
static class Parent {
|
||||
@ -558,9 +569,9 @@ public static void main(String[] args) {
|
||||
}
|
||||
```
|
||||
|
||||
接口中不可以使用静态语句块,但仍然有类变量初始化的赋值操作,因此接口与类一样都会生成 <clinit\>() 方法。但接口与类不同的是,执行接口的 <clinit\>() 方法不需要先执行父接口的 <clinit\>() 方法。只有当父接口中定义的变量使用时,父接口才会初始化。另外,接口的实现类在初始化时也一样不会执行接口的 <clinit\>() 方法。
|
||||
接口中不可以使用静态语句块,但仍然有类变量初始化的赋值操作,因此接口与类一样都会生成 \<clinit>() 方法。但接口与类不同的是,执行接口的 \<clinit>() 方法不需要先执行父接口的 \<clinit>() 方法。只有当父接口中定义的变量使用时,父接口才会初始化。另外,接口的实现类在初始化时也一样不会执行接口的 \<clinit>() 方法。
|
||||
|
||||
虚拟机会保证一个类的 <clinit\>() 方法在多线程环境下被正确的加锁和同步,如果多个线程同时初始化一个类,只会有一个线程执行这个类的 <clinit\>() 方法,其它线程都会阻塞等待,直到活动线程执行 <clinit\>() 方法完毕。如果在一个类的 <clinit\>() 方法中有耗时的操作,就可能造成多个线程阻塞,在实际过程中此种阻塞很隐蔽。
|
||||
虚拟机会保证一个类的 \<clinit>() 方法在多线程环境下被正确的加锁和同步,如果多个线程同时初始化一个类,只会有一个线程执行这个类的 \<clinit>() 方法,其它线程都会阻塞等待,直到活动线程执行 \<clinit>() 方法完毕。如果在一个类的 \<clinit>() 方法中有耗时的操作,就可能造成多个线程阻塞,在实际过程中此种阻塞很隐蔽。
|
||||
|
||||
### 类初始化时机
|
||||
|
||||
@ -568,33 +579,29 @@ public static void main(String[] args) {
|
||||
|
||||
虚拟机规范中并没有强制约束何时进行加载,但是规范严格规定了有且只有下列五种情况必须对类进行初始化(加载、验证、准备都会随之发生):
|
||||
|
||||
- 遇到 new、getstatic、putstatic、invokestatic 这四条字节码指令时,如果类没有进行过初始化,则必须先触发其初始化。最常见的生成这 4 条指令的场景是:使用 new 关键字实例化对象的时候;读取或设置一个类的静态字段(被 final 修饰、已在编译期把结果放入常量池的静态字段除外)的时候;以及调用一个类的静态方法的时候。
|
||||
|
||||
- 使用 java.lang.reflect 包的方法对类进行反射调用的时候,如果类没有进行初始化,则需要先触发其初始化。
|
||||
|
||||
- 当初始化一个类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化。
|
||||
|
||||
- 当虚拟机启动时,用户需要指定一个要执行的主类(包含 main() 方法的那个类),虚拟机会先初始化这个主类;
|
||||
|
||||
- 当使用 JDK 1.7 的动态语言支持时,如果一个 java.lang.invoke.MethodHandle 实例最后的解析结果为 REF_getStatic, REF_putStatic, REF_invokeStatic 的方法句柄,并且这个方法句柄所对应的类没有进行过初始化,则需要先触发其初始化;
|
||||
* 遇到 new、getstatic、putstatic、invokestatic 这四条字节码指令时,如果类没有进行过初始化,则必须先触发其初始化。最常见的生成这 4 条指令的场景是:使用 new 关键字实例化对象的时候;读取或设置一个类的静态字段(被 final 修饰、已在编译期把结果放入常量池的静态字段除外)的时候;以及调用一个类的静态方法的时候。
|
||||
* 使用 java.lang.reflect 包的方法对类进行反射调用的时候,如果类没有进行初始化,则需要先触发其初始化。
|
||||
* 当初始化一个类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化。
|
||||
* 当虚拟机启动时,用户需要指定一个要执行的主类(包含 main() 方法的那个类),虚拟机会先初始化这个主类;
|
||||
* 当使用 JDK 1.7 的动态语言支持时,如果一个 java.lang.invoke.MethodHandle 实例最后的解析结果为 REF\_getStatic, REF\_putStatic, REF\_invokeStatic 的方法句柄,并且这个方法句柄所对应的类没有进行过初始化,则需要先触发其初始化;
|
||||
|
||||
#### 2. 被动引用
|
||||
|
||||
以上 5 种场景中的行为称为对一个类进行主动引用。除此之外,所有引用类的方式都不会触发初始化,称为被动引用。被动引用的常见例子包括:
|
||||
|
||||
- 通过子类引用父类的静态字段,不会导致子类初始化。
|
||||
* 通过子类引用父类的静态字段,不会导致子类初始化。
|
||||
|
||||
```java
|
||||
System.out.println(SubClass.value); // value 字段在 SuperClass 中定义
|
||||
```
|
||||
|
||||
- 通过数组定义来引用类,不会触发此类的初始化。该过程会对数组类进行初始化,数组类是一个由虚拟机自动生成的、直接继承自 Object 的子类,其中包含了数组的属性和方法。
|
||||
* 通过数组定义来引用类,不会触发此类的初始化。该过程会对数组类进行初始化,数组类是一个由虚拟机自动生成的、直接继承自 Object 的子类,其中包含了数组的属性和方法。
|
||||
|
||||
```java
|
||||
SuperClass[] sca = new SuperClass[10];
|
||||
```
|
||||
|
||||
- 常量在编译阶段会存入调用类的常量池中,本质上并没有直接引用到定义常量的类,因此不会触发定义常量的类的初始化。
|
||||
* 常量在编译阶段会存入调用类的常量池中,本质上并没有直接引用到定义常量的类,因此不会触发定义常量的类的初始化。
|
||||
|
||||
```java
|
||||
System.out.println(ConstClass.HELLOWORLD);
|
||||
@ -610,17 +617,14 @@ System.out.println(ConstClass.HELLOWORLD);
|
||||
|
||||
从 Java 虚拟机的角度来讲,只存在以下两种不同的类加载器:
|
||||
|
||||
- 启动类加载器(Bootstrap ClassLoader),使用 C++ 实现,是虚拟机自身的一部分;
|
||||
|
||||
- 所有其它类的加载器,使用 Java 实现,独立于虚拟机,继承自抽象类 java.lang.ClassLoader。
|
||||
* 启动类加载器(Bootstrap ClassLoader),使用 C++ 实现,是虚拟机自身的一部分;
|
||||
* 所有其它类的加载器,使用 Java 实现,独立于虚拟机,继承自抽象类 java.lang.ClassLoader。
|
||||
|
||||
从 Java 开发人员的角度看,类加载器可以划分得更细致一些:
|
||||
|
||||
- 启动类加载器(Bootstrap ClassLoader)此类加载器负责将存放在 <JRE_HOME\>\lib 目录中的,或者被 -Xbootclasspath 参数所指定的路径中的,并且是虚拟机识别的(仅按照文件名识别,如 rt.jar,名字不符合的类库即使放在 lib 目录中也不会被加载)类库加载到虚拟机内存中。启动类加载器无法被 Java 程序直接引用,用户在编写自定义类加载器时,如果需要把加载请求委派给启动类加载器,直接使用 null 代替即可。
|
||||
|
||||
- 扩展类加载器(Extension ClassLoader)这个类加载器是由 ExtClassLoader(sun.misc.Launcher$ExtClassLoader)实现的。它负责将 <JAVA_HOME\>/lib/ext 或者被 java.ext.dir 系统变量所指定路径中的所有类库加载到内存中,开发者可以直接使用扩展类加载器。
|
||||
|
||||
- 应用程序类加载器(Application ClassLoader)这个类加载器是由 AppClassLoader(sun.misc.Launcher$AppClassLoader)实现的。由于这个类加载器是 ClassLoader 中的 getSystemClassLoader() 方法的返回值,因此一般称为系统类加载器。它负责加载用户类路径(ClassPath)上所指定的类库,开发者可以直接使用这个类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
|
||||
* 启动类加载器(Bootstrap ClassLoader)此类加载器负责将存放在 \<JRE\_HOME>\lib 目录中的,或者被 -Xbootclasspath 参数所指定的路径中的,并且是虚拟机识别的(仅按照文件名识别,如 rt.jar,名字不符合的类库即使放在 lib 目录中也不会被加载)类库加载到虚拟机内存中。启动类加载器无法被 Java 程序直接引用,用户在编写自定义类加载器时,如果需要把加载请求委派给启动类加载器,直接使用 null 代替即可。
|
||||
* 扩展类加载器(Extension ClassLoader)这个类加载器是由 ExtClassLoader(sun.misc.Launcher$ExtClassLoader)实现的。它负责将 \<JAVA\_HOME>/lib/ext 或者被 java.ext.dir 系统变量所指定路径中的所有类库加载到内存中,开发者可以直接使用扩展类加载器。
|
||||
* 应用程序类加载器(Application ClassLoader)这个类加载器是由 AppClassLoader(sun.misc.Launcher$AppClassLoader)实现的。由于这个类加载器是 ClassLoader 中的 getSystemClassLoader() 方法的返回值,因此一般称为系统类加载器。它负责加载用户类路径(ClassPath)上所指定的类库,开发者可以直接使用这个类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
|
||||
|
||||
### 双亲委派模型
|
||||
|
||||
@ -628,7 +632,8 @@ System.out.println(ConstClass.HELLOWORLD);
|
||||
|
||||
下图展示了类加载器之间的层次关系,称为双亲委派模型(Parents Delegation Model)。该模型要求除了顶层的启动类加载器外,其它的类加载器都要有自己的父类加载器。这里的父子关系一般通过组合关系(Composition)来实现,而不是继承关系(Inheritance)。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/0dd2d40a-5b2b-4d45-b176-e75a4cd4bdbf.png" width="500px"> </div><br>
|
||||
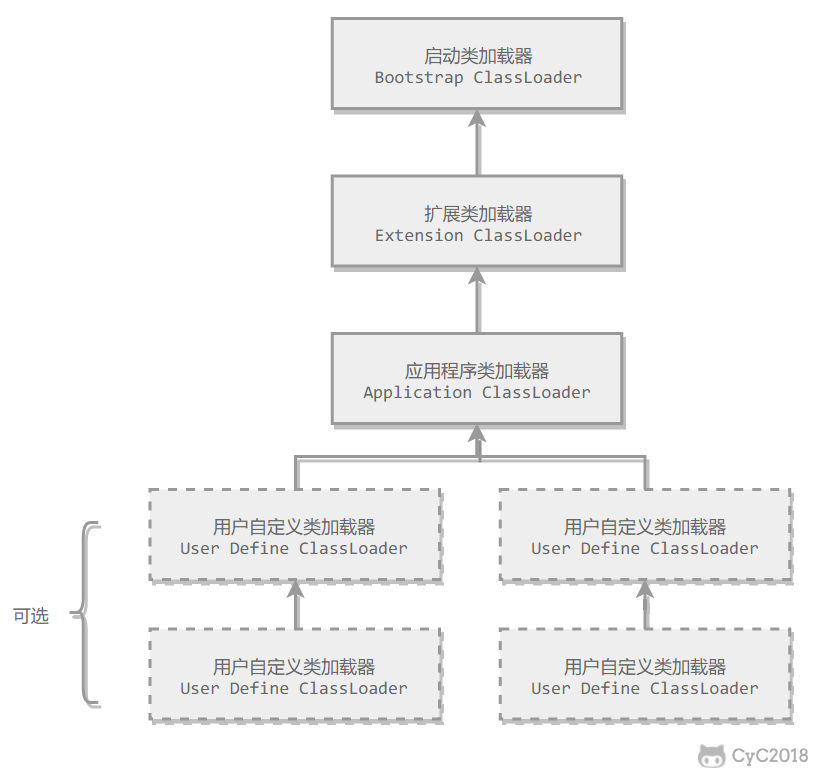\
|
||||
|
||||
|
||||
#### 1. 工作过程
|
||||
|
||||
@ -739,17 +744,16 @@ public class FileSystemClassLoader extends ClassLoader {
|
||||
|
||||
## 参考资料
|
||||
|
||||
- 周志明. 深入理解 Java 虚拟机 [M]. 机械工业出版社, 2011.
|
||||
- [Chapter 2. The Structure of the Java Virtual Machine](https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-2.html#jvms-2.5.4)
|
||||
- [Jvm memory](https://www.slideshare.net/benewu/jvm-memory)
|
||||
[Getting Started with the G1 Garbage Collector](http://www.oracle.com/webfolder/technetwork/tutorials/obe/java/G1GettingStarted/index.html)
|
||||
- [JNI Part1: Java Native Interface Introduction and “Hello World” application](http://electrofriends.com/articles/jni/jni-part1-java-native-interface/)
|
||||
- [Memory Architecture Of JVM(Runtime Data Areas)](https://hackthejava.wordpress.com/2015/01/09/memory-architecture-by-jvmruntime-data-areas/)
|
||||
- [JVM Run-Time Data Areas](https://www.programcreek.com/2013/04/jvm-run-time-data-areas/)
|
||||
- [Android on x86: Java Native Interface and the Android Native Development Kit](http://www.drdobbs.com/architecture-and-design/android-on-x86-java-native-interface-and/240166271)
|
||||
- [深入理解 JVM(2)——GC 算法与内存分配策略](https://crowhawk.github.io/2017/08/10/jvm_2/)
|
||||
- [深入理解 JVM(3)——7 种垃圾收集器](https://crowhawk.github.io/2017/08/15/jvm_3/)
|
||||
- [JVM Internals](http://blog.jamesdbloom.com/JVMInternals.html)
|
||||
- [深入探讨 Java 类加载器](https://www.ibm.com/developerworks/cn/java/j-lo-classloader/index.html#code6)
|
||||
- [Guide to WeakHashMap in Java](http://www.baeldung.com/java-weakhashmap)
|
||||
- [Tomcat example source code file (ConcurrentCache.java)](https://alvinalexander.com/java/jwarehouse/apache-tomcat-6.0.16/java/org/apache/el/util/ConcurrentCache.java.shtml)
|
||||
* 周志明. 深入理解 Java 虚拟机 \[M]. 机械工业出版社, 2011.
|
||||
* [Chapter 2. The Structure of the Java Virtual Machine](https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-2.html#jvms-2.5.4)
|
||||
* [Jvm memory](https://www.slideshare.net/benewu/jvm-memory) [Getting Started with the G1 Garbage Collector](http://www.oracle.com/webfolder/technetwork/tutorials/obe/java/G1GettingStarted/index.html)
|
||||
* [JNI Part1: Java Native Interface Introduction and “Hello World” application](http://electrofriends.com/articles/jni/jni-part1-java-native-interface/)
|
||||
* [Memory Architecture Of JVM(Runtime Data Areas)](https://hackthejava.wordpress.com/2015/01/09/memory-architecture-by-jvmruntime-data-areas/)
|
||||
* [JVM Run-Time Data Areas](https://www.programcreek.com/2013/04/jvm-run-time-data-areas/)
|
||||
* [Android on x86: Java Native Interface and the Android Native Development Kit](http://www.drdobbs.com/architecture-and-design/android-on-x86-java-native-interface-and/240166271)
|
||||
* [深入理解 JVM(2)——GC 算法与内存分配策略](https://crowhawk.github.io/2017/08/10/jvm\_2/)
|
||||
* [深入理解 JVM(3)——7 种垃圾收集器](https://crowhawk.github.io/2017/08/15/jvm\_3/)
|
||||
* [JVM Internals](http://blog.jamesdbloom.com/JVMInternals.html)
|
||||
* [深入探讨 Java 类加载器](https://www.ibm.com/developerworks/cn/java/j-lo-classloader/index.html#code6)
|
||||
* [Guide to WeakHashMap in Java](http://www.baeldung.com/java-weakhashmap)
|
||||
* [Tomcat example source code file (ConcurrentCache.java)](https://alvinalexander.com/java/jwarehouse/apache-tomcat-6.0.16/java/org/apache/el/util/ConcurrentCache.java.shtml)
|
||||
|
||||
@ -1,47 +1,45 @@
|
||||
# Leetcode 题解 - 动态规划
|
||||
<!-- GFM-TOC -->
|
||||
* [Leetcode 题解 - 动态规划](#leetcode-题解---动态规划)
|
||||
* [斐波那契数列](#斐波那契数列)
|
||||
* [1. 爬楼梯](#1-爬楼梯)
|
||||
* [2. 强盗抢劫](#2-强盗抢劫)
|
||||
* [3. 强盗在环形街区抢劫](#3-强盗在环形街区抢劫)
|
||||
* [4. 信件错排](#4-信件错排)
|
||||
* [5. 母牛生产](#5-母牛生产)
|
||||
* [矩阵路径](#矩阵路径)
|
||||
* [1. 矩阵的最小路径和](#1-矩阵的最小路径和)
|
||||
* [2. 矩阵的总路径数](#2-矩阵的总路径数)
|
||||
* [数组区间](#数组区间)
|
||||
* [1. 数组区间和](#1-数组区间和)
|
||||
* [2. 数组中等差递增子区间的个数](#2-数组中等差递增子区间的个数)
|
||||
* [分割整数](#分割整数)
|
||||
* [1. 分割整数的最大乘积](#1-分割整数的最大乘积)
|
||||
* [2. 按平方数来分割整数](#2-按平方数来分割整数)
|
||||
* [3. 分割整数构成字母字符串](#3-分割整数构成字母字符串)
|
||||
* [最长递增子序列](#最长递增子序列)
|
||||
* [1. 最长递增子序列](#1-最长递增子序列)
|
||||
* [2. 一组整数对能够构成的最长链](#2-一组整数对能够构成的最长链)
|
||||
* [3. 最长摆动子序列](#3-最长摆动子序列)
|
||||
* [最长公共子序列](#最长公共子序列)
|
||||
* [1. 最长公共子序列](#1-最长公共子序列)
|
||||
* [0-1 背包](#0-1-背包)
|
||||
* [1. 划分数组为和相等的两部分](#1-划分数组为和相等的两部分)
|
||||
* [2. 改变一组数的正负号使得它们的和为一给定数](#2-改变一组数的正负号使得它们的和为一给定数)
|
||||
* [3. 01 字符构成最多的字符串](#3-01-字符构成最多的字符串)
|
||||
* [4. 找零钱的最少硬币数](#4-找零钱的最少硬币数)
|
||||
* [5. 找零钱的硬币数组合](#5-找零钱的硬币数组合)
|
||||
* [6. 字符串按单词列表分割](#6-字符串按单词列表分割)
|
||||
* [7. 组合总和](#7-组合总和)
|
||||
* [股票交易](#股票交易)
|
||||
* [1. 需要冷却期的股票交易](#1-需要冷却期的股票交易)
|
||||
* [2. 需要交易费用的股票交易](#2-需要交易费用的股票交易)
|
||||
* [3. 只能进行两次的股票交易](#3-只能进行两次的股票交易)
|
||||
* [4. 只能进行 k 次的股票交易](#4-只能进行-k-次的股票交易)
|
||||
* [字符串编辑](#字符串编辑)
|
||||
* [1. 删除两个字符串的字符使它们相等](#1-删除两个字符串的字符使它们相等)
|
||||
* [2. 编辑距离](#2-编辑距离)
|
||||
* [3. 复制粘贴字符](#3-复制粘贴字符)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [Leetcode 题解 - 动态规划](<Leetcode 题解 - 动态规划.md#leetcode-题解---动态规划>)
|
||||
* [斐波那契数列](<Leetcode 题解 - 动态规划.md#斐波那契数列>)
|
||||
* [1. 爬楼梯](<Leetcode 题解 - 动态规划.md#1-爬楼梯>)
|
||||
* [2. 强盗抢劫](<Leetcode 题解 - 动态规划.md#2-强盗抢劫>)
|
||||
* [3. 强盗在环形街区抢劫](<Leetcode 题解 - 动态规划.md#3-强盗在环形街区抢劫>)
|
||||
* [4. 信件错排](<Leetcode 题解 - 动态规划.md#4-信件错排>)
|
||||
* [5. 母牛生产](<Leetcode 题解 - 动态规划.md#5-母牛生产>)
|
||||
* [矩阵路径](<Leetcode 题解 - 动态规划.md#矩阵路径>)
|
||||
* [1. 矩阵的最小路径和](<Leetcode 题解 - 动态规划.md#1-矩阵的最小路径和>)
|
||||
* [2. 矩阵的总路径数](<Leetcode 题解 - 动态规划.md#2-矩阵的总路径数>)
|
||||
* [数组区间](<Leetcode 题解 - 动态规划.md#数组区间>)
|
||||
* [1. 数组区间和](<Leetcode 题解 - 动态规划.md#1-数组区间和>)
|
||||
* [2. 数组中等差递增子区间的个数](<Leetcode 题解 - 动态规划.md#2-数组中等差递增子区间的个数>)
|
||||
* [分割整数](<Leetcode 题解 - 动态规划.md#分割整数>)
|
||||
* [1. 分割整数的最大乘积](<Leetcode 题解 - 动态规划.md#1-分割整数的最大乘积>)
|
||||
* [2. 按平方数来分割整数](<Leetcode 题解 - 动态规划.md#2-按平方数来分割整数>)
|
||||
* [3. 分割整数构成字母字符串](<Leetcode 题解 - 动态规划.md#3-分割整数构成字母字符串>)
|
||||
* [最长递增子序列](<Leetcode 题解 - 动态规划.md#最长递增子序列>)
|
||||
* [1. 最长递增子序列](<Leetcode 题解 - 动态规划.md#1-最长递增子序列>)
|
||||
* [2. 一组整数对能够构成的最长链](<Leetcode 题解 - 动态规划.md#2-一组整数对能够构成的最长链>)
|
||||
* [3. 最长摆动子序列](<Leetcode 题解 - 动态规划.md#3-最长摆动子序列>)
|
||||
* [最长公共子序列](<Leetcode 题解 - 动态规划.md#最长公共子序列>)
|
||||
* [1. 最长公共子序列](<Leetcode 题解 - 动态规划.md#1-最长公共子序列>)
|
||||
* [0-1 背包](<Leetcode 题解 - 动态规划.md#0-1-背包>)
|
||||
* [1. 划分数组为和相等的两部分](<Leetcode 题解 - 动态规划.md#1-划分数组为和相等的两部分>)
|
||||
* [2. 改变一组数的正负号使得它们的和为一给定数](<Leetcode 题解 - 动态规划.md#2-改变一组数的正负号使得它们的和为一给定数>)
|
||||
* [3. 01 字符构成最多的字符串](<Leetcode 题解 - 动态规划.md#3-01-字符构成最多的字符串>)
|
||||
* [4. 找零钱的最少硬币数](<Leetcode 题解 - 动态规划.md#4-找零钱的最少硬币数>)
|
||||
* [5. 找零钱的硬币数组合](<Leetcode 题解 - 动态规划.md#5-找零钱的硬币数组合>)
|
||||
* [6. 字符串按单词列表分割](<Leetcode 题解 - 动态规划.md#6-字符串按单词列表分割>)
|
||||
* [7. 组合总和](<Leetcode 题解 - 动态规划.md#7-组合总和>)
|
||||
* [股票交易](<Leetcode 题解 - 动态规划.md#股票交易>)
|
||||
* [1. 需要冷却期的股票交易](<Leetcode 题解 - 动态规划.md#1-需要冷却期的股票交易>)
|
||||
* [2. 需要交易费用的股票交易](<Leetcode 题解 - 动态规划.md#2-需要交易费用的股票交易>)
|
||||
* [3. 只能进行两次的股票交易](<Leetcode 题解 - 动态规划.md#3-只能进行两次的股票交易>)
|
||||
* [4. 只能进行 k 次的股票交易](<Leetcode 题解 - 动态规划.md#4-只能进行-k-次的股票交易>)
|
||||
* [字符串编辑](<Leetcode 题解 - 动态规划.md#字符串编辑>)
|
||||
* [1. 删除两个字符串的字符使它们相等](<Leetcode 题解 - 动态规划.md#1-删除两个字符串的字符使它们相等>)
|
||||
* [2. 编辑距离](<Leetcode 题解 - 动态规划.md#2-编辑距离>)
|
||||
* [3. 复制粘贴字符](<Leetcode 题解 - 动态规划.md#3-复制粘贴字符>)
|
||||
|
||||
递归和动态规划都是将原问题拆成多个子问题然后求解,他们之间最本质的区别是,动态规划保存了子问题的解,避免重复计算。
|
||||
|
||||
@ -55,15 +53,14 @@
|
||||
|
||||
题目描述:有 N 阶楼梯,每次可以上一阶或者两阶,求有多少种上楼梯的方法。
|
||||
|
||||
定义一个数组 dp 存储上楼梯的方法数(为了方便讨论,数组下标从 1 开始),dp[i] 表示走到第 i 个楼梯的方法数目。
|
||||
定义一个数组 dp 存储上楼梯的方法数(为了方便讨论,数组下标从 1 开始),dp\[i] 表示走到第 i 个楼梯的方法数目。
|
||||
|
||||
第 i 个楼梯可以从第 i-1 和 i-2 个楼梯再走一步到达,走到第 i 个楼梯的方法数为走到第 i-1 和第 i-2 个楼梯的方法数之和。
|
||||
|
||||
<!--<div align="center"><img src="https://latex.codecogs.com/gif.latex?dp[i]=dp[i-1]+dp[i-2]" class="mathjax-pic"/></div> <br>-->
|
||||
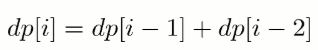\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/14fe1e71-8518-458f-a220-116003061a83.png" width="200px"> </div><br>
|
||||
|
||||
考虑到 dp[i] 只与 dp[i - 1] 和 dp[i - 2] 有关,因此可以只用两个变量来存储 dp[i - 1] 和 dp[i - 2],使得原来的 O(N) 空间复杂度优化为 O(1) 复杂度。
|
||||
考虑到 dp\[i] 只与 dp\[i - 1] 和 dp\[i - 2] 有关,因此可以只用两个变量来存储 dp\[i - 1] 和 dp\[i - 2],使得原来的 O(N) 空间复杂度优化为 O(1) 复杂度。
|
||||
|
||||
```java
|
||||
public int climbStairs(int n) {
|
||||
@ -88,13 +85,12 @@ public int climbStairs(int n) {
|
||||
|
||||
题目描述:抢劫一排住户,但是不能抢邻近的住户,求最大抢劫量。
|
||||
|
||||
定义 dp 数组用来存储最大的抢劫量,其中 dp[i] 表示抢到第 i 个住户时的最大抢劫量。
|
||||
定义 dp 数组用来存储最大的抢劫量,其中 dp\[i] 表示抢到第 i 个住户时的最大抢劫量。
|
||||
|
||||
由于不能抢劫邻近住户,如果抢劫了第 i -1 个住户,那么就不能再抢劫第 i 个住户,所以
|
||||
|
||||
<!--<div align="center"><img src="https://latex.codecogs.com/gif.latex?dp[i]=max(dp[i-2]+nums[i],dp[i-1])" class="mathjax-pic"/></div> <br>-->
|
||||
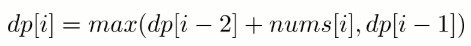\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/2de794ca-aa7b-48f3-a556-a0e2708cb976.jpg" width="350px"> </div><br>
|
||||
|
||||
```java
|
||||
public int rob(int[] nums) {
|
||||
@ -141,28 +137,26 @@ private int rob(int[] nums, int first, int last) {
|
||||
|
||||
题目描述:有 N 个 信 和 信封,它们被打乱,求错误装信方式的数量。
|
||||
|
||||
定义一个数组 dp 存储错误方式数量,dp[i] 表示前 i 个信和信封的错误方式数量。假设第 i 个信装到第 j 个信封里面,而第 j 个信装到第 k 个信封里面。根据 i 和 k 是否相等,有两种情况:
|
||||
定义一个数组 dp 存储错误方式数量,dp\[i] 表示前 i 个信和信封的错误方式数量。假设第 i 个信装到第 j 个信封里面,而第 j 个信装到第 k 个信封里面。根据 i 和 k 是否相等,有两种情况:
|
||||
|
||||
- i==k,交换 i 和 j 的信后,它们的信和信封在正确的位置,但是其余 i-2 封信有 dp[i-2] 种错误装信的方式。由于 j 有 i-1 种取值,因此共有 (i-1)\*dp[i-2] 种错误装信方式。
|
||||
- i != k,交换 i 和 j 的信后,第 i 个信和信封在正确的位置,其余 i-1 封信有 dp[i-1] 种错误装信方式。由于 j 有 i-1 种取值,因此共有 (i-1)\*dp[i-1] 种错误装信方式。
|
||||
* i==k,交换 i 和 j 的信后,它们的信和信封在正确的位置,但是其余 i-2 封信有 dp\[i-2] 种错误装信的方式。由于 j 有 i-1 种取值,因此共有 (i-1)\*dp\[i-2] 种错误装信方式。
|
||||
* i != k,交换 i 和 j 的信后,第 i 个信和信封在正确的位置,其余 i-1 封信有 dp\[i-1] 种错误装信方式。由于 j 有 i-1 种取值,因此共有 (i-1)\*dp\[i-1] 种错误装信方式。
|
||||
|
||||
综上所述,错误装信数量方式数量为:
|
||||
|
||||
<!--<div align="center"><img src="https://latex.codecogs.com/gif.latex?dp[i]=(i-1)*dp[i-2]+(i-1)*dp[i-1]" class="mathjax-pic"/></div> <br>-->
|
||||
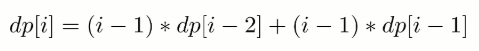\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/da1f96b9-fd4d-44ca-8925-fb14c5733388.png" width="350px"> </div><br>
|
||||
|
||||
### 5. 母牛生产
|
||||
|
||||
[程序员代码面试指南-P181](#)
|
||||
[程序员代码面试指南-P181](<Leetcode 题解 - 动态规划.md>)
|
||||
|
||||
题目描述:假设农场中成熟的母牛每年都会生 1 头小母牛,并且永远不会死。第一年有 1 只小母牛,从第二年开始,母牛开始生小母牛。每只小母牛 3 年之后成熟又可以生小母牛。给定整数 N,求 N 年后牛的数量。
|
||||
|
||||
第 i 年成熟的牛的数量为:
|
||||
|
||||
<!--<div align="center"><img src="https://latex.codecogs.com/gif.latex?dp[i]=dp[i-1]+dp[i-3]" class="mathjax-pic"/></div> <br>-->
|
||||
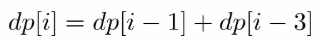\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/879814ee-48b5-4bcb-86f5-dcc400cb81ad.png" width="250px"> </div><br>
|
||||
|
||||
## 矩阵路径
|
||||
|
||||
@ -212,7 +206,8 @@ public int minPathSum(int[][] grid) {
|
||||
|
||||
题目描述:统计从矩阵左上角到右下角的路径总数,每次只能向右或者向下移动。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/dc82f0f3-c1d4-4ac8-90ac-d5b32a9bd75a.jpg" width=""> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```java
|
||||
public int uniquePaths(int m, int n) {
|
||||
@ -257,7 +252,7 @@ sumRange(2, 5) -> -1
|
||||
sumRange(0, 5) -> -3
|
||||
```
|
||||
|
||||
求区间 i \~ j 的和,可以转换为 sum[j + 1] - sum[i],其中 sum[i] 为 0 \~ i - 1 的和。
|
||||
求区间 i \~ j 的和,可以转换为 sum\[j + 1] - sum\[i],其中 sum\[i] 为 0 \~ i - 1 的和。
|
||||
|
||||
```java
|
||||
class NumArray {
|
||||
@ -296,9 +291,9 @@ return: 6, for 3 arithmetic slices in A:
|
||||
[2, 3, 4]
|
||||
```
|
||||
|
||||
dp[i] 表示以 A[i] 为结尾的等差递增子区间的个数。
|
||||
dp\[i] 表示以 A\[i] 为结尾的等差递增子区间的个数。
|
||||
|
||||
当 A[i] - A[i-1] == A[i-1] - A[i-2],那么 [A[i-2], A[i-1], A[i]] 构成一个等差递增子区间。而且在以 A[i-1] 为结尾的递增子区间的后面再加上一个 A[i],一样可以构成新的递增子区间。
|
||||
当 A\[i] - A\[i-1] == A\[i-1] - A\[i-2],那么 \[A\[i-2], A\[i-1], A\[i]] 构成一个等差递增子区间。而且在以 A\[i-1] 为结尾的递增子区间的后面再加上一个 A\[i],一样可以构成新的递增子区间。
|
||||
|
||||
```html
|
||||
dp[2] = 1
|
||||
@ -312,7 +307,7 @@ dp[4] = dp[3] + 1 = 3
|
||||
[2, 3, 4] // 新的递增子区间
|
||||
```
|
||||
|
||||
综上,在 A[i] - A[i-1] == A[i-1] - A[i-2] 时,dp[i] = dp[i-1] + 1。
|
||||
综上,在 A\[i] - A\[i-1] == A\[i-1] - A\[i-2] 时,dp\[i] = dp\[i-1] + 1。
|
||||
|
||||
因为递增子区间不一定以最后一个元素为结尾,可以是任意一个元素结尾,因此需要返回 dp 数组累加的结果。
|
||||
|
||||
@ -433,19 +428,18 @@ public int numDecodings(String s) {
|
||||
|
||||
## 最长递增子序列
|
||||
|
||||
已知一个序列 {S<sub>1</sub>, S<sub>2</sub>,...,S<sub>n</sub>},取出若干数组成新的序列 {S<sub>i1</sub>, S<sub>i2</sub>,..., S<sub>im</sub>},其中 i1、i2 ... im 保持递增,即新序列中各个数仍然保持原数列中的先后顺序,称新序列为原序列的一个 **子序列** 。
|
||||
已知一个序列 {S1, S2,...,Sn},取出若干数组成新的序列 {Si1, Si2,..., Sim},其中 i1、i2 ... im 保持递增,即新序列中各个数仍然保持原数列中的先后顺序,称新序列为原序列的一个 **子序列** 。
|
||||
|
||||
如果在子序列中,当下标 ix > iy 时,S<sub>ix</sub> > S<sub>iy</sub>,称子序列为原序列的一个 **递增子序列** 。
|
||||
如果在子序列中,当下标 ix > iy 时,Six > Siy,称子序列为原序列的一个 **递增子序列** 。
|
||||
|
||||
定义一个数组 dp 存储最长递增子序列的长度,dp[n] 表示以 S<sub>n</sub> 结尾的序列的最长递增子序列长度。对于一个递增子序列 {S<sub>i1</sub>, S<sub>i2</sub>,...,S<sub>im</sub>},如果 im < n 并且 S<sub>im</sub> < S<sub>n</sub>,此时 {S<sub>i1</sub>, S<sub>i2</sub>,..., S<sub>im</sub>, S<sub>n</sub>} 为一个递增子序列,递增子序列的长度增加 1。满足上述条件的递增子序列中,长度最长的那个递增子序列就是要找的,在长度最长的递增子序列上加上 S<sub>n</sub> 就构成了以 S<sub>n</sub> 为结尾的最长递增子序列。因此 dp[n] = max{ dp[i]+1 | S<sub>i</sub> < S<sub>n</sub> && i < n} 。
|
||||
定义一个数组 dp 存储最长递增子序列的长度,dp\[n] 表示以 Sn 结尾的序列的最长递增子序列长度。对于一个递增子序列 {Si1, Si2,...,Sim},如果 im < n 并且 Sim < Sn,此时 {Si1, Si2,..., Sim, Sn} 为一个递增子序列,递增子序列的长度增加 1。满足上述条件的递增子序列中,长度最长的那个递增子序列就是要找的,在长度最长的递增子序列上加上 Sn 就构成了以 Sn 为结尾的最长递增子序列。因此 dp\[n] = max{ dp\[i]+1 | Si < Sn && i < n} 。
|
||||
|
||||
因为在求 dp[n] 时可能无法找到一个满足条件的递增子序列,此时 {S<sub>n</sub>} 就构成了递增子序列,需要对前面的求解方程做修改,令 dp[n] 最小为 1,即:
|
||||
因为在求 dp\[n] 时可能无法找到一个满足条件的递增子序列,此时 {Sn} 就构成了递增子序列,需要对前面的求解方程做修改,令 dp\[n] 最小为 1,即:
|
||||
|
||||
<!--<div align="center"><img src="https://latex.codecogs.com/gif.latex?dp[n]=max\{1,dp[i]+1|S_i<S_n\&\&i<n\}" class="mathjax-pic"/></div> <br>-->
|
||||
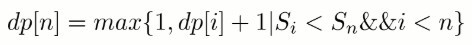\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/ee994da4-0fc7-443d-ac56-c08caf00a204.jpg" width="350px"> </div><br>
|
||||
|
||||
对于一个长度为 N 的序列,最长递增子序列并不一定会以 S<sub>N</sub> 为结尾,因此 dp[N] 不是序列的最长递增子序列的长度,需要遍历 dp 数组找出最大值才是所要的结果,max{ dp[i] | 1 <= i <= N} 即为所求。
|
||||
对于一个长度为 N 的序列,最长递增子序列并不一定会以 SN 为结尾,因此 dp\[N] 不是序列的最长递增子序列的长度,需要遍历 dp 数组找出最大值才是所要的结果,max{ dp\[i] | 1 <= i <= N} 即为所求。
|
||||
|
||||
### 1. 最长递增子序列
|
||||
|
||||
@ -480,14 +474,14 @@ for (int i = 0; i < n; i++) {
|
||||
return ret;
|
||||
```
|
||||
|
||||
以上解法的时间复杂度为 O(N<sup>2</sup>),可以使用二分查找将时间复杂度降低为 O(NlogN)。
|
||||
以上解法的时间复杂度为 O(N2),可以使用二分查找将时间复杂度降低为 O(NlogN)。
|
||||
|
||||
定义一个 tails 数组,其中 tails[i] 存储长度为 i + 1 的最长递增子序列的最后一个元素。对于一个元素 x,
|
||||
定义一个 tails 数组,其中 tails\[i] 存储长度为 i + 1 的最长递增子序列的最后一个元素。对于一个元素 x,
|
||||
|
||||
- 如果它大于 tails 数组所有的值,那么把它添加到 tails 后面,表示最长递增子序列长度加 1;
|
||||
- 如果 tails[i-1] \< x \<= tails[i],那么更新 tails[i] = x。
|
||||
* 如果它大于 tails 数组所有的值,那么把它添加到 tails 后面,表示最长递增子序列长度加 1;
|
||||
* 如果 tails\[i-1] < x <= tails\[i],那么更新 tails\[i] = x。
|
||||
|
||||
例如对于数组 [4,3,6,5],有:
|
||||
例如对于数组 \[4,3,6,5],有:
|
||||
|
||||
```html
|
||||
tails len num
|
||||
@ -498,7 +492,7 @@ tails len num
|
||||
[3,5] 2 null
|
||||
```
|
||||
|
||||
可以看出 tails 数组保持有序,因此在查找 S<sub>i</sub> 位于 tails 数组的位置时就可以使用二分查找。
|
||||
可以看出 tails 数组保持有序,因此在查找 Si 位于 tails 数组的位置时就可以使用二分查找。
|
||||
|
||||
```java
|
||||
public int lengthOfLIS(int[] nums) {
|
||||
@ -543,7 +537,7 @@ Output: 2
|
||||
Explanation: The longest chain is [1,2] -> [3,4]
|
||||
```
|
||||
|
||||
题目描述:对于 (a, b) 和 (c, d) ,如果 b \< c,则它们可以构成一条链。
|
||||
题目描述:对于 (a, b) 和 (c, d) ,如果 b < c,则它们可以构成一条链。
|
||||
|
||||
```java
|
||||
public int findLongestChain(int[][] pairs) {
|
||||
@ -607,24 +601,23 @@ public int wiggleMaxLength(int[] nums) {
|
||||
|
||||
对于两个子序列 S1 和 S2,找出它们最长的公共子序列。
|
||||
|
||||
定义一个二维数组 dp 用来存储最长公共子序列的长度,其中 dp[i][j] 表示 S1 的前 i 个字符与 S2 的前 j 个字符最长公共子序列的长度。考虑 S1<sub>i</sub> 与 S2<sub>j</sub> 值是否相等,分为两种情况:
|
||||
定义一个二维数组 dp 用来存储最长公共子序列的长度,其中 dp\[i]\[j] 表示 S1 的前 i 个字符与 S2 的前 j 个字符最长公共子序列的长度。考虑 S1i 与 S2j 值是否相等,分为两种情况:
|
||||
|
||||
- 当 S1<sub>i</sub>==S2<sub>j</sub> 时,那么就能在 S1 的前 i-1 个字符与 S2 的前 j-1 个字符最长公共子序列的基础上再加上 S1<sub>i</sub> 这个值,最长公共子序列长度加 1,即 dp[i][j] = dp[i-1][j-1] + 1。
|
||||
- 当 S1<sub>i</sub> != S2<sub>j</sub> 时,此时最长公共子序列为 S1 的前 i-1 个字符和 S2 的前 j 个字符最长公共子序列,或者 S1 的前 i 个字符和 S2 的前 j-1 个字符最长公共子序列,取它们的最大者,即 dp[i][j] = max{ dp[i-1][j], dp[i][j-1] }。
|
||||
* 当 S1i==S2j 时,那么就能在 S1 的前 i-1 个字符与 S2 的前 j-1 个字符最长公共子序列的基础上再加上 S1i 这个值,最长公共子序列长度加 1,即 dp\[i]\[j] = dp\[i-1]\[j-1] + 1。
|
||||
* 当 S1i != S2j 时,此时最长公共子序列为 S1 的前 i-1 个字符和 S2 的前 j 个字符最长公共子序列,或者 S1 的前 i 个字符和 S2 的前 j-1 个字符最长公共子序列,取它们的最大者,即 dp\[i]\[j] = max{ dp\[i-1]\[j], dp\[i]\[j-1] }。
|
||||
|
||||
综上,最长公共子序列的状态转移方程为:
|
||||
|
||||
<!--<div align="center"><img src="https://latex.codecogs.com/gif.latex?dp[i][j]=\left\{\begin{array}{rcl}dp[i-1][j-1]&&{S1_i==S2_j}\\max(dp[i-1][j],dp[i][j-1])&&{S1_i<>S2_j}\end{array}\right." class="mathjax-pic"/></div> <br>-->
|
||||
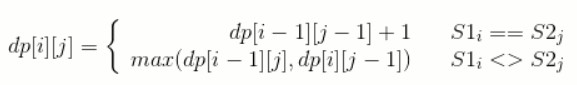\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/ecd89a22-c075-4716-8423-e0ba89230e9a.jpg" width="450px"> </div><br>
|
||||
|
||||
对于长度为 N 的序列 S<sub>1</sub> 和长度为 M 的序列 S<sub>2</sub>,dp[N][M] 就是序列 S<sub>1</sub> 和序列 S<sub>2</sub> 的最长公共子序列长度。
|
||||
对于长度为 N 的序列 S1 和长度为 M 的序列 S2,dp\[N]\[M] 就是序列 S1 和序列 S2 的最长公共子序列长度。
|
||||
|
||||
与最长递增子序列相比,最长公共子序列有以下不同点:
|
||||
|
||||
- 针对的是两个序列,求它们的最长公共子序列。
|
||||
- 在最长递增子序列中,dp[i] 表示以 S<sub>i</sub> 为结尾的最长递增子序列长度,子序列必须包含 S<sub>i</sub> ;在最长公共子序列中,dp[i][j] 表示 S1 中前 i 个字符与 S2 中前 j 个字符的最长公共子序列长度,不一定包含 S1<sub>i</sub> 和 S2<sub>j</sub>。
|
||||
- 在求最终解时,最长公共子序列中 dp[N][M] 就是最终解,而最长递增子序列中 dp[N] 不是最终解,因为以 S<sub>N</sub> 为结尾的最长递增子序列不一定是整个序列最长递增子序列,需要遍历一遍 dp 数组找到最大者。
|
||||
* 针对的是两个序列,求它们的最长公共子序列。
|
||||
* 在最长递增子序列中,dp\[i] 表示以 Si 为结尾的最长递增子序列长度,子序列必须包含 Si ;在最长公共子序列中,dp\[i]\[j] 表示 S1 中前 i 个字符与 S2 中前 j 个字符的最长公共子序列长度,不一定包含 S1i 和 S2j。
|
||||
* 在求最终解时,最长公共子序列中 dp\[N]\[M] 就是最终解,而最长递增子序列中 dp\[N] 不是最终解,因为以 SN 为结尾的最长递增子序列不一定是整个序列最长递增子序列,需要遍历一遍 dp 数组找到最大者。
|
||||
|
||||
### 1. 最长公共子序列
|
||||
|
||||
@ -653,16 +646,15 @@ public int wiggleMaxLength(int[] nums) {
|
||||
|
||||
有一个容量为 N 的背包,要用这个背包装下物品的价值最大,这些物品有两个属性:体积 w 和价值 v。
|
||||
|
||||
定义一个二维数组 dp 存储最大价值,其中 dp[i][j] 表示前 i 件物品体积不超过 j 的情况下能达到的最大价值。设第 i 件物品体积为 w,价值为 v,根据第 i 件物品是否添加到背包中,可以分两种情况讨论:
|
||||
定义一个二维数组 dp 存储最大价值,其中 dp\[i]\[j] 表示前 i 件物品体积不超过 j 的情况下能达到的最大价值。设第 i 件物品体积为 w,价值为 v,根据第 i 件物品是否添加到背包中,可以分两种情况讨论:
|
||||
|
||||
- 第 i 件物品没添加到背包,总体积不超过 j 的前 i 件物品的最大价值就是总体积不超过 j 的前 i-1 件物品的最大价值,dp[i][j] = dp[i-1][j]。
|
||||
- 第 i 件物品添加到背包中,dp[i][j] = dp[i-1][j-w] + v。
|
||||
* 第 i 件物品没添加到背包,总体积不超过 j 的前 i 件物品的最大价值就是总体积不超过 j 的前 i-1 件物品的最大价值,dp\[i]\[j] = dp\[i-1]\[j]。
|
||||
* 第 i 件物品添加到背包中,dp\[i]\[j] = dp\[i-1]\[j-w] + v。
|
||||
|
||||
第 i 件物品可添加也可以不添加,取决于哪种情况下最大价值更大。因此,0-1 背包的状态转移方程为:
|
||||
|
||||
<!--<div align="center"><img src="https://latex.codecogs.com/gif.latex?dp[i][j]=max(dp[i-1][j],dp[i-1][j-w]+v)" class="mathjax-pic"/></div> <br>-->
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/8cb2be66-3d47-41ba-b55b-319fc68940d4.png" width="400px"> </div><br>
|
||||
|
||||
```java
|
||||
// W 为背包总体积
|
||||
@ -685,15 +677,14 @@ public int knapsack(int W, int N, int[] weights, int[] values) {
|
||||
}
|
||||
```
|
||||
|
||||
**空间优化**
|
||||
**空间优化**
|
||||
|
||||
在程序实现时可以对 0-1 背包做优化。观察状态转移方程可以知道,前 i 件物品的状态仅与前 i-1 件物品的状态有关,因此可以将 dp 定义为一维数组,其中 dp[j] 既可以表示 dp[i-1][j] 也可以表示 dp[i][j]。此时,
|
||||
在程序实现时可以对 0-1 背包做优化。观察状态转移方程可以知道,前 i 件物品的状态仅与前 i-1 件物品的状态有关,因此可以将 dp 定义为一维数组,其中 dp\[j] 既可以表示 dp\[i-1]\[j] 也可以表示 dp\[i]\[j]。此时,
|
||||
|
||||
<!--<div align="center"><img src="https://latex.codecogs.com/gif.latex?dp[j]=max(dp[j],dp[j-w]+v)" class="mathjax-pic"/></div> <br>-->
|
||||
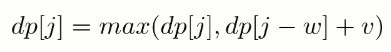\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/9ae89f16-7905-4a6f-88a2-874b4cac91f4.jpg" width="300px"> </div><br>
|
||||
|
||||
因为 dp[j-w] 表示 dp[i-1][j-w],因此不能先求 dp[i][j-w],防止将 dp[i-1][j-w] 覆盖。也就是说要先计算 dp[i][j] 再计算 dp[i][j-w],在程序实现时需要按倒序来循环求解。
|
||||
因为 dp\[j-w] 表示 dp\[i-1]\[j-w],因此不能先求 dp\[i]\[j-w],防止将 dp\[i-1]\[j-w] 覆盖。也就是说要先计算 dp\[i]\[j] 再计算 dp\[i]\[j-w],在程序实现时需要按倒序来循环求解。
|
||||
|
||||
```java
|
||||
public int knapsack(int W, int N, int[] weights, int[] values) {
|
||||
@ -710,25 +701,22 @@ public int knapsack(int W, int N, int[] weights, int[] values) {
|
||||
}
|
||||
```
|
||||
|
||||
**无法使用贪心算法的解释**
|
||||
**无法使用贪心算法的解释**
|
||||
|
||||
0-1 背包问题无法使用贪心算法来求解,也就是说不能按照先添加性价比最高的物品来达到最优,这是因为这种方式可能造成背包空间的浪费,从而无法达到最优。考虑下面的物品和一个容量为 5 的背包,如果先添加物品 0 再添加物品 1,那么只能存放的价值为 16,浪费了大小为 2 的空间。最优的方式是存放物品 1 和物品 2,价值为 22.
|
||||
|
||||
| id | w | v | v/w |
|
||||
| --- | --- | --- | --- |
|
||||
| 0 | 1 | 6 | 6 |
|
||||
| 1 | 2 | 10 | 5 |
|
||||
| 2 | 3 | 12 | 4 |
|
||||
| id | w | v | v/w |
|
||||
| -- | - | -- | --- |
|
||||
| 0 | 1 | 6 | 6 |
|
||||
| 1 | 2 | 10 | 5 |
|
||||
| 2 | 3 | 12 | 4 |
|
||||
|
||||
**变种**
|
||||
**变种**
|
||||
|
||||
- 完全背包:物品数量为无限个
|
||||
|
||||
- 多重背包:物品数量有限制
|
||||
|
||||
- 多维费用背包:物品不仅有重量,还有体积,同时考虑这两种限制
|
||||
|
||||
- 其它:物品之间相互约束或者依赖
|
||||
* 完全背包:物品数量为无限个
|
||||
* 多重背包:物品数量有限制
|
||||
* 多维费用背包:物品不仅有重量,还有体积,同时考虑这两种限制
|
||||
* 其它:物品之间相互约束或者依赖
|
||||
|
||||
### 1. 划分数组为和相等的两部分
|
||||
|
||||
@ -904,9 +892,9 @@ return -1.
|
||||
|
||||
题目描述:给一些面额的硬币,要求用这些硬币来组成给定面额的钱数,并且使得硬币数量最少。硬币可以重复使用。
|
||||
|
||||
- 物品:硬币
|
||||
- 物品大小:面额
|
||||
- 物品价值:数量
|
||||
* 物品:硬币
|
||||
* 物品大小:面额
|
||||
* 物品价值:数量
|
||||
|
||||
因为硬币可以重复使用,因此这是一个完全背包问题。完全背包只需要将 0-1 背包的逆序遍历 dp 数组改为正序遍历即可。
|
||||
|
||||
@ -936,7 +924,7 @@ public int coinChange(int[] coins, int amount) {
|
||||
|
||||
[Leetcode](https://leetcode.com/problems/coin-change-2/description/) / [力扣](https://leetcode-cn.com/problems/coin-change-2/description/)
|
||||
|
||||
```text-html-basic
|
||||
```
|
||||
Input: amount = 5, coins = [1, 2, 5]
|
||||
Output: 4
|
||||
Explanation: there are four ways to make up the amount:
|
||||
@ -1056,7 +1044,8 @@ public int combinationSum4(int[] nums, int target) {
|
||||
|
||||
题目描述:交易之后需要有一天的冷却时间。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/ffd96b99-8009-487c-8e98-11c9d44ef14f.png" width="300px"> </div><br>
|
||||
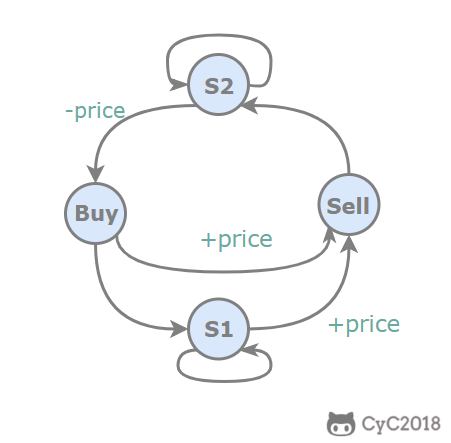\
|
||||
|
||||
|
||||
```java
|
||||
public int maxProfit(int[] prices) {
|
||||
@ -1099,7 +1088,8 @@ The total profit is ((8 - 1) - 2) + ((9 - 4) - 2) = 8.
|
||||
|
||||
题目描述:每交易一次,都要支付一定的费用。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/1e2c588c-72b7-445e-aacb-d55dc8a88c29.png" width="300px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```java
|
||||
public int maxProfit(int[] prices, int fee) {
|
||||
@ -1120,7 +1110,6 @@ public int maxProfit(int[] prices, int fee) {
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### 3. 只能进行两次的股票交易
|
||||
|
||||
123\. Best Time to Buy and Sell Stock III (Hard)
|
||||
|
||||
@ -1,15 +1,13 @@
|
||||
# Leetcode 题解 - 双指针
|
||||
<!-- GFM-TOC -->
|
||||
* [Leetcode 题解 - 双指针](#leetcode-题解---双指针)
|
||||
* [1. 有序数组的 Two Sum](#1-有序数组的-two-sum)
|
||||
* [2. 两数平方和](#2-两数平方和)
|
||||
* [3. 反转字符串中的元音字符](#3-反转字符串中的元音字符)
|
||||
* [4. 回文字符串](#4-回文字符串)
|
||||
* [5. 归并两个有序数组](#5-归并两个有序数组)
|
||||
* [6. 判断链表是否存在环](#6-判断链表是否存在环)
|
||||
* [7. 最长子序列](#7-最长子序列)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [Leetcode 题解 - 双指针](<Leetcode 题解 - 双指针.md#leetcode-题解---双指针>)
|
||||
* [1. 有序数组的 Two Sum](<Leetcode 题解 - 双指针.md#1-有序数组的-two-sum>)
|
||||
* [2. 两数平方和](<Leetcode 题解 - 双指针.md#2-两数平方和>)
|
||||
* [3. 反转字符串中的元音字符](<Leetcode 题解 - 双指针.md#3-反转字符串中的元音字符>)
|
||||
* [4. 回文字符串](<Leetcode 题解 - 双指针.md#4-回文字符串>)
|
||||
* [5. 归并两个有序数组](<Leetcode 题解 - 双指针.md#5-归并两个有序数组>)
|
||||
* [6. 判断链表是否存在环](<Leetcode 题解 - 双指针.md#6-判断链表是否存在环>)
|
||||
* [7. 最长子序列](<Leetcode 题解 - 双指针.md#7-最长子序列>)
|
||||
|
||||
双指针主要用于遍历数组,两个指针指向不同的元素,从而协同完成任务。
|
||||
|
||||
@ -28,13 +26,14 @@ Output: index1=1, index2=2
|
||||
|
||||
使用双指针,一个指针指向值较小的元素,一个指针指向值较大的元素。指向较小元素的指针从头向尾遍历,指向较大元素的指针从尾向头遍历。
|
||||
|
||||
- 如果两个指针指向元素的和 sum == target,那么得到要求的结果;
|
||||
- 如果 sum \> target,移动较大的元素,使 sum 变小一些;
|
||||
- 如果 sum \< target,移动较小的元素,使 sum 变大一些。
|
||||
* 如果两个指针指向元素的和 sum == target,那么得到要求的结果;
|
||||
* 如果 sum > target,移动较大的元素,使 sum 变小一些;
|
||||
* 如果 sum < target,移动较小的元素,使 sum 变大一些。
|
||||
|
||||
数组中的元素最多遍历一次,时间复杂度为 O(N)。只使用了两个额外变量,空间复杂度为 O(1)。
|
||||
数组中的元素最多遍历一次,时间复杂度为 O(N)。只使用了两个额外变量,空间复杂度为 O(1)。
|
||||
|
||||
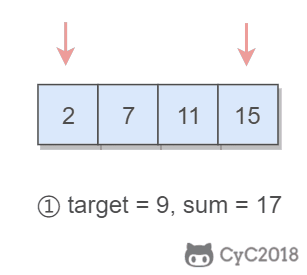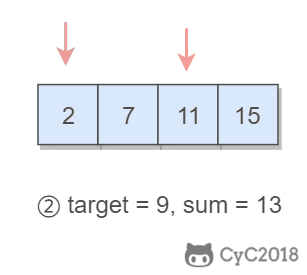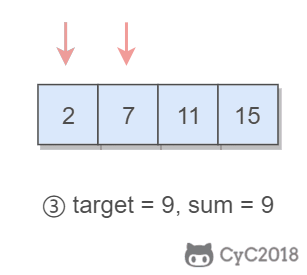\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/437cb54c-5970-4ba9-b2ef-2541f7d6c81e.gif" width="200px"> </div><br>
|
||||
|
||||
```java
|
||||
public int[] twoSum(int[] numbers, int target) {
|
||||
@ -70,9 +69,9 @@ Explanation: 1 * 1 + 2 * 2 = 5
|
||||
|
||||
可以看成是在元素为 0\~target 的有序数组中查找两个数,使得这两个数的平方和为 target,如果能找到,则返回 true,表示 target 是两个整数的平方和。
|
||||
|
||||
本题和 167\. Two Sum II - Input array is sorted 类似,只有一个明显区别:一个是和为 target,一个是平方和为 target。本题同样可以使用双指针得到两个数,使其平方和为 target。
|
||||
本题和 167. Two Sum II - Input array is sorted 类似,只有一个明显区别:一个是和为 target,一个是平方和为 target。本题同样可以使用双指针得到两个数,使其平方和为 target。
|
||||
|
||||
本题的关键是右指针的初始化,实现剪枝,从而降低时间复杂度。设右指针为 x,左指针固定为 0,为了使 0<sup>2</sup> + x<sup>2</sup> 的值尽可能接近 target,我们可以将 x 取为 sqrt(target)。
|
||||
本题的关键是右指针的初始化,实现剪枝,从而降低时间复杂度。设右指针为 x,左指针固定为 0,为了使 02 + x2 的值尽可能接近 target,我们可以将 x 取为 sqrt(target)。
|
||||
|
||||
因为最多只需要遍历一次 0\~sqrt(target),所以时间复杂度为 O(sqrt(target))。又因为只使用了两个额外的变量,因此空间复杂度为 O(1)。
|
||||
|
||||
@ -104,16 +103,18 @@ Explanation: 1 * 1 + 2 * 2 = 5
|
||||
Given s = "leetcode", return "leotcede".
|
||||
```
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/a7cb8423-895d-4975-8ef8-662a0029c772.png" width="400px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
使用双指针,一个指针从头向尾遍历,一个指针从尾到头遍历,当两个指针都遍历到元音字符时,交换这两个元音字符。
|
||||
|
||||
为了快速判断一个字符是不是元音字符,我们将全部元音字符添加到集合 HashSet 中,从而以 O(1) 的时间复杂度进行该操作。
|
||||
|
||||
- 时间复杂度为 O(N):只需要遍历所有元素一次
|
||||
- 空间复杂度 O(1):只需要使用两个额外变量
|
||||
* 时间复杂度为 O(N):只需要遍历所有元素一次
|
||||
* 空间复杂度 O(1):只需要使用两个额外变量
|
||||
|
||||
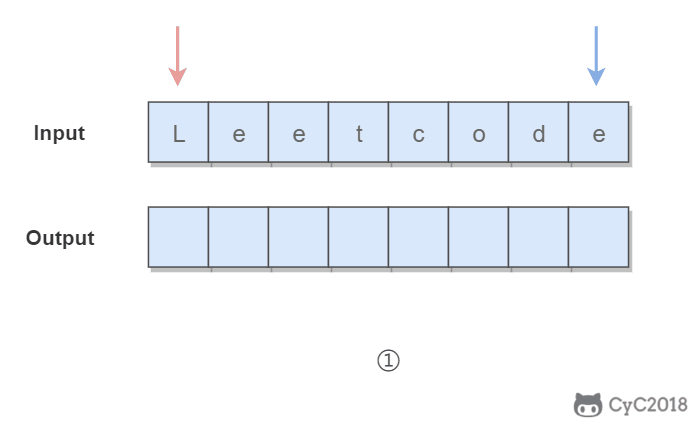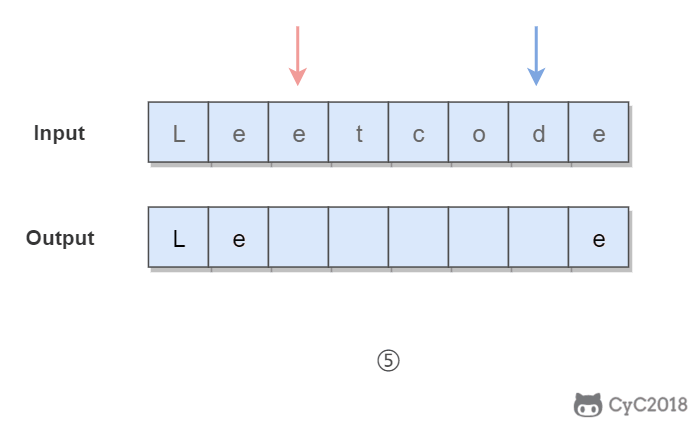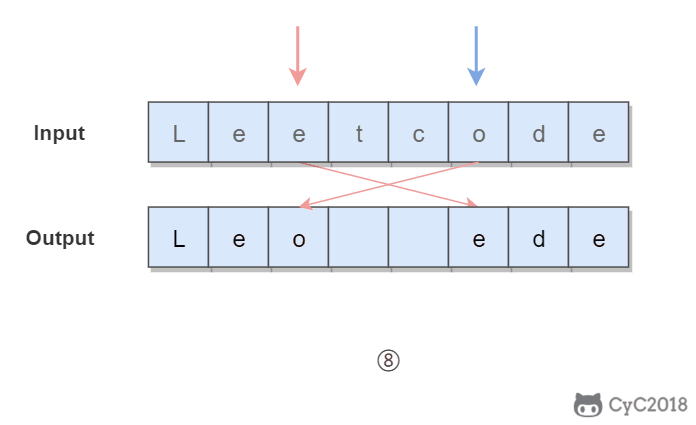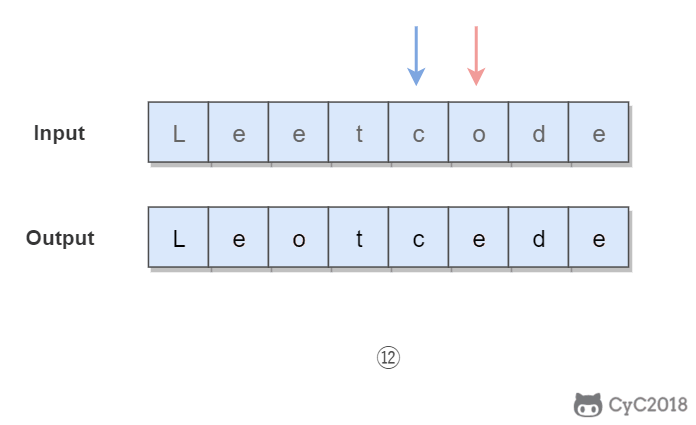\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/ef25ff7c-0f63-420d-8b30-eafbeea35d11.gif" width="400px"> </div><br>
|
||||
|
||||
```java
|
||||
private final static HashSet<Character> vowels = new HashSet<>(
|
||||
@ -157,7 +158,8 @@ Explanation: You could delete the character 'c'.
|
||||
|
||||
使用双指针可以很容易判断一个字符串是否是回文字符串:令一个指针从左到右遍历,一个指针从右到左遍历,这两个指针同时移动一个位置,每次都判断两个指针指向的字符是否相同,如果都相同,字符串才是具有左右对称性质的回文字符串。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/fcc941ec-134b-4dcd-bc86-1702fd305300.gif" width="250px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
本题的关键是处理删除一个字符。在使用双指针遍历字符串时,如果出现两个指针指向的字符不相等的情况,我们就试着删除一个字符,再判断删除完之后的字符串是否是回文字符串。
|
||||
|
||||
@ -165,7 +167,8 @@ Explanation: You could delete the character 'c'.
|
||||
|
||||
在试着删除字符时,我们既可以删除左指针指向的字符,也可以删除右指针指向的字符。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/db5f30a7-8bfa-4ecc-ab5d-747c77818964.gif" width="300px"> </div><br>
|
||||
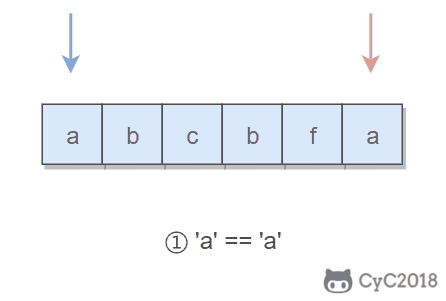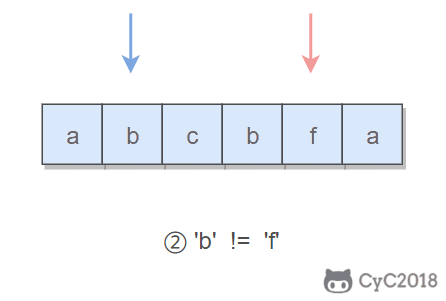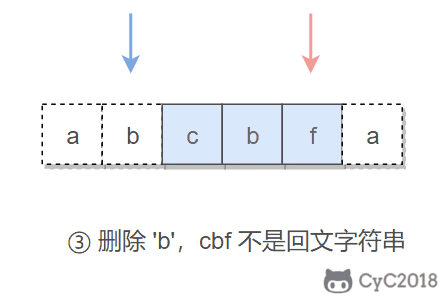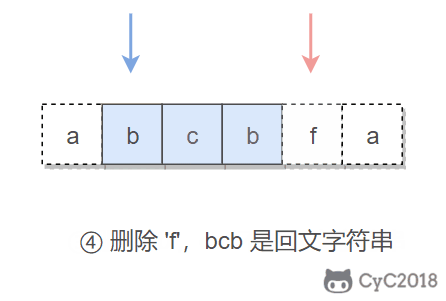\
|
||||
|
||||
|
||||
```java
|
||||
public boolean validPalindrome(String s) {
|
||||
|
||||
@ -1,26 +1,24 @@
|
||||
# Leetcode 题解 - 排序
|
||||
<!-- GFM-TOC -->
|
||||
* [Leetcode 题解 - 排序](#leetcode-题解---排序)
|
||||
* [快速选择](#快速选择)
|
||||
* [堆](#堆)
|
||||
* [1. Kth Element](#1-kth-element)
|
||||
* [桶排序](#桶排序)
|
||||
* [1. 出现频率最多的 k 个元素](#1-出现频率最多的-k-个元素)
|
||||
* [2. 按照字符出现次数对字符串排序](#2-按照字符出现次数对字符串排序)
|
||||
* [荷兰国旗问题](#荷兰国旗问题)
|
||||
* [1. 按颜色进行排序](#1-按颜色进行排序)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [Leetcode 题解 - 排序](<Leetcode 题解 - 排序.md#leetcode-题解---排序>)
|
||||
* [快速选择](<Leetcode 题解 - 排序.md#快速选择>)
|
||||
* [堆](<Leetcode 题解 - 排序.md#堆>)
|
||||
* [1. Kth Element](<Leetcode 题解 - 排序.md#1-kth-element>)
|
||||
* [桶排序](<Leetcode 题解 - 排序.md#桶排序>)
|
||||
* [1. 出现频率最多的 k 个元素](<Leetcode 题解 - 排序.md#1-出现频率最多的-k-个元素>)
|
||||
* [2. 按照字符出现次数对字符串排序](<Leetcode 题解 - 排序.md#2-按照字符出现次数对字符串排序>)
|
||||
* [荷兰国旗问题](<Leetcode 题解 - 排序.md#荷兰国旗问题>)
|
||||
* [1. 按颜色进行排序](<Leetcode 题解 - 排序.md#1-按颜色进行排序>)
|
||||
|
||||
## 快速选择
|
||||
|
||||
用于求解 **Kth Element** 问题,也就是第 K 个元素的问题。
|
||||
用于求解 **Kth Element** 问题,也就是第 K 个元素的问题。
|
||||
|
||||
可以使用快速排序的 partition() 进行实现。需要先打乱数组,否则最坏情况下时间复杂度为 O(N<sup>2</sup>)。
|
||||
可以使用快速排序的 partition() 进行实现。需要先打乱数组,否则最坏情况下时间复杂度为 O(N2)。
|
||||
|
||||
## 堆
|
||||
|
||||
用于求解 **TopK Elements** 问题,也就是 K 个最小元素的问题。使用最小堆来实现 TopK 问题,最小堆使用大顶堆来实现,大顶堆的堆顶元素为当前堆的最大元素。实现过程:不断地往大顶堆中插入新元素,当堆中元素的数量大于 k 时,移除堆顶元素,也就是当前堆中最大的元素,剩下的元素都为当前添加过的元素中最小的 K 个元素。插入和移除堆顶元素的时间复杂度都为 log<sub>2</sub>N。
|
||||
用于求解 **TopK Elements** 问题,也就是 K 个最小元素的问题。使用最小堆来实现 TopK 问题,最小堆使用大顶堆来实现,大顶堆的堆顶元素为当前堆的最大元素。实现过程:不断地往大顶堆中插入新元素,当堆中元素的数量大于 k 时,移除堆顶元素,也就是当前堆中最大的元素,剩下的元素都为当前添加过的元素中最小的 K 个元素。插入和移除堆顶元素的时间复杂度都为 log2N。
|
||||
|
||||
堆也可以用于求解 Kth Element 问题,得到了大小为 K 的最小堆之后,因为使用了大顶堆来实现,因此堆顶元素就是第 K 大的元素。
|
||||
|
||||
@ -34,14 +32,14 @@
|
||||
|
||||
[Leetcode](https://leetcode.com/problems/kth-largest-element-in-an-array/description/) / [力扣](https://leetcode-cn.com/problems/kth-largest-element-in-an-array/description/)
|
||||
|
||||
```text
|
||||
```
|
||||
Input: [3,2,1,5,6,4] and k = 2
|
||||
Output: 5
|
||||
```
|
||||
|
||||
题目描述:找到倒数第 k 个的元素。
|
||||
|
||||
**排序** :时间复杂度 O(NlogN),空间复杂度 O(1)
|
||||
**排序** :时间复杂度 O(NlogN),空间复杂度 O(1)
|
||||
|
||||
```java
|
||||
public int findKthLargest(int[] nums, int k) {
|
||||
@ -50,7 +48,7 @@ public int findKthLargest(int[] nums, int k) {
|
||||
}
|
||||
```
|
||||
|
||||
**堆** :时间复杂度 O(NlogK),空间复杂度 O(K)。
|
||||
**堆** :时间复杂度 O(NlogK),空间复杂度 O(K)。
|
||||
|
||||
```java
|
||||
public int findKthLargest(int[] nums, int k) {
|
||||
@ -64,7 +62,7 @@ public int findKthLargest(int[] nums, int k) {
|
||||
}
|
||||
```
|
||||
|
||||
**快速选择** :时间复杂度 O(N),空间复杂度 O(1)
|
||||
**快速选择** :时间复杂度 O(N),空间复杂度 O(1)
|
||||
|
||||
```java
|
||||
public int findKthLargest(int[] nums, int k) {
|
||||
@ -206,7 +204,7 @@ public String frequencySort(String s) {
|
||||
|
||||
有三种颜色的球,算法的目标是将这三种球按颜色顺序正确地排列。它其实是三向切分快速排序的一种变种,在三向切分快速排序中,每次切分都将数组分成三个区间:小于切分元素、等于切分元素、大于切分元素,而该算法是将数组分成三个区间:等于红色、等于白色、等于蓝色。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/7a3215ec-6fb7-4935-8b0d-cb408208f7cb.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### 1. 按颜色进行排序
|
||||
|
||||
@ -1,65 +1,64 @@
|
||||
# Leetcode 题解 - 搜索
|
||||
<!-- GFM-TOC -->
|
||||
* [Leetcode 题解 - 搜索](#leetcode-题解---搜索)
|
||||
* [BFS](#bfs)
|
||||
* [1. 计算在网格中从原点到特定点的最短路径长度](#1-计算在网格中从原点到特定点的最短路径长度)
|
||||
* [2. 组成整数的最小平方数数量](#2-组成整数的最小平方数数量)
|
||||
* [3. 最短单词路径](#3-最短单词路径)
|
||||
* [DFS](#dfs)
|
||||
* [1. 查找最大的连通面积](#1-查找最大的连通面积)
|
||||
* [2. 矩阵中的连通分量数目](#2-矩阵中的连通分量数目)
|
||||
* [3. 好友关系的连通分量数目](#3-好友关系的连通分量数目)
|
||||
* [4. 填充封闭区域](#4-填充封闭区域)
|
||||
* [5. 能到达的太平洋和大西洋的区域](#5-能到达的太平洋和大西洋的区域)
|
||||
* [Backtracking](#backtracking)
|
||||
* [1. 数字键盘组合](#1-数字键盘组合)
|
||||
* [2. IP 地址划分](#2-ip-地址划分)
|
||||
* [3. 在矩阵中寻找字符串](#3-在矩阵中寻找字符串)
|
||||
* [4. 输出二叉树中所有从根到叶子的路径](#4-输出二叉树中所有从根到叶子的路径)
|
||||
* [5. 排列](#5-排列)
|
||||
* [6. 含有相同元素求排列](#6-含有相同元素求排列)
|
||||
* [7. 组合](#7-组合)
|
||||
* [8. 组合求和](#8-组合求和)
|
||||
* [9. 含有相同元素的组合求和](#9-含有相同元素的组合求和)
|
||||
* [10. 1-9 数字的组合求和](#10-1-9-数字的组合求和)
|
||||
* [11. 子集](#11-子集)
|
||||
* [12. 含有相同元素求子集](#12-含有相同元素求子集)
|
||||
* [13. 分割字符串使得每个部分都是回文数](#13-分割字符串使得每个部分都是回文数)
|
||||
* [14. 数独](#14-数独)
|
||||
* [15. N 皇后](#15-n-皇后)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [Leetcode 题解 - 搜索](<Leetcode 题解 - 搜索.md#leetcode-题解---搜索>)
|
||||
* [BFS](<Leetcode 题解 - 搜索.md#bfs>)
|
||||
* [1. 计算在网格中从原点到特定点的最短路径长度](<Leetcode 题解 - 搜索.md#1-计算在网格中从原点到特定点的最短路径长度>)
|
||||
* [2. 组成整数的最小平方数数量](<Leetcode 题解 - 搜索.md#2-组成整数的最小平方数数量>)
|
||||
* [3. 最短单词路径](<Leetcode 题解 - 搜索.md#3-最短单词路径>)
|
||||
* [DFS](<Leetcode 题解 - 搜索.md#dfs>)
|
||||
* [1. 查找最大的连通面积](<Leetcode 题解 - 搜索.md#1-查找最大的连通面积>)
|
||||
* [2. 矩阵中的连通分量数目](<Leetcode 题解 - 搜索.md#2-矩阵中的连通分量数目>)
|
||||
* [3. 好友关系的连通分量数目](<Leetcode 题解 - 搜索.md#3-好友关系的连通分量数目>)
|
||||
* [4. 填充封闭区域](<Leetcode 题解 - 搜索.md#4-填充封闭区域>)
|
||||
* [5. 能到达的太平洋和大西洋的区域](<Leetcode 题解 - 搜索.md#5-能到达的太平洋和大西洋的区域>)
|
||||
* [Backtracking](<Leetcode 题解 - 搜索.md#backtracking>)
|
||||
* [1. 数字键盘组合](<Leetcode 题解 - 搜索.md#1-数字键盘组合>)
|
||||
* [2. IP 地址划分](<Leetcode 题解 - 搜索.md#2-ip-地址划分>)
|
||||
* [3. 在矩阵中寻找字符串](<Leetcode 题解 - 搜索.md#3-在矩阵中寻找字符串>)
|
||||
* [4. 输出二叉树中所有从根到叶子的路径](<Leetcode 题解 - 搜索.md#4-输出二叉树中所有从根到叶子的路径>)
|
||||
* [5. 排列](<Leetcode 题解 - 搜索.md#5-排列>)
|
||||
* [6. 含有相同元素求排列](<Leetcode 题解 - 搜索.md#6-含有相同元素求排列>)
|
||||
* [7. 组合](<Leetcode 题解 - 搜索.md#7-组合>)
|
||||
* [8. 组合求和](<Leetcode 题解 - 搜索.md#8-组合求和>)
|
||||
* [9. 含有相同元素的组合求和](<Leetcode 题解 - 搜索.md#9-含有相同元素的组合求和>)
|
||||
* [10. 1-9 数字的组合求和](<Leetcode 题解 - 搜索.md#10-1-9-数字的组合求和>)
|
||||
* [11. 子集](<Leetcode 题解 - 搜索.md#11-子集>)
|
||||
* [12. 含有相同元素求子集](<Leetcode 题解 - 搜索.md#12-含有相同元素求子集>)
|
||||
* [13. 分割字符串使得每个部分都是回文数](<Leetcode 题解 - 搜索.md#13-分割字符串使得每个部分都是回文数>)
|
||||
* [14. 数独](<Leetcode 题解 - 搜索.md#14-数独>)
|
||||
* [15. N 皇后](<Leetcode 题解 - 搜索.md#15-n-皇后>)
|
||||
|
||||
深度优先搜索和广度优先搜索广泛运用于树和图中,但是它们的应用远远不止如此。
|
||||
|
||||
## BFS
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/95903878-725b-4ed9-bded-bc4aae0792a9.jpg"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
广度优先搜索一层一层地进行遍历,每层遍历都是以上一层遍历的结果作为起点,遍历一个距离能访问到的所有节点。需要注意的是,遍历过的节点不能再次被遍历。
|
||||
|
||||
第一层:
|
||||
|
||||
- 0 -\> {6,2,1,5}
|
||||
* 0 -> {6,2,1,5}
|
||||
|
||||
第二层:
|
||||
|
||||
- 6 -\> {4}
|
||||
- 2 -\> {}
|
||||
- 1 -\> {}
|
||||
- 5 -\> {3}
|
||||
* 6 -> {4}
|
||||
* 2 -> {}
|
||||
* 1 -> {}
|
||||
* 5 -> {3}
|
||||
|
||||
第三层:
|
||||
|
||||
- 4 -\> {}
|
||||
- 3 -\> {}
|
||||
* 4 -> {}
|
||||
* 3 -> {}
|
||||
|
||||
每一层遍历的节点都与根节点距离相同。设 d<sub>i</sub> 表示第 i 个节点与根节点的距离,推导出一个结论:对于先遍历的节点 i 与后遍历的节点 j,有 d<sub>i</sub> <= d<sub>j</sub>。利用这个结论,可以求解最短路径等 **最优解** 问题:第一次遍历到目的节点,其所经过的路径为最短路径。应该注意的是,使用 BFS 只能求解无权图的最短路径,无权图是指从一个节点到另一个节点的代价都记为 1。
|
||||
每一层遍历的节点都与根节点距离相同。设 di 表示第 i 个节点与根节点的距离,推导出一个结论:对于先遍历的节点 i 与后遍历的节点 j,有 di <= dj。利用这个结论,可以求解最短路径等 **最优解** 问题:第一次遍历到目的节点,其所经过的路径为最短路径。应该注意的是,使用 BFS 只能求解无权图的最短路径,无权图是指从一个节点到另一个节点的代价都记为 1。
|
||||
|
||||
在程序实现 BFS 时需要考虑以下问题:
|
||||
|
||||
- 队列:用来存储每一轮遍历得到的节点;
|
||||
- 标记:对于遍历过的节点,应该将它标记,防止重复遍历。
|
||||
* 队列:用来存储每一轮遍历得到的节点;
|
||||
* 标记:对于遍历过的节点,应该将它标记,防止重复遍历。
|
||||
|
||||
### 1. 计算在网格中从原点到特定点的最短路径长度
|
||||
|
||||
@ -277,18 +276,19 @@ private int getShortestPath(List<Integer>[] graphic, int start, int end) {
|
||||
|
||||
## DFS
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/74dc31eb-6baa-47ea-ab1c-d27a0ca35093.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
广度优先搜索一层一层遍历,每一层得到的所有新节点,要用队列存储起来以备下一层遍历的时候再遍历。
|
||||
|
||||
而深度优先搜索在得到一个新节点时立即对新节点进行遍历:从节点 0 出发开始遍历,得到到新节点 6 时,立马对新节点 6 进行遍历,得到新节点 4;如此反复以这种方式遍历新节点,直到没有新节点了,此时返回。返回到根节点 0 的情况是,继续对根节点 0 进行遍历,得到新节点 2,然后继续以上步骤。
|
||||
|
||||
从一个节点出发,使用 DFS 对一个图进行遍历时,能够遍历到的节点都是从初始节点可达的,DFS 常用来求解这种 **可达性** 问题。
|
||||
从一个节点出发,使用 DFS 对一个图进行遍历时,能够遍历到的节点都是从初始节点可达的,DFS 常用来求解这种 **可达性** 问题。
|
||||
|
||||
在程序实现 DFS 时需要考虑以下问题:
|
||||
|
||||
- 栈:用栈来保存当前节点信息,当遍历新节点返回时能够继续遍历当前节点。可以使用递归栈。
|
||||
- 标记:和 BFS 一样同样需要对已经遍历过的节点进行标记。
|
||||
* 栈:用栈来保存当前节点信息,当遍历新节点返回时能够继续遍历当前节点。可以使用递归栈。
|
||||
* 标记:和 BFS 一样同样需要对已经遍历过的节点进行标记。
|
||||
|
||||
### 1. 查找最大的连通面积
|
||||
|
||||
@ -408,7 +408,7 @@ Explanation:The 0th and 1st students are direct friends, so they are in a friend
|
||||
The 2nd student himself is in a friend circle. So return 2.
|
||||
```
|
||||
|
||||
题目描述:好友关系可以看成是一个无向图,例如第 0 个人与第 1 个人是好友,那么 M[0][1] 和 M[1][0] 的值都为 1。
|
||||
题目描述:好友关系可以看成是一个无向图,例如第 0 个人与第 1 个人是好友,那么 M\[0]\[1] 和 M\[1]\[0] 的值都为 1。
|
||||
|
||||
```java
|
||||
private int n;
|
||||
@ -585,13 +585,13 @@ private void dfs(int r, int c, boolean[][] canReach) {
|
||||
|
||||
Backtracking(回溯)属于 DFS。
|
||||
|
||||
- 普通 DFS 主要用在 **可达性问题** ,这种问题只需要执行到特点的位置然后返回即可。
|
||||
- 而 Backtracking 主要用于求解 **排列组合** 问题,例如有 { 'a','b','c' } 三个字符,求解所有由这三个字符排列得到的字符串,这种问题在执行到特定的位置返回之后还会继续执行求解过程。
|
||||
* 普通 DFS 主要用在 **可达性问题** ,这种问题只需要执行到特点的位置然后返回即可。
|
||||
* 而 Backtracking 主要用于求解 **排列组合** 问题,例如有 { 'a','b','c' } 三个字符,求解所有由这三个字符排列得到的字符串,这种问题在执行到特定的位置返回之后还会继续执行求解过程。
|
||||
|
||||
因为 Backtracking 不是立即返回,而要继续求解,因此在程序实现时,需要注意对元素的标记问题:
|
||||
|
||||
- 在访问一个新元素进入新的递归调用时,需要将新元素标记为已经访问,这样才能在继续递归调用时不用重复访问该元素;
|
||||
- 但是在递归返回时,需要将元素标记为未访问,因为只需要保证在一个递归链中不同时访问一个元素,可以访问已经访问过但是不在当前递归链中的元素。
|
||||
* 在访问一个新元素进入新的递归调用时,需要将新元素标记为已经访问,这样才能在继续递归调用时不用重复访问该元素;
|
||||
* 但是在递归返回时,需要将元素标记为未访问,因为只需要保证在一个递归链中不同时访问一个元素,可以访问已经访问过但是不在当前递归链中的元素。
|
||||
|
||||
### 1. 数字键盘组合
|
||||
|
||||
@ -599,7 +599,8 @@ Backtracking(回溯)属于 DFS。
|
||||
|
||||
[Leetcode](https://leetcode.com/problems/letter-combinations-of-a-phone-number/description/) / [力扣](https://leetcode-cn.com/problems/letter-combinations-of-a-phone-number/description/)
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/9823768c-212b-4b1a-b69a-b3f59e07b977.jpg"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```html
|
||||
Input:Digit string "23"
|
||||
@ -766,7 +767,6 @@ private boolean backtracking(int curLen, int r, int c, boolean[][] visited, fina
|
||||
```
|
||||
|
||||
```java
|
||||
|
||||
public List<String> binaryTreePaths(TreeNode root) {
|
||||
List<String> paths = new ArrayList<>();
|
||||
if (root == null) {
|
||||
@ -1069,7 +1069,7 @@ private void backtracking(int k, int n, int start,
|
||||
|
||||
[Leetcode](https://leetcode.com/problems/subsets/description/) / [力扣](https://leetcode-cn.com/problems/subsets/description/)
|
||||
|
||||
找出集合的所有子集,子集不能重复,[1, 2] 和 [2, 1] 这种子集算重复
|
||||
找出集合的所有子集,子集不能重复,\[1, 2] 和 \[2, 1] 这种子集算重复
|
||||
|
||||
```java
|
||||
public List<List<Integer>> subsets(int[] nums) {
|
||||
@ -1202,7 +1202,8 @@ private boolean isPalindrome(String s, int begin, int end) {
|
||||
|
||||
[Leetcode](https://leetcode.com/problems/sudoku-solver/description/) / [力扣](https://leetcode-cn.com/problems/sudoku-solver/description/)
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/0e8fdc96-83c1-4798-9abe-45fc91d70b9d.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```java
|
||||
private boolean[][] rowsUsed = new boolean[9][10];
|
||||
@ -1261,7 +1262,8 @@ private int cubeNum(int i, int j) {
|
||||
|
||||
[Leetcode](https://leetcode.com/problems/n-queens/description/) / [力扣](https://leetcode-cn.com/problems/n-queens/description/)
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/067b310c-6877-40fe-9dcf-10654e737485.jpg"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
在 n\*n 的矩阵中摆放 n 个皇后,并且每个皇后不能在同一行,同一列,同一对角线上,求所有的 n 皇后的解。
|
||||
|
||||
@ -1269,12 +1271,13 @@ private int cubeNum(int i, int j) {
|
||||
|
||||
45 度对角线标记数组的长度为 2 \* n - 1,通过下图可以明确 (r, c) 的位置所在的数组下标为 r + c。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/9c422923-1447-4a3b-a4e1-97e663738187.jpg" width="300px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
135 度对角线标记数组的长度也是 2 \* n - 1,(r, c) 的位置所在的数组下标为 n - 1 - (r - c)。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/7a85e285-e152-4116-b6dc-3fab27ba9437.jpg" width="300px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```java
|
||||
private List<List<String>> solutions;
|
||||
|
||||
@ -1,44 +1,42 @@
|
||||
# Leetcode 题解 - 树
|
||||
<!-- GFM-TOC -->
|
||||
* [Leetcode 题解 - 树](#leetcode-题解---树)
|
||||
* [递归](#递归)
|
||||
* [1. 树的高度](#1-树的高度)
|
||||
* [2. 平衡树](#2-平衡树)
|
||||
* [3. 两节点的最长路径](#3-两节点的最长路径)
|
||||
* [4. 翻转树](#4-翻转树)
|
||||
* [5. 归并两棵树](#5-归并两棵树)
|
||||
* [6. 判断路径和是否等于一个数](#6-判断路径和是否等于一个数)
|
||||
* [7. 统计路径和等于一个数的路径数量](#7-统计路径和等于一个数的路径数量)
|
||||
* [8. 子树](#8-子树)
|
||||
* [9. 树的对称](#9-树的对称)
|
||||
* [10. 最小路径](#10-最小路径)
|
||||
* [11. 统计左叶子节点的和](#11-统计左叶子节点的和)
|
||||
* [12. 相同节点值的最大路径长度](#12-相同节点值的最大路径长度)
|
||||
* [13. 间隔遍历](#13-间隔遍历)
|
||||
* [14. 找出二叉树中第二小的节点](#14-找出二叉树中第二小的节点)
|
||||
* [层次遍历](#层次遍历)
|
||||
* [1. 一棵树每层节点的平均数](#1-一棵树每层节点的平均数)
|
||||
* [2. 得到左下角的节点](#2-得到左下角的节点)
|
||||
* [前中后序遍历](#前中后序遍历)
|
||||
* [1. 非递归实现二叉树的前序遍历](#1-非递归实现二叉树的前序遍历)
|
||||
* [2. 非递归实现二叉树的后序遍历](#2-非递归实现二叉树的后序遍历)
|
||||
* [3. 非递归实现二叉树的中序遍历](#3-非递归实现二叉树的中序遍历)
|
||||
* [BST](#bst)
|
||||
* [1. 修剪二叉查找树](#1-修剪二叉查找树)
|
||||
* [2. 寻找二叉查找树的第 k 个元素](#2-寻找二叉查找树的第-k-个元素)
|
||||
* [3. 把二叉查找树每个节点的值都加上比它大的节点的值](#3-把二叉查找树每个节点的值都加上比它大的节点的值)
|
||||
* [4. 二叉查找树的最近公共祖先](#4-二叉查找树的最近公共祖先)
|
||||
* [5. 二叉树的最近公共祖先](#5-二叉树的最近公共祖先)
|
||||
* [6. 从有序数组中构造二叉查找树](#6-从有序数组中构造二叉查找树)
|
||||
* [7. 根据有序链表构造平衡的二叉查找树](#7-根据有序链表构造平衡的二叉查找树)
|
||||
* [8. 在二叉查找树中寻找两个节点,使它们的和为一个给定值](#8-在二叉查找树中寻找两个节点,使它们的和为一个给定值)
|
||||
* [9. 在二叉查找树中查找两个节点之差的最小绝对值](#9-在二叉查找树中查找两个节点之差的最小绝对值)
|
||||
* [10. 寻找二叉查找树中出现次数最多的值](#10-寻找二叉查找树中出现次数最多的值)
|
||||
* [Trie](#trie)
|
||||
* [1. 实现一个 Trie](#1-实现一个-trie)
|
||||
* [2. 实现一个 Trie,用来求前缀和](#2-实现一个-trie,用来求前缀和)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [Leetcode 题解 - 树](<Leetcode 题解 - 树.md#leetcode-题解---树>)
|
||||
* [递归](<Leetcode 题解 - 树.md#递归>)
|
||||
* [1. 树的高度](<Leetcode 题解 - 树.md#1-树的高度>)
|
||||
* [2. 平衡树](<Leetcode 题解 - 树.md#2-平衡树>)
|
||||
* [3. 两节点的最长路径](<Leetcode 题解 - 树.md#3-两节点的最长路径>)
|
||||
* [4. 翻转树](<Leetcode 题解 - 树.md#4-翻转树>)
|
||||
* [5. 归并两棵树](<Leetcode 题解 - 树.md#5-归并两棵树>)
|
||||
* [6. 判断路径和是否等于一个数](<Leetcode 题解 - 树.md#6-判断路径和是否等于一个数>)
|
||||
* [7. 统计路径和等于一个数的路径数量](<Leetcode 题解 - 树.md#7-统计路径和等于一个数的路径数量>)
|
||||
* [8. 子树](<Leetcode 题解 - 树.md#8-子树>)
|
||||
* [9. 树的对称](<Leetcode 题解 - 树.md#9-树的对称>)
|
||||
* [10. 最小路径](<Leetcode 题解 - 树.md#10-最小路径>)
|
||||
* [11. 统计左叶子节点的和](<Leetcode 题解 - 树.md#11-统计左叶子节点的和>)
|
||||
* [12. 相同节点值的最大路径长度](<Leetcode 题解 - 树.md#12-相同节点值的最大路径长度>)
|
||||
* [13. 间隔遍历](<Leetcode 题解 - 树.md#13-间隔遍历>)
|
||||
* [14. 找出二叉树中第二小的节点](<Leetcode 题解 - 树.md#14-找出二叉树中第二小的节点>)
|
||||
* [层次遍历](<Leetcode 题解 - 树.md#层次遍历>)
|
||||
* [1. 一棵树每层节点的平均数](<Leetcode 题解 - 树.md#1-一棵树每层节点的平均数>)
|
||||
* [2. 得到左下角的节点](<Leetcode 题解 - 树.md#2-得到左下角的节点>)
|
||||
* [前中后序遍历](<Leetcode 题解 - 树.md#前中后序遍历>)
|
||||
* [1. 非递归实现二叉树的前序遍历](<Leetcode 题解 - 树.md#1-非递归实现二叉树的前序遍历>)
|
||||
* [2. 非递归实现二叉树的后序遍历](<Leetcode 题解 - 树.md#2-非递归实现二叉树的后序遍历>)
|
||||
* [3. 非递归实现二叉树的中序遍历](<Leetcode 题解 - 树.md#3-非递归实现二叉树的中序遍历>)
|
||||
* [BST](<Leetcode 题解 - 树.md#bst>)
|
||||
* [1. 修剪二叉查找树](<Leetcode 题解 - 树.md#1-修剪二叉查找树>)
|
||||
* [2. 寻找二叉查找树的第 k 个元素](<Leetcode 题解 - 树.md#2-寻找二叉查找树的第-k-个元素>)
|
||||
* [3. 把二叉查找树每个节点的值都加上比它大的节点的值](<Leetcode 题解 - 树.md#3-把二叉查找树每个节点的值都加上比它大的节点的值>)
|
||||
* [4. 二叉查找树的最近公共祖先](<Leetcode 题解 - 树.md#4-二叉查找树的最近公共祖先>)
|
||||
* [5. 二叉树的最近公共祖先](<Leetcode 题解 - 树.md#5-二叉树的最近公共祖先>)
|
||||
* [6. 从有序数组中构造二叉查找树](<Leetcode 题解 - 树.md#6-从有序数组中构造二叉查找树>)
|
||||
* [7. 根据有序链表构造平衡的二叉查找树](<Leetcode 题解 - 树.md#7-根据有序链表构造平衡的二叉查找树>)
|
||||
* [8. 在二叉查找树中寻找两个节点,使它们的和为一个给定值](<Leetcode 题解 - 树.md#8-在二叉查找树中寻找两个节点,使它们的和为一个给定值>)
|
||||
* [9. 在二叉查找树中查找两个节点之差的最小绝对值](<Leetcode 题解 - 树.md#9-在二叉查找树中查找两个节点之差的最小绝对值>)
|
||||
* [10. 寻找二叉查找树中出现次数最多的值](<Leetcode 题解 - 树.md#10-寻找二叉查找树中出现次数最多的值>)
|
||||
* [Trie](<Leetcode 题解 - 树.md#trie>)
|
||||
* [1. 实现一个 Trie](<Leetcode 题解 - 树.md#1-实现一个-trie>)
|
||||
* [2. 实现一个 Trie,用来求前缀和](<Leetcode 题解 - 树.md#2-实现一个-trie,用来求前缀和>)
|
||||
|
||||
## 递归
|
||||
|
||||
@ -550,10 +548,10 @@ public int findBottomLeftValue(TreeNode root) {
|
||||
4 5 6
|
||||
```
|
||||
|
||||
- 层次遍历顺序:[1 2 3 4 5 6]
|
||||
- 前序遍历顺序:[1 2 4 5 3 6]
|
||||
- 中序遍历顺序:[4 2 5 1 3 6]
|
||||
- 后序遍历顺序:[4 5 2 6 3 1]
|
||||
* 层次遍历顺序:\[1 2 3 4 5 6]
|
||||
* 前序遍历顺序:\[1 2 4 5 3 6]
|
||||
* 中序遍历顺序:\[4 2 5 1 3 6]
|
||||
* 后序遍历顺序:\[4 5 2 6 3 1]
|
||||
|
||||
层次遍历使用 BFS 实现,利用的就是 BFS 一层一层遍历的特性;而前序、中序、后序遍历利用了 DFS 实现。
|
||||
|
||||
@ -617,7 +615,7 @@ public List<Integer> preorderTraversal(TreeNode root) {
|
||||
|
||||
[Leetcode](https://leetcode.com/problems/binary-tree-postorder-traversal/description/) / [力扣](https://leetcode-cn.com/problems/binary-tree-postorder-traversal/description/)
|
||||
|
||||
前序遍历为 root -\> left -\> right,后序遍历为 left -\> right -\> root。可以修改前序遍历成为 root -\> right -\> left,那么这个顺序就和后序遍历正好相反。
|
||||
前序遍历为 root -> left -> right,后序遍历为 left -> right -> root。可以修改前序遍历成为 root -> right -> left,那么这个顺序就和后序遍历正好相反。
|
||||
|
||||
```java
|
||||
public List<Integer> postorderTraversal(TreeNode root) {
|
||||
@ -715,7 +713,6 @@ public TreeNode trimBST(TreeNode root, int L, int R) {
|
||||
|
||||
[Leetcode](https://leetcode.com/problems/kth-smallest-element-in-a-bst/description/) / [力扣](https://leetcode-cn.com/problems/kth-smallest-element-in-a-bst/description/)
|
||||
|
||||
|
||||
中序遍历解法:
|
||||
|
||||
```java
|
||||
@ -822,7 +819,7 @@ public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
|
||||
|
||||
### 5. 二叉树的最近公共祖先
|
||||
|
||||
236\. Lowest Common Ancestor of a Binary Tree (Medium)
|
||||
236\. Lowest Common Ancestor of a Binary Tree (Medium)
|
||||
|
||||
[Leetcode](https://leetcode.com/problems/lowest-common-ancestor-of-a-binary-tree/description/) / [力扣](https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-tree/description/)
|
||||
|
||||
@ -1052,7 +1049,8 @@ private void inOrder(TreeNode node, List<Integer> nums) {
|
||||
|
||||
## Trie
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/5c638d59-d4ae-4ba4-ad44-80bdc30f38dd.jpg"/> </div><br>
|
||||
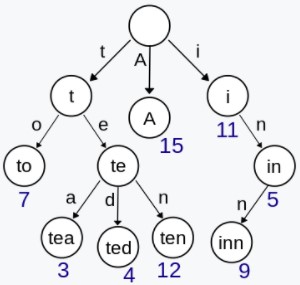\
|
||||
|
||||
|
||||
Trie,又称前缀树或字典树,用于判断字符串是否存在或者是否具有某种字符串前缀。
|
||||
|
||||
@ -1186,4 +1184,3 @@ class MapSum {
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
@ -1,19 +1,17 @@
|
||||
# Leetcode 题解 - 贪心思想
|
||||
<!-- GFM-TOC -->
|
||||
* [Leetcode 题解 - 贪心思想](#leetcode-题解---贪心思想)
|
||||
* [1. 分配饼干](#1-分配饼干)
|
||||
* [2. 不重叠的区间个数](#2-不重叠的区间个数)
|
||||
* [3. 投飞镖刺破气球](#3-投飞镖刺破气球)
|
||||
* [4. 根据身高和序号重组队列](#4-根据身高和序号重组队列)
|
||||
* [5. 买卖股票最大的收益](#5-买卖股票最大的收益)
|
||||
* [6. 买卖股票的最大收益 II](#6-买卖股票的最大收益-ii)
|
||||
* [7. 种植花朵](#7-种植花朵)
|
||||
* [8. 判断是否为子序列](#8-判断是否为子序列)
|
||||
* [9. 修改一个数成为非递减数组](#9-修改一个数成为非递减数组)
|
||||
* [10. 子数组最大的和](#10-子数组最大的和)
|
||||
* [11. 分隔字符串使同种字符出现在一起](#11-分隔字符串使同种字符出现在一起)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [Leetcode 题解 - 贪心思想](<Leetcode 题解 - 贪心思想.md#leetcode-题解---贪心思想>)
|
||||
* [1. 分配饼干](<Leetcode 题解 - 贪心思想.md#1-分配饼干>)
|
||||
* [2. 不重叠的区间个数](<Leetcode 题解 - 贪心思想.md#2-不重叠的区间个数>)
|
||||
* [3. 投飞镖刺破气球](<Leetcode 题解 - 贪心思想.md#3-投飞镖刺破气球>)
|
||||
* [4. 根据身高和序号重组队列](<Leetcode 题解 - 贪心思想.md#4-根据身高和序号重组队列>)
|
||||
* [5. 买卖股票最大的收益](<Leetcode 题解 - 贪心思想.md#5-买卖股票最大的收益>)
|
||||
* [6. 买卖股票的最大收益 II](<Leetcode 题解 - 贪心思想.md#6-买卖股票的最大收益-ii>)
|
||||
* [7. 种植花朵](<Leetcode 题解 - 贪心思想.md#7-种植花朵>)
|
||||
* [8. 判断是否为子序列](<Leetcode 题解 - 贪心思想.md#8-判断是否为子序列>)
|
||||
* [9. 修改一个数成为非递减数组](<Leetcode 题解 - 贪心思想.md#9-修改一个数成为非递减数组>)
|
||||
* [10. 子数组最大的和](<Leetcode 题解 - 贪心思想.md#10-子数组最大的和>)
|
||||
* [11. 分隔字符串使同种字符出现在一起](<Leetcode 题解 - 贪心思想.md#11-分隔字符串使同种字符出现在一起>)
|
||||
|
||||
保证每次操作都是局部最优的,并且最后得到的结果是全局最优的。
|
||||
|
||||
@ -35,9 +33,10 @@ Output: 2
|
||||
|
||||
在以上的解法中,我们只在每次分配时饼干时选择一种看起来是当前最优的分配方法,但无法保证这种局部最优的分配方法最后能得到全局最优解。我们假设能得到全局最优解,并使用反证法进行证明,即假设存在一种比我们使用的贪心策略更优的最优策略。如果不存在这种最优策略,表示贪心策略就是最优策略,得到的解也就是全局最优解。
|
||||
|
||||
证明:假设在某次选择中,贪心策略选择给当前满足度最小的孩子分配第 m 个饼干,第 m 个饼干为可以满足该孩子的最小饼干。假设存在一种最优策略,可以给该孩子分配第 n 个饼干,并且 m \< n。我们可以发现,经过这一轮分配,贪心策略分配后剩下的饼干一定有一个比最优策略来得大。因此在后续的分配中,贪心策略一定能满足更多的孩子。也就是说不存在比贪心策略更优的策略,即贪心策略就是最优策略。
|
||||
证明:假设在某次选择中,贪心策略选择给当前满足度最小的孩子分配第 m 个饼干,第 m 个饼干为可以满足该孩子的最小饼干。假设存在一种最优策略,可以给该孩子分配第 n 个饼干,并且 m < n。我们可以发现,经过这一轮分配,贪心策略分配后剩下的饼干一定有一个比最优策略来得大。因此在后续的分配中,贪心策略一定能满足更多的孩子。也就是说不存在比贪心策略更优的策略,即贪心策略就是最优策略。
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/e69537d2-a016-4676-b169-9ea17eeb9037.gif" width="430px"> </div><br>
|
||||
|
||||
```java
|
||||
public int findContentChildren(int[] grid, int[] size) {
|
||||
@ -133,7 +132,7 @@ Output:
|
||||
|
||||
题目描述:气球在一个水平数轴上摆放,可以重叠,飞镖垂直投向坐标轴,使得路径上的气球都被刺破。求解最小的投飞镖次数使所有气球都被刺破。
|
||||
|
||||
也是计算不重叠的区间个数,不过和 Non-overlapping Intervals 的区别在于,[1, 2] 和 [2, 3] 在本题中算是重叠区间。
|
||||
也是计算不重叠的区间个数,不过和 Non-overlapping Intervals 的区别在于,\[1, 2] 和 \[2, 3] 在本题中算是重叠区间。
|
||||
|
||||
```java
|
||||
public int findMinArrowShots(int[][] points) {
|
||||
@ -211,7 +210,6 @@ public int maxProfit(int[] prices) {
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
## 6. 买卖股票的最大收益 II
|
||||
|
||||
122\. Best Time to Buy and Sell Stock II (Easy)
|
||||
@ -220,7 +218,7 @@ public int maxProfit(int[] prices) {
|
||||
|
||||
题目描述:可以进行多次交易,多次交易之间不能交叉进行,可以进行多次交易。
|
||||
|
||||
对于 [a, b, c, d],如果有 a \<= b \<= c \<= d ,那么最大收益为 d - a。而 d - a = (d - c) + (c - b) + (b - a) ,因此当访问到一个 prices[i] 且 prices[i] - prices[i-1] \> 0,那么就把 prices[i] - prices[i-1] 添加到收益中。
|
||||
对于 \[a, b, c, d],如果有 a <= b <= c <= d ,那么最大收益为 d - a。而 d - a = (d - c) + (c - b) + (b - a) ,因此当访问到一个 prices\[i] 且 prices\[i] - prices\[i-1] > 0,那么就把 prices\[i] - prices\[i-1] 添加到收益中。
|
||||
|
||||
```java
|
||||
public int maxProfit(int[] prices) {
|
||||
@ -234,7 +232,6 @@ public int maxProfit(int[] prices) {
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
## 7. 种植花朵
|
||||
|
||||
605\. Can Place Flowers (Easy)
|
||||
@ -305,7 +302,7 @@ Explanation: You could modify the first 4 to 1 to get a non-decreasing array.
|
||||
|
||||
题目描述:判断一个数组是否能只修改一个数就成为非递减数组。
|
||||
|
||||
在出现 nums[i] \< nums[i - 1] 时,需要考虑的是应该修改数组的哪个数,使得本次修改能使 i 之前的数组成为非递减数组,并且 **不影响后续的操作** 。优先考虑令 nums[i - 1] = nums[i],因为如果修改 nums[i] = nums[i - 1] 的话,那么 nums[i] 这个数会变大,就有可能比 nums[i + 1] 大,从而影响了后续操作。还有一个比较特别的情况就是 nums[i] \< nums[i - 2],修改 nums[i - 1] = nums[i] 不能使数组成为非递减数组,只能修改 nums[i] = nums[i - 1]。
|
||||
在出现 nums\[i] < nums\[i - 1] 时,需要考虑的是应该修改数组的哪个数,使得本次修改能使 i 之前的数组成为非递减数组,并且 **不影响后续的操作** 。优先考虑令 nums\[i - 1] = nums\[i],因为如果修改 nums\[i] = nums\[i - 1] 的话,那么 nums\[i] 这个数会变大,就有可能比 nums\[i + 1] 大,从而影响了后续操作。还有一个比较特别的情况就是 nums\[i] < nums\[i - 2],修改 nums\[i - 1] = nums\[i] 不能使数组成为非递减数组,只能修改 nums\[i] = nums\[i - 1]。
|
||||
|
||||
```java
|
||||
public boolean checkPossibility(int[] nums) {
|
||||
@ -325,8 +322,6 @@ public boolean checkPossibility(int[] nums) {
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 10. 子数组最大的和
|
||||
|
||||
53\. Maximum Subarray (Easy)
|
||||
|
||||
514
notes/Linux.md
514
notes/Linux.md
@ -1,91 +1,89 @@
|
||||
# Linux
|
||||
<!-- GFM-TOC -->
|
||||
* [Linux](#linux)
|
||||
* [前言](#前言)
|
||||
* [一、常用操作以及概念](#一常用操作以及概念)
|
||||
* [快捷键](#快捷键)
|
||||
* [求助](#求助)
|
||||
* [关机](#关机)
|
||||
* [PATH](#path)
|
||||
* [sudo](#sudo)
|
||||
* [包管理工具](#包管理工具)
|
||||
* [发行版](#发行版)
|
||||
* [VIM 三个模式](#vim-三个模式)
|
||||
* [GNU](#gnu)
|
||||
* [开源协议](#开源协议)
|
||||
* [二、磁盘](#二磁盘)
|
||||
* [磁盘接口](#磁盘接口)
|
||||
* [磁盘的文件名](#磁盘的文件名)
|
||||
* [三、分区](#三分区)
|
||||
* [分区表](#分区表)
|
||||
* [开机检测程序](#开机检测程序)
|
||||
* [四、文件系统](#四文件系统)
|
||||
* [分区与文件系统](#分区与文件系统)
|
||||
* [组成](#组成)
|
||||
* [文件读取](#文件读取)
|
||||
* [磁盘碎片](#磁盘碎片)
|
||||
* [block](#block)
|
||||
* [inode](#inode)
|
||||
* [目录](#目录)
|
||||
* [日志](#日志)
|
||||
* [挂载](#挂载)
|
||||
* [目录配置](#目录配置)
|
||||
* [五、文件](#五文件)
|
||||
* [文件属性](#文件属性)
|
||||
* [文件与目录的基本操作](#文件与目录的基本操作)
|
||||
* [修改权限](#修改权限)
|
||||
* [默认权限](#默认权限)
|
||||
* [目录的权限](#目录的权限)
|
||||
* [链接](#链接)
|
||||
* [获取文件内容](#获取文件内容)
|
||||
* [指令与文件搜索](#指令与文件搜索)
|
||||
* [六、压缩与打包](#六压缩与打包)
|
||||
* [压缩文件名](#压缩文件名)
|
||||
* [压缩指令](#压缩指令)
|
||||
* [打包](#打包)
|
||||
* [七、Bash](#七bash)
|
||||
* [特性](#特性)
|
||||
* [变量操作](#变量操作)
|
||||
* [指令搜索顺序](#指令搜索顺序)
|
||||
* [数据流重定向](#数据流重定向)
|
||||
* [八、管道指令](#八管道指令)
|
||||
* [提取指令](#提取指令)
|
||||
* [排序指令](#排序指令)
|
||||
* [双向输出重定向](#双向输出重定向)
|
||||
* [字符转换指令](#字符转换指令)
|
||||
* [分区指令](#分区指令)
|
||||
* [九、正则表达式](#九正则表达式)
|
||||
* [grep](#grep)
|
||||
* [printf](#printf)
|
||||
* [awk](#awk)
|
||||
* [十、进程管理](#十进程管理)
|
||||
* [查看进程](#查看进程)
|
||||
* [进程状态](#进程状态)
|
||||
* [SIGCHLD](#sigchld)
|
||||
* [wait()](#wait)
|
||||
* [waitpid()](#waitpid)
|
||||
* [孤儿进程](#孤儿进程)
|
||||
* [僵尸进程](#僵尸进程)
|
||||
* [参考资料](#参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [Linux](Linux.md#linux)
|
||||
* [前言](Linux.md#前言)
|
||||
* [一、常用操作以及概念](Linux.md#一常用操作以及概念)
|
||||
* [快捷键](Linux.md#快捷键)
|
||||
* [求助](Linux.md#求助)
|
||||
* [关机](Linux.md#关机)
|
||||
* [PATH](Linux.md#path)
|
||||
* [sudo](Linux.md#sudo)
|
||||
* [包管理工具](Linux.md#包管理工具)
|
||||
* [发行版](Linux.md#发行版)
|
||||
* [VIM 三个模式](Linux.md#vim-三个模式)
|
||||
* [GNU](Linux.md#gnu)
|
||||
* [开源协议](Linux.md#开源协议)
|
||||
* [二、磁盘](Linux.md#二磁盘)
|
||||
* [磁盘接口](Linux.md#磁盘接口)
|
||||
* [磁盘的文件名](Linux.md#磁盘的文件名)
|
||||
* [三、分区](Linux.md#三分区)
|
||||
* [分区表](Linux.md#分区表)
|
||||
* [开机检测程序](Linux.md#开机检测程序)
|
||||
* [四、文件系统](Linux.md#四文件系统)
|
||||
* [分区与文件系统](Linux.md#分区与文件系统)
|
||||
* [组成](Linux.md#组成)
|
||||
* [文件读取](Linux.md#文件读取)
|
||||
* [磁盘碎片](Linux.md#磁盘碎片)
|
||||
* [block](Linux.md#block)
|
||||
* [inode](Linux.md#inode)
|
||||
* [目录](Linux.md#目录)
|
||||
* [日志](Linux.md#日志)
|
||||
* [挂载](Linux.md#挂载)
|
||||
* [目录配置](Linux.md#目录配置)
|
||||
* [五、文件](Linux.md#五文件)
|
||||
* [文件属性](Linux.md#文件属性)
|
||||
* [文件与目录的基本操作](Linux.md#文件与目录的基本操作)
|
||||
* [修改权限](Linux.md#修改权限)
|
||||
* [默认权限](Linux.md#默认权限)
|
||||
* [目录的权限](Linux.md#目录的权限)
|
||||
* [链接](Linux.md#链接)
|
||||
* [获取文件内容](Linux.md#获取文件内容)
|
||||
* [指令与文件搜索](Linux.md#指令与文件搜索)
|
||||
* [六、压缩与打包](Linux.md#六压缩与打包)
|
||||
* [压缩文件名](Linux.md#压缩文件名)
|
||||
* [压缩指令](Linux.md#压缩指令)
|
||||
* [打包](Linux.md#打包)
|
||||
* [七、Bash](Linux.md#七bash)
|
||||
* [特性](Linux.md#特性)
|
||||
* [变量操作](Linux.md#变量操作)
|
||||
* [指令搜索顺序](Linux.md#指令搜索顺序)
|
||||
* [数据流重定向](Linux.md#数据流重定向)
|
||||
* [八、管道指令](Linux.md#八管道指令)
|
||||
* [提取指令](Linux.md#提取指令)
|
||||
* [排序指令](Linux.md#排序指令)
|
||||
* [双向输出重定向](Linux.md#双向输出重定向)
|
||||
* [字符转换指令](Linux.md#字符转换指令)
|
||||
* [分区指令](Linux.md#分区指令)
|
||||
* [九、正则表达式](Linux.md#九正则表达式)
|
||||
* [grep](Linux.md#grep)
|
||||
* [printf](Linux.md#printf)
|
||||
* [awk](Linux.md#awk)
|
||||
* [十、进程管理](Linux.md#十进程管理)
|
||||
* [查看进程](Linux.md#查看进程)
|
||||
* [进程状态](Linux.md#进程状态)
|
||||
* [SIGCHLD](Linux.md#sigchld)
|
||||
* [wait()](Linux.md#wait)
|
||||
* [waitpid()](Linux.md#waitpid)
|
||||
* [孤儿进程](Linux.md#孤儿进程)
|
||||
* [僵尸进程](Linux.md#僵尸进程)
|
||||
* [参考资料](Linux.md#参考资料)
|
||||
|
||||
## 前言
|
||||
|
||||
为了便于理解,本文从常用操作和概念开始讲起。虽然已经尽量做到简化,但是涉及到的内容还是有点多。在面试中,Linux 知识点相对于网络和操作系统等知识点而言不是那么重要,只需要重点掌握一些原理和命令即可。为了方便大家准备面试,在此先将一些比较重要的知识点列出来:
|
||||
|
||||
- 能简单使用 cat,grep,cut 等命令进行一些操作;
|
||||
- 文件系统相关的原理,inode 和 block 等概念,数据恢复;
|
||||
- 硬链接与软链接;
|
||||
- 进程管理相关,僵尸进程与孤儿进程,SIGCHLD 。
|
||||
* 能简单使用 cat,grep,cut 等命令进行一些操作;
|
||||
* 文件系统相关的原理,inode 和 block 等概念,数据恢复;
|
||||
* 硬链接与软链接;
|
||||
* 进程管理相关,僵尸进程与孤儿进程,SIGCHLD 。
|
||||
|
||||
## 一、常用操作以及概念
|
||||
|
||||
### 快捷键
|
||||
|
||||
- Tab:命令和文件名补全;
|
||||
- Ctrl+C:中断正在运行的程序;
|
||||
- Ctrl+D:结束键盘输入(End Of File,EOF)
|
||||
* Tab:命令和文件名补全;
|
||||
* Ctrl+C:中断正在运行的程序;
|
||||
* Ctrl+D:结束键盘输入(End Of File,EOF)
|
||||
|
||||
### 求助
|
||||
|
||||
@ -99,11 +97,11 @@ man 是 manual 的缩写,将指令的具体信息显示出来。
|
||||
|
||||
当执行 `man date` 时,有 DATE(1) 出现,其中的数字代表指令的类型,常用的数字及其类型如下:
|
||||
|
||||
| 代号 | 类型 |
|
||||
| :--: | -- |
|
||||
| 1 | 用户在 shell 环境中可以操作的指令或者可执行文件 |
|
||||
| 5 | 配置文件 |
|
||||
| 8 | 系统管理员可以使用的管理指令 |
|
||||
| 代号 | 类型 |
|
||||
| :-: | --------------------------- |
|
||||
| 1 | 用户在 shell 环境中可以操作的指令或者可执行文件 |
|
||||
| 5 | 配置文件 |
|
||||
| 8 | 系统管理员可以使用的管理指令 |
|
||||
|
||||
#### 3. info
|
||||
|
||||
@ -149,51 +147,50 @@ sudo 允许一般用户使用 root 可执行的命令,不过只有在 /etc/sud
|
||||
|
||||
RPM 和 DPKG 为最常见的两类软件包管理工具:
|
||||
|
||||
- RPM 全称为 Redhat Package Manager,最早由 Red Hat 公司制定实施,随后被 GNU 开源操作系统接受并成为许多 Linux 系统的既定软件标准。YUM 基于 RPM,具有依赖管理和软件升级功能。
|
||||
- 与 RPM 竞争的是基于 Debian 操作系统的 DEB 软件包管理工具 DPKG,全称为 Debian Package,功能方面与 RPM 相似。
|
||||
* RPM 全称为 Redhat Package Manager,最早由 Red Hat 公司制定实施,随后被 GNU 开源操作系统接受并成为许多 Linux 系统的既定软件标准。YUM 基于 RPM,具有依赖管理和软件升级功能。
|
||||
* 与 RPM 竞争的是基于 Debian 操作系统的 DEB 软件包管理工具 DPKG,全称为 Debian Package,功能方面与 RPM 相似。
|
||||
|
||||
### 发行版
|
||||
|
||||
Linux 发行版是 Linux 内核及各种应用软件的集成版本。
|
||||
|
||||
| 基于的包管理工具 | 商业发行版 | 社区发行版 |
|
||||
| :--: | :--: | :--: |
|
||||
| RPM | Red Hat | Fedora / CentOS |
|
||||
| DPKG | Ubuntu | Debian |
|
||||
| 基于的包管理工具 | 商业发行版 | 社区发行版 |
|
||||
| :------: | :-----: | :-------------: |
|
||||
| RPM | Red Hat | Fedora / CentOS |
|
||||
| DPKG | Ubuntu | Debian |
|
||||
|
||||
### VIM 三个模式
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191209002818626.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
|
||||
- 一般指令模式(Command mode):VIM 的默认模式,可以用于移动游标查看内容;
|
||||
- 编辑模式(Insert mode):按下 "i" 等按键之后进入,可以对文本进行编辑;
|
||||
- 指令列模式(Bottom-line mode):按下 ":" 按键之后进入,用于保存退出等操作。
|
||||
* 一般指令模式(Command mode):VIM 的默认模式,可以用于移动游标查看内容;
|
||||
* 编辑模式(Insert mode):按下 "i" 等按键之后进入,可以对文本进行编辑;
|
||||
* 指令列模式(Bottom-line mode):按下 ":" 按键之后进入,用于保存退出等操作。
|
||||
|
||||
在指令列模式下,有以下命令用于离开或者保存文件。
|
||||
|
||||
| 命令 | 作用 |
|
||||
| :--: | :--: |
|
||||
| :w | 写入磁盘|
|
||||
| :w! | 当文件为只读时,强制写入磁盘。到底能不能写入,与用户对该文件的权限有关 |
|
||||
| :q | 离开 |
|
||||
| :q! | 强制离开不保存 |
|
||||
| :wq | 写入磁盘后离开 |
|
||||
| :wq!| 强制写入磁盘后离开 |
|
||||
| 命令 | 作用 |
|
||||
| :--: | :---------------------------------: |
|
||||
| :w | 写入磁盘 |
|
||||
| :w! | 当文件为只读时,强制写入磁盘。到底能不能写入,与用户对该文件的权限有关 |
|
||||
| :q | 离开 |
|
||||
| :q! | 强制离开不保存 |
|
||||
| :wq | 写入磁盘后离开 |
|
||||
| :wq! | 强制写入磁盘后离开 |
|
||||
|
||||
### GNU
|
||||
|
||||
GNU 计划,译为革奴计划,它的目标是创建一套完全自由的操作系统,称为 GNU,其内容软件完全以 GPL 方式发布。其中 GPL 全称为 GNU 通用公共许可协议(GNU General Public License),包含了以下内容:
|
||||
|
||||
- 以任何目的运行此程序的自由;
|
||||
- 再复制的自由;
|
||||
- 改进此程序,并公开发布改进的自由。
|
||||
* 以任何目的运行此程序的自由;
|
||||
* 再复制的自由;
|
||||
* 改进此程序,并公开发布改进的自由。
|
||||
|
||||
### 开源协议
|
||||
|
||||
- [Choose an open source license](https://choosealicense.com/)
|
||||
- [如何选择开源许可证?](http://www.ruanyifeng.com/blog/2011/05/how_to_choose_free_software_licenses.html)
|
||||
* [Choose an open source license](https://choosealicense.com)
|
||||
* [如何选择开源许可证?](http://www.ruanyifeng.com/blog/2011/05/how\_to\_choose\_free\_software\_licenses.html)
|
||||
|
||||
## 二、磁盘
|
||||
|
||||
@ -203,32 +200,36 @@ GNU 计划,译为革奴计划,它的目标是创建一套完全自由的操
|
||||
|
||||
IDE(ATA)全称 Advanced Technology Attachment,接口速度最大为 133MB/s,因为并口线的抗干扰性太差,且排线占用空间较大,不利电脑内部散热,已逐渐被 SATA 所取代。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/924914c0-660c-4e4a-bbc0-1df1146e7516.jpg" width="400"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
#### 2. SATA
|
||||
|
||||
SATA 全称 Serial ATA,也就是使用串口的 ATA 接口,抗干扰性强,且对数据线的长度要求比 ATA 低很多,支持热插拔等功能。SATA-II 的接口速度为 300MB/s,而 SATA-III 标准可达到 600MB/s 的传输速度。SATA 的数据线也比 ATA 的细得多,有利于机箱内的空气流通,整理线材也比较方便。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/f9f2a16b-4843-44d1-9759-c745772e9bcf.jpg" width=""/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
#### 3. SCSI
|
||||
|
||||
SCSI 全称是 Small Computer System Interface(小型机系统接口),SCSI 硬盘广为工作站以及个人电脑以及服务器所使用,因此会使用较为先进的技术,如碟片转速 15000rpm 的高转速,且传输时 CPU 占用率较低,但是单价也比相同容量的 ATA 及 SATA 硬盘更加昂贵。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/f0574025-c514-49f5-a591-6d6a71f271f7.jpg" width=""/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
#### 4. SAS
|
||||
|
||||
SAS(Serial Attached SCSI)是新一代的 SCSI 技术,和 SATA 硬盘相同,都是采取序列式技术以获得更高的传输速度,可达到 6Gb/s。此外也通过缩小连接线改善系统内部空间等。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/6729baa0-57d7-4817-b3aa-518cbccf824c.jpg" width=""/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### 磁盘的文件名
|
||||
|
||||
Linux 中每个硬件都被当做一个文件,包括磁盘。磁盘以磁盘接口类型进行命名,常见磁盘的文件名如下:
|
||||
|
||||
- IDE 磁盘:/dev/hd[a-d]
|
||||
- SATA/SCSI/SAS 磁盘:/dev/sd[a-p]
|
||||
* IDE 磁盘:/dev/hd\[a-d]
|
||||
* SATA/SCSI/SAS 磁盘:/dev/sd\[a-p]
|
||||
|
||||
其中文件名后面的序号的确定与系统检测到磁盘的顺序有关,而与磁盘所插入的插槽位置无关。
|
||||
|
||||
@ -252,11 +253,12 @@ Linux 也把分区当成文件,分区文件的命名方式为:磁盘文件
|
||||
|
||||
GPT 第 1 个区块记录了主要开机记录(MBR),紧接着是 33 个区块记录分区信息,并把最后的 33 个区块用于对分区信息进行备份。这 33 个区块第一个为 GPT 表头纪录,这个部份纪录了分区表本身的位置与大小和备份分区的位置,同时放置了分区表的校验码 (CRC32),操作系统可以根据这个校验码来判断 GPT 是否正确。若有错误,可以使用备份分区进行恢复。
|
||||
|
||||
GPT 没有扩展分区概念,都是主分区,每个 LBA 可以分 4 个分区,因此总共可以分 4 * 32 = 128 个分区。
|
||||
GPT 没有扩展分区概念,都是主分区,每个 LBA 可以分 4 个分区,因此总共可以分 4 \* 32 = 128 个分区。
|
||||
|
||||
MBR 不支持 2.2 TB 以上的硬盘,GPT 则最多支持到 2<sup>33</sup> TB = 8 ZB。
|
||||
MBR 不支持 2.2 TB 以上的硬盘,GPT 则最多支持到 233 TB = 8 ZB。
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/GUID_Partition_Table_Scheme.svg.png" width="400"/> </div><br>
|
||||
|
||||
### 开机检测程序
|
||||
|
||||
@ -264,7 +266,8 @@ MBR 不支持 2.2 TB 以上的硬盘,GPT 则最多支持到 2<sup>33</sup> TB
|
||||
|
||||
BIOS(Basic Input/Output System,基本输入输出系统),它是一个固件(嵌入在硬件中的软件),BIOS 程序存放在断电后内容不会丢失的只读内存中。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/50831a6f-2777-46ea-a571-29f23c85cc21.jpg"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
BIOS 是开机的时候计算机执行的第一个程序,这个程序知道可以开机的磁盘,并读取磁盘第一个扇区的主要开机记录(MBR),由主要开机记录(MBR)执行其中的开机管理程序,这个开机管理程序会加载操作系统的核心文件。
|
||||
|
||||
@ -272,7 +275,8 @@ BIOS 是开机的时候计算机执行的第一个程序,这个程序知道可
|
||||
|
||||
下图中,第一扇区的主要开机记录(MBR)中的开机管理程序提供了两个选单:M1、M2,M1 指向了 Windows 操作系统,而 M2 指向其它分区的启动扇区,里面包含了另外一个开机管理程序,提供了一个指向 Linux 的选单。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/f900f266-a323-42b2-bc43-218fdb8811a8.jpg" width="600"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
安装多重引导,最好先安装 Windows 再安装 Linux。因为安装 Windows 时会覆盖掉主要开机记录(MBR),而 Linux 可以选择将开机管理程序安装在主要开机记录(MBR)或者其它分区的启动扇区,并且可以设置开机管理程序的选单。
|
||||
|
||||
@ -290,25 +294,28 @@ BIOS 不可以读取 GPT 分区表,而 UEFI 可以。
|
||||
|
||||
最主要的几个组成部分如下:
|
||||
|
||||
- inode:一个文件占用一个 inode,记录文件的属性,同时记录此文件的内容所在的 block 编号;
|
||||
- block:记录文件的内容,文件太大时,会占用多个 block。
|
||||
* inode:一个文件占用一个 inode,记录文件的属性,同时记录此文件的内容所在的 block 编号;
|
||||
* block:记录文件的内容,文件太大时,会占用多个 block。
|
||||
|
||||
除此之外还包括:
|
||||
|
||||
- superblock:记录文件系统的整体信息,包括 inode 和 block 的总量、使用量、剩余量,以及文件系统的格式与相关信息等;
|
||||
- block bitmap:记录 block 是否被使用的位图。
|
||||
* superblock:记录文件系统的整体信息,包括 inode 和 block 的总量、使用量、剩余量,以及文件系统的格式与相关信息等;
|
||||
* block bitmap:记录 block 是否被使用的位图。
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/BSD_disk.png" width="800"/> </div><br>
|
||||
|
||||
### 文件读取
|
||||
|
||||
对于 Ext2 文件系统,当要读取一个文件的内容时,先在 inode 中查找文件内容所在的所有 block,然后把所有 block 的内容读出来。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/12a65cc6-20e0-4706-9fe6-3ba49413d7f6.png" width="500px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
而对于 FAT 文件系统,它没有 inode,每个 block 中存储着下一个 block 的编号。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/5b718e86-7102-4bb6-8ca5-d1dd791530c5.png" width="500px"> </div><br>
|
||||
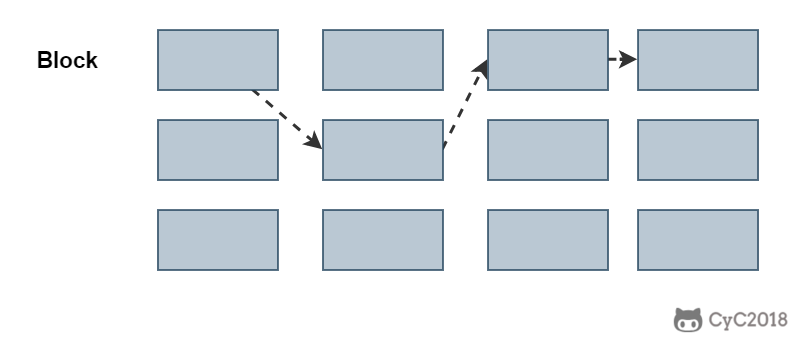\
|
||||
|
||||
|
||||
### 磁盘碎片
|
||||
|
||||
@ -318,10 +325,10 @@ BIOS 不可以读取 GPT 分区表,而 UEFI 可以。
|
||||
|
||||
在 Ext2 文件系统中所支持的 block 大小有 1K,2K 及 4K 三种,不同的大小限制了单个文件和文件系统的最大大小。
|
||||
|
||||
| 大小 | 1KB | 2KB | 4KB |
|
||||
| :---: | :---: | :---: | :---: |
|
||||
| 最大单一文件 | 16GB | 256GB | 2TB |
|
||||
| 最大文件系统 | 2TB | 8TB | 16TB |
|
||||
| 大小 | 1KB | 2KB | 4KB |
|
||||
| :----: | :--: | :---: | :--: |
|
||||
| 最大单一文件 | 16GB | 256GB | 2TB |
|
||||
| 最大文件系统 | 2TB | 8TB | 16TB |
|
||||
|
||||
一个 block 只能被一个文件所使用,未使用的部分直接浪费了。因此如果需要存储大量的小文件,那么最好选用比较小的 block。
|
||||
|
||||
@ -329,23 +336,24 @@ BIOS 不可以读取 GPT 分区表,而 UEFI 可以。
|
||||
|
||||
inode 具体包含以下信息:
|
||||
|
||||
- 权限 (read/write/excute);
|
||||
- 拥有者与群组 (owner/group);
|
||||
- 容量;
|
||||
- 建立或状态改变的时间 (ctime);
|
||||
- 最近读取时间 (atime);
|
||||
- 最近修改时间 (mtime);
|
||||
- 定义文件特性的旗标 (flag),如 SetUID...;
|
||||
- 该文件真正内容的指向 (pointer)。
|
||||
* 权限 (read/write/excute);
|
||||
* 拥有者与群组 (owner/group);
|
||||
* 容量;
|
||||
* 建立或状态改变的时间 (ctime);
|
||||
* 最近读取时间 (atime);
|
||||
* 最近修改时间 (mtime);
|
||||
* 定义文件特性的旗标 (flag),如 SetUID...;
|
||||
* 该文件真正内容的指向 (pointer)。
|
||||
|
||||
inode 具有以下特点:
|
||||
|
||||
- 每个 inode 大小均固定为 128 bytes (新的 ext4 与 xfs 可设定到 256 bytes);
|
||||
- 每个文件都仅会占用一个 inode。
|
||||
* 每个 inode 大小均固定为 128 bytes (新的 ext4 与 xfs 可设定到 256 bytes);
|
||||
* 每个文件都仅会占用一个 inode。
|
||||
|
||||
inode 中记录了文件内容所在的 block 编号,但是每个 block 非常小,一个大文件随便都需要几十万的 block。而一个 inode 大小有限,无法直接引用这么多 block 编号。因此引入了间接、双间接、三间接引用。间接引用让 inode 记录的引用 block 块记录引用信息。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/inode_with_signatures.jpg" width="600"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### 目录
|
||||
|
||||
@ -367,11 +375,12 @@ ext3/ext4 文件系统引入了日志功能,可以利用日志来修复文件
|
||||
|
||||
为了使不同 Linux 发行版本的目录结构保持一致性,Filesystem Hierarchy Standard (FHS) 规定了 Linux 的目录结构。最基础的三个目录如下:
|
||||
|
||||
- / (root, 根目录)
|
||||
- /usr (unix software resource):所有系统默认软件都会安装到这个目录;
|
||||
- /var (variable):存放系统或程序运行过程中的数据文件。
|
||||
* / (root, 根目录)
|
||||
* /usr (unix software resource):所有系统默认软件都会安装到这个目录;
|
||||
* /var (variable):存放系统或程序运行过程中的数据文件。
|
||||
|
||||
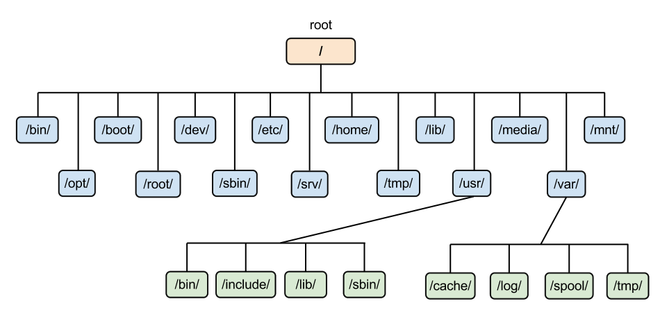\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/linux-filesystem.png" width=""/> </div><br>
|
||||
|
||||
## 五、文件
|
||||
|
||||
@ -381,27 +390,27 @@ ext3/ext4 文件系统引入了日志功能,可以利用日志来修复文件
|
||||
|
||||
使用 ls 查看一个文件时,会显示一个文件的信息,例如 `drwxr-xr-x 3 root root 17 May 6 00:14 .config`,对这个信息的解释如下:
|
||||
|
||||
- drwxr-xr-x:文件类型以及权限,第 1 位为文件类型字段,后 9 位为文件权限字段
|
||||
- 3:链接数
|
||||
- root:文件拥有者
|
||||
- root:所属群组
|
||||
- 17:文件大小
|
||||
- May 6 00:14:文件最后被修改的时间
|
||||
- .config:文件名
|
||||
* drwxr-xr-x:文件类型以及权限,第 1 位为文件类型字段,后 9 位为文件权限字段
|
||||
* 3:链接数
|
||||
* root:文件拥有者
|
||||
* root:所属群组
|
||||
* 17:文件大小
|
||||
* May 6 00:14:文件最后被修改的时间
|
||||
* .config:文件名
|
||||
|
||||
常见的文件类型及其含义有:
|
||||
|
||||
- d:目录
|
||||
- -:文件
|
||||
- l:链接文件
|
||||
* d:目录
|
||||
* \-:文件
|
||||
* l:链接文件
|
||||
|
||||
9 位的文件权限字段中,每 3 个为一组,共 3 组,每一组分别代表对文件拥有者、所属群组以及其它人的文件权限。一组权限中的 3 位分别为 r、w、x 权限,表示可读、可写、可执行。
|
||||
|
||||
文件时间有以下三种:
|
||||
|
||||
- modification time (mtime):文件的内容更新就会更新;
|
||||
- status time (ctime):文件的状态(权限、属性)更新就会更新;
|
||||
- access time (atime):读取文件时就会更新。
|
||||
* modification time (mtime):文件的内容更新就会更新;
|
||||
* status time (ctime):文件的状态(权限、属性)更新就会更新;
|
||||
* access time (atime):读取文件时就会更新。
|
||||
|
||||
### 文件与目录的基本操作
|
||||
|
||||
@ -525,8 +534,8 @@ cp [-adfilprsu] source destination
|
||||
|
||||
### 默认权限
|
||||
|
||||
- 文件默认权限:文件默认没有可执行权限,因此为 666,也就是 -rw-rw-rw- 。
|
||||
- 目录默认权限:目录必须要能够进入,也就是必须拥有可执行权限,因此为 777 ,也就是 drwxrwxrwx。
|
||||
* 文件默认权限:文件默认没有可执行权限,因此为 666,也就是 -rw-rw-rw- 。
|
||||
* 目录默认权限:目录必须要能够进入,也就是必须拥有可执行权限,因此为 777 ,也就是 drwxrwxrwx。
|
||||
|
||||
可以通过 umask 设置或者查看默认权限,通常以掩码的形式来表示,例如 002 表示其它用户的权限去除了一个 2 的权限,也就是写权限,因此建立新文件时默认的权限为 -rw-rw-r--。
|
||||
|
||||
@ -538,7 +547,7 @@ cp [-adfilprsu] source destination
|
||||
|
||||
### 链接
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/1e46fd03-0cda-4d60-9b1c-0c256edaf6b2.png" width="450px"> </div><br>
|
||||
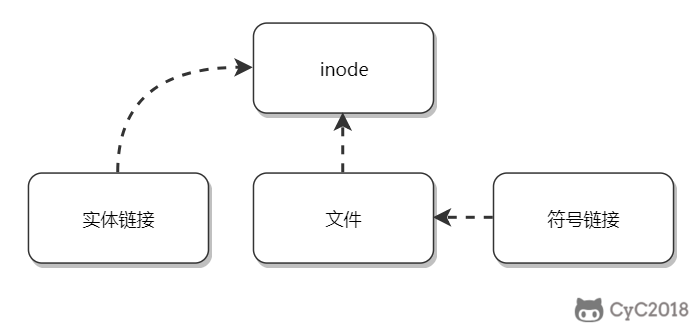\
|
||||
|
||||
|
||||
```html
|
||||
@ -655,7 +664,7 @@ locate 使用 /var/lib/mlocate/ 这个数据库来进行搜索,它存储在内
|
||||
example: find . -name "shadow*"
|
||||
```
|
||||
|
||||
**① 与时间有关的选项**
|
||||
**① 与时间有关的选项**
|
||||
|
||||
```html
|
||||
-mtime n :列出在 n 天前的那一天修改过内容的文件
|
||||
@ -664,11 +673,12 @@ example: find . -name "shadow*"
|
||||
-newer file : 列出比 file 更新的文件
|
||||
```
|
||||
|
||||
+4、4 和 -4 的指示的时间范围如下:
|
||||
\+4、4 和 -4 的指示的时间范围如下:
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/658fc5e7-79c0-4247-9445-d69bf194c539.png" width=""/> </div><br>
|
||||
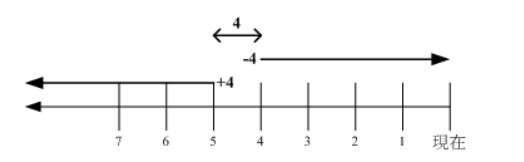\
|
||||
|
||||
**② 与文件拥有者和所属群组有关的选项**
|
||||
|
||||
**② 与文件拥有者和所属群组有关的选项**
|
||||
|
||||
```html
|
||||
-uid n
|
||||
@ -679,7 +689,7 @@ example: find . -name "shadow*"
|
||||
-nogroup:搜索所属群组不存在于 /etc/group 的文件
|
||||
```
|
||||
|
||||
**③ 与文件权限和名称有关的选项**
|
||||
**③ 与文件权限和名称有关的选项**
|
||||
|
||||
```html
|
||||
-name filename
|
||||
@ -696,17 +706,17 @@ example: find . -name "shadow*"
|
||||
|
||||
Linux 底下有很多压缩文件名,常见的如下:
|
||||
|
||||
| 扩展名 | 压缩程序 |
|
||||
| -- | -- |
|
||||
| \*.Z | compress |
|
||||
|\*.zip | zip |
|
||||
|\*.gz | gzip|
|
||||
|\*.bz2 | bzip2 |
|
||||
|\*.xz | xz |
|
||||
|\*.tar | tar 程序打包的数据,没有经过压缩 |
|
||||
|\*.tar.gz | tar 程序打包的文件,经过 gzip 的压缩 |
|
||||
|\*.tar.bz2 | tar 程序打包的文件,经过 bzip2 的压缩 |
|
||||
|\*.tar.xz | tar 程序打包的文件,经过 xz 的压缩 |
|
||||
| 扩展名 | 压缩程序 |
|
||||
| ---------- | ------------------------ |
|
||||
| \*.Z | compress |
|
||||
| \*.zip | zip |
|
||||
| \*.gz | gzip |
|
||||
| \*.bz2 | bzip2 |
|
||||
| \*.xz | xz |
|
||||
| \*.tar | tar 程序打包的数据,没有经过压缩 |
|
||||
| \*.tar.gz | tar 程序打包的文件,经过 gzip 的压缩 |
|
||||
| \*.tar.bz2 | tar 程序打包的文件,经过 bzip2 的压缩 |
|
||||
| \*.tar.xz | tar 程序打包的文件,经过 xz 的压缩 |
|
||||
|
||||
### 压缩指令
|
||||
|
||||
@ -771,11 +781,11 @@ $ tar [-z|-j|-J] [xv] [-f 已有的 tar 文件] [-C 目录] ==解压缩
|
||||
-C 目录 : 在特定目录解压缩。
|
||||
```
|
||||
|
||||
| 使用方式 | 命令 |
|
||||
| :---: | --- |
|
||||
| 使用方式 | 命令 |
|
||||
| :--: | ----------------------------------------- |
|
||||
| 打包压缩 | tar -jcv -f filename.tar.bz2 要被压缩的文件或目录名称 |
|
||||
| 查 看 | tar -jtv -f filename.tar.bz2 |
|
||||
| 解压缩 | tar -jxv -f filename.tar.bz2 -C 要解压缩的目录 |
|
||||
| 查 看 | tar -jtv -f filename.tar.bz2 |
|
||||
| 解压缩 | tar -jxv -f filename.tar.bz2 -C 要解压缩的目录 |
|
||||
|
||||
## 七、Bash
|
||||
|
||||
@ -783,17 +793,17 @@ $ tar [-z|-j|-J] [xv] [-f 已有的 tar 文件] [-C 目录] ==解压缩
|
||||
|
||||
### 特性
|
||||
|
||||
- 命令历史:记录使用过的命令
|
||||
- 命令与文件补全:快捷键:tab
|
||||
- 命名别名:例如 ll 是 ls -al 的别名
|
||||
- shell scripts
|
||||
- 通配符:例如 ls -l /usr/bin/X\* 列出 /usr/bin 下面所有以 X 开头的文件
|
||||
* 命令历史:记录使用过的命令
|
||||
* 命令与文件补全:快捷键:tab
|
||||
* 命名别名:例如 ll 是 ls -al 的别名
|
||||
* shell scripts
|
||||
* 通配符:例如 ls -l /usr/bin/X\* 列出 /usr/bin 下面所有以 X 开头的文件
|
||||
|
||||
### 变量操作
|
||||
|
||||
对一个变量赋值直接使用 =。
|
||||
|
||||
对变量取用需要在变量前加上 \$ ,也可以用 \${} 的形式;
|
||||
对变量取用需要在变量前加上 $ ,也可以用 ${} 的形式;
|
||||
|
||||
输出变量使用 echo 命令。
|
||||
|
||||
@ -805,10 +815,10 @@ $ echo ${x}
|
||||
|
||||
变量内容如果有空格,必须使用双引号或者单引号。
|
||||
|
||||
- 双引号内的特殊字符可以保留原本特性,例如 x="lang is \$LANG",则 x 的值为 lang is zh_TW.UTF-8;
|
||||
- 单引号内的特殊字符就是特殊字符本身,例如 x='lang is \$LANG',则 x 的值为 lang is \$LANG。
|
||||
* 双引号内的特殊字符可以保留原本特性,例如 x="lang is $LANG",则 x 的值为 lang is zh\_TW.UTF-8;
|
||||
* 单引号内的特殊字符就是特殊字符本身,例如 x='lang is $LANG',则 x 的值为 lang is $LANG。
|
||||
|
||||
可以使用 \`指令\` 或者 \$(指令) 的方式将指令的执行结果赋值给变量。例如 version=\$(uname -r),则 version 的值为 4.15.0-22-generic。
|
||||
可以使用 \`指令\` 或者 $(指令) 的方式将指令的执行结果赋值给变量。例如 version=$(uname -r),则 version 的值为 4.15.0-22-generic。
|
||||
|
||||
可以使用 export 命令将自定义变量转成环境变量,环境变量可以在子程序中使用,所谓子程序就是由当前 Bash 而产生的子 Bash。
|
||||
|
||||
@ -822,7 +832,7 @@ $ declare [-aixr] variable
|
||||
-r : 定义为 readonly 类型
|
||||
```
|
||||
|
||||
使用 [ ] 来对数组进行索引操作:
|
||||
使用 \[ ] 来对数组进行索引操作:
|
||||
|
||||
```bash
|
||||
$ array[1]=a
|
||||
@ -832,26 +842,26 @@ $ echo ${array[1]}
|
||||
|
||||
### 指令搜索顺序
|
||||
|
||||
- 以绝对或相对路径来执行指令,例如 /bin/ls 或者 ./ls ;
|
||||
- 由别名找到该指令来执行;
|
||||
- 由 Bash 内置的指令来执行;
|
||||
- 按 \$PATH 变量指定的搜索路径的顺序找到第一个指令来执行。
|
||||
* 以绝对或相对路径来执行指令,例如 /bin/ls 或者 ./ls ;
|
||||
* 由别名找到该指令来执行;
|
||||
* 由 Bash 内置的指令来执行;
|
||||
* 按 $PATH 变量指定的搜索路径的顺序找到第一个指令来执行。
|
||||
|
||||
### 数据流重定向
|
||||
|
||||
重定向指的是使用文件代替标准输入、标准输出和标准错误输出。
|
||||
|
||||
| 1 | 代码 | 运算符 |
|
||||
| :---: | :---: | :---:|
|
||||
| 标准输入 (stdin) | 0 | \< 或 \<\< |
|
||||
| 标准输出 (stdout) | 1 | > 或 \>\> |
|
||||
| 标准错误输出 (stderr) | 2 | 2\> 或 2\>\> |
|
||||
| 1 | 代码 | 运算符 |
|
||||
| :-------------: | :-: | :------: |
|
||||
| 标准输入 (stdin) | 0 | < 或 << |
|
||||
| 标准输出 (stdout) | 1 | > 或 >> |
|
||||
| 标准错误输出 (stderr) | 2 | 2> 或 2>> |
|
||||
|
||||
其中,有一个箭头的表示以覆盖的方式重定向,而有两个箭头的表示以追加的方式重定向。
|
||||
|
||||
可以将不需要的标准输出以及标准错误输出重定向到 /dev/null,相当于扔进垃圾箱。
|
||||
|
||||
如果需要将标准输出以及标准错误输出同时重定向到一个文件,需要将某个输出转换为另一个输出,例如 2\>&1 表示将标准错误输出转换为标准输出。
|
||||
如果需要将标准输出以及标准错误输出同时重定向到一个文件,需要将某个输出转换为另一个输出,例如 2>&1 表示将标准错误输出转换为标准输出。
|
||||
|
||||
```bash
|
||||
$ find /home -name .bashrc > list 2>&1
|
||||
@ -906,7 +916,7 @@ $ export | cut -c 12-
|
||||
|
||||
### 排序指令
|
||||
|
||||
**sort** 用于排序。
|
||||
**sort** 用于排序。
|
||||
|
||||
```html
|
||||
$ sort [-fbMnrtuk] [file or stdin]
|
||||
@ -930,7 +940,7 @@ alex:x:1001:1002::/home/alex:/bin/bash
|
||||
arod:x:1002:1003::/home/arod:/bin/bash
|
||||
```
|
||||
|
||||
**uniq** 可以将重复的数据只取一个。
|
||||
**uniq** 可以将重复的数据只取一个。
|
||||
|
||||
```html
|
||||
$ uniq [-ic]
|
||||
@ -952,7 +962,7 @@ $ last | cut -d ' ' -f 1 | sort | uniq -c
|
||||
|
||||
### 双向输出重定向
|
||||
|
||||
输出重定向会将输出内容重定向到文件中,而 **tee** 不仅能够完成这个功能,还能保留屏幕上的输出。也就是说,使用 tee 指令,一个输出会同时传送到文件和屏幕上。
|
||||
输出重定向会将输出内容重定向到文件中,而 **tee** 不仅能够完成这个功能,还能保留屏幕上的输出。也就是说,使用 tee 指令,一个输出会同时传送到文件和屏幕上。
|
||||
|
||||
```html
|
||||
$ tee [-a] file
|
||||
@ -960,7 +970,7 @@ $ tee [-a] file
|
||||
|
||||
### 字符转换指令
|
||||
|
||||
**tr** 用来删除一行中的字符,或者对字符进行替换。
|
||||
**tr** 用来删除一行中的字符,或者对字符进行替换。
|
||||
|
||||
```html
|
||||
$ tr [-ds] SET1 ...
|
||||
@ -973,21 +983,21 @@ $ tr [-ds] SET1 ...
|
||||
$ last | tr '[a-z]' '[A-Z]'
|
||||
```
|
||||
|
||||
**col** 将 tab 字符转为空格字符。
|
||||
**col** 将 tab 字符转为空格字符。
|
||||
|
||||
```html
|
||||
$ col [-xb]
|
||||
-x : 将 tab 键转换成对等的空格键
|
||||
```
|
||||
|
||||
**expand** 将 tab 转换一定数量的空格,默认是 8 个。
|
||||
**expand** 将 tab 转换一定数量的空格,默认是 8 个。
|
||||
|
||||
```html
|
||||
$ expand [-t] file
|
||||
-t :tab 转为空格的数量
|
||||
```
|
||||
|
||||
**join** 将有相同数据的那一行合并在一起。
|
||||
**join** 将有相同数据的那一行合并在一起。
|
||||
|
||||
```html
|
||||
$ join [-ti12] file1 file2
|
||||
@ -997,7 +1007,7 @@ $ join [-ti12] file1 file2
|
||||
-2 :第二个文件所用的比较字段
|
||||
```
|
||||
|
||||
**paste** 直接将两行粘贴在一起。
|
||||
**paste** 直接将两行粘贴在一起。
|
||||
|
||||
```html
|
||||
$ paste [-d] file1 file2
|
||||
@ -1006,7 +1016,7 @@ $ paste [-d] file1 file2
|
||||
|
||||
### 分区指令
|
||||
|
||||
**split** 将一个文件划分成多个文件。
|
||||
**split** 将一个文件划分成多个文件。
|
||||
|
||||
```html
|
||||
$ split [-bl] file PREFIX
|
||||
@ -1062,9 +1072,9 @@ $ printf '%10s %5i %5i %5i %8.2f \n' $(cat printf.txt)
|
||||
|
||||
是由 Alfred Aho,Peter Weinberger 和 Brian Kernighan 创造,awk 这个名字就是这三个创始人名字的首字母。
|
||||
|
||||
awk 每次处理一行,处理的最小单位是字段,每个字段的命名方式为:\$n,n 为字段号,从 1 开始,\$0 表示一整行。
|
||||
awk 每次处理一行,处理的最小单位是字段,每个字段的命名方式为:$n,n 为字段号,从 1 开始,$0 表示一整行。
|
||||
|
||||
示例:取出最近五个登录用户的用户名和 IP。首先用 last -n 5 取出用最近五个登录用户的所有信息,可以看到用户名和 IP 分别在第 1 列和第 3 列,我们用 \$1 和 \$3 就能取出这两个字段,然后用 print 进行打印。
|
||||
示例:取出最近五个登录用户的用户名和 IP。首先用 last -n 5 取出用最近五个登录用户的所有信息,可以看到用户名和 IP 分别在第 1 列和第 3 列,我们用 $1 和 $3 就能取出这两个字段,然后用 print 进行打印。
|
||||
|
||||
```html
|
||||
$ last -n 5
|
||||
@ -1092,7 +1102,7 @@ $ awk '条件类型 1 {动作 1} 条件类型 2 {动作 2} ...' filename
|
||||
|
||||
示例:/etc/passwd 文件第三个字段为 UID,对 UID 小于 10 的数据进行处理。
|
||||
|
||||
```text
|
||||
```
|
||||
$ cat /etc/passwd | awk 'BEGIN {FS=":"} $3 < 10 {print $1 "\t " $3}'
|
||||
root 0
|
||||
bin 1
|
||||
@ -1101,11 +1111,11 @@ daemon 2
|
||||
|
||||
awk 变量:
|
||||
|
||||
| 变量名称 | 代表意义 |
|
||||
| :--: | -- |
|
||||
| NF | 每一行拥有的字段总数 |
|
||||
| NR | 目前所处理的是第几行数据 |
|
||||
| FS | 目前的分隔字符,默认是空格键 |
|
||||
| 变量名称 | 代表意义 |
|
||||
| :--: | -------------- |
|
||||
| NF | 每一行拥有的字段总数 |
|
||||
| NR | 目前所处理的是第几行数据 |
|
||||
| FS | 目前的分隔字符,默认是空格键 |
|
||||
|
||||
示例:显示正在处理的行号以及每一行有多少字段
|
||||
|
||||
@ -1128,19 +1138,19 @@ dmtsai lines: 5 columns: 9
|
||||
|
||||
示例:查看自己的进程
|
||||
|
||||
```sh
|
||||
```
|
||||
## ps -l
|
||||
```
|
||||
|
||||
示例:查看系统所有进程
|
||||
|
||||
```sh
|
||||
```
|
||||
## ps aux
|
||||
```
|
||||
|
||||
示例:查看特定的进程
|
||||
|
||||
```sh
|
||||
```
|
||||
## ps aux | grep threadx
|
||||
```
|
||||
|
||||
@ -1150,7 +1160,7 @@ dmtsai lines: 5 columns: 9
|
||||
|
||||
示例:查看所有进程树
|
||||
|
||||
```sh
|
||||
```
|
||||
## pstree -A
|
||||
```
|
||||
|
||||
@ -1160,7 +1170,7 @@ dmtsai lines: 5 columns: 9
|
||||
|
||||
示例:两秒钟刷新一次
|
||||
|
||||
```sh
|
||||
```
|
||||
## top -d 2
|
||||
```
|
||||
|
||||
@ -1170,35 +1180,37 @@ dmtsai lines: 5 columns: 9
|
||||
|
||||
示例:查看特定端口的进程
|
||||
|
||||
```sh
|
||||
```
|
||||
## netstat -anp | grep port
|
||||
```
|
||||
|
||||
### 进程状态
|
||||
|
||||
| 状态 | 说明 |
|
||||
| :---: | --- |
|
||||
| R | running or runnable (on run queue)<br>正在执行或者可执行,此时进程位于执行队列中。|
|
||||
| D | uninterruptible sleep (usually I/O)<br>不可中断阻塞,通常为 IO 阻塞。 |
|
||||
| S | interruptible sleep (waiting for an event to complete) <br> 可中断阻塞,此时进程正在等待某个事件完成。|
|
||||
| Z | zombie (terminated but not reaped by its parent)<br>僵死,进程已经终止但是尚未被其父进程获取信息。|
|
||||
| T | stopped (either by a job control signal or because it is being traced) <br> 结束,进程既可以被作业控制信号结束,也可能是正在被追踪。|
|
||||
<br>
|
||||
| 状态 | 说明 |
|
||||
| :---------: | ------------------------------------------------------------------------------------------------------------- |
|
||||
| R | <p>running or runnable (on run queue)<br>正在执行或者可执行,此时进程位于执行队列中。</p> |
|
||||
| D | <p>uninterruptible sleep (usually I/O)<br>不可中断阻塞,通常为 IO 阻塞。</p> |
|
||||
| S | <p>interruptible sleep (waiting for an event to complete)<br>可中断阻塞,此时进程正在等待某个事件完成。</p> |
|
||||
| Z | <p>zombie (terminated but not reaped by its parent)<br>僵死,进程已经终止但是尚未被其父进程获取信息。</p> |
|
||||
| T | <p>stopped (either by a job control signal or because it is being traced)<br>结束,进程既可以被作业控制信号结束,也可能是正在被追踪。</p> |
|
||||
| <p><br></p> | |
|
||||
|
||||
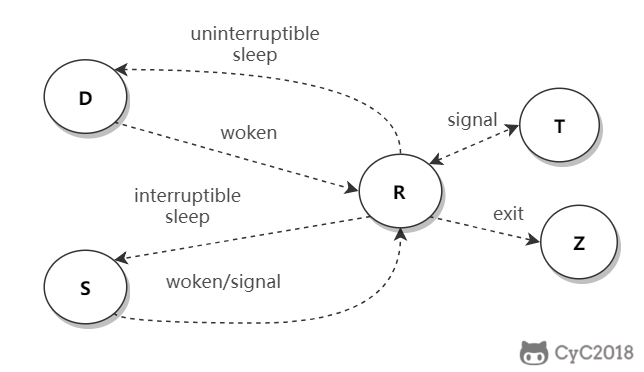\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/2bab4127-3e7d-48cc-914e-436be859fb05.png" width="490px"/> </div><br>
|
||||
|
||||
### SIGCHLD
|
||||
|
||||
当一个子进程改变了它的状态时(停止运行,继续运行或者退出),有两件事会发生在父进程中:
|
||||
|
||||
- 得到 SIGCHLD 信号;
|
||||
- waitpid() 或者 wait() 调用会返回。
|
||||
* 得到 SIGCHLD 信号;
|
||||
* waitpid() 或者 wait() 调用会返回。
|
||||
|
||||
其中子进程发送的 SIGCHLD 信号包含了子进程的信息,比如进程 ID、进程状态、进程使用 CPU 的时间等。
|
||||
|
||||
在子进程退出时,它的进程描述符不会立即释放,这是为了让父进程得到子进程信息,父进程通过 wait() 和 waitpid() 来获得一个已经退出的子进程的信息。
|
||||
|
||||
<div align="center"> <!-- <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/flow.png" width=""/> --> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### wait()
|
||||
|
||||
@ -1244,21 +1256,21 @@ options 参数主要有 WNOHANG 和 WUNTRACED 两个选项,WNOHANG 可以使 w
|
||||
|
||||
## 参考资料
|
||||
|
||||
- 鸟哥. 鸟 哥 的 Linux 私 房 菜 基 础 篇 第 三 版[J]. 2009.
|
||||
- [Linux 平台上的软件包管理](https://www.ibm.com/developerworks/cn/linux/l-cn-rpmdpkg/index.html)
|
||||
- [Linux 之守护进程、僵死进程与孤儿进程](http://liubigbin.github.io/2016/03/11/Linux-%E4%B9%8B%E5%AE%88%E6%8A%A4%E8%BF%9B%E7%A8%8B%E3%80%81%E5%83%B5%E6%AD%BB%E8%BF%9B%E7%A8%8B%E4%B8%8E%E5%AD%A4%E5%84%BF%E8%BF%9B%E7%A8%8B/)
|
||||
- [What is the difference between a symbolic link and a hard link?](https://stackoverflow.com/questions/185899/what-is-the-difference-between-a-symbolic-link-and-a-hard-link)
|
||||
- [Linux process states](https://idea.popcount.org/2012-12-11-linux-process-states/)
|
||||
- [GUID Partition Table](https://en.wikipedia.org/wiki/GUID_Partition_Table)
|
||||
- [详解 wait 和 waitpid 函数](https://blog.csdn.net/kevinhg/article/details/7001719)
|
||||
- [IDE、SATA、SCSI、SAS、FC、SSD 硬盘类型介绍](https://blog.csdn.net/tianlesoftware/article/details/6009110)
|
||||
- [Akai IB-301S SCSI Interface for S2800,S3000](http://www.mpchunter.com/s3000/akai-ib-301s-scsi-interface-for-s2800s3000/)
|
||||
- [Parallel ATA](https://en.wikipedia.org/wiki/Parallel_ATA)
|
||||
- [ADATA XPG SX900 256GB SATA 3 SSD Review – Expanded Capacity and SandForce Driven Speed](http://www.thessdreview.com/our-reviews/adata-xpg-sx900-256gb-sata-3-ssd-review-expanded-capacity-and-sandforce-driven-speed/4/)
|
||||
- [Decoding UCS Invicta – Part 1](https://blogs.cisco.com/datacenter/decoding-ucs-invicta-part-1)
|
||||
- [硬盘](https://zh.wikipedia.org/wiki/%E7%A1%AC%E7%9B%98)
|
||||
- [Difference between SAS and SATA](http://www.differencebetween.info/difference-between-sas-and-sata)
|
||||
- [BIOS](https://zh.wikipedia.org/wiki/BIOS)
|
||||
- [File system design case studies](https://www.cs.rutgers.edu/\~pxk/416/notes/13-fs-studies.html)
|
||||
- [Programming Project #4](https://classes.soe.ucsc.edu/cmps111/Fall08/proj4.shtml)
|
||||
- [FILE SYSTEM DESIGN](http://web.cs.ucla.edu/classes/fall14/cs111/scribe/11a/index.html)
|
||||
* 鸟哥. 鸟 哥 的 Linux 私 房 菜 基 础 篇 第 三 版\[J]. 2009.
|
||||
* [Linux 平台上的软件包管理](https://www.ibm.com/developerworks/cn/linux/l-cn-rpmdpkg/index.html)
|
||||
* [Linux 之守护进程、僵死进程与孤儿进程](http://liubigbin.github.io/2016/03/11/Linux-%E4%B9%8B%E5%AE%88%E6%8A%A4%E8%BF%9B%E7%A8%8B%E3%80%81%E5%83%B5%E6%AD%BB%E8%BF%9B%E7%A8%8B%E4%B8%8E%E5%AD%A4%E5%84%BF%E8%BF%9B%E7%A8%8B/)
|
||||
* [What is the difference between a symbolic link and a hard link?](https://stackoverflow.com/questions/185899/what-is-the-difference-between-a-symbolic-link-and-a-hard-link)
|
||||
* [Linux process states](https://idea.popcount.org/2012-12-11-linux-process-states/)
|
||||
* [GUID Partition Table](https://en.wikipedia.org/wiki/GUID\_Partition\_Table)
|
||||
* [详解 wait 和 waitpid 函数](https://blog.csdn.net/kevinhg/article/details/7001719)
|
||||
* [IDE、SATA、SCSI、SAS、FC、SSD 硬盘类型介绍](https://blog.csdn.net/tianlesoftware/article/details/6009110)
|
||||
* [Akai IB-301S SCSI Interface for S2800,S3000](http://www.mpchunter.com/s3000/akai-ib-301s-scsi-interface-for-s2800s3000/)
|
||||
* [Parallel ATA](https://en.wikipedia.org/wiki/Parallel\_ATA)
|
||||
* [ADATA XPG SX900 256GB SATA 3 SSD Review – Expanded Capacity and SandForce Driven Speed](http://www.thessdreview.com/our-reviews/adata-xpg-sx900-256gb-sata-3-ssd-review-expanded-capacity-and-sandforce-driven-speed/4/)
|
||||
* [Decoding UCS Invicta – Part 1](https://blogs.cisco.com/datacenter/decoding-ucs-invicta-part-1)
|
||||
* [硬盘](https://zh.wikipedia.org/wiki/%E7%A1%AC%E7%9B%98)
|
||||
* [Difference between SAS and SATA](http://www.differencebetween.info/difference-between-sas-and-sata)
|
||||
* [BIOS](https://zh.wikipedia.org/wiki/BIOS)
|
||||
* [File system design case studies](https://www.cs.rutgers.edu/\~pxk/416/notes/13-fs-studies.html)
|
||||
* [Programming Project #4](https://classes.soe.ucsc.edu/cmps111/Fall08/proj4.shtml)
|
||||
* [FILE SYSTEM DESIGN](http://web.cs.ucla.edu/classes/fall14/cs111/scribe/11a/index.html)
|
||||
|
||||
206
notes/MySQL.md
206
notes/MySQL.md
@ -1,36 +1,34 @@
|
||||
# MySQL
|
||||
<!-- GFM-TOC -->
|
||||
* [MySQL](#mysql)
|
||||
* [一、索引](#一索引)
|
||||
* [B+ Tree 原理](#b-tree-原理)
|
||||
* [MySQL 索引](#mysql-索引)
|
||||
* [索引优化](#索引优化)
|
||||
* [索引的优点](#索引的优点)
|
||||
* [索引的使用条件](#索引的使用条件)
|
||||
* [二、查询性能优化](#二查询性能优化)
|
||||
* [使用 Explain 进行分析](#使用-explain-进行分析)
|
||||
* [优化数据访问](#优化数据访问)
|
||||
* [重构查询方式](#重构查询方式)
|
||||
* [三、存储引擎](#三存储引擎)
|
||||
* [InnoDB](#innodb)
|
||||
* [MyISAM](#myisam)
|
||||
* [比较](#比较)
|
||||
* [四、数据类型](#四数据类型)
|
||||
* [整型](#整型)
|
||||
* [浮点数](#浮点数)
|
||||
* [字符串](#字符串)
|
||||
* [时间和日期](#时间和日期)
|
||||
* [五、切分](#五切分)
|
||||
* [水平切分](#水平切分)
|
||||
* [垂直切分](#垂直切分)
|
||||
* [Sharding 策略](#sharding-策略)
|
||||
* [Sharding 存在的问题](#sharding-存在的问题)
|
||||
* [六、复制](#六复制)
|
||||
* [主从复制](#主从复制)
|
||||
* [读写分离](#读写分离)
|
||||
* [参考资料](#参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [MySQL](MySQL.md#mysql)
|
||||
* [一、索引](MySQL.md#一索引)
|
||||
* [B+ Tree 原理](MySQL.md#b-tree-原理)
|
||||
* [MySQL 索引](MySQL.md#mysql-索引)
|
||||
* [索引优化](MySQL.md#索引优化)
|
||||
* [索引的优点](MySQL.md#索引的优点)
|
||||
* [索引的使用条件](MySQL.md#索引的使用条件)
|
||||
* [二、查询性能优化](MySQL.md#二查询性能优化)
|
||||
* [使用 Explain 进行分析](MySQL.md#使用-explain-进行分析)
|
||||
* [优化数据访问](MySQL.md#优化数据访问)
|
||||
* [重构查询方式](MySQL.md#重构查询方式)
|
||||
* [三、存储引擎](MySQL.md#三存储引擎)
|
||||
* [InnoDB](MySQL.md#innodb)
|
||||
* [MyISAM](MySQL.md#myisam)
|
||||
* [比较](MySQL.md#比较)
|
||||
* [四、数据类型](MySQL.md#四数据类型)
|
||||
* [整型](MySQL.md#整型)
|
||||
* [浮点数](MySQL.md#浮点数)
|
||||
* [字符串](MySQL.md#字符串)
|
||||
* [时间和日期](MySQL.md#时间和日期)
|
||||
* [五、切分](MySQL.md#五切分)
|
||||
* [水平切分](MySQL.md#水平切分)
|
||||
* [垂直切分](MySQL.md#垂直切分)
|
||||
* [Sharding 策略](MySQL.md#sharding-策略)
|
||||
* [Sharding 存在的问题](MySQL.md#sharding-存在的问题)
|
||||
* [六、复制](MySQL.md#六复制)
|
||||
* [主从复制](MySQL.md#主从复制)
|
||||
* [读写分离](MySQL.md#读写分离)
|
||||
* [参考资料](MySQL.md#参考资料)
|
||||
|
||||
## 一、索引
|
||||
|
||||
@ -42,9 +40,10 @@ B Tree 指的是 Balance Tree,也就是平衡树。平衡树是一颗查找树
|
||||
|
||||
B+ Tree 是基于 B Tree 和叶子节点顺序访问指针进行实现,它具有 B Tree 的平衡性,并且通过顺序访问指针来提高区间查询的性能。
|
||||
|
||||
在 B+ Tree 中,一个节点中的 key 从左到右非递减排列,如果某个指针的左右相邻 key 分别是 key<sub>i</sub> 和 key<sub>i+1</sub>,且不为 null,则该指针指向节点的所有 key 大于等于 key<sub>i</sub> 且小于等于 key<sub>i+1</sub>。
|
||||
在 B+ Tree 中,一个节点中的 key 从左到右非递减排列,如果某个指针的左右相邻 key 分别是 keyi 和 keyi+1,且不为 null,则该指针指向节点的所有 key 大于等于 keyi 且小于等于 keyi+1。
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/33576849-9275-47bb-ada7-8ded5f5e7c73.png" width="350px"> </div><br>
|
||||
|
||||
#### 2. 操作
|
||||
|
||||
@ -58,7 +57,7 @@ B+ Tree 是基于 B Tree 和叶子节点顺序访问指针进行实现,它具
|
||||
|
||||
(一)B+ 树有更低的树高
|
||||
|
||||
平衡树的树高 O(h)=O(log<sub>d</sub>N),其中 d 为每个节点的出度。红黑树的出度为 2,而 B+ Tree 的出度一般都非常大,所以红黑树的树高 h 很明显比 B+ Tree 大非常多。
|
||||
平衡树的树高 O(h)=O(logdN),其中 d 为每个节点的出度。红黑树的出度为 2,而 B+ Tree 的出度一般都非常大,所以红黑树的树高 h 很明显比 B+ Tree 大非常多。
|
||||
|
||||
(二)磁盘访问原理
|
||||
|
||||
@ -88,18 +87,20 @@ B+ Tree 是基于 B Tree 和叶子节点顺序访问指针进行实现,它具
|
||||
|
||||
InnoDB 的 B+Tree 索引分为主索引和辅助索引。主索引的叶子节点 data 域记录着完整的数据记录,这种索引方式被称为聚簇索引。因为无法把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/45016e98-6879-4709-8569-262b2d6d60b9.png" width="350px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
辅助索引的叶子节点的 data 域记录着主键的值,因此在使用辅助索引进行查找时,需要先查找到主键值,然后再到主索引中进行查找。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/7c349b91-050b-4d72-a7f8-ec86320307ea.png" width="350px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
#### 2. 哈希索引
|
||||
|
||||
哈希索引能以 O(1) 时间进行查找,但是失去了有序性:
|
||||
|
||||
- 无法用于排序与分组;
|
||||
- 只支持精确查找,无法用于部分查找和范围查找。
|
||||
* 无法用于排序与分组;
|
||||
* 只支持精确查找,无法用于部分查找和范围查找。
|
||||
|
||||
InnoDB 存储引擎有一个特殊的功能叫“自适应哈希索引”,当某个索引值被使用的非常频繁时,会在 B+Tree 索引之上再创建一个哈希索引,这样就让 B+Tree 索引具有哈希索引的一些优点,比如快速的哈希查找。
|
||||
|
||||
@ -125,7 +126,7 @@ MyISAM 存储引擎支持空间数据索引(R-Tree),可以用于地理数
|
||||
|
||||
在进行查询时,索引列不能是表达式的一部分,也不能是函数的参数,否则无法使用索引。
|
||||
|
||||
例如下面的查询不能使用 actor_id 列的索引:
|
||||
例如下面的查询不能使用 actor\_id 列的索引:
|
||||
|
||||
```sql
|
||||
SELECT actor_id FROM sakila.actor WHERE actor_id + 1 = 5;
|
||||
@ -133,7 +134,7 @@ SELECT actor_id FROM sakila.actor WHERE actor_id + 1 = 5;
|
||||
|
||||
#### 2. 多列索引
|
||||
|
||||
在需要使用多个列作为条件进行查询时,使用多列索引比使用多个单列索引性能更好。例如下面的语句中,最好把 actor_id 和 film_id 设置为多列索引。
|
||||
在需要使用多个列作为条件进行查询时,使用多列索引比使用多个单列索引性能更好。例如下面的语句中,最好把 actor\_id 和 film\_id 设置为多列索引。
|
||||
|
||||
```sql
|
||||
SELECT film_id, actor_ id FROM sakila.film_actor
|
||||
@ -146,7 +147,7 @@ WHERE actor_id = 1 AND film_id = 1;
|
||||
|
||||
索引的选择性是指:不重复的索引值和记录总数的比值。最大值为 1,此时每个记录都有唯一的索引与其对应。选择性越高,每个记录的区分度越高,查询效率也越高。
|
||||
|
||||
例如下面显示的结果中 customer_id 的选择性比 staff_id 更高,因此最好把 customer_id 列放在多列索引的前面。
|
||||
例如下面显示的结果中 customer\_id 的选择性比 staff\_id 更高,因此最好把 customer\_id 列放在多列索引的前面。
|
||||
|
||||
```sql
|
||||
SELECT COUNT(DISTINCT staff_id)/COUNT(*) AS staff_id_selectivity,
|
||||
@ -173,25 +174,21 @@ customer_id_selectivity: 0.0373
|
||||
|
||||
具有以下优点:
|
||||
|
||||
- 索引通常远小于数据行的大小,只读取索引能大大减少数据访问量。
|
||||
- 一些存储引擎(例如 MyISAM)在内存中只缓存索引,而数据依赖于操作系统来缓存。因此,只访问索引可以不使用系统调用(通常比较费时)。
|
||||
- 对于 InnoDB 引擎,若辅助索引能够覆盖查询,则无需访问主索引。
|
||||
* 索引通常远小于数据行的大小,只读取索引能大大减少数据访问量。
|
||||
* 一些存储引擎(例如 MyISAM)在内存中只缓存索引,而数据依赖于操作系统来缓存。因此,只访问索引可以不使用系统调用(通常比较费时)。
|
||||
* 对于 InnoDB 引擎,若辅助索引能够覆盖查询,则无需访问主索引。
|
||||
|
||||
### 索引的优点
|
||||
|
||||
- 大大减少了服务器需要扫描的数据行数。
|
||||
|
||||
- 帮助服务器避免进行排序和分组,以及避免创建临时表(B+Tree 索引是有序的,可以用于 ORDER BY 和 GROUP BY 操作。临时表主要是在排序和分组过程中创建,不需要排序和分组,也就不需要创建临时表)。
|
||||
|
||||
- 将随机 I/O 变为顺序 I/O(B+Tree 索引是有序的,会将相邻的数据都存储在一起)。
|
||||
* 大大减少了服务器需要扫描的数据行数。
|
||||
* 帮助服务器避免进行排序和分组,以及避免创建临时表(B+Tree 索引是有序的,可以用于 ORDER BY 和 GROUP BY 操作。临时表主要是在排序和分组过程中创建,不需要排序和分组,也就不需要创建临时表)。
|
||||
* 将随机 I/O 变为顺序 I/O(B+Tree 索引是有序的,会将相邻的数据都存储在一起)。
|
||||
|
||||
### 索引的使用条件
|
||||
|
||||
- 对于非常小的表、大部分情况下简单的全表扫描比建立索引更高效;
|
||||
|
||||
- 对于中到大型的表,索引就非常有效;
|
||||
|
||||
- 但是对于特大型的表,建立和维护索引的代价将会随之增长。这种情况下,需要用到一种技术可以直接区分出需要查询的一组数据,而不是一条记录一条记录地匹配,例如可以使用分区技术。
|
||||
* 对于非常小的表、大部分情况下简单的全表扫描比建立索引更高效;
|
||||
* 对于中到大型的表,索引就非常有效;
|
||||
* 但是对于特大型的表,建立和维护索引的代价将会随之增长。这种情况下,需要用到一种技术可以直接区分出需要查询的一组数据,而不是一条记录一条记录地匹配,例如可以使用分区技术。
|
||||
|
||||
## 二、查询性能优化
|
||||
|
||||
@ -201,17 +198,17 @@ Explain 用来分析 SELECT 查询语句,开发人员可以通过分析 Explai
|
||||
|
||||
比较重要的字段有:
|
||||
|
||||
- select_type : 查询类型,有简单查询、联合查询、子查询等
|
||||
- key : 使用的索引
|
||||
- rows : 扫描的行数
|
||||
* select\_type : 查询类型,有简单查询、联合查询、子查询等
|
||||
* key : 使用的索引
|
||||
* rows : 扫描的行数
|
||||
|
||||
### 优化数据访问
|
||||
|
||||
#### 1. 减少请求的数据量
|
||||
|
||||
- 只返回必要的列:最好不要使用 SELECT * 语句。
|
||||
- 只返回必要的行:使用 LIMIT 语句来限制返回的数据。
|
||||
- 缓存重复查询的数据:使用缓存可以避免在数据库中进行查询,特别在要查询的数据经常被重复查询时,缓存带来的查询性能提升将会是非常明显的。
|
||||
* 只返回必要的列:最好不要使用 SELECT \* 语句。
|
||||
* 只返回必要的行:使用 LIMIT 语句来限制返回的数据。
|
||||
* 缓存重复查询的数据:使用缓存可以避免在数据库中进行查询,特别在要查询的数据经常被重复查询时,缓存带来的查询性能提升将会是非常明显的。
|
||||
|
||||
#### 2. 减少服务器端扫描的行数
|
||||
|
||||
@ -239,11 +236,11 @@ do {
|
||||
|
||||
将一个大连接查询分解成对每一个表进行一次单表查询,然后在应用程序中进行关联,这样做的好处有:
|
||||
|
||||
- 让缓存更高效。对于连接查询,如果其中一个表发生变化,那么整个查询缓存就无法使用。而分解后的多个查询,即使其中一个表发生变化,对其它表的查询缓存依然可以使用。
|
||||
- 分解成多个单表查询,这些单表查询的缓存结果更可能被其它查询使用到,从而减少冗余记录的查询。
|
||||
- 减少锁竞争;
|
||||
- 在应用层进行连接,可以更容易对数据库进行拆分,从而更容易做到高性能和可伸缩。
|
||||
- 查询本身效率也可能会有所提升。例如下面的例子中,使用 IN() 代替连接查询,可以让 MySQL 按照 ID 顺序进行查询,这可能比随机的连接要更高效。
|
||||
* 让缓存更高效。对于连接查询,如果其中一个表发生变化,那么整个查询缓存就无法使用。而分解后的多个查询,即使其中一个表发生变化,对其它表的查询缓存依然可以使用。
|
||||
* 分解成多个单表查询,这些单表查询的缓存结果更可能被其它查询使用到,从而减少冗余记录的查询。
|
||||
* 减少锁竞争;
|
||||
* 在应用层进行连接,可以更容易对数据库进行拆分,从而更容易做到高性能和可伸缩。
|
||||
* 查询本身效率也可能会有所提升。例如下面的例子中,使用 IN() 代替连接查询,可以让 MySQL 按照 ID 顺序进行查询,这可能比随机的连接要更高效。
|
||||
|
||||
```sql
|
||||
SELECT * FROM tag
|
||||
@ -284,21 +281,16 @@ SELECT * FROM post WHERE post.id IN (123,456,567,9098,8904);
|
||||
|
||||
可以手工或者自动执行检查和修复操作,但是和事务恢复以及崩溃恢复不同,可能导致一些数据丢失,而且修复操作是非常慢的。
|
||||
|
||||
如果指定了 DELAY_KEY_WRITE 选项,在每次修改执行完成时,不会立即将修改的索引数据写入磁盘,而是会写到内存中的键缓冲区,只有在清理键缓冲区或者关闭表的时候才会将对应的索引块写入磁盘。这种方式可以极大的提升写入性能,但是在数据库或者主机崩溃时会造成索引损坏,需要执行修复操作。
|
||||
如果指定了 DELAY\_KEY\_WRITE 选项,在每次修改执行完成时,不会立即将修改的索引数据写入磁盘,而是会写到内存中的键缓冲区,只有在清理键缓冲区或者关闭表的时候才会将对应的索引块写入磁盘。这种方式可以极大的提升写入性能,但是在数据库或者主机崩溃时会造成索引损坏,需要执行修复操作。
|
||||
|
||||
### 比较
|
||||
|
||||
- 事务:InnoDB 是事务型的,可以使用 Commit 和 Rollback 语句。
|
||||
|
||||
- 并发:MyISAM 只支持表级锁,而 InnoDB 还支持行级锁。
|
||||
|
||||
- 外键:InnoDB 支持外键。
|
||||
|
||||
- 备份:InnoDB 支持在线热备份。
|
||||
|
||||
- 崩溃恢复:MyISAM 崩溃后发生损坏的概率比 InnoDB 高很多,而且恢复的速度也更慢。
|
||||
|
||||
- 其它特性:MyISAM 支持压缩表和空间数据索引。
|
||||
* 事务:InnoDB 是事务型的,可以使用 Commit 和 Rollback 语句。
|
||||
* 并发:MyISAM 只支持表级锁,而 InnoDB 还支持行级锁。
|
||||
* 外键:InnoDB 支持外键。
|
||||
* 备份:InnoDB 支持在线热备份。
|
||||
* 崩溃恢复:MyISAM 崩溃后发生损坏的概率比 InnoDB 高很多,而且恢复的速度也更慢。
|
||||
* 其它特性:MyISAM 支持压缩表和空间数据索引。
|
||||
|
||||
## 四、数据类型
|
||||
|
||||
@ -340,7 +332,7 @@ MySQL 提供了两种相似的日期时间类型:DATETIME 和 TIMESTAMP。
|
||||
|
||||
它和时区有关,也就是说一个时间戳在不同的时区所代表的具体时间是不同的。
|
||||
|
||||
MySQL 提供了 FROM_UNIXTIME() 函数把 UNIX 时间戳转换为日期,并提供了 UNIX_TIMESTAMP() 函数把日期转换为 UNIX 时间戳。
|
||||
MySQL 提供了 FROM\_UNIXTIME() 函数把 UNIX 时间戳转换为日期,并提供了 UNIX\_TIMESTAMP() 函数把日期转换为 UNIX 时间戳。
|
||||
|
||||
默认情况下,如果插入时没有指定 TIMESTAMP 列的值,会将这个值设置为当前时间。
|
||||
|
||||
@ -354,7 +346,8 @@ MySQL 提供了 FROM_UNIXTIME() 函数把 UNIX 时间戳转换为日期,并提
|
||||
|
||||
当一个表的数据不断增多时,Sharding 是必然的选择,它可以将数据分布到集群的不同节点上,从而缓存单个数据库的压力。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/63c2909f-0c5f-496f-9fe5-ee9176b31aba.jpg" width=""> </div><br>
|
||||
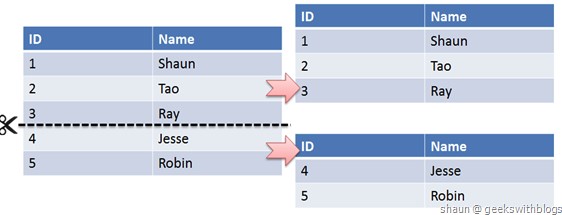\
|
||||
|
||||
|
||||
### 垂直切分
|
||||
|
||||
@ -362,13 +355,14 @@ MySQL 提供了 FROM_UNIXTIME() 函数把 UNIX 时间戳转换为日期,并提
|
||||
|
||||
在数据库的层面使用垂直切分将按数据库中表的密集程度部署到不同的库中,例如将原来的电商数据库垂直切分成商品数据库、用户数据库等。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/e130e5b8-b19a-4f1e-b860-223040525cf6.jpg" width=""> </div><br>
|
||||
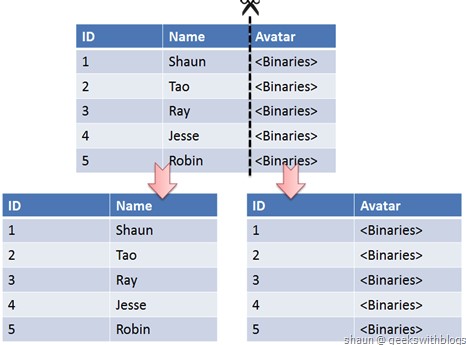\
|
||||
|
||||
|
||||
### Sharding 策略
|
||||
|
||||
- 哈希取模:hash(key) % N;
|
||||
- 范围:可以是 ID 范围也可以是时间范围;
|
||||
- 映射表:使用单独的一个数据库来存储映射关系。
|
||||
* 哈希取模:hash(key) % N;
|
||||
* 范围:可以是 ID 范围也可以是时间范围;
|
||||
* 映射表:使用单独的一个数据库来存储映射关系。
|
||||
|
||||
### Sharding 存在的问题
|
||||
|
||||
@ -382,9 +376,9 @@ MySQL 提供了 FROM_UNIXTIME() 函数把 UNIX 时间戳转换为日期,并提
|
||||
|
||||
#### 3. ID 唯一性
|
||||
|
||||
- 使用全局唯一 ID(GUID)
|
||||
- 为每个分片指定一个 ID 范围
|
||||
- 分布式 ID 生成器 (如 Twitter 的 Snowflake 算法)
|
||||
* 使用全局唯一 ID(GUID)
|
||||
* 为每个分片指定一个 ID 范围
|
||||
* 分布式 ID 生成器 (如 Twitter 的 Snowflake 算法)
|
||||
|
||||
## 六、复制
|
||||
|
||||
@ -392,11 +386,12 @@ MySQL 提供了 FROM_UNIXTIME() 函数把 UNIX 时间戳转换为日期,并提
|
||||
|
||||
主要涉及三个线程:binlog 线程、I/O 线程和 SQL 线程。
|
||||
|
||||
- **binlog 线程** :负责将主服务器上的数据更改写入二进制日志(Binary log)中。
|
||||
- **I/O 线程** :负责从主服务器上读取二进制日志,并写入从服务器的中继日志(Relay log)。
|
||||
- **SQL 线程** :负责读取中继日志,解析出主服务器已经执行的数据更改并在从服务器中重放(Replay)。
|
||||
* **binlog 线程** :负责将主服务器上的数据更改写入二进制日志(Binary log)中。
|
||||
* **I/O 线程** :负责从主服务器上读取二进制日志,并写入从服务器的中继日志(Relay log)。
|
||||
* **SQL 线程** :负责读取中继日志,解析出主服务器已经执行的数据更改并在从服务器中重放(Replay)。
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/master-slave.png" width=""> </div><br>
|
||||
|
||||
### 读写分离
|
||||
|
||||
@ -404,24 +399,25 @@ MySQL 提供了 FROM_UNIXTIME() 函数把 UNIX 时间戳转换为日期,并提
|
||||
|
||||
读写分离能提高性能的原因在于:
|
||||
|
||||
- 主从服务器负责各自的读和写,极大程度缓解了锁的争用;
|
||||
- 从服务器可以使用 MyISAM,提升查询性能以及节约系统开销;
|
||||
- 增加冗余,提高可用性。
|
||||
* 主从服务器负责各自的读和写,极大程度缓解了锁的争用;
|
||||
* 从服务器可以使用 MyISAM,提升查询性能以及节约系统开销;
|
||||
* 增加冗余,提高可用性。
|
||||
|
||||
读写分离常用代理方式来实现,代理服务器接收应用层传来的读写请求,然后决定转发到哪个服务器。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/master-slave-proxy.png" width=""> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 参考资料
|
||||
|
||||
- BaronScbwartz, PeterZaitsev, VadimTkacbenko, 等. 高性能 MySQL[M]. 电子工业出版社, 2013.
|
||||
- 姜承尧. MySQL 技术内幕: InnoDB 存储引擎 [M]. 机械工业出版社, 2011.
|
||||
- [20+ 条 MySQL 性能优化的最佳经验](https://www.jfox.info/20-tiao-mysql-xing-nen-you-hua-de-zui-jia-jing-yan.html)
|
||||
- [服务端指南 数据存储篇 | MySQL(09) 分库与分表带来的分布式困境与应对之策](http://blog.720ui.com/2017/mysql_core_09_multi_db_table2/ "服务端指南 数据存储篇 | MySQL(09) 分库与分表带来的分布式困境与应对之策")
|
||||
- [How to create unique row ID in sharded databases?](https://stackoverflow.com/questions/788829/how-to-create-unique-row-id-in-sharded-databases)
|
||||
- [SQL Azure Federation – Introduction](http://geekswithblogs.net/shaunxu/archive/2012/01/07/sql-azure-federation-ndash-introduction.aspx "Title of this entry.")
|
||||
- [MySQL 索引背后的数据结构及算法原理](http://blog.codinglabs.org/articles/theory-of-mysql-index.html)
|
||||
- [MySQL 性能优化神器 Explain 使用分析](https://segmentfault.com/a/1190000008131735)
|
||||
- [How Sharding Works](https://medium.com/@jeeyoungk/how-sharding-works-b4dec46b3f6)
|
||||
- [大众点评订单系统分库分表实践](https://tech.meituan.com/dianping_order_db_sharding.html)
|
||||
- [B + 树](https://zh.wikipedia.org/wiki/B%2B%E6%A0%91)
|
||||
* BaronScbwartz, PeterZaitsev, VadimTkacbenko, 等. 高性能 MySQL\[M]. 电子工业出版社, 2013.
|
||||
* 姜承尧. MySQL 技术内幕: InnoDB 存储引擎 \[M]. 机械工业出版社, 2011.
|
||||
* [20+ 条 MySQL 性能优化的最佳经验](https://www.jfox.info/20-tiao-mysql-xing-nen-you-hua-de-zui-jia-jing-yan.html)
|
||||
* [服务端指南 数据存储篇 | MySQL(09) 分库与分表带来的分布式困境与应对之策](http://blog.720ui.com/2017/mysql\_core\_09\_multi\_db\_table2/)
|
||||
* [How to create unique row ID in sharded databases?](https://stackoverflow.com/questions/788829/how-to-create-unique-row-id-in-sharded-databases)
|
||||
* [SQL Azure Federation – Introduction](http://geekswithblogs.net/shaunxu/archive/2012/01/07/sql-azure-federation-ndash-introduction.aspx)
|
||||
* [MySQL 索引背后的数据结构及算法原理](http://blog.codinglabs.org/articles/theory-of-mysql-index.html)
|
||||
* [MySQL 性能优化神器 Explain 使用分析](https://segmentfault.com/a/1190000008131735)
|
||||
* [How Sharding Works](https://medium.com/@jeeyoungk/how-sharding-works-b4dec46b3f6)
|
||||
* [大众点评订单系统分库分表实践](https://tech.meituan.com/dianping\_order\_db\_sharding.html)
|
||||
* [B + 树](https://zh.wikipedia.org/wiki/B%2B%E6%A0%91)
|
||||
|
||||
2
notes/README.md
Normal file
2
notes/README.md
Normal file
@ -0,0 +1,2 @@
|
||||
# notes
|
||||
|
||||
226
notes/Redis.md
226
notes/Redis.md
@ -1,51 +1,49 @@
|
||||
# Redis
|
||||
<!-- GFM-TOC -->
|
||||
* [Redis](#redis)
|
||||
* [一、概述](#一概述)
|
||||
* [二、数据类型](#二数据类型)
|
||||
* [STRING](#string)
|
||||
* [LIST](#list)
|
||||
* [SET](#set)
|
||||
* [HASH](#hash)
|
||||
* [ZSET](#zset)
|
||||
* [三、数据结构](#三数据结构)
|
||||
* [字典](#字典)
|
||||
* [跳跃表](#跳跃表)
|
||||
* [四、使用场景](#四使用场景)
|
||||
* [计数器](#计数器)
|
||||
* [缓存](#缓存)
|
||||
* [查找表](#查找表)
|
||||
* [消息队列](#消息队列)
|
||||
* [会话缓存](#会话缓存)
|
||||
* [分布式锁实现](#分布式锁实现)
|
||||
* [其它](#其它)
|
||||
* [五、Redis 与 Memcached](#五redis-与-memcached)
|
||||
* [数据类型](#数据类型)
|
||||
* [数据持久化](#数据持久化)
|
||||
* [分布式](#分布式)
|
||||
* [内存管理机制](#内存管理机制)
|
||||
* [六、键的过期时间](#六键的过期时间)
|
||||
* [七、数据淘汰策略](#七数据淘汰策略)
|
||||
* [八、持久化](#八持久化)
|
||||
* [RDB 持久化](#rdb-持久化)
|
||||
* [AOF 持久化](#aof-持久化)
|
||||
* [九、事务](#九事务)
|
||||
* [十、事件](#十事件)
|
||||
* [文件事件](#文件事件)
|
||||
* [时间事件](#时间事件)
|
||||
* [事件的调度与执行](#事件的调度与执行)
|
||||
* [十一、复制](#十一复制)
|
||||
* [连接过程](#连接过程)
|
||||
* [主从链](#主从链)
|
||||
* [十二、Sentinel](#十二sentinel)
|
||||
* [十三、分片](#十三分片)
|
||||
* [十四、一个简单的论坛系统分析](#十四一个简单的论坛系统分析)
|
||||
* [文章信息](#文章信息)
|
||||
* [点赞功能](#点赞功能)
|
||||
* [对文章进行排序](#对文章进行排序)
|
||||
* [参考资料](#参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [Redis](Redis.md#redis)
|
||||
* [一、概述](Redis.md#一概述)
|
||||
* [二、数据类型](Redis.md#二数据类型)
|
||||
* [STRING](Redis.md#string)
|
||||
* [LIST](Redis.md#list)
|
||||
* [SET](Redis.md#set)
|
||||
* [HASH](Redis.md#hash)
|
||||
* [ZSET](Redis.md#zset)
|
||||
* [三、数据结构](Redis.md#三数据结构)
|
||||
* [字典](Redis.md#字典)
|
||||
* [跳跃表](Redis.md#跳跃表)
|
||||
* [四、使用场景](Redis.md#四使用场景)
|
||||
* [计数器](Redis.md#计数器)
|
||||
* [缓存](Redis.md#缓存)
|
||||
* [查找表](Redis.md#查找表)
|
||||
* [消息队列](Redis.md#消息队列)
|
||||
* [会话缓存](Redis.md#会话缓存)
|
||||
* [分布式锁实现](Redis.md#分布式锁实现)
|
||||
* [其它](Redis.md#其它)
|
||||
* [五、Redis 与 Memcached](Redis.md#五redis-与-memcached)
|
||||
* [数据类型](Redis.md#数据类型)
|
||||
* [数据持久化](Redis.md#数据持久化)
|
||||
* [分布式](Redis.md#分布式)
|
||||
* [内存管理机制](Redis.md#内存管理机制)
|
||||
* [六、键的过期时间](Redis.md#六键的过期时间)
|
||||
* [七、数据淘汰策略](Redis.md#七数据淘汰策略)
|
||||
* [八、持久化](Redis.md#八持久化)
|
||||
* [RDB 持久化](Redis.md#rdb-持久化)
|
||||
* [AOF 持久化](Redis.md#aof-持久化)
|
||||
* [九、事务](Redis.md#九事务)
|
||||
* [十、事件](Redis.md#十事件)
|
||||
* [文件事件](Redis.md#文件事件)
|
||||
* [时间事件](Redis.md#时间事件)
|
||||
* [事件的调度与执行](Redis.md#事件的调度与执行)
|
||||
* [十一、复制](Redis.md#十一复制)
|
||||
* [连接过程](Redis.md#连接过程)
|
||||
* [主从链](Redis.md#主从链)
|
||||
* [十二、Sentinel](Redis.md#十二sentinel)
|
||||
* [十三、分片](Redis.md#十三分片)
|
||||
* [十四、一个简单的论坛系统分析](Redis.md#十四一个简单的论坛系统分析)
|
||||
* [文章信息](Redis.md#文章信息)
|
||||
* [点赞功能](Redis.md#点赞功能)
|
||||
* [对文章进行排序](Redis.md#对文章进行排序)
|
||||
* [参考资料](Redis.md#参考资料)
|
||||
|
||||
## 一、概述
|
||||
|
||||
@ -57,19 +55,20 @@ Redis 支持很多特性,例如将内存中的数据持久化到硬盘中,
|
||||
|
||||
## 二、数据类型
|
||||
|
||||
| 数据类型 | 可以存储的值 | 操作 |
|
||||
| :--: | :--: | :--: |
|
||||
| STRING | 字符串、整数或者浮点数 | 对整个字符串或者字符串的其中一部分执行操作\</br\> 对整数和浮点数执行自增或者自减操作 |
|
||||
| LIST | 列表 | 从两端压入或者弹出元素 \</br\> 对单个或者多个元素进行修剪,\</br\> 只保留一个范围内的元素 |
|
||||
| SET | 无序集合 | 添加、获取、移除单个元素\</br\> 检查一个元素是否存在于集合中\</br\> 计算交集、并集、差集\</br\> 从集合里面随机获取元素 |
|
||||
| HASH | 包含键值对的无序散列表 | 添加、获取、移除单个键值对\</br\> 获取所有键值对\</br\> 检查某个键是否存在|
|
||||
| ZSET | 有序集合 | 添加、获取、删除元素\</br\> 根据分值范围或者成员来获取元素\</br\> 计算一个键的排名 |
|
||||
| 数据类型 | 可以存储的值 | 操作 |
|
||||
| :----: | :---------: | :------------------------------------------------------------------: |
|
||||
| STRING | 字符串、整数或者浮点数 | 对整个字符串或者字符串的其中一部分执行操作\</br> 对整数和浮点数执行自增或者自减操作 |
|
||||
| LIST | 列表 | 从两端压入或者弹出元素 \</br> 对单个或者多个元素进行修剪,\</br> 只保留一个范围内的元素 |
|
||||
| SET | 无序集合 | 添加、获取、移除单个元素\</br> 检查一个元素是否存在于集合中\</br> 计算交集、并集、差集\</br> 从集合里面随机获取元素 |
|
||||
| HASH | 包含键值对的无序散列表 | 添加、获取、移除单个键值对\</br> 获取所有键值对\</br> 检查某个键是否存在 |
|
||||
| ZSET | 有序集合 | 添加、获取、删除元素\</br> 根据分值范围或者成员来获取元素\</br> 计算一个键的排名 |
|
||||
|
||||
> [What Redis data structures look like](https://redislabs.com/ebook/part-1-getting-started/chapter-1-getting-to-know-redis/1-2-what-redis-data-structures-look-like/)
|
||||
|
||||
### STRING
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/6019b2db-bc3e-4408-b6d8-96025f4481d6.png" width="400"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```html
|
||||
> set hello world
|
||||
@ -84,7 +83,8 @@ OK
|
||||
|
||||
### LIST
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/fb327611-7e2b-4f2f-9f5b-38592d408f07.png" width="400"/> </div><br>
|
||||
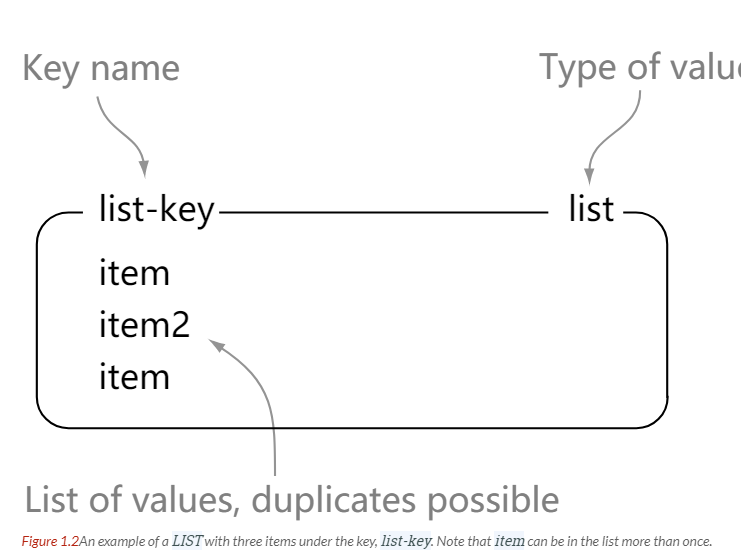\
|
||||
|
||||
|
||||
```html
|
||||
> rpush list-key item
|
||||
@ -112,7 +112,8 @@ OK
|
||||
|
||||
### SET
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/cd5fbcff-3f35-43a6-8ffa-082a93ce0f0e.png" width="400"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```html
|
||||
> sadd set-key item
|
||||
@ -146,7 +147,8 @@ OK
|
||||
|
||||
### HASH
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/7bd202a7-93d4-4f3a-a878-af68ae25539a.png" width="400"/> </div><br>
|
||||
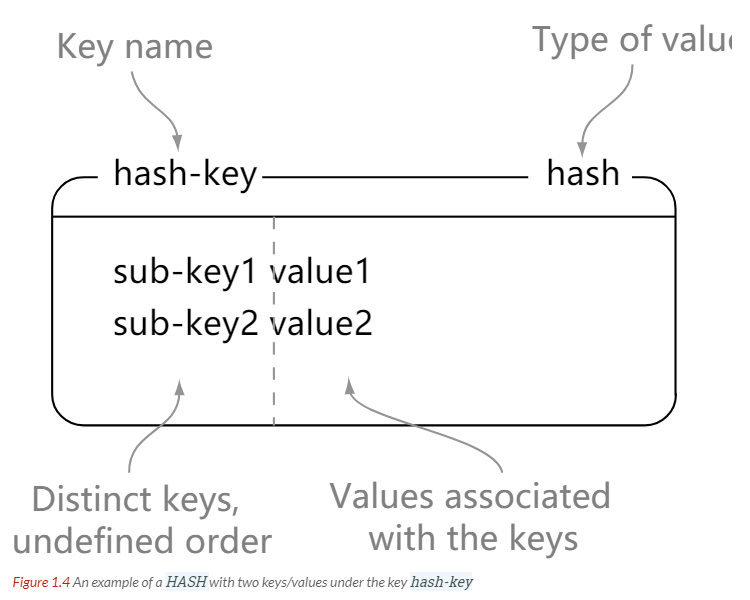\
|
||||
|
||||
|
||||
```html
|
||||
> hset hash-key sub-key1 value1
|
||||
@ -177,7 +179,8 @@ OK
|
||||
|
||||
### ZSET
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/1202b2d6-9469-4251-bd47-ca6034fb6116.png" width="400"/> </div><br>
|
||||
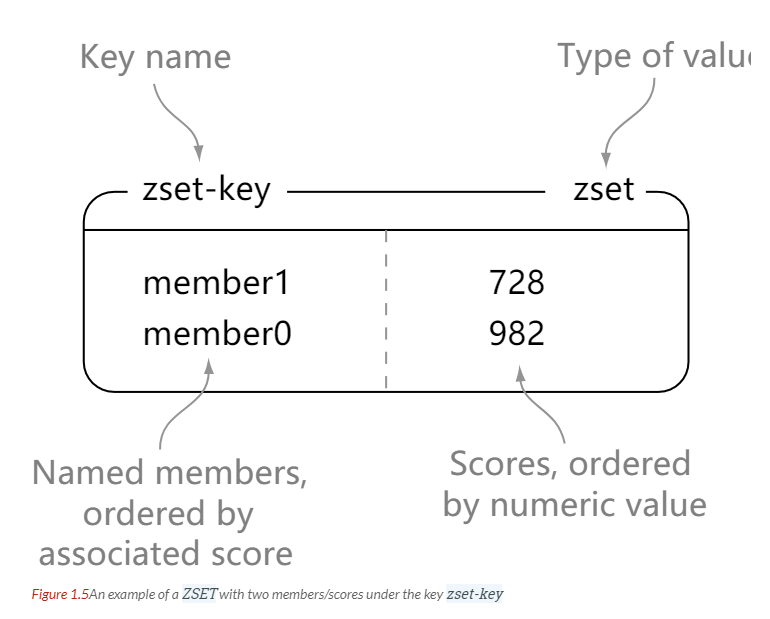\
|
||||
|
||||
|
||||
```html
|
||||
> zadd zset-key 728 member1
|
||||
@ -251,7 +254,7 @@ typedef struct dict {
|
||||
|
||||
rehash 操作不是一次性完成,而是采用渐进方式,这是为了避免一次性执行过多的 rehash 操作给服务器带来过大的负担。
|
||||
|
||||
渐进式 rehash 通过记录 dict 的 rehashidx 完成,它从 0 开始,然后每执行一次 rehash 都会递增。例如在一次 rehash 中,要把 dict[0] rehash 到 dict[1],这一次会把 dict[0] 上 table[rehashidx] 的键值对 rehash 到 dict[1] 上,dict[0] 的 table[rehashidx] 指向 null,并令 rehashidx++。
|
||||
渐进式 rehash 通过记录 dict 的 rehashidx 完成,它从 0 开始,然后每执行一次 rehash 都会递增。例如在一次 rehash 中,要把 dict\[0] rehash 到 dict\[1],这一次会把 dict\[0] 上 table\[rehashidx] 的键值对 rehash 到 dict\[1] 上,dict\[0] 的 table\[rehashidx] 指向 null,并令 rehashidx++。
|
||||
|
||||
在 rehash 期间,每次对字典执行添加、删除、查找或者更新操作时,都会执行一次渐进式 rehash。
|
||||
|
||||
@ -319,17 +322,19 @@ int dictRehash(dict *d, int n) {
|
||||
|
||||
跳跃表是基于多指针有序链表实现的,可以看成多个有序链表。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/beba612e-dc5b-4fc2-869d-0b23408ac90a.png" width="600px"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
在查找时,从上层指针开始查找,找到对应的区间之后再到下一层去查找。下图演示了查找 22 的过程。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/0ea37ee2-c224-4c79-b895-e131c6805c40.png" width="600px"/> </div><br>
|
||||
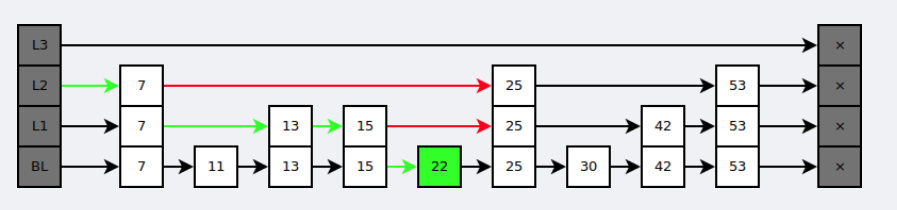\
|
||||
|
||||
|
||||
与红黑树等平衡树相比,跳跃表具有以下优点:
|
||||
|
||||
- 插入速度非常快速,因为不需要进行旋转等操作来维护平衡性;
|
||||
- 更容易实现;
|
||||
- 支持无锁操作。
|
||||
* 插入速度非常快速,因为不需要进行旋转等操作来维护平衡性;
|
||||
* 更容易实现;
|
||||
* 支持无锁操作。
|
||||
|
||||
## 四、使用场景
|
||||
|
||||
@ -393,9 +398,8 @@ Redis Cluster 实现了分布式的支持。
|
||||
|
||||
### 内存管理机制
|
||||
|
||||
- 在 Redis 中,并不是所有数据都一直存储在内存中,可以将一些很久没用的 value 交换到磁盘,而 Memcached 的数据则会一直在内存中。
|
||||
|
||||
- Memcached 将内存分割成特定长度的块来存储数据,以完全解决内存碎片的问题。但是这种方式会使得内存的利用率不高,例如块的大小为 128 bytes,只存储 100 bytes 的数据,那么剩下的 28 bytes 就浪费掉了。
|
||||
* 在 Redis 中,并不是所有数据都一直存储在内存中,可以将一些很久没用的 value 交换到磁盘,而 Memcached 的数据则会一直在内存中。
|
||||
* Memcached 将内存分割成特定长度的块来存储数据,以完全解决内存碎片的问题。但是这种方式会使得内存的利用率不高,例如块的大小为 128 bytes,只存储 100 bytes 的数据,那么剩下的 28 bytes 就浪费掉了。
|
||||
|
||||
## 六、键的过期时间
|
||||
|
||||
@ -409,14 +413,14 @@ Redis 可以为每个键设置过期时间,当键过期时,会自动删除
|
||||
|
||||
Redis 具体有 6 种淘汰策略:
|
||||
|
||||
| 策略 | 描述 |
|
||||
| :--: | :--: |
|
||||
| volatile-lru | 从已设置过期时间的数据集中挑选最近最少使用的数据淘汰 |
|
||||
| volatile-ttl | 从已设置过期时间的数据集中挑选将要过期的数据淘汰 |
|
||||
|volatile-random | 从已设置过期时间的数据集中任意选择数据淘汰 |
|
||||
| allkeys-lru | 从所有数据集中挑选最近最少使用的数据淘汰 |
|
||||
| allkeys-random | 从所有数据集中任意选择数据进行淘汰 |
|
||||
| noeviction | 禁止驱逐数据 |
|
||||
| 策略 | 描述 |
|
||||
| :-------------: | :------------------------: |
|
||||
| volatile-lru | 从已设置过期时间的数据集中挑选最近最少使用的数据淘汰 |
|
||||
| volatile-ttl | 从已设置过期时间的数据集中挑选将要过期的数据淘汰 |
|
||||
| volatile-random | 从已设置过期时间的数据集中任意选择数据淘汰 |
|
||||
| allkeys-lru | 从所有数据集中挑选最近最少使用的数据淘汰 |
|
||||
| allkeys-random | 从所有数据集中任意选择数据进行淘汰 |
|
||||
| noeviction | 禁止驱逐数据 |
|
||||
|
||||
作为内存数据库,出于对性能和内存消耗的考虑,Redis 的淘汰算法实际实现上并非针对所有 key,而是抽样一小部分并且从中选出被淘汰的 key。
|
||||
|
||||
@ -444,15 +448,15 @@ Redis 是内存型数据库,为了保证数据在断电后不会丢失,需
|
||||
|
||||
使用 AOF 持久化需要设置同步选项,从而确保写命令同步到磁盘文件上的时机。这是因为对文件进行写入并不会马上将内容同步到磁盘上,而是先存储到缓冲区,然后由操作系统决定什么时候同步到磁盘。有以下同步选项:
|
||||
|
||||
| 选项 | 同步频率 |
|
||||
| :--: | :--: |
|
||||
| always | 每个写命令都同步 |
|
||||
| everysec | 每秒同步一次 |
|
||||
| no | 让操作系统来决定何时同步 |
|
||||
| 选项 | 同步频率 |
|
||||
| :------: | :----------: |
|
||||
| always | 每个写命令都同步 |
|
||||
| everysec | 每秒同步一次 |
|
||||
| no | 让操作系统来决定何时同步 |
|
||||
|
||||
- always 选项会严重减低服务器的性能;
|
||||
- everysec 选项比较合适,可以保证系统崩溃时只会丢失一秒左右的数据,并且 Redis 每秒执行一次同步对服务器性能几乎没有任何影响;
|
||||
- no 选项并不能给服务器性能带来多大的提升,而且也会增加系统崩溃时数据丢失的数量。
|
||||
* always 选项会严重减低服务器的性能;
|
||||
* everysec 选项比较合适,可以保证系统崩溃时只会丢失一秒左右的数据,并且 Redis 每秒执行一次同步对服务器性能几乎没有任何影响;
|
||||
* no 选项并不能给服务器性能带来多大的提升,而且也会增加系统崩溃时数据丢失的数量。
|
||||
|
||||
随着服务器写请求的增多,AOF 文件会越来越大。Redis 提供了一种将 AOF 重写的特性,能够去除 AOF 文件中的冗余写命令。
|
||||
|
||||
@ -474,7 +478,8 @@ Redis 服务器是一个事件驱动程序。
|
||||
|
||||
Redis 基于 Reactor 模式开发了自己的网络事件处理器,使用 I/O 多路复用程序来同时监听多个套接字,并将到达的事件传送给文件事件分派器,分派器会根据套接字产生的事件类型调用相应的事件处理器。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/9ea86eb5-000a-4281-b948-7b567bd6f1d8.png" width=""/> </div><br>
|
||||
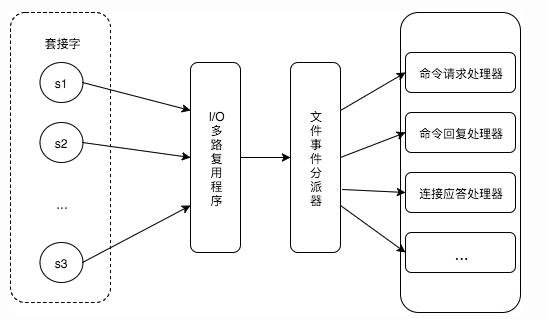\
|
||||
|
||||
|
||||
### 时间事件
|
||||
|
||||
@ -482,8 +487,8 @@ Redis 基于 Reactor 模式开发了自己的网络事件处理器,使用 I/O
|
||||
|
||||
时间事件又分为:
|
||||
|
||||
- 定时事件:是让一段程序在指定的时间之内执行一次;
|
||||
- 周期性事件:是让一段程序每隔指定时间就执行一次。
|
||||
* 定时事件:是让一段程序在指定的时间之内执行一次;
|
||||
* 周期性事件:是让一段程序每隔指定时间就执行一次。
|
||||
|
||||
Redis 将所有时间事件都放在一个无序链表中,通过遍历整个链表查找出已到达的时间事件,并调用相应的事件处理器。
|
||||
|
||||
@ -527,7 +532,8 @@ def main():
|
||||
|
||||
从事件处理的角度来看,服务器运行流程如下:
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/c0a9fa91-da2e-4892-8c9f-80206a6f7047.png" width="350"/> </div><br>
|
||||
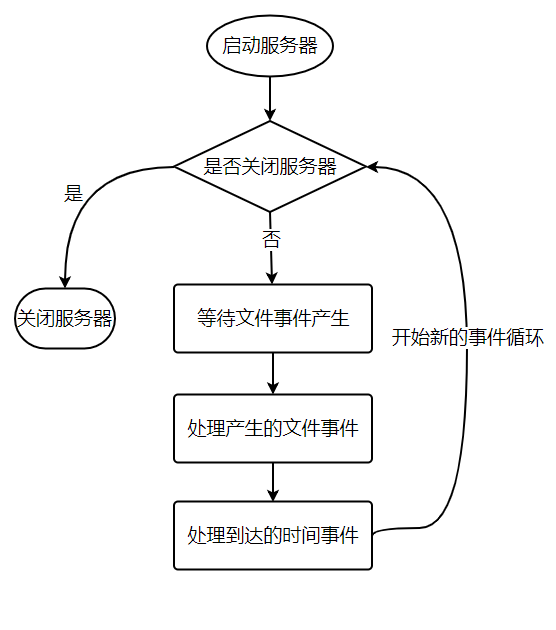\
|
||||
|
||||
|
||||
## 十一、复制
|
||||
|
||||
@ -538,16 +544,15 @@ def main():
|
||||
### 连接过程
|
||||
|
||||
1. 主服务器创建快照文件,发送给从服务器,并在发送期间使用缓冲区记录执行的写命令。快照文件发送完毕之后,开始向从服务器发送存储在缓冲区中的写命令;
|
||||
|
||||
2. 从服务器丢弃所有旧数据,载入主服务器发来的快照文件,之后从服务器开始接受主服务器发来的写命令;
|
||||
|
||||
3. 主服务器每执行一次写命令,就向从服务器发送相同的写命令。
|
||||
|
||||
### 主从链
|
||||
|
||||
随着负载不断上升,主服务器可能无法很快地更新所有从服务器,或者重新连接和重新同步从服务器将导致系统超载。为了解决这个问题,可以创建一个中间层来分担主服务器的复制工作。中间层的服务器是最上层服务器的从服务器,又是最下层服务器的主服务器。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/395a9e83-b1a1-4a1d-b170-d081e7bb5bab.png" width="600"/> </div><br>
|
||||
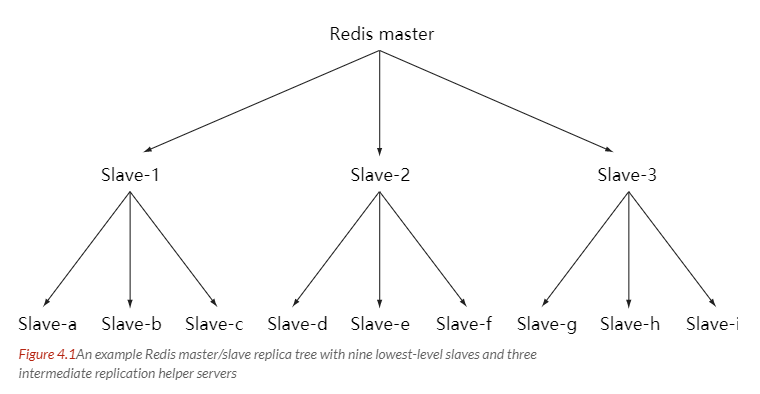\
|
||||
|
||||
|
||||
## 十二、Sentinel
|
||||
|
||||
@ -559,22 +564,22 @@ Sentinel(哨兵)可以监听集群中的服务器,并在主服务器进入
|
||||
|
||||
假设有 4 个 Redis 实例 R0,R1,R2,R3,还有很多表示用户的键 user:1,user:2,... ,有不同的方式来选择一个指定的键存储在哪个实例中。
|
||||
|
||||
- 最简单的方式是范围分片,例如用户 id 从 0\~1000 的存储到实例 R0 中,用户 id 从 1001\~2000 的存储到实例 R1 中,等等。但是这样需要维护一张映射范围表,维护操作代价很高。
|
||||
- 还有一种方式是哈希分片,使用 CRC32 哈希函数将键转换为一个数字,再对实例数量求模就能知道应该存储的实例。
|
||||
* 最简单的方式是范围分片,例如用户 id 从 0\~1000 的存储到实例 R0 中,用户 id 从 1001\~2000 的存储到实例 R1 中,等等。但是这样需要维护一张映射范围表,维护操作代价很高。
|
||||
* 还有一种方式是哈希分片,使用 CRC32 哈希函数将键转换为一个数字,再对实例数量求模就能知道应该存储的实例。
|
||||
|
||||
根据执行分片的位置,可以分为三种分片方式:
|
||||
|
||||
- 客户端分片:客户端使用一致性哈希等算法决定键应当分布到哪个节点。
|
||||
- 代理分片:将客户端请求发送到代理上,由代理转发请求到正确的节点上。
|
||||
- 服务器分片:Redis Cluster。
|
||||
* 客户端分片:客户端使用一致性哈希等算法决定键应当分布到哪个节点。
|
||||
* 代理分片:将客户端请求发送到代理上,由代理转发请求到正确的节点上。
|
||||
* 服务器分片:Redis Cluster。
|
||||
|
||||
## 十四、一个简单的论坛系统分析
|
||||
|
||||
该论坛系统功能如下:
|
||||
|
||||
- 可以发布文章;
|
||||
- 可以对文章进行点赞;
|
||||
- 在首页可以按文章的发布时间或者文章的点赞数进行排序显示。
|
||||
* 可以发布文章;
|
||||
* 可以对文章进行点赞;
|
||||
* 在首页可以按文章的发布时间或者文章的点赞数进行排序显示。
|
||||
|
||||
### 文章信息
|
||||
|
||||
@ -582,7 +587,8 @@ Sentinel(哨兵)可以监听集群中的服务器,并在主服务器进入
|
||||
|
||||
Redis 没有关系型数据库中的表这一概念来将同种类型的数据存放在一起,而是使用命名空间的方式来实现这一功能。键名的前面部分存储命名空间,后面部分的内容存储 ID,通常使用 : 来进行分隔。例如下面的 HASH 的键名为 article:92617,其中 article 为命名空间,ID 为 92617。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/7c54de21-e2ff-402e-bc42-4037de1c1592.png" width="400"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### 点赞功能
|
||||
|
||||
@ -590,21 +596,23 @@ Redis 没有关系型数据库中的表这一概念来将同种类型的数据
|
||||
|
||||
为了节约内存,规定一篇文章发布满一周之后,就不能再对它进行投票,而文章的已投票集合也会被删除,可以为文章的已投票集合设置一个一周的过期时间就能实现这个规定。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/485fdf34-ccf8-4185-97c6-17374ee719a0.png" width="400"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### 对文章进行排序
|
||||
|
||||
为了按发布时间和点赞数进行排序,可以建立一个文章发布时间的有序集合和一个文章点赞数的有序集合。(下图中的 score 就是这里所说的点赞数;下面所示的有序集合分值并不直接是时间和点赞数,而是根据时间和点赞数间接计算出来的)
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/f7d170a3-e446-4a64-ac2d-cb95028f81a8.png" width="800"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 参考资料
|
||||
|
||||
- Carlson J L. Redis in Action[J]. Media.johnwiley.com.au, 2013.
|
||||
- [黄健宏. Redis 设计与实现 [M]. 机械工业出版社, 2014.](http://redisbook.com/index.html)
|
||||
- [REDIS IN ACTION](https://redislabs.com/ebook/foreword/)
|
||||
- [Skip Lists: Done Right](http://ticki.github.io/blog/skip-lists-done-right/)
|
||||
- [论述 Redis 和 Memcached 的差异](http://www.cnblogs.com/loveincode/p/7411911.html)
|
||||
- [Redis 3.0 中文版- 分片](http://wiki.jikexueyuan.com/project/redis-guide)
|
||||
- [Redis 应用场景](http://www.scienjus.com/redis-use-case/)
|
||||
- [Using Redis as an LRU cache](https://redis.io/topics/lru-cache)
|
||||
* Carlson J L. Redis in Action\[J]. Media.johnwiley.com.au, 2013.
|
||||
* [黄健宏. Redis 设计与实现 \[M\]. 机械工业出版社, 2014.](http://redisbook.com/index.html)
|
||||
* [REDIS IN ACTION](https://redislabs.com/ebook/foreword/)
|
||||
* [Skip Lists: Done Right](http://ticki.github.io/blog/skip-lists-done-right/)
|
||||
* [论述 Redis 和 Memcached 的差异](http://www.cnblogs.com/loveincode/p/7411911.html)
|
||||
* [Redis 3.0 中文版- 分片](http://wiki.jikexueyuan.com/project/redis-guide)
|
||||
* [Redis 应用场景](http://www.scienjus.com/redis-use-case/)
|
||||
* [Using Redis as an LRU cache](https://redis.io/topics/lru-cache)
|
||||
|
||||
118
notes/Socket.md
118
notes/Socket.md
@ -1,40 +1,38 @@
|
||||
# Socket
|
||||
<!-- GFM-TOC -->
|
||||
* [Socket](#socket)
|
||||
* [一、I/O 模型](#一io-模型)
|
||||
* [阻塞式 I/O](#阻塞式-io)
|
||||
* [非阻塞式 I/O](#非阻塞式-io)
|
||||
* [I/O 复用](#io-复用)
|
||||
* [信号驱动 I/O](#信号驱动-io)
|
||||
* [异步 I/O](#异步-io)
|
||||
* [五大 I/O 模型比较](#五大-io-模型比较)
|
||||
* [二、I/O 复用](#二io-复用)
|
||||
* [select](#select)
|
||||
* [poll](#poll)
|
||||
* [比较](#比较)
|
||||
* [epoll](#epoll)
|
||||
* [工作模式](#工作模式)
|
||||
* [应用场景](#应用场景)
|
||||
* [参考资料](#参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [Socket](Socket.md#socket)
|
||||
* [一、I/O 模型](Socket.md#一io-模型)
|
||||
* [阻塞式 I/O](Socket.md#阻塞式-io)
|
||||
* [非阻塞式 I/O](Socket.md#非阻塞式-io)
|
||||
* [I/O 复用](Socket.md#io-复用)
|
||||
* [信号驱动 I/O](Socket.md#信号驱动-io)
|
||||
* [异步 I/O](Socket.md#异步-io)
|
||||
* [五大 I/O 模型比较](Socket.md#五大-io-模型比较)
|
||||
* [二、I/O 复用](Socket.md#二io-复用)
|
||||
* [select](Socket.md#select)
|
||||
* [poll](Socket.md#poll)
|
||||
* [比较](Socket.md#比较)
|
||||
* [epoll](Socket.md#epoll)
|
||||
* [工作模式](Socket.md#工作模式)
|
||||
* [应用场景](Socket.md#应用场景)
|
||||
* [参考资料](Socket.md#参考资料)
|
||||
|
||||
## 一、I/O 模型
|
||||
|
||||
一个输入操作通常包括两个阶段:
|
||||
|
||||
- 等待数据准备好
|
||||
- 从内核向进程复制数据
|
||||
* 等待数据准备好
|
||||
* 从内核向进程复制数据
|
||||
|
||||
对于一个套接字上的输入操作,第一步通常涉及等待数据从网络中到达。当所等待数据到达时,它被复制到内核中的某个缓冲区。第二步就是把数据从内核缓冲区复制到应用进程缓冲区。
|
||||
|
||||
Unix 有五种 I/O 模型:
|
||||
|
||||
- 阻塞式 I/O
|
||||
- 非阻塞式 I/O
|
||||
- I/O 复用(select 和 poll)
|
||||
- 信号驱动式 I/O(SIGIO)
|
||||
- 异步 I/O(AIO)
|
||||
* 阻塞式 I/O
|
||||
* 非阻塞式 I/O
|
||||
* I/O 复用(select 和 poll)
|
||||
* 信号驱动式 I/O(SIGIO)
|
||||
* 异步 I/O(AIO)
|
||||
|
||||
### 阻塞式 I/O
|
||||
|
||||
@ -48,7 +46,8 @@ Unix 有五种 I/O 模型:
|
||||
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *src_addr, socklen_t *addrlen);
|
||||
```
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/1492928416812_4.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### 非阻塞式 I/O
|
||||
|
||||
@ -56,7 +55,8 @@ ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *
|
||||
|
||||
由于 CPU 要处理更多的系统调用,因此这种模型的 CPU 利用率比较低。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/1492929000361_5.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### I/O 复用
|
||||
|
||||
@ -66,7 +66,8 @@ ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *
|
||||
|
||||
如果一个 Web 服务器没有 I/O 复用,那么每一个 Socket 连接都需要创建一个线程去处理。如果同时有几万个连接,那么就需要创建相同数量的线程。相比于多进程和多线程技术,I/O 复用不需要进程线程创建和切换的开销,系统开销更小。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/1492929444818_6.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### 信号驱动 I/O
|
||||
|
||||
@ -74,26 +75,29 @@ ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr *
|
||||
|
||||
相比于非阻塞式 I/O 的轮询方式,信号驱动 I/O 的 CPU 利用率更高。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/1492929553651_7.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### 异步 I/O
|
||||
|
||||
应用进程执行 aio_read 系统调用会立即返回,应用进程可以继续执行,不会被阻塞,内核会在所有操作完成之后向应用进程发送信号。
|
||||
应用进程执行 aio\_read 系统调用会立即返回,应用进程可以继续执行,不会被阻塞,内核会在所有操作完成之后向应用进程发送信号。
|
||||
|
||||
异步 I/O 与信号驱动 I/O 的区别在于,异步 I/O 的信号是通知应用进程 I/O 完成,而信号驱动 I/O 的信号是通知应用进程可以开始 I/O。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/1492930243286_8.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### 五大 I/O 模型比较
|
||||
|
||||
- 同步 I/O:将数据从内核缓冲区复制到应用进程缓冲区的阶段(第二阶段),应用进程会阻塞。
|
||||
- 异步 I/O:第二阶段应用进程不会阻塞。
|
||||
* 同步 I/O:将数据从内核缓冲区复制到应用进程缓冲区的阶段(第二阶段),应用进程会阻塞。
|
||||
* 异步 I/O:第二阶段应用进程不会阻塞。
|
||||
|
||||
同步 I/O 包括阻塞式 I/O、非阻塞式 I/O、I/O 复用和信号驱动 I/O ,它们的主要区别在第一个阶段。
|
||||
|
||||
非阻塞式 I/O 、信号驱动 I/O 和异步 I/O 在第一阶段不会阻塞。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/1492928105791_3.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 二、I/O 复用
|
||||
|
||||
@ -107,11 +111,9 @@ int select(int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct t
|
||||
|
||||
select 允许应用程序监视一组文件描述符,等待一个或者多个描述符成为就绪状态,从而完成 I/O 操作。
|
||||
|
||||
- fd_set 使用数组实现,数组大小使用 FD_SETSIZE 定义,所以只能监听少于 FD_SETSIZE 数量的描述符。有三种类型的描述符类型:readset、writeset、exceptset,分别对应读、写、异常条件的描述符集合。
|
||||
|
||||
- timeout 为超时参数,调用 select 会一直阻塞直到有描述符的事件到达或者等待的时间超过 timeout。
|
||||
|
||||
- 成功调用返回结果大于 0,出错返回结果为 -1,超时返回结果为 0。
|
||||
* fd\_set 使用数组实现,数组大小使用 FD\_SETSIZE 定义,所以只能监听少于 FD\_SETSIZE 数量的描述符。有三种类型的描述符类型:readset、writeset、exceptset,分别对应读、写、异常条件的描述符集合。
|
||||
* timeout 为超时参数,调用 select 会一直阻塞直到有描述符的事件到达或者等待的时间超过 timeout。
|
||||
* 成功调用返回结果大于 0,出错返回结果为 -1,超时返回结果为 0。
|
||||
|
||||
```c
|
||||
fd_set fd_in, fd_out;
|
||||
@ -170,7 +172,6 @@ struct pollfd {
|
||||
};
|
||||
```
|
||||
|
||||
|
||||
```c
|
||||
// The structure for two events
|
||||
struct pollfd fds[2];
|
||||
@ -209,10 +210,10 @@ else
|
||||
|
||||
select 和 poll 的功能基本相同,不过在一些实现细节上有所不同。
|
||||
|
||||
- select 会修改描述符,而 poll 不会;
|
||||
- select 的描述符类型使用数组实现,FD_SETSIZE 大小默认为 1024,因此默认只能监听少于 1024 个描述符。如果要监听更多描述符的话,需要修改 FD_SETSIZE 之后重新编译;而 poll 没有描述符数量的限制;
|
||||
- poll 提供了更多的事件类型,并且对描述符的重复利用上比 select 高。
|
||||
- 如果一个线程对某个描述符调用了 select 或者 poll,另一个线程关闭了该描述符,会导致调用结果不确定。
|
||||
* select 会修改描述符,而 poll 不会;
|
||||
* select 的描述符类型使用数组实现,FD\_SETSIZE 大小默认为 1024,因此默认只能监听少于 1024 个描述符。如果要监听更多描述符的话,需要修改 FD\_SETSIZE 之后重新编译;而 poll 没有描述符数量的限制;
|
||||
* poll 提供了更多的事件类型,并且对描述符的重复利用上比 select 高。
|
||||
* 如果一个线程对某个描述符调用了 select 或者 poll,另一个线程关闭了该描述符,会导致调用结果不确定。
|
||||
|
||||
#### 2. 速度
|
||||
|
||||
@ -230,7 +231,7 @@ int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
|
||||
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
|
||||
```
|
||||
|
||||
epoll_ctl() 用于向内核注册新的描述符或者是改变某个文件描述符的状态。已注册的描述符在内核中会被维护在一棵红黑树上,通过回调函数内核会将 I/O 准备好的描述符加入到一个链表中管理,进程调用 epoll_wait() 便可以得到事件完成的描述符。
|
||||
epoll\_ctl() 用于向内核注册新的描述符或者是改变某个文件描述符的状态。已注册的描述符在内核中会被维护在一棵红黑树上,通过回调函数内核会将 I/O 准备好的描述符加入到一个链表中管理,进程调用 epoll\_wait() 便可以得到事件完成的描述符。
|
||||
|
||||
从上面的描述可以看出,epoll 只需要将描述符从进程缓冲区向内核缓冲区拷贝一次,并且进程不需要通过轮询来获得事件完成的描述符。
|
||||
|
||||
@ -238,7 +239,7 @@ epoll 仅适用于 Linux OS。
|
||||
|
||||
epoll 比 select 和 poll 更加灵活而且没有描述符数量限制。
|
||||
|
||||
epoll 对多线程编程更有友好,一个线程调用了 epoll_wait() 另一个线程关闭了同一个描述符也不会产生像 select 和 poll 的不确定情况。
|
||||
epoll 对多线程编程更有友好,一个线程调用了 epoll\_wait() 另一个线程关闭了同一个描述符也不会产生像 select 和 poll 的不确定情况。
|
||||
|
||||
```c
|
||||
// Create the epoll descriptor. Only one is needed per app, and is used to monitor all sockets.
|
||||
@ -287,18 +288,17 @@ else
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### 工作模式
|
||||
|
||||
epoll 的描述符事件有两种触发模式:LT(level trigger)和 ET(edge trigger)。
|
||||
|
||||
#### 1. LT 模式
|
||||
|
||||
当 epoll_wait() 检测到描述符事件到达时,将此事件通知进程,进程可以不立即处理该事件,下次调用 epoll_wait() 会再次通知进程。是默认的一种模式,并且同时支持 Blocking 和 No-Blocking。
|
||||
当 epoll\_wait() 检测到描述符事件到达时,将此事件通知进程,进程可以不立即处理该事件,下次调用 epoll\_wait() 会再次通知进程。是默认的一种模式,并且同时支持 Blocking 和 No-Blocking。
|
||||
|
||||
#### 2. ET 模式
|
||||
|
||||
和 LT 模式不同的是,通知之后进程必须立即处理事件,下次再调用 epoll_wait() 时不会再得到事件到达的通知。
|
||||
和 LT 模式不同的是,通知之后进程必须立即处理事件,下次再调用 epoll\_wait() 时不会再得到事件到达的通知。
|
||||
|
||||
很大程度上减少了 epoll 事件被重复触发的次数,因此效率要比 LT 模式高。只支持 No-Blocking,以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死。
|
||||
|
||||
@ -322,16 +322,16 @@ poll 没有最大描述符数量的限制,如果平台支持并且对实时性
|
||||
|
||||
需要同时监控小于 1000 个描述符,就没有必要使用 epoll,因为这个应用场景下并不能体现 epoll 的优势。
|
||||
|
||||
需要监控的描述符状态变化多,而且都是非常短暂的,也没有必要使用 epoll。因为 epoll 中的所有描述符都存储在内核中,造成每次需要对描述符的状态改变都需要通过 epoll_ctl() 进行系统调用,频繁系统调用降低效率。并且 epoll 的描述符存储在内核,不容易调试。
|
||||
需要监控的描述符状态变化多,而且都是非常短暂的,也没有必要使用 epoll。因为 epoll 中的所有描述符都存储在内核中,造成每次需要对描述符的状态改变都需要通过 epoll\_ctl() 进行系统调用,频繁系统调用降低效率。并且 epoll 的描述符存储在内核,不容易调试。
|
||||
|
||||
## 参考资料
|
||||
|
||||
- Stevens W R, Fenner B, Rudoff A M. UNIX network programming[M]. Addison-Wesley Professional, 2004.
|
||||
- http://man7.org/linux/man-pages/man2/select.2.html
|
||||
- http://man7.org/linux/man-pages/man2/poll.2.html
|
||||
- [Boost application performance using asynchronous I/O](https://www.ibm.com/developerworks/linux/library/l-async/)
|
||||
- [Synchronous and Asynchronous I/O](https://msdn.microsoft.com/en-us/library/windows/desktop/aa365683(v=vs.85).aspx)
|
||||
- [Linux IO 模式及 select、poll、epoll 详解](https://segmentfault.com/a/1190000003063859)
|
||||
- [poll vs select vs event-based](https://daniel.haxx.se/docs/poll-vs-select.html)
|
||||
- [select / poll / epoll: practical difference for system architects](http://www.ulduzsoft.com/2014/01/select-poll-epoll-practical-difference-for-system-architects/)
|
||||
- [Browse the source code of userspace/glibc/sysdeps/unix/sysv/linux/ online](https://code.woboq.org/userspace/glibc/sysdeps/unix/sysv/linux/)
|
||||
* Stevens W R, Fenner B, Rudoff A M. UNIX network programming\[M]. Addison-Wesley Professional, 2004.
|
||||
* http://man7.org/linux/man-pages/man2/select.2.html
|
||||
* http://man7.org/linux/man-pages/man2/poll.2.html
|
||||
* [Boost application performance using asynchronous I/O](https://www.ibm.com/developerworks/linux/library/l-async/)
|
||||
* [Synchronous and Asynchronous I/O](https://msdn.microsoft.com/en-us/library/windows/desktop/aa365683\(v=vs.85\).aspx)
|
||||
* [Linux IO 模式及 select、poll、epoll 详解](https://segmentfault.com/a/1190000003063859)
|
||||
* [poll vs select vs event-based](https://daniel.haxx.se/docs/poll-vs-select.html)
|
||||
* [select / poll / epoll: practical difference for system architects](http://www.ulduzsoft.com/2014/01/select-poll-epoll-practical-difference-for-system-architects/)
|
||||
* [Browse the source code of userspace/glibc/sysdeps/unix/sysv/linux/ online](https://code.woboq.org/userspace/glibc/sysdeps/unix/sysv/linux/)
|
||||
|
||||
111
notes/代码可读性.md
111
notes/代码可读性.md
@ -1,22 +1,21 @@
|
||||
<!-- GFM-TOC -->
|
||||
* [一、可读性的重要性](#一可读性的重要性)
|
||||
* [二、用名字表达代码含义](#二用名字表达代码含义)
|
||||
* [三、名字不能带来歧义](#三名字不能带来歧义)
|
||||
* [四、良好的代码风格](#四良好的代码风格)
|
||||
* [五、为何编写注释](#五为何编写注释)
|
||||
* [六、如何编写注释](#六如何编写注释)
|
||||
* [七、提高控制流的可读性](#七提高控制流的可读性)
|
||||
* [八、拆分长表达式](#八拆分长表达式)
|
||||
* [九、变量与可读性](#九变量与可读性)
|
||||
* [十、抽取函数](#十抽取函数)
|
||||
* [十一、一次只做一件事](#十一一次只做一件事)
|
||||
* [十二、用自然语言表述代码](#十二用自然语言表述代码)
|
||||
* [十三、减少代码量](#十三减少代码量)
|
||||
* [参考资料](#参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
# 代码可读性
|
||||
|
||||
* [一、可读性的重要性](代码可读性.md#一可读性的重要性)
|
||||
* [二、用名字表达代码含义](代码可读性.md#二用名字表达代码含义)
|
||||
* [三、名字不能带来歧义](代码可读性.md#三名字不能带来歧义)
|
||||
* [四、良好的代码风格](代码可读性.md#四良好的代码风格)
|
||||
* [五、为何编写注释](代码可读性.md#五为何编写注释)
|
||||
* [六、如何编写注释](代码可读性.md#六如何编写注释)
|
||||
* [七、提高控制流的可读性](代码可读性.md#七提高控制流的可读性)
|
||||
* [八、拆分长表达式](代码可读性.md#八拆分长表达式)
|
||||
* [九、变量与可读性](代码可读性.md#九变量与可读性)
|
||||
* [十、抽取函数](代码可读性.md#十抽取函数)
|
||||
* [十一、一次只做一件事](代码可读性.md#十一一次只做一件事)
|
||||
* [十二、用自然语言表述代码](代码可读性.md#十二用自然语言表述代码)
|
||||
* [十三、减少代码量](代码可读性.md#十三减少代码量)
|
||||
* [参考资料](代码可读性.md#参考资料)
|
||||
|
||||
# 一、可读性的重要性
|
||||
## 一、可读性的重要性
|
||||
|
||||
编程有很大一部分时间是在阅读代码,不仅要阅读自己的代码,而且要阅读别人的代码。因此,可读性良好的代码能够大大提高编程效率。
|
||||
|
||||
@ -24,35 +23,35 @@
|
||||
|
||||
只有在核心领域为了效率才可以放弃可读性,否则可读性是第一位。
|
||||
|
||||
# 二、用名字表达代码含义
|
||||
## 二、用名字表达代码含义
|
||||
|
||||
一些比较有表达力的单词:
|
||||
|
||||
| 单词 | 可替代单词 |
|
||||
| :---: | --- |
|
||||
| send | deliver、dispatch、announce、distribute、route |
|
||||
| find | search、extract、locate、recover |
|
||||
| start| launch、create、begin、open|
|
||||
| make | create、set up、build、generate、compose、add、new |
|
||||
| 单词 | 可替代单词 |
|
||||
| :---: | -------------------------------------------- |
|
||||
| send | deliver、dispatch、announce、distribute、route |
|
||||
| find | search、extract、locate、recover |
|
||||
| start | launch、create、begin、open |
|
||||
| make | create、set up、build、generate、compose、add、new |
|
||||
|
||||
使用 i、j、k 作为循环迭代器的名字过于简单,user_i、member_i 这种名字会更有表达力。因为循环层次越多,代码越难理解,有表达力的迭代器名字可读性会更高。
|
||||
使用 i、j、k 作为循环迭代器的名字过于简单,user\_i、member\_i 这种名字会更有表达力。因为循环层次越多,代码越难理解,有表达力的迭代器名字可读性会更高。
|
||||
|
||||
为名字添加形容词等信息能让名字更具有表达力,但是名字也会变长。名字长短的准则是:作用域越大,名字越长。因此只有在短作用域才能使用一些简单名字。
|
||||
|
||||
# 三、名字不能带来歧义
|
||||
## 三、名字不能带来歧义
|
||||
|
||||
起完名字要思考一下别人会对这个名字有何解读,会不会误解了原本想表达的含义。
|
||||
|
||||
布尔相关的命名加上 is、can、should、has 等前缀。
|
||||
|
||||
- 用 min、max 表示数量范围;
|
||||
- 用 first、last 表示访问空间的包含范围;
|
||||
* 用 min、max 表示数量范围;
|
||||
* 用 first、last 表示访问空间的包含范围;
|
||||
* begin、end 表示访问空间的排除范围,即 end 不包含尾部。
|
||||
|
||||
- begin、end 表示访问空间的排除范围,即 end 不包含尾部。
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191209003453268.png"/> </div><br>
|
||||
|
||||
# 四、良好的代码风格
|
||||
## 四、良好的代码风格
|
||||
|
||||
适当的空行和缩进。
|
||||
|
||||
@ -66,7 +65,7 @@ int c = 111; // 注释
|
||||
|
||||
语句顺序不能随意,比如与 html 表单相关联的变量的赋值应该和表单在 html 中的顺序一致。
|
||||
|
||||
# 五、为何编写注释
|
||||
## 五、为何编写注释
|
||||
|
||||
阅读代码首先会注意到注释,如果注释没太大作用,那么就会浪费代码阅读的时间。那些能直接看出含义的代码不需要写注释,特别是不需要为每个方法都加上注释,比如那些简单的 getter 和 setter 方法,为这些方法写注释反而让代码可读性更差。
|
||||
|
||||
@ -78,14 +77,14 @@ int c = 111; // 注释
|
||||
|
||||
用 TODO 等做标记:
|
||||
|
||||
| 标记 | 用法 |
|
||||
|---|---|
|
||||
|TODO| 待做 |
|
||||
|FIXME| 待修复 |
|
||||
|HACK| 粗糙的解决方案 |
|
||||
|XXX| 危险!这里有重要的问题 |
|
||||
| 标记 | 用法 |
|
||||
| ----- | ----------- |
|
||||
| TODO | 待做 |
|
||||
| FIXME | 待修复 |
|
||||
| HACK | 粗糙的解决方案 |
|
||||
| XXX | 危险!这里有重要的问题 |
|
||||
|
||||
# 六、如何编写注释
|
||||
## 六、如何编写注释
|
||||
|
||||
尽量简洁明了:
|
||||
|
||||
@ -112,7 +111,7 @@ int add(int x, int y) {
|
||||
|
||||
使用专业名词来缩短概念上的解释,比如用设计模式名来说明代码。
|
||||
|
||||
# 七、提高控制流的可读性
|
||||
## 七、提高控制流的可读性
|
||||
|
||||
条件表达式中,左侧是变量,右侧是常数。比如下面第一个语句正确:
|
||||
|
||||
@ -129,7 +128,7 @@ do / while 的条件放在后面,不够简单明了,并且会有一些迷惑
|
||||
|
||||
在嵌套的循环中,用一些 return 语句往往能减少嵌套的层数。
|
||||
|
||||
# 八、拆分长表达式
|
||||
## 八、拆分长表达式
|
||||
|
||||
长表达式的可读性很差,可以引入一些解释变量从而拆分表达式:
|
||||
|
||||
@ -137,6 +136,7 @@ do / while 的条件放在后面,不够简单明了,并且会有一些迷惑
|
||||
if line.split(':')[0].strip() == "root":
|
||||
...
|
||||
```
|
||||
|
||||
```python
|
||||
username = line.split(':')[0].strip()
|
||||
if username == "root":
|
||||
@ -150,15 +150,16 @@ if (!a && !b) {
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
```java
|
||||
if (!(a || b)) {
|
||||
...
|
||||
}
|
||||
```
|
||||
|
||||
# 九、变量与可读性
|
||||
## 九、变量与可读性
|
||||
|
||||
**去除控制流变量** 。在循环中通过使用 break 或者 return 可以减少控制流变量的使用。
|
||||
**去除控制流变量** 。在循环中通过使用 break 或者 return 可以减少控制流变量的使用。
|
||||
|
||||
```java
|
||||
boolean done = false;
|
||||
@ -180,9 +181,9 @@ while(/* condition */) {
|
||||
}
|
||||
```
|
||||
|
||||
**减小变量作用域** 。作用域越小,越容易定位到变量所有使用的地方。
|
||||
**减小变量作用域** 。作用域越小,越容易定位到变量所有使用的地方。
|
||||
|
||||
JavaScript 可以用闭包减小作用域。以下代码中 submit_form 是函数变量,submitted 变量控制函数不会被提交两次。第一个实现中 submitted 是全局变量,第二个实现把 submitted 放到匿名函数中,从而限制了起作用域范围。
|
||||
JavaScript 可以用闭包减小作用域。以下代码中 submit\_form 是函数变量,submitted 变量控制函数不会被提交两次。第一个实现中 submitted 是全局变量,第二个实现把 submitted 放到匿名函数中,从而限制了起作用域范围。
|
||||
|
||||
```js
|
||||
submitted = false;
|
||||
@ -210,7 +211,7 @@ JavaScript 中没有用 var 声明的变量都是全局变量,而全局变量
|
||||
|
||||
变量定义的位置应当离它使用的位置最近。
|
||||
|
||||
**实例解析**
|
||||
**实例解析**
|
||||
|
||||
在一个网页中有以下文本输入字段:
|
||||
|
||||
@ -243,9 +244,9 @@ var setFirstEmptyInput = function(new_alue) {
|
||||
|
||||
以上实现有以下问题:
|
||||
|
||||
- found 可以去除;
|
||||
- elem 作用域过大;
|
||||
- 可以用 for 循环代替 while 循环;
|
||||
* found 可以去除;
|
||||
* elem 作用域过大;
|
||||
* 可以用 for 循环代替 while 循环;
|
||||
|
||||
```js
|
||||
var setFirstEmptyInput = function(new_value) {
|
||||
@ -262,7 +263,7 @@ var setFirstEmptyInput = function(new_value) {
|
||||
};
|
||||
```
|
||||
|
||||
# 十、抽取函数
|
||||
## 十、抽取函数
|
||||
|
||||
工程学就是把大问题拆分成小问题再把这些问题的解决方案放回一起。
|
||||
|
||||
@ -310,22 +311,22 @@ public int findClostElement(int[] arr) {
|
||||
|
||||
函数抽取也用于减小代码的冗余。
|
||||
|
||||
# 十一、一次只做一件事
|
||||
## 十一、一次只做一件事
|
||||
|
||||
只做一件事的代码很容易让人知道其要做的事;
|
||||
|
||||
基本流程:列出代码所做的所有任务;把每个任务拆分到不同的函数,或者不同的段落。
|
||||
|
||||
# 十二、用自然语言表述代码
|
||||
## 十二、用自然语言表述代码
|
||||
|
||||
先用自然语言书写代码逻辑,也就是伪代码,然后再写代码,这样代码逻辑会更清晰。
|
||||
|
||||
# 十三、减少代码量
|
||||
## 十三、减少代码量
|
||||
|
||||
不要过度设计,编码过程会有很多变化,过度设计的内容到最后往往是无用的。
|
||||
|
||||
多用标准库实现。
|
||||
|
||||
# 参考资料
|
||||
## 参考资料
|
||||
|
||||
- Dustin, Boswell, Trevor, 等. 编写可读代码的艺术 [M]. 机械工业出版社, 2012.
|
||||
* Dustin, Boswell, Trevor, 等. 编写可读代码的艺术 \[M]. 机械工业出版社, 2012.
|
||||
|
||||
236
notes/分布式.md
236
notes/分布式.md
@ -1,33 +1,31 @@
|
||||
# 分布式
|
||||
<!-- GFM-TOC -->
|
||||
* [分布式](#分布式)
|
||||
* [一、分布式锁](#一分布式锁)
|
||||
* [数据库的唯一索引](#数据库的唯一索引)
|
||||
* [Redis 的 SETNX 指令](#redis-的-setnx-指令)
|
||||
* [Redis 的 RedLock 算法](#redis-的-redlock-算法)
|
||||
* [Zookeeper 的有序节点](#zookeeper-的有序节点)
|
||||
* [二、分布式事务](#二分布式事务)
|
||||
* [2PC](#2pc)
|
||||
* [本地消息表](#本地消息表)
|
||||
* [三、CAP](#三cap)
|
||||
* [一致性](#一致性)
|
||||
* [可用性](#可用性)
|
||||
* [分区容忍性](#分区容忍性)
|
||||
* [权衡](#权衡)
|
||||
* [四、BASE](#四base)
|
||||
* [基本可用](#基本可用)
|
||||
* [软状态](#软状态)
|
||||
* [最终一致性](#最终一致性)
|
||||
* [五、Paxos](#五paxos)
|
||||
* [执行过程](#执行过程)
|
||||
* [约束条件](#约束条件)
|
||||
* [六、Raft](#六raft)
|
||||
* [单个 Candidate 的竞选](#单个-candidate-的竞选)
|
||||
* [多个 Candidate 竞选](#多个-candidate-竞选)
|
||||
* [数据同步](#数据同步)
|
||||
* [参考](#参考)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [分布式](分布式.md#分布式)
|
||||
* [一、分布式锁](分布式.md#一分布式锁)
|
||||
* [数据库的唯一索引](分布式.md#数据库的唯一索引)
|
||||
* [Redis 的 SETNX 指令](分布式.md#redis-的-setnx-指令)
|
||||
* [Redis 的 RedLock 算法](分布式.md#redis-的-redlock-算法)
|
||||
* [Zookeeper 的有序节点](分布式.md#zookeeper-的有序节点)
|
||||
* [二、分布式事务](分布式.md#二分布式事务)
|
||||
* [2PC](分布式.md#2pc)
|
||||
* [本地消息表](分布式.md#本地消息表)
|
||||
* [三、CAP](分布式.md#三cap)
|
||||
* [一致性](分布式.md#一致性)
|
||||
* [可用性](分布式.md#可用性)
|
||||
* [分区容忍性](分布式.md#分区容忍性)
|
||||
* [权衡](分布式.md#权衡)
|
||||
* [四、BASE](分布式.md#四base)
|
||||
* [基本可用](分布式.md#基本可用)
|
||||
* [软状态](分布式.md#软状态)
|
||||
* [最终一致性](分布式.md#最终一致性)
|
||||
* [五、Paxos](分布式.md#五paxos)
|
||||
* [执行过程](分布式.md#执行过程)
|
||||
* [约束条件](分布式.md#约束条件)
|
||||
* [六、Raft](分布式.md#六raft)
|
||||
* [单个 Candidate 的竞选](分布式.md#单个-candidate-的竞选)
|
||||
* [多个 Candidate 竞选](分布式.md#多个-candidate-竞选)
|
||||
* [数据同步](分布式.md#数据同步)
|
||||
* [参考](分布式.md#参考)
|
||||
|
||||
## 一、分布式锁
|
||||
|
||||
@ -35,8 +33,8 @@
|
||||
|
||||
阻塞锁通常使用互斥量来实现:
|
||||
|
||||
- 互斥量为 0 表示有其它进程在使用锁,此时处于锁定状态;
|
||||
- 互斥量为 1 表示未锁定状态。
|
||||
* 互斥量为 0 表示有其它进程在使用锁,此时处于锁定状态;
|
||||
* 互斥量为 1 表示未锁定状态。
|
||||
|
||||
1 和 0 可以用一个整型值表示,也可以用某个数据是否存在表示。
|
||||
|
||||
@ -46,9 +44,9 @@
|
||||
|
||||
存在以下几个问题:
|
||||
|
||||
- 锁没有失效时间,解锁失败的话其它进程无法再获得该锁;
|
||||
- 只能是非阻塞锁,插入失败直接就报错了,无法重试;
|
||||
- 不可重入,已经获得锁的进程也必须重新获取锁。
|
||||
* 锁没有失效时间,解锁失败的话其它进程无法再获得该锁;
|
||||
* 只能是非阻塞锁,插入失败直接就报错了,无法重试;
|
||||
* 不可重入,已经获得锁的进程也必须重新获取锁。
|
||||
|
||||
### Redis 的 SETNX 指令
|
||||
|
||||
@ -62,23 +60,24 @@ EXPIRE 指令可以为一个键值对设置一个过期时间,从而避免了
|
||||
|
||||
使用了多个 Redis 实例来实现分布式锁,这是为了保证在发生单点故障时仍然可用。
|
||||
|
||||
- 尝试从 N 个互相独立 Redis 实例获取锁;
|
||||
- 计算获取锁消耗的时间,只有时间小于锁的过期时间,并且从大多数(N / 2 + 1)实例上获取了锁,才认为获取锁成功;
|
||||
- 如果获取锁失败,就到每个实例上释放锁。
|
||||
* 尝试从 N 个互相独立 Redis 实例获取锁;
|
||||
* 计算获取锁消耗的时间,只有时间小于锁的过期时间,并且从大多数(N / 2 + 1)实例上获取了锁,才认为获取锁成功;
|
||||
* 如果获取锁失败,就到每个实例上释放锁。
|
||||
|
||||
### Zookeeper 的有序节点
|
||||
|
||||
#### 1. Zookeeper 抽象模型
|
||||
|
||||
Zookeeper 提供了一种树形结构的命名空间,/app1/p_1 节点的父节点为 /app1。
|
||||
Zookeeper 提供了一种树形结构的命名空间,/app1/p\_1 节点的父节点为 /app1。
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/aefa8042-15fa-4e8b-9f50-20b282a2c624.png" width="320px"> </div><br>
|
||||
|
||||
#### 2. 节点类型
|
||||
|
||||
- 永久节点:不会因为会话结束或者超时而消失;
|
||||
- 临时节点:如果会话结束或者超时就会消失;
|
||||
- 有序节点:会在节点名的后面加一个数字后缀,并且是有序的,例如生成的有序节点为 /lock/node-0000000000,它的下一个有序节点则为 /lock/node-0000000001,以此类推。
|
||||
* 永久节点:不会因为会话结束或者超时而消失;
|
||||
* 临时节点:如果会话结束或者超时就会消失;
|
||||
* 有序节点:会在节点名的后面加一个数字后缀,并且是有序的,例如生成的有序节点为 /lock/node-0000000000,它的下一个有序节点则为 /lock/node-0000000001,以此类推。
|
||||
|
||||
#### 3. 监听器
|
||||
|
||||
@ -86,10 +85,10 @@ Zookeeper 提供了一种树形结构的命名空间,/app1/p_1 节点的父节
|
||||
|
||||
#### 4. 分布式锁实现
|
||||
|
||||
- 创建一个锁目录 /lock;
|
||||
- 当一个客户端需要获取锁时,在 /lock 下创建临时的且有序的子节点;
|
||||
- 客户端获取 /lock 下的子节点列表,判断自己创建的子节点是否为当前子节点列表中序号最小的子节点,如果是则认为获得锁;否则监听自己的前一个子节点,获得子节点的变更通知后重复此步骤直至获得锁;
|
||||
- 执行业务代码,完成后,删除对应的子节点。
|
||||
* 创建一个锁目录 /lock;
|
||||
* 当一个客户端需要获取锁时,在 /lock 下创建临时的且有序的子节点;
|
||||
* 客户端获取 /lock 下的子节点列表,判断自己创建的子节点是否为当前子节点列表中序号最小的子节点,如果是则认为获得锁;否则监听自己的前一个子节点,获得子节点的变更通知后重复此步骤直至获得锁;
|
||||
* 执行业务代码,完成后,删除对应的子节点。
|
||||
|
||||
#### 5. 会话超时
|
||||
|
||||
@ -107,8 +106,8 @@ Zookeeper 提供了一种树形结构的命名空间,/app1/p_1 节点的父节
|
||||
|
||||
分布式锁和分布式事务区别:
|
||||
|
||||
- 锁问题的关键在于进程操作的互斥关系,例如多个进程同时修改账户的余额,如果没有互斥关系则会导致该账户的余额不正确。
|
||||
- 而事务问题的关键则在于事务涉及的一系列操作需要满足 ACID 特性,例如要满足原子性操作则需要这些操作要么都执行,要么都不执行。
|
||||
* 锁问题的关键在于进程操作的互斥关系,例如多个进程同时修改账户的余额,如果没有互斥关系则会导致该账户的余额不正确。
|
||||
* 而事务问题的关键则在于事务涉及的一系列操作需要满足 ACID 特性,例如要满足原子性操作则需要这些操作要么都执行,要么都不执行。
|
||||
|
||||
### 2PC
|
||||
|
||||
@ -116,35 +115,37 @@ Zookeeper 提供了一种树形结构的命名空间,/app1/p_1 节点的父节
|
||||
|
||||
#### 1. 运行过程
|
||||
|
||||
##### 1.1 准备阶段
|
||||
**1.1 准备阶段**
|
||||
|
||||
协调者询问参与者事务是否执行成功,参与者发回事务执行结果。询问可以看成一种投票,需要参与者都同意才能执行。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/44d33643-1004-43a3-b99a-4d688a08d0a1.png" width="550px"> </div><br>
|
||||
\
|
||||
|
||||
##### 1.2 提交阶段
|
||||
|
||||
**1.2 提交阶段**
|
||||
|
||||
如果事务在每个参与者上都执行成功,事务协调者发送通知让参与者提交事务;否则,协调者发送通知让参与者回滚事务。
|
||||
|
||||
需要注意的是,在准备阶段,参与者执行了事务,但是还未提交。只有在提交阶段接收到协调者发来的通知后,才进行提交或者回滚。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/d2ae9932-e2b1-4191-8ee9-e573f36d3895.png" width="550px"> </div><br>
|
||||
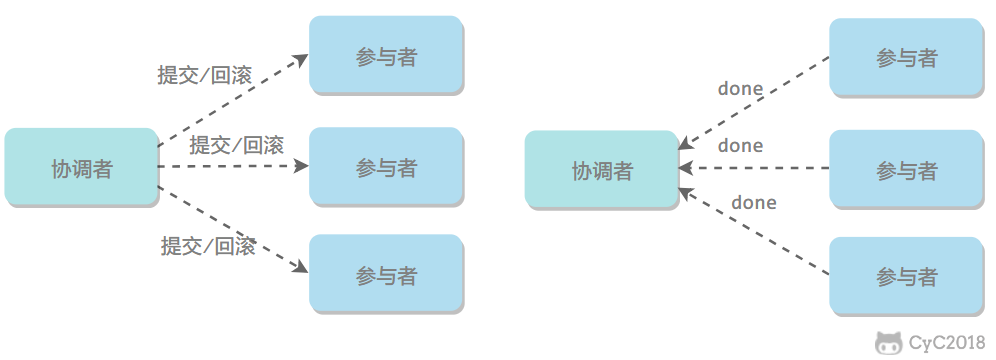\
|
||||
|
||||
|
||||
#### 2. 存在的问题
|
||||
|
||||
##### 2.1 同步阻塞
|
||||
**2.1 同步阻塞**
|
||||
|
||||
所有事务参与者在等待其它参与者响应的时候都处于同步阻塞等待状态,无法进行其它操作。
|
||||
|
||||
##### 2.2 单点问题
|
||||
**2.2 单点问题**
|
||||
|
||||
协调者在 2PC 中起到非常大的作用,发生故障将会造成很大影响。特别是在提交阶段发生故障,所有参与者会一直同步阻塞等待,无法完成其它操作。
|
||||
|
||||
##### 2.3 数据不一致
|
||||
**2.3 数据不一致**
|
||||
|
||||
在提交阶段,如果协调者只发送了部分 Commit 消息,此时网络发生异常,那么只有部分参与者接收到 Commit 消息,也就是说只有部分参与者提交了事务,使得系统数据不一致。
|
||||
|
||||
##### 2.4 太过保守
|
||||
**2.4 太过保守**
|
||||
|
||||
任意一个节点失败就会导致整个事务失败,没有完善的容错机制。
|
||||
|
||||
@ -156,14 +157,15 @@ Zookeeper 提供了一种树形结构的命名空间,/app1/p_1 节点的父节
|
||||
2. 之后将本地消息表中的消息转发到消息队列中,如果转发成功则将消息从本地消息表中删除,否则继续重新转发。
|
||||
3. 在分布式事务操作的另一方从消息队列中读取一个消息,并执行消息中的操作。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/476329d4-e2ef-4f7b-8ac9-a52a6f784600.png" width="740px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 三、CAP
|
||||
|
||||
分布式系统不可能同时满足一致性(C:Consistency)、可用性(A:Availability)和分区容忍性(P:Partition Tolerance),最多只能同时满足其中两项。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/a14268b3-b937-4ffa-a34a-4cc53071686b.jpg" width="450px"> </div><br>
|
||||
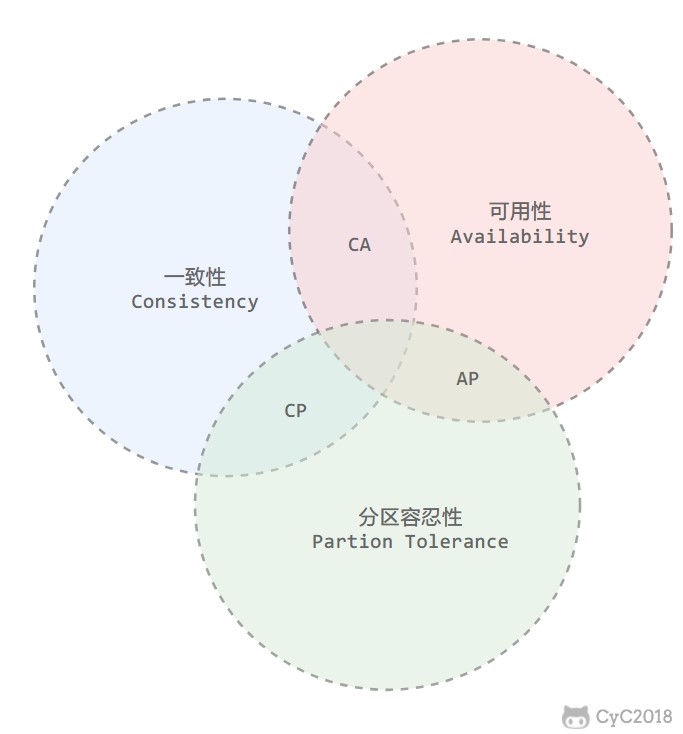\
|
||||
|
||||
|
||||
### 一致性
|
||||
|
||||
@ -189,8 +191,8 @@ Zookeeper 提供了一种树形结构的命名空间,/app1/p_1 节点的父节
|
||||
|
||||
可用性和一致性往往是冲突的,很难使它们同时满足。在多个节点之间进行数据同步时,
|
||||
|
||||
- 为了保证一致性(CP),不能访问未同步完成的节点,也就失去了部分可用性;
|
||||
- 为了保证可用性(AP),允许读取所有节点的数据,但是数据可能不一致。
|
||||
* 为了保证一致性(CP),不能访问未同步完成的节点,也就失去了部分可用性;
|
||||
* 为了保证可用性(AP),允许读取所有节点的数据,但是数据可能不一致。
|
||||
|
||||
## 四、BASE
|
||||
|
||||
@ -198,7 +200,6 @@ BASE 是基本可用(Basically Available)、软状态(Soft State)和最
|
||||
|
||||
BASE 理论是对 CAP 中一致性和可用性权衡的结果,它的核心思想是:即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。
|
||||
|
||||
|
||||
### 基本可用
|
||||
|
||||
指分布式系统在出现故障的时候,保证核心可用,允许损失部分可用性。
|
||||
@ -223,59 +224,65 @@ ACID 要求强一致性,通常运用在传统的数据库系统上。而 BASE
|
||||
|
||||
主要有三类节点:
|
||||
|
||||
- 提议者(Proposer):提议一个值;
|
||||
- 接受者(Acceptor):对每个提议进行投票;
|
||||
- 告知者(Learner):被告知投票的结果,不参与投票过程。
|
||||
* 提议者(Proposer):提议一个值;
|
||||
* 接受者(Acceptor):对每个提议进行投票;
|
||||
* 告知者(Learner):被告知投票的结果,不参与投票过程。
|
||||
|
||||
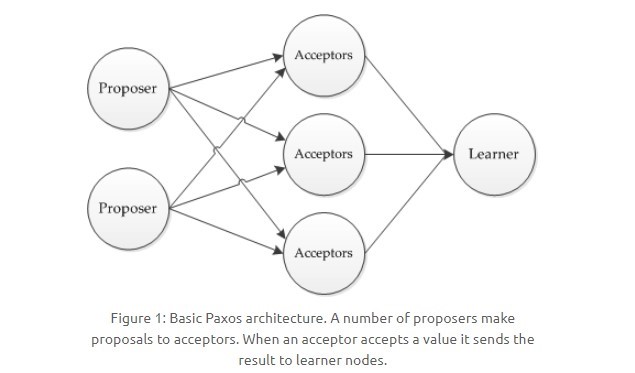\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/b988877c-0f0a-4593-916d-de2081320628.jpg"/> </div><br>
|
||||
|
||||
### 执行过程
|
||||
|
||||
规定一个提议包含两个字段:[n, v],其中 n 为序号(具有唯一性),v 为提议值。
|
||||
规定一个提议包含两个字段:\[n, v],其中 n 为序号(具有唯一性),v 为提议值。
|
||||
|
||||
#### 1. Prepare 阶段
|
||||
|
||||
下图演示了两个 Proposer 和三个 Acceptor 的系统中运行该算法的初始过程,每个 Proposer 都会向所有 Acceptor 发送 Prepare 请求。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/1a9977e4-2f5c-49a6-aec9-f3027c9f46a7.png"/> </div><br>
|
||||
\
|
||||
|
||||
当 Acceptor 接收到一个 Prepare 请求,包含的提议为 [n1, v1],并且之前还未接收过 Prepare 请求,那么发送一个 Prepare 响应,设置当前接收到的提议为 [n1, v1],并且保证以后不会再接受序号小于 n1 的提议。
|
||||
|
||||
如下图,Acceptor X 在收到 [n=2, v=8] 的 Prepare 请求时,由于之前没有接收过提议,因此就发送一个 [no previous] 的 Prepare 响应,设置当前接收到的提议为 [n=2, v=8],并且保证以后不会再接受序号小于 2 的提议。其它的 Acceptor 类似。
|
||||
当 Acceptor 接收到一个 Prepare 请求,包含的提议为 \[n1, v1],并且之前还未接收过 Prepare 请求,那么发送一个 Prepare 响应,设置当前接收到的提议为 \[n1, v1],并且保证以后不会再接受序号小于 n1 的提议。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/fb44307f-8e98-4ff7-a918-31dacfa564b4.jpg"/> </div><br>
|
||||
如下图,Acceptor X 在收到 \[n=2, v=8] 的 Prepare 请求时,由于之前没有接收过提议,因此就发送一个 \[no previous] 的 Prepare 响应,设置当前接收到的提议为 \[n=2, v=8],并且保证以后不会再接受序号小于 2 的提议。其它的 Acceptor 类似。
|
||||
|
||||
如果 Acceptor 接收到一个 Prepare 请求,包含的提议为 [n2, v2],并且之前已经接收过提议 [n1, v1]。如果 n1 \> n2,那么就丢弃该提议请求;否则,发送 Prepare 响应,该 Prepare 响应包含之前已经接收过的提议 [n1, v1],设置当前接收到的提议为 [n2, v2],并且保证以后不会再接受序号小于 n2 的提议。
|
||||
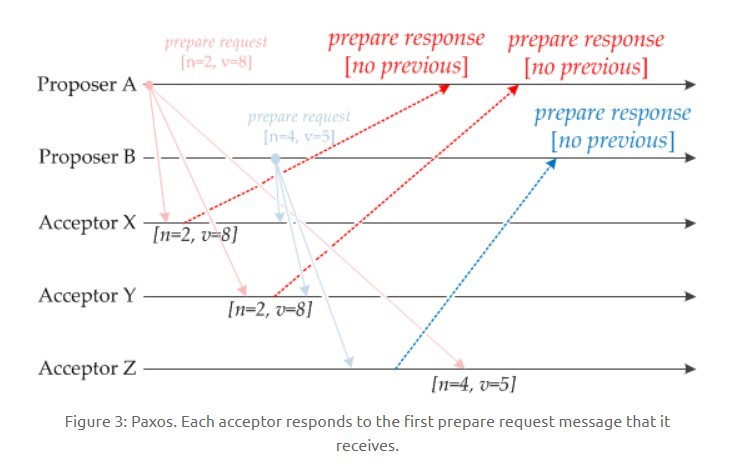\
|
||||
|
||||
如下图,Acceptor Z 收到 Proposer A 发来的 [n=2, v=8] 的 Prepare 请求,由于之前已经接收过 [n=4, v=5] 的提议,并且 n \> 2,因此就抛弃该提议请求;Acceptor X 收到 Proposer B 发来的 [n=4, v=5] 的 Prepare 请求,因为之前接收到的提议为 [n=2, v=8],并且 2 \<= 4,因此就发送 [n=2, v=8] 的 Prepare 响应,设置当前接收到的提议为 [n=4, v=5],并且保证以后不会再接受序号小于 4 的提议。Acceptor Y 类似。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/2bcc58ad-bf7f-485c-89b5-e7cafc211ce2.jpg"/> </div><br>
|
||||
如果 Acceptor 接收到一个 Prepare 请求,包含的提议为 \[n2, v2],并且之前已经接收过提议 \[n1, v1]。如果 n1 > n2,那么就丢弃该提议请求;否则,发送 Prepare 响应,该 Prepare 响应包含之前已经接收过的提议 \[n1, v1],设置当前接收到的提议为 \[n2, v2],并且保证以后不会再接受序号小于 n2 的提议。
|
||||
|
||||
如下图,Acceptor Z 收到 Proposer A 发来的 \[n=2, v=8] 的 Prepare 请求,由于之前已经接收过 \[n=4, v=5] 的提议,并且 n > 2,因此就抛弃该提议请求;Acceptor X 收到 Proposer B 发来的 \[n=4, v=5] 的 Prepare 请求,因为之前接收到的提议为 \[n=2, v=8],并且 2 <= 4,因此就发送 \[n=2, v=8] 的 Prepare 响应,设置当前接收到的提议为 \[n=4, v=5],并且保证以后不会再接受序号小于 4 的提议。Acceptor Y 类似。
|
||||
|
||||
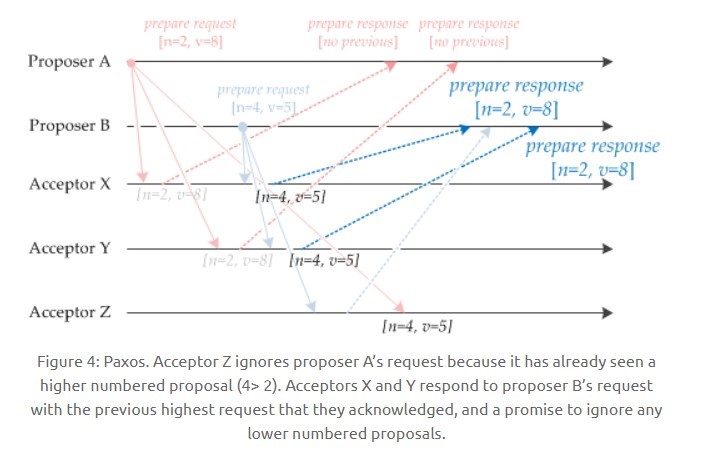\
|
||||
|
||||
|
||||
#### 2. Accept 阶段
|
||||
|
||||
当一个 Proposer 接收到超过一半 Acceptor 的 Prepare 响应时,就可以发送 Accept 请求。
|
||||
|
||||
Proposer A 接收到两个 Prepare 响应之后,就发送 [n=2, v=8] Accept 请求。该 Accept 请求会被所有 Acceptor 丢弃,因为此时所有 Acceptor 都保证不接受序号小于 4 的提议。
|
||||
Proposer A 接收到两个 Prepare 响应之后,就发送 \[n=2, v=8] Accept 请求。该 Accept 请求会被所有 Acceptor 丢弃,因为此时所有 Acceptor 都保证不接受序号小于 4 的提议。
|
||||
|
||||
Proposer B 过后也收到了两个 Prepare 响应,因此也开始发送 Accept 请求。需要注意的是,Accept 请求的 v 需要取它收到的最大提议编号对应的 v 值,也就是 8。因此它发送 [n=4, v=8] 的 Accept 请求。
|
||||
Proposer B 过后也收到了两个 Prepare 响应,因此也开始发送 Accept 请求。需要注意的是,Accept 请求的 v 需要取它收到的最大提议编号对应的 v 值,也就是 8。因此它发送 \[n=4, v=8] 的 Accept 请求。
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/9b838aee-0996-44a5-9b0f-3d1e3e2f5100.png"/> </div><br>
|
||||
|
||||
#### 3. Learn 阶段
|
||||
|
||||
Acceptor 接收到 Accept 请求时,如果序号大于等于该 Acceptor 承诺的最小序号,那么就发送 Learn 提议给所有的 Learner。当 Learner 发现有大多数的 Acceptor 接收了某个提议,那么该提议的提议值就被 Paxos 选择出来。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/bf667594-bb4b-4634-bf9b-0596a45415ba.jpg"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### 约束条件
|
||||
|
||||
#### 1\. 正确性
|
||||
#### 1. 正确性
|
||||
|
||||
指只有一个提议值会生效。
|
||||
|
||||
因为 Paxos 协议要求每个生效的提议被多数 Acceptor 接收,并且 Acceptor 不会接受两个不同的提议,因此可以保证正确性。
|
||||
|
||||
#### 2\. 可终止性
|
||||
#### 2. 可终止性
|
||||
|
||||
指最后总会有一个提议生效。
|
||||
|
||||
@ -285,66 +292,75 @@ Paxos 协议能够让 Proposer 发送的提议朝着能被大多数 Acceptor 接
|
||||
|
||||
Raft 也是分布式一致性协议,主要是用来竞选主节点。
|
||||
|
||||
- [Raft: Understandable Distributed Consensus](http://thesecretlivesofdata.com/raft)
|
||||
* [Raft: Understandable Distributed Consensus](http://thesecretlivesofdata.com/raft)
|
||||
|
||||
### 单个 Candidate 的竞选
|
||||
|
||||
有三种节点:Follower、Candidate 和 Leader。Leader 会周期性的发送心跳包给 Follower。每个 Follower 都设置了一个随机的竞选超时时间,一般为 150ms\~300ms,如果在这个时间内没有收到 Leader 的心跳包,就会变成 Candidate,进入竞选阶段。
|
||||
|
||||
- 下图展示一个分布式系统的最初阶段,此时只有 Follower 没有 Leader。Node A 等待一个随机的竞选超时时间之后,没收到 Leader 发来的心跳包,因此进入竞选阶段。
|
||||
* 下图展示一个分布式系统的最初阶段,此时只有 Follower 没有 Leader。Node A 等待一个随机的竞选超时时间之后,没收到 Leader 发来的心跳包,因此进入竞选阶段。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/111521118015898.gif"/> </div><br>
|
||||
\
|
||||
|
||||
- 此时 Node A 发送投票请求给其它所有节点。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/111521118445538.gif"/> </div><br>
|
||||
* 此时 Node A 发送投票请求给其它所有节点。
|
||||
|
||||
- 其它节点会对请求进行回复,如果超过一半的节点回复了,那么该 Candidate 就会变成 Leader。
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/111521118483039.gif"/> </div><br>
|
||||
|
||||
- 之后 Leader 会周期性地发送心跳包给 Follower,Follower 接收到心跳包,会重新开始计时。
|
||||
* 其它节点会对请求进行回复,如果超过一半的节点回复了,那么该 Candidate 就会变成 Leader。
|
||||
|
||||
\
|
||||
|
||||
|
||||
* 之后 Leader 会周期性地发送心跳包给 Follower,Follower 接收到心跳包,会重新开始计时。
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/111521118640738.gif"/> </div><br>
|
||||
|
||||
### 多个 Candidate 竞选
|
||||
|
||||
- 如果有多个 Follower 成为 Candidate,并且所获得票数相同,那么就需要重新开始投票。例如下图中 Node B 和 Node D 都获得两票,需要重新开始投票。
|
||||
* 如果有多个 Follower 成为 Candidate,并且所获得票数相同,那么就需要重新开始投票。例如下图中 Node B 和 Node D 都获得两票,需要重新开始投票。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/111521119203347.gif"/> </div><br>
|
||||
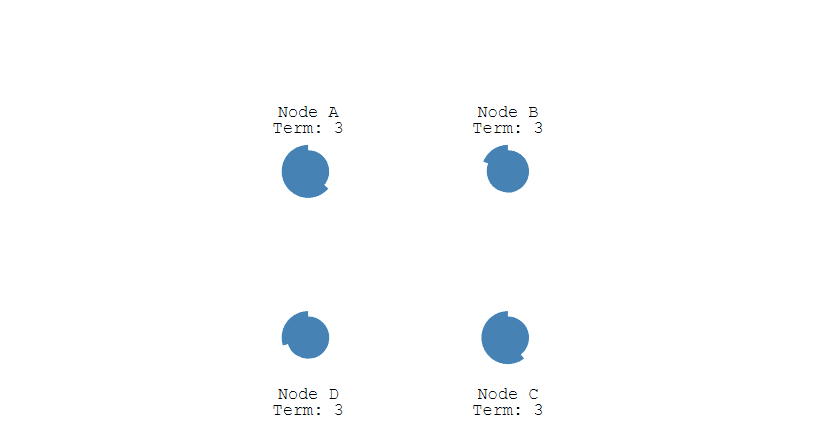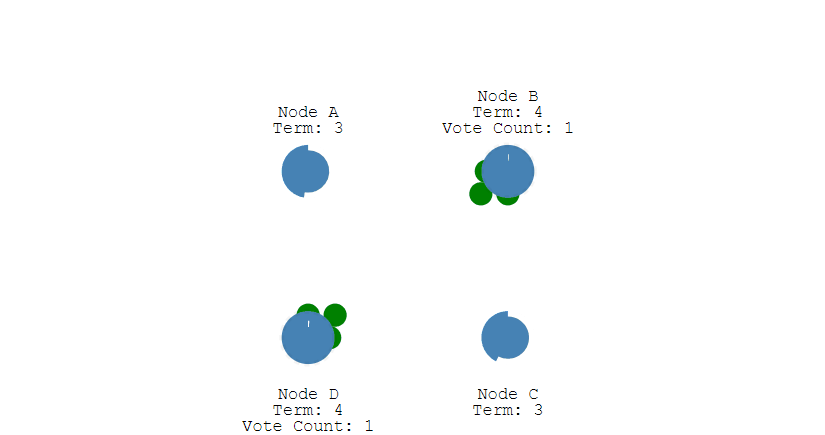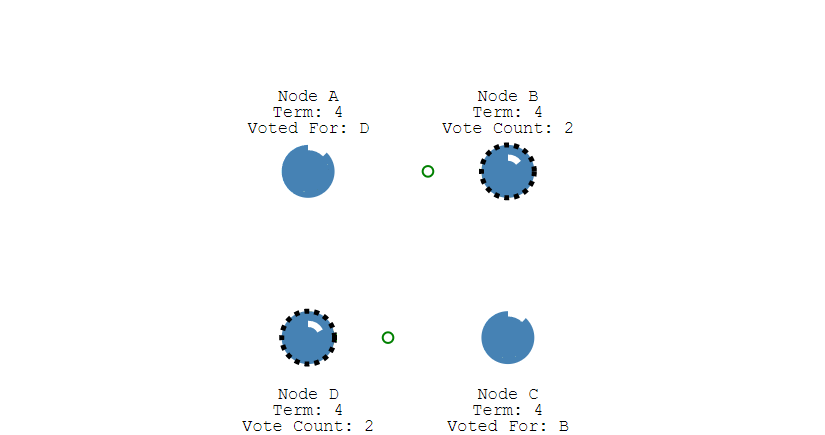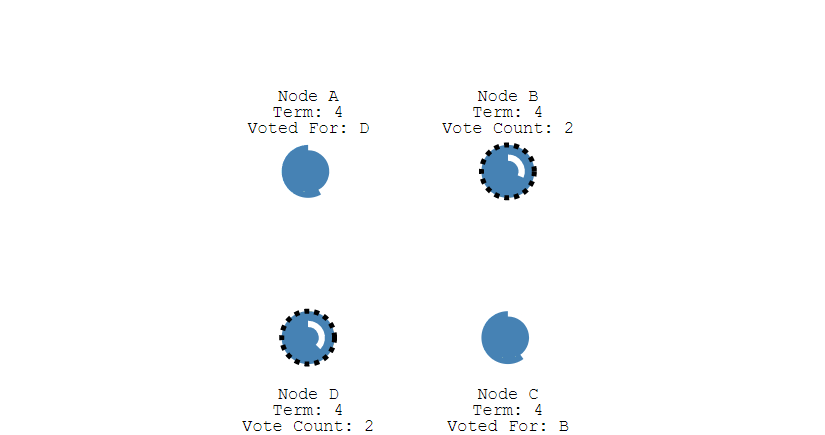\
|
||||
|
||||
- 由于每个节点设置的随机竞选超时时间不同,因此下一次再次出现多个 Candidate 并获得同样票数的概率很低。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/111521119368714.gif"/> </div><br>
|
||||
* 由于每个节点设置的随机竞选超时时间不同,因此下一次再次出现多个 Candidate 并获得同样票数的概率很低。
|
||||
|
||||
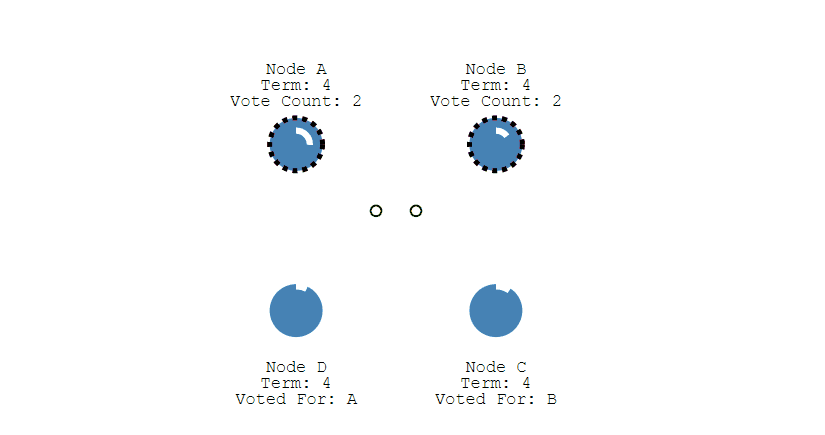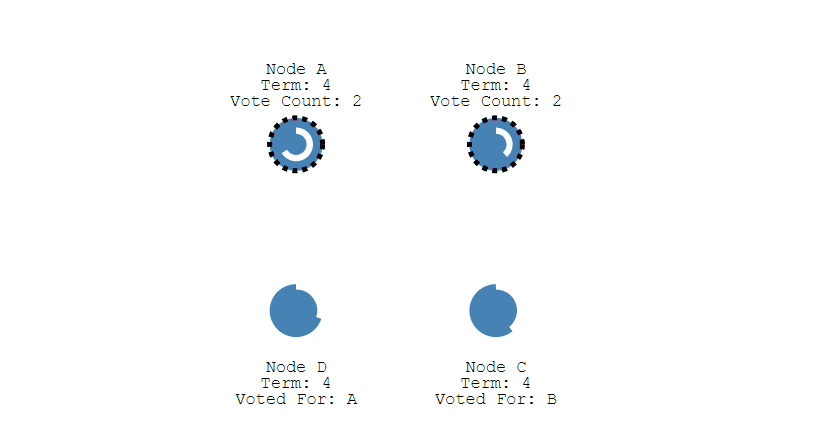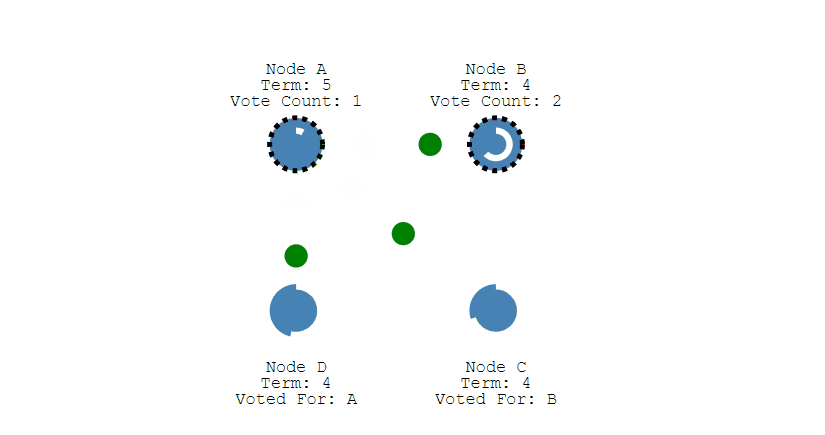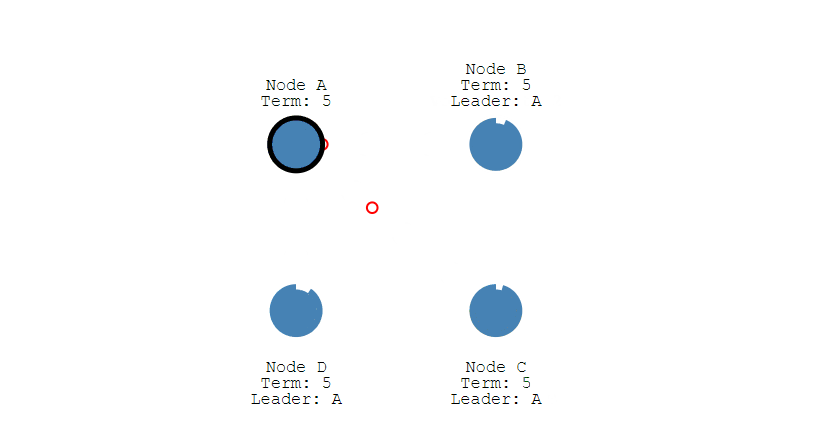\
|
||||
|
||||
|
||||
### 数据同步
|
||||
|
||||
- 来自客户端的修改都会被传入 Leader。注意该修改还未被提交,只是写入日志中。
|
||||
* 来自客户端的修改都会被传入 Leader。注意该修改还未被提交,只是写入日志中。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/71550414107576.gif"/> </div><br>
|
||||
\
|
||||
|
||||
- Leader 会把修改复制到所有 Follower。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/91550414131331.gif"/> </div><br>
|
||||
* Leader 会把修改复制到所有 Follower。
|
||||
|
||||
- Leader 会等待大多数的 Follower 也进行了修改,然后才将修改提交。
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/101550414151983.gif"/> </div><br>
|
||||
|
||||
- 此时 Leader 会通知的所有 Follower 让它们也提交修改,此时所有节点的值达成一致。
|
||||
* Leader 会等待大多数的 Follower 也进行了修改,然后才将修改提交。
|
||||
|
||||
\
|
||||
|
||||
|
||||
* 此时 Leader 会通知的所有 Follower 让它们也提交修改,此时所有节点的值达成一致。
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/111550414182638.gif"/> </div><br>
|
||||
|
||||
## 参考
|
||||
|
||||
- 倪超. 从 Paxos 到 ZooKeeper : 分布式一致性原理与实践 [M]. 电子工业出版社, 2015.
|
||||
- [Distributed locks with Redis](https://redis.io/topics/distlock)
|
||||
- [浅谈分布式锁](http://www.linkedkeeper.com/detail/blog.action?bid=1023)
|
||||
- [基于 Zookeeper 的分布式锁](http://www.dengshenyu.com/java/%E5%88%86%E5%B8%83%E5%BC%8F%E7%B3%BB%E7%BB%9F/2017/10/23/zookeeper-distributed-lock.html)
|
||||
- [聊聊分布式事务,再说说解决方案](https://www.cnblogs.com/savorboard/p/distributed-system-transaction-consistency.html)
|
||||
- [分布式系统的事务处理](https://coolshell.cn/articles/10910.html)
|
||||
- [深入理解分布式事务](https://juejin.im/entry/577c6f220a2b5800573492be)
|
||||
- [What is CAP theorem in distributed database system?](http://www.colooshiki.com/index.php/2017/04/20/what-is-cap-theorem-in-distributed-database-system/)
|
||||
- [NEAT ALGORITHMS - PAXOS](http://harry.me/blog/2014/12/27/neat-algorithms-paxos/)
|
||||
- [Paxos By Example](https://angus.nyc/2012/paxos-by-example/)
|
||||
|
||||
* 倪超. 从 Paxos 到 ZooKeeper : 分布式一致性原理与实践 \[M]. 电子工业出版社, 2015.
|
||||
* [Distributed locks with Redis](https://redis.io/topics/distlock)
|
||||
* [浅谈分布式锁](http://www.linkedkeeper.com/detail/blog.action?bid=1023)
|
||||
* [基于 Zookeeper 的分布式锁](http://www.dengshenyu.com/java/%E5%88%86%E5%B8%83%E5%BC%8F%E7%B3%BB%E7%BB%9F/2017/10/23/zookeeper-distributed-lock.html)
|
||||
* [聊聊分布式事务,再说说解决方案](https://www.cnblogs.com/savorboard/p/distributed-system-transaction-consistency.html)
|
||||
* [分布式系统的事务处理](https://coolshell.cn/articles/10910.html)
|
||||
* [深入理解分布式事务](https://juejin.im/entry/577c6f220a2b5800573492be)
|
||||
* [What is CAP theorem in distributed database system?](http://www.colooshiki.com/index.php/2017/04/20/what-is-cap-theorem-in-distributed-database-system/)
|
||||
* [NEAT ALGORITHMS - PAXOS](http://harry.me/blog/2014/12/27/neat-algorithms-paxos/)
|
||||
* [Paxos By Example](https://angus.nyc/2012/paxos-by-example/)
|
||||
|
||||
322
notes/数据库系统原理.md
322
notes/数据库系统原理.md
@ -1,47 +1,45 @@
|
||||
# 数据库系统原理
|
||||
<!-- GFM-TOC -->
|
||||
* [数据库系统原理](#数据库系统原理)
|
||||
* [一、事务](#一事务)
|
||||
* [概念](#概念)
|
||||
* [ACID](#acid)
|
||||
* [AUTOCOMMIT](#autocommit)
|
||||
* [二、并发一致性问题](#二并发一致性问题)
|
||||
* [丢失修改](#丢失修改)
|
||||
* [读脏数据](#读脏数据)
|
||||
* [不可重复读](#不可重复读)
|
||||
* [幻影读](#幻影读)
|
||||
* [三、封锁](#三封锁)
|
||||
* [封锁粒度](#封锁粒度)
|
||||
* [封锁类型](#封锁类型)
|
||||
* [封锁协议](#封锁协议)
|
||||
* [MySQL 隐式与显式锁定](#mysql-隐式与显式锁定)
|
||||
* [四、隔离级别](#四隔离级别)
|
||||
* [未提交读(READ UNCOMMITTED)](#未提交读read-uncommitted)
|
||||
* [提交读(READ COMMITTED)](#提交读read-committed)
|
||||
* [可重复读(REPEATABLE READ)](#可重复读repeatable-read)
|
||||
* [可串行化(SERIALIZABLE)](#可串行化serializable)
|
||||
* [五、多版本并发控制](#五多版本并发控制)
|
||||
* [基本思想](#基本思想)
|
||||
* [版本号](#版本号)
|
||||
* [Undo 日志](#undo-日志)
|
||||
* [ReadView](#readview)
|
||||
* [快照读与当前读](#快照读与当前读)
|
||||
* [六、Next-Key Locks](#六next-key-locks)
|
||||
* [Record Locks](#record-locks)
|
||||
* [Gap Locks](#gap-locks)
|
||||
* [Next-Key Locks](#next-key-locks)
|
||||
* [七、关系数据库设计理论](#七关系数据库设计理论)
|
||||
* [函数依赖](#函数依赖)
|
||||
* [异常](#异常)
|
||||
* [范式](#范式)
|
||||
* [八、ER 图](#八er-图)
|
||||
* [实体的三种联系](#实体的三种联系)
|
||||
* [表示出现多次的关系](#表示出现多次的关系)
|
||||
* [联系的多向性](#联系的多向性)
|
||||
* [表示子类](#表示子类)
|
||||
* [参考资料](#参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [数据库系统原理](数据库系统原理.md#数据库系统原理)
|
||||
* [一、事务](数据库系统原理.md#一事务)
|
||||
* [概念](数据库系统原理.md#概念)
|
||||
* [ACID](数据库系统原理.md#acid)
|
||||
* [AUTOCOMMIT](数据库系统原理.md#autocommit)
|
||||
* [二、并发一致性问题](数据库系统原理.md#二并发一致性问题)
|
||||
* [丢失修改](数据库系统原理.md#丢失修改)
|
||||
* [读脏数据](数据库系统原理.md#读脏数据)
|
||||
* [不可重复读](数据库系统原理.md#不可重复读)
|
||||
* [幻影读](数据库系统原理.md#幻影读)
|
||||
* [三、封锁](数据库系统原理.md#三封锁)
|
||||
* [封锁粒度](数据库系统原理.md#封锁粒度)
|
||||
* [封锁类型](数据库系统原理.md#封锁类型)
|
||||
* [封锁协议](数据库系统原理.md#封锁协议)
|
||||
* [MySQL 隐式与显式锁定](数据库系统原理.md#mysql-隐式与显式锁定)
|
||||
* [四、隔离级别](数据库系统原理.md#四隔离级别)
|
||||
* [未提交读(READ UNCOMMITTED)](数据库系统原理.md#未提交读read-uncommitted)
|
||||
* [提交读(READ COMMITTED)](数据库系统原理.md#提交读read-committed)
|
||||
* [可重复读(REPEATABLE READ)](数据库系统原理.md#可重复读repeatable-read)
|
||||
* [可串行化(SERIALIZABLE)](数据库系统原理.md#可串行化serializable)
|
||||
* [五、多版本并发控制](数据库系统原理.md#五多版本并发控制)
|
||||
* [基本思想](数据库系统原理.md#基本思想)
|
||||
* [版本号](数据库系统原理.md#版本号)
|
||||
* [Undo 日志](数据库系统原理.md#undo-日志)
|
||||
* [ReadView](数据库系统原理.md#readview)
|
||||
* [快照读与当前读](数据库系统原理.md#快照读与当前读)
|
||||
* [六、Next-Key Locks](数据库系统原理.md#六next-key-locks)
|
||||
* [Record Locks](数据库系统原理.md#record-locks)
|
||||
* [Gap Locks](数据库系统原理.md#gap-locks)
|
||||
* [Next-Key Locks](数据库系统原理.md#next-key-locks)
|
||||
* [七、关系数据库设计理论](数据库系统原理.md#七关系数据库设计理论)
|
||||
* [函数依赖](数据库系统原理.md#函数依赖)
|
||||
* [异常](数据库系统原理.md#异常)
|
||||
* [范式](数据库系统原理.md#范式)
|
||||
* [八、ER 图](数据库系统原理.md#八er-图)
|
||||
* [实体的三种联系](数据库系统原理.md#实体的三种联系)
|
||||
* [表示出现多次的关系](数据库系统原理.md#表示出现多次的关系)
|
||||
* [联系的多向性](数据库系统原理.md#联系的多向性)
|
||||
* [表示子类](数据库系统原理.md#表示子类)
|
||||
* [参考资料](数据库系统原理.md#参考资料)
|
||||
|
||||
## 一、事务
|
||||
|
||||
@ -49,7 +47,8 @@
|
||||
|
||||
事务指的是满足 ACID 特性的一组操作,可以通过 Commit 提交一个事务,也可以使用 Rollback 进行回滚。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191207222237925.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### ACID
|
||||
|
||||
@ -73,16 +72,17 @@
|
||||
|
||||
系统发生崩溃可以用重做日志(Redo Log)进行恢复,从而实现持久性。与回滚日志记录数据的逻辑修改不同,重做日志记录的是数据页的物理修改。
|
||||
|
||||
----
|
||||
***
|
||||
|
||||
事务的 ACID 特性概念简单,但不是很好理解,主要是因为这几个特性不是一种平级关系:
|
||||
|
||||
- 只有满足一致性,事务的执行结果才是正确的。
|
||||
- 在无并发的情况下,事务串行执行,隔离性一定能够满足。此时只要能满足原子性,就一定能满足一致性。
|
||||
- 在并发的情况下,多个事务并行执行,事务不仅要满足原子性,还需要满足隔离性,才能满足一致性。
|
||||
- 事务满足持久化是为了能应对系统崩溃的情况。
|
||||
* 只有满足一致性,事务的执行结果才是正确的。
|
||||
* 在无并发的情况下,事务串行执行,隔离性一定能够满足。此时只要能满足原子性,就一定能满足一致性。
|
||||
* 在并发的情况下,多个事务并行执行,事务不仅要满足原子性,还需要满足隔离性,才能满足一致性。
|
||||
* 事务满足持久化是为了能应对系统崩溃的情况。
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191207210437023.png"/> </div><br>
|
||||
|
||||
### AUTOCOMMIT
|
||||
|
||||
@ -94,29 +94,33 @@ MySQL 默认采用自动提交模式。也就是说,如果不显式使用`STAR
|
||||
|
||||
### 丢失修改
|
||||
|
||||
丢失修改指一个事务的更新操作被另外一个事务的更新操作替换。一般在现实生活中常会遇到,例如:T<sub>1</sub> 和 T<sub>2</sub> 两个事务都对一个数据进行修改,T<sub>1</sub> 先修改并提交生效,T<sub>2</sub> 随后修改,T<sub>2</sub> 的修改覆盖了 T<sub>1</sub> 的修改。
|
||||
丢失修改指一个事务的更新操作被另外一个事务的更新操作替换。一般在现实生活中常会遇到,例如:T1 和 T2 两个事务都对一个数据进行修改,T1 先修改并提交生效,T2 随后修改,T2 的修改覆盖了 T1 的修改。
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191207221744244.png"/> </div><br>
|
||||
|
||||
### 读脏数据
|
||||
|
||||
读脏数据指在不同的事务下,当前事务可以读到另外事务未提交的数据。例如:T<sub>1</sub> 修改一个数据但未提交,T<sub>2</sub> 随后读取这个数据。如果 T<sub>1</sub> 撤销了这次修改,那么 T<sub>2</sub> 读取的数据是脏数据。
|
||||
读脏数据指在不同的事务下,当前事务可以读到另外事务未提交的数据。例如:T1 修改一个数据但未提交,T2 随后读取这个数据。如果 T1 撤销了这次修改,那么 T2 读取的数据是脏数据。
|
||||
|
||||
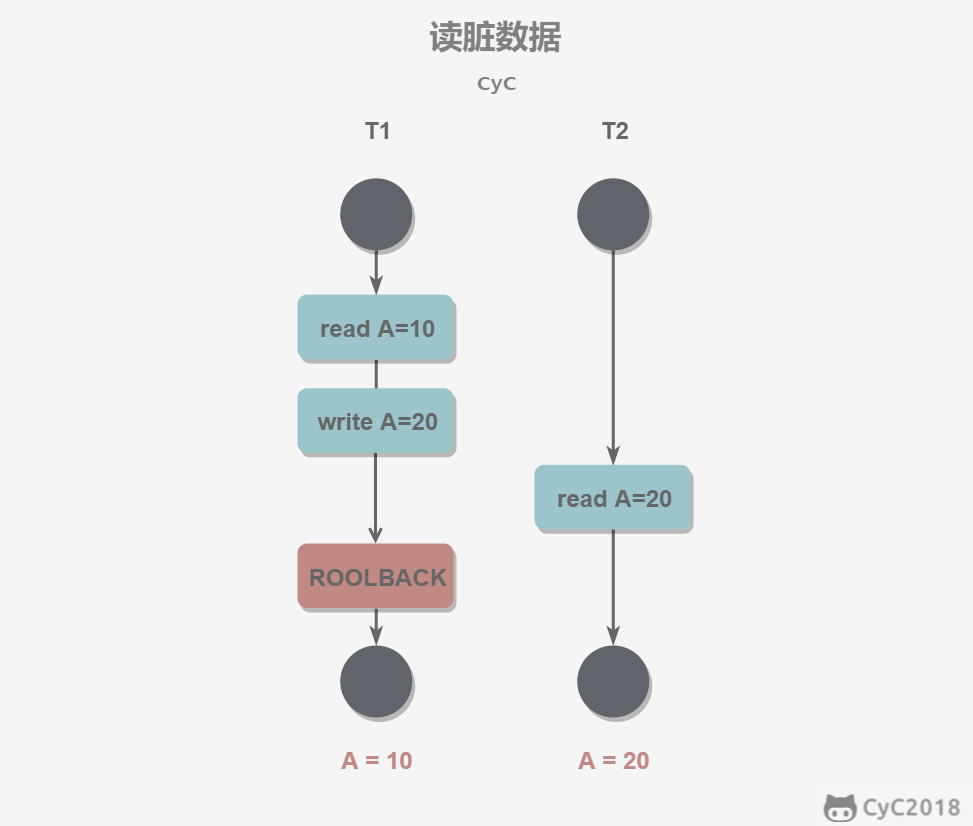\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191207221920368.png"/> </div><br>
|
||||
|
||||
### 不可重复读
|
||||
|
||||
不可重复读指在一个事务内多次读取同一数据集合。在这一事务还未结束前,另一事务也访问了该同一数据集合并做了修改,由于第二个事务的修改,第一次事务的两次读取的数据可能不一致。例如:T<sub>2</sub> 读取一个数据,T<sub>1</sub> 对该数据做了修改。如果 T<sub>2</sub> 再次读取这个数据,此时读取的结果和第一次读取的结果不同。
|
||||
不可重复读指在一个事务内多次读取同一数据集合。在这一事务还未结束前,另一事务也访问了该同一数据集合并做了修改,由于第二个事务的修改,第一次事务的两次读取的数据可能不一致。例如:T2 读取一个数据,T1 对该数据做了修改。如果 T2 再次读取这个数据,此时读取的结果和第一次读取的结果不同。
|
||||
|
||||
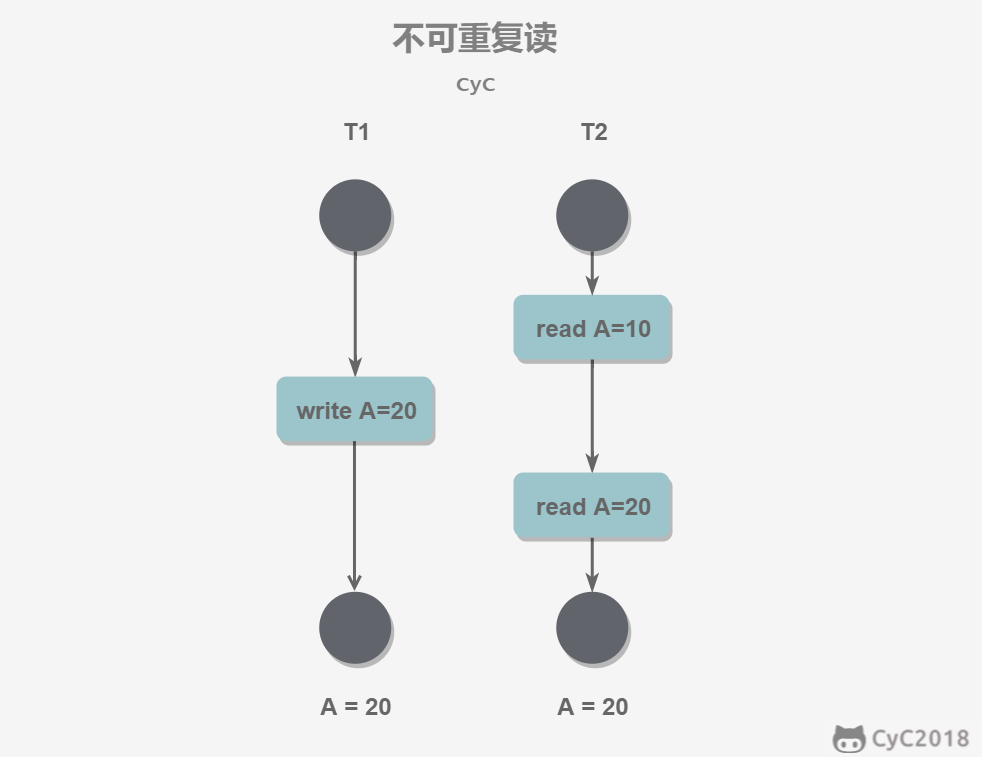\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191207222102010.png"/> </div><br>
|
||||
|
||||
### 幻影读
|
||||
|
||||
幻读本质上也属于不可重复读的情况,T<sub>1</sub> 读取某个范围的数据,T<sub>2</sub> 在这个范围内插入新的数据,T<sub>1</sub> 再次读取这个范围的数据,此时读取的结果和和第一次读取的结果不同。
|
||||
幻读本质上也属于不可重复读的情况,T1 读取某个范围的数据,T2 在这个范围内插入新的数据,T1 再次读取这个范围的数据,此时读取的结果和和第一次读取的结果不同。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191207222134306.png"/> </div><br>
|
||||
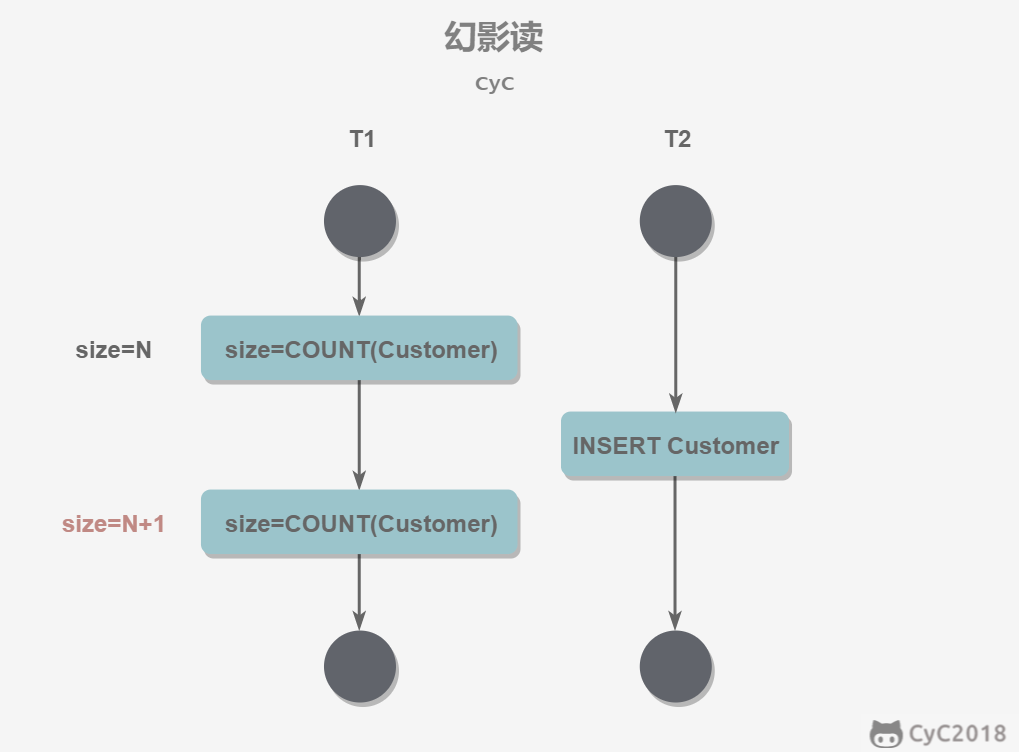\
|
||||
|
||||
----
|
||||
|
||||
***
|
||||
|
||||
产生并发不一致性问题的主要原因是破坏了事务的隔离性,解决方法是通过并发控制来保证隔离性。并发控制可以通过封锁来实现,但是封锁操作需要用户自己控制,相当复杂。数据库管理系统提供了事务的隔离级别,让用户以一种更轻松的方式处理并发一致性问题。
|
||||
|
||||
@ -132,22 +136,22 @@ MySQL 中提供了两种封锁粒度:行级锁以及表级锁。
|
||||
|
||||
在选择封锁粒度时,需要在锁开销和并发程度之间做一个权衡。
|
||||
|
||||
|
||||
### 封锁类型
|
||||
|
||||
#### 1. 读写锁
|
||||
|
||||
- 互斥锁(Exclusive),简写为 X 锁,又称写锁。
|
||||
- 共享锁(Shared),简写为 S 锁,又称读锁。
|
||||
* 互斥锁(Exclusive),简写为 X 锁,又称写锁。
|
||||
* 共享锁(Shared),简写为 S 锁,又称读锁。
|
||||
|
||||
有以下两个规定:
|
||||
|
||||
- 一个事务对数据对象 A 加了 X 锁,就可以对 A 进行读取和更新。加锁期间其它事务不能对 A 加任何锁。
|
||||
- 一个事务对数据对象 A 加了 S 锁,可以对 A 进行读取操作,但是不能进行更新操作。加锁期间其它事务能对 A 加 S 锁,但是不能加 X 锁。
|
||||
* 一个事务对数据对象 A 加了 X 锁,就可以对 A 进行读取和更新。加锁期间其它事务不能对 A 加任何锁。
|
||||
* 一个事务对数据对象 A 加了 S 锁,可以对 A 进行读取操作,但是不能进行更新操作。加锁期间其它事务能对 A 加 S 锁,但是不能加 X 锁。
|
||||
|
||||
锁的兼容关系如下:
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191207213523777.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
#### 2. 意向锁
|
||||
|
||||
@ -157,47 +161,51 @@ MySQL 中提供了两种封锁粒度:行级锁以及表级锁。
|
||||
|
||||
意向锁在原来的 X/S 锁之上引入了 IX/IS,IX/IS 都是表锁,用来表示一个事务想要在表中的某个数据行上加 X 锁或 S 锁。有以下两个规定:
|
||||
|
||||
- 一个事务在获得某个数据行对象的 S 锁之前,必须先获得表的 IS 锁或者更强的锁;
|
||||
- 一个事务在获得某个数据行对象的 X 锁之前,必须先获得表的 IX 锁。
|
||||
* 一个事务在获得某个数据行对象的 S 锁之前,必须先获得表的 IS 锁或者更强的锁;
|
||||
* 一个事务在获得某个数据行对象的 X 锁之前,必须先获得表的 IX 锁。
|
||||
|
||||
通过引入意向锁,事务 T 想要对表 A 加 X 锁,只需要先检测是否有其它事务对表 A 加了 X/IX/S/IS 锁,如果加了就表示有其它事务正在使用这个表或者表中某一行的锁,因此事务 T 加 X 锁失败。
|
||||
|
||||
各种锁的兼容关系如下:
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191207214442687.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
解释如下:
|
||||
|
||||
- 任意 IS/IX 锁之间都是兼容的,因为它们只表示想要对表加锁,而不是真正加锁;
|
||||
- 这里兼容关系针对的是表级锁,而表级的 IX 锁和行级的 X 锁兼容,两个事务可以对两个数据行加 X 锁。(事务 T<sub>1</sub> 想要对数据行 R<sub>1</sub> 加 X 锁,事务 T<sub>2</sub> 想要对同一个表的数据行 R<sub>2</sub> 加 X 锁,两个事务都需要对该表加 IX 锁,但是 IX 锁是兼容的,并且 IX 锁与行级的 X 锁也是兼容的,因此两个事务都能加锁成功,对同一个表中的两个数据行做修改。)
|
||||
* 任意 IS/IX 锁之间都是兼容的,因为它们只表示想要对表加锁,而不是真正加锁;
|
||||
* 这里兼容关系针对的是表级锁,而表级的 IX 锁和行级的 X 锁兼容,两个事务可以对两个数据行加 X 锁。(事务 T1 想要对数据行 R1 加 X 锁,事务 T2 想要对同一个表的数据行 R2 加 X 锁,两个事务都需要对该表加 IX 锁,但是 IX 锁是兼容的,并且 IX 锁与行级的 X 锁也是兼容的,因此两个事务都能加锁成功,对同一个表中的两个数据行做修改。)
|
||||
|
||||
### 封锁协议
|
||||
|
||||
#### 1. 三级封锁协议
|
||||
|
||||
**一级封锁协议**
|
||||
**一级封锁协议**
|
||||
|
||||
事务 T 要修改数据 A 时必须加 X 锁,直到 T 结束才释放锁。
|
||||
|
||||
可以解决丢失修改问题,因为不能同时有两个事务对同一个数据进行修改,那么事务的修改就不会被覆盖。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191207220440451.png"/> </div><br>
|
||||
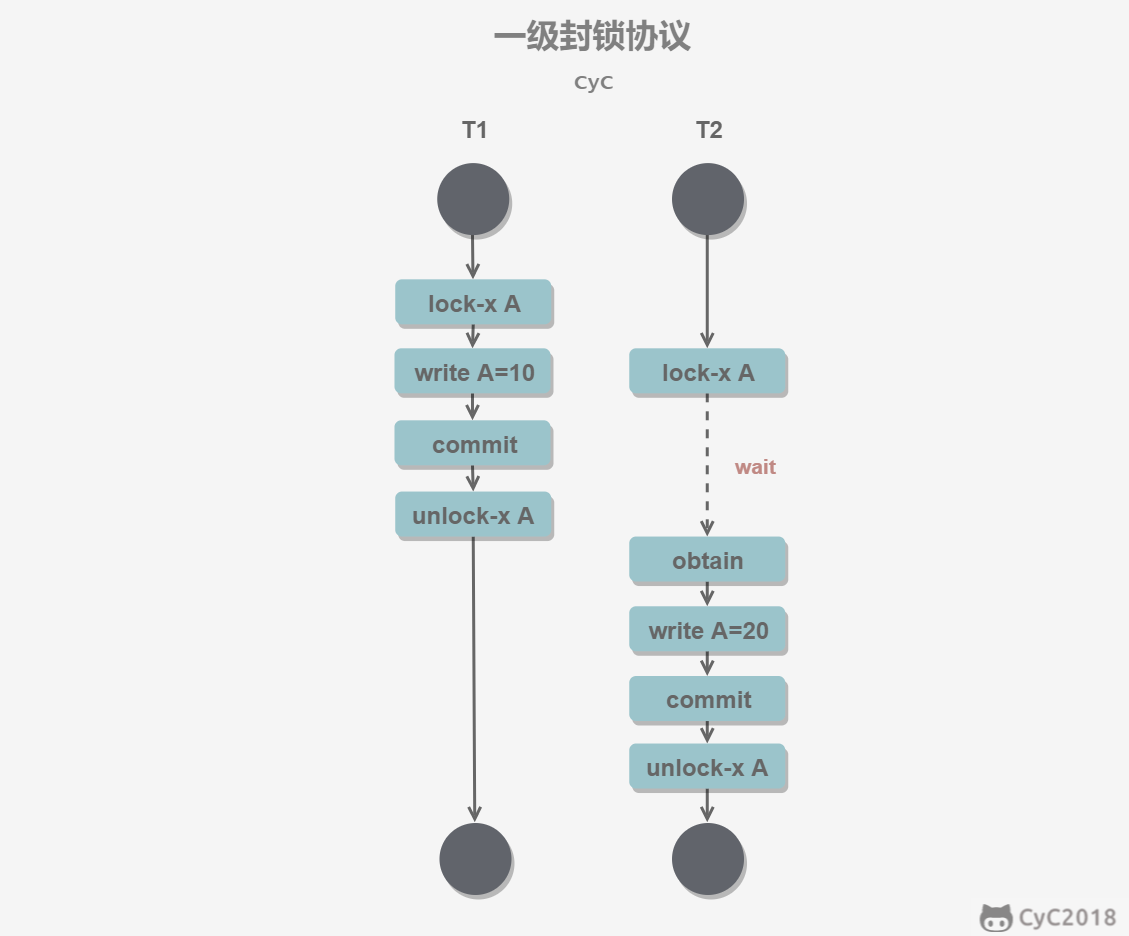\
|
||||
|
||||
**二级封锁协议**
|
||||
|
||||
**二级封锁协议**
|
||||
|
||||
在一级的基础上,要求读取数据 A 时必须加 S 锁,读取完马上释放 S 锁。
|
||||
|
||||
可以解决读脏数据问题,因为如果一个事务在对数据 A 进行修改,根据 1 级封锁协议,会加 X 锁,那么就不能再加 S 锁了,也就是不会读入数据。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191207220831843.png"/> </div><br>
|
||||
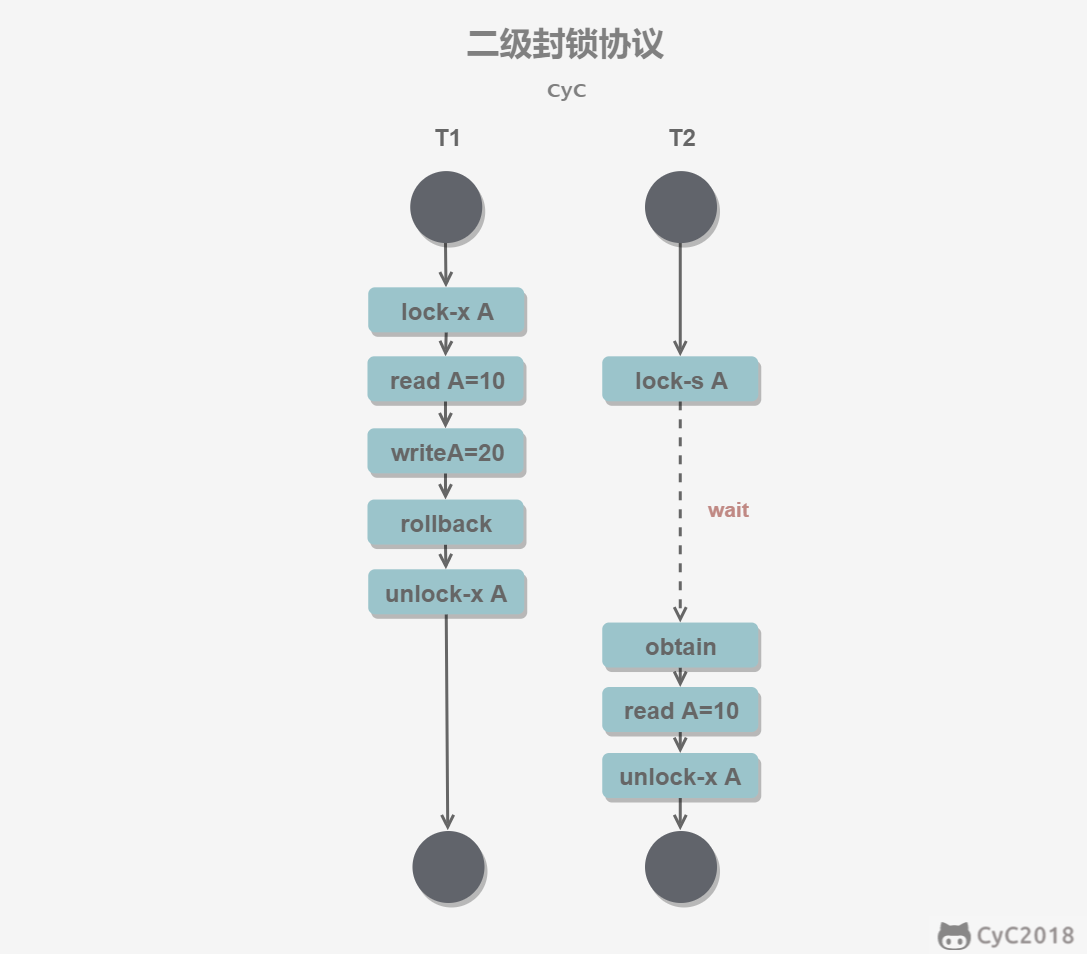\
|
||||
|
||||
**三级封锁协议**
|
||||
|
||||
**三级封锁协议**
|
||||
|
||||
在二级的基础上,要求读取数据 A 时必须加 S 锁,直到事务结束了才能释放 S 锁。
|
||||
|
||||
可以解决不可重复读的问题,因为读 A 时,其它事务不能对 A 加 X 锁,从而避免了在读的期间数据发生改变。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191207221313819.png"/> </div><br>
|
||||
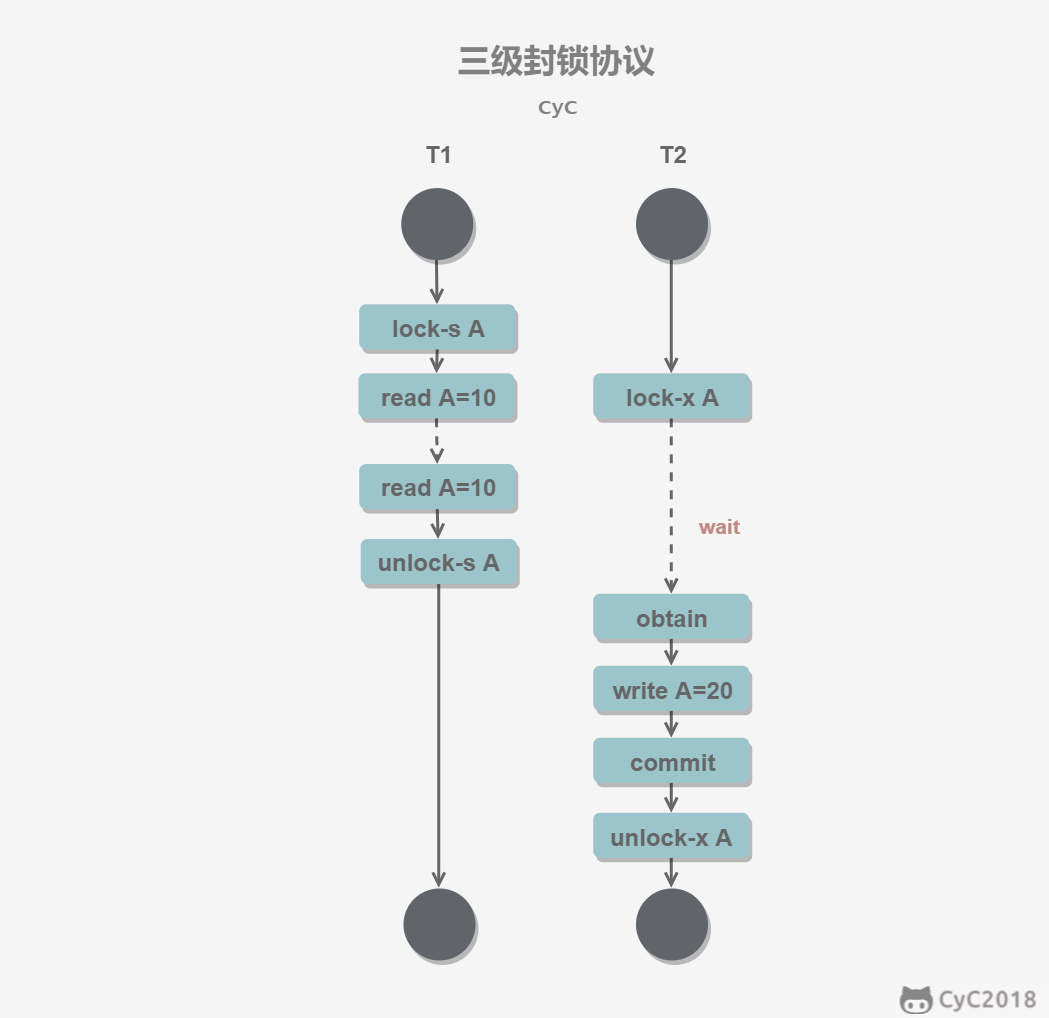\
|
||||
|
||||
|
||||
#### 2. 两段锁协议
|
||||
|
||||
@ -248,9 +256,10 @@ SELECT ... FOR UPDATE;
|
||||
|
||||
该隔离级别需要加锁实现,因为要使用加锁机制保证同一时间只有一个事务执行,也就是保证事务串行执行。
|
||||
|
||||
----
|
||||
***
|
||||
|
||||
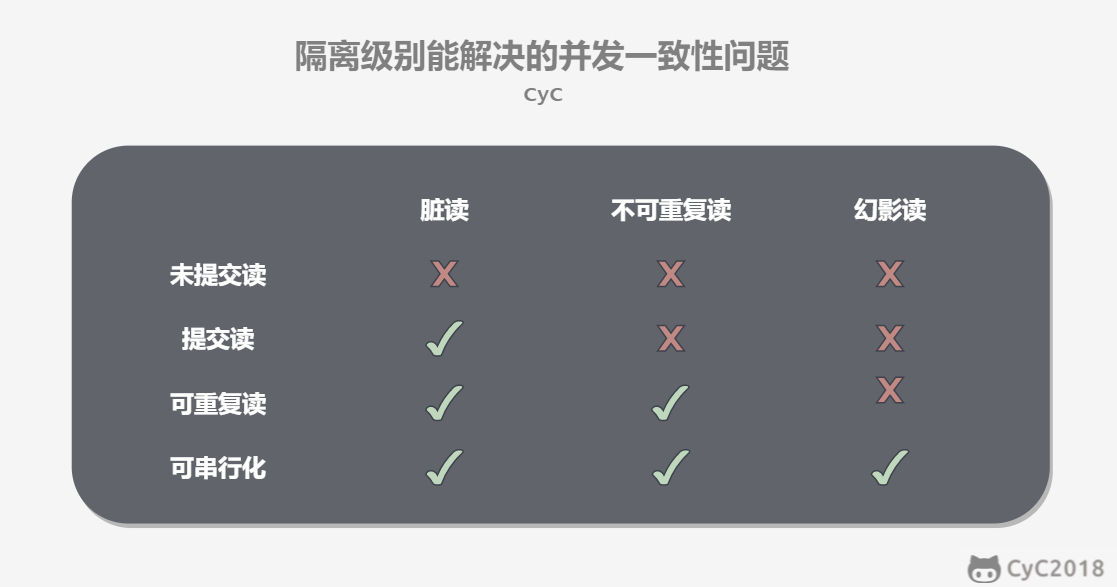\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191207223400787.png"/> </div><br>
|
||||
|
||||
## 五、多版本并发控制
|
||||
|
||||
@ -266,12 +275,12 @@ SELECT ... FOR UPDATE;
|
||||
|
||||
### 版本号
|
||||
|
||||
- 系统版本号 SYS_ID:是一个递增的数字,每开始一个新的事务,系统版本号就会自动递增。
|
||||
- 事务版本号 TRX_ID :事务开始时的系统版本号。
|
||||
* 系统版本号 SYS\_ID:是一个递增的数字,每开始一个新的事务,系统版本号就会自动递增。
|
||||
* 事务版本号 TRX\_ID :事务开始时的系统版本号。
|
||||
|
||||
### Undo 日志
|
||||
|
||||
MVCC 的多版本指的是多个版本的快照,快照存储在 Undo 日志中,该日志通过回滚指针 ROLL_PTR 把一个数据行的所有快照连接起来。
|
||||
MVCC 的多版本指的是多个版本的快照,快照存储在 Undo 日志中,该日志通过回滚指针 ROLL\_PTR 把一个数据行的所有快照连接起来。
|
||||
|
||||
例如在 MySQL 创建一个表 t,包含主键 id 和一个字段 x。我们先插入一个数据行,然后对该数据行执行两次更新操作。
|
||||
|
||||
@ -281,28 +290,29 @@ UPDATE t SET x="b" WHERE id=1;
|
||||
UPDATE t SET x="c" WHERE id=1;
|
||||
```
|
||||
|
||||
因为没有使用 `START TRANSACTION` 将上面的操作当成一个事务来执行,根据 MySQL 的 AUTOCOMMIT 机制,每个操作都会被当成一个事务来执行,所以上面的操作总共涉及到三个事务。快照中除了记录事务版本号 TRX_ID 和操作之外,还记录了一个 bit 的 DEL 字段,用于标记是否被删除。
|
||||
因为没有使用 `START TRANSACTION` 将上面的操作当成一个事务来执行,根据 MySQL 的 AUTOCOMMIT 机制,每个操作都会被当成一个事务来执行,所以上面的操作总共涉及到三个事务。快照中除了记录事务版本号 TRX\_ID 和操作之外,还记录了一个 bit 的 DEL 字段,用于标记是否被删除。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208164808217.png"/> </div><br>
|
||||
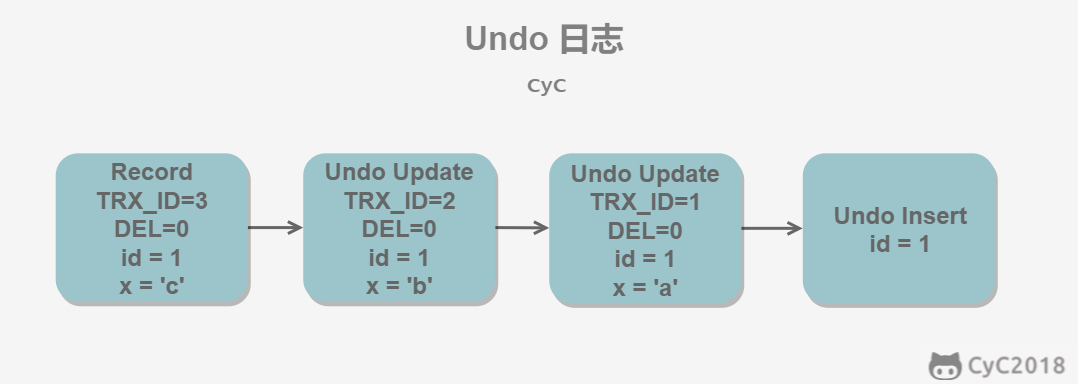\
|
||||
|
||||
INSERT、UPDATE、DELETE 操作会创建一个日志,并将事务版本号 TRX_ID 写入。DELETE 可以看成是一个特殊的 UPDATE,还会额外将 DEL 字段设置为 1。
|
||||
|
||||
INSERT、UPDATE、DELETE 操作会创建一个日志,并将事务版本号 TRX\_ID 写入。DELETE 可以看成是一个特殊的 UPDATE,还会额外将 DEL 字段设置为 1。
|
||||
|
||||
### ReadView
|
||||
|
||||
MVCC 维护了一个 ReadView 结构,主要包含了当前系统未提交的事务列表 TRX_IDs {TRX_ID_1, TRX_ID_2, ...},还有该列表的最小值 TRX_ID_MIN 和 TRX_ID_MAX。
|
||||
MVCC 维护了一个 ReadView 结构,主要包含了当前系统未提交的事务列表 TRX\_IDs {TRX\_ID\_1, TRX\_ID\_2, ...},还有该列表的最小值 TRX\_ID\_MIN 和 TRX\_ID\_MAX。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208171445674.png"/> </div><br>
|
||||
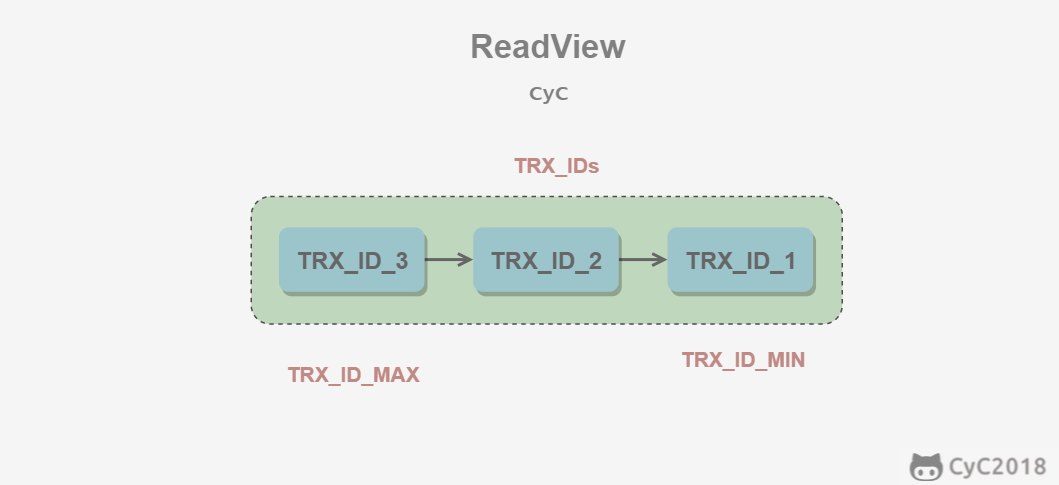\
|
||||
|
||||
在进行 SELECT 操作时,根据数据行快照的 TRX_ID 与 TRX_ID_MIN 和 TRX_ID_MAX 之间的关系,从而判断数据行快照是否可以使用:
|
||||
|
||||
- TRX_ID \< TRX_ID_MIN,表示该数据行快照时在当前所有未提交事务之前进行更改的,因此可以使用。
|
||||
在进行 SELECT 操作时,根据数据行快照的 TRX\_ID 与 TRX\_ID\_MIN 和 TRX\_ID\_MAX 之间的关系,从而判断数据行快照是否可以使用:
|
||||
|
||||
- TRX_ID \> TRX_ID_MAX,表示该数据行快照是在事务启动之后被更改的,因此不可使用。
|
||||
- TRX_ID_MIN \<= TRX_ID \<= TRX_ID_MAX,需要根据隔离级别再进行判断:
|
||||
- 提交读:如果 TRX_ID 在 TRX_IDs 列表中,表示该数据行快照对应的事务还未提交,则该快照不可使用。否则表示已经提交,可以使用。
|
||||
- 可重复读:都不可以使用。因为如果可以使用的话,那么其它事务也可以读到这个数据行快照并进行修改,那么当前事务再去读这个数据行得到的值就会发生改变,也就是出现了不可重复读问题。
|
||||
* TRX\_ID < TRX\_ID\_MIN,表示该数据行快照时在当前所有未提交事务之前进行更改的,因此可以使用。
|
||||
* TRX\_ID > TRX\_ID\_MAX,表示该数据行快照是在事务启动之后被更改的,因此不可使用。
|
||||
* TRX\_ID\_MIN <= TRX\_ID <= TRX\_ID\_MAX,需要根据隔离级别再进行判断:
|
||||
* 提交读:如果 TRX\_ID 在 TRX\_IDs 列表中,表示该数据行快照对应的事务还未提交,则该快照不可使用。否则表示已经提交,可以使用。
|
||||
* 可重复读:都不可以使用。因为如果可以使用的话,那么其它事务也可以读到这个数据行快照并进行修改,那么当前事务再去读这个数据行得到的值就会发生改变,也就是出现了不可重复读问题。
|
||||
|
||||
在数据行快照不可使用的情况下,需要沿着 Undo Log 的回滚指针 ROLL_PTR 找到下一个快照,再进行上面的判断。
|
||||
在数据行快照不可使用的情况下,需要沿着 Undo Log 的回滚指针 ROLL\_PTR 找到下一个快照,再进行上面的判断。
|
||||
|
||||
### 快照读与当前读
|
||||
|
||||
@ -367,31 +377,31 @@ SELECT c FROM t WHERE c BETWEEN 10 and 20 FOR UPDATE;
|
||||
|
||||
### 函数依赖
|
||||
|
||||
记 A-\>B 表示 A 函数决定 B,也可以说 B 函数依赖于 A。
|
||||
记 A->B 表示 A 函数决定 B,也可以说 B 函数依赖于 A。
|
||||
|
||||
如果 {A1,A2,... ,An} 是关系的一个或多个属性的集合,该集合函数决定了关系的其它所有属性并且是最小的,那么该集合就称为键码。
|
||||
|
||||
对于 A-\>B,如果能找到 A 的真子集 A',使得 A'-\> B,那么 A-\>B 就是部分函数依赖,否则就是完全函数依赖。
|
||||
对于 A->B,如果能找到 A 的真子集 A',使得 A'-> B,那么 A->B 就是部分函数依赖,否则就是完全函数依赖。
|
||||
|
||||
对于 A-\>B,B-\>C,则 A-\>C 是一个传递函数依赖。
|
||||
对于 A->B,B->C,则 A->C 是一个传递函数依赖。
|
||||
|
||||
### 异常
|
||||
|
||||
以下的学生课程关系的函数依赖为 {Sno, Cname} -\> {Sname, Sdept, Mname, Grade},键码为 {Sno, Cname}。也就是说,确定学生和课程之后,就能确定其它信息。
|
||||
以下的学生课程关系的函数依赖为 {Sno, Cname} -> {Sname, Sdept, Mname, Grade},键码为 {Sno, Cname}。也就是说,确定学生和课程之后,就能确定其它信息。
|
||||
|
||||
| Sno | Sname | Sdept | Mname | Cname | Grade |
|
||||
| :---: | :---: | :---: | :---: | :---: |:---:|
|
||||
| 1 | 学生-1 | 学院-1 | 院长-1 | 课程-1 | 90 |
|
||||
| 2 | 学生-2 | 学院-2 | 院长-2 | 课程-2 | 80 |
|
||||
| 2 | 学生-2 | 学院-2 | 院长-2 | 课程-1 | 100 |
|
||||
| 3 | 学生-3 | 学院-2 | 院长-2 | 课程-2 | 95 |
|
||||
| :-: | :---: | :---: | :---: | :---: | :---: |
|
||||
| 1 | 学生-1 | 学院-1 | 院长-1 | 课程-1 | 90 |
|
||||
| 2 | 学生-2 | 学院-2 | 院长-2 | 课程-2 | 80 |
|
||||
| 2 | 学生-2 | 学院-2 | 院长-2 | 课程-1 | 100 |
|
||||
| 3 | 学生-3 | 学院-2 | 院长-2 | 课程-2 | 95 |
|
||||
|
||||
不符合范式的关系,会产生很多异常,主要有以下四种异常:
|
||||
|
||||
- 冗余数据:例如 `学生-2` 出现了两次。
|
||||
- 修改异常:修改了一个记录中的信息,但是另一个记录中相同的信息却没有被修改。
|
||||
- 删除异常:删除一个信息,那么也会丢失其它信息。例如删除了 `课程-1` 需要删除第一行和第三行,那么 `学生-1` 的信息就会丢失。
|
||||
- 插入异常:例如想要插入一个学生的信息,如果这个学生还没选课,那么就无法插入。
|
||||
* 冗余数据:例如 `学生-2` 出现了两次。
|
||||
* 修改异常:修改了一个记录中的信息,但是另一个记录中相同的信息却没有被修改。
|
||||
* 删除异常:删除一个信息,那么也会丢失其它信息。例如删除了 `课程-1` 需要删除第一行和第三行,那么 `学生-1` 的信息就会丢失。
|
||||
* 插入异常:例如想要插入一个学生的信息,如果这个学生还没选课,那么就无法插入。
|
||||
|
||||
### 范式
|
||||
|
||||
@ -409,52 +419,54 @@ SELECT c FROM t WHERE c BETWEEN 10 and 20 FOR UPDATE;
|
||||
|
||||
可以通过分解来满足。
|
||||
|
||||
<font size=4> **分解前** </font><br>
|
||||
**分解前**\
|
||||
|
||||
|
||||
| Sno | Sname | Sdept | Mname | Cname | Grade |
|
||||
| :---: | :---: | :---: | :---: | :---: |:---:|
|
||||
| 1 | 学生-1 | 学院-1 | 院长-1 | 课程-1 | 90 |
|
||||
| 2 | 学生-2 | 学院-2 | 院长-2 | 课程-2 | 80 |
|
||||
| 2 | 学生-2 | 学院-2 | 院长-2 | 课程-1 | 100 |
|
||||
| 3 | 学生-3 | 学院-2 | 院长-2 | 课程-2 | 95 |
|
||||
| :-: | :---: | :---: | :---: | :---: | :---: |
|
||||
| 1 | 学生-1 | 学院-1 | 院长-1 | 课程-1 | 90 |
|
||||
| 2 | 学生-2 | 学院-2 | 院长-2 | 课程-2 | 80 |
|
||||
| 2 | 学生-2 | 学院-2 | 院长-2 | 课程-1 | 100 |
|
||||
| 3 | 学生-3 | 学院-2 | 院长-2 | 课程-2 | 95 |
|
||||
|
||||
以上学生课程关系中,{Sno, Cname} 为键码,有如下函数依赖:
|
||||
|
||||
- Sno -\> Sname, Sdept
|
||||
- Sdept -\> Mname
|
||||
- Sno, Cname-\> Grade
|
||||
* Sno -> Sname, Sdept
|
||||
* Sdept -> Mname
|
||||
* Sno, Cname-> Grade
|
||||
|
||||
Grade 完全函数依赖于键码,它没有任何冗余数据,每个学生的每门课都有特定的成绩。
|
||||
|
||||
Sname, Sdept 和 Mname 都部分依赖于键码,当一个学生选修了多门课时,这些数据就会出现多次,造成大量冗余数据。
|
||||
|
||||
<font size=4> **分解后** </font><br>
|
||||
**分解后**\
|
||||
|
||||
|
||||
关系-1
|
||||
|
||||
| Sno | Sname | Sdept | Mname |
|
||||
| :---: | :---: | :---: | :---: |
|
||||
| 1 | 学生-1 | 学院-1 | 院长-1 |
|
||||
| 2 | 学生-2 | 学院-2 | 院长-2 |
|
||||
| 3 | 学生-3 | 学院-2 | 院长-2 |
|
||||
| :-: | :---: | :---: | :---: |
|
||||
| 1 | 学生-1 | 学院-1 | 院长-1 |
|
||||
| 2 | 学生-2 | 学院-2 | 院长-2 |
|
||||
| 3 | 学生-3 | 学院-2 | 院长-2 |
|
||||
|
||||
有以下函数依赖:
|
||||
|
||||
- Sno -\> Sname, Sdept
|
||||
- Sdept -\> Mname
|
||||
* Sno -> Sname, Sdept
|
||||
* Sdept -> Mname
|
||||
|
||||
关系-2
|
||||
|
||||
| Sno | Cname | Grade |
|
||||
| :---: | :---: |:---:|
|
||||
| 1 | 课程-1 | 90 |
|
||||
| 2 | 课程-2 | 80 |
|
||||
| 2 | 课程-1 | 100 |
|
||||
| 3 | 课程-2 | 95 |
|
||||
| :-: | :---: | :---: |
|
||||
| 1 | 课程-1 | 90 |
|
||||
| 2 | 课程-2 | 80 |
|
||||
| 2 | 课程-1 | 100 |
|
||||
| 3 | 课程-2 | 95 |
|
||||
|
||||
有以下函数依赖:
|
||||
|
||||
- Sno, Cname -\> Grade
|
||||
* Sno, Cname -> Grade
|
||||
|
||||
#### 3. 第三范式 (3NF)
|
||||
|
||||
@ -462,24 +474,24 @@ Sname, Sdept 和 Mname 都部分依赖于键码,当一个学生选修了多门
|
||||
|
||||
上面的 关系-1 中存在以下传递函数依赖:
|
||||
|
||||
- Sno -\> Sdept -\> Mname
|
||||
* Sno -> Sdept -> Mname
|
||||
|
||||
可以进行以下分解:
|
||||
|
||||
关系-11
|
||||
|
||||
| Sno | Sname | Sdept |
|
||||
| :---: | :---: | :---: |
|
||||
| 1 | 学生-1 | 学院-1 |
|
||||
| 2 | 学生-2 | 学院-2 |
|
||||
| 3 | 学生-3 | 学院-2 |
|
||||
| :-: | :---: | :---: |
|
||||
| 1 | 学生-1 | 学院-1 |
|
||||
| 2 | 学生-2 | 学院-2 |
|
||||
| 3 | 学生-3 | 学院-2 |
|
||||
|
||||
关系-12
|
||||
|
||||
| Sdept | Mname |
|
||||
| :---: | :---: |
|
||||
| 学院-1 | 院长-1 |
|
||||
| 学院-2 | 院长-2 |
|
||||
| 学院-1 | 院长-1 |
|
||||
| 学院-2 | 院长-2 |
|
||||
|
||||
## 八、ER 图
|
||||
|
||||
@ -491,13 +503,14 @@ Entity-Relationship,有三个组成部分:实体、属性、联系。
|
||||
|
||||
包含一对一,一对多,多对多三种。
|
||||
|
||||
- 如果 A 到 B 是一对多关系,那么画个带箭头的线段指向 B;
|
||||
- 如果是一对一,画两个带箭头的线段;
|
||||
- 如果是多对多,画两个不带箭头的线段。
|
||||
* 如果 A 到 B 是一对多关系,那么画个带箭头的线段指向 B;
|
||||
* 如果是一对一,画两个带箭头的线段;
|
||||
* 如果是多对多,画两个不带箭头的线段。
|
||||
|
||||
下图的 Course 和 Student 是一对多的关系。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/1d28ad05-39e5-49a2-a6a1-a6f496adba6a.png" width="380px"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### 表示出现多次的关系
|
||||
|
||||
@ -505,31 +518,34 @@ Entity-Relationship,有三个组成部分:实体、属性、联系。
|
||||
|
||||
下图表示一个课程的先修关系,先修关系出现两个 Course 实体,第一个是先修课程,后一个是后修课程,因此需要用两条线来表示这种关系。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/ac929ea3-daca-40ec-9e95-4b2fa6678243.png" width="250px"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### 联系的多向性
|
||||
|
||||
虽然老师可以开设多门课,并且可以教授多名学生,但是对于特定的学生和课程,只有一个老师教授,这就构成了一个三元联系。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/5bb1b38a-527e-4802-a385-267dadbd30ba.png" width="350px"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### 表示子类
|
||||
|
||||
用一个三角形和两条线来连接类和子类,与子类有关的属性和联系都连到子类上,而与父类和子类都有关的连到父类上。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/14389ea4-8d96-4e96-9f76-564ca3324c1e.png" width="450px"/> </div><br>
|
||||
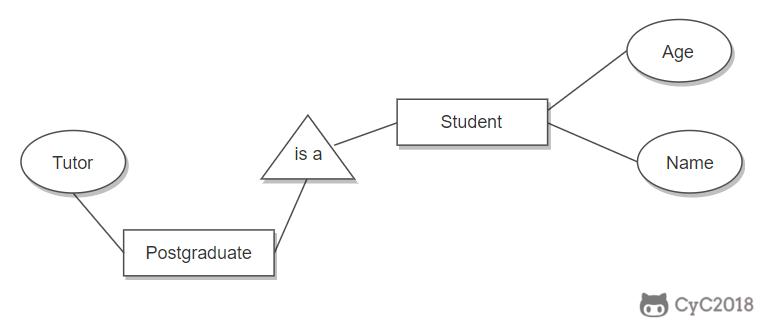\
|
||||
|
||||
|
||||
## 参考资料
|
||||
|
||||
- AbrahamSilberschatz, HenryF.Korth, S.Sudarshan, 等. 数据库系统概念 [M]. 机械工业出版社, 2006.
|
||||
- 施瓦茨. 高性能 MYSQL(第3版)[M]. 电子工业出版社, 2013.
|
||||
- 史嘉权. 数据库系统概论[M]. 清华大学出版社有限公司, 2006.
|
||||
- [The InnoDB Storage Engine](https://dev.mysql.com/doc/refman/5.7/en/innodb-storage-engine.html)
|
||||
- [Transaction isolation levels](https://www.slideshare.net/ErnestoHernandezRodriguez/transaction-isolation-levels)
|
||||
- [Concurrency Control](http://scanftree.com/dbms/2-phase-locking-protocol)
|
||||
- [The Nightmare of Locking, Blocking and Isolation Levels!](https://www.slideshare.net/brshristov/the-nightmare-of-locking-blocking-and-isolation-levels-46391666)
|
||||
- [Database Normalization and Normal Forms with an Example](https://aksakalli.github.io/2012/03/12/database-normalization-and-normal-forms-with-an-example.html)
|
||||
- [The basics of the InnoDB undo logging and history system](https://blog.jcole.us/2014/04/16/the-basics-of-the-innodb-undo-logging-and-history-system/)
|
||||
- [MySQL locking for the busy web developer](https://www.brightbox.com/blog/2013/10/31/on-mysql-locks/)
|
||||
- [浅入浅出 MySQL 和 InnoDB](https://draveness.me/mysql-innodb)
|
||||
- [Innodb 中的事务隔离级别和锁的关系](https://tech.meituan.com/2014/08/20/innodb-lock.html)
|
||||
* AbrahamSilberschatz, HenryF.Korth, S.Sudarshan, 等. 数据库系统概念 \[M]. 机械工业出版社, 2006.
|
||||
* 施瓦茨. 高性能 MYSQL(第3版)\[M]. 电子工业出版社, 2013.
|
||||
* 史嘉权. 数据库系统概论\[M]. 清华大学出版社有限公司, 2006.
|
||||
* [The InnoDB Storage Engine](https://dev.mysql.com/doc/refman/5.7/en/innodb-storage-engine.html)
|
||||
* [Transaction isolation levels](https://www.slideshare.net/ErnestoHernandezRodriguez/transaction-isolation-levels)
|
||||
* [Concurrency Control](http://scanftree.com/dbms/2-phase-locking-protocol)
|
||||
* [The Nightmare of Locking, Blocking and Isolation Levels!](https://www.slideshare.net/brshristov/the-nightmare-of-locking-blocking-and-isolation-levels-46391666)
|
||||
* [Database Normalization and Normal Forms with an Example](https://aksakalli.github.io/2012/03/12/database-normalization-and-normal-forms-with-an-example.html)
|
||||
* [The basics of the InnoDB undo logging and history system](https://blog.jcole.us/2014/04/16/the-basics-of-the-innodb-undo-logging-and-history-system/)
|
||||
* [MySQL locking for the busy web developer](https://www.brightbox.com/blog/2013/10/31/on-mysql-locks/)
|
||||
* [浅入浅出 MySQL 和 InnoDB](https://draveness.me/mysql-innodb)
|
||||
* [Innodb 中的事务隔离级别和锁的关系](https://tech.meituan.com/2014/08/20/innodb-lock.html)
|
||||
|
||||
@ -1,12 +1,10 @@
|
||||
# 构建工具
|
||||
<!-- GFM-TOC -->
|
||||
* [构建工具](#构建工具)
|
||||
* [一、构建工具的作用](#一构建工具的作用)
|
||||
* [二、Java 主流构建工具](#二java-主流构建工具)
|
||||
* [三、Maven](#三maven)
|
||||
* [参考资料](#参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [构建工具](构建工具.md#构建工具)
|
||||
* [一、构建工具的作用](构建工具.md#一构建工具的作用)
|
||||
* [二、Java 主流构建工具](构建工具.md#二java-主流构建工具)
|
||||
* [三、Maven](构建工具.md#三maven)
|
||||
* [参考资料](构建工具.md#参考资料)
|
||||
|
||||
## 一、构建工具的作用
|
||||
|
||||
@ -20,7 +18,8 @@
|
||||
|
||||
Ant 具有编译、测试和打包功能,其后出现的 Maven 在 Ant 的功能基础上又新增了依赖管理功能,而最新的 Gradle 又在 Maven 的功能基础上新增了对 Groovy 语言的支持。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191208204118932.png"/> </div><br>
|
||||
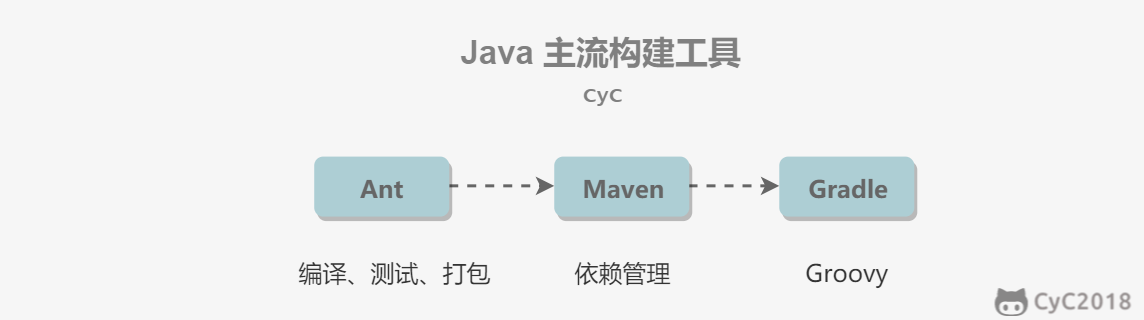\
|
||||
|
||||
|
||||
Gradle 和 Maven 的区别是,它使用 Groovy 这种特定领域语言(DSL)来管理构建脚本,而不再使用 XML 这种标记性语言。因为项目如果庞大的话,XML 很容易就变得臃肿。
|
||||
|
||||
@ -65,9 +64,9 @@ dependencies {
|
||||
|
||||
仓库的搜索顺序为:本地仓库、中央仓库、远程仓库。
|
||||
|
||||
- 本地仓库用来存储项目的依赖库;
|
||||
- 中央仓库是下载依赖库的默认位置;
|
||||
- 远程仓库,因为并非所有的依赖库都在中央仓库,或者中央仓库访问速度很慢,远程仓库是中央仓库的补充。
|
||||
* 本地仓库用来存储项目的依赖库;
|
||||
* 中央仓库是下载依赖库的默认位置;
|
||||
* 远程仓库,因为并非所有的依赖库都在中央仓库,或者中央仓库访问速度很慢,远程仓库是中央仓库的补充。
|
||||
|
||||
### POM
|
||||
|
||||
@ -82,12 +81,12 @@ POM 代表项目对象模型,它是一个 XML 文件,保存在项目根目
|
||||
</dependency>
|
||||
```
|
||||
|
||||
[groupId, artifactId, version, packaging, classifier] 称为一个项目的坐标,其中 groupId、artifactId、version 必须定义,packaging 可选(默认为 Jar),classifier 不能直接定义的,需要结合插件使用。
|
||||
\[groupId, artifactId, version, packaging, classifier] 称为一个项目的坐标,其中 groupId、artifactId、version 必须定义,packaging 可选(默认为 Jar),classifier 不能直接定义的,需要结合插件使用。
|
||||
|
||||
- groupId:项目组 Id,必须全球唯一;
|
||||
- artifactId:项目 Id,即项目名;
|
||||
- version:项目版本;
|
||||
- packaging:项目打包方式。
|
||||
* groupId:项目组 Id,必须全球唯一;
|
||||
* artifactId:项目 Id,即项目名;
|
||||
* version:项目版本;
|
||||
* packaging:项目打包方式。
|
||||
|
||||
### 依赖原则
|
||||
|
||||
@ -97,6 +96,7 @@ POM 代表项目对象模型,它是一个 XML 文件,保存在项目根目
|
||||
A -> B -> C -> X(1.0)
|
||||
A -> D -> X(2.0)
|
||||
```
|
||||
|
||||
由于 X(2.0) 路径最短,所以使用 X(2.0)。
|
||||
|
||||
#### 2. 声明顺序优先原则
|
||||
@ -118,9 +118,8 @@ A -> C -> X(2.0)
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [POM Reference](http://maven.apache.org/pom.html#Dependency_Version_Requirement_Specification)
|
||||
- [What is a build tool?](https://stackoverflow.com/questions/7249871/what-is-a-build-tool)
|
||||
- [Java Build Tools Comparisons: Ant vs Maven vs Gradle](https://programmingmitra.blogspot.com/2016/05/java-build-tools-comparisons-ant-vs.html)
|
||||
- [maven 2 gradle](http://sagioto.github.io/maven2gradle/)
|
||||
- [新一代构建工具 gradle](https://www.imooc.com/learn/833)
|
||||
|
||||
* [POM Reference](http://maven.apache.org/pom.html#Dependency\_Version\_Requirement\_Specification)
|
||||
* [What is a build tool?](https://stackoverflow.com/questions/7249871/what-is-a-build-tool)
|
||||
* [Java Build Tools Comparisons: Ant vs Maven vs Gradle](https://programmingmitra.blogspot.com/2016/05/java-build-tools-comparisons-ant-vs.html)
|
||||
* [maven 2 gradle](http://sagioto.github.io/maven2gradle/)
|
||||
* [新一代构建工具 gradle](https://www.imooc.com/learn/833)
|
||||
|
||||
263
notes/正则表达式.md
263
notes/正则表达式.md
@ -1,19 +1,17 @@
|
||||
# 正则表达式
|
||||
<!-- GFM-TOC -->
|
||||
* [正则表达式](#正则表达式)
|
||||
* [一、概述](#一概述)
|
||||
* [二、匹配单个字符](#二匹配单个字符)
|
||||
* [三、匹配一组字符](#三匹配一组字符)
|
||||
* [四、使用元字符](#四使用元字符)
|
||||
* [五、重复匹配](#五重复匹配)
|
||||
* [六、位置匹配](#六位置匹配)
|
||||
* [七、使用子表达式](#七使用子表达式)
|
||||
* [八、回溯引用](#八回溯引用)
|
||||
* [九、前后查找](#九前后查找)
|
||||
* [十、嵌入条件](#十嵌入条件)
|
||||
* [参考资料](#参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [正则表达式](正则表达式.md#正则表达式)
|
||||
* [一、概述](正则表达式.md#一概述)
|
||||
* [二、匹配单个字符](正则表达式.md#二匹配单个字符)
|
||||
* [三、匹配一组字符](正则表达式.md#三匹配一组字符)
|
||||
* [四、使用元字符](正则表达式.md#四使用元字符)
|
||||
* [五、重复匹配](正则表达式.md#五重复匹配)
|
||||
* [六、位置匹配](正则表达式.md#六位置匹配)
|
||||
* [七、使用子表达式](正则表达式.md#七使用子表达式)
|
||||
* [八、回溯引用](正则表达式.md#八回溯引用)
|
||||
* [九、前后查找](正则表达式.md#九前后查找)
|
||||
* [十、嵌入条件](正则表达式.md#十嵌入条件)
|
||||
* [参考资料](正则表达式.md#参考资料)
|
||||
|
||||
## 一、概述
|
||||
|
||||
@ -21,49 +19,49 @@
|
||||
|
||||
正则表达式内置于其它语言或者软件产品中,它本身不是一种语言或者软件。
|
||||
|
||||
[正则表达式在线工具](https://regexr.com/)
|
||||
[正则表达式在线工具](https://regexr.com)
|
||||
|
||||
## 二、匹配单个字符
|
||||
|
||||
**.** 可以用来匹配任何的单个字符,但是在绝大多数实现里面,不能匹配换行符;
|
||||
**.** 可以用来匹配任何的单个字符,但是在绝大多数实现里面,不能匹配换行符;
|
||||
|
||||
**.** 是元字符,表示它有特殊的含义,而不是字符本身的含义。如果需要匹配 . ,那么要用 \ 进行转义,即在 . 前面加上 \ 。
|
||||
**.** 是元字符,表示它有特殊的含义,而不是字符本身的含义。如果需要匹配 . ,那么要用 \ 进行转义,即在 . 前面加上 \ 。
|
||||
|
||||
正则表达式一般是区分大小写的,但也有些实现不区分。
|
||||
|
||||
**正则表达式**
|
||||
**正则表达式**
|
||||
|
||||
```
|
||||
C.C2018
|
||||
```
|
||||
|
||||
**匹配结果**
|
||||
**匹配结果**
|
||||
|
||||
My name is **CyC2018** .
|
||||
My name is **CyC2018** .
|
||||
|
||||
## 三、匹配一组字符
|
||||
|
||||
**[ ]** 定义一个字符集合;
|
||||
**\[ ]** 定义一个字符集合;
|
||||
|
||||
0-9、a-z 定义了一个字符区间,区间使用 ASCII 码来确定,字符区间在 [ ] 中使用。
|
||||
0-9、a-z 定义了一个字符区间,区间使用 ASCII 码来确定,字符区间在 \[ ] 中使用。
|
||||
|
||||
**-** 只有在 [ ] 之间才是元字符,在 [ ] 之外就是一个普通字符;
|
||||
**-** 只有在 \[ ] 之间才是元字符,在 \[ ] 之外就是一个普通字符;
|
||||
|
||||
**^** 在 [ ] 中是取非操作。
|
||||
**^** 在 \[ ] 中是取非操作。
|
||||
|
||||
**应用**
|
||||
**应用**
|
||||
|
||||
匹配以 abc 为开头,并且最后一个字母不为数字的字符串:
|
||||
|
||||
**正则表达式**
|
||||
**正则表达式**
|
||||
|
||||
```
|
||||
abc[^0-9]
|
||||
```
|
||||
|
||||
**匹配结果**
|
||||
**匹配结果**
|
||||
|
||||
1. **abcd**
|
||||
1. **abcd**
|
||||
2. abc1
|
||||
3. abc2
|
||||
|
||||
@ -71,14 +69,14 @@ abc[^0-9]
|
||||
|
||||
### 匹配空白字符
|
||||
|
||||
| 元字符 | 说明 |
|
||||
| :---: | :---: |
|
||||
| [\b] | 回退(删除)一个字符 |
|
||||
| \f | 换页符 |
|
||||
| \n | 换行符 |
|
||||
| \r | 回车符 |
|
||||
| \t | 制表符 |
|
||||
| \v | 垂直制表符 |
|
||||
| 元字符 | 说明 |
|
||||
| :---: | :--------: |
|
||||
| \[\b] | 回退(删除)一个字符 |
|
||||
| \f | 换页符 |
|
||||
| | 换行符 |
|
||||
| | 回车符 |
|
||||
| | 制表符 |
|
||||
| \v | 垂直制表符 |
|
||||
|
||||
\r\n 是 Windows 中的文本行结束标签,在 Unix/Linux 则是 \n。
|
||||
|
||||
@ -88,64 +86,64 @@ abc[^0-9]
|
||||
|
||||
#### 1. 数字元字符
|
||||
|
||||
| 元字符 | 说明 |
|
||||
| :---: | :---: |
|
||||
| \d | 数字字符,等价于 [0-9] |
|
||||
| \D | 非数字字符,等价于 [^0-9] |
|
||||
| 元字符 | 说明 |
|
||||
| :-: | :---------------: |
|
||||
| \d | 数字字符,等价于 \[0-9] |
|
||||
| \D | 非数字字符,等价于 \[^0-9] |
|
||||
|
||||
#### 2. 字母数字元字符
|
||||
|
||||
| 元字符 | 说明 |
|
||||
| :---: | :---: |
|
||||
| \w | 大小写字母,下划线和数字,等价于 [a-zA-Z0-9\_] |
|
||||
| \W | 对 \w 取非 |
|
||||
| 元字符 | 说明 |
|
||||
| :-: | :-----------------------------: |
|
||||
| \w | 大小写字母,下划线和数字,等价于 \[a-zA-Z0-9\_] |
|
||||
| \W | 对 \w 取非 |
|
||||
|
||||
#### 3. 空白字符元字符
|
||||
|
||||
| 元字符 | 说明 |
|
||||
| :---: | :---: |
|
||||
| \s | 任何一个空白字符,等价于 [\f\n\r\t\v] |
|
||||
| \S | 对 \s 取非 |
|
||||
| 元字符 | 说明 |
|
||||
| :-: | :------------------------: |
|
||||
| \s | 任何一个空白字符,等价于 \[\f\n\r\t\v] |
|
||||
| \S | 对 \s 取非 |
|
||||
|
||||
\x 匹配十六进制字符,\0 匹配八进制,例如 \xA 对应值为 10 的 ASCII 字符 ,即 \n。
|
||||
|
||||
## 五、重复匹配
|
||||
|
||||
- **\+** 匹配 1 个或者多个字符
|
||||
- **\** * 匹配 0 个或者多个字符
|
||||
- **?** 匹配 0 个或者 1 个字符
|
||||
* **+** 匹配 1 个或者多个字符
|
||||
* \*_\*_ \* 匹配 0 个或者多个字符
|
||||
* **?** 匹配 0 个或者 1 个字符
|
||||
|
||||
**应用**
|
||||
**应用**
|
||||
|
||||
匹配邮箱地址。
|
||||
|
||||
**正则表达式**
|
||||
**正则表达式**
|
||||
|
||||
```
|
||||
[\w.]+@\w+\.\w+
|
||||
```
|
||||
|
||||
[\w.] 匹配的是字母数字或者 . ,在其后面加上 + ,表示匹配多次。在字符集合 [ ] 里,. 不是元字符;
|
||||
\[\w.] 匹配的是字母数字或者 . ,在其后面加上 + ,表示匹配多次。在字符集合 \[ ] 里,. 不是元字符;
|
||||
|
||||
**匹配结果**
|
||||
**匹配结果**
|
||||
|
||||
**abc.def\<span\>@\</span\>qq.com**
|
||||
**abc.def\<span>@\</span>qq.com**
|
||||
|
||||
- **{n}** 匹配 n 个字符
|
||||
- **{m,n}** 匹配 m\~n 个字符
|
||||
- **{m,}** 至少匹配 m 个字符
|
||||
* **{n}** 匹配 n 个字符
|
||||
* **{m,n}** 匹配 m\~n 个字符
|
||||
* **{m,}** 至少匹配 m 个字符
|
||||
|
||||
\* 和 + 都是贪婪型元字符,会匹配尽可能多的内容。在后面加 ? 可以转换为懒惰型元字符,例如 \*?、+? 和 {m,n}? 。
|
||||
|
||||
**正则表达式**
|
||||
**正则表达式**
|
||||
|
||||
```
|
||||
a.+c
|
||||
```
|
||||
|
||||
**匹配结果**
|
||||
**匹配结果**
|
||||
|
||||
**abcabcabc**
|
||||
**abcabcabc**
|
||||
|
||||
由于 + 是贪婪型的,因此 .+ 会匹配更可能多的内容,所以会把整个 abcabcabc 文本都匹配,而不是只匹配前面的 abc 文本。用懒惰型可以实现匹配前面的。
|
||||
|
||||
@ -153,135 +151,136 @@ a.+c
|
||||
|
||||
### 单词边界
|
||||
|
||||
**\b** 可以匹配一个单词的边界,边界是指位于 \w 和 \W 之间的位置;**\B** 匹配一个不是单词边界的位置。
|
||||
**\b** 可以匹配一个单词的边界,边界是指位于 \w 和 \W 之间的位置;**\B** 匹配一个不是单词边界的位置。
|
||||
|
||||
\b 只匹配位置,不匹配字符,因此 \babc\b 匹配出来的结果为 3 个字符。
|
||||
|
||||
### 字符串边界
|
||||
|
||||
**^** 匹配整个字符串的开头,**$** 匹配结尾。
|
||||
**^** 匹配整个字符串的开头,**$** 匹配结尾。
|
||||
|
||||
^ 元字符在字符集合中用作求非,在字符集合外用作匹配字符串的开头。
|
||||
|
||||
分行匹配模式(multiline)下,换行被当做字符串的边界。
|
||||
|
||||
**应用**
|
||||
**应用**
|
||||
|
||||
匹配代码中以 // 开始的注释行
|
||||
|
||||
**正则表达式**
|
||||
**正则表达式**
|
||||
|
||||
```
|
||||
^\s*\/\/.*$
|
||||
```
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/600e9c75-5033-4dad-ae2b-930957db638e.png"/> </div><br>
|
||||
\
|
||||
|
||||
**匹配结果**
|
||||
|
||||
**匹配结果**
|
||||
|
||||
1. public void fun() {
|
||||
2. **// 注释 1**
|
||||
3. int a = 1;
|
||||
4. int b = 2;
|
||||
5. **// 注释 2**
|
||||
6. int c = a + b;
|
||||
2.   **// 注释 1**
|
||||
3.   int a = 1;
|
||||
4.   int b = 2;
|
||||
5.   **// 注释 2**
|
||||
6.   int c = a + b;
|
||||
7. }
|
||||
|
||||
## 七、使用子表达式
|
||||
|
||||
使用 **( )** 定义一个子表达式。子表达式的内容可以当成一个独立元素,即可以将它看成一个字符,并且使用 * 等元字符。
|
||||
使用 **( )** 定义一个子表达式。子表达式的内容可以当成一个独立元素,即可以将它看成一个字符,并且使用 \* 等元字符。
|
||||
|
||||
子表达式可以嵌套,但是嵌套层次过深会变得很难理解。
|
||||
|
||||
**正则表达式**
|
||||
**正则表达式**
|
||||
|
||||
```
|
||||
(ab){2,}
|
||||
```
|
||||
|
||||
**匹配结果**
|
||||
**匹配结果**
|
||||
|
||||
**ababab**
|
||||
**ababab**
|
||||
|
||||
**|** 是或元字符,它把左边和右边所有的部分都看成单独的两个部分,两个部分只要有一个匹配就行。
|
||||
**|** 是或元字符,它把左边和右边所有的部分都看成单独的两个部分,两个部分只要有一个匹配就行。
|
||||
|
||||
**正则表达式**
|
||||
**正则表达式**
|
||||
|
||||
```
|
||||
(19|20)\d{2}
|
||||
```
|
||||
|
||||
**匹配结果**
|
||||
**匹配结果**
|
||||
|
||||
1. **1900**
|
||||
2. **2010**
|
||||
1. **1900**
|
||||
2. **2010**
|
||||
3. 1020
|
||||
|
||||
**应用**
|
||||
**应用**
|
||||
|
||||
匹配 IP 地址。
|
||||
|
||||
IP 地址中每部分都是 0-255 的数字,用正则表达式匹配时以下情况是合法的:
|
||||
|
||||
- 一位数字
|
||||
- 不以 0 开头的两位数字
|
||||
- 1 开头的三位数
|
||||
- 2 开头,第 2 位是 0-4 的三位数
|
||||
- 25 开头,第 3 位是 0-5 的三位数
|
||||
* 一位数字
|
||||
* 不以 0 开头的两位数字
|
||||
* 1 开头的三位数
|
||||
* 2 开头,第 2 位是 0-4 的三位数
|
||||
* 25 开头,第 3 位是 0-5 的三位数
|
||||
|
||||
**正则表达式**
|
||||
**正则表达式**
|
||||
|
||||
```
|
||||
((25[0-5]|(2[0-4]\d)|(1\d{2})|([1-9]\d)|(\d))\.){3}(25[0-5]|(2[0-4]\d)|(1\d{2})|([1-9]\d)|(\d))
|
||||
```
|
||||
|
||||
**匹配结果**
|
||||
**匹配结果**
|
||||
|
||||
1. **192.168.0.1**
|
||||
1. **192.168.0.1**
|
||||
2. 00.00.00.00
|
||||
3. 555.555.555.555
|
||||
|
||||
## 八、回溯引用
|
||||
|
||||
回溯引用使用 **\n** 来引用某个子表达式,其中 n 代表的是子表达式的序号,从 1 开始。它和子表达式匹配的内容一致,比如子表达式匹配到 abc,那么回溯引用部分也需要匹配 abc 。
|
||||
回溯引用使用 来引用某个子表达式,其中 n 代表的是子表达式的序号,从 1 开始。它和子表达式匹配的内容一致,比如子表达式匹配到 abc,那么回溯引用部分也需要匹配 abc 。
|
||||
|
||||
**应用**
|
||||
**应用**
|
||||
|
||||
匹配 HTML 中合法的标题元素。
|
||||
|
||||
**正则表达式**
|
||||
**正则表达式**
|
||||
|
||||
\1 将回溯引用子表达式 (h[1-6]) 匹配的内容,也就是说必须和子表达式匹配的内容一致。
|
||||
\1 将回溯引用子表达式 (h\[1-6]) 匹配的内容,也就是说必须和子表达式匹配的内容一致。
|
||||
|
||||
```
|
||||
<(h[1-6])>\w*?<\/\1>
|
||||
```
|
||||
|
||||
**匹配结果**
|
||||
**匹配结果**
|
||||
|
||||
1. **<h1\>x</h1\>**
|
||||
2. **<h2\>x</h2\>**
|
||||
3. <h3\>x</h1\>
|
||||
1. **\<h1>x\</h1>**
|
||||
2. **\<h2>x\</h2>**
|
||||
3. \<h3>x\</h1>
|
||||
|
||||
### 替换
|
||||
|
||||
需要用到两个正则表达式。
|
||||
|
||||
**应用**
|
||||
**应用**
|
||||
|
||||
修改电话号码格式。
|
||||
|
||||
**文本**
|
||||
**文本**
|
||||
|
||||
313-555-1234
|
||||
|
||||
**查找正则表达式**
|
||||
**查找正则表达式**
|
||||
|
||||
```
|
||||
(\d{3})(-)(\d{3})(-)(\d{4})
|
||||
```
|
||||
|
||||
**替换正则表达式**
|
||||
**替换正则表达式**
|
||||
|
||||
在第一个子表达式查找的结果加上 () ,然后加一个空格,在第三个和第五个字表达式查找的结果中间加上 - 进行分隔。
|
||||
|
||||
@ -289,41 +288,41 @@ IP 地址中每部分都是 0-255 的数字,用正则表达式匹配时以下
|
||||
($1) $3-$5
|
||||
```
|
||||
|
||||
**结果**
|
||||
**结果**
|
||||
|
||||
(313) 555-1234
|
||||
|
||||
### 大小写转换
|
||||
|
||||
| 元字符 | 说明 |
|
||||
| :---: | :---: |
|
||||
| \l | 把下个字符转换为小写 |
|
||||
| \u| 把下个字符转换为大写 |
|
||||
| \L | 把\L 和\E 之间的字符全部转换为小写 |
|
||||
| \U | 把\U 和\E 之间的字符全部转换为大写 |
|
||||
| \E | 结束\L 或者\U |
|
||||
| 元字符 | 说明 |
|
||||
| :-: | :------------------: |
|
||||
| \l | 把下个字符转换为小写 |
|
||||
| \u | 把下个字符转换为大写 |
|
||||
| \L | 把\L 和\E 之间的字符全部转换为小写 |
|
||||
| \U | 把\U 和\E 之间的字符全部转换为大写 |
|
||||
| \E | 结束\L 或者\U |
|
||||
|
||||
**应用**
|
||||
**应用**
|
||||
|
||||
把文本的第二个和第三个字符转换为大写。
|
||||
|
||||
**文本**
|
||||
**文本**
|
||||
|
||||
abcd
|
||||
|
||||
**查找**
|
||||
**查找**
|
||||
|
||||
```
|
||||
(\w)(\w{2})(\w)
|
||||
```
|
||||
|
||||
**替换**
|
||||
**替换**
|
||||
|
||||
```
|
||||
$1\U$2\E$3
|
||||
```
|
||||
|
||||
**结果**
|
||||
**结果**
|
||||
|
||||
aBCd
|
||||
|
||||
@ -331,21 +330,21 @@ aBCd
|
||||
|
||||
前后查找规定了匹配的内容首尾应该匹配的内容,但是又不包含首尾匹配的内容。
|
||||
|
||||
向前查找使用 **?=** 定义,它规定了尾部匹配的内容,这个匹配的内容在 ?= 之后定义。所谓向前查找,就是规定了一个匹配的内容,然后以这个内容为尾部向前面查找需要匹配的内容。向后匹配用 ?\<= 定义(注: JavaScript 不支持向后匹配,Java 对其支持也不完善)。
|
||||
向前查找使用 **?=** 定义,它规定了尾部匹配的内容,这个匹配的内容在 ?= 之后定义。所谓向前查找,就是规定了一个匹配的内容,然后以这个内容为尾部向前面查找需要匹配的内容。向后匹配用 ?<= 定义(注: JavaScript 不支持向后匹配,Java 对其支持也不完善)。
|
||||
|
||||
**应用**
|
||||
**应用**
|
||||
|
||||
查找出邮件地址 @ 字符前面的部分。
|
||||
|
||||
**正则表达式**
|
||||
**正则表达式**
|
||||
|
||||
```
|
||||
\w+(?=@)
|
||||
```
|
||||
|
||||
**结果**
|
||||
**结果**
|
||||
|
||||
**abc** @qq.com
|
||||
**abc** @qq.com
|
||||
|
||||
对向前和向后查找取非,只要把 = 替换成 ! 即可,比如 (?=) 替换成 (?!) 。取非操作使得匹配那些首尾不符合要求的内容。
|
||||
|
||||
@ -355,38 +354,38 @@ aBCd
|
||||
|
||||
条件为某个子表达式是否匹配,如果匹配则需要继续匹配条件表达式后面的内容。
|
||||
|
||||
**正则表达式**
|
||||
**正则表达式**
|
||||
|
||||
子表达式 (\\() 匹配一个左括号,其后的 ? 表示匹配 0 个或者 1 个。 ?(1) 为条件,当子表达式 1 匹配时条件成立,需要执行 \) 匹配,也就是匹配右括号。
|
||||
子表达式 (\\() 匹配一个左括号,其后的 ? 表示匹配 0 个或者 1 个。 ?(1) 为条件,当子表达式 1 匹配时条件成立,需要执行 ) 匹配,也就是匹配右括号。
|
||||
|
||||
```
|
||||
(\()?abc(?(1)\))
|
||||
```
|
||||
|
||||
**结果**
|
||||
**结果**
|
||||
|
||||
1. **(abc)**
|
||||
2. **abc**
|
||||
1. **(abc)**
|
||||
2. **abc**
|
||||
3. (abc
|
||||
|
||||
### 前后查找条件
|
||||
|
||||
条件为定义的首尾是否匹配,如果匹配,则继续执行后面的匹配。注意,首尾不包含在匹配的内容中。
|
||||
|
||||
**正则表达式**
|
||||
**正则表达式**
|
||||
|
||||
?(?=-) 为前向查找条件,只有在以 - 为前向查找的结尾能匹配 \d{5} ,才继续匹配 -\d{4} 。
|
||||
?(?=-) 为前向查找条件,只有在以 - 为前向查找的结尾能匹配 \d{5} ,才继续匹配 -\d{4} 。
|
||||
|
||||
```
|
||||
\d{5}(?(?=-)-\d{4})
|
||||
```
|
||||
|
||||
**结果**
|
||||
**结果**
|
||||
|
||||
1. **11111**
|
||||
1. **11111**
|
||||
2. 22222-
|
||||
3. **33333-4444**
|
||||
3. **33333-4444**
|
||||
|
||||
## 参考资料
|
||||
|
||||
- BenForta. 正则表达式必知必会 [M]. 人民邮电出版社, 2007.
|
||||
* BenForta. 正则表达式必知必会 \[M]. 人民邮电出版社, 2007.
|
||||
|
||||
@ -1,19 +1,17 @@
|
||||
# 消息队列
|
||||
<!-- GFM-TOC -->
|
||||
* [消息队列](#消息队列)
|
||||
* [一、消息模型](#一消息模型)
|
||||
* [点对点](#点对点)
|
||||
* [发布/订阅](#发布订阅)
|
||||
* [二、使用场景](#二使用场景)
|
||||
* [异步处理](#异步处理)
|
||||
* [流量削锋](#流量削锋)
|
||||
* [应用解耦](#应用解耦)
|
||||
* [三、可靠性](#三可靠性)
|
||||
* [发送端的可靠性](#发送端的可靠性)
|
||||
* [接收端的可靠性](#接收端的可靠性)
|
||||
* [参考资料](#参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [消息队列](消息队列.md#消息队列)
|
||||
* [一、消息模型](消息队列.md#一消息模型)
|
||||
* [点对点](消息队列.md#点对点)
|
||||
* [发布/订阅](消息队列.md#发布订阅)
|
||||
* [二、使用场景](消息队列.md#二使用场景)
|
||||
* [异步处理](消息队列.md#异步处理)
|
||||
* [流量削锋](消息队列.md#流量削锋)
|
||||
* [应用解耦](消息队列.md#应用解耦)
|
||||
* [三、可靠性](消息队列.md#三可靠性)
|
||||
* [发送端的可靠性](消息队列.md#发送端的可靠性)
|
||||
* [接收端的可靠性](消息队列.md#接收端的可靠性)
|
||||
* [参考资料](消息队列.md#参考资料)
|
||||
|
||||
## 一、消息模型
|
||||
|
||||
@ -21,20 +19,23 @@
|
||||
|
||||
消息生产者向消息队列中发送了一个消息之后,只能被一个消费者消费一次。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191212011250613.png"/> </div><br>
|
||||
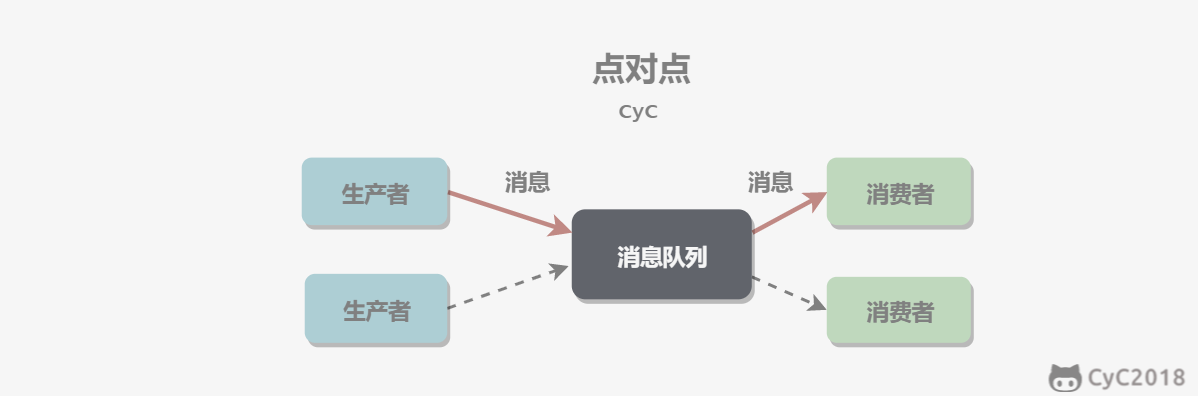\
|
||||
|
||||
|
||||
### 发布/订阅
|
||||
|
||||
消息生产者向频道发送一个消息之后,多个消费者可以从该频道订阅到这条消息并消费。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191212011410374.png"/> </div><br>
|
||||
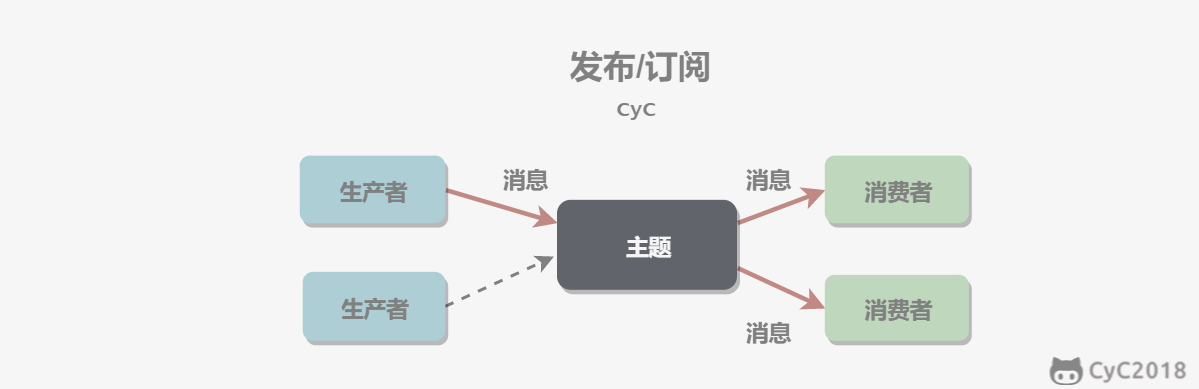\
|
||||
|
||||
|
||||
发布与订阅模式和观察者模式有以下不同:
|
||||
|
||||
- 观察者模式中,观察者和主题都知道对方的存在;而在发布与订阅模式中,生产者与消费者不知道对方的存在,它们之间通过频道进行通信。
|
||||
- 观察者模式是同步的,当事件触发时,主题会调用观察者的方法,然后等待方法返回;而发布与订阅模式是异步的,生产者向频道发送一个消息之后,就不需要关心消费者何时去订阅这个消息,可以立即返回。
|
||||
* 观察者模式中,观察者和主题都知道对方的存在;而在发布与订阅模式中,生产者与消费者不知道对方的存在,它们之间通过频道进行通信。
|
||||
* 观察者模式是同步的,当事件触发时,主题会调用观察者的方法,然后等待方法返回;而发布与订阅模式是异步的,生产者向频道发送一个消息之后,就不需要关心消费者何时去订阅这个消息,可以立即返回。
|
||||
|
||||
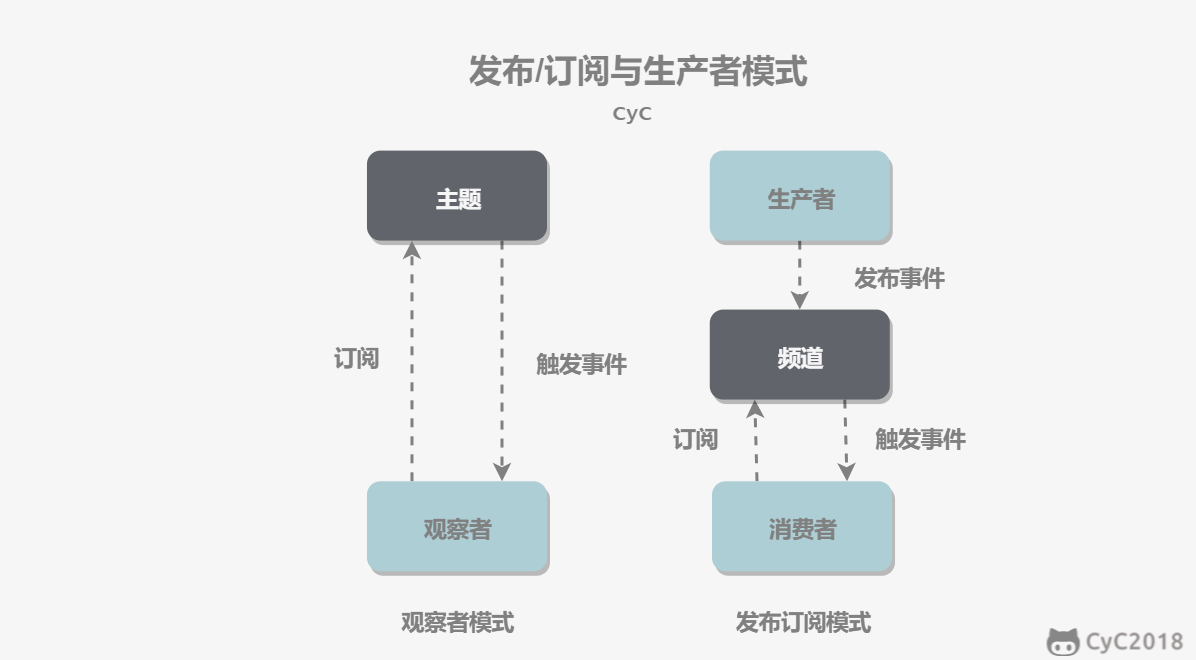\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/image-20191212011747967.png"/> </div><br>
|
||||
|
||||
## 二、使用场景
|
||||
|
||||
@ -72,10 +73,10 @@
|
||||
|
||||
两种实现方法:
|
||||
|
||||
- 保证接收端处理消息的业务逻辑具有幂等性:只要具有幂等性,那么消费多少次消息,最后处理的结果都是一样的。
|
||||
- 保证消息具有唯一编号,并使用一张日志表来记录已经消费的消息编号。
|
||||
* 保证接收端处理消息的业务逻辑具有幂等性:只要具有幂等性,那么消费多少次消息,最后处理的结果都是一样的。
|
||||
* 保证消息具有唯一编号,并使用一张日志表来记录已经消费的消息编号。
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [Observer vs Pub-Sub](http://developers-club.com/posts/270339/)
|
||||
- [消息队列中点对点与发布订阅区别](https://blog.csdn.net/lizhitao/article/details/47723105)
|
||||
* [Observer vs Pub-Sub](http://developers-club.com/posts/270339/)
|
||||
* [消息队列中点对点与发布订阅区别](https://blog.csdn.net/lizhitao/article/details/47723105)
|
||||
|
||||
@ -1,27 +1,32 @@
|
||||
# 算法 - 其它
|
||||
|
||||
## 汉诺塔
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/69d6c38d-1dec-4f72-ae60-60dbc10e9d15.png" width="300"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
有三个柱子,分别为 from、buffer、to。需要将 from 上的圆盘全部移动到 to 上,并且要保证小圆盘始终在大圆盘上。
|
||||
|
||||
这是一个经典的递归问题,分为三步求解:
|
||||
|
||||
① 将 n-1 个圆盘从 from -\> buffer
|
||||
① 将 n-1 个圆盘从 from -> buffer
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/f9240aa1-8d48-4959-b28a-7ca45c3e4d91.png" width="300"/> </div><br>
|
||||
\
|
||||
|
||||
② 将 1 个圆盘从 from -\> to
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/f579cab0-3d49-4d00-8e14-e9e1669d0f9f.png" width="300"/> </div><br>
|
||||
② 将 1 个圆盘从 from -> to
|
||||
|
||||
③ 将 n-1 个圆盘从 buffer -\> to
|
||||
\
|
||||
|
||||
|
||||
③ 将 n-1 个圆盘从 buffer -> to
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/d02f74dd-8e33-4f3c-bf29-53203a06695a.png" width="300"/> </div><br>
|
||||
|
||||
如果只有一个圆盘,那么只需要进行一次移动操作。
|
||||
|
||||
从上面的讨论可以知道,a<sub>n</sub> = 2 * a<sub>n-1</sub> + 1,显然 a<sub>n</sub> = 2<sup>n</sup> - 1,n 个圆盘需要移动 2<sup>n</sup> - 1 次。
|
||||
从上面的讨论可以知道,an = 2 \* an-1 + 1,显然 an = 2n - 1,n 个圆盘需要移动 2n - 1 次。
|
||||
|
||||
```java
|
||||
public class Hanoi {
|
||||
@ -57,10 +62,10 @@ from H1 to H3
|
||||
|
||||
例如对于一个文本文件,其中各种字符出现的次数如下:
|
||||
|
||||
- a : 10
|
||||
- b : 20
|
||||
- c : 40
|
||||
- d : 80
|
||||
* a : 10
|
||||
* b : 20
|
||||
* c : 40
|
||||
* d : 80
|
||||
|
||||
可以将每种字符转换成二进制编码,例如将 a 转换为 00,b 转换为 01,c 转换为 10,d 转换为 11。这是最简单的一种编码方式,没有考虑各个字符的权值(出现频率)。而哈夫曼编码采用了贪心策略,使出现频率最高的字符的编码最短,从而保证整体的编码长度最短。
|
||||
|
||||
@ -68,7 +73,8 @@ from H1 to H3
|
||||
|
||||
生成编码时,从根节点出发,向左遍历则添加二进制位 0,向右则添加二进制位 1,直到遍历到叶子节点,叶子节点代表的字符的编码就是这个路径编码。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/8edc5164-810b-4cc5-bda8-2a2c98556377.jpg" width="300"/> </div><br>
|
||||
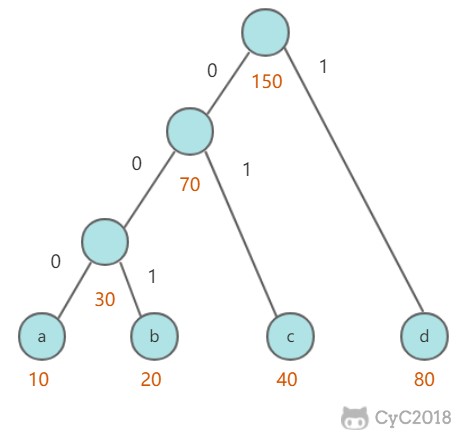\
|
||||
|
||||
|
||||
```java
|
||||
public class Huffman {
|
||||
|
||||
@ -1,26 +1,25 @@
|
||||
# 算法 - 并查集
|
||||
<!-- GFM-TOC -->
|
||||
* [算法 - 并查集](#算法---并查集)
|
||||
* [前言](#前言)
|
||||
* [Quick Find](#quick-find)
|
||||
* [Quick Union](#quick-union)
|
||||
* [加权 Quick Union](#加权-quick-union)
|
||||
* [路径压缩的加权 Quick Union](#路径压缩的加权-quick-union)
|
||||
* [比较](#比较)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [算法 - 并查集](<算法 - 并查集.md#算法---并查集>)
|
||||
* [前言](<算法 - 并查集.md#前言>)
|
||||
* [Quick Find](<算法 - 并查集.md#quick-find>)
|
||||
* [Quick Union](<算法 - 并查集.md#quick-union>)
|
||||
* [加权 Quick Union](<算法 - 并查集.md#加权-quick-union>)
|
||||
* [路径压缩的加权 Quick Union](<算法 - 并查集.md#路径压缩的加权-quick-union>)
|
||||
* [比较](<算法 - 并查集.md#比较>)
|
||||
|
||||
## 前言
|
||||
|
||||
用于解决动态连通性问题,能动态连接两个点,并且判断两个点是否连通。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/02943a90-7dd4-4e9a-9325-f8217d3cc54d.jpg" width="350"/> </div><br>
|
||||
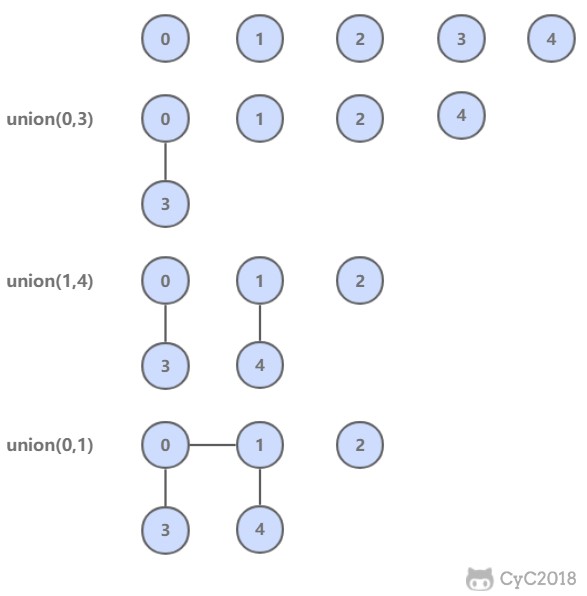\
|
||||
|
||||
| 方法 | 描述 |
|
||||
| :---: | :---: |
|
||||
| UF(int N) | 构造一个大小为 N 的并查集 |
|
||||
| void union(int p, int q) | 连接 p 和 q 节点 |
|
||||
| int find(int p) | 查找 p 所在的连通分量编号 |
|
||||
|
||||
| 方法 | 描述 |
|
||||
| :-----------------------------: | :-------------: |
|
||||
| UF(int N) | 构造一个大小为 N 的并查集 |
|
||||
| void union(int p, int q) | 连接 p 和 q 节点 |
|
||||
| int find(int p) | 查找 p 所在的连通分量编号 |
|
||||
| boolean connected(int p, int q) | 判断 p 和 q 节点是否连通 |
|
||||
|
||||
```java
|
||||
@ -53,7 +52,8 @@ public abstract class UF {
|
||||
|
||||
但是 union 操作代价却很高,需要将其中一个连通分量中的所有节点 id 值都修改为另一个节点的 id 值。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/0972501d-f854-4d26-8fce-babb27c267f6.jpg" width="320"/> </div><br>
|
||||
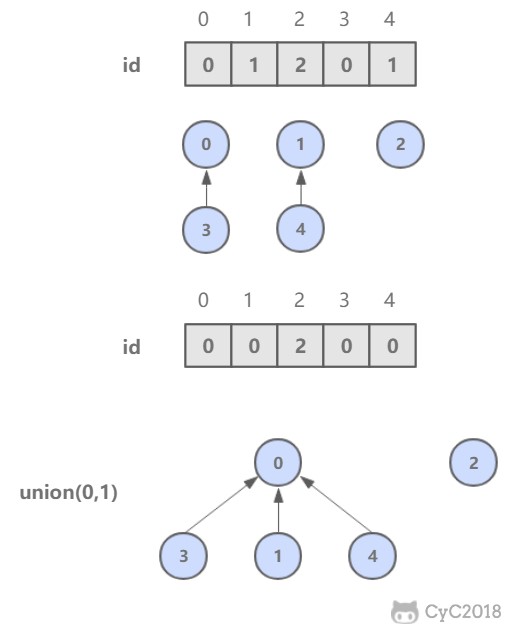\
|
||||
|
||||
|
||||
```java
|
||||
public class QuickFindUF extends UF {
|
||||
@ -93,7 +93,8 @@ public class QuickFindUF extends UF {
|
||||
|
||||
但是 find 操作开销很大,因为同一个连通分量的节点 id 值不同,id 值只是用来指向另一个节点。因此需要一直向上查找操作,直到找到最上层的节点。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/11b27de5-5a9d-45e4-95cc-417fa3ad1d38.jpg" width="280"/> </div><br>
|
||||
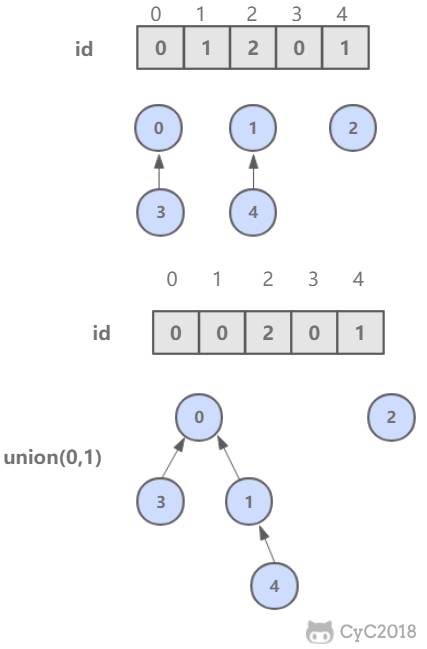\
|
||||
|
||||
|
||||
```java
|
||||
public class QuickUnionUF extends UF {
|
||||
@ -126,7 +127,8 @@ public class QuickUnionUF extends UF {
|
||||
|
||||
这种方法可以快速进行 union 操作,但是 find 操作和树高成正比,最坏的情况下树的高度为节点的数目。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/23e4462b-263f-4d15-8805-529e0ca7a4d1.jpg" width="100"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 加权 Quick Union
|
||||
|
||||
@ -134,7 +136,8 @@ public class QuickUnionUF extends UF {
|
||||
|
||||
理论研究证明,加权 quick-union 算法构造的树深度最多不超过 logN。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/a9f18f8a-c1ea-422e-aa56-d91716b0f755.jpg" width="150"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```java
|
||||
public class WeightedQuickUnionUF extends UF {
|
||||
@ -186,9 +189,9 @@ public class WeightedQuickUnionUF extends UF {
|
||||
|
||||
## 比较
|
||||
|
||||
| 算法 | union | find |
|
||||
| :---: | :---: | :---: |
|
||||
| Quick Find | N | 1 |
|
||||
| Quick Union | 树高 | 树高 |
|
||||
| 加权 Quick Union | logN | logN |
|
||||
| 算法 | union | find |
|
||||
| :-----------------: | :----: | :----: |
|
||||
| Quick Find | N | 1 |
|
||||
| Quick Union | 树高 | 树高 |
|
||||
| 加权 Quick Union | logN | logN |
|
||||
| 路径压缩的加权 Quick Union | 非常接近 1 | 非常接近 1 |
|
||||
|
||||
@ -1,4 +1,5 @@
|
||||
# 算法 - 排序
|
||||
|
||||
## 约定
|
||||
|
||||
待排序的元素需要实现 Java 的 Comparable 接口,该接口有 compareTo() 方法,可以用它来判断两个元素的大小关系。
|
||||
@ -28,9 +29,10 @@ public abstract class Sort<T extends Comparable<T>> {
|
||||
|
||||
从数组中选择最小元素,将它与数组的第一个元素交换位置。再从数组剩下的元素中选择出最小的元素,将它与数组的第二个元素交换位置。不断进行这样的操作,直到将整个数组排序。
|
||||
|
||||
选择排序需要 \~N<sup>2</sup>/2 次比较和 \~N 次交换,它的运行时间与输入无关,这个特点使得它对一个已经排序的数组也需要这么多的比较和交换操作。
|
||||
选择排序需要 \~N2/2 次比较和 \~N 次交换,它的运行时间与输入无关,这个特点使得它对一个已经排序的数组也需要这么多的比较和交换操作。
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/bc6be2d0-ed5e-4def-89e5-3ada9afa811a.gif" width="230px"> </div><br>
|
||||
|
||||
```java
|
||||
public class Selection<T extends Comparable<T>> extends Sort<T> {
|
||||
@ -57,7 +59,8 @@ public class Selection<T extends Comparable<T>> extends Sort<T> {
|
||||
|
||||
在一轮循环中,如果没有发生交换,那么说明数组已经是有序的,此时可以直接退出。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/0f8d178b-52d8-491b-9dfd-41e05a952578.gif" width="200px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```java
|
||||
public class Bubble<T extends Comparable<T>> extends Sort<T> {
|
||||
@ -87,11 +90,12 @@ public class Bubble<T extends Comparable<T>> extends Sort<T> {
|
||||
|
||||
插入排序的时间复杂度取决于数组的初始顺序,如果数组已经部分有序了,那么逆序较少,需要的交换次数也就较少,时间复杂度较低。
|
||||
|
||||
- 平均情况下插入排序需要 \~N<sup>2</sup>/4 比较以及 \~N<sup>2</sup>/4 次交换;
|
||||
- 最坏的情况下需要 \~N<sup>2</sup>/2 比较以及 \~N<sup>2</sup>/2 次交换,最坏的情况是数组是倒序的;
|
||||
- 最好的情况下需要 N-1 次比较和 0 次交换,最好的情况就是数组已经有序了。
|
||||
* 平均情况下插入排序需要 \~N2/4 比较以及 \~N2/4 次交换;
|
||||
* 最坏的情况下需要 \~N2/2 比较以及 \~N2/2 次交换,最坏的情况是数组是倒序的;
|
||||
* 最好的情况下需要 N-1 次比较和 0 次交换,最好的情况就是数组已经有序了。
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/35253fa4-f60a-4e3b-aaec-8fc835aabdac.gif" width="200px"> </div><br>
|
||||
|
||||
```java
|
||||
public class Insertion<T extends Comparable<T>> extends Sort<T> {
|
||||
@ -114,7 +118,8 @@ public class Insertion<T extends Comparable<T>> extends Sort<T> {
|
||||
|
||||
希尔排序使用插入排序对间隔 h 的序列进行排序。通过不断减小 h,最后令 h=1,就可以使得整个数组是有序的。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/7818c574-97a8-48db-8e62-8bfb030b02ba.png" width="450px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```java
|
||||
public class Shell<T extends Comparable<T>> extends Sort<T> {
|
||||
@ -139,16 +144,16 @@ public class Shell<T extends Comparable<T>> extends Sort<T> {
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
希尔排序的运行时间达不到平方级别,使用递增序列 1, 4, 13, 40, ... 的希尔排序所需要的比较次数不会超过 N 的若干倍乘于递增序列的长度。后面介绍的高级排序算法只会比希尔排序快两倍左右。
|
||||
希尔排序的运行时间达不到平方级别,使用递增序列 1, 4, 13, 40, ... 的希尔排序所需要的比较次数不会超过 N 的若干倍乘于递增序列的长度。后面介绍的高级排序算法只会比希尔排序快两倍左右。
|
||||
|
||||
## 归并排序
|
||||
|
||||
归并排序的思想是将数组分成两部分,分别进行排序,然后归并起来。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/ec840967-d127-4da3-b6bb-186996c56746.png" width="300px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### 1. 归并方法
|
||||
|
||||
@ -213,7 +218,6 @@ public class Up2DownMergeSort<T extends Comparable<T>> extends MergeSort<T> {
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### 3. 自底向上归并排序
|
||||
|
||||
先归并那些微型数组,然后成对归并得到的微型数组。
|
||||
@ -234,17 +238,17 @@ public class Down2UpMergeSort<T extends Comparable<T>> extends MergeSort<T> {
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
## 快速排序
|
||||
|
||||
### 1. 基本算法
|
||||
|
||||
- 归并排序将数组分为两个子数组分别排序,并将有序的子数组归并使得整个数组排序;
|
||||
- 快速排序通过一个切分元素将数组分为两个子数组,左子数组小于等于切分元素,右子数组大于等于切分元素,将这两个子数组排序也就将整个数组排序了。
|
||||
* 归并排序将数组分为两个子数组分别排序,并将有序的子数组归并使得整个数组排序;
|
||||
* 快速排序通过一个切分元素将数组分为两个子数组,左子数组小于等于切分元素,右子数组大于等于切分元素,将这两个子数组排序也就将整个数组排序了。
|
||||
|
||||
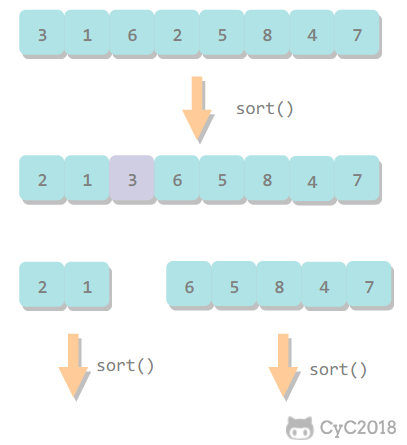\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/6234eb3d-ccf2-4987-a724-235aef6957b1.png" width="280px"> </div><br>
|
||||
|
||||
```java
|
||||
public class QuickSort<T extends Comparable<T>> extends Sort<T> {
|
||||
@ -273,9 +277,10 @@ public class QuickSort<T extends Comparable<T>> extends Sort<T> {
|
||||
|
||||
### 2. 切分
|
||||
|
||||
取 a[l] 作为切分元素,然后从数组的左端向右扫描直到找到第一个大于等于它的元素,再从数组的右端向左扫描找到第一个小于它的元素,交换这两个元素。不断进行这个过程,就可以保证左指针 i 的左侧元素都不大于切分元素,右指针 j 的右侧元素都不小于切分元素。当两个指针相遇时,将切分元素 a[l] 和 a[j] 交换位置。
|
||||
取 a\[l] 作为切分元素,然后从数组的左端向右扫描直到找到第一个大于等于它的元素,再从数组的右端向左扫描找到第一个小于它的元素,交换这两个元素。不断进行这个过程,就可以保证左指针 i 的左侧元素都不大于切分元素,右指针 j 的右侧元素都不小于切分元素。当两个指针相遇时,将切分元素 a\[l] 和 a\[j] 交换位置。
|
||||
|
||||
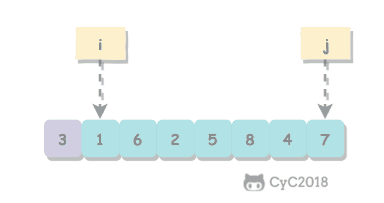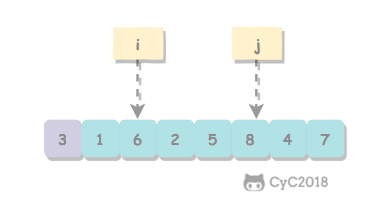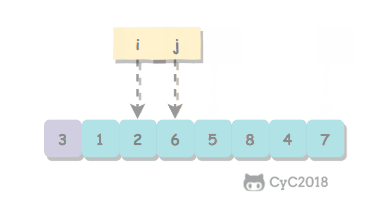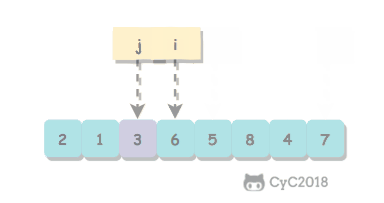\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/c4859290-e27d-4f12-becf-e2a5c1f3a275.gif" width="320px"> </div><br>
|
||||
|
||||
```java
|
||||
private int partition(T[] nums, int l, int h) {
|
||||
@ -297,21 +302,21 @@ private int partition(T[] nums, int l, int h) {
|
||||
|
||||
快速排序是原地排序,不需要辅助数组,但是递归调用需要辅助栈。
|
||||
|
||||
快速排序最好的情况下是每次都正好将数组对半分,这样递归调用次数才是最少的。这种情况下比较次数为 C<sub>N</sub>=2C<sub>N/2</sub>+N,复杂度为 O(NlogN)。
|
||||
快速排序最好的情况下是每次都正好将数组对半分,这样递归调用次数才是最少的。这种情况下比较次数为 CN=2CN/2+N,复杂度为 O(NlogN)。
|
||||
|
||||
最坏的情况下,第一次从最小的元素切分,第二次从第二小的元素切分,如此这般。因此最坏的情况下需要比较 N<sup>2</sup>/2。为了防止数组最开始就是有序的,在进行快速排序时需要随机打乱数组。
|
||||
最坏的情况下,第一次从最小的元素切分,第二次从第二小的元素切分,如此这般。因此最坏的情况下需要比较 N2/2。为了防止数组最开始就是有序的,在进行快速排序时需要随机打乱数组。
|
||||
|
||||
### 4. 算法改进
|
||||
|
||||
##### 4.1 切换到插入排序
|
||||
**4.1 切换到插入排序**
|
||||
|
||||
因为快速排序在小数组中也会递归调用自己,对于小数组,插入排序比快速排序的性能更好,因此在小数组中可以切换到插入排序。
|
||||
|
||||
##### 4.2 三数取中
|
||||
**4.2 三数取中**
|
||||
|
||||
最好的情况下是每次都能取数组的中位数作为切分元素,但是计算中位数的代价很高。一种折中方法是取 3 个元素,并将大小居中的元素作为切分元素。
|
||||
|
||||
##### 4.3 三向切分
|
||||
**4.3 三向切分**
|
||||
|
||||
对于有大量重复元素的数组,可以将数组切分为三部分,分别对应小于、等于和大于切分元素。
|
||||
|
||||
@ -345,7 +350,7 @@ public class ThreeWayQuickSort<T extends Comparable<T>> extends QuickSort<T> {
|
||||
|
||||
### 5. 基于切分的快速选择算法
|
||||
|
||||
快速排序的 partition() 方法,会返回一个整数 j 使得 a[l..j-1] 小于等于 a[j],且 a[j+1..h] 大于等于 a[j],此时 a[j] 就是数组的第 j 大元素。
|
||||
快速排序的 partition() 方法,会返回一个整数 j 使得 a\[l..j-1] 小于等于 a\[j],且 a\[j+1..h] 大于等于 a\[j],此时 a\[j] 就是数组的第 j 大元素。
|
||||
|
||||
可以利用这个特性找出数组的第 k 个元素。
|
||||
|
||||
@ -379,7 +384,8 @@ public T select(T[] nums, int k) {
|
||||
|
||||
堆可以用数组来表示,这是因为堆是完全二叉树,而完全二叉树很容易就存储在数组中。位置 k 的节点的父节点位置为 k/2,而它的两个子节点的位置分别为 2k 和 2k+1。这里不使用数组索引为 0 的位置,是为了更清晰地描述节点的位置关系。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/f48883c8-9d8a-494e-99a4-317d8ddb8552.png" width="170px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```java
|
||||
public class Heap<T extends Comparable<T>> {
|
||||
@ -415,7 +421,8 @@ public class Heap<T extends Comparable<T>> {
|
||||
|
||||
在堆中,当一个节点比父节点大,那么需要交换这个两个节点。交换后还可能比它新的父节点大,因此需要不断地进行比较和交换操作,把这种操作称为上浮。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/99d5e84e-fc2a-49a3-8259-8de274617756.gif" width="270px"> </div><br>
|
||||
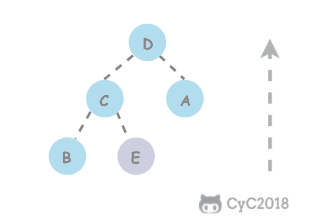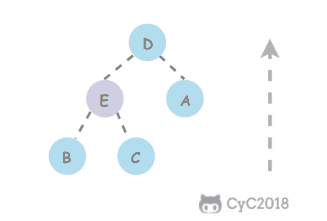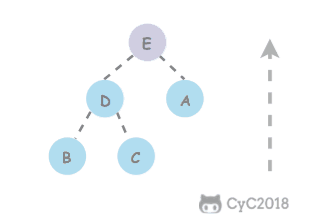\
|
||||
|
||||
|
||||
```java
|
||||
private void swim(int k) {
|
||||
@ -428,7 +435,8 @@ private void swim(int k) {
|
||||
|
||||
类似地,当一个节点比子节点来得小,也需要不断地向下进行比较和交换操作,把这种操作称为下沉。一个节点如果有两个子节点,应当与两个子节点中最大那个节点进行交换。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/4bf5e3fb-a285-4138-b3b6-780956eb1df1.gif" width="270px"> </div><br>
|
||||
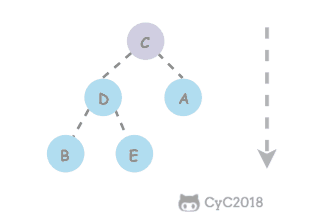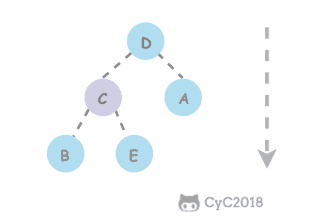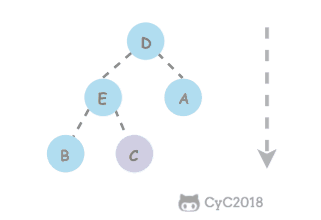\
|
||||
|
||||
|
||||
```java
|
||||
private void sink(int k) {
|
||||
@ -473,17 +481,19 @@ public T delMax() {
|
||||
|
||||
把最大元素和当前堆中数组的最后一个元素交换位置,并且不删除它,那么就可以得到一个从尾到头的递减序列,从正向来看就是一个递增序列,这就是堆排序。
|
||||
|
||||
##### 5.1 构建堆
|
||||
**5.1 构建堆**
|
||||
|
||||
无序数组建立堆最直接的方法是从左到右遍历数组进行上浮操作。一个更高效的方法是从右至左进行下沉操作,如果一个节点的两个节点都已经是堆有序,那么进行下沉操作可以使得这个节点为根节点的堆有序。叶子节点不需要进行下沉操作,可以忽略叶子节点的元素,因此只需要遍历一半的元素即可。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/c2ca8dd2-8d00-4a3e-bece-db7849ac9cfd.gif" width="210px"> </div><br>
|
||||
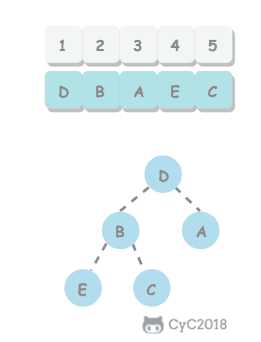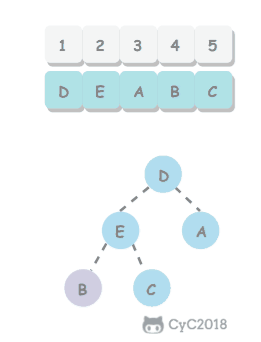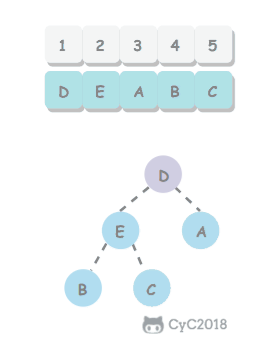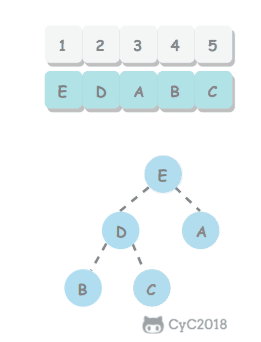\
|
||||
|
||||
##### 5.2 交换堆顶元素与最后一个元素
|
||||
|
||||
**5.2 交换堆顶元素与最后一个元素**
|
||||
|
||||
交换之后需要进行下沉操作维持堆的有序状态。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/d156bcda-ac8d-4324-95e0-0c8df41567c9.gif" width="250px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```java
|
||||
public class HeapSort<T extends Comparable<T>> extends Sort<T> {
|
||||
@ -534,16 +544,16 @@ public class HeapSort<T extends Comparable<T>> extends Sort<T> {
|
||||
|
||||
### 1. 排序算法的比较
|
||||
|
||||
| 算法 | 稳定性 | 时间复杂度 | 空间复杂度 | 备注 |
|
||||
| :---: | :---: |:---: | :---: | :---: |
|
||||
| 选择排序 | × | N<sup>2</sup> | 1 | |
|
||||
| 冒泡排序 | √ | N<sup>2</sup> | 1 | |
|
||||
| 插入排序 | √ | N \~ N<sup>2</sup> | 1 | 时间复杂度和初始顺序有关 |
|
||||
| 希尔排序 | × | N 的若干倍乘于递增序列的长度 | 1 | 改进版插入排序 |
|
||||
| 快速排序 | × | NlogN | logN | |
|
||||
| 三向切分快速排序 | × | N \~ NlogN | logN | 适用于有大量重复主键|
|
||||
| 归并排序 | √ | NlogN | N | |
|
||||
| 堆排序 | × | NlogN | 1 | 无法利用局部性原理|
|
||||
| 算法 | 稳定性 | 时间复杂度 | 空间复杂度 | 备注 |
|
||||
| :------: | :-: | :-------------: | :---: | :----------: |
|
||||
| 选择排序 | × | N2 | 1 | |
|
||||
| 冒泡排序 | √ | N2 | 1 | |
|
||||
| 插入排序 | √ | N \~ N2 | 1 | 时间复杂度和初始顺序有关 |
|
||||
| 希尔排序 | × | N 的若干倍乘于递增序列的长度 | 1 | 改进版插入排序 |
|
||||
| 快速排序 | × | NlogN | logN | |
|
||||
| 三向切分快速排序 | × | N \~ NlogN | logN | 适用于有大量重复主键 |
|
||||
| 归并排序 | √ | NlogN | N | |
|
||||
| 堆排序 | × | NlogN | 1 | 无法利用局部性原理 |
|
||||
|
||||
快速排序是最快的通用排序算法,它的内循环的指令很少,而且它还能利用缓存,因为它总是顺序地访问数据。它的运行时间近似为 \~cNlogN,这里的 c 比其它线性对数级别的排序算法都要小。
|
||||
|
||||
@ -551,4 +561,4 @@ public class HeapSort<T extends Comparable<T>> extends Sort<T> {
|
||||
|
||||
### 2. Java 的排序算法实现
|
||||
|
||||
Java 主要排序方法为 java.util.Arrays.sort(),对于原始数据类型使用三向切分的快速排序,对于引用类型使用归并排序。
|
||||
Java 主要排序方法为 java.util.Arrays.sort(),对于原始数据类型使用三向切分的快速排序,对于引用类型使用归并排序。
|
||||
|
||||
@ -1,40 +1,38 @@
|
||||
# 算法 - 符号表
|
||||
<!-- GFM-TOC -->
|
||||
* [算法 - 符号表](#算法---符号表)
|
||||
* [前言](#前言)
|
||||
* [初级实现](#初级实现)
|
||||
* [1. 链表实现无序符号表](#1-链表实现无序符号表)
|
||||
* [2. 二分查找实现有序符号表](#2-二分查找实现有序符号表)
|
||||
* [二叉查找树](#二叉查找树)
|
||||
* [1. get()](#1-get)
|
||||
* [2. put()](#2-put)
|
||||
* [3. 分析](#3-分析)
|
||||
* [4. floor()](#4-floor)
|
||||
* [5. rank()](#5-rank)
|
||||
* [6. min()](#6-min)
|
||||
* [7. deleteMin()](#7-deletemin)
|
||||
* [8. delete()](#8-delete)
|
||||
* [9. keys()](#9-keys)
|
||||
* [10. 分析](#10-分析)
|
||||
* [2-3 查找树](#2-3-查找树)
|
||||
* [1. 插入操作](#1-插入操作)
|
||||
* [2. 性质](#2-性质)
|
||||
* [红黑树](#红黑树)
|
||||
* [1. 左旋转](#1-左旋转)
|
||||
* [2. 右旋转](#2-右旋转)
|
||||
* [3. 颜色转换](#3-颜色转换)
|
||||
* [4. 插入](#4-插入)
|
||||
* [5. 分析](#5-分析)
|
||||
* [散列表](#散列表)
|
||||
* [1. 散列函数](#1-散列函数)
|
||||
* [2. 拉链法](#2-拉链法)
|
||||
* [3. 线性探测法](#3-线性探测法)
|
||||
* [小结](#小结)
|
||||
* [1. 符号表算法比较](#1-符号表算法比较)
|
||||
* [2. Java 的符号表实现](#2-java-的符号表实现)
|
||||
* [3. 稀疏向量乘法](#3-稀疏向量乘法)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [算法 - 符号表](<算法 - 符号表.md#算法---符号表>)
|
||||
* [前言](<算法 - 符号表.md#前言>)
|
||||
* [初级实现](<算法 - 符号表.md#初级实现>)
|
||||
* [1. 链表实现无序符号表](<算法 - 符号表.md#1-链表实现无序符号表>)
|
||||
* [2. 二分查找实现有序符号表](<算法 - 符号表.md#2-二分查找实现有序符号表>)
|
||||
* [二叉查找树](<算法 - 符号表.md#二叉查找树>)
|
||||
* [1. get()](<算法 - 符号表.md#1-get>)
|
||||
* [2. put()](<算法 - 符号表.md#2-put>)
|
||||
* [3. 分析](<算法 - 符号表.md#3-分析>)
|
||||
* [4. floor()](<算法 - 符号表.md#4-floor>)
|
||||
* [5. rank()](<算法 - 符号表.md#5-rank>)
|
||||
* [6. min()](<算法 - 符号表.md#6-min>)
|
||||
* [7. deleteMin()](<算法 - 符号表.md#7-deletemin>)
|
||||
* [8. delete()](<算法 - 符号表.md#8-delete>)
|
||||
* [9. keys()](<算法 - 符号表.md#9-keys>)
|
||||
* [10. 分析](<算法 - 符号表.md#10-分析>)
|
||||
* [2-3 查找树](<算法 - 符号表.md#2-3-查找树>)
|
||||
* [1. 插入操作](<算法 - 符号表.md#1-插入操作>)
|
||||
* [2. 性质](<算法 - 符号表.md#2-性质>)
|
||||
* [红黑树](<算法 - 符号表.md#红黑树>)
|
||||
* [1. 左旋转](<算法 - 符号表.md#1-左旋转>)
|
||||
* [2. 右旋转](<算法 - 符号表.md#2-右旋转>)
|
||||
* [3. 颜色转换](<算法 - 符号表.md#3-颜色转换>)
|
||||
* [4. 插入](<算法 - 符号表.md#4-插入>)
|
||||
* [5. 分析](<算法 - 符号表.md#5-分析>)
|
||||
* [散列表](<算法 - 符号表.md#散列表>)
|
||||
* [1. 散列函数](<算法 - 符号表.md#1-散列函数>)
|
||||
* [2. 拉链法](<算法 - 符号表.md#2-拉链法>)
|
||||
* [3. 线性探测法](<算法 - 符号表.md#3-线性探测法>)
|
||||
* [小结](<算法 - 符号表.md#小结>)
|
||||
* [1. 符号表算法比较](<算法 - 符号表.md#1-符号表算法比较>)
|
||||
* [2. Java 的符号表实现](<算法 - 符号表.md#2-java-的符号表实现>)
|
||||
* [3. 稀疏向量乘法](<算法 - 符号表.md#3-稀疏向量乘法>)
|
||||
|
||||
## 前言
|
||||
|
||||
@ -245,15 +243,17 @@ public class BinarySearchOrderedST<Key extends Comparable<Key>, Value> implement
|
||||
|
||||
## 二叉查找树
|
||||
|
||||
**二叉树** 是一个空链接,或者是一个有左右两个链接的节点,每个链接都指向一颗子二叉树。
|
||||
**二叉树** 是一个空链接,或者是一个有左右两个链接的节点,每个链接都指向一颗子二叉树。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/c11528f6-fc71-4a2b-8d2f-51b8954c38f1.jpg" width="180"/> </div><br>
|
||||
\
|
||||
|
||||
**二叉查找树** (BST)是一颗二叉树,并且每个节点的值都大于等于其左子树中的所有节点的值而小于等于右子树的所有节点的值。
|
||||
|
||||
**二叉查找树** (BST)是一颗二叉树,并且每个节点的值都大于等于其左子树中的所有节点的值而小于等于右子树的所有节点的值。
|
||||
|
||||
BST 有一个重要性质,就是它的中序遍历结果递增排序。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/ef552ae3-ae0d-4217-88e6-99cbe8163f0c.jpg" width="200"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
基本数据结构:
|
||||
|
||||
@ -300,9 +300,9 @@ public class BST<Key extends Comparable<Key>, Value> implements OrderedST<Key, V
|
||||
|
||||
### 1. get()
|
||||
|
||||
- 如果树是空的,则查找未命中;
|
||||
- 如果被查找的键和根节点的键相等,查找命中;
|
||||
- 否则递归地在子树中查找:如果被查找的键较小就在左子树中查找,较大就在右子树中查找。
|
||||
* 如果树是空的,则查找未命中;
|
||||
* 如果被查找的键和根节点的键相等,查找命中;
|
||||
* 否则递归地在子树中查找:如果被查找的键较小就在左子树中查找,较大就在右子树中查找。
|
||||
|
||||
```java
|
||||
@Override
|
||||
@ -327,7 +327,8 @@ private Value get(Node x, Key key) {
|
||||
|
||||
当插入的键不存在于树中,需要创建一个新节点,并且更新上层节点的链接指向该节点,使得该节点正确地链接到树中。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/58b70113-3876-49af-85a9-68eb00a72d59.jpg" width="200"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```java
|
||||
@Override
|
||||
@ -356,18 +357,20 @@ private Node put(Node x, Key key, Value value) {
|
||||
|
||||
最好的情况下树是完全平衡的,每条空链接和根节点的距离都为 logN。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/c395a428-827c-405b-abd7-8a069316f583.jpg" width="200"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
在最坏的情况下,树的高度为 N。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/5ea609cb-8ad4-4c4c-aee6-45a40a81794a.jpg" width="200"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### 4. floor()
|
||||
|
||||
floor(key):小于等于键的最大键
|
||||
|
||||
- 如果键小于根节点的键,那么 floor(key) 一定在左子树中;
|
||||
- 如果键大于根节点的键,需要先判断右子树中是否存在 floor(key),如果存在就返回,否则根节点就是 floor(key)。
|
||||
* 如果键小于根节点的键,那么 floor(key) 一定在左子树中;
|
||||
* 如果键大于根节点的键,需要先判断右子树中是否存在 floor(key),如果存在就返回,否则根节点就是 floor(key)。
|
||||
|
||||
```java
|
||||
public Key floor(Key key) {
|
||||
@ -394,9 +397,9 @@ private Node floor(Node x, Key key) {
|
||||
|
||||
rank(key) 返回 key 的排名。
|
||||
|
||||
- 如果键和根节点的键相等,返回左子树的节点数;
|
||||
- 如果小于,递归计算在左子树中的排名;
|
||||
- 如果大于,递归计算在右子树中的排名,加上左子树的节点数,再加上 1(根节点)。
|
||||
* 如果键和根节点的键相等,返回左子树的节点数;
|
||||
* 如果小于,递归计算在左子树中的排名;
|
||||
* 如果大于,递归计算在右子树中的排名,加上左子树的节点数,再加上 1(根节点)。
|
||||
|
||||
```java
|
||||
@Override
|
||||
@ -438,7 +441,8 @@ private Node min(Node x) {
|
||||
|
||||
令指向最小节点的链接指向最小节点的右子树。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/31b7e8de-ed11-4f69-b5fd-ba454120ac31.jpg" width="450"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```java
|
||||
public void deleteMin() {
|
||||
@ -456,10 +460,11 @@ public Node deleteMin(Node x) {
|
||||
|
||||
### 8. delete()
|
||||
|
||||
- 如果待删除的节点只有一个子树, 那么只需要让指向待删除节点的链接指向唯一的子树即可;
|
||||
- 否则,让右子树的最小节点替换该节点。
|
||||
* 如果待删除的节点只有一个子树, 那么只需要让指向待删除节点的链接指向唯一的子树即可;
|
||||
* 否则,让右子树的最小节点替换该节点。
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/23b9d625-ef28-42b5-bb22-d7aedd007e16.jpg" width="400"/> </div><br>
|
||||
|
||||
```java
|
||||
public void delete(Key key) {
|
||||
@ -522,7 +527,8 @@ private List<Key> keys(Node x, Key l, Key h) {
|
||||
|
||||
2-3 查找树引入了 2- 节点和 3- 节点,目的是为了让树平衡。一颗完美平衡的 2-3 查找树的所有空链接到根节点的距离应该是相同的。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/1097658b-c0e6-4821-be9b-25304726a11c.jpg" width="160px"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### 1. 插入操作
|
||||
|
||||
@ -530,13 +536,15 @@ private List<Key> keys(Node x, Key l, Key h) {
|
||||
|
||||
根据叶子节点的类型不同,有不同的处理方式:
|
||||
|
||||
- 如果插入到 2- 节点上,那么直接将新节点和原来的节点组成 3- 节点即可。
|
||||
* 如果插入到 2- 节点上,那么直接将新节点和原来的节点组成 3- 节点即可。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/0c6f9930-8704-4a54-af23-19f9ca3e48b0.jpg" width="350"/> </div><br>
|
||||
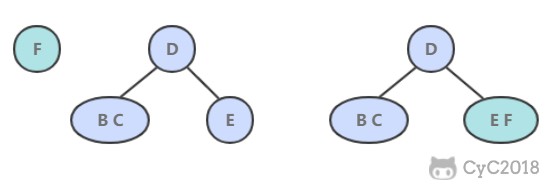\
|
||||
|
||||
- 如果是插入到 3- 节点上,就会产生一个临时 4- 节点时,需要将 4- 节点分裂成 3 个 2- 节点,并将中间的 2- 节点移到上层节点中。如果上移操作继续产生临时 4- 节点则一直进行分裂上移,直到不存在临时 4- 节点。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/7002c01b-1ed5-475a-9e5f-5fc8a4cdbcc0.jpg" width="460"/> </div><br>
|
||||
* 如果是插入到 3- 节点上,就会产生一个临时 4- 节点时,需要将 4- 节点分裂成 3 个 2- 节点,并将中间的 2- 节点移到上层节点中。如果上移操作继续产生临时 4- 节点则一直进行分裂上移,直到不存在临时 4- 节点。
|
||||
|
||||
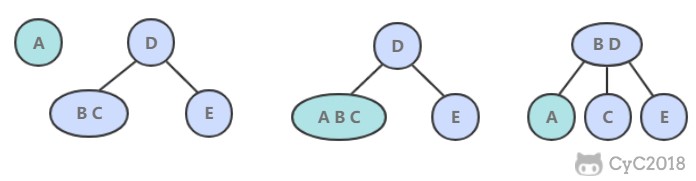\
|
||||
|
||||
|
||||
### 2. 性质
|
||||
|
||||
@ -548,16 +556,18 @@ private List<Key> keys(Node x, Key l, Key h) {
|
||||
|
||||
红黑树是 2-3 查找树,但它不需要分别定义 2- 节点和 3- 节点,而是在普通的二叉查找树之上,为节点添加颜色。指向一个节点的链接颜色如果为红色,那么这个节点和上层节点表示的是一个 3- 节点,而黑色则是普通链接。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/f1912ba6-6402-4321-9aa8-13d32fd121d1.jpg" width="240"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
红黑树具有以下性质:
|
||||
|
||||
- 红链接都为左链接;
|
||||
- 完美黑色平衡,即任意空链接到根节点的路径上的黑链接数量相同。
|
||||
* 红链接都为左链接;
|
||||
* 完美黑色平衡,即任意空链接到根节点的路径上的黑链接数量相同。
|
||||
|
||||
画红黑树时可以将红链接画平。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/f5cb6028-425d-4939-91eb-cca9dd6b6c6c.jpg" width="220"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```java
|
||||
public class RedBlackBST<Key extends Comparable<Key>, Value> extends BST<Key, Value> {
|
||||
@ -577,7 +587,8 @@ public class RedBlackBST<Key extends Comparable<Key>, Value> extends BST<Key, Va
|
||||
|
||||
因为合法的红链接都为左链接,如果出现右链接为红链接,那么就需要进行左旋转操作。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/f4d534ab-0092-4a81-9e5b-ae889b9a72be.jpg" width="480"/> </div><br>
|
||||
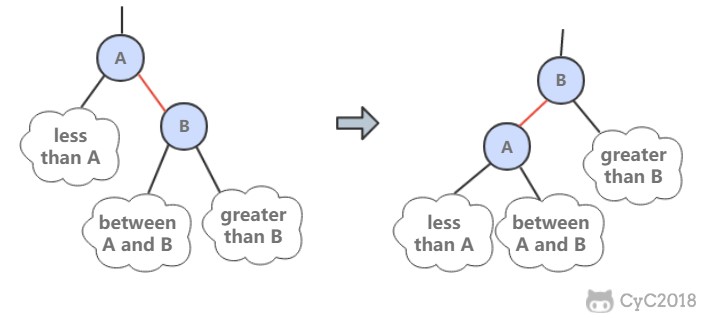\
|
||||
|
||||
|
||||
```java
|
||||
public Node rotateLeft(Node h) {
|
||||
@ -596,7 +607,8 @@ public Node rotateLeft(Node h) {
|
||||
|
||||
进行右旋转是为了转换两个连续的左红链接,这会在之后的插入过程中探讨。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/63c8ffea-a9f2-4ebe-97d1-d71be71246f9.jpg" width="480"/> </div><br>
|
||||
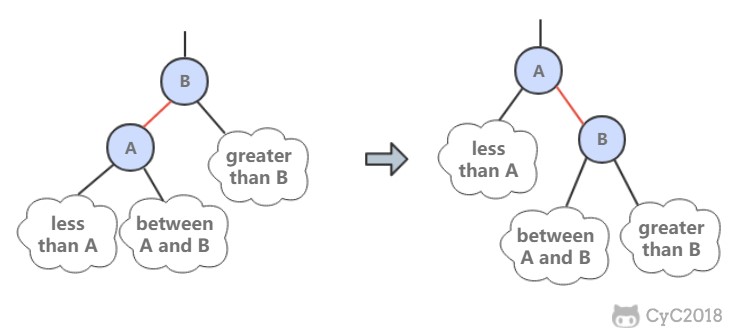\
|
||||
|
||||
|
||||
```java
|
||||
public Node rotateRight(Node h) {
|
||||
@ -615,7 +627,8 @@ public Node rotateRight(Node h) {
|
||||
|
||||
一个 4- 节点在红黑树中表现为一个节点的左右子节点都是红色的。分裂 4- 节点除了需要将子节点的颜色由红变黑之外,同时需要将父节点的颜色由黑变红,从 2-3 树的角度看就是将中间节点移到上层节点。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/094b279a-b2db-4be7-87a3-b2a039c7448e.jpg" width="270"/> </div><br>
|
||||
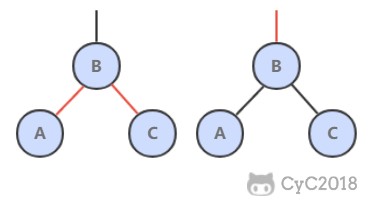\
|
||||
|
||||
|
||||
```java
|
||||
void flipColors(Node h) {
|
||||
@ -629,11 +642,12 @@ void flipColors(Node h) {
|
||||
|
||||
先将一个节点按二叉查找树的方法插入到正确位置,然后再进行如下颜色操作:
|
||||
|
||||
- 如果右子节点是红色的而左子节点是黑色的,进行左旋转;
|
||||
- 如果左子节点是红色的,而且左子节点的左子节点也是红色的,进行右旋转;
|
||||
- 如果左右子节点均为红色的,进行颜色转换。
|
||||
* 如果右子节点是红色的而左子节点是黑色的,进行左旋转;
|
||||
* 如果左子节点是红色的,而且左子节点的左子节点也是红色的,进行右旋转;
|
||||
* 如果左右子节点均为红色的,进行颜色转换。
|
||||
|
||||
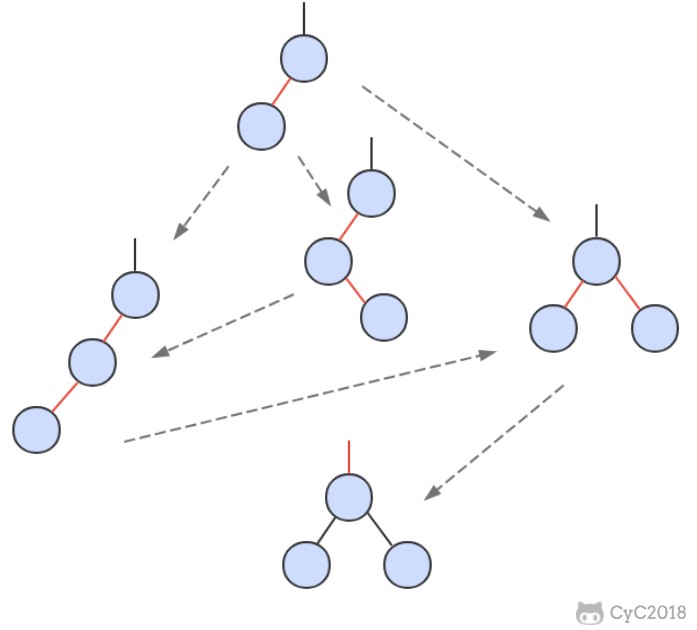\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/4c457532-550b-4eca-b881-037b84b4934b.jpg" width="430"/> </div><br>
|
||||
|
||||
```java
|
||||
@Override
|
||||
@ -686,17 +700,17 @@ private Node put(Node x, Key key, Value value) {
|
||||
|
||||
### 1. 散列函数
|
||||
|
||||
对于一个大小为 M 的散列表,散列函数能够把任意键转换为 [0, M-1] 内的正整数,该正整数即为 hash 值。
|
||||
对于一个大小为 M 的散列表,散列函数能够把任意键转换为 \[0, M-1] 内的正整数,该正整数即为 hash 值。
|
||||
|
||||
散列表存在冲突,也就是两个不同的键可能有相同的 hash 值。
|
||||
|
||||
散列函数应该满足以下三个条件:
|
||||
|
||||
- 一致性:相等的键应当有相等的 hash 值,两个键相等表示调用 equals() 返回的值相等。
|
||||
- 高效性:计算应当简便,有必要的话可以把 hash 值缓存起来,在调用 hash 函数时直接返回。
|
||||
- 均匀性:所有键的 hash 值应当均匀地分布到 [0, M-1] 之间,如果不能满足这个条件,有可能产生很多冲突,从而导致散列表的性能下降。
|
||||
* 一致性:相等的键应当有相等的 hash 值,两个键相等表示调用 equals() 返回的值相等。
|
||||
* 高效性:计算应当简便,有必要的话可以把 hash 值缓存起来,在调用 hash 函数时直接返回。
|
||||
* 均匀性:所有键的 hash 值应当均匀地分布到 \[0, M-1] 之间,如果不能满足这个条件,有可能产生很多冲突,从而导致散列表的性能下降。
|
||||
|
||||
除留余数法可以将整数散列到 [0, M-1] 之间,例如一个正整数 k,计算 k%M 既可得到一个 [0, M-1] 之间的 hash 值。注意 M 最好是一个素数,否则无法利用键包含的所有信息。例如 M 为 10<sup>k</sup>,那么只能利用键的后 k 位。
|
||||
除留余数法可以将整数散列到 \[0, M-1] 之间,例如一个正整数 k,计算 k%M 既可得到一个 \[0, M-1] 之间的 hash 值。注意 M 最好是一个素数,否则无法利用键包含的所有信息。例如 M 为 10k,那么只能利用键的后 k 位。
|
||||
|
||||
对于其它数,可以将其转换成整数的形式,然后利用除留余数法。例如对于浮点数,可以将其的二进制形式转换成整数。
|
||||
|
||||
@ -756,18 +770,19 @@ public class Transaction {
|
||||
|
||||
查找需要分两步,首先查找 Key 所在的链表,然后在链表中顺序查找。
|
||||
|
||||
对于 N 个键,M 条链表 (N\>M),如果哈希函数能够满足均匀性的条件,每条链表的大小趋向于 N/M,因此未命中的查找和插入操作所需要的比较次数为 \~N/M。
|
||||
对于 N 个键,M 条链表 (N>M),如果哈希函数能够满足均匀性的条件,每条链表的大小趋向于 N/M,因此未命中的查找和插入操作所需要的比较次数为 \~N/M。
|
||||
|
||||
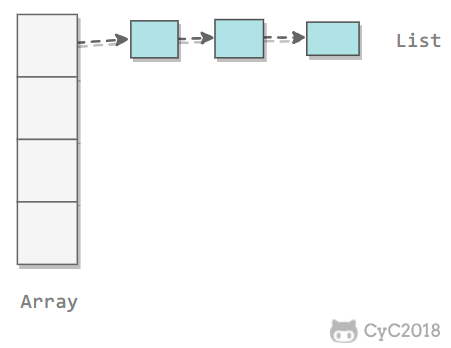\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/cbbfe06c-f0cb-47c4-bf7b-2780aebd98b2.png" width="330px"> </div><br>
|
||||
|
||||
### 3. 线性探测法
|
||||
|
||||
线性探测法使用空位来解决冲突,当冲突发生时,向前探测一个空位来存储冲突的键。
|
||||
|
||||
使用线性探测法,数组的大小 M 应当大于键的个数 N(M\>N)。
|
||||
使用线性探测法,数组的大小 M 应当大于键的个数 N(M>N)。
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/0dbc4f7d-05c9-4aae-8065-7b7ea7e9709e.gif" width="350px"> </div><br>
|
||||
|
||||
```java
|
||||
public class LinearProbingHashST<Key, Value> implements UnorderedST<Key, Value> {
|
||||
@ -797,7 +812,7 @@ public class LinearProbingHashST<Key, Value> implements UnorderedST<Key, Value>
|
||||
}
|
||||
```
|
||||
|
||||
##### 3.1 查找
|
||||
**3.1 查找**
|
||||
|
||||
```java
|
||||
public Value get(Key key) {
|
||||
@ -809,7 +824,7 @@ public Value get(Key key) {
|
||||
}
|
||||
```
|
||||
|
||||
##### 3.2 插入
|
||||
**3.2 插入**
|
||||
|
||||
```java
|
||||
public void put(Key key, Value value) {
|
||||
@ -831,7 +846,7 @@ private void putInternal(Key key, Value value) {
|
||||
}
|
||||
```
|
||||
|
||||
##### 3.3 删除
|
||||
**3.3 删除**
|
||||
|
||||
删除操作应当将右侧所有相邻的键值对重新插入散列表中。
|
||||
|
||||
@ -864,14 +879,14 @@ public void delete(Key key) {
|
||||
}
|
||||
```
|
||||
|
||||
##### 3.5 调整数组大小
|
||||
**3.5 调整数组大小**
|
||||
|
||||
线性探测法的成本取决于连续条目的长度,连续条目也叫聚簇。当聚簇很长时,在查找和插入时也需要进行很多次探测。例如下图中 2\~4 位置就是一个聚簇。
|
||||
|
||||
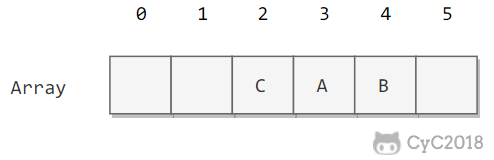\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/ace20410-f053-4c4a-aca4-2c603ff11bbe.png" width="340px"> </div><br>
|
||||
|
||||
α = N/M,把 α 称为使用率。理论证明,当 α 小于 1/2 时探测的预计次数只在 1.5 到 2.5 之间。为了保证散列表的性能,应当调整数组的大小,使得 α 在 [1/4, 1/2] 之间。
|
||||
α = N/M,把 α 称为使用率。理论证明,当 α 小于 1/2 时探测的预计次数只在 1.5 到 2.5 之间。为了保证散列表的性能,应当调整数组的大小,使得 α 在 \[1/4, 1/2] 之间。
|
||||
|
||||
```java
|
||||
private void resize() {
|
||||
@ -897,21 +912,21 @@ private void resize(int cap) {
|
||||
|
||||
### 1. 符号表算法比较
|
||||
|
||||
| 算法 | 插入 | 查找 | 是否有序 |
|
||||
| :---: | :---: | :---: | :---: |
|
||||
| 链表实现的无序符号表 | N | N | yes |
|
||||
| 二分查找实现的有序符号表 | N | logN | yes |
|
||||
| 二叉查找树 | logN | logN | yes |
|
||||
| 2-3 查找树 | logN | logN | yes |
|
||||
| 拉链法实现的散列表 | N/M | N/M | no |
|
||||
| 线性探测法实现的散列表 | 1 | 1 | no |
|
||||
| 算法 | 插入 | 查找 | 是否有序 |
|
||||
| :----------: | :--: | :--: | :--: |
|
||||
| 链表实现的无序符号表 | N | N | yes |
|
||||
| 二分查找实现的有序符号表 | N | logN | yes |
|
||||
| 二叉查找树 | logN | logN | yes |
|
||||
| 2-3 查找树 | logN | logN | yes |
|
||||
| 拉链法实现的散列表 | N/M | N/M | no |
|
||||
| 线性探测法实现的散列表 | 1 | 1 | no |
|
||||
|
||||
应当优先考虑散列表,当需要有序性操作时使用红黑树。
|
||||
|
||||
### 2. Java 的符号表实现
|
||||
|
||||
- java.util.TreeMap:红黑树
|
||||
- java.util.HashMap:拉链法的散列表
|
||||
* java.util.TreeMap:红黑树
|
||||
* java.util.HashMap:拉链法的散列表
|
||||
|
||||
### 3. 稀疏向量乘法
|
||||
|
||||
|
||||
84
notes/缓存.md
84
notes/缓存.md
@ -1,16 +1,14 @@
|
||||
# 缓存
|
||||
<!-- GFM-TOC -->
|
||||
* [缓存](#缓存)
|
||||
* [一、缓存特征](#一缓存特征)
|
||||
* [二、缓存位置](#二缓存位置)
|
||||
* [三、CDN](#三cdn)
|
||||
* [四、缓存问题](#四缓存问题)
|
||||
* [五、数据分布](#五数据分布)
|
||||
* [六、一致性哈希](#六一致性哈希)
|
||||
* [七、LRU](#七lru)
|
||||
* [参考资料](#参考资料)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [缓存](缓存.md#缓存)
|
||||
* [一、缓存特征](缓存.md#一缓存特征)
|
||||
* [二、缓存位置](缓存.md#二缓存位置)
|
||||
* [三、CDN](缓存.md#三cdn)
|
||||
* [四、缓存问题](缓存.md#四缓存问题)
|
||||
* [五、数据分布](缓存.md#五数据分布)
|
||||
* [六、一致性哈希](缓存.md#六一致性哈希)
|
||||
* [七、LRU](缓存.md#七lru)
|
||||
* [参考资料](缓存.md#参考资料)
|
||||
|
||||
## 一、缓存特征
|
||||
|
||||
@ -28,11 +26,9 @@
|
||||
|
||||
### 淘汰策略
|
||||
|
||||
- FIFO(First In First Out):先进先出策略,在实时性的场景下,需要经常访问最新的数据,那么就可以使用 FIFO,使得最先进入的数据(最晚的数据)被淘汰。
|
||||
|
||||
- LRU(Least Recently Used):最近最久未使用策略,优先淘汰最久未使用的数据,也就是上次被访问时间距离现在最久的数据。该策略可以保证内存中的数据都是热点数据,也就是经常被访问的数据,从而保证缓存命中率。
|
||||
|
||||
- LFU(Least Frequently Used):最不经常使用策略,优先淘汰一段时间内使用次数最少的数据。
|
||||
* FIFO(First In First Out):先进先出策略,在实时性的场景下,需要经常访问最新的数据,那么就可以使用 FIFO,使得最先进入的数据(最晚的数据)被淘汰。
|
||||
* LRU(Least Recently Used):最近最久未使用策略,优先淘汰最久未使用的数据,也就是上次被访问时间距离现在最久的数据。该策略可以保证内存中的数据都是热点数据,也就是经常被访问的数据,从而保证缓存命中率。
|
||||
* LFU(Least Frequently Used):最不经常使用策略,优先淘汰一段时间内使用次数最少的数据。
|
||||
|
||||
## 二、缓存位置
|
||||
|
||||
@ -76,11 +72,12 @@ CPU 为了解决运算速度与主存 IO 速度不匹配的问题,引入了多
|
||||
|
||||
CDN 主要有以下优点:
|
||||
|
||||
- 更快地将数据分发给用户;
|
||||
- 通过部署多台服务器,从而提高系统整体的带宽性能;
|
||||
- 多台服务器可以看成是一种冗余机制,从而具有高可用性。
|
||||
* 更快地将数据分发给用户;
|
||||
* 通过部署多台服务器,从而提高系统整体的带宽性能;
|
||||
* 多台服务器可以看成是一种冗余机制,从而具有高可用性。
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/15313ed8-a520-4799-a300-2b6b36be314f.jpg"/> </div><br>
|
||||
|
||||
## 四、缓存问题
|
||||
|
||||
@ -90,8 +87,8 @@ CDN 主要有以下优点:
|
||||
|
||||
解决方案:
|
||||
|
||||
- 对这些不存在的数据缓存一个空数据;
|
||||
- 对这类请求进行过滤。
|
||||
* 对这些不存在的数据缓存一个空数据;
|
||||
* 对这类请求进行过滤。
|
||||
|
||||
### 缓存雪崩
|
||||
|
||||
@ -101,10 +98,9 @@ CDN 主要有以下优点:
|
||||
|
||||
解决方案:
|
||||
|
||||
- 为了防止缓存在同一时间大面积过期导致的缓存雪崩,可以通过观察用户行为,合理设置缓存过期时间来实现;
|
||||
- 为了防止缓存服务器宕机出现的缓存雪崩,可以使用分布式缓存,分布式缓存中每一个节点只缓存部分的数据,当某个节点宕机时可以保证其它节点的缓存仍然可用。
|
||||
- 也可以进行缓存预热,避免在系统刚启动不久由于还未将大量数据进行缓存而导致缓存雪崩。
|
||||
|
||||
* 为了防止缓存在同一时间大面积过期导致的缓存雪崩,可以通过观察用户行为,合理设置缓存过期时间来实现;
|
||||
* 为了防止缓存服务器宕机出现的缓存雪崩,可以使用分布式缓存,分布式缓存中每一个节点只缓存部分的数据,当某个节点宕机时可以保证其它节点的缓存仍然可用。
|
||||
* 也可以进行缓存预热,避免在系统刚启动不久由于还未将大量数据进行缓存而导致缓存雪崩。
|
||||
|
||||
### 缓存一致性
|
||||
|
||||
@ -112,8 +108,8 @@ CDN 主要有以下优点:
|
||||
|
||||
解决方案:
|
||||
|
||||
- 在数据更新的同时立即去更新缓存;
|
||||
- 在读缓存之前先判断缓存是否是最新的,如果不是最新的先进行更新。
|
||||
* 在数据更新的同时立即去更新缓存;
|
||||
* 在读缓存之前先判断缓存是否是最新的,如果不是最新的先进行更新。
|
||||
|
||||
要保证缓存一致性需要付出很大的代价,缓存数据最好是那些对一致性要求不高的数据,允许缓存数据存在一些脏数据。
|
||||
|
||||
@ -125,9 +121,9 @@ CDN 主要有以下优点:
|
||||
|
||||
解决方案:
|
||||
|
||||
- 优化批量数据操作命令;
|
||||
- 减少网络通信次数;
|
||||
- 降低接入成本,使用长连接 / 连接池,NIO 等。
|
||||
* 优化批量数据操作命令;
|
||||
* 减少网络通信次数;
|
||||
* 降低接入成本,使用长连接 / 连接池,NIO 等。
|
||||
|
||||
## 五、数据分布
|
||||
|
||||
@ -143,8 +139,8 @@ CDN 主要有以下优点:
|
||||
|
||||
顺序分布相比于哈希分布的主要优点如下:
|
||||
|
||||
- 能保持数据原有的顺序;
|
||||
- 并且能够准确控制每台服务器存储的数据量,从而使得存储空间的利用率最大。
|
||||
* 能保持数据原有的顺序;
|
||||
* 并且能够准确控制每台服务器存储的数据量,从而使得存储空间的利用率最大。
|
||||
|
||||
## 六、一致性哈希
|
||||
|
||||
@ -152,13 +148,15 @@ Distributed Hash Table(DHT) 是一种哈希分布方式,其目的是为了
|
||||
|
||||
### 基本原理
|
||||
|
||||
将哈希空间 [0, 2<sup>n</sup>-1] 看成一个哈希环,每个服务器节点都配置到哈希环上。每个数据对象通过哈希取模得到哈希值之后,存放到哈希环中顺时针方向第一个大于等于该哈希值的节点上。
|
||||
将哈希空间 \[0, 2n-1] 看成一个哈希环,每个服务器节点都配置到哈希环上。每个数据对象通过哈希取模得到哈希值之后,存放到哈希环中顺时针方向第一个大于等于该哈希值的节点上。
|
||||
|
||||
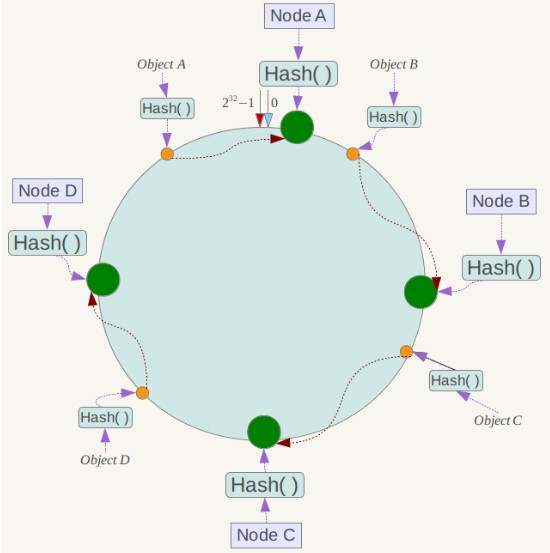\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/68b110b9-76c6-4ee2-b541-4145e65adb3e.jpg"/> </div><br>
|
||||
|
||||
一致性哈希在增加或者删除节点时只会影响到哈希环中相邻的节点,例如下图中新增节点 X,只需要将它前一个节点 C 上的数据重新进行分布即可,对于节点 A、B、D 都没有影响。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/66402828-fb2b-418f-83f6-82153491bcfe.jpg"/> </div><br>
|
||||
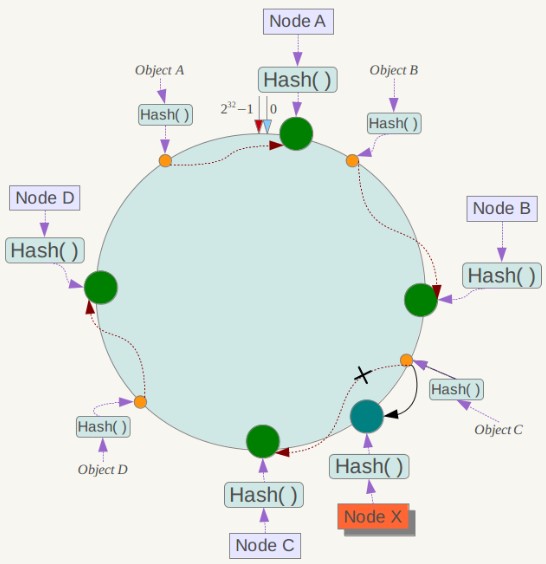\
|
||||
|
||||
|
||||
### 虚拟节点
|
||||
|
||||
@ -172,8 +170,8 @@ Distributed Hash Table(DHT) 是一种哈希分布方式,其目的是为了
|
||||
|
||||
以下是基于 双向链表 + HashMap 的 LRU 算法实现,对算法的解释如下:
|
||||
|
||||
- 访问某个节点时,将其从原来的位置删除,并重新插入到链表头部。这样就能保证链表尾部存储的就是最近最久未使用的节点,当节点数量大于缓存最大空间时就淘汰链表尾部的节点。
|
||||
- 为了使删除操作时间复杂度为 O(1),就不能采用遍历的方式找到某个节点。HashMap 存储着 Key 到节点的映射,通过 Key 就能以 O(1) 的时间得到节点,然后再以 O(1) 的时间将其从双向队列中删除。
|
||||
* 访问某个节点时,将其从原来的位置删除,并重新插入到链表头部。这样就能保证链表尾部存储的就是最近最久未使用的节点,当节点数量大于缓存最大空间时就淘汰链表尾部的节点。
|
||||
* 为了使删除操作时间复杂度为 O(1),就不能采用遍历的方式找到某个节点。HashMap 存储着 Key 到节点的映射,通过 Key 就能以 O(1) 的时间得到节点,然后再以 O(1) 的时间将其从双向队列中删除。
|
||||
|
||||
```java
|
||||
public class LRU<K, V> implements Iterable<K> {
|
||||
@ -303,8 +301,8 @@ public class LRU<K, V> implements Iterable<K> {
|
||||
|
||||
## 参考资料
|
||||
|
||||
- 大规模分布式存储系统
|
||||
- [缓存那些事](https://tech.meituan.com/cache_about.html)
|
||||
- [一致性哈希算法](https://my.oschina.net/jayhu/blog/732849)
|
||||
- [内容分发网络](https://zh.wikipedia.org/wiki/%E5%85%A7%E5%AE%B9%E5%82%B3%E9%81%9E%E7%B6%B2%E8%B7%AF)
|
||||
- [How Aspiration CDN helps to improve your website loading speed?](https://www.aspirationhosting.com/aspiration-cdn/)
|
||||
* 大规模分布式存储系统
|
||||
* [缓存那些事](https://tech.meituan.com/cache\_about.html)
|
||||
* [一致性哈希算法](https://my.oschina.net/jayhu/blog/732849)
|
||||
* [内容分发网络](https://zh.wikipedia.org/wiki/%E5%85%A7%E5%AE%B9%E5%82%B3%E9%81%9E%E7%B6%B2%E8%B7%AF)
|
||||
* [How Aspiration CDN helps to improve your website loading speed?](https://www.aspirationhosting.com/aspiration-cdn/)
|
||||
|
||||
@ -1,20 +1,18 @@
|
||||
# 计算机操作系统 - 内存管理
|
||||
<!-- GFM-TOC -->
|
||||
* [计算机操作系统 - 内存管理](#计算机操作系统---内存管理)
|
||||
* [虚拟内存](#虚拟内存)
|
||||
* [分页系统地址映射](#分页系统地址映射)
|
||||
* [页面置换算法](#页面置换算法)
|
||||
* [1. 最佳](#1-最佳)
|
||||
* [2. 最近最久未使用](#2-最近最久未使用)
|
||||
* [3. 最近未使用](#3-最近未使用)
|
||||
* [4. 先进先出](#4-先进先出)
|
||||
* [5. 第二次机会算法](#5-第二次机会算法)
|
||||
* [6. 时钟](#6-时钟)
|
||||
* [分段](#分段)
|
||||
* [段页式](#段页式)
|
||||
* [分页与分段的比较](#分页与分段的比较)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [计算机操作系统 - 内存管理](<计算机操作系统 - 内存管理.md#计算机操作系统---内存管理>)
|
||||
* [虚拟内存](<计算机操作系统 - 内存管理.md#虚拟内存>)
|
||||
* [分页系统地址映射](<计算机操作系统 - 内存管理.md#分页系统地址映射>)
|
||||
* [页面置换算法](<计算机操作系统 - 内存管理.md#页面置换算法>)
|
||||
* [1. 最佳](<计算机操作系统 - 内存管理.md#1-最佳>)
|
||||
* [2. 最近最久未使用](<计算机操作系统 - 内存管理.md#2-最近最久未使用>)
|
||||
* [3. 最近未使用](<计算机操作系统 - 内存管理.md#3-最近未使用>)
|
||||
* [4. 先进先出](<计算机操作系统 - 内存管理.md#4-先进先出>)
|
||||
* [5. 第二次机会算法](<计算机操作系统 - 内存管理.md#5-第二次机会算法>)
|
||||
* [6. 时钟](<计算机操作系统 - 内存管理.md#6-时钟>)
|
||||
* [分段](<计算机操作系统 - 内存管理.md#分段>)
|
||||
* [段页式](<计算机操作系统 - 内存管理.md#段页式>)
|
||||
* [分页与分段的比较](<计算机操作系统 - 内存管理.md#分页与分段的比较>)
|
||||
|
||||
## 虚拟内存
|
||||
|
||||
@ -24,7 +22,8 @@
|
||||
|
||||
从上面的描述中可以看出,虚拟内存允许程序不用将地址空间中的每一页都映射到物理内存,也就是说一个程序不需要全部调入内存就可以运行,这使得有限的内存运行大程序成为可能。例如有一台计算机可以产生 16 位地址,那么一个程序的地址空间范围是 0\~64K。该计算机只有 32KB 的物理内存,虚拟内存技术允许该计算机运行一个 64K 大小的程序。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/7b281b1e-0595-402b-ae35-8c91084c33c1.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 分页系统地址映射
|
||||
|
||||
@ -34,7 +33,8 @@
|
||||
|
||||
下图的页表存放着 16 个页,这 16 个页需要用 4 个比特位来进行索引定位。例如对于虚拟地址(0010 000000000100),前 4 位是存储页面号 2,读取表项内容为(110 1),页表项最后一位表示是否存在于内存中,1 表示存在。后 12 位存储偏移量。这个页对应的页框的地址为 (110 000000000100)。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/cf4386a1-58c9-4eca-a17f-e12b1e9770eb.png" width="500"/> </div><br>
|
||||
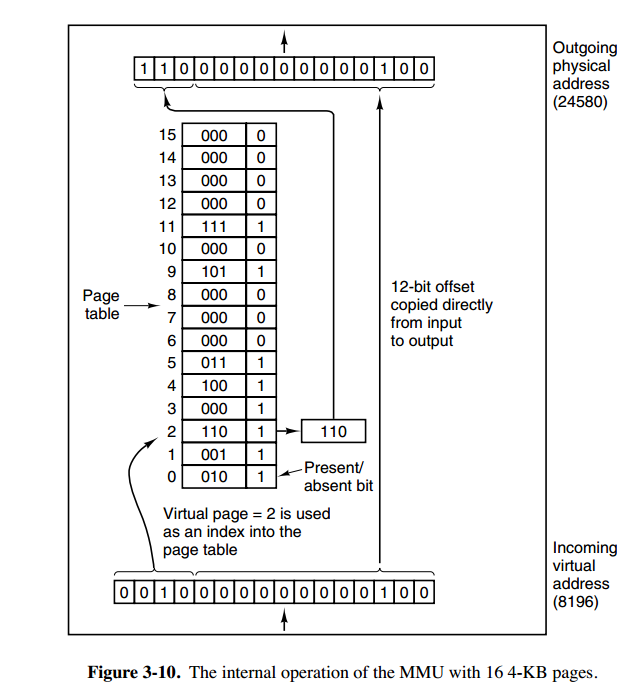\
|
||||
|
||||
|
||||
## 页面置换算法
|
||||
|
||||
@ -74,17 +74,17 @@
|
||||
4,7,0,7,1,0,1,2,1,2,6
|
||||
```
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/eb859228-c0f2-4bce-910d-d9f76929352b.png"/> </div><br>
|
||||
### 3. 最近未使用
|
||||
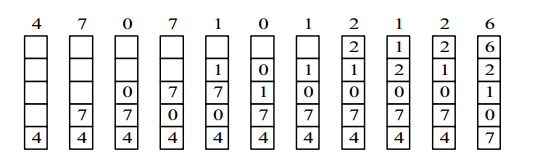\
|
||||
\### 3. 最近未使用
|
||||
|
||||
> NRU, Not Recently Used
|
||||
|
||||
每个页面都有两个状态位:R 与 M,当页面被访问时设置页面的 R=1,当页面被修改时设置 M=1。其中 R 位会定时被清零。可以将页面分成以下四类:
|
||||
|
||||
- R=0,M=0
|
||||
- R=0,M=1
|
||||
- R=1,M=0
|
||||
- R=1,M=1
|
||||
* R=0,M=0
|
||||
* R=0,M=1
|
||||
* R=1,M=0
|
||||
* R=1,M=1
|
||||
|
||||
当发生缺页中断时,NRU 算法随机地从类编号最小的非空类中挑选一个页面将它换出。
|
||||
|
||||
@ -104,7 +104,8 @@ FIFO 算法可能会把经常使用的页面置换出去,为了避免这一问
|
||||
|
||||
当页面被访问 (读或写) 时设置该页面的 R 位为 1。需要替换的时候,检查最老页面的 R 位。如果 R 位是 0,那么这个页面既老又没有被使用,可以立刻置换掉;如果是 1,就将 R 位清 0,并把该页面放到链表的尾端,修改它的装入时间使它就像刚装入的一样,然后继续从链表的头部开始搜索。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/ecf8ad5d-5403-48b9-b6e7-f2e20ffe8fca.png"/> </div><br>
|
||||
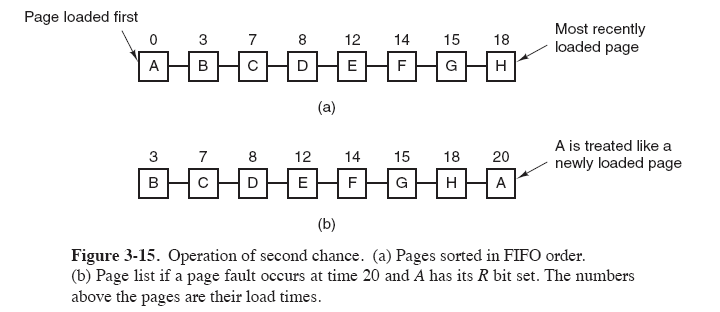\
|
||||
|
||||
|
||||
### 6. 时钟
|
||||
|
||||
@ -112,7 +113,8 @@ FIFO 算法可能会把经常使用的页面置换出去,为了避免这一问
|
||||
|
||||
第二次机会算法需要在链表中移动页面,降低了效率。时钟算法使用环形链表将页面连接起来,再使用一个指针指向最老的页面。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/5f5ef0b6-98ea-497c-a007-f6c55288eab1.png"/> </div><br>
|
||||
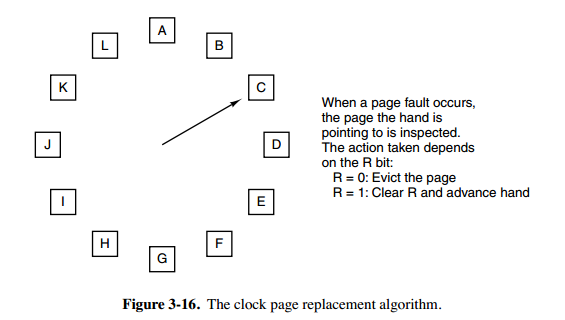\
|
||||
|
||||
|
||||
## 分段
|
||||
|
||||
@ -120,11 +122,13 @@ FIFO 算法可能会把经常使用的页面置换出去,为了避免这一问
|
||||
|
||||
下图为一个编译器在编译过程中建立的多个表,有 4 个表是动态增长的,如果使用分页系统的一维地址空间,动态增长的特点会导致覆盖问题的出现。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/22de0538-7c6e-4365-bd3b-8ce3c5900216.png"/> </div><br>
|
||||
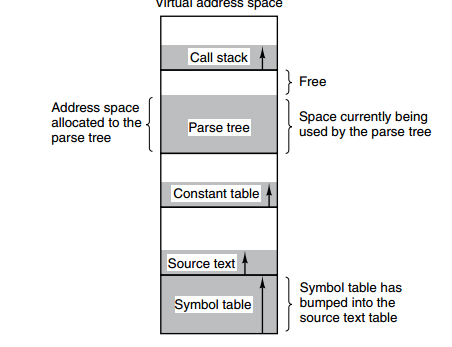\
|
||||
|
||||
|
||||
分段的做法是把每个表分成段,一个段构成一个独立的地址空间。每个段的长度可以不同,并且可以动态增长。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/e0900bb2-220a-43b7-9aa9-1d5cd55ff56e.png"/> </div><br>
|
||||
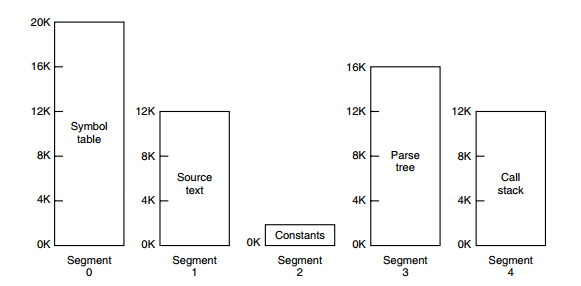\
|
||||
|
||||
|
||||
## 段页式
|
||||
|
||||
@ -132,10 +136,7 @@ FIFO 算法可能会把经常使用的页面置换出去,为了避免这一问
|
||||
|
||||
## 分页与分段的比较
|
||||
|
||||
- 对程序员的透明性:分页透明,但是分段需要程序员显式划分每个段。
|
||||
|
||||
- 地址空间的维度:分页是一维地址空间,分段是二维的。
|
||||
|
||||
- 大小是否可以改变:页的大小不可变,段的大小可以动态改变。
|
||||
|
||||
- 出现的原因:分页主要用于实现虚拟内存,从而获得更大的地址空间;分段主要是为了使程序和数据可以被划分为逻辑上独立的地址空间并且有助于共享和保护。
|
||||
* 对程序员的透明性:分页透明,但是分段需要程序员显式划分每个段。
|
||||
* 地址空间的维度:分页是一维地址空间,分段是二维的。
|
||||
* 大小是否可以改变:页的大小不可变,段的大小可以动态改变。
|
||||
* 出现的原因:分页主要用于实现虚拟内存,从而获得更大的地址空间;分段主要是为了使程序和数据可以被划分为逻辑上独立的地址空间并且有助于共享和保护。
|
||||
|
||||
@ -1,26 +1,24 @@
|
||||
# 计算机操作系统 - 概述
|
||||
<!-- GFM-TOC -->
|
||||
* [计算机操作系统 - 概述](#计算机操作系统---概述)
|
||||
* [基本特征](#基本特征)
|
||||
* [1. 并发](#1-并发)
|
||||
* [2. 共享](#2-共享)
|
||||
* [3. 虚拟](#3-虚拟)
|
||||
* [4. 异步](#4-异步)
|
||||
* [基本功能](#基本功能)
|
||||
* [1. 进程管理](#1-进程管理)
|
||||
* [2. 内存管理](#2-内存管理)
|
||||
* [3. 文件管理](#3-文件管理)
|
||||
* [4. 设备管理](#4-设备管理)
|
||||
* [系统调用](#系统调用)
|
||||
* [宏内核和微内核](#宏内核和微内核)
|
||||
* [1. 宏内核](#1-宏内核)
|
||||
* [2. 微内核](#2-微内核)
|
||||
* [中断分类](#中断分类)
|
||||
* [1. 外中断](#1-外中断)
|
||||
* [2. 异常](#2-异常)
|
||||
* [3. 陷入](#3-陷入)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [计算机操作系统 - 概述](<计算机操作系统 - 概述.md#计算机操作系统---概述>)
|
||||
* [基本特征](<计算机操作系统 - 概述.md#基本特征>)
|
||||
* [1. 并发](<计算机操作系统 - 概述.md#1-并发>)
|
||||
* [2. 共享](<计算机操作系统 - 概述.md#2-共享>)
|
||||
* [3. 虚拟](<计算机操作系统 - 概述.md#3-虚拟>)
|
||||
* [4. 异步](<计算机操作系统 - 概述.md#4-异步>)
|
||||
* [基本功能](<计算机操作系统 - 概述.md#基本功能>)
|
||||
* [1. 进程管理](<计算机操作系统 - 概述.md#1-进程管理>)
|
||||
* [2. 内存管理](<计算机操作系统 - 概述.md#2-内存管理>)
|
||||
* [3. 文件管理](<计算机操作系统 - 概述.md#3-文件管理>)
|
||||
* [4. 设备管理](<计算机操作系统 - 概述.md#4-设备管理>)
|
||||
* [系统调用](<计算机操作系统 - 概述.md#系统调用>)
|
||||
* [宏内核和微内核](<计算机操作系统 - 概述.md#宏内核和微内核>)
|
||||
* [1. 宏内核](<计算机操作系统 - 概述.md#1-宏内核>)
|
||||
* [2. 微内核](<计算机操作系统 - 概述.md#2-微内核>)
|
||||
* [中断分类](<计算机操作系统 - 概述.md#中断分类>)
|
||||
* [1. 外中断](<计算机操作系统 - 概述.md#1-外中断>)
|
||||
* [2. 异常](<计算机操作系统 - 概述.md#2-异常>)
|
||||
* [3. 陷入](<计算机操作系统 - 概述.md#3-陷入>)
|
||||
|
||||
## 基本特征
|
||||
|
||||
@ -78,18 +76,19 @@
|
||||
|
||||
如果一个进程在用户态需要使用内核态的功能,就进行系统调用从而陷入内核,由操作系统代为完成。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/tGPV0.png" width="600"/> </div><br>
|
||||
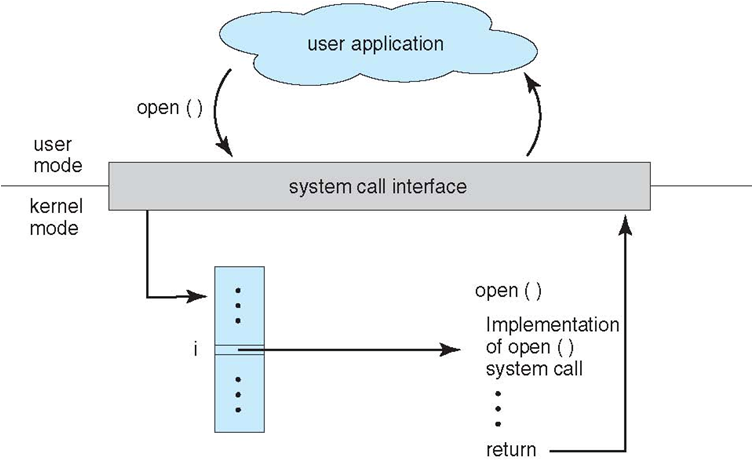\
|
||||
|
||||
|
||||
Linux 的系统调用主要有以下这些:
|
||||
|
||||
| Task | Commands |
|
||||
| :---: | --- |
|
||||
| 进程控制 | fork(); exit(); wait(); |
|
||||
| 进程通信 | pipe(); shmget(); mmap(); |
|
||||
| 文件操作 | open(); read(); write(); |
|
||||
| 设备操作 | ioctl(); read(); write(); |
|
||||
| Task | Commands |
|
||||
| :--: | --------------------------- |
|
||||
| 进程控制 | fork(); exit(); wait(); |
|
||||
| 进程通信 | pipe(); shmget(); mmap(); |
|
||||
| 文件操作 | open(); read(); write(); |
|
||||
| 设备操作 | ioctl(); read(); write(); |
|
||||
| 信息维护 | getpid(); alarm(); sleep(); |
|
||||
| 安全 | chmod(); umask(); chown(); |
|
||||
| 安全 | chmod(); umask(); chown(); |
|
||||
|
||||
## 宏内核和微内核
|
||||
|
||||
@ -107,7 +106,8 @@ Linux 的系统调用主要有以下这些:
|
||||
|
||||
因为需要频繁地在用户态和核心态之间进行切换,所以会有一定的性能损失。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/2_14_microkernelArchitecture.jpg"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 中断分类
|
||||
|
||||
|
||||
@ -1,42 +1,41 @@
|
||||
# 计算机操作系统 - 死锁
|
||||
<!-- GFM-TOC -->
|
||||
* [计算机操作系统 - 死锁](#计算机操作系统---死锁)
|
||||
* [必要条件](#必要条件)
|
||||
* [处理方法](#处理方法)
|
||||
* [鸵鸟策略](#鸵鸟策略)
|
||||
* [死锁检测与死锁恢复](#死锁检测与死锁恢复)
|
||||
* [1. 每种类型一个资源的死锁检测](#1-每种类型一个资源的死锁检测)
|
||||
* [2. 每种类型多个资源的死锁检测](#2-每种类型多个资源的死锁检测)
|
||||
* [3. 死锁恢复](#3-死锁恢复)
|
||||
* [死锁预防](#死锁预防)
|
||||
* [1. 破坏互斥条件](#1-破坏互斥条件)
|
||||
* [2. 破坏占有和等待条件](#2-破坏占有和等待条件)
|
||||
* [3. 破坏不可抢占条件](#3-破坏不可抢占条件)
|
||||
* [4. 破坏环路等待](#4-破坏环路等待)
|
||||
* [死锁避免](#死锁避免)
|
||||
* [1. 安全状态](#1-安全状态)
|
||||
* [2. 单个资源的银行家算法](#2-单个资源的银行家算法)
|
||||
* [3. 多个资源的银行家算法](#3-多个资源的银行家算法)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [计算机操作系统 - 死锁](<计算机操作系统 - 死锁.md#计算机操作系统---死锁>)
|
||||
* [必要条件](<计算机操作系统 - 死锁.md#必要条件>)
|
||||
* [处理方法](<计算机操作系统 - 死锁.md#处理方法>)
|
||||
* [鸵鸟策略](<计算机操作系统 - 死锁.md#鸵鸟策略>)
|
||||
* [死锁检测与死锁恢复](<计算机操作系统 - 死锁.md#死锁检测与死锁恢复>)
|
||||
* [1. 每种类型一个资源的死锁检测](<计算机操作系统 - 死锁.md#1-每种类型一个资源的死锁检测>)
|
||||
* [2. 每种类型多个资源的死锁检测](<计算机操作系统 - 死锁.md#2-每种类型多个资源的死锁检测>)
|
||||
* [3. 死锁恢复](<计算机操作系统 - 死锁.md#3-死锁恢复>)
|
||||
* [死锁预防](<计算机操作系统 - 死锁.md#死锁预防>)
|
||||
* [1. 破坏互斥条件](<计算机操作系统 - 死锁.md#1-破坏互斥条件>)
|
||||
* [2. 破坏占有和等待条件](<计算机操作系统 - 死锁.md#2-破坏占有和等待条件>)
|
||||
* [3. 破坏不可抢占条件](<计算机操作系统 - 死锁.md#3-破坏不可抢占条件>)
|
||||
* [4. 破坏环路等待](<计算机操作系统 - 死锁.md#4-破坏环路等待>)
|
||||
* [死锁避免](<计算机操作系统 - 死锁.md#死锁避免>)
|
||||
* [1. 安全状态](<计算机操作系统 - 死锁.md#1-安全状态>)
|
||||
* [2. 单个资源的银行家算法](<计算机操作系统 - 死锁.md#2-单个资源的银行家算法>)
|
||||
* [3. 多个资源的银行家算法](<计算机操作系统 - 死锁.md#3-多个资源的银行家算法>)
|
||||
|
||||
## 必要条件
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/c037c901-7eae-4e31-a1e4-9d41329e5c3e.png"/> </div><br>
|
||||
\
|
||||
|
||||
- 互斥:每个资源要么已经分配给了一个进程,要么就是可用的。
|
||||
- 占有和等待:已经得到了某个资源的进程可以再请求新的资源。
|
||||
- 不可抢占:已经分配给一个进程的资源不能强制性地被抢占,它只能被占有它的进程显式地释放。
|
||||
- 环路等待:有两个或者两个以上的进程组成一条环路,该环路中的每个进程都在等待下一个进程所占有的资源。
|
||||
|
||||
* 互斥:每个资源要么已经分配给了一个进程,要么就是可用的。
|
||||
* 占有和等待:已经得到了某个资源的进程可以再请求新的资源。
|
||||
* 不可抢占:已经分配给一个进程的资源不能强制性地被抢占,它只能被占有它的进程显式地释放。
|
||||
* 环路等待:有两个或者两个以上的进程组成一条环路,该环路中的每个进程都在等待下一个进程所占有的资源。
|
||||
|
||||
## 处理方法
|
||||
|
||||
主要有以下四种方法:
|
||||
|
||||
- 鸵鸟策略
|
||||
- 死锁检测与死锁恢复
|
||||
- 死锁预防
|
||||
- 死锁避免
|
||||
* 鸵鸟策略
|
||||
* 死锁检测与死锁恢复
|
||||
* 死锁预防
|
||||
* 死锁避免
|
||||
|
||||
## 鸵鸟策略
|
||||
|
||||
@ -54,7 +53,8 @@
|
||||
|
||||
### 1. 每种类型一个资源的死锁检测
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/b1fa0453-a4b0-4eae-a352-48acca8fff74.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
上图为资源分配图,其中方框表示资源,圆圈表示进程。资源指向进程表示该资源已经分配给该进程,进程指向资源表示进程请求获取该资源。
|
||||
|
||||
@ -64,30 +64,31 @@
|
||||
|
||||
### 2. 每种类型多个资源的死锁检测
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/e1eda3d5-5ec8-4708-8e25-1a04c5e11f48.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
上图中,有三个进程四个资源,每个数据代表的含义如下:
|
||||
|
||||
- E 向量:资源总量
|
||||
- A 向量:资源剩余量
|
||||
- C 矩阵:每个进程所拥有的资源数量,每一行都代表一个进程拥有资源的数量
|
||||
- R 矩阵:每个进程请求的资源数量
|
||||
* E 向量:资源总量
|
||||
* A 向量:资源剩余量
|
||||
* C 矩阵:每个进程所拥有的资源数量,每一行都代表一个进程拥有资源的数量
|
||||
* R 矩阵:每个进程请求的资源数量
|
||||
|
||||
进程 P<sub>1</sub> 和 P<sub>2</sub> 所请求的资源都得不到满足,只有进程 P<sub>3</sub> 可以,让 P<sub>3</sub> 执行,之后释放 P<sub>3</sub> 拥有的资源,此时 A = (2 2 2 0)。P<sub>2</sub> 可以执行,执行后释放 P<sub>2</sub> 拥有的资源,A = (4 2 2 1) 。P<sub>1</sub> 也可以执行。所有进程都可以顺利执行,没有死锁。
|
||||
进程 P1 和 P2 所请求的资源都得不到满足,只有进程 P3 可以,让 P3 执行,之后释放 P3 拥有的资源,此时 A = (2 2 2 0)。P2 可以执行,执行后释放 P2 拥有的资源,A = (4 2 2 1) 。P1 也可以执行。所有进程都可以顺利执行,没有死锁。
|
||||
|
||||
算法总结如下:
|
||||
|
||||
每个进程最开始时都不被标记,执行过程有可能被标记。当算法结束时,任何没有被标记的进程都是死锁进程。
|
||||
|
||||
1. 寻找一个没有标记的进程 P<sub>i</sub>,它所请求的资源小于等于 A。
|
||||
1. 寻找一个没有标记的进程 Pi,它所请求的资源小于等于 A。
|
||||
2. 如果找到了这样一个进程,那么将 C 矩阵的第 i 行向量加到 A 中,标记该进程,并转回 1。
|
||||
3. 如果没有这样一个进程,算法终止。
|
||||
|
||||
### 3. 死锁恢复
|
||||
|
||||
- 利用抢占恢复
|
||||
- 利用回滚恢复
|
||||
- 通过杀死进程恢复
|
||||
* 利用抢占恢复
|
||||
* 利用回滚恢复
|
||||
* 通过杀死进程恢复
|
||||
|
||||
## 死锁预防
|
||||
|
||||
@ -113,7 +114,8 @@
|
||||
|
||||
### 1. 安全状态
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/ed523051-608f-4c3f-b343-383e2d194470.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
图 a 的第二列 Has 表示已拥有的资源数,第三列 Max 表示总共需要的资源数,Free 表示还有可以使用的资源数。从图 a 开始出发,先让 B 拥有所需的所有资源(图 b),运行结束后释放 B,此时 Free 变为 5(图 c);接着以同样的方式运行 C 和 A,使得所有进程都能成功运行,因此可以称图 a 所示的状态时安全的。
|
||||
|
||||
@ -125,20 +127,22 @@
|
||||
|
||||
一个小城镇的银行家,他向一群客户分别承诺了一定的贷款额度,算法要做的是判断对请求的满足是否会进入不安全状态,如果是,就拒绝请求;否则予以分配。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/d160ec2e-cfe2-4640-bda7-62f53e58b8c0.png"/> </div><br>
|
||||
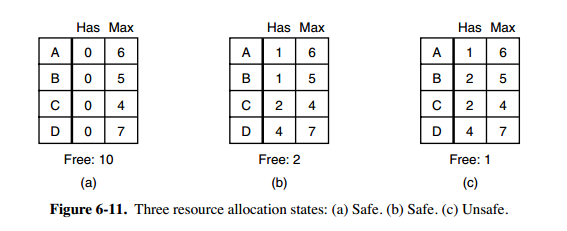\
|
||||
|
||||
|
||||
上图 c 为不安全状态,因此算法会拒绝之前的请求,从而避免进入图 c 中的状态。
|
||||
|
||||
### 3. 多个资源的银行家算法
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/62e0dd4f-44c3-43ee-bb6e-fedb9e068519.png"/> </div><br>
|
||||
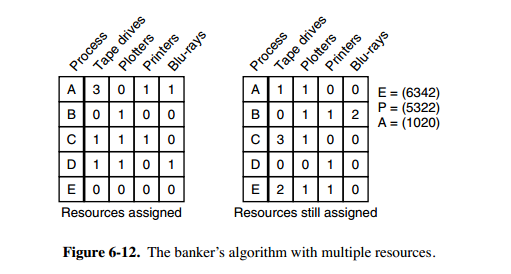\
|
||||
|
||||
|
||||
上图中有五个进程,四个资源。左边的图表示已经分配的资源,右边的图表示还需要分配的资源。最右边的 E、P 以及 A 分别表示:总资源、已分配资源以及可用资源,注意这三个为向量,而不是具体数值,例如 A=(1020),表示 4 个资源分别还剩下 1/0/2/0。
|
||||
|
||||
检查一个状态是否安全的算法如下:
|
||||
|
||||
- 查找右边的矩阵是否存在一行小于等于向量 A。如果不存在这样的行,那么系统将会发生死锁,状态是不安全的。
|
||||
- 假若找到这样一行,将该进程标记为终止,并将其已分配资源加到 A 中。
|
||||
- 重复以上两步,直到所有进程都标记为终止,则状态时安全的。
|
||||
* 查找右边的矩阵是否存在一行小于等于向量 A。如果不存在这样的行,那么系统将会发生死锁,状态是不安全的。
|
||||
* 假若找到这样一行,将该进程标记为终止,并将其已分配资源加到 A 中。
|
||||
* 重复以上两步,直到所有进程都标记为终止,则状态时安全的。
|
||||
|
||||
如果一个状态不是安全的,需要拒绝进入这个状态。
|
||||
|
||||
@ -1,32 +1,31 @@
|
||||
# 计算机操作系统 - 设备管理
|
||||
<!-- GFM-TOC -->
|
||||
* [计算机操作系统 - 设备管理](#计算机操作系统---设备管理)
|
||||
* [磁盘结构](#磁盘结构)
|
||||
* [磁盘调度算法](#磁盘调度算法)
|
||||
* [1. 先来先服务](#1-先来先服务)
|
||||
* [2. 最短寻道时间优先](#2-最短寻道时间优先)
|
||||
* [3. 电梯算法](#3-电梯算法)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [计算机操作系统 - 设备管理](<计算机操作系统 - 设备管理.md#计算机操作系统---设备管理>)
|
||||
* [磁盘结构](<计算机操作系统 - 设备管理.md#磁盘结构>)
|
||||
* [磁盘调度算法](<计算机操作系统 - 设备管理.md#磁盘调度算法>)
|
||||
* [1. 先来先服务](<计算机操作系统 - 设备管理.md#1-先来先服务>)
|
||||
* [2. 最短寻道时间优先](<计算机操作系统 - 设备管理.md#2-最短寻道时间优先>)
|
||||
* [3. 电梯算法](<计算机操作系统 - 设备管理.md#3-电梯算法>)
|
||||
|
||||
## 磁盘结构
|
||||
|
||||
- 盘面(Platter):一个磁盘有多个盘面;
|
||||
- 磁道(Track):盘面上的圆形带状区域,一个盘面可以有多个磁道;
|
||||
- 扇区(Track Sector):磁道上的一个弧段,一个磁道可以有多个扇区,它是最小的物理储存单位,目前主要有 512 bytes 与 4 K 两种大小;
|
||||
- 磁头(Head):与盘面非常接近,能够将盘面上的磁场转换为电信号(读),或者将电信号转换为盘面的磁场(写);
|
||||
- 制动手臂(Actuator arm):用于在磁道之间移动磁头;
|
||||
- 主轴(Spindle):使整个盘面转动。
|
||||
* 盘面(Platter):一个磁盘有多个盘面;
|
||||
* 磁道(Track):盘面上的圆形带状区域,一个盘面可以有多个磁道;
|
||||
* 扇区(Track Sector):磁道上的一个弧段,一个磁道可以有多个扇区,它是最小的物理储存单位,目前主要有 512 bytes 与 4 K 两种大小;
|
||||
* 磁头(Head):与盘面非常接近,能够将盘面上的磁场转换为电信号(读),或者将电信号转换为盘面的磁场(写);
|
||||
* 制动手臂(Actuator arm):用于在磁道之间移动磁头;
|
||||
* 主轴(Spindle):使整个盘面转动。
|
||||
|
||||
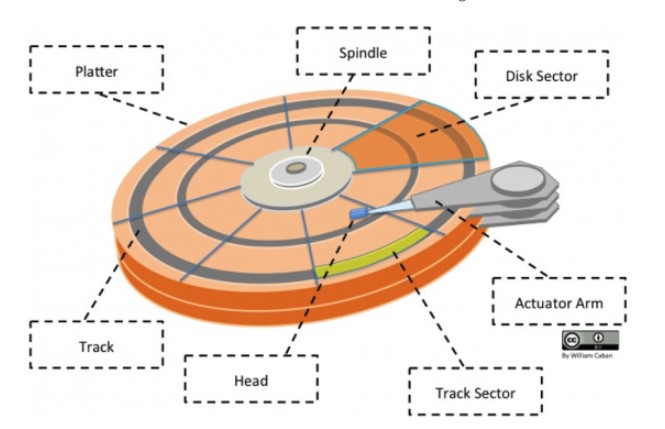\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/014fbc4d-d873-4a12-b160-867ddaed9807.jpg"/> </div><br>
|
||||
|
||||
## 磁盘调度算法
|
||||
|
||||
读写一个磁盘块的时间的影响因素有:
|
||||
|
||||
- 旋转时间(主轴转动盘面,使得磁头移动到适当的扇区上)
|
||||
- 寻道时间(制动手臂移动,使得磁头移动到适当的磁道上)
|
||||
- 实际的数据传输时间
|
||||
* 旋转时间(主轴转动盘面,使得磁头移动到适当的扇区上)
|
||||
* 寻道时间(制动手臂移动,使得磁头移动到适当的磁道上)
|
||||
* 实际的数据传输时间
|
||||
|
||||
其中,寻道时间最长,因此磁盘调度的主要目标是使磁盘的平均寻道时间最短。
|
||||
|
||||
@ -46,7 +45,8 @@
|
||||
|
||||
虽然平均寻道时间比较低,但是不够公平。如果新到达的磁道请求总是比一个在等待的磁道请求近,那么在等待的磁道请求会一直等待下去,也就是出现饥饿现象。具体来说,两端的磁道请求更容易出现饥饿现象。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/4e2485e4-34bd-4967-9f02-0c093b797aaa.png"/> </div><br>
|
||||
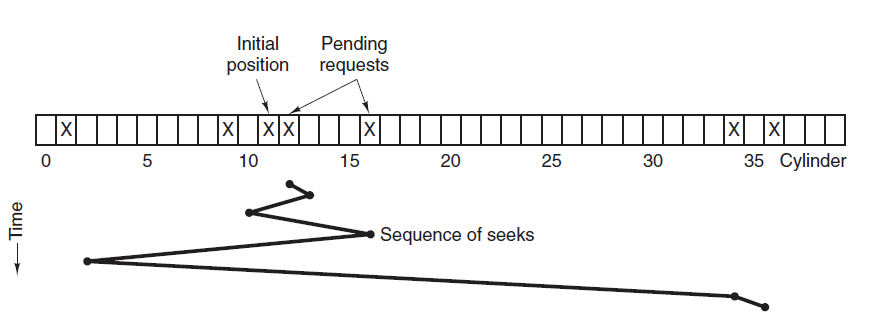\
|
||||
|
||||
|
||||
### 3. 电梯算法
|
||||
|
||||
@ -58,4 +58,4 @@
|
||||
|
||||
因为考虑了移动方向,因此所有的磁盘请求都会被满足,解决了 SSTF 的饥饿问题。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/271ce08f-c124-475f-b490-be44fedc6d2e.png"/> </div><br>
|
||||
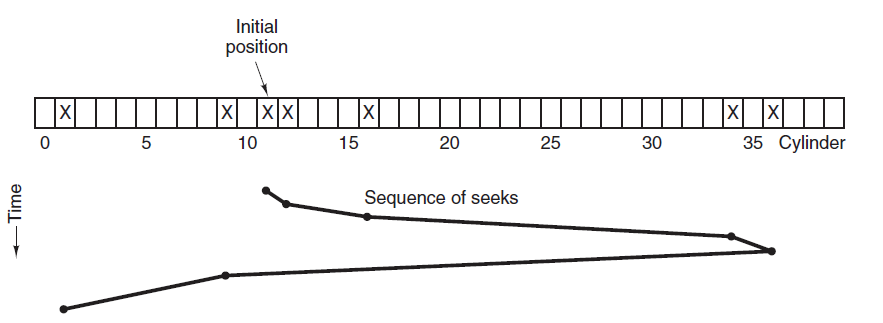\
|
||||
|
||||
@ -1,32 +1,30 @@
|
||||
# 计算机操作系统 - 进程管理
|
||||
<!-- GFM-TOC -->
|
||||
* [计算机操作系统 - 进程管理](#计算机操作系统---进程管理)
|
||||
* [进程与线程](#进程与线程)
|
||||
* [1. 进程](#1-进程)
|
||||
* [2. 线程](#2-线程)
|
||||
* [3. 区别](#3-区别)
|
||||
* [进程状态的切换](#进程状态的切换)
|
||||
* [进程调度算法](#进程调度算法)
|
||||
* [1. 批处理系统](#1-批处理系统)
|
||||
* [2. 交互式系统](#2-交互式系统)
|
||||
* [3. 实时系统](#3-实时系统)
|
||||
* [进程同步](#进程同步)
|
||||
* [1. 临界区](#1-临界区)
|
||||
* [2. 同步与互斥](#2-同步与互斥)
|
||||
* [3. 信号量](#3-信号量)
|
||||
* [4. 管程](#4-管程)
|
||||
* [经典同步问题](#经典同步问题)
|
||||
* [1. 哲学家进餐问题](#1-哲学家进餐问题)
|
||||
* [2. 读者-写者问题](#2-读者-写者问题)
|
||||
* [进程通信](#进程通信)
|
||||
* [1. 管道](#1-管道)
|
||||
* [2. FIFO](#2-fifo)
|
||||
* [3. 消息队列](#3-消息队列)
|
||||
* [4. 信号量](#4-信号量)
|
||||
* [5. 共享存储](#5-共享存储)
|
||||
* [6. 套接字](#6-套接字)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [计算机操作系统 - 进程管理](<计算机操作系统 - 进程管理.md#计算机操作系统---进程管理>)
|
||||
* [进程与线程](<计算机操作系统 - 进程管理.md#进程与线程>)
|
||||
* [1. 进程](<计算机操作系统 - 进程管理.md#1-进程>)
|
||||
* [2. 线程](<计算机操作系统 - 进程管理.md#2-线程>)
|
||||
* [3. 区别](<计算机操作系统 - 进程管理.md#3-区别>)
|
||||
* [进程状态的切换](<计算机操作系统 - 进程管理.md#进程状态的切换>)
|
||||
* [进程调度算法](<计算机操作系统 - 进程管理.md#进程调度算法>)
|
||||
* [1. 批处理系统](<计算机操作系统 - 进程管理.md#1-批处理系统>)
|
||||
* [2. 交互式系统](<计算机操作系统 - 进程管理.md#2-交互式系统>)
|
||||
* [3. 实时系统](<计算机操作系统 - 进程管理.md#3-实时系统>)
|
||||
* [进程同步](<计算机操作系统 - 进程管理.md#进程同步>)
|
||||
* [1. 临界区](<计算机操作系统 - 进程管理.md#1-临界区>)
|
||||
* [2. 同步与互斥](<计算机操作系统 - 进程管理.md#2-同步与互斥>)
|
||||
* [3. 信号量](<计算机操作系统 - 进程管理.md#3-信号量>)
|
||||
* [4. 管程](<计算机操作系统 - 进程管理.md#4-管程>)
|
||||
* [经典同步问题](<计算机操作系统 - 进程管理.md#经典同步问题>)
|
||||
* [1. 哲学家进餐问题](<计算机操作系统 - 进程管理.md#1-哲学家进餐问题>)
|
||||
* [2. 读者-写者问题](<计算机操作系统 - 进程管理.md#2-读者-写者问题>)
|
||||
* [进程通信](<计算机操作系统 - 进程管理.md#进程通信>)
|
||||
* [1. 管道](<计算机操作系统 - 进程管理.md#1-管道>)
|
||||
* [2. FIFO](<计算机操作系统 - 进程管理.md#2-fifo>)
|
||||
* [3. 消息队列](<计算机操作系统 - 进程管理.md#3-消息队列>)
|
||||
* [4. 信号量](<计算机操作系统 - 进程管理.md#4-信号量>)
|
||||
* [5. 共享存储](<计算机操作系统 - 进程管理.md#5-共享存储>)
|
||||
* [6. 套接字](<计算机操作系统 - 进程管理.md#6-套接字>)
|
||||
|
||||
## 进程与线程
|
||||
|
||||
@ -38,7 +36,8 @@
|
||||
|
||||
下图显示了 4 个程序创建了 4 个进程,这 4 个进程可以并发地执行。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/a6ac2b08-3861-4e85-baa8-382287bfee9f.png"/> </div><br>
|
||||
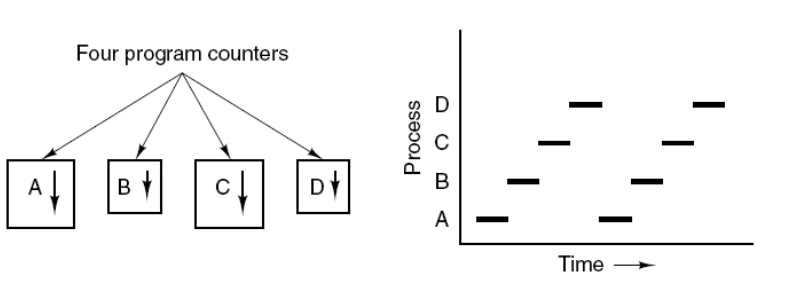\
|
||||
|
||||
|
||||
### 2. 线程
|
||||
|
||||
@ -48,7 +47,8 @@
|
||||
|
||||
QQ 和浏览器是两个进程,浏览器进程里面有很多线程,例如 HTTP 请求线程、事件响应线程、渲染线程等等,线程的并发执行使得在浏览器中点击一个新链接从而发起 HTTP 请求时,浏览器还可以响应用户的其它事件。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/3cd630ea-017c-488d-ad1d-732b4efeddf5.png"/> </div><br>
|
||||
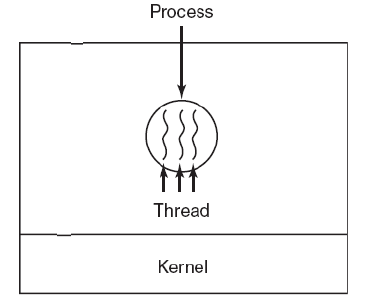\
|
||||
|
||||
|
||||
### 3. 区别
|
||||
|
||||
@ -70,16 +70,17 @@ QQ 和浏览器是两个进程,浏览器进程里面有很多线程,例如 H
|
||||
|
||||
## 进程状态的切换
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/ProcessState.png" width="500"/> </div><br>
|
||||
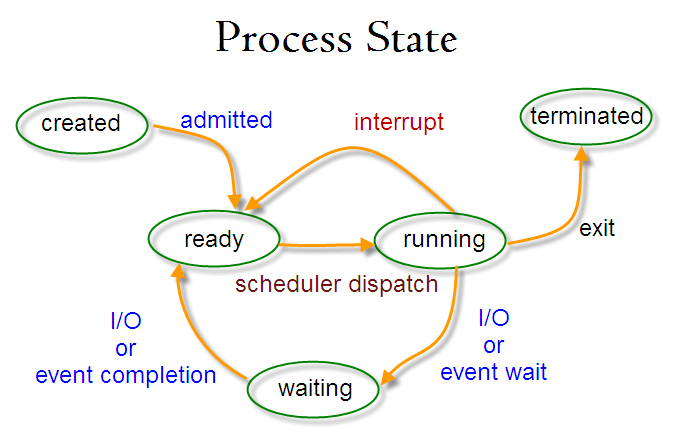\
|
||||
|
||||
- 就绪状态(ready):等待被调度
|
||||
- 运行状态(running)
|
||||
- 阻塞状态(waiting):等待资源
|
||||
|
||||
* 就绪状态(ready):等待被调度
|
||||
* 运行状态(running)
|
||||
* 阻塞状态(waiting):等待资源
|
||||
|
||||
应该注意以下内容:
|
||||
|
||||
- 只有就绪态和运行态可以相互转换,其它的都是单向转换。就绪状态的进程通过调度算法从而获得 CPU 时间,转为运行状态;而运行状态的进程,在分配给它的 CPU 时间片用完之后就会转为就绪状态,等待下一次调度。
|
||||
- 阻塞状态是缺少需要的资源从而由运行状态转换而来,但是该资源不包括 CPU 时间,缺少 CPU 时间会从运行态转换为就绪态。
|
||||
* 只有就绪态和运行态可以相互转换,其它的都是单向转换。就绪状态的进程通过调度算法从而获得 CPU 时间,转为运行状态;而运行状态的进程,在分配给它的 CPU 时间片用完之后就会转为就绪状态,等待下一次调度。
|
||||
* 阻塞状态是缺少需要的资源从而由运行状态转换而来,但是该资源不包括 CPU 时间,缺少 CPU 时间会从运行态转换为就绪态。
|
||||
|
||||
## 进程调度算法
|
||||
|
||||
@ -89,19 +90,19 @@ QQ 和浏览器是两个进程,浏览器进程里面有很多线程,例如 H
|
||||
|
||||
批处理系统没有太多的用户操作,在该系统中,调度算法目标是保证吞吐量和周转时间(从提交到终止的时间)。
|
||||
|
||||
**1.1 先来先服务 first-come first-serverd(FCFS)**
|
||||
**1.1 先来先服务 first-come first-serverd(FCFS)**
|
||||
|
||||
非抢占式的调度算法,按照请求的顺序进行调度。
|
||||
|
||||
有利于长作业,但不利于短作业,因为短作业必须一直等待前面的长作业执行完毕才能执行,而长作业又需要执行很长时间,造成了短作业等待时间过长。
|
||||
|
||||
**1.2 短作业优先 shortest job first(SJF)**
|
||||
**1.2 短作业优先 shortest job first(SJF)**
|
||||
|
||||
非抢占式的调度算法,按估计运行时间最短的顺序进行调度。
|
||||
|
||||
长作业有可能会饿死,处于一直等待短作业执行完毕的状态。因为如果一直有短作业到来,那么长作业永远得不到调度。
|
||||
|
||||
**1.3 最短剩余时间优先 shortest remaining time next(SRTN)**
|
||||
**1.3 最短剩余时间优先 shortest remaining time next(SRTN)**
|
||||
|
||||
最短作业优先的抢占式版本,按剩余运行时间的顺序进行调度。 当一个新的作业到达时,其整个运行时间与当前进程的剩余时间作比较。如果新的进程需要的时间更少,则挂起当前进程,运行新的进程。否则新的进程等待。
|
||||
|
||||
@ -109,24 +110,25 @@ QQ 和浏览器是两个进程,浏览器进程里面有很多线程,例如 H
|
||||
|
||||
交互式系统有大量的用户交互操作,在该系统中调度算法的目标是快速地进行响应。
|
||||
|
||||
**2.1 时间片轮转**
|
||||
**2.1 时间片轮转**
|
||||
|
||||
将所有就绪进程按 FCFS 的原则排成一个队列,每次调度时,把 CPU 时间分配给队首进程,该进程可以执行一个时间片。当时间片用完时,由计时器发出时钟中断,调度程序便停止该进程的执行,并将它送往就绪队列的末尾,同时继续把 CPU 时间分配给队首的进程。
|
||||
|
||||
时间片轮转算法的效率和时间片的大小有很大关系:
|
||||
|
||||
- 因为进程切换都要保存进程的信息并且载入新进程的信息,如果时间片太小,会导致进程切换得太频繁,在进程切换上就会花过多时间。
|
||||
- 而如果时间片过长,那么实时性就不能得到保证。
|
||||
* 因为进程切换都要保存进程的信息并且载入新进程的信息,如果时间片太小,会导致进程切换得太频繁,在进程切换上就会花过多时间。
|
||||
* 而如果时间片过长,那么实时性就不能得到保证。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/8c662999-c16c-481c-9f40-1fdba5bc9167.png"/> </div><br>
|
||||
\
|
||||
|
||||
**2.2 优先级调度**
|
||||
|
||||
**2.2 优先级调度**
|
||||
|
||||
为每个进程分配一个优先级,按优先级进行调度。
|
||||
|
||||
为了防止低优先级的进程永远等不到调度,可以随着时间的推移增加等待进程的优先级。
|
||||
|
||||
**2.3 多级反馈队列**
|
||||
**2.3 多级反馈队列**
|
||||
|
||||
一个进程需要执行 100 个时间片,如果采用时间片轮转调度算法,那么需要交换 100 次。
|
||||
|
||||
@ -136,7 +138,8 @@ QQ 和浏览器是两个进程,浏览器进程里面有很多线程,例如 H
|
||||
|
||||
可以将这种调度算法看成是时间片轮转调度算法和优先级调度算法的结合。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/042cf928-3c8e-4815-ae9c-f2780202c68f.png"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### 3. 实时系统
|
||||
|
||||
@ -160,19 +163,19 @@ QQ 和浏览器是两个进程,浏览器进程里面有很多线程,例如 H
|
||||
|
||||
### 2. 同步与互斥
|
||||
|
||||
- 同步:多个进程因为合作产生的直接制约关系,使得进程有一定的先后执行关系。
|
||||
- 互斥:多个进程在同一时刻只有一个进程能进入临界区。
|
||||
* 同步:多个进程因为合作产生的直接制约关系,使得进程有一定的先后执行关系。
|
||||
* 互斥:多个进程在同一时刻只有一个进程能进入临界区。
|
||||
|
||||
### 3. 信号量
|
||||
|
||||
信号量(Semaphore)是一个整型变量,可以对其执行 down 和 up 操作,也就是常见的 P 和 V 操作。
|
||||
|
||||
- **down** : 如果信号量大于 0 ,执行 -1 操作;如果信号量等于 0,进程睡眠,等待信号量大于 0;
|
||||
- **up** :对信号量执行 +1 操作,唤醒睡眠的进程让其完成 down 操作。
|
||||
* **down** : 如果信号量大于 0 ,执行 -1 操作;如果信号量等于 0,进程睡眠,等待信号量大于 0;
|
||||
* **up** :对信号量执行 +1 操作,唤醒睡眠的进程让其完成 down 操作。
|
||||
|
||||
down 和 up 操作需要被设计成原语,不可分割,通常的做法是在执行这些操作的时候屏蔽中断。
|
||||
|
||||
如果信号量的取值只能为 0 或者 1,那么就成为了 **互斥量(Mutex)** ,0 表示临界区已经加锁,1 表示临界区解锁。
|
||||
如果信号量的取值只能为 0 或者 1,那么就成为了 **互斥量(Mutex)** ,0 表示临界区已经加锁,1 表示临界区解锁。
|
||||
|
||||
```c
|
||||
typedef int semaphore;
|
||||
@ -190,7 +193,7 @@ void P2() {
|
||||
}
|
||||
```
|
||||
|
||||
\<font size=3\> **使用信号量实现生产者-消费者问题** \</font\> \</br\>
|
||||
\<font size=3> **使用信号量实现生产者-消费者问题** \</font> \</br>
|
||||
|
||||
问题描述:使用一个缓冲区来保存物品,只有缓冲区没有满,生产者才可以放入物品;只有缓冲区不为空,消费者才可以拿走物品。
|
||||
|
||||
@ -255,9 +258,10 @@ end monitor;
|
||||
|
||||
管程有一个重要特性:在一个时刻只能有一个进程使用管程。进程在无法继续执行的时候不能一直占用管程,否则其它进程永远不能使用管程。
|
||||
|
||||
管程引入了 **条件变量** 以及相关的操作:**wait()** 和 **signal()** 来实现同步操作。对条件变量执行 wait() 操作会导致调用进程阻塞,把管程让出来给另一个进程持有。signal() 操作用于唤醒被阻塞的进程。
|
||||
管程引入了 **条件变量** 以及相关的操作:**wait()** 和 **signal()** 来实现同步操作。对条件变量执行 wait() 操作会导致调用进程阻塞,把管程让出来给另一个进程持有。signal() 操作用于唤醒被阻塞的进程。
|
||||
|
||||
**使用管程实现生产者-消费者问题**\
|
||||
|
||||
<font size=3> **使用管程实现生产者-消费者问题** </font><br>
|
||||
|
||||
```pascal
|
||||
// 管程
|
||||
@ -310,7 +314,8 @@ end;
|
||||
|
||||
### 1. 哲学家进餐问题
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/a9077f06-7584-4f2b-8c20-3a8e46928820.jpg"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
五个哲学家围着一张圆桌,每个哲学家面前放着食物。哲学家的生活有两种交替活动:吃饭以及思考。当一个哲学家吃饭时,需要先拿起自己左右两边的两根筷子,并且一次只能拿起一根筷子。
|
||||
|
||||
@ -333,8 +338,8 @@ void philosopher(int i) {
|
||||
|
||||
为了防止死锁的发生,可以设置两个条件:
|
||||
|
||||
- 必须同时拿起左右两根筷子;
|
||||
- 只有在两个邻居都没有进餐的情况下才允许进餐。
|
||||
* 必须同时拿起左右两根筷子;
|
||||
* 只有在两个邻居都没有进餐的情况下才允许进餐。
|
||||
|
||||
```c
|
||||
#define N 5
|
||||
@ -392,7 +397,7 @@ void check(i) {
|
||||
|
||||
允许多个进程同时对数据进行读操作,但是不允许读和写以及写和写操作同时发生。
|
||||
|
||||
一个整型变量 count 记录在对数据进行读操作的进程数量,一个互斥量 count_mutex 用于对 count 加锁,一个互斥量 data_mutex 用于对读写的数据加锁。
|
||||
一个整型变量 count 记录在对数据进行读操作的进程数量,一个互斥量 count\_mutex 用于对 count 加锁,一个互斥量 data\_mutex 用于对读写的数据加锁。
|
||||
|
||||
```c
|
||||
typedef int semaphore;
|
||||
@ -480,7 +485,7 @@ We can observe that every reader is forced to acquire ReadLock. On the otherhand
|
||||
|
||||
From the both cases we observed that either reader or writer has to starve. Below solutionadds the constraint that no thread shall be allowed to starve; that is, the operation of obtaining a lock on the shared data will always terminate in a bounded amount of time.
|
||||
|
||||
```source-c
|
||||
```
|
||||
int readCount; // init to 0; number of readers currently accessing resource
|
||||
|
||||
// all semaphores initialised to 1
|
||||
@ -529,21 +534,20 @@ void reader()
|
||||
// </EXIT>
|
||||
up(&readCountAccess); // release access to readCount
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
## 进程通信
|
||||
|
||||
进程同步与进程通信很容易混淆,它们的区别在于:
|
||||
|
||||
- 进程同步:控制多个进程按一定顺序执行;
|
||||
- 进程通信:进程间传输信息。
|
||||
* 进程同步:控制多个进程按一定顺序执行;
|
||||
* 进程通信:进程间传输信息。
|
||||
|
||||
进程通信是一种手段,而进程同步是一种目的。也可以说,为了能够达到进程同步的目的,需要让进程进行通信,传输一些进程同步所需要的信息。
|
||||
|
||||
### 1. 管道
|
||||
|
||||
管道是通过调用 pipe 函数创建的,fd[0] 用于读,fd[1] 用于写。
|
||||
管道是通过调用 pipe 函数创建的,fd\[0] 用于读,fd\[1] 用于写。
|
||||
|
||||
```c
|
||||
#include <unistd.h>
|
||||
@ -552,10 +556,11 @@ int pipe(int fd[2]);
|
||||
|
||||
它具有以下限制:
|
||||
|
||||
- 只支持半双工通信(单向交替传输);
|
||||
- 只能在父子进程或者兄弟进程中使用。
|
||||
* 只支持半双工通信(单向交替传输);
|
||||
* 只能在父子进程或者兄弟进程中使用。
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/53cd9ade-b0a6-4399-b4de-7f1fbd06cdfb.png"/> </div><br>
|
||||
|
||||
### 2. FIFO
|
||||
|
||||
@ -569,15 +574,16 @@ int mkfifoat(int fd, const char *path, mode_t mode);
|
||||
|
||||
FIFO 常用于客户-服务器应用程序中,FIFO 用作汇聚点,在客户进程和服务器进程之间传递数据。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/2ac50b81-d92a-4401-b9ec-f2113ecc3076.png"/> </div><br>
|
||||
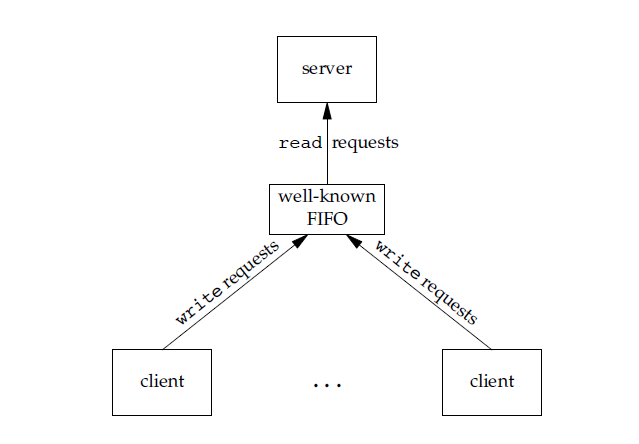\
|
||||
|
||||
|
||||
### 3. 消息队列
|
||||
|
||||
相比于 FIFO,消息队列具有以下优点:
|
||||
|
||||
- 消息队列可以独立于读写进程存在,从而避免了 FIFO 中同步管道的打开和关闭时可能产生的困难;
|
||||
- 避免了 FIFO 的同步阻塞问题,不需要进程自己提供同步方法;
|
||||
- 读进程可以根据消息类型有选择地接收消息,而不像 FIFO 那样只能默认地接收。
|
||||
* 消息队列可以独立于读写进程存在,从而避免了 FIFO 中同步管道的打开和关闭时可能产生的困难;
|
||||
* 避免了 FIFO 的同步阻塞问题,不需要进程自己提供同步方法;
|
||||
* 读进程可以根据消息类型有选择地接收消息,而不像 FIFO 那样只能默认地接收。
|
||||
|
||||
### 4. 信号量
|
||||
|
||||
|
||||
@ -1,16 +1,13 @@
|
||||
# 计算机操作系统 - 链接
|
||||
<!-- GFM-TOC -->
|
||||
* [计算机操作系统 - 链接](#计算机操作系统---链接)
|
||||
* [编译系统](#编译系统)
|
||||
* [静态链接](#静态链接)
|
||||
* [目标文件](#目标文件)
|
||||
* [动态链接](#动态链接)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [计算机操作系统 - 链接](<计算机操作系统 - 链接.md#计算机操作系统---链接>)
|
||||
* [编译系统](<计算机操作系统 - 链接.md#编译系统>)
|
||||
* [静态链接](<计算机操作系统 - 链接.md#静态链接>)
|
||||
* [目标文件](<计算机操作系统 - 链接.md#目标文件>)
|
||||
* [动态链接](<计算机操作系统 - 链接.md#动态链接>)
|
||||
|
||||
## 编译系统
|
||||
|
||||
|
||||
以下是一个 hello.c 程序:
|
||||
|
||||
```c
|
||||
@ -31,38 +28,40 @@ gcc -o hello hello.c
|
||||
|
||||
这个过程大致如下:
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/b396d726-b75f-4a32-89a2-03a7b6e19f6f.jpg" width="800"/> </div><br>
|
||||
\
|
||||
|
||||
- 预处理阶段:处理以 # 开头的预处理命令;
|
||||
- 编译阶段:翻译成汇编文件;
|
||||
- 汇编阶段:将汇编文件翻译成可重定位目标文件;
|
||||
- 链接阶段:将可重定位目标文件和 printf.o 等单独预编译好的目标文件进行合并,得到最终的可执行目标文件。
|
||||
|
||||
* 预处理阶段:处理以 # 开头的预处理命令;
|
||||
* 编译阶段:翻译成汇编文件;
|
||||
* 汇编阶段:将汇编文件翻译成可重定位目标文件;
|
||||
* 链接阶段:将可重定位目标文件和 printf.o 等单独预编译好的目标文件进行合并,得到最终的可执行目标文件。
|
||||
|
||||
## 静态链接
|
||||
|
||||
静态链接器以一组可重定位目标文件为输入,生成一个完全链接的可执行目标文件作为输出。链接器主要完成以下两个任务:
|
||||
|
||||
- 符号解析:每个符号对应于一个函数、一个全局变量或一个静态变量,符号解析的目的是将每个符号引用与一个符号定义关联起来。
|
||||
- 重定位:链接器通过把每个符号定义与一个内存位置关联起来,然后修改所有对这些符号的引用,使得它们指向这个内存位置。
|
||||
* 符号解析:每个符号对应于一个函数、一个全局变量或一个静态变量,符号解析的目的是将每个符号引用与一个符号定义关联起来。
|
||||
* 重定位:链接器通过把每个符号定义与一个内存位置关联起来,然后修改所有对这些符号的引用,使得它们指向这个内存位置。
|
||||
|
||||
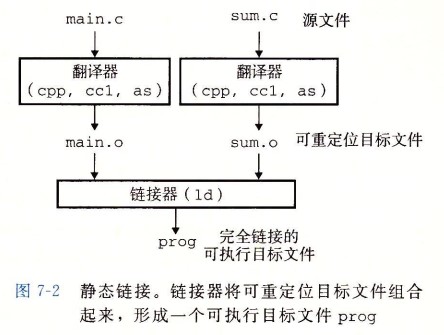\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/47d98583-8bb0-45cc-812d-47eefa0a4a40.jpg"/> </div><br>
|
||||
|
||||
## 目标文件
|
||||
|
||||
- 可执行目标文件:可以直接在内存中执行;
|
||||
- 可重定位目标文件:可与其它可重定位目标文件在链接阶段合并,创建一个可执行目标文件;
|
||||
- 共享目标文件:这是一种特殊的可重定位目标文件,可以在运行时被动态加载进内存并链接;
|
||||
* 可执行目标文件:可以直接在内存中执行;
|
||||
* 可重定位目标文件:可与其它可重定位目标文件在链接阶段合并,创建一个可执行目标文件;
|
||||
* 共享目标文件:这是一种特殊的可重定位目标文件,可以在运行时被动态加载进内存并链接;
|
||||
|
||||
## 动态链接
|
||||
|
||||
静态库有以下两个问题:
|
||||
|
||||
- 当静态库更新时那么整个程序都要重新进行链接;
|
||||
- 对于 printf 这种标准函数库,如果每个程序都要有代码,这会极大浪费资源。
|
||||
* 当静态库更新时那么整个程序都要重新进行链接;
|
||||
* 对于 printf 这种标准函数库,如果每个程序都要有代码,这会极大浪费资源。
|
||||
|
||||
共享库是为了解决静态库的这两个问题而设计的,在 Linux 系统中通常用 .so 后缀来表示,Windows 系统上它们被称为 DLL。它具有以下特点:
|
||||
|
||||
- 在给定的文件系统中一个库只有一个文件,所有引用该库的可执行目标文件都共享这个文件,它不会被复制到引用它的可执行文件中;
|
||||
- 在内存中,一个共享库的 .text 节(已编译程序的机器代码)的一个副本可以被不同的正在运行的进程共享。
|
||||
* 在给定的文件系统中一个库只有一个文件,所有引用该库的可执行目标文件都共享这个文件,它不会被复制到引用它的可执行文件中;
|
||||
* 在内存中,一个共享库的 .text 节(已编译程序的机器代码)的一个副本可以被不同的正在运行的进程共享。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/76dc7769-1aac-4888-9bea-064f1caa8e77.jpg"/> </div><br>
|
||||
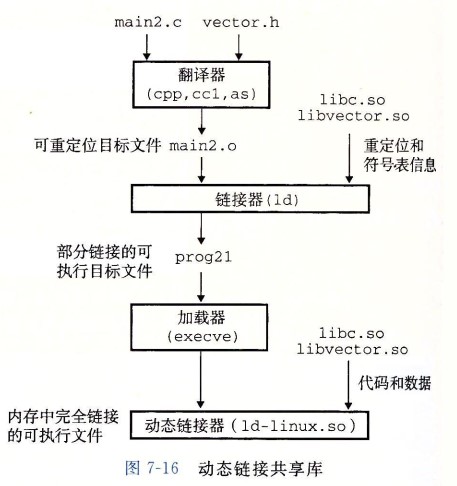\
|
||||
|
||||
@ -1,69 +1,59 @@
|
||||
# 计算机网络 - 传输层
|
||||
<!-- GFM-TOC -->
|
||||
* [计算机网络 - 传输层](#计算机网络---传输层)
|
||||
* [UDP 和 TCP 的特点](#udp-和-tcp-的特点)
|
||||
* [UDP 首部格式](#udp-首部格式)
|
||||
* [TCP 首部格式](#tcp-首部格式)
|
||||
* [TCP 的三次握手](#tcp-的三次握手)
|
||||
* [TCP 的四次挥手](#tcp-的四次挥手)
|
||||
* [TCP 可靠传输](#tcp-可靠传输)
|
||||
* [TCP 滑动窗口](#tcp-滑动窗口)
|
||||
* [TCP 流量控制](#tcp-流量控制)
|
||||
* [TCP 拥塞控制](#tcp-拥塞控制)
|
||||
* [1. 慢开始与拥塞避免](#1-慢开始与拥塞避免)
|
||||
* [2. 快重传与快恢复](#2-快重传与快恢复)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [计算机网络 - 传输层](<计算机网络 - 传输层.md#计算机网络---传输层>)
|
||||
* [UDP 和 TCP 的特点](<计算机网络 - 传输层.md#udp-和-tcp-的特点>)
|
||||
* [UDP 首部格式](<计算机网络 - 传输层.md#udp-首部格式>)
|
||||
* [TCP 首部格式](<计算机网络 - 传输层.md#tcp-首部格式>)
|
||||
* [TCP 的三次握手](<计算机网络 - 传输层.md#tcp-的三次握手>)
|
||||
* [TCP 的四次挥手](<计算机网络 - 传输层.md#tcp-的四次挥手>)
|
||||
* [TCP 可靠传输](<计算机网络 - 传输层.md#tcp-可靠传输>)
|
||||
* [TCP 滑动窗口](<计算机网络 - 传输层.md#tcp-滑动窗口>)
|
||||
* [TCP 流量控制](<计算机网络 - 传输层.md#tcp-流量控制>)
|
||||
* [TCP 拥塞控制](<计算机网络 - 传输层.md#tcp-拥塞控制>)
|
||||
* [1. 慢开始与拥塞避免](<计算机网络 - 传输层.md#1-慢开始与拥塞避免>)
|
||||
* [2. 快重传与快恢复](<计算机网络 - 传输层.md#2-快重传与快恢复>)
|
||||
|
||||
网络层只把分组发送到目的主机,但是真正通信的并不是主机而是主机中的进程。传输层提供了进程间的逻辑通信,传输层向高层用户屏蔽了下面网络层的核心细节,使应用程序看起来像是在两个传输层实体之间有一条端到端的逻辑通信信道。
|
||||
|
||||
## UDP 和 TCP 的特点
|
||||
|
||||
- 用户数据报协议 UDP(User Datagram Protocol)是无连接的,尽最大可能交付,没有拥塞控制,面向报文(对于应用程序传下来的报文不合并也不拆分,只是添加 UDP 首部),支持一对一、一对多、多对一和多对多的交互通信。
|
||||
|
||||
- 传输控制协议 TCP(Transmission Control Protocol)是面向连接的,提供可靠交付,有流量控制,拥塞控制,提供全双工通信,面向字节流(把应用层传下来的报文看成字节流,把字节流组织成大小不等的数据块),每一条 TCP 连接只能是点对点的(一对一)。
|
||||
* 用户数据报协议 UDP(User Datagram Protocol)是无连接的,尽最大可能交付,没有拥塞控制,面向报文(对于应用程序传下来的报文不合并也不拆分,只是添加 UDP 首部),支持一对一、一对多、多对一和多对多的交互通信。
|
||||
* 传输控制协议 TCP(Transmission Control Protocol)是面向连接的,提供可靠交付,有流量控制,拥塞控制,提供全双工通信,面向字节流(把应用层传下来的报文看成字节流,把字节流组织成大小不等的数据块),每一条 TCP 连接只能是点对点的(一对一)。
|
||||
|
||||
## UDP 首部格式
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/d4c3a4a1-0846-46ec-9cc3-eaddfca71254.jpg" width="600"/> </div><br>
|
||||
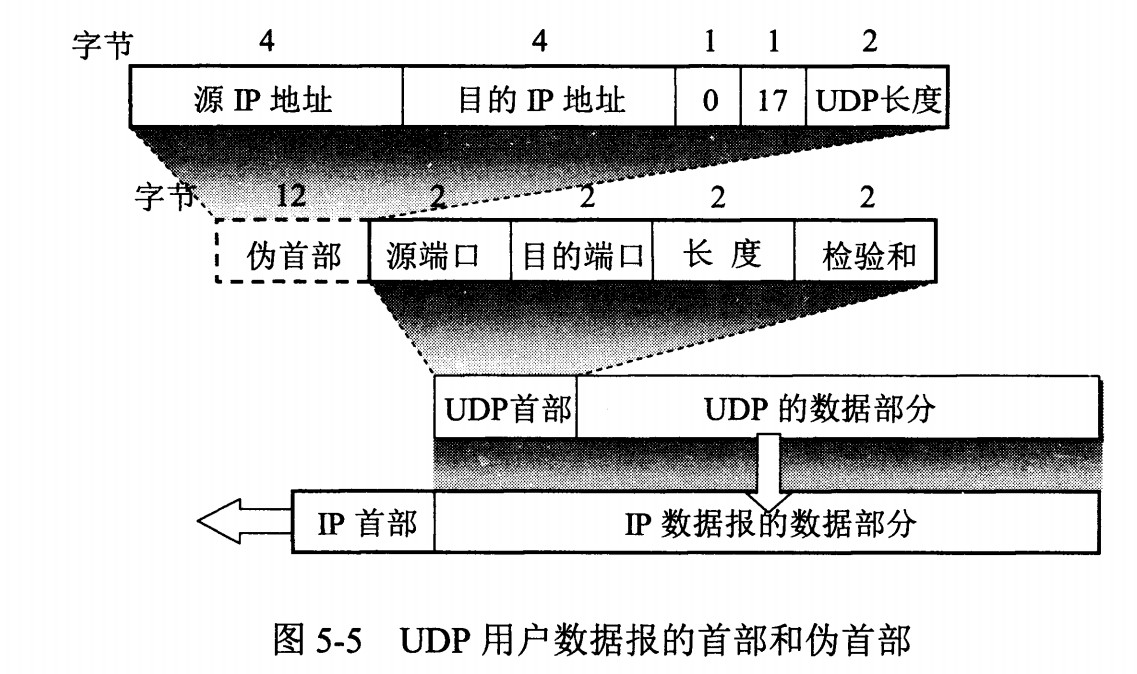\
|
||||
|
||||
|
||||
首部字段只有 8 个字节,包括源端口、目的端口、长度、检验和。12 字节的伪首部是为了计算检验和临时添加的。
|
||||
|
||||
## TCP 首部格式
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/55dc4e84-573d-4c13-a765-52ed1dd251f9.png" width="700"/> </div><br>
|
||||
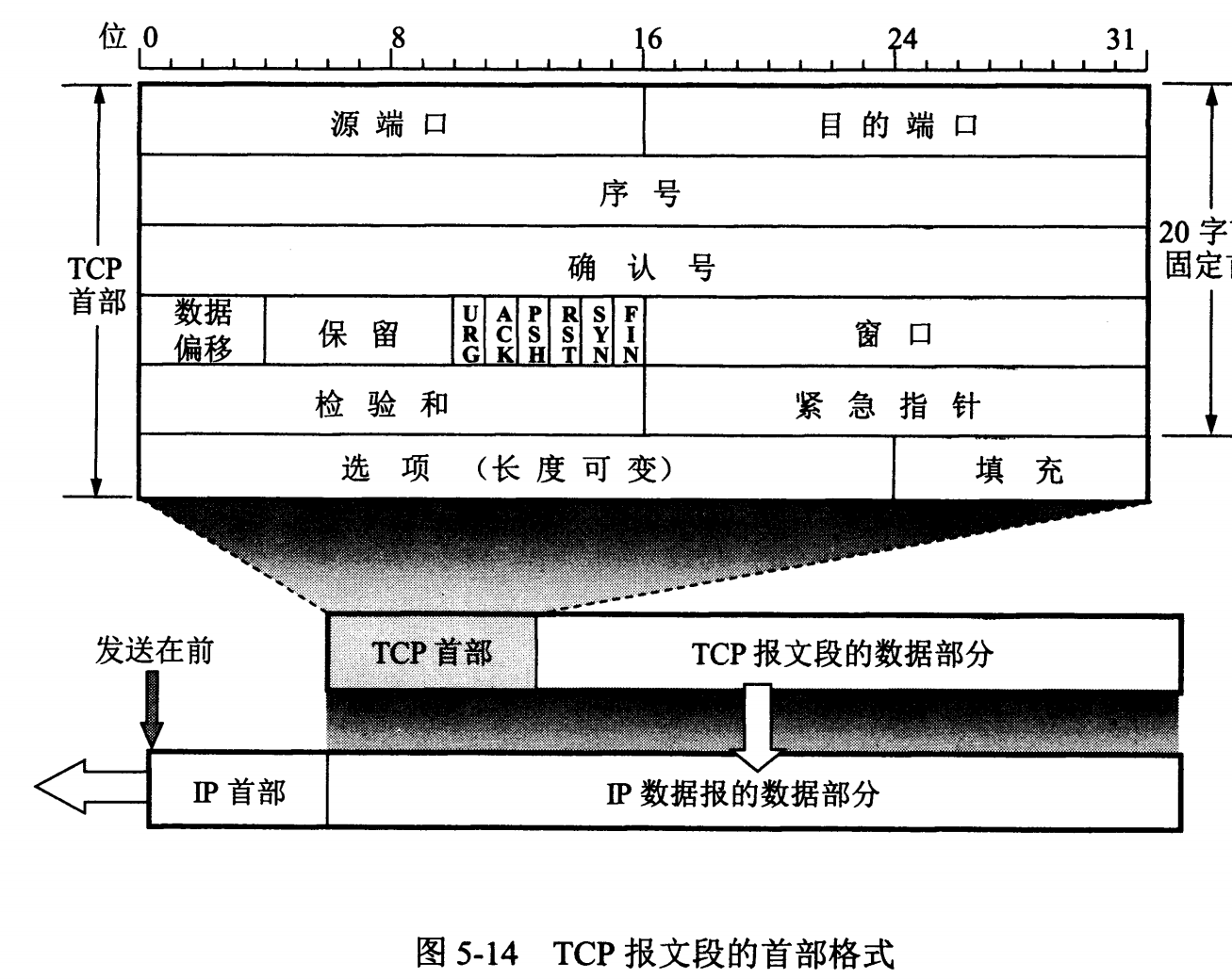\
|
||||
|
||||
- **序号** :用于对字节流进行编号,例如序号为 301,表示第一个字节的编号为 301,如果携带的数据长度为 100 字节,那么下一个报文段的序号应为 401。
|
||||
|
||||
- **确认号** :期望收到的下一个报文段的序号。例如 B 正确收到 A 发送来的一个报文段,序号为 501,携带的数据长度为 200 字节,因此 B 期望下一个报文段的序号为 701,B 发送给 A 的确认报文段中确认号就为 701。
|
||||
|
||||
- **数据偏移** :指的是数据部分距离报文段起始处的偏移量,实际上指的是首部的长度。
|
||||
|
||||
- **确认 ACK** :当 ACK=1 时确认号字段有效,否则无效。TCP 规定,在连接建立后所有传送的报文段都必须把 ACK 置 1。
|
||||
|
||||
- **同步 SYN** :在连接建立时用来同步序号。当 SYN=1,ACK=0 时表示这是一个连接请求报文段。若对方同意建立连接,则响应报文中 SYN=1,ACK=1。
|
||||
|
||||
- **终止 FIN** :用来释放一个连接,当 FIN=1 时,表示此报文段的发送方的数据已发送完毕,并要求释放连接。
|
||||
|
||||
- **窗口** :窗口值作为接收方让发送方设置其发送窗口的依据。之所以要有这个限制,是因为接收方的数据缓存空间是有限的。
|
||||
* **序号** :用于对字节流进行编号,例如序号为 301,表示第一个字节的编号为 301,如果携带的数据长度为 100 字节,那么下一个报文段的序号应为 401。
|
||||
* **确认号** :期望收到的下一个报文段的序号。例如 B 正确收到 A 发送来的一个报文段,序号为 501,携带的数据长度为 200 字节,因此 B 期望下一个报文段的序号为 701,B 发送给 A 的确认报文段中确认号就为 701。
|
||||
* **数据偏移** :指的是数据部分距离报文段起始处的偏移量,实际上指的是首部的长度。
|
||||
* **确认 ACK** :当 ACK=1 时确认号字段有效,否则无效。TCP 规定,在连接建立后所有传送的报文段都必须把 ACK 置 1。
|
||||
* **同步 SYN** :在连接建立时用来同步序号。当 SYN=1,ACK=0 时表示这是一个连接请求报文段。若对方同意建立连接,则响应报文中 SYN=1,ACK=1。
|
||||
* **终止 FIN** :用来释放一个连接,当 FIN=1 时,表示此报文段的发送方的数据已发送完毕,并要求释放连接。
|
||||
* **窗口** :窗口值作为接收方让发送方设置其发送窗口的依据。之所以要有这个限制,是因为接收方的数据缓存空间是有限的。
|
||||
|
||||
## TCP 的三次握手
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/e92d0ebc-7d46-413b-aec1-34a39602f787.png" width="600"/> </div><br>
|
||||
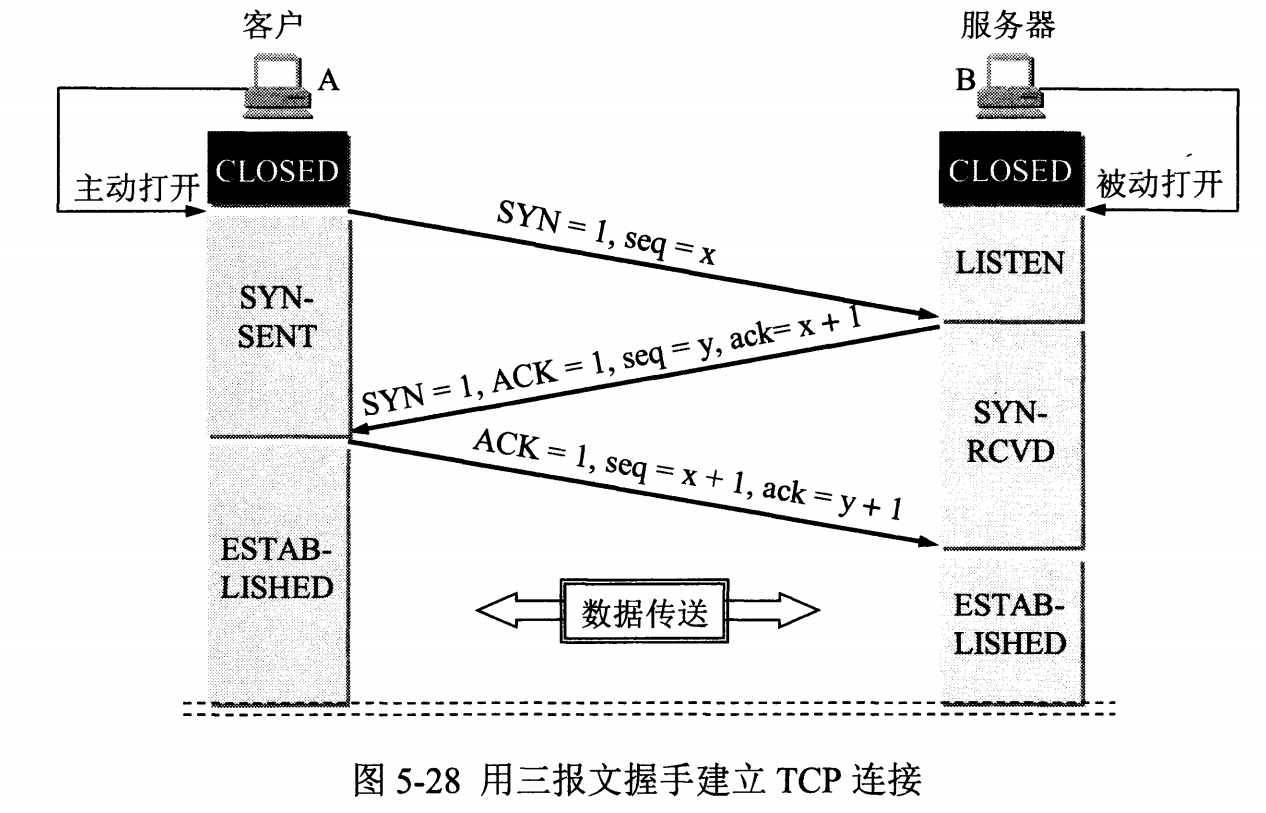\
|
||||
|
||||
|
||||
假设 A 为客户端,B 为服务器端。
|
||||
|
||||
- 首先 B 处于 LISTEN(监听)状态,等待客户的连接请求。
|
||||
* 首先 B 处于 LISTEN(监听)状态,等待客户的连接请求。
|
||||
* A 向 B 发送连接请求报文,SYN=1,ACK=0,选择一个初始的序号 x。
|
||||
* B 收到连接请求报文,如果同意建立连接,则向 A 发送连接确认报文,SYN=1,ACK=1,确认号为 x+1,同时也选择一个初始的序号 y。
|
||||
* A 收到 B 的连接确认报文后,还要向 B 发出确认,确认号为 y+1,序号为 x+1。
|
||||
* B 收到 A 的确认后,连接建立。
|
||||
|
||||
- A 向 B 发送连接请求报文,SYN=1,ACK=0,选择一个初始的序号 x。
|
||||
|
||||
- B 收到连接请求报文,如果同意建立连接,则向 A 发送连接确认报文,SYN=1,ACK=1,确认号为 x+1,同时也选择一个初始的序号 y。
|
||||
|
||||
- A 收到 B 的连接确认报文后,还要向 B 发出确认,确认号为 y+1,序号为 x+1。
|
||||
|
||||
- B 收到 A 的确认后,连接建立。
|
||||
|
||||
**三次握手的原因**
|
||||
**三次握手的原因**
|
||||
|
||||
第三次握手是为了防止失效的连接请求到达服务器,让服务器错误打开连接。
|
||||
|
||||
@ -71,31 +61,27 @@
|
||||
|
||||
## TCP 的四次挥手
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/f87afe72-c2df-4c12-ac03-9b8d581a8af8.jpg" width="600"/> </div><br>
|
||||
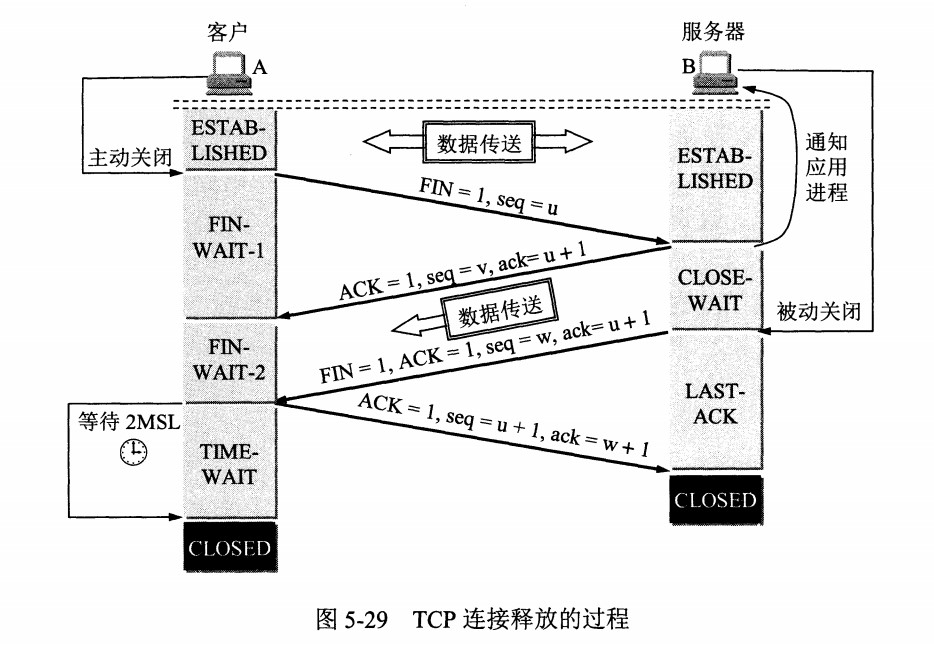\
|
||||
|
||||
|
||||
以下描述不讨论序号和确认号,因为序号和确认号的规则比较简单。并且不讨论 ACK,因为 ACK 在连接建立之后都为 1。
|
||||
|
||||
- A 发送连接释放报文,FIN=1。
|
||||
* A 发送连接释放报文,FIN=1。
|
||||
* B 收到之后发出确认,此时 TCP 属于半关闭状态,B 能向 A 发送数据但是 A 不能向 B 发送数据。
|
||||
* 当 B 不再需要连接时,发送连接释放报文,FIN=1。
|
||||
* A 收到后发出确认,进入 TIME-WAIT 状态,等待 2 MSL(最大报文存活时间)后释放连接。
|
||||
* B 收到 A 的确认后释放连接。
|
||||
|
||||
- B 收到之后发出确认,此时 TCP 属于半关闭状态,B 能向 A 发送数据但是 A 不能向 B 发送数据。
|
||||
|
||||
- 当 B 不再需要连接时,发送连接释放报文,FIN=1。
|
||||
|
||||
- A 收到后发出确认,进入 TIME-WAIT 状态,等待 2 MSL(最大报文存活时间)后释放连接。
|
||||
|
||||
- B 收到 A 的确认后释放连接。
|
||||
|
||||
**四次挥手的原因**
|
||||
**四次挥手的原因**
|
||||
|
||||
客户端发送了 FIN 连接释放报文之后,服务器收到了这个报文,就进入了 CLOSE-WAIT 状态。这个状态是为了让服务器端发送还未传送完毕的数据,传送完毕之后,服务器会发送 FIN 连接释放报文。
|
||||
|
||||
**TIME_WAIT**
|
||||
**TIME\_WAIT**
|
||||
|
||||
客户端接收到服务器端的 FIN 报文后进入此状态,此时并不是直接进入 CLOSED 状态,还需要等待一个时间计时器设置的时间 2MSL。这么做有两个理由:
|
||||
|
||||
- 确保最后一个确认报文能够到达。如果 B 没收到 A 发送来的确认报文,那么就会重新发送连接释放请求报文,A 等待一段时间就是为了处理这种情况的发生。
|
||||
|
||||
- 等待一段时间是为了让本连接持续时间内所产生的所有报文都从网络中消失,使得下一个新的连接不会出现旧的连接请求报文。
|
||||
* 确保最后一个确认报文能够到达。如果 B 没收到 A 发送来的确认报文,那么就会重新发送连接释放请求报文,A 等待一段时间就是为了处理这种情况的发生。
|
||||
* 等待一段时间是为了让本连接持续时间内所产生的所有报文都从网络中消失,使得下一个新的连接不会出现旧的连接请求报文。
|
||||
|
||||
## TCP 可靠传输
|
||||
|
||||
@ -103,13 +89,13 @@ TCP 使用超时重传来实现可靠传输:如果一个已经发送的报文
|
||||
|
||||
一个报文段从发送再到接收到确认所经过的时间称为往返时间 RTT,加权平均往返时间 RTTs 计算如下:
|
||||
|
||||
<div align="center"><img src="https://latex.codecogs.com/gif.latex?RTTs=(1-a)*(RTTs)+a*RTT" class="mathjax-pic"/></div> <br>
|
||||
\*\(RTTs\)+a\*RTT)\
|
||||
其中,0 ≤ a < 1,RTTs 随着 a 的增加更容易受到 RTT 的影响。
|
||||
|
||||
超时时间 RTO 应该略大于 RTTs,TCP 使用的超时时间计算如下:
|
||||
|
||||
<div align="center"><img src="https://latex.codecogs.com/gif.latex?RTO=RTTs+4*RTT_d" class="mathjax-pic"/></div> <br>
|
||||
其中 RTT<sub>d</sub> 为偏差的加权平均值。
|
||||
\
|
||||
其中 RTTd 为偏差的加权平均值。
|
||||
|
||||
## TCP 滑动窗口
|
||||
|
||||
@ -119,7 +105,8 @@ TCP 使用超时重传来实现可靠传输:如果一个已经发送的报文
|
||||
|
||||
接收窗口只会对窗口内最后一个按序到达的字节进行确认,例如接收窗口已经收到的字节为 {31, 34, 35},其中 {31} 按序到达,而 {34, 35} 就不是,因此只对字节 31 进行确认。发送方得到一个字节的确认之后,就知道这个字节之前的所有字节都已经被接收。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/a3253deb-8d21-40a1-aae4-7d178e4aa319.jpg" width="800"/> </div><br>
|
||||
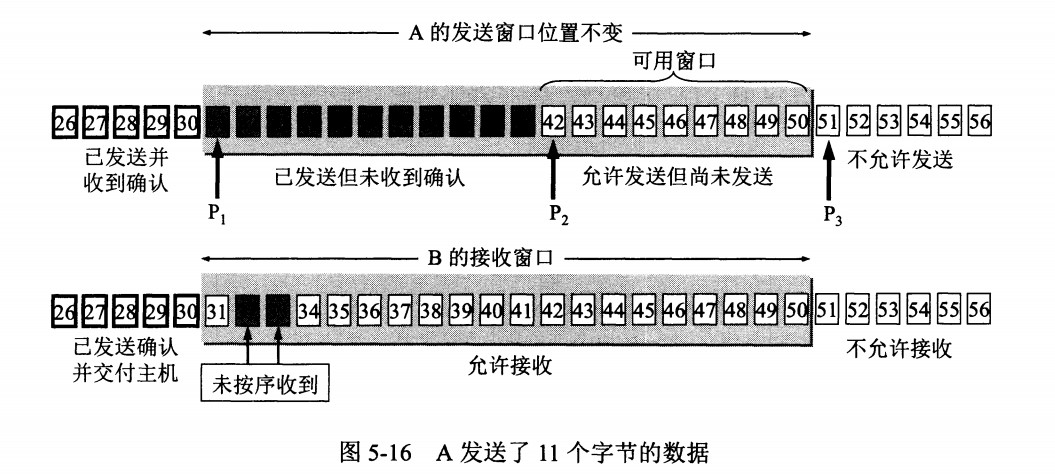\
|
||||
|
||||
|
||||
## TCP 流量控制
|
||||
|
||||
@ -131,7 +118,8 @@ TCP 使用超时重传来实现可靠传输:如果一个已经发送的报文
|
||||
|
||||
如果网络出现拥塞,分组将会丢失,此时发送方会继续重传,从而导致网络拥塞程度更高。因此当出现拥塞时,应当控制发送方的速率。这一点和流量控制很像,但是出发点不同。流量控制是为了让接收方能来得及接收,而拥塞控制是为了降低整个网络的拥塞程度。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/51e2ed95-65b8-4ae9-8af3-65602d452a25.jpg" width="500"/> </div><br>
|
||||
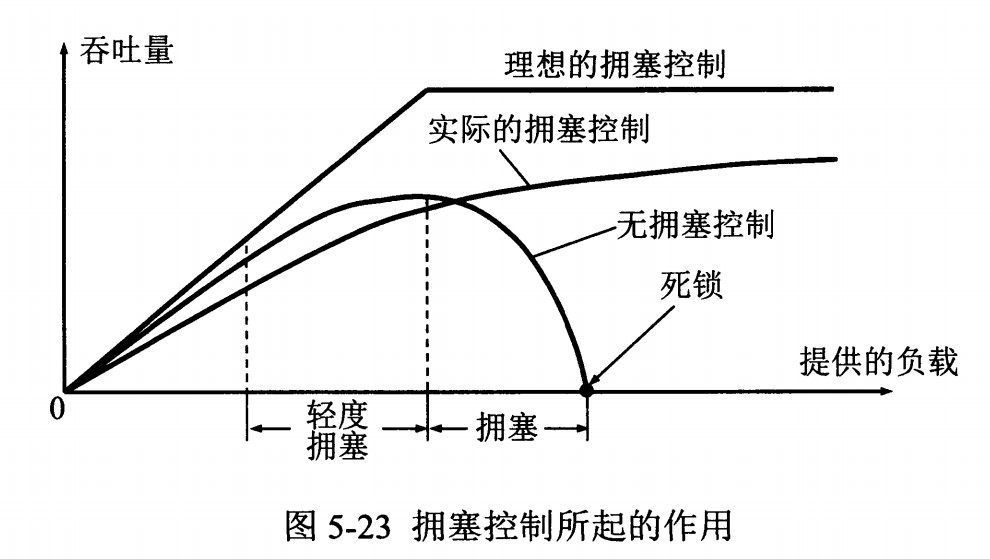\
|
||||
|
||||
|
||||
TCP 主要通过四个算法来进行拥塞控制:慢开始、拥塞避免、快重传、快恢复。
|
||||
|
||||
@ -139,27 +127,28 @@ TCP 主要通过四个算法来进行拥塞控制:慢开始、拥塞避免、
|
||||
|
||||
为了便于讨论,做如下假设:
|
||||
|
||||
- 接收方有足够大的接收缓存,因此不会发生流量控制;
|
||||
- 虽然 TCP 的窗口基于字节,但是这里设窗口的大小单位为报文段。
|
||||
* 接收方有足够大的接收缓存,因此不会发生流量控制;
|
||||
* 虽然 TCP 的窗口基于字节,但是这里设窗口的大小单位为报文段。
|
||||
|
||||
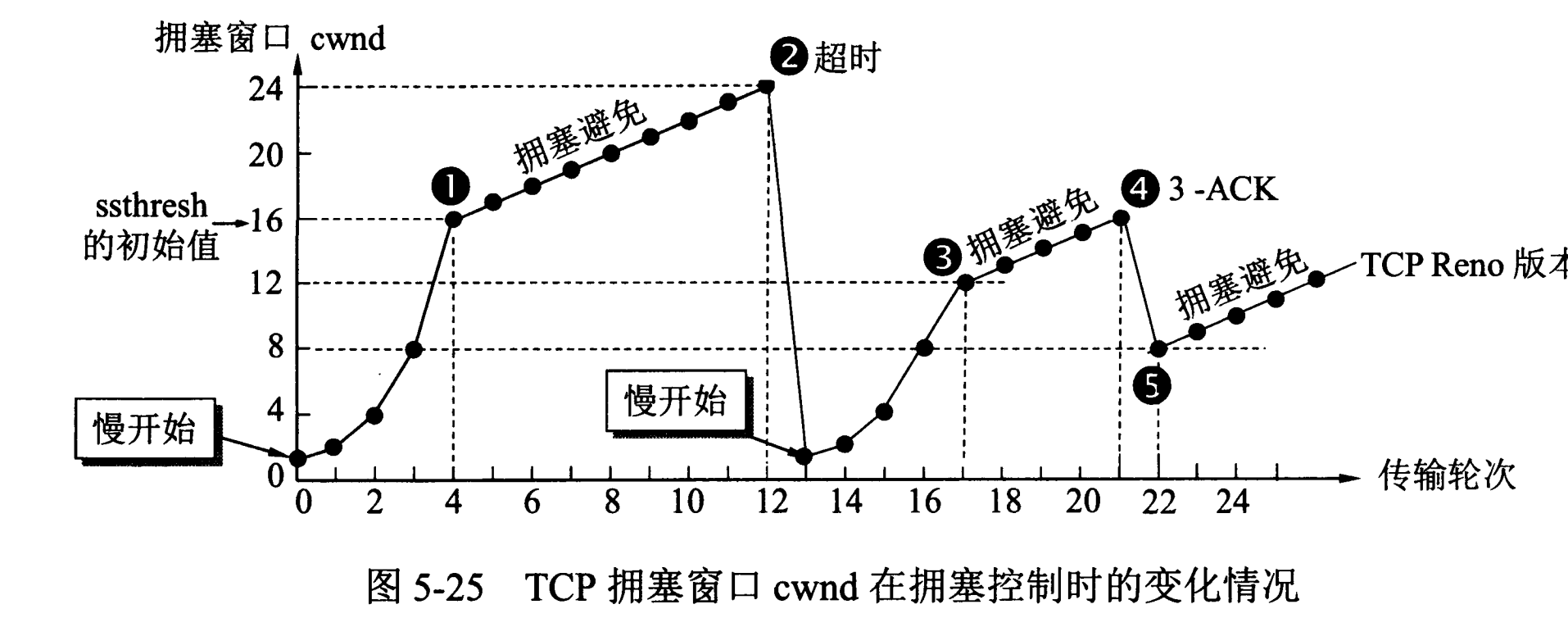\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/910f613f-514f-4534-87dd-9b4699d59d31.png" width="800"/> </div><br>
|
||||
|
||||
### 1. 慢开始与拥塞避免
|
||||
|
||||
发送的最初执行慢开始,令 cwnd = 1,发送方只能发送 1 个报文段;当收到确认后,将 cwnd 加倍,因此之后发送方能够发送的报文段数量为:2、4、8 ...
|
||||
|
||||
注意到慢开始每个轮次都将 cwnd 加倍,这样会让 cwnd 增长速度非常快,从而使得发送方发送的速度增长速度过快,网络拥塞的可能性也就更高。设置一个慢开始门限 ssthresh,当 cwnd \>= ssthresh 时,进入拥塞避免,每个轮次只将 cwnd 加 1。
|
||||
注意到慢开始每个轮次都将 cwnd 加倍,这样会让 cwnd 增长速度非常快,从而使得发送方发送的速度增长速度过快,网络拥塞的可能性也就更高。设置一个慢开始门限 ssthresh,当 cwnd >= ssthresh 时,进入拥塞避免,每个轮次只将 cwnd 加 1。
|
||||
|
||||
如果出现了超时,则令 ssthresh = cwnd / 2,然后重新执行慢开始。
|
||||
|
||||
### 2. 快重传与快恢复
|
||||
|
||||
在接收方,要求每次接收到报文段都应该对最后一个已收到的有序报文段进行确认。例如已经接收到 M<sub>1</sub> 和 M<sub>2</sub>,此时收到 M<sub>4</sub>,应当发送对 M<sub>2</sub> 的确认。
|
||||
在接收方,要求每次接收到报文段都应该对最后一个已收到的有序报文段进行确认。例如已经接收到 M1 和 M2,此时收到 M4,应当发送对 M2 的确认。
|
||||
|
||||
在发送方,如果收到三个重复确认,那么可以知道下一个报文段丢失,此时执行快重传,立即重传下一个报文段。例如收到三个 M<sub>2</sub>,则 M<sub>3</sub> 丢失,立即重传 M<sub>3</sub>。
|
||||
在发送方,如果收到三个重复确认,那么可以知道下一个报文段丢失,此时执行快重传,立即重传下一个报文段。例如收到三个 M2,则 M3 丢失,立即重传 M3。
|
||||
|
||||
在这种情况下,只是丢失个别报文段,而不是网络拥塞。因此执行快恢复,令 ssthresh = cwnd / 2 ,cwnd = ssthresh,注意到此时直接进入拥塞避免。
|
||||
|
||||
慢开始和快恢复的快慢指的是 cwnd 的设定值,而不是 cwnd 的增长速率。慢开始 cwnd 设定为 1,而快恢复 cwnd 设定为 ssthresh。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/f61b5419-c94a-4df1-8d4d-aed9ae8cc6d5.png" width="600"/> </div><br>
|
||||
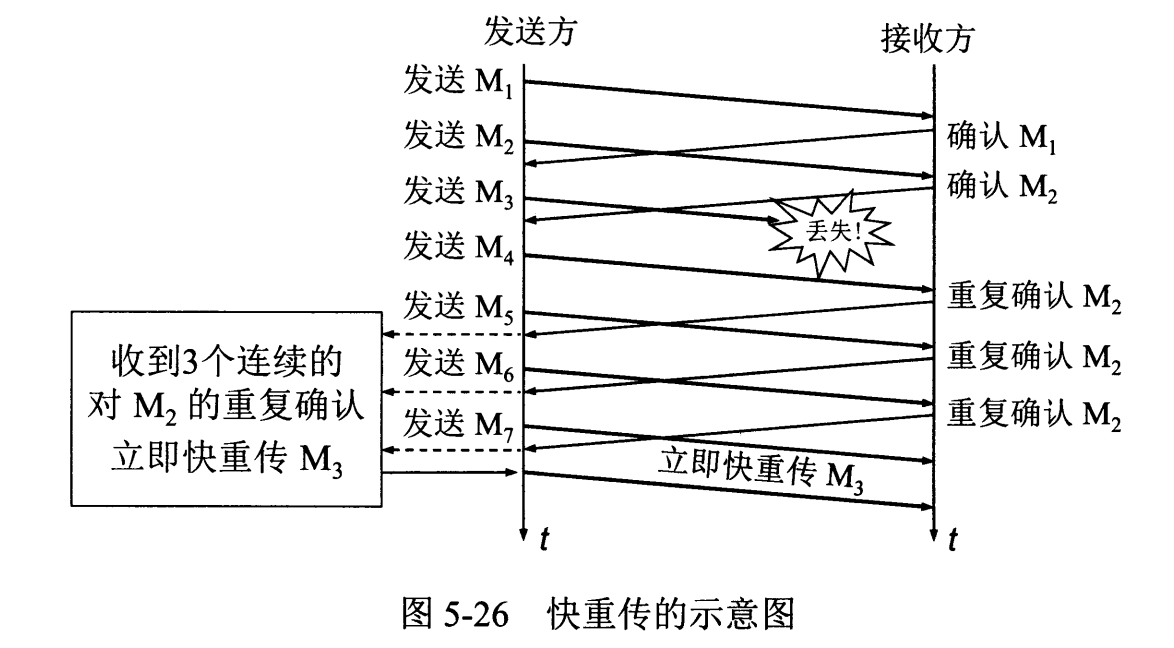\
|
||||
|
||||
@ -1,22 +1,20 @@
|
||||
# 计算机网络 - 应用层
|
||||
<!-- GFM-TOC -->
|
||||
* [计算机网络 - 应用层](#计算机网络---应用层)
|
||||
* [域名系统](#域名系统)
|
||||
* [文件传送协议](#文件传送协议)
|
||||
* [动态主机配置协议](#动态主机配置协议)
|
||||
* [远程登录协议](#远程登录协议)
|
||||
* [电子邮件协议](#电子邮件协议)
|
||||
* [1. SMTP](#1-smtp)
|
||||
* [2. POP3](#2-pop3)
|
||||
* [3. IMAP](#3-imap)
|
||||
* [常用端口](#常用端口)
|
||||
* [Web 页面请求过程](#web-页面请求过程)
|
||||
* [1. DHCP 配置主机信息](#1-dhcp-配置主机信息)
|
||||
* [2. ARP 解析 MAC 地址](#2-arp-解析-mac-地址)
|
||||
* [3. DNS 解析域名](#3-dns-解析域名)
|
||||
* [4. HTTP 请求页面](#4-http-请求页面)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [计算机网络 - 应用层](<计算机网络 - 应用层.md#计算机网络---应用层>)
|
||||
* [域名系统](<计算机网络 - 应用层.md#域名系统>)
|
||||
* [文件传送协议](<计算机网络 - 应用层.md#文件传送协议>)
|
||||
* [动态主机配置协议](<计算机网络 - 应用层.md#动态主机配置协议>)
|
||||
* [远程登录协议](<计算机网络 - 应用层.md#远程登录协议>)
|
||||
* [电子邮件协议](<计算机网络 - 应用层.md#电子邮件协议>)
|
||||
* [1. SMTP](<计算机网络 - 应用层.md#1-smtp>)
|
||||
* [2. POP3](<计算机网络 - 应用层.md#2-pop3>)
|
||||
* [3. IMAP](<计算机网络 - 应用层.md#3-imap>)
|
||||
* [常用端口](<计算机网络 - 应用层.md#常用端口>)
|
||||
* [Web 页面请求过程](<计算机网络 - 应用层.md#web-页面请求过程>)
|
||||
* [1. DHCP 配置主机信息](<计算机网络 - 应用层.md#1-dhcp-配置主机信息>)
|
||||
* [2. ARP 解析 MAC 地址](<计算机网络 - 应用层.md#2-arp-解析-mac-地址>)
|
||||
* [3. DNS 解析域名](<计算机网络 - 应用层.md#3-dns-解析域名>)
|
||||
* [4. HTTP 请求页面](<计算机网络 - 应用层.md#4-http-请求页面>)
|
||||
|
||||
## 域名系统
|
||||
|
||||
@ -24,29 +22,32 @@ DNS 是一个分布式数据库,提供了主机名和 IP 地址之间相互转
|
||||
|
||||
域名具有层次结构,从上到下依次为:根域名、顶级域名、二级域名。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/b54eeb16-0b0e-484c-be62-306f57c40d77.jpg"/> </div><br>
|
||||
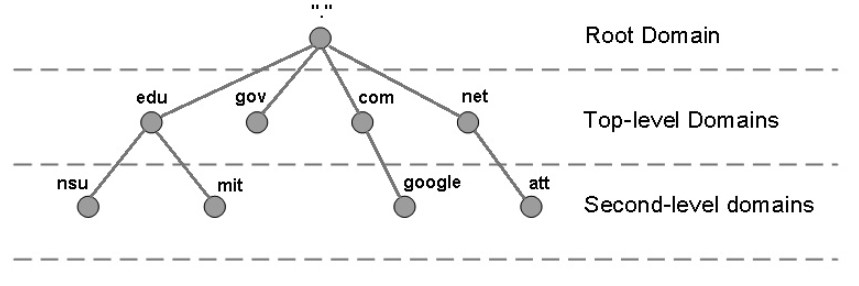\
|
||||
|
||||
|
||||
DNS 可以使用 UDP 或者 TCP 进行传输,使用的端口号都为 53。大多数情况下 DNS 使用 UDP 进行传输,这就要求域名解析器和域名服务器都必须自己处理超时和重传从而保证可靠性。在两种情况下会使用 TCP 进行传输:
|
||||
|
||||
- 如果返回的响应超过的 512 字节(UDP 最大只支持 512 字节的数据)。
|
||||
- 区域传送(区域传送是主域名服务器向辅助域名服务器传送变化的那部分数据)。
|
||||
* 如果返回的响应超过的 512 字节(UDP 最大只支持 512 字节的数据)。
|
||||
* 区域传送(区域传送是主域名服务器向辅助域名服务器传送变化的那部分数据)。
|
||||
|
||||
## 文件传送协议
|
||||
|
||||
FTP 使用 TCP 进行连接,它需要两个连接来传送一个文件:
|
||||
|
||||
- 控制连接:服务器打开端口号 21 等待客户端的连接,客户端主动建立连接后,使用这个连接将客户端的命令传送给服务器,并传回服务器的应答。
|
||||
- 数据连接:用来传送一个文件数据。
|
||||
* 控制连接:服务器打开端口号 21 等待客户端的连接,客户端主动建立连接后,使用这个连接将客户端的命令传送给服务器,并传回服务器的应答。
|
||||
* 数据连接:用来传送一个文件数据。
|
||||
|
||||
根据数据连接是否是服务器端主动建立,FTP 有主动和被动两种模式:
|
||||
|
||||
- 主动模式:服务器端主动建立数据连接,其中服务器端的端口号为 20,客户端的端口号随机,但是必须大于 1024,因为 0\~1023 是熟知端口号。
|
||||
* 主动模式:服务器端主动建立数据连接,其中服务器端的端口号为 20,客户端的端口号随机,但是必须大于 1024,因为 0\~1023 是熟知端口号。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/03f47940-3843-4b51-9e42-5dcaff44858b.jpg"/> </div><br>
|
||||
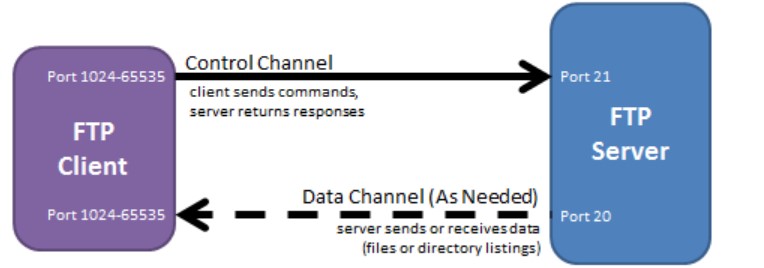\
|
||||
|
||||
- 被动模式:客户端主动建立数据连接,其中客户端的端口号由客户端自己指定,服务器端的端口号随机。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/be5c2c61-86d2-4dba-a289-b48ea23219de.jpg"/> </div><br>
|
||||
* 被动模式:客户端主动建立数据连接,其中客户端的端口号由客户端自己指定,服务器端的端口号随机。
|
||||
|
||||
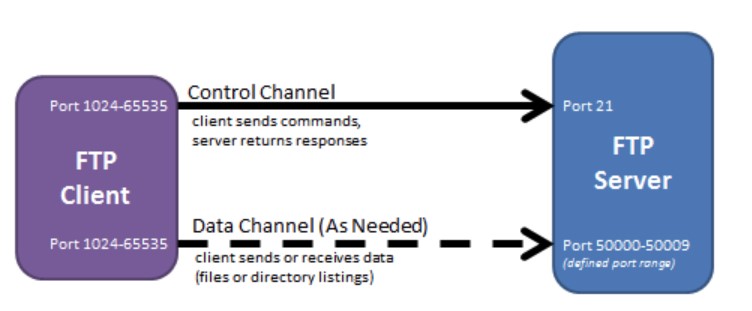\
|
||||
|
||||
|
||||
主动模式要求客户端开放端口号给服务器端,需要去配置客户端的防火墙。被动模式只需要服务器端开放端口号即可,无需客户端配置防火墙。但是被动模式会导致服务器端的安全性减弱,因为开放了过多的端口号。
|
||||
|
||||
@ -63,7 +64,8 @@ DHCP 工作过程如下:
|
||||
3. 如果客户端选择了某个 DHCP 服务器提供的信息,那么就发送 Request 报文给该 DHCP 服务器。
|
||||
4. DHCP 服务器发送 Ack 报文,表示客户端此时可以使用提供给它的信息。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/23219e4c-9fc0-4051-b33a-2bd95bf054ab.jpg"/> </div><br>
|
||||
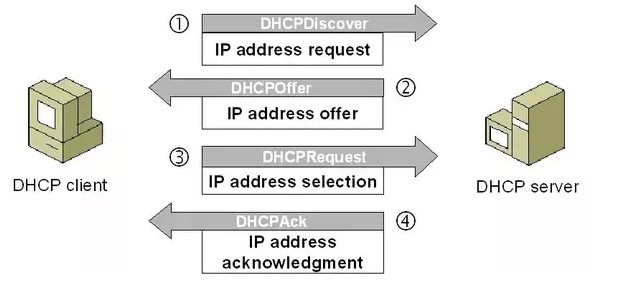\
|
||||
|
||||
|
||||
## 远程登录协议
|
||||
|
||||
@ -77,13 +79,15 @@ TELNET 可以适应许多计算机和操作系统的差异,例如不同操作
|
||||
|
||||
邮件协议包含发送协议和读取协议,发送协议常用 SMTP,读取协议常用 POP3 和 IMAP。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/7b3efa99-d306-4982-8cfb-e7153c33aab4.png" width="700"/> </div><br>
|
||||
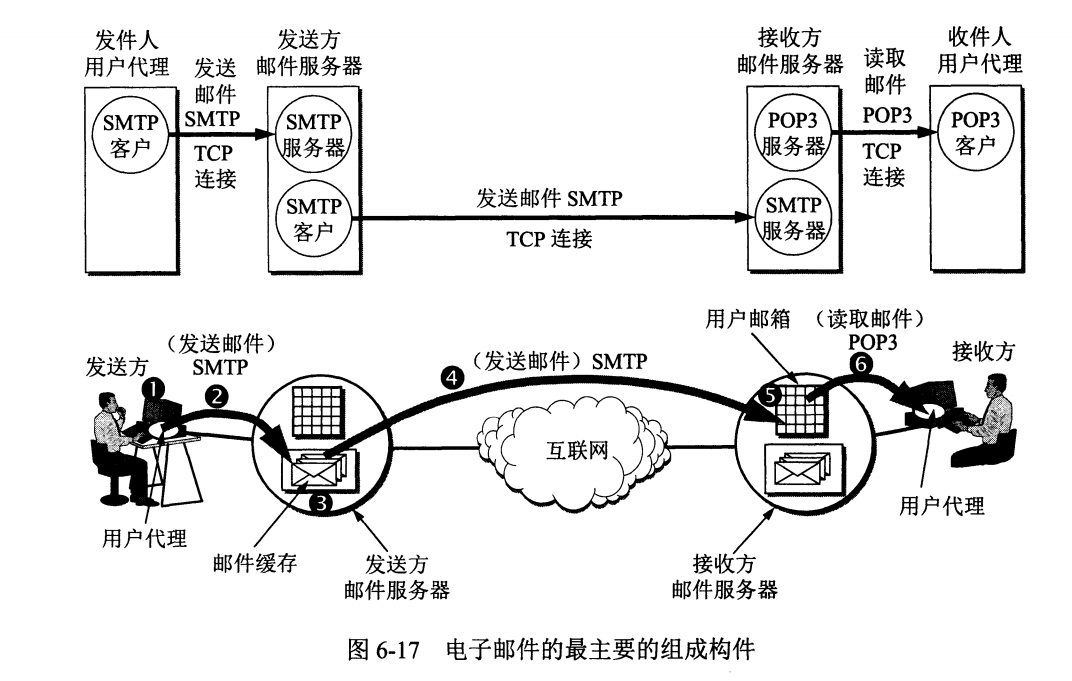\
|
||||
|
||||
|
||||
### 1. SMTP
|
||||
|
||||
SMTP 只能发送 ASCII 码,而互联网邮件扩充 MIME 可以发送二进制文件。MIME 并没有改动或者取代 SMTP,而是增加邮件主体的结构,定义了非 ASCII 码的编码规则。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/ed5522bb-3a60-481c-8654-43e7195a48fe.png" width=""/> </div><br>
|
||||
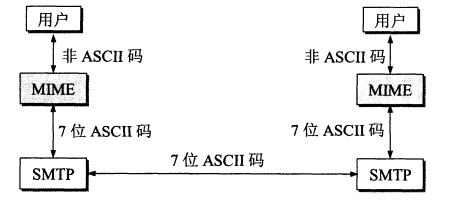\
|
||||
|
||||
|
||||
### 2. POP3
|
||||
|
||||
@ -95,74 +99,53 @@ IMAP 协议中客户端和服务器上的邮件保持同步,如果不手动删
|
||||
|
||||
## 常用端口
|
||||
|
||||
|应用| 应用层协议 | 端口号 | 传输层协议 | 备注 |
|
||||
| :---: | :--: | :--: | :--: | :--: |
|
||||
| 域名解析 | DNS | 53 | UDP/TCP | 长度超过 512 字节时使用 TCP |
|
||||
| 动态主机配置协议 | DHCP | 67/68 | UDP | |
|
||||
| 简单网络管理协议 | SNMP | 161/162 | UDP | |
|
||||
| 文件传送协议 | FTP | 20/21 | TCP | 控制连接 21,数据连接 20 |
|
||||
| 远程终端协议 | TELNET | 23 | TCP | |
|
||||
| 超文本传送协议 | HTTP | 80 | TCP | |
|
||||
| 简单邮件传送协议 | SMTP | 25 | TCP | |
|
||||
| 邮件读取协议 | POP3 | 110 | TCP | |
|
||||
| 网际报文存取协议 | IMAP | 143 | TCP | |
|
||||
| 应用 | 应用层协议 | 端口号 | 传输层协议 | 备注 |
|
||||
| :------: | :----: | :-----: | :-----: | :----------------: |
|
||||
| 域名解析 | DNS | 53 | UDP/TCP | 长度超过 512 字节时使用 TCP |
|
||||
| 动态主机配置协议 | DHCP | 67/68 | UDP | |
|
||||
| 简单网络管理协议 | SNMP | 161/162 | UDP | |
|
||||
| 文件传送协议 | FTP | 20/21 | TCP | 控制连接 21,数据连接 20 |
|
||||
| 远程终端协议 | TELNET | 23 | TCP | |
|
||||
| 超文本传送协议 | HTTP | 80 | TCP | |
|
||||
| 简单邮件传送协议 | SMTP | 25 | TCP | |
|
||||
| 邮件读取协议 | POP3 | 110 | TCP | |
|
||||
| 网际报文存取协议 | IMAP | 143 | TCP | |
|
||||
|
||||
## Web 页面请求过程
|
||||
|
||||
### 1. DHCP 配置主机信息
|
||||
|
||||
- 假设主机最开始没有 IP 地址以及其它信息,那么就需要先使用 DHCP 来获取。
|
||||
|
||||
- 主机生成一个 DHCP 请求报文,并将这个报文放入具有目的端口 67 和源端口 68 的 UDP 报文段中。
|
||||
|
||||
- 该报文段则被放入在一个具有广播 IP 目的地址(255.255.255.255) 和源 IP 地址(0.0.0.0)的 IP 数据报中。
|
||||
|
||||
- 该数据报则被放置在 MAC 帧中,该帧具有目的地址 FF:\<zero-width space\>FF:\<zero-width space\>FF:\<zero-width space\>FF:\<zero-width space\>FF:FF,将广播到与交换机连接的所有设备。
|
||||
|
||||
- 连接在交换机的 DHCP 服务器收到广播帧之后,不断地向上分解得到 IP 数据报、UDP 报文段、DHCP 请求报文,之后生成 DHCP ACK 报文,该报文包含以下信息:IP 地址、DNS 服务器的 IP 地址、默认网关路由器的 IP 地址和子网掩码。该报文被放入 UDP 报文段中,UDP 报文段有被放入 IP 数据报中,最后放入 MAC 帧中。
|
||||
|
||||
- 该帧的目的地址是请求主机的 MAC 地址,因为交换机具有自学习能力,之前主机发送了广播帧之后就记录了 MAC 地址到其转发接口的交换表项,因此现在交换机就可以直接知道应该向哪个接口发送该帧。
|
||||
|
||||
- 主机收到该帧后,不断分解得到 DHCP 报文。之后就配置它的 IP 地址、子网掩码和 DNS 服务器的 IP 地址,并在其 IP 转发表中安装默认网关。
|
||||
* 假设主机最开始没有 IP 地址以及其它信息,那么就需要先使用 DHCP 来获取。
|
||||
* 主机生成一个 DHCP 请求报文,并将这个报文放入具有目的端口 67 和源端口 68 的 UDP 报文段中。
|
||||
* 该报文段则被放入在一个具有广播 IP 目的地址(255.255.255.255) 和源 IP 地址(0.0.0.0)的 IP 数据报中。
|
||||
* 该数据报则被放置在 MAC 帧中,该帧具有目的地址 FF:\<zero-width space>FF:\<zero-width space>FF:\<zero-width space>FF:\<zero-width space>FF:FF,将广播到与交换机连接的所有设备。
|
||||
* 连接在交换机的 DHCP 服务器收到广播帧之后,不断地向上分解得到 IP 数据报、UDP 报文段、DHCP 请求报文,之后生成 DHCP ACK 报文,该报文包含以下信息:IP 地址、DNS 服务器的 IP 地址、默认网关路由器的 IP 地址和子网掩码。该报文被放入 UDP 报文段中,UDP 报文段有被放入 IP 数据报中,最后放入 MAC 帧中。
|
||||
* 该帧的目的地址是请求主机的 MAC 地址,因为交换机具有自学习能力,之前主机发送了广播帧之后就记录了 MAC 地址到其转发接口的交换表项,因此现在交换机就可以直接知道应该向哪个接口发送该帧。
|
||||
* 主机收到该帧后,不断分解得到 DHCP 报文。之后就配置它的 IP 地址、子网掩码和 DNS 服务器的 IP 地址,并在其 IP 转发表中安装默认网关。
|
||||
|
||||
### 2. ARP 解析 MAC 地址
|
||||
|
||||
- 主机通过浏览器生成一个 TCP 套接字,套接字向 HTTP 服务器发送 HTTP 请求。为了生成该套接字,主机需要知道网站的域名对应的 IP 地址。
|
||||
|
||||
- 主机生成一个 DNS 查询报文,该报文具有 53 号端口,因为 DNS 服务器的端口号是 53。
|
||||
|
||||
- 该 DNS 查询报文被放入目的地址为 DNS 服务器 IP 地址的 IP 数据报中。
|
||||
|
||||
- 该 IP 数据报被放入一个以太网帧中,该帧将发送到网关路由器。
|
||||
|
||||
- DHCP 过程只知道网关路由器的 IP 地址,为了获取网关路由器的 MAC 地址,需要使用 ARP 协议。
|
||||
|
||||
- 主机生成一个包含目的地址为网关路由器 IP 地址的 ARP 查询报文,将该 ARP 查询报文放入一个具有广播目的地址(FF:\<zero-width space\>FF:\<zero-width space\>FF:\<zero-width space\>FF:\<zero-width space\>FF:FF)的以太网帧中,并向交换机发送该以太网帧,交换机将该帧转发给所有的连接设备,包括网关路由器。
|
||||
|
||||
- 网关路由器接收到该帧后,不断向上分解得到 ARP 报文,发现其中的 IP 地址与其接口的 IP 地址匹配,因此就发送一个 ARP 回答报文,包含了它的 MAC 地址,发回给主机。
|
||||
* 主机通过浏览器生成一个 TCP 套接字,套接字向 HTTP 服务器发送 HTTP 请求。为了生成该套接字,主机需要知道网站的域名对应的 IP 地址。
|
||||
* 主机生成一个 DNS 查询报文,该报文具有 53 号端口,因为 DNS 服务器的端口号是 53。
|
||||
* 该 DNS 查询报文被放入目的地址为 DNS 服务器 IP 地址的 IP 数据报中。
|
||||
* 该 IP 数据报被放入一个以太网帧中,该帧将发送到网关路由器。
|
||||
* DHCP 过程只知道网关路由器的 IP 地址,为了获取网关路由器的 MAC 地址,需要使用 ARP 协议。
|
||||
* 主机生成一个包含目的地址为网关路由器 IP 地址的 ARP 查询报文,将该 ARP 查询报文放入一个具有广播目的地址(FF:\<zero-width space>FF:\<zero-width space>FF:\<zero-width space>FF:\<zero-width space>FF:FF)的以太网帧中,并向交换机发送该以太网帧,交换机将该帧转发给所有的连接设备,包括网关路由器。
|
||||
* 网关路由器接收到该帧后,不断向上分解得到 ARP 报文,发现其中的 IP 地址与其接口的 IP 地址匹配,因此就发送一个 ARP 回答报文,包含了它的 MAC 地址,发回给主机。
|
||||
|
||||
### 3. DNS 解析域名
|
||||
|
||||
- 知道了网关路由器的 MAC 地址之后,就可以继续 DNS 的解析过程了。
|
||||
|
||||
- 网关路由器接收到包含 DNS 查询报文的以太网帧后,抽取出 IP 数据报,并根据转发表决定该 IP 数据报应该转发的路由器。
|
||||
|
||||
- 因为路由器具有内部网关协议(RIP、OSPF)和外部网关协议(BGP)这两种路由选择协议,因此路由表中已经配置了网关路由器到达 DNS 服务器的路由表项。
|
||||
|
||||
- 到达 DNS 服务器之后,DNS 服务器抽取出 DNS 查询报文,并在 DNS 数据库中查找待解析的域名。
|
||||
|
||||
- 找到 DNS 记录之后,发送 DNS 回答报文,将该回答报文放入 UDP 报文段中,然后放入 IP 数据报中,通过路由器反向转发回网关路由器,并经过以太网交换机到达主机。
|
||||
* 知道了网关路由器的 MAC 地址之后,就可以继续 DNS 的解析过程了。
|
||||
* 网关路由器接收到包含 DNS 查询报文的以太网帧后,抽取出 IP 数据报,并根据转发表决定该 IP 数据报应该转发的路由器。
|
||||
* 因为路由器具有内部网关协议(RIP、OSPF)和外部网关协议(BGP)这两种路由选择协议,因此路由表中已经配置了网关路由器到达 DNS 服务器的路由表项。
|
||||
* 到达 DNS 服务器之后,DNS 服务器抽取出 DNS 查询报文,并在 DNS 数据库中查找待解析的域名。
|
||||
* 找到 DNS 记录之后,发送 DNS 回答报文,将该回答报文放入 UDP 报文段中,然后放入 IP 数据报中,通过路由器反向转发回网关路由器,并经过以太网交换机到达主机。
|
||||
|
||||
### 4. HTTP 请求页面
|
||||
|
||||
- 有了 HTTP 服务器的 IP 地址之后,主机就能够生成 TCP 套接字,该套接字将用于向 Web 服务器发送 HTTP GET 报文。
|
||||
|
||||
- 在生成 TCP 套接字之前,必须先与 HTTP 服务器进行三次握手来建立连接。生成一个具有目的端口 80 的 TCP SYN 报文段,并向 HTTP 服务器发送该报文段。
|
||||
|
||||
- HTTP 服务器收到该报文段之后,生成 TCP SYN ACK 报文段,发回给主机。
|
||||
|
||||
- 连接建立之后,浏览器生成 HTTP GET 报文,并交付给 HTTP 服务器。
|
||||
|
||||
- HTTP 服务器从 TCP 套接字读取 HTTP GET 报文,生成一个 HTTP 响应报文,将 Web 页面内容放入报文主体中,发回给主机。
|
||||
|
||||
- 浏览器收到 HTTP 响应报文后,抽取出 Web 页面内容,之后进行渲染,显示 Web 页面。
|
||||
* 有了 HTTP 服务器的 IP 地址之后,主机就能够生成 TCP 套接字,该套接字将用于向 Web 服务器发送 HTTP GET 报文。
|
||||
* 在生成 TCP 套接字之前,必须先与 HTTP 服务器进行三次握手来建立连接。生成一个具有目的端口 80 的 TCP SYN 报文段,并向 HTTP 服务器发送该报文段。
|
||||
* HTTP 服务器收到该报文段之后,生成 TCP SYN ACK 报文段,发回给主机。
|
||||
* 连接建立之后,浏览器生成 HTTP GET 报文,并交付给 HTTP 服务器。
|
||||
* HTTP 服务器从 TCP 套接字读取 HTTP GET 报文,生成一个 HTTP 响应报文,将 Web 页面内容放入报文主体中,发回给主机。
|
||||
* 浏览器收到 HTTP 响应报文后,抽取出 Web 页面内容,之后进行渲染,显示 Web 页面。
|
||||
|
||||
@ -1,50 +1,53 @@
|
||||
# 计算机网络 - 概述
|
||||
<!-- GFM-TOC -->
|
||||
* [计算机网络 - 概述](#计算机网络---概述)
|
||||
* [网络的网络](#网络的网络)
|
||||
* [ISP](#isp)
|
||||
* [主机之间的通信方式](#主机之间的通信方式)
|
||||
* [电路交换与分组交换](#电路交换与分组交换)
|
||||
* [1. 电路交换](#1-电路交换)
|
||||
* [2. 分组交换](#2-分组交换)
|
||||
* [时延](#时延)
|
||||
* [1. 排队时延](#1-排队时延)
|
||||
* [2. 处理时延](#2-处理时延)
|
||||
* [3. 传输时延](#3-传输时延)
|
||||
* [4. 传播时延](#4-传播时延)
|
||||
* [计算机网络体系结构](#计算机网络体系结构)
|
||||
* [1. 五层协议](#1-五层协议)
|
||||
* [2. OSI](#2-osi)
|
||||
* [3. TCP/IP](#3-tcpip)
|
||||
* [4. 数据在各层之间的传递过程](#4-数据在各层之间的传递过程)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [计算机网络 - 概述](<计算机网络 - 概述.md#计算机网络---概述>)
|
||||
* [网络的网络](<计算机网络 - 概述.md#网络的网络>)
|
||||
* [ISP](<计算机网络 - 概述.md#isp>)
|
||||
* [主机之间的通信方式](<计算机网络 - 概述.md#主机之间的通信方式>)
|
||||
* [电路交换与分组交换](<计算机网络 - 概述.md#电路交换与分组交换>)
|
||||
* [1. 电路交换](<计算机网络 - 概述.md#1-电路交换>)
|
||||
* [2. 分组交换](<计算机网络 - 概述.md#2-分组交换>)
|
||||
* [时延](<计算机网络 - 概述.md#时延>)
|
||||
* [1. 排队时延](<计算机网络 - 概述.md#1-排队时延>)
|
||||
* [2. 处理时延](<计算机网络 - 概述.md#2-处理时延>)
|
||||
* [3. 传输时延](<计算机网络 - 概述.md#3-传输时延>)
|
||||
* [4. 传播时延](<计算机网络 - 概述.md#4-传播时延>)
|
||||
* [计算机网络体系结构](<计算机网络 - 概述.md#计算机网络体系结构>)
|
||||
* [1. 五层协议](<计算机网络 - 概述.md#1-五层协议>)
|
||||
* [2. OSI](<计算机网络 - 概述.md#2-osi>)
|
||||
* [3. TCP/IP](<计算机网络 - 概述.md#3-tcpip>)
|
||||
* [4. 数据在各层之间的传递过程](<计算机网络 - 概述.md#4-数据在各层之间的传递过程>)
|
||||
|
||||
## 网络的网络
|
||||
|
||||
网络把主机连接起来,而互连网(internet)是把多种不同的网络连接起来,因此互连网是网络的网络。而互联网(Internet)是全球范围的互连网。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/network-of-networks.gif" width="450"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## ISP
|
||||
|
||||
互联网服务提供商 ISP 可以从互联网管理机构获得许多 IP 地址,同时拥有通信线路以及路由器等联网设备,个人或机构向 ISP 缴纳一定的费用就可以接入互联网。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/72be01cd-41ae-45f7-99b9-a8d284e44dd4.png" width="500"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
目前的互联网是一种多层次 ISP 结构,ISP 根据覆盖面积的大小分为第一层 ISP、区域 ISP 和接入 ISP。互联网交换点 IXP 允许两个 ISP 直接相连而不用经过第三个 ISP。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/3be42601-9d33-4d29-8358-a9d16453af93.png" width="500"/> </div><br>
|
||||
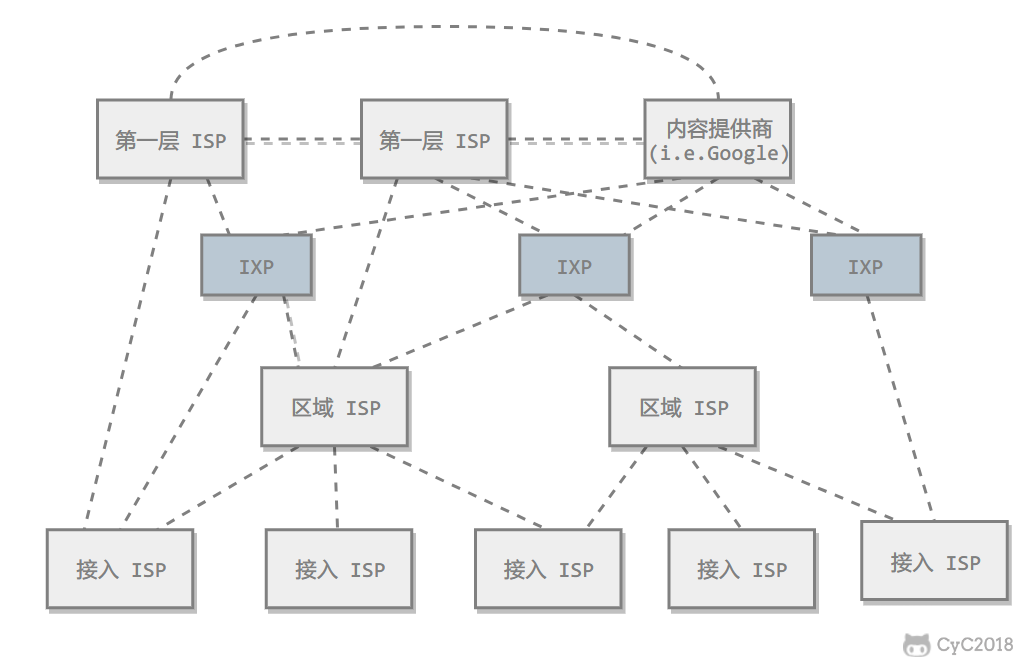\
|
||||
|
||||
|
||||
## 主机之间的通信方式
|
||||
|
||||
- 客户-服务器(C/S):客户是服务的请求方,服务器是服务的提供方。
|
||||
* 客户-服务器(C/S):客户是服务的请求方,服务器是服务的提供方。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/914894c2-0bc4-46b5-bef9-0316a69ef521.jpg" width="240px"> </div><br>
|
||||
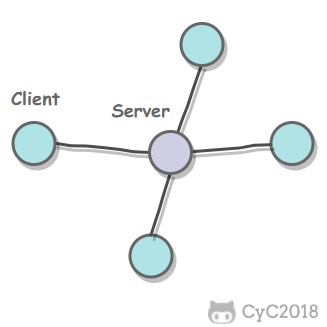\
|
||||
|
||||
- 对等(P2P):不区分客户和服务器。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/42430e94-3137-48c0-bdb6-3cebaf9102e3.jpg" width="200px"> </div><br>
|
||||
* 对等(P2P):不区分客户和服务器。
|
||||
|
||||
\
|
||||
|
||||
|
||||
## 电路交换与分组交换
|
||||
|
||||
@ -62,7 +65,8 @@
|
||||
|
||||
总时延 = 排队时延 + 处理时延 + 传输时延 + 传播时延
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/4b2ae78c-e254-44df-9e37-578e2f2bef52.jpg" width="380"/> </div><br>
|
||||
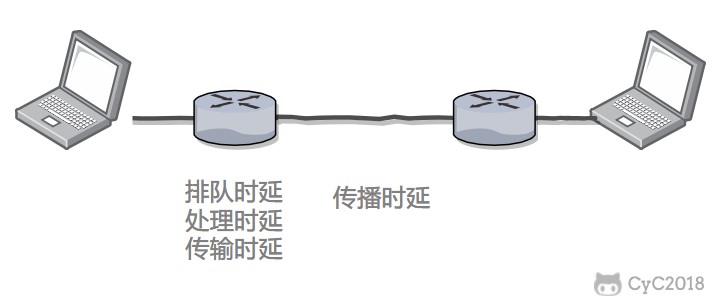\
|
||||
|
||||
|
||||
### 1. 排队时延
|
||||
|
||||
@ -76,9 +80,7 @@
|
||||
|
||||
主机或路由器传输数据帧所需要的时间。
|
||||
|
||||
<!-- <div align="center"><img src="https://latex.codecogs.com/gif.latex?delay=\frac{l(bit)}{v(bit/s)}" class="mathjax-pic"/></div> <br> -->
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/dcdbb96c-9077-4121-aeb8-743e54ac02a4.png" width="150px"> </div><br>
|
||||
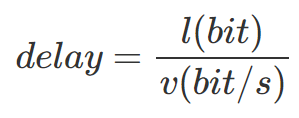\
|
||||
|
||||
|
||||
其中 l 表示数据帧的长度,v 表示传输速率。
|
||||
@ -87,35 +89,30 @@
|
||||
|
||||
电磁波在信道中传播所需要花费的时间,电磁波传播的速度接近光速。
|
||||
|
||||
<!-- <div align="center"><img src="https://latex.codecogs.com/gif.latex?delay=\frac{l(m)}{v(m/s)}" class="mathjax-pic"/></div> <br> -->
|
||||
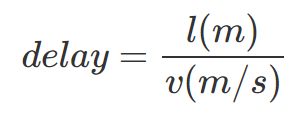\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/a1616dac-0e12-40b2-827d-9e3f7f0b940d.png" width="150"> </div><br>
|
||||
|
||||
其中 l 表示信道长度,v 表示电磁波在信道上的传播速度。
|
||||
|
||||
## 计算机网络体系结构
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/0fa6c237-a909-4e2a-a771-2c5485cd8ce0.png" width="450"/> </div><br>
|
||||
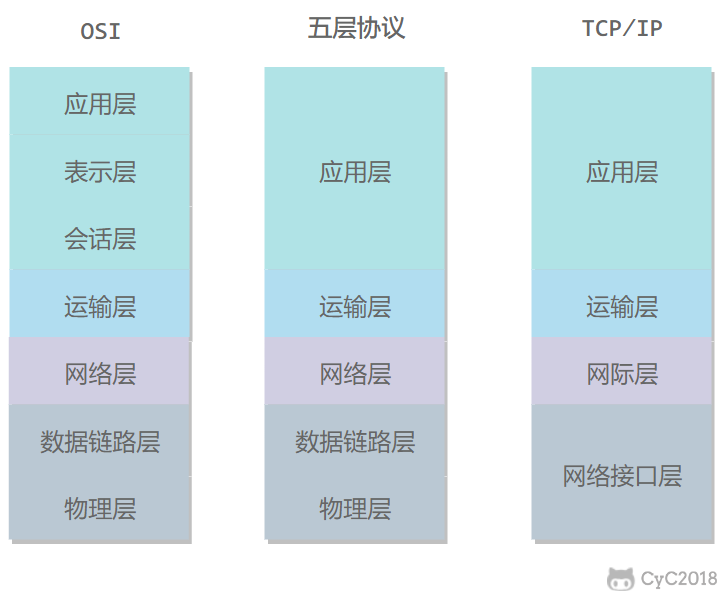\
|
||||
|
||||
|
||||
### 1. 五层协议
|
||||
|
||||
- **应用层** :为特定应用程序提供数据传输服务,例如 HTTP、DNS 等协议。数据单位为报文。
|
||||
|
||||
- **传输层** :为进程提供通用数据传输服务。由于应用层协议很多,定义通用的传输层协议就可以支持不断增多的应用层协议。运输层包括两种协议:传输控制协议 TCP,提供面向连接、可靠的数据传输服务,数据单位为报文段;用户数据报协议 UDP,提供无连接、尽最大努力的数据传输服务,数据单位为用户数据报。TCP 主要提供完整性服务,UDP 主要提供及时性服务。
|
||||
|
||||
- **网络层** :为主机提供数据传输服务。而传输层协议是为主机中的进程提供数据传输服务。网络层把传输层传递下来的报文段或者用户数据报封装成分组。
|
||||
|
||||
- **数据链路层** :网络层针对的还是主机之间的数据传输服务,而主机之间可以有很多链路,链路层协议就是为同一链路的主机提供数据传输服务。数据链路层把网络层传下来的分组封装成帧。
|
||||
|
||||
- **物理层** :考虑的是怎样在传输媒体上传输数据比特流,而不是指具体的传输媒体。物理层的作用是尽可能屏蔽传输媒体和通信手段的差异,使数据链路层感觉不到这些差异。
|
||||
* **应用层** :为特定应用程序提供数据传输服务,例如 HTTP、DNS 等协议。数据单位为报文。
|
||||
* **传输层** :为进程提供通用数据传输服务。由于应用层协议很多,定义通用的传输层协议就可以支持不断增多的应用层协议。运输层包括两种协议:传输控制协议 TCP,提供面向连接、可靠的数据传输服务,数据单位为报文段;用户数据报协议 UDP,提供无连接、尽最大努力的数据传输服务,数据单位为用户数据报。TCP 主要提供完整性服务,UDP 主要提供及时性服务。
|
||||
* **网络层** :为主机提供数据传输服务。而传输层协议是为主机中的进程提供数据传输服务。网络层把传输层传递下来的报文段或者用户数据报封装成分组。
|
||||
* **数据链路层** :网络层针对的还是主机之间的数据传输服务,而主机之间可以有很多链路,链路层协议就是为同一链路的主机提供数据传输服务。数据链路层把网络层传下来的分组封装成帧。
|
||||
* **物理层** :考虑的是怎样在传输媒体上传输数据比特流,而不是指具体的传输媒体。物理层的作用是尽可能屏蔽传输媒体和通信手段的差异,使数据链路层感觉不到这些差异。
|
||||
|
||||
### 2. OSI
|
||||
|
||||
其中表示层和会话层用途如下:
|
||||
|
||||
- **表示层** :数据压缩、加密以及数据描述,这使得应用程序不必关心在各台主机中数据内部格式不同的问题。
|
||||
|
||||
- **会话层** :建立及管理会话。
|
||||
* **表示层** :数据压缩、加密以及数据描述,这使得应用程序不必关心在各台主机中数据内部格式不同的问题。
|
||||
* **会话层** :建立及管理会话。
|
||||
|
||||
五层协议没有表示层和会话层,而是将这些功能留给应用程序开发者处理。
|
||||
|
||||
@ -125,7 +122,8 @@
|
||||
|
||||
TCP/IP 体系结构不严格遵循 OSI 分层概念,应用层可能会直接使用 IP 层或者网络接口层。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/48d79be8-085b-4862-8a9d-18402eb93b31.png" width="250"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### 4. 数据在各层之间的传递过程
|
||||
|
||||
|
||||
@ -1,22 +1,19 @@
|
||||
# 计算机网络 - 物理层
|
||||
<!-- GFM-TOC -->
|
||||
* [计算机网络 - 物理层](#计算机网络---物理层)
|
||||
* [通信方式](#通信方式)
|
||||
* [带通调制](#带通调制)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [计算机网络 - 物理层](<计算机网络 - 物理层.md#计算机网络---物理层>)
|
||||
* [通信方式](<计算机网络 - 物理层.md#通信方式>)
|
||||
* [带通调制](<计算机网络 - 物理层.md#带通调制>)
|
||||
|
||||
## 通信方式
|
||||
|
||||
根据信息在传输线上的传送方向,分为以下三种通信方式:
|
||||
|
||||
- 单工通信:单向传输
|
||||
- 半双工通信:双向交替传输
|
||||
- 全双工通信:双向同时传输
|
||||
* 单工通信:单向传输
|
||||
* 半双工通信:双向交替传输
|
||||
* 全双工通信:双向同时传输
|
||||
|
||||
## 带通调制
|
||||
|
||||
模拟信号是连续的信号,数字信号是离散的信号。带通调制把数字信号转换为模拟信号。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/c34f4503-f62c-4043-9dc6-3e03288657df.jpg" width="500"/> </div><br>
|
||||
|
||||
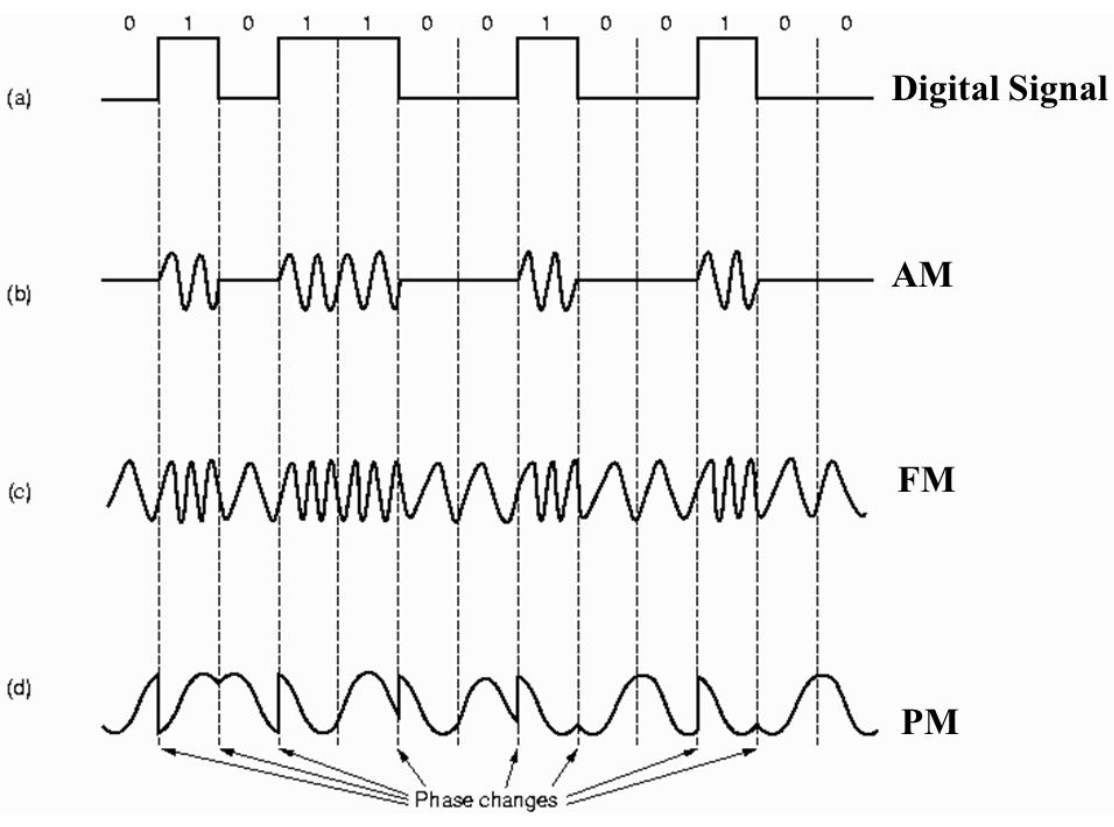\
|
||||
|
||||
@ -1,26 +1,24 @@
|
||||
# 计算机网络 - 网络层
|
||||
<!-- GFM-TOC -->
|
||||
* [计算机网络 - 网络层](#计算机网络---网络层)
|
||||
* [概述](#概述)
|
||||
* [IP 数据报格式](#ip-数据报格式)
|
||||
* [IP 地址编址方式](#ip-地址编址方式)
|
||||
* [1. 分类](#1-分类)
|
||||
* [2. 子网划分](#2-子网划分)
|
||||
* [3. 无分类](#3-无分类)
|
||||
* [地址解析协议 ARP](#地址解析协议-arp)
|
||||
* [网际控制报文协议 ICMP](#网际控制报文协议-icmp)
|
||||
* [1. Ping](#1-ping)
|
||||
* [2. Traceroute](#2-traceroute)
|
||||
* [虚拟专用网 VPN](#虚拟专用网-vpn)
|
||||
* [网络地址转换 NAT](#网络地址转换-nat)
|
||||
* [路由器的结构](#路由器的结构)
|
||||
* [路由器分组转发流程](#路由器分组转发流程)
|
||||
* [路由选择协议](#路由选择协议)
|
||||
* [1. 内部网关协议 RIP](#1-内部网关协议-rip)
|
||||
* [2. 内部网关协议 OSPF](#2-内部网关协议-ospf)
|
||||
* [3. 外部网关协议 BGP](#3-外部网关协议-bgp)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [计算机网络 - 网络层](<计算机网络 - 网络层.md#计算机网络---网络层>)
|
||||
* [概述](<计算机网络 - 网络层.md#概述>)
|
||||
* [IP 数据报格式](<计算机网络 - 网络层.md#ip-数据报格式>)
|
||||
* [IP 地址编址方式](<计算机网络 - 网络层.md#ip-地址编址方式>)
|
||||
* [1. 分类](<计算机网络 - 网络层.md#1-分类>)
|
||||
* [2. 子网划分](<计算机网络 - 网络层.md#2-子网划分>)
|
||||
* [3. 无分类](<计算机网络 - 网络层.md#3-无分类>)
|
||||
* [地址解析协议 ARP](<计算机网络 - 网络层.md#地址解析协议-arp>)
|
||||
* [网际控制报文协议 ICMP](<计算机网络 - 网络层.md#网际控制报文协议-icmp>)
|
||||
* [1. Ping](<计算机网络 - 网络层.md#1-ping>)
|
||||
* [2. Traceroute](<计算机网络 - 网络层.md#2-traceroute>)
|
||||
* [虚拟专用网 VPN](<计算机网络 - 网络层.md#虚拟专用网-vpn>)
|
||||
* [网络地址转换 NAT](<计算机网络 - 网络层.md#网络地址转换-nat>)
|
||||
* [路由器的结构](<计算机网络 - 网络层.md#路由器的结构>)
|
||||
* [路由器分组转发流程](<计算机网络 - 网络层.md#路由器分组转发流程>)
|
||||
* [路由选择协议](<计算机网络 - 网络层.md#路由选择协议>)
|
||||
* [1. 内部网关协议 RIP](<计算机网络 - 网络层.md#1-内部网关协议-rip>)
|
||||
* [2. 内部网关协议 OSPF](<计算机网络 - 网络层.md#2-内部网关协议-ospf>)
|
||||
* [3. 外部网关协议 BGP](<计算机网络 - 网络层.md#3-外部网关协议-bgp>)
|
||||
|
||||
## 概述
|
||||
|
||||
@ -28,59 +26,55 @@
|
||||
|
||||
使用 IP 协议,可以把异构的物理网络连接起来,使得在网络层看起来好像是一个统一的网络。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/8d779ab7-ffcc-47c6-90ec-ede8260b2368.png" width="800"/> </div><br>
|
||||
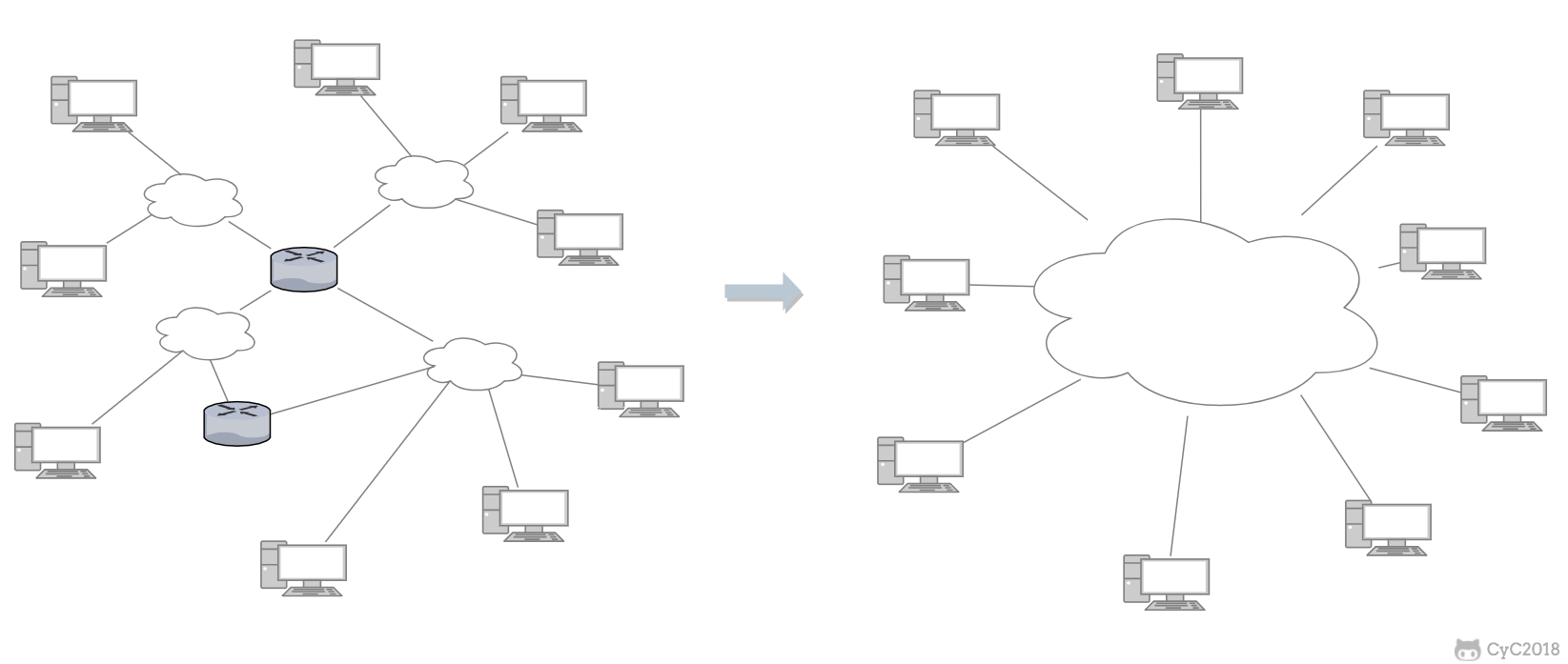\
|
||||
|
||||
|
||||
与 IP 协议配套使用的还有三个协议:
|
||||
|
||||
- 地址解析协议 ARP(Address Resolution Protocol)
|
||||
- 网际控制报文协议 ICMP(Internet Control Message Protocol)
|
||||
- 网际组管理协议 IGMP(Internet Group Management Protocol)
|
||||
* 地址解析协议 ARP(Address Resolution Protocol)
|
||||
* 网际控制报文协议 ICMP(Internet Control Message Protocol)
|
||||
* 网际组管理协议 IGMP(Internet Group Management Protocol)
|
||||
|
||||
## IP 数据报格式
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/85c05fb1-5546-4c50-9221-21f231cdc8c5.jpg" width="700"/> </div><br>
|
||||
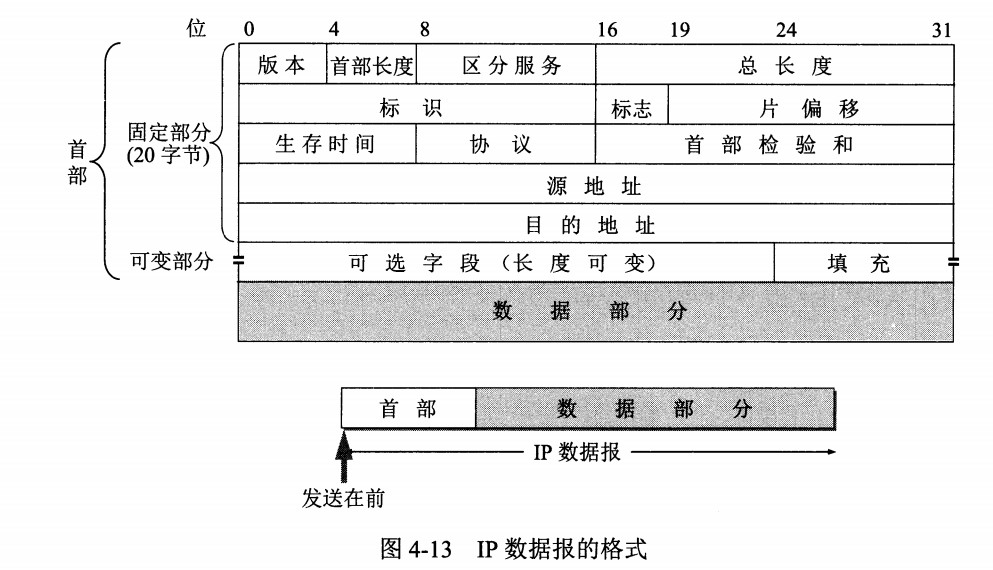\
|
||||
|
||||
- **版本** : 有 4(IPv4)和 6(IPv6)两个值;
|
||||
|
||||
- **首部长度** : 占 4 位,因此最大值为 15。值为 1 表示的是 1 个 32 位字的长度,也就是 4 字节。因为固定部分长度为 20 字节,因此该值最小为 5。如果可选字段的长度不是 4 字节的整数倍,就用尾部的填充部分来填充。
|
||||
* **版本** : 有 4(IPv4)和 6(IPv6)两个值;
|
||||
* **首部长度** : 占 4 位,因此最大值为 15。值为 1 表示的是 1 个 32 位字的长度,也就是 4 字节。因为固定部分长度为 20 字节,因此该值最小为 5。如果可选字段的长度不是 4 字节的整数倍,就用尾部的填充部分来填充。
|
||||
* **区分服务** : 用来获得更好的服务,一般情况下不使用。
|
||||
* **总长度** : 包括首部长度和数据部分长度。
|
||||
* **生存时间** :TTL,它的存在是为了防止无法交付的数据报在互联网中不断兜圈子。以路由器跳数为单位,当 TTL 为 0 时就丢弃数据报。
|
||||
* **协议** :指出携带的数据应该上交给哪个协议进行处理,例如 ICMP、TCP、UDP 等。
|
||||
* **首部检验和** :因为数据报每经过一个路由器,都要重新计算检验和,因此检验和不包含数据部分可以减少计算的工作量。
|
||||
* **标识** : 在数据报长度过长从而发生分片的情况下,相同数据报的不同分片具有相同的标识符。
|
||||
* **片偏移** : 和标识符一起,用于发生分片的情况。片偏移的单位为 8 字节。
|
||||
|
||||
- **区分服务** : 用来获得更好的服务,一般情况下不使用。
|
||||
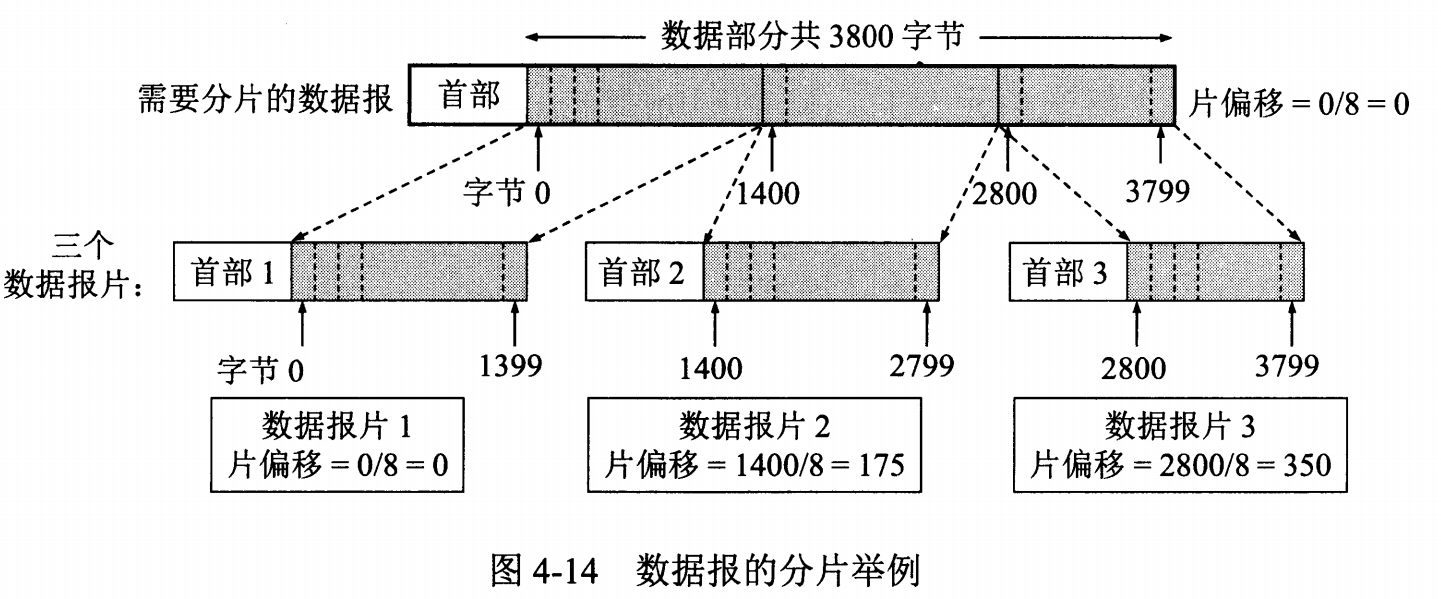\
|
||||
|
||||
- **总长度** : 包括首部长度和数据部分长度。
|
||||
|
||||
- **生存时间** :TTL,它的存在是为了防止无法交付的数据报在互联网中不断兜圈子。以路由器跳数为单位,当 TTL 为 0 时就丢弃数据报。
|
||||
|
||||
- **协议** :指出携带的数据应该上交给哪个协议进行处理,例如 ICMP、TCP、UDP 等。
|
||||
|
||||
- **首部检验和** :因为数据报每经过一个路由器,都要重新计算检验和,因此检验和不包含数据部分可以减少计算的工作量。
|
||||
|
||||
- **标识** : 在数据报长度过长从而发生分片的情况下,相同数据报的不同分片具有相同的标识符。
|
||||
|
||||
- **片偏移** : 和标识符一起,用于发生分片的情况。片偏移的单位为 8 字节。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/23ba890e-e11c-45e2-a20c-64d217f83430.png" width="700"/> </div><br>
|
||||
|
||||
## IP 地址编址方式
|
||||
|
||||
IP 地址的编址方式经历了三个历史阶段:
|
||||
|
||||
- 分类
|
||||
- 子网划分
|
||||
- 无分类
|
||||
* 分类
|
||||
* 子网划分
|
||||
* 无分类
|
||||
|
||||
### 1. 分类
|
||||
|
||||
由两部分组成,网络号和主机号,其中不同分类具有不同的网络号长度,并且是固定的。
|
||||
|
||||
IP 地址 ::= {\< 网络号 \>, \< 主机号 \>}
|
||||
IP 地址 ::= {< 网络号 >, < 主机号 >}
|
||||
|
||||
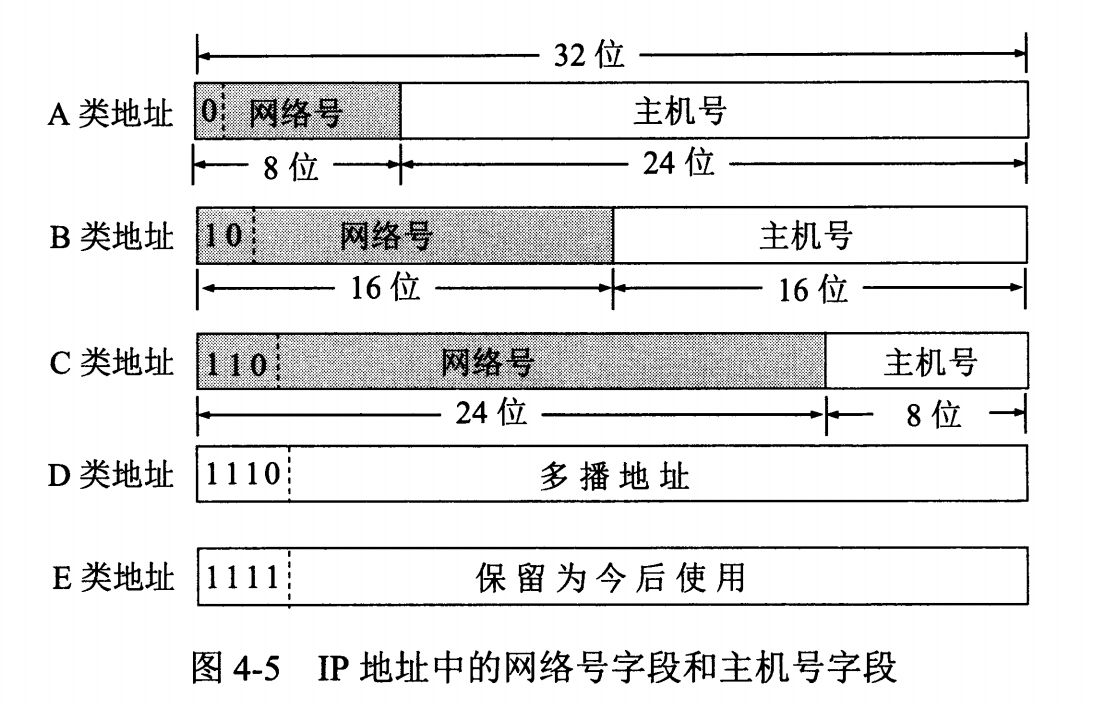\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/cbf50eb8-22b4-4528-a2e7-d187143d57f7.png" width="500"/> </div><br>
|
||||
|
||||
### 2. 子网划分
|
||||
|
||||
通过在主机号字段中拿一部分作为子网号,把两级 IP 地址划分为三级 IP 地址。
|
||||
|
||||
IP 地址 ::= {\< 网络号 \>, \< 子网号 \>, \< 主机号 \>}
|
||||
IP 地址 ::= {< 网络号 >, < 子网号 >, < 主机号 >}
|
||||
|
||||
要使用子网,必须配置子网掩码。一个 B 类地址的默认子网掩码为 255.255.0.0,如果 B 类地址的子网占两个比特,那么子网掩码为 11111111 11111111 11000000 00000000,也就是 255.255.192.0。
|
||||
|
||||
@ -90,13 +84,13 @@ IP 地址 ::= {\< 网络号 \>, \< 子网号 \>, \< 主机号 \>}
|
||||
|
||||
无分类编址 CIDR 消除了传统 A 类、B 类和 C 类地址以及划分子网的概念,使用网络前缀和主机号来对 IP 地址进行编码,网络前缀的长度可以根据需要变化。
|
||||
|
||||
IP 地址 ::= {\< 网络前缀号 \>, \< 主机号 \>}
|
||||
IP 地址 ::= {< 网络前缀号 >, < 主机号 >}
|
||||
|
||||
CIDR 的记法上采用在 IP 地址后面加上网络前缀长度的方法,例如 128.14.35.7/20 表示前 20 位为网络前缀。
|
||||
|
||||
CIDR 的地址掩码可以继续称为子网掩码,子网掩码首 1 长度为网络前缀的长度。
|
||||
|
||||
一个 CIDR 地址块中有很多地址,一个 CIDR 表示的网络就可以表示原来的很多个网络,并且在路由表中只需要一个路由就可以代替原来的多个路由,减少了路由表项的数量。把这种通过使用网络前缀来减少路由表项的方式称为路由聚合,也称为 **构成超网** 。
|
||||
一个 CIDR 地址块中有很多地址,一个 CIDR 表示的网络就可以表示原来的很多个网络,并且在路由表中只需要一个路由就可以代替原来的多个路由,减少了路由表项的数量。把这种通过使用网络前缀来减少路由表项的方式称为路由聚合,也称为 **构成超网** 。
|
||||
|
||||
在路由表中的项目由“网络前缀”和“下一跳地址”组成,在查找时可能会得到不止一个匹配结果,应当采用最长前缀匹配来确定应该匹配哪一个。
|
||||
|
||||
@ -104,27 +98,32 @@ CIDR 的地址掩码可以继续称为子网掩码,子网掩码首 1 长度为
|
||||
|
||||
网络层实现主机之间的通信,而链路层实现具体每段链路之间的通信。因此在通信过程中,IP 数据报的源地址和目的地址始终不变,而 MAC 地址随着链路的改变而改变。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/66192382-558b-4b05-a35d-ac4a2b1a9811.jpg" width="700"/> </div><br>
|
||||
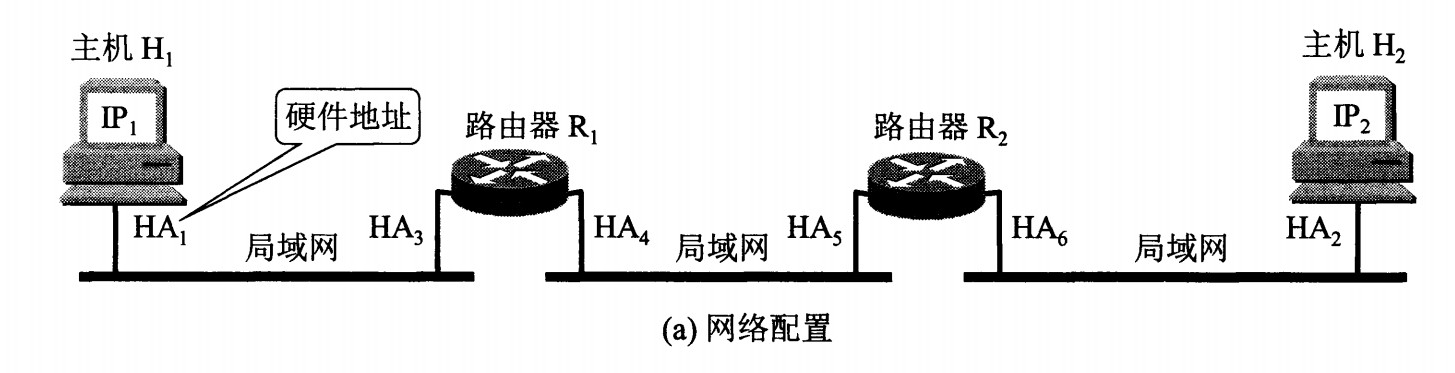\
|
||||
|
||||
|
||||
ARP 实现由 IP 地址得到 MAC 地址。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/b9d79a5a-e7af-499b-b989-f10483e71b8b.jpg" width="500"/> </div><br>
|
||||
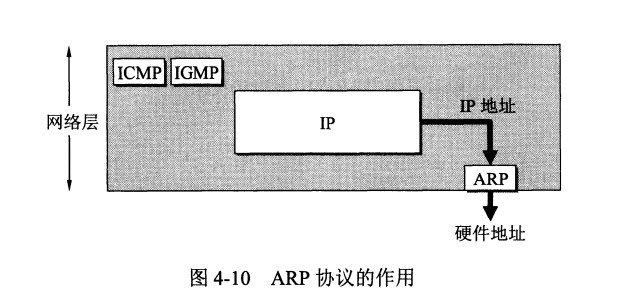\
|
||||
|
||||
|
||||
每个主机都有一个 ARP 高速缓存,里面有本局域网上的各主机和路由器的 IP 地址到 MAC 地址的映射表。
|
||||
|
||||
如果主机 A 知道主机 B 的 IP 地址,但是 ARP 高速缓存中没有该 IP 地址到 MAC 地址的映射,此时主机 A 通过广播的方式发送 ARP 请求分组,主机 B 收到该请求后会发送 ARP 响应分组给主机 A 告知其 MAC 地址,随后主机 A 向其高速缓存中写入主机 B 的 IP 地址到 MAC 地址的映射。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/8006a450-6c2f-498c-a928-c927f758b1d0.png" width="700"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 网际控制报文协议 ICMP
|
||||
|
||||
ICMP 是为了更有效地转发 IP 数据报和提高交付成功的机会。它封装在 IP 数据报中,但是不属于高层协议。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/e3124763-f75e-46c3-ba82-341e6c98d862.jpg" width="500"/> </div><br>
|
||||
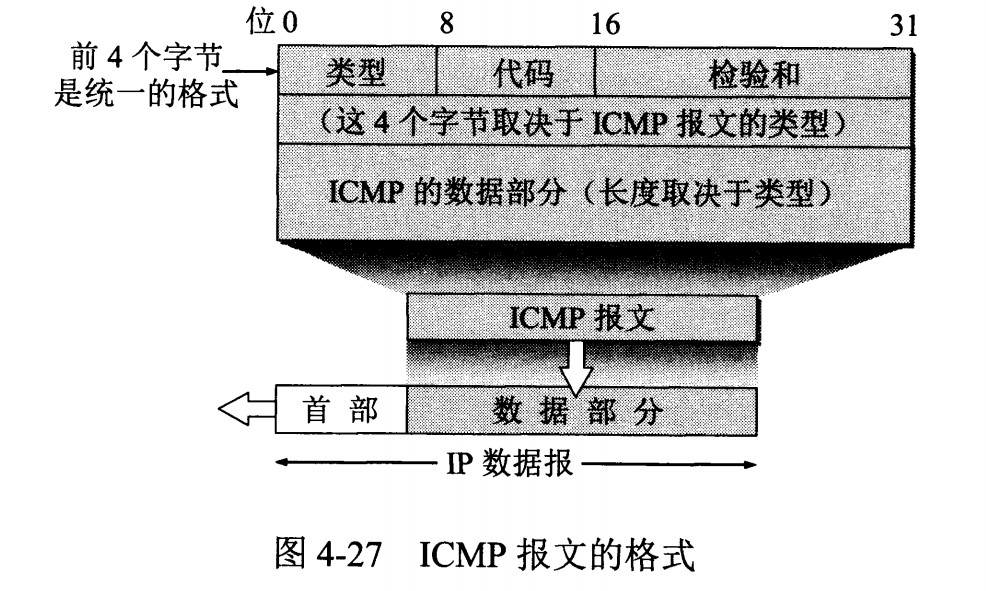\
|
||||
|
||||
|
||||
ICMP 报文分为差错报告报文和询问报文。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/aa29cc88-7256-4399-8c7f-3cf4a6489559.png" width="600"/> </div><br>
|
||||
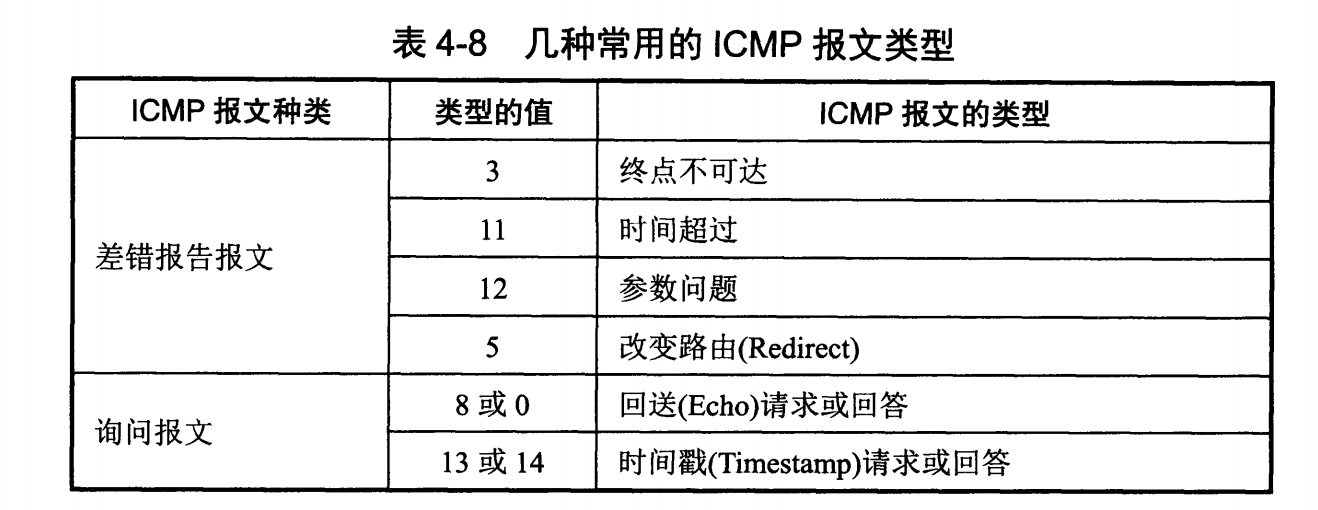\
|
||||
|
||||
|
||||
### 1. Ping
|
||||
|
||||
@ -138,10 +137,10 @@ Traceroute 是 ICMP 的另一个应用,用来跟踪一个分组从源点到终
|
||||
|
||||
Traceroute 发送的 IP 数据报封装的是无法交付的 UDP 用户数据报,并由目的主机发送终点不可达差错报告报文。
|
||||
|
||||
- 源主机向目的主机发送一连串的 IP 数据报。第一个数据报 P1 的生存时间 TTL 设置为 1,当 P1 到达路径上的第一个路由器 R1 时,R1 收下它并把 TTL 减 1,此时 TTL 等于 0,R1 就把 P1 丢弃,并向源主机发送一个 ICMP 时间超过差错报告报文;
|
||||
- 源主机接着发送第二个数据报 P2,并把 TTL 设置为 2。P2 先到达 R1,R1 收下后把 TTL 减 1 再转发给 R2,R2 收下后也把 TTL 减 1,由于此时 TTL 等于 0,R2 就丢弃 P2,并向源主机发送一个 ICMP 时间超过差错报文。
|
||||
- 不断执行这样的步骤,直到最后一个数据报刚刚到达目的主机,主机不转发数据报,也不把 TTL 值减 1。但是因为数据报封装的是无法交付的 UDP,因此目的主机要向源主机发送 ICMP 终点不可达差错报告报文。
|
||||
- 之后源主机知道了到达目的主机所经过的路由器 IP 地址以及到达每个路由器的往返时间。
|
||||
* 源主机向目的主机发送一连串的 IP 数据报。第一个数据报 P1 的生存时间 TTL 设置为 1,当 P1 到达路径上的第一个路由器 R1 时,R1 收下它并把 TTL 减 1,此时 TTL 等于 0,R1 就把 P1 丢弃,并向源主机发送一个 ICMP 时间超过差错报告报文;
|
||||
* 源主机接着发送第二个数据报 P2,并把 TTL 设置为 2。P2 先到达 R1,R1 收下后把 TTL 减 1 再转发给 R2,R2 收下后也把 TTL 减 1,由于此时 TTL 等于 0,R2 就丢弃 P2,并向源主机发送一个 ICMP 时间超过差错报文。
|
||||
* 不断执行这样的步骤,直到最后一个数据报刚刚到达目的主机,主机不转发数据报,也不把 TTL 值减 1。但是因为数据报封装的是无法交付的 UDP,因此目的主机要向源主机发送 ICMP 终点不可达差错报告报文。
|
||||
* 之后源主机知道了到达目的主机所经过的路由器 IP 地址以及到达每个路由器的往返时间。
|
||||
|
||||
## 虚拟专用网 VPN
|
||||
|
||||
@ -149,15 +148,16 @@ Traceroute 发送的 IP 数据报封装的是无法交付的 UDP 用户数据报
|
||||
|
||||
有三个专用地址块:
|
||||
|
||||
- 10.0.0.0 \~ 10.255.255.255
|
||||
- 172.16.0.0 \~ 172.31.255.255
|
||||
- 192.168.0.0 \~ 192.168.255.255
|
||||
* 10.0.0.0 \~ 10.255.255.255
|
||||
* 172.16.0.0 \~ 172.31.255.255
|
||||
* 192.168.0.0 \~ 192.168.255.255
|
||||
|
||||
VPN 使用公用的互联网作为本机构各专用网之间的通信载体。专用指机构内的主机只与本机构内的其它主机通信;虚拟指好像是,而实际上并不是,它有经过公用的互联网。
|
||||
|
||||
下图中,场所 A 和 B 的通信经过互联网,如果场所 A 的主机 X 要和另一个场所 B 的主机 Y 通信,IP 数据报的源地址是 10.1.0.1,目的地址是 10.2.0.3。数据报先发送到与互联网相连的路由器 R1,R1 对内部数据进行加密,然后重新加上数据报的首部,源地址是路由器 R1 的全球地址 125.1.2.3,目的地址是路由器 R2 的全球地址 194.4.5.6。路由器 R2 收到数据报后将数据部分进行解密,恢复原来的数据报,此时目的地址为 10.2.0.3,就交付给 Y。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/1556770b-8c01-4681-af10-46f1df69202c.jpg" width="800"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 网络地址转换 NAT
|
||||
|
||||
@ -165,7 +165,8 @@ VPN 使用公用的互联网作为本机构各专用网之间的通信载体。
|
||||
|
||||
在以前,NAT 将本地 IP 和全球 IP 一一对应,这种方式下拥有 n 个全球 IP 地址的专用网内最多只可以同时有 n 台主机接入互联网。为了更有效地利用全球 IP 地址,现在常用的 NAT 转换表把传输层的端口号也用上了,使得多个专用网内部的主机共用一个全球 IP 地址。使用端口号的 NAT 也叫做网络地址与端口转换 NAPT。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/2719067e-b299-4639-9065-bed6729dbf0b.png" width=""/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## 路由器的结构
|
||||
|
||||
@ -173,18 +174,20 @@ VPN 使用公用的互联网作为本机构各专用网之间的通信载体。
|
||||
|
||||
分组转发结构由三个部分组成:交换结构、一组输入端口和一组输出端口。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/c3369072-c740-43b0-b276-202bd1d3960d.jpg" width="600"/> </div><br>
|
||||
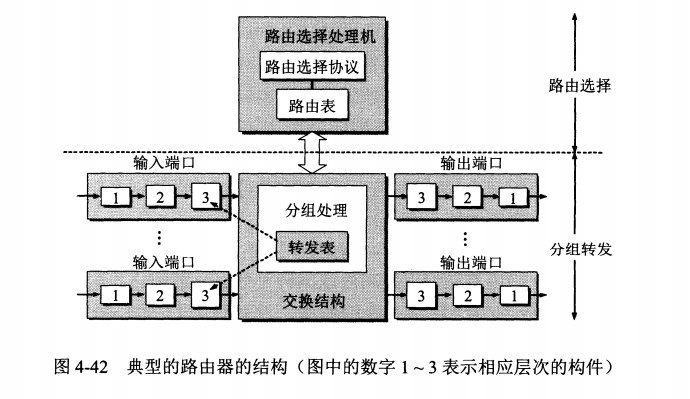\
|
||||
|
||||
|
||||
## 路由器分组转发流程
|
||||
|
||||
- 从数据报的首部提取目的主机的 IP 地址 D,得到目的网络地址 N。
|
||||
- 若 N 就是与此路由器直接相连的某个网络地址,则进行直接交付;
|
||||
- 若路由表中有目的地址为 D 的特定主机路由,则把数据报传送给表中所指明的下一跳路由器;
|
||||
- 若路由表中有到达网络 N 的路由,则把数据报传送给路由表中所指明的下一跳路由器;
|
||||
- 若路由表中有一个默认路由,则把数据报传送给路由表中所指明的默认路由器;
|
||||
- 报告转发分组出错。
|
||||
* 从数据报的首部提取目的主机的 IP 地址 D,得到目的网络地址 N。
|
||||
* 若 N 就是与此路由器直接相连的某个网络地址,则进行直接交付;
|
||||
* 若路由表中有目的地址为 D 的特定主机路由,则把数据报传送给表中所指明的下一跳路由器;
|
||||
* 若路由表中有到达网络 N 的路由,则把数据报传送给路由表中所指明的下一跳路由器;
|
||||
* 若路由表中有一个默认路由,则把数据报传送给路由表中所指明的默认路由器;
|
||||
* 报告转发分组出错。
|
||||
|
||||
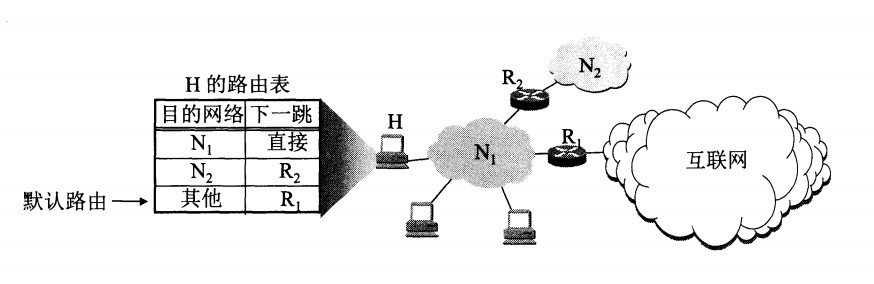\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/1ab49e39-012b-4383-8284-26570987e3c4.jpg" width="800"/> </div><br>
|
||||
|
||||
## 路由选择协议
|
||||
|
||||
@ -194,8 +197,8 @@ VPN 使用公用的互联网作为本机构各专用网之间的通信载体。
|
||||
|
||||
可以把路由选择协议划分为两大类:
|
||||
|
||||
- 自治系统内部的路由选择:RIP 和 OSPF
|
||||
- 自治系统间的路由选择:BGP
|
||||
* 自治系统内部的路由选择:RIP 和 OSPF
|
||||
* 自治系统间的路由选择:BGP
|
||||
|
||||
### 1. 内部网关协议 RIP
|
||||
|
||||
@ -205,11 +208,11 @@ RIP 按固定的时间间隔仅和相邻路由器交换自己的路由表,经
|
||||
|
||||
距离向量算法:
|
||||
|
||||
- 对地址为 X 的相邻路由器发来的 RIP 报文,先修改报文中的所有项目,把下一跳字段中的地址改为 X,并把所有的距离字段加 1;
|
||||
- 对修改后的 RIP 报文中的每一个项目,进行以下步骤:
|
||||
- 若原来的路由表中没有目的网络 N,则把该项目添加到路由表中;
|
||||
- 否则:若下一跳路由器地址是 X,则把收到的项目替换原来路由表中的项目;否则:若收到的项目中的距离 d 小于路由表中的距离,则进行更新(例如原始路由表项为 Net2, 5, P,新表项为 Net2, 4, X,则更新);否则什么也不做。
|
||||
- 若 3 分钟还没有收到相邻路由器的更新路由表,则把该相邻路由器标为不可达,即把距离置为 16。
|
||||
* 对地址为 X 的相邻路由器发来的 RIP 报文,先修改报文中的所有项目,把下一跳字段中的地址改为 X,并把所有的距离字段加 1;
|
||||
* 对修改后的 RIP 报文中的每一个项目,进行以下步骤:
|
||||
* 若原来的路由表中没有目的网络 N,则把该项目添加到路由表中;
|
||||
* 否则:若下一跳路由器地址是 X,则把收到的项目替换原来路由表中的项目;否则:若收到的项目中的距离 d 小于路由表中的距离,则进行更新(例如原始路由表项为 Net2, 5, P,新表项为 Net2, 4, X,则更新);否则什么也不做。
|
||||
* 若 3 分钟还没有收到相邻路由器的更新路由表,则把该相邻路由器标为不可达,即把距离置为 16。
|
||||
|
||||
RIP 协议实现简单,开销小。但是 RIP 能使用的最大距离为 15,限制了网络的规模。并且当网络出现故障时,要经过比较长的时间才能将此消息传送到所有路由器。
|
||||
|
||||
@ -221,9 +224,9 @@ RIP 协议实现简单,开销小。但是 RIP 能使用的最大距离为 15
|
||||
|
||||
OSPF 具有以下特点:
|
||||
|
||||
- 向本自治系统中的所有路由器发送信息,这种方法是洪泛法。
|
||||
- 发送的信息就是与相邻路由器的链路状态,链路状态包括与哪些路由器相连以及链路的度量,度量用费用、距离、时延、带宽等来表示。
|
||||
- 只有当链路状态发生变化时,路由器才会发送信息。
|
||||
* 向本自治系统中的所有路由器发送信息,这种方法是洪泛法。
|
||||
* 发送的信息就是与相邻路由器的链路状态,链路状态包括与哪些路由器相连以及链路的度量,度量用费用、距离、时延、带宽等来表示。
|
||||
* 只有当链路状态发生变化时,路由器才会发送信息。
|
||||
|
||||
所有路由器都具有全网的拓扑结构图,并且是一致的。相比于 RIP,OSPF 的更新过程收敛的很快。
|
||||
|
||||
@ -233,12 +236,12 @@ BGP(Border Gateway Protocol,边界网关协议)
|
||||
|
||||
AS 之间的路由选择很困难,主要是由于:
|
||||
|
||||
- 互联网规模很大;
|
||||
- 各个 AS 内部使用不同的路由选择协议,无法准确定义路径的度量;
|
||||
- AS 之间的路由选择必须考虑有关的策略,比如有些 AS 不愿意让其它 AS 经过。
|
||||
* 互联网规模很大;
|
||||
* 各个 AS 内部使用不同的路由选择协议,无法准确定义路径的度量;
|
||||
* AS 之间的路由选择必须考虑有关的策略,比如有些 AS 不愿意让其它 AS 经过。
|
||||
|
||||
BGP 只能寻找一条比较好的路由,而不是最佳路由。
|
||||
|
||||
每个 AS 都必须配置 BGP 发言人,通过在两个相邻 BGP 发言人之间建立 TCP 连接来交换路由信息。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/9cd0ae20-4fb5-4017-a000-f7d3a0eb3529.png" width="600"/> </div><br>
|
||||
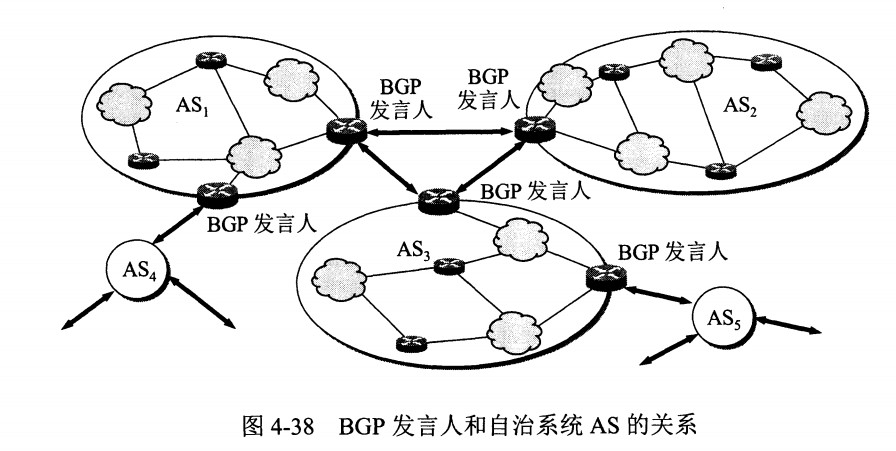\
|
||||
|
||||
@ -1,28 +1,26 @@
|
||||
# 计算机网络 - 链路层
|
||||
<!-- GFM-TOC -->
|
||||
* [计算机网络 - 链路层](#计算机网络---链路层)
|
||||
* [基本问题](#基本问题)
|
||||
* [1. 封装成帧](#1-封装成帧)
|
||||
* [2. 透明传输](#2-透明传输)
|
||||
* [3. 差错检测](#3-差错检测)
|
||||
* [信道分类](#信道分类)
|
||||
* [1. 广播信道](#1-广播信道)
|
||||
* [2. 点对点信道](#2-点对点信道)
|
||||
* [信道复用技术](#信道复用技术)
|
||||
* [1. 频分复用](#1-频分复用)
|
||||
* [2. 时分复用](#2-时分复用)
|
||||
* [3. 统计时分复用](#3-统计时分复用)
|
||||
* [4. 波分复用](#4-波分复用)
|
||||
* [5. 码分复用](#5-码分复用)
|
||||
* [CSMA/CD 协议](#csmacd-协议)
|
||||
* [PPP 协议](#ppp-协议)
|
||||
* [MAC 地址](#mac-地址)
|
||||
* [局域网](#局域网)
|
||||
* [以太网](#以太网)
|
||||
* [交换机](#交换机)
|
||||
* [虚拟局域网](#虚拟局域网)
|
||||
<!-- GFM-TOC -->
|
||||
|
||||
* [计算机网络 - 链路层](<计算机网络 - 链路层.md#计算机网络---链路层>)
|
||||
* [基本问题](<计算机网络 - 链路层.md#基本问题>)
|
||||
* [1. 封装成帧](<计算机网络 - 链路层.md#1-封装成帧>)
|
||||
* [2. 透明传输](<计算机网络 - 链路层.md#2-透明传输>)
|
||||
* [3. 差错检测](<计算机网络 - 链路层.md#3-差错检测>)
|
||||
* [信道分类](<计算机网络 - 链路层.md#信道分类>)
|
||||
* [1. 广播信道](<计算机网络 - 链路层.md#1-广播信道>)
|
||||
* [2. 点对点信道](<计算机网络 - 链路层.md#2-点对点信道>)
|
||||
* [信道复用技术](<计算机网络 - 链路层.md#信道复用技术>)
|
||||
* [1. 频分复用](<计算机网络 - 链路层.md#1-频分复用>)
|
||||
* [2. 时分复用](<计算机网络 - 链路层.md#2-时分复用>)
|
||||
* [3. 统计时分复用](<计算机网络 - 链路层.md#3-统计时分复用>)
|
||||
* [4. 波分复用](<计算机网络 - 链路层.md#4-波分复用>)
|
||||
* [5. 码分复用](<计算机网络 - 链路层.md#5-码分复用>)
|
||||
* [CSMA/CD 协议](<计算机网络 - 链路层.md#csmacd-协议>)
|
||||
* [PPP 协议](<计算机网络 - 链路层.md#ppp-协议>)
|
||||
* [MAC 地址](<计算机网络 - 链路层.md#mac-地址>)
|
||||
* [局域网](<计算机网络 - 链路层.md#局域网>)
|
||||
* [以太网](<计算机网络 - 链路层.md#以太网>)
|
||||
* [交换机](<计算机网络 - 链路层.md#交换机>)
|
||||
* [虚拟局域网](<计算机网络 - 链路层.md#虚拟局域网>)
|
||||
|
||||
## 基本问题
|
||||
|
||||
@ -30,7 +28,8 @@
|
||||
|
||||
将网络层传下来的分组添加首部和尾部,用于标记帧的开始和结束。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/29a14735-e154-4f60-9a04-c9628e5d09f4.png" width="300"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### 2. 透明传输
|
||||
|
||||
@ -38,7 +37,8 @@
|
||||
|
||||
帧使用首部和尾部进行定界,如果帧的数据部分含有和首部尾部相同的内容,那么帧的开始和结束位置就会被错误的判定。需要在数据部分出现首部尾部相同的内容前面插入转义字符。如果数据部分出现转义字符,那么就在转义字符前面再加个转义字符。在接收端进行处理之后可以还原出原始数据。这个过程透明传输的内容是转义字符,用户察觉不到转义字符的存在。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/e738a3d2-f42e-4755-ae13-ca23497e7a97.png" width="500"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### 3. 差错检测
|
||||
|
||||
@ -66,13 +66,15 @@
|
||||
|
||||
频分复用的所有主机在相同的时间占用不同的频率带宽资源。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/4aa5e057-bc57-4719-ab57-c6fbc861c505.png" width="350"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### 2. 时分复用
|
||||
|
||||
时分复用的所有主机在不同的时间占用相同的频率带宽资源。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/67582ade-d44a-46a6-8757-3c1296cc1ef9.png" width="350"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
使用频分复用和时分复用进行通信,在通信的过程中主机会一直占用一部分信道资源。但是由于计算机数据的突发性质,通信过程没必要一直占用信道资源而不让出给其它用户使用,因此这两种方式对信道的利用率都不高。
|
||||
|
||||
@ -80,7 +82,8 @@
|
||||
|
||||
是对时分复用的一种改进,不固定每个用户在时分复用帧中的位置,只要有数据就集中起来组成统计时分复用帧然后发送。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/6283be2a-814a-4a10-84bf-9592533fe6bc.png" width="350"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
### 4. 波分复用
|
||||
|
||||
@ -88,61 +91,59 @@
|
||||
|
||||
### 5. 码分复用
|
||||
|
||||
为每个用户分配 m bit 的码片,并且所有的码片正交,对于任意两个码片 <img src="https://latex.codecogs.com/gif.latex?\vec{S}" class="mathjax-pic"/> 和 <img src="https://latex.codecogs.com/gif.latex?\vec{T}" class="mathjax-pic"/> 有
|
||||
为每个用户分配 m bit 的码片,并且所有的码片正交,对于任意两个码片  和  有
|
||||
|
||||
<!-- <div align="center"><img src="https://latex.codecogs.com/gif.latex?\frac{1}{m}\vec{S}\cdot\vec{T}=0" class="mathjax-pic"/></div> <br> -->
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/308a02e9-3346-4251-8c41-bd5536dab491.png" width="100px"> </div><br>
|
||||
|
||||
为了讨论方便,取 m=8,设码片 <img src="https://latex.codecogs.com/gif.latex?\vec{S}" class="mathjax-pic"/> 为 00011011。在拥有该码片的用户发送比特 1 时就发送该码片,发送比特 0 时就发送该码片的反码 11100100。
|
||||
为了讨论方便,取 m=8,设码片  为 00011011。在拥有该码片的用户发送比特 1 时就发送该码片,发送比特 0 时就发送该码片的反码 11100100。
|
||||
|
||||
在计算时将 00011011 记作 (-1 -1 -1 +1 +1 -1 +1 +1),可以得到
|
||||
|
||||
<!-- <div align="center"><img src="https://latex.codecogs.com/gif.latex?\frac{1}{m}\vec{S}\cdot\vec{S}=1" class="mathjax-pic"/></div> <br> -->
|
||||
\
|
||||
\
|
||||
|
||||
<!-- <div align="center"><img src="https://latex.codecogs.com/gif.latex?\frac{1}{m}\vec{S}\cdot\vec{S'}=-1" class="mathjax-pic"/></div> <br> -->
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/6fda1dc7-5c74-49c1-bb79-237a77e43a43.png" width="100px"> </div><br>
|
||||
其中  为  的反码。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/e325a903-f0b1-4fbd-82bf-88913dc2f290.png" width="125px"> </div><br>
|
||||
|
||||
其中 <img src="https://latex.codecogs.com/gif.latex?\vec{S'}" class="mathjax-pic"/> 为 <img src="https://latex.codecogs.com/gif.latex?\vec{S}" class="mathjax-pic"/> 的反码。
|
||||
|
||||
利用上面的式子我们知道,当接收端使用码片 <img src="https://latex.codecogs.com/gif.latex?\vec{S}" class="mathjax-pic"/> 对接收到的数据进行内积运算时,结果为 0 的是其它用户发送的数据,结果为 1 的是用户发送的比特 1,结果为 -1 的是用户发送的比特 0。
|
||||
利用上面的式子我们知道,当接收端使用码片  对接收到的数据进行内积运算时,结果为 0 的是其它用户发送的数据,结果为 1 的是用户发送的比特 1,结果为 -1 的是用户发送的比特 0。
|
||||
|
||||
码分复用需要发送的数据量为原先的 m 倍。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/99b6060e-099d-4201-8e86-f8ab3768a7cf.png" width="500px"> </div><br>
|
||||
\
|
||||
|
||||
|
||||
## CSMA/CD 协议
|
||||
|
||||
CSMA/CD 表示载波监听多点接入 / 碰撞检测。
|
||||
|
||||
- **多点接入** :说明这是总线型网络,许多主机以多点的方式连接到总线上。
|
||||
- **载波监听** :每个主机都必须不停地监听信道。在发送前,如果监听到信道正在使用,就必须等待。
|
||||
- **碰撞检测** :在发送中,如果监听到信道已有其它主机正在发送数据,就表示发生了碰撞。虽然每个主机在发送数据之前都已经监听到信道为空闲,但是由于电磁波的传播时延的存在,还是有可能会发生碰撞。
|
||||
* **多点接入** :说明这是总线型网络,许多主机以多点的方式连接到总线上。
|
||||
* **载波监听** :每个主机都必须不停地监听信道。在发送前,如果监听到信道正在使用,就必须等待。
|
||||
* **碰撞检测** :在发送中,如果监听到信道已有其它主机正在发送数据,就表示发生了碰撞。虽然每个主机在发送数据之前都已经监听到信道为空闲,但是由于电磁波的传播时延的存在,还是有可能会发生碰撞。
|
||||
|
||||
记端到端的传播时延为 τ,最先发送的站点最多经过 2τ 就可以知道是否发生了碰撞,称 2τ 为 **争用期** 。只有经过争用期之后还没有检测到碰撞,才能肯定这次发送不会发生碰撞。
|
||||
记端到端的传播时延为 τ,最先发送的站点最多经过 2τ 就可以知道是否发生了碰撞,称 2τ 为 **争用期** 。只有经过争用期之后还没有检测到碰撞,才能肯定这次发送不会发生碰撞。
|
||||
|
||||
当发生碰撞时,站点要停止发送,等待一段时间再发送。这个时间采用 **截断二进制指数退避算法** 来确定。从离散的整数集合 {0, 1, .., (2<sup>k</sup>-1)} 中随机取出一个数,记作 r,然后取 r 倍的争用期作为重传等待时间。
|
||||
当发生碰撞时,站点要停止发送,等待一段时间再发送。这个时间采用 **截断二进制指数退避算法** 来确定。从离散的整数集合 {0, 1, .., (2k-1)} 中随机取出一个数,记作 r,然后取 r 倍的争用期作为重传等待时间。
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/19d423e9-74f7-4c2b-9b97-55890e0d5193.png" width="400"/> </div><br>
|
||||
|
||||
## PPP 协议
|
||||
|
||||
互联网用户通常需要连接到某个 ISP 之后才能接入到互联网,PPP 协议是用户计算机和 ISP 进行通信时所使用的数据链路层协议。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/e1ab9f28-cb15-4178-84b2-98aad87f9bc8.jpg" width="300"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
PPP 的帧格式:
|
||||
|
||||
- F 字段为帧的定界符
|
||||
- A 和 C 字段暂时没有意义
|
||||
- FCS 字段是使用 CRC 的检验序列
|
||||
- 信息部分的长度不超过 1500
|
||||
* F 字段为帧的定界符
|
||||
* A 和 C 字段暂时没有意义
|
||||
* FCS 字段是使用 CRC 的检验序列
|
||||
* 信息部分的长度不超过 1500
|
||||
|
||||
\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/759013d7-61d8-4509-897a-d75af598a236.png" width="400"/> </div><br>
|
||||
|
||||
## MAC 地址
|
||||
|
||||
@ -158,7 +159,8 @@ MAC 地址是链路层地址,长度为 6 字节(48 位),用于唯一标
|
||||
|
||||
可以按照网络拓扑结构对局域网进行分类:
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/807f4258-dba8-4c54-9c3c-a707c7ccffa2.jpg" width="800"/> </div><br>
|
||||
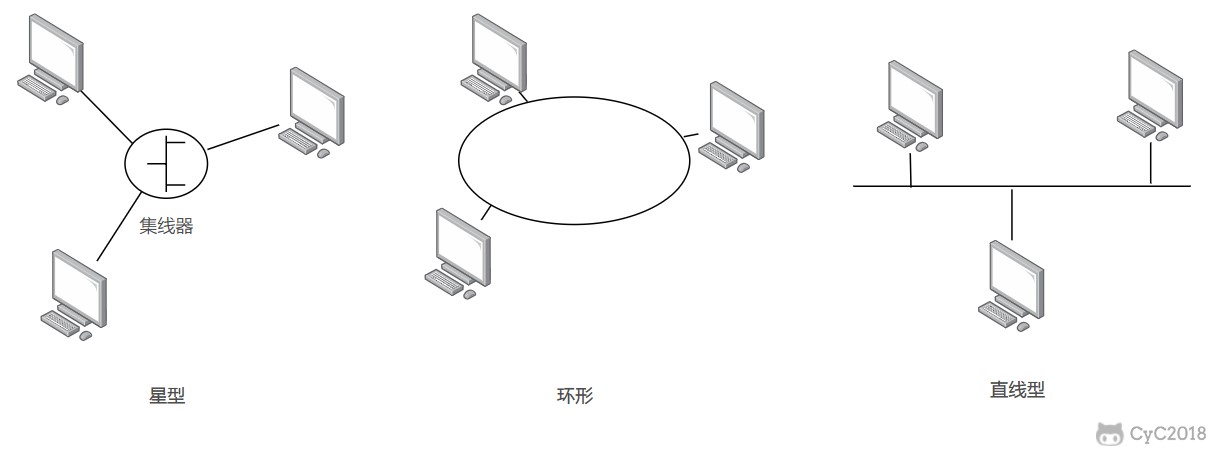\
|
||||
|
||||
|
||||
## 以太网
|
||||
|
||||
@ -170,11 +172,12 @@ MAC 地址是链路层地址,长度为 6 字节(48 位),用于唯一标
|
||||
|
||||
以太网帧格式:
|
||||
|
||||
- **类型** :标记上层使用的协议;
|
||||
- **数据** :长度在 46-1500 之间,如果太小则需要填充;
|
||||
- **FCS** :帧检验序列,使用的是 CRC 检验方法;
|
||||
* **类型** :标记上层使用的协议;
|
||||
* **数据** :长度在 46-1500 之间,如果太小则需要填充;
|
||||
* **FCS** :帧检验序列,使用的是 CRC 检验方法;
|
||||
|
||||
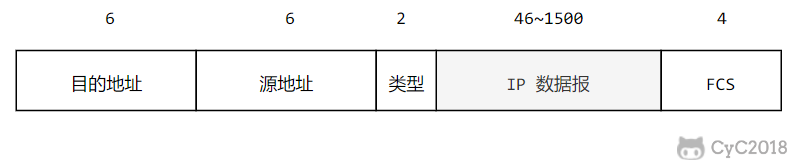\
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/164944d3-bbd2-4bb2-924b-e62199c51b90.png" width="500"/> </div><br>
|
||||
|
||||
## 交换机
|
||||
|
||||
@ -184,7 +187,8 @@ MAC 地址是链路层地址,长度为 6 字节(48 位),用于唯一标
|
||||
|
||||
下图中,交换机有 4 个接口,主机 A 向主机 B 发送数据帧时,交换机把主机 A 到接口 1 的映射写入交换表中。为了发送数据帧到 B,先查交换表,此时没有主机 B 的表项,那么主机 A 就发送广播帧,主机 C 和主机 D 会丢弃该帧,主机 B 回应该帧向主机 A 发送数据包时,交换机查找交换表得到主机 A 映射的接口为 1,就发送数据帧到接口 1,同时交换机添加主机 B 到接口 2 的映射。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/a4444545-0d68-4015-9a3d-19209dc436b3.png" width="800"/> </div><br>
|
||||
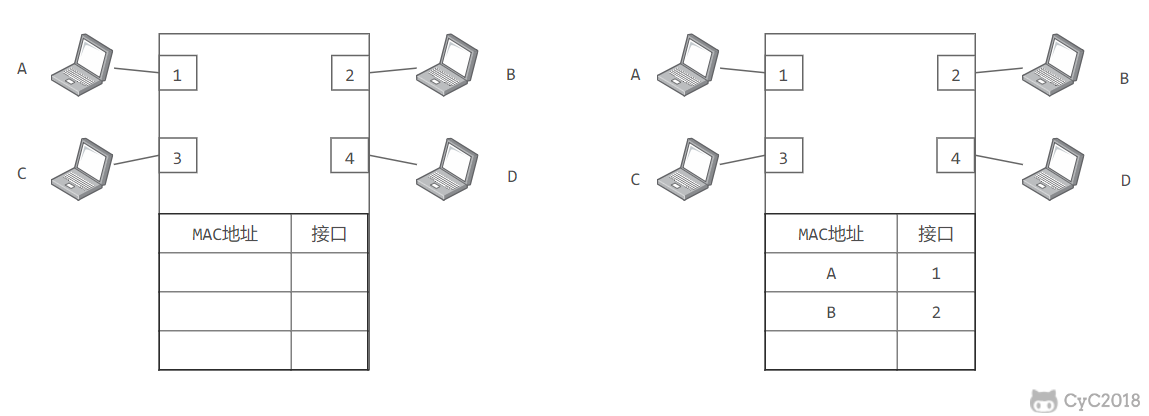\
|
||||
|
||||
|
||||
## 虚拟局域网
|
||||
|
||||
@ -194,5 +198,4 @@ MAC 地址是链路层地址,长度为 6 字节(48 位),用于唯一标
|
||||
|
||||
使用 VLAN 干线连接来建立虚拟局域网,每台交换机上的一个特殊接口被设置为干线接口,以互连 VLAN 交换机。IEEE 定义了一种扩展的以太网帧格式 802.1Q,它在标准以太网帧上加进了 4 字节首部 VLAN 标签,用于表示该帧属于哪一个虚拟局域网。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/e98e9d20-206b-4533-bacf-3448d0096f38.png" width="500"/> </div><br>
|
||||
|
||||
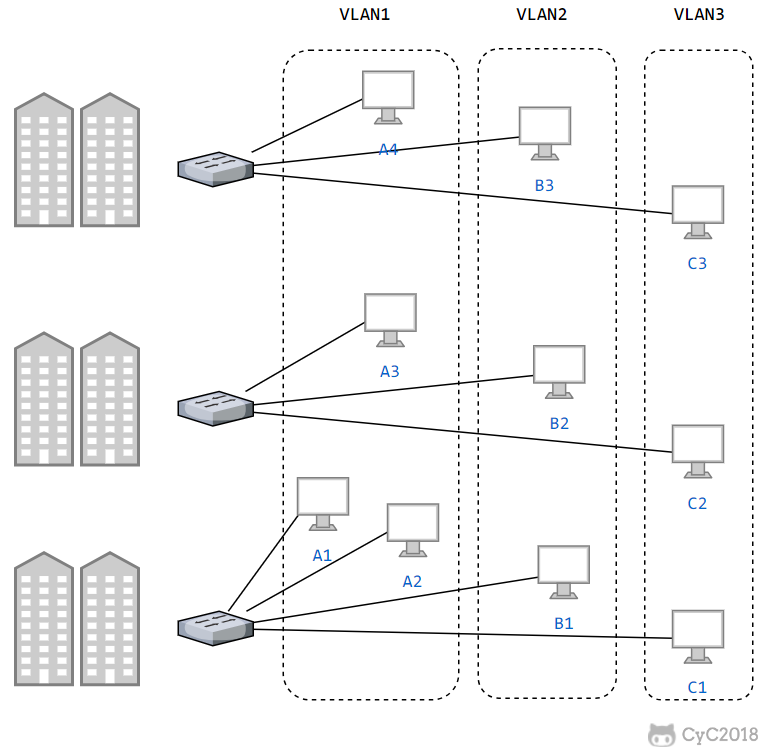\
|
||||
|
||||
@ -1,20 +1,21 @@
|
||||
## 单例(Singleton)
|
||||
# 单例(Singleton)
|
||||
|
||||
### Intent
|
||||
## Intent
|
||||
|
||||
确保一个类只有一个实例,并提供该实例的全局访问点。
|
||||
|
||||
### Class Diagram
|
||||
## Class Diagram
|
||||
|
||||
使用一个私有构造函数、一个私有静态变量以及一个公有静态函数来实现。
|
||||
|
||||
私有构造函数保证了不能通过构造函数来创建对象实例,只能通过公有静态函数返回唯一的私有静态变量。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/eca1f422-8381-409b-ad04-98ef39ae38ba.png"/> </div><br>
|
||||
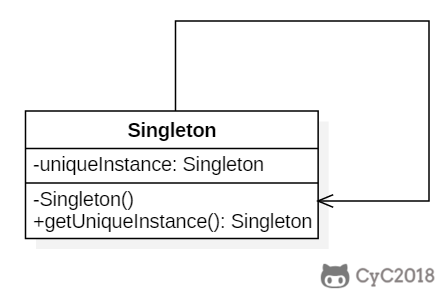\
|
||||
|
||||
### Implementation
|
||||
|
||||
#### Ⅰ 懒汉式-线程不安全
|
||||
## Implementation
|
||||
|
||||
### Ⅰ 懒汉式-线程不安全
|
||||
|
||||
以下实现中,私有静态变量 uniqueInstance 被延迟实例化,这样做的好处是,如果没有用到该类,那么就不会实例化 uniqueInstance,从而节约资源。
|
||||
|
||||
@ -37,7 +38,7 @@ public class Singleton {
|
||||
}
|
||||
```
|
||||
|
||||
#### Ⅱ 饿汉式-线程安全
|
||||
### Ⅱ 饿汉式-线程安全
|
||||
|
||||
线程不安全问题主要是由于 uniqueInstance 被实例化多次,采取直接实例化 uniqueInstance 的方式就不会产生线程不安全问题。
|
||||
|
||||
@ -47,7 +48,7 @@ public class Singleton {
|
||||
private static Singleton uniqueInstance = new Singleton();
|
||||
```
|
||||
|
||||
#### Ⅲ 懒汉式-线程安全
|
||||
### Ⅲ 懒汉式-线程安全
|
||||
|
||||
只需要对 getUniqueInstance() 方法加锁,那么在一个时间点只能有一个线程能够进入该方法,从而避免了实例化多次 uniqueInstance。
|
||||
|
||||
@ -62,7 +63,7 @@ public static synchronized Singleton getUniqueInstance() {
|
||||
}
|
||||
```
|
||||
|
||||
#### Ⅳ 双重校验锁-线程安全
|
||||
### Ⅳ 双重校验锁-线程安全
|
||||
|
||||
uniqueInstance 只需要被实例化一次,之后就可以直接使用了。加锁操作只需要对实例化那部分的代码进行,只有当 uniqueInstance 没有被实例化时,才需要进行加锁。
|
||||
|
||||
@ -105,11 +106,11 @@ uniqueInstance 采用 volatile 关键字修饰也是很有必要的, `uniqueIn
|
||||
2. 初始化 uniqueInstance
|
||||
3. 将 uniqueInstance 指向分配的内存地址
|
||||
|
||||
但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1>3>2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T<sub>1</sub> 执行了 1 和 3,此时 T<sub>2</sub> 调用 getUniqueInstance() 后发现 uniqueInstance 不为空,因此返回 uniqueInstance,但此时 uniqueInstance 还未被初始化。
|
||||
但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1>3>2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 getUniqueInstance() 后发现 uniqueInstance 不为空,因此返回 uniqueInstance,但此时 uniqueInstance 还未被初始化。
|
||||
|
||||
使用 volatile 可以禁止 JVM 的指令重排,保证在多线程环境下也能正常运行。
|
||||
|
||||
#### Ⅴ 静态内部类实现
|
||||
### Ⅴ 静态内部类实现
|
||||
|
||||
当 Singleton 类被加载时,静态内部类 SingletonHolder 没有被加载进内存。只有当调用 `getUniqueInstance()` 方法从而触发 `SingletonHolder.INSTANCE` 时 SingletonHolder 才会被加载,此时初始化 INSTANCE 实例,并且 JVM 能确保 INSTANCE 只被实例化一次。
|
||||
|
||||
@ -131,7 +132,7 @@ public class Singleton {
|
||||
}
|
||||
```
|
||||
|
||||
#### Ⅵ 枚举实现
|
||||
### Ⅵ 枚举实现
|
||||
|
||||
```java
|
||||
public enum Singleton {
|
||||
@ -186,16 +187,15 @@ secondName
|
||||
|
||||
该实现在多次序列化和序列化之后,不会得到多个实例。而其它实现需要使用 transient 修饰所有字段,并且实现序列化和反序列化的方法。
|
||||
|
||||
### Examples
|
||||
## Examples
|
||||
|
||||
- Logger Classes
|
||||
- Configuration Classes
|
||||
- Accesing resources in shared mode
|
||||
- Factories implemented as Singletons
|
||||
* Logger Classes
|
||||
* Configuration Classes
|
||||
* Accesing resources in shared mode
|
||||
* Factories implemented as Singletons
|
||||
|
||||
### JDK
|
||||
|
||||
- [java.lang.Runtime#getRuntime()](http://docs.oracle.com/javase/8/docs/api/java/lang/Runtime.html#getRuntime%28%29)
|
||||
- [java.awt.Desktop#getDesktop()](http://docs.oracle.com/javase/8/docs/api/java/awt/Desktop.html#getDesktop--)
|
||||
- [java.lang.System#getSecurityManager()](https://docs.oracle.com/javase/8/docs/api/java/lang/System.html#getSecurityManager--)
|
||||
## JDK
|
||||
|
||||
* [java.lang.Runtime#getRuntime()](http://docs.oracle.com/javase/8/docs/api/java/lang/Runtime.html#getRuntime%28%29)
|
||||
* [java.awt.Desktop#getDesktop()](http://docs.oracle.com/javase/8/docs/api/java/awt/Desktop.html#getDesktop--)
|
||||
* [java.lang.System#getSecurityManager()](https://docs.oracle.com/javase/8/docs/api/java/lang/System.html#getSecurityManager--)
|
||||
|
||||
@ -1,27 +1,28 @@
|
||||
## 5. 中介者(Mediator)
|
||||
# 5. 中介者(Mediator)
|
||||
|
||||
### Intent
|
||||
## Intent
|
||||
|
||||
集中相关对象之间复杂的沟通和控制方式。
|
||||
|
||||
### Class Diagram
|
||||
## Class Diagram
|
||||
|
||||
* Mediator:中介者,定义一个接口用于与各同事(Colleague)对象通信。
|
||||
* Colleague:同事,相关对象
|
||||
|
||||
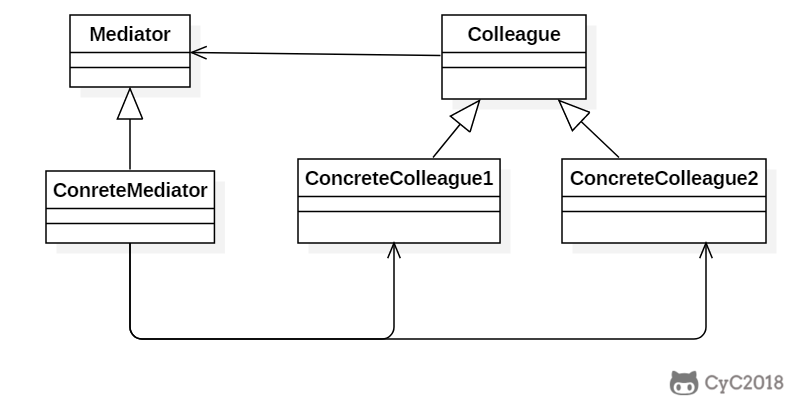\
|
||||
|
||||
|
||||
|
||||
- Mediator:中介者,定义一个接口用于与各同事(Colleague)对象通信。
|
||||
- Colleague:同事,相关对象
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/30d6e95c-2e3c-4d32-bf4f-68128a70bc05.png"/> </div><br>
|
||||
|
||||
### Implementation
|
||||
## Implementation
|
||||
|
||||
Alarm(闹钟)、CoffeePot(咖啡壶)、Calendar(日历)、Sprinkler(喷头)是一组相关的对象,在某个对象的事件产生时需要去操作其它对象,形成了下面这种依赖结构:
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/82cfda3b-b53b-4c89-9fdb-26dd2db0cd02.jpg"/> </div><br>
|
||||
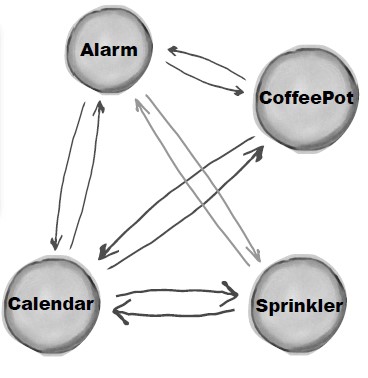\
|
||||
|
||||
|
||||
使用中介者模式可以将复杂的依赖结构变成星形结构:
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/5359cbf5-5a79-4874-9b17-f23c53c2cb80.jpg"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```java
|
||||
public abstract class Colleague {
|
||||
@ -161,10 +162,10 @@ doCalender()
|
||||
doSprinkler()
|
||||
```
|
||||
|
||||
### JDK
|
||||
## JDK
|
||||
|
||||
- All scheduleXXX() methods of [java.util.Timer](http://docs.oracle.com/javase/8/docs/api/java/util/Timer.html)
|
||||
- [java.util.concurrent.Executor#execute()](http://docs.oracle.com/javase/8/docs/api/java/util/concurrent/Executor.html#execute-java.lang.Runnable-)
|
||||
- submit() and invokeXXX() methods of [java.util.concurrent.ExecutorService](http://docs.oracle.com/javase/8/docs/api/java/util/concurrent/ExecutorService.html)
|
||||
- scheduleXXX() methods of [java.util.concurrent.ScheduledExecutorService](http://docs.oracle.com/javase/8/docs/api/java/util/concurrent/ScheduledExecutorService.html)
|
||||
- [java.lang.reflect.Method#invoke()](http://docs.oracle.com/javase/8/docs/api/java/lang/reflect/Method.html#invoke-java.lang.Object-java.lang.Object...-)
|
||||
* All scheduleXXX() methods of [java.util.Timer](http://docs.oracle.com/javase/8/docs/api/java/util/Timer.html)
|
||||
* [java.util.concurrent.Executor#execute()](http://docs.oracle.com/javase/8/docs/api/java/util/concurrent/Executor.html#execute-java.lang.Runnable-)
|
||||
* submit() and invokeXXX() methods of [java.util.concurrent.ExecutorService](http://docs.oracle.com/javase/8/docs/api/java/util/concurrent/ExecutorService.html)
|
||||
* scheduleXXX() methods of [java.util.concurrent.ScheduledExecutorService](http://docs.oracle.com/javase/8/docs/api/java/util/concurrent/ScheduledExecutorService.html)
|
||||
* [java.lang.reflect.Method#invoke()](http://docs.oracle.com/javase/8/docs/api/java/lang/reflect/Method.html#invoke-java.lang.Object-java.lang.Object...-)
|
||||
|
||||
@ -1,20 +1,19 @@
|
||||
## 享元(Flyweight)
|
||||
|
||||
### Intent
|
||||
|
||||
# 享元(Flyweight)
|
||||
|
||||
## Intent
|
||||
|
||||
利用共享的方式来支持大量细粒度的对象,这些对象一部分内部状态是相同的。
|
||||
|
||||
### Class Diagram
|
||||
## Class Diagram
|
||||
|
||||
- Flyweight:享元对象
|
||||
- IntrinsicState:内部状态,享元对象共享内部状态
|
||||
- ExtrinsicState:外部状态,每个享元对象的外部状态不同
|
||||
* Flyweight:享元对象
|
||||
* IntrinsicState:内部状态,享元对象共享内部状态
|
||||
* ExtrinsicState:外部状态,每个享元对象的外部状态不同
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/5f5c22d5-9c0e-49e1-b5b0-6cc7032724d4.png"/> </div><br>
|
||||
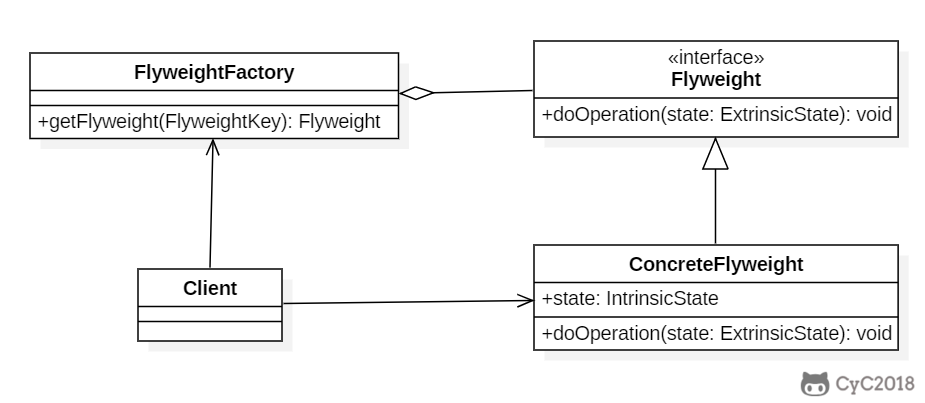\
|
||||
|
||||
### Implementation
|
||||
|
||||
## Implementation
|
||||
|
||||
```java
|
||||
public interface Flyweight {
|
||||
@ -77,11 +76,11 @@ IntrinsicState: aa
|
||||
ExtrinsicState: y
|
||||
```
|
||||
|
||||
### JDK
|
||||
## JDK
|
||||
|
||||
Java 利用缓存来加速大量小对象的访问时间。
|
||||
|
||||
- java.lang.Integer#valueOf(int)
|
||||
- java.lang.Boolean#valueOf(boolean)
|
||||
- java.lang.Byte#valueOf(byte)
|
||||
- java.lang.Character#valueOf(char)
|
||||
* java.lang.Integer#valueOf(int)
|
||||
* java.lang.Boolean#valueOf(boolean)
|
||||
* java.lang.Byte#valueOf(byte)
|
||||
* java.lang.Character#valueOf(char)
|
||||
|
||||
@ -1,21 +1,22 @@
|
||||
## 代理(Proxy)
|
||||
# 代理(Proxy)
|
||||
|
||||
### Intent
|
||||
## Intent
|
||||
|
||||
控制对其它对象的访问。
|
||||
|
||||
### Class Diagram
|
||||
## Class Diagram
|
||||
|
||||
代理有以下四类:
|
||||
|
||||
- 远程代理(Remote Proxy):控制对远程对象(不同地址空间)的访问,它负责将请求及其参数进行编码,并向不同地址空间中的对象发送已经编码的请求。
|
||||
- 虚拟代理(Virtual Proxy):根据需要创建开销很大的对象,它可以缓存实体的附加信息,以便延迟对它的访问,例如在网站加载一个很大图片时,不能马上完成,可以用虚拟代理缓存图片的大小信息,然后生成一张临时图片代替原始图片。
|
||||
- 保护代理(Protection Proxy):按权限控制对象的访问,它负责检查调用者是否具有实现一个请求所必须的访问权限。
|
||||
- 智能代理(Smart Reference):取代了简单的指针,它在访问对象时执行一些附加操作:记录对象的引用次数;当第一次引用一个对象时,将它装入内存;在访问一个实际对象前,检查是否已经锁定了它,以确保其它对象不能改变它。
|
||||
* 远程代理(Remote Proxy):控制对远程对象(不同地址空间)的访问,它负责将请求及其参数进行编码,并向不同地址空间中的对象发送已经编码的请求。
|
||||
* 虚拟代理(Virtual Proxy):根据需要创建开销很大的对象,它可以缓存实体的附加信息,以便延迟对它的访问,例如在网站加载一个很大图片时,不能马上完成,可以用虚拟代理缓存图片的大小信息,然后生成一张临时图片代替原始图片。
|
||||
* 保护代理(Protection Proxy):按权限控制对象的访问,它负责检查调用者是否具有实现一个请求所必须的访问权限。
|
||||
* 智能代理(Smart Reference):取代了简单的指针,它在访问对象时执行一些附加操作:记录对象的引用次数;当第一次引用一个对象时,将它装入内存;在访问一个实际对象前,检查是否已经锁定了它,以确保其它对象不能改变它。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/9b679ff5-94c6-48a7-b9b7-2ea868e828ed.png"/> </div><br>
|
||||
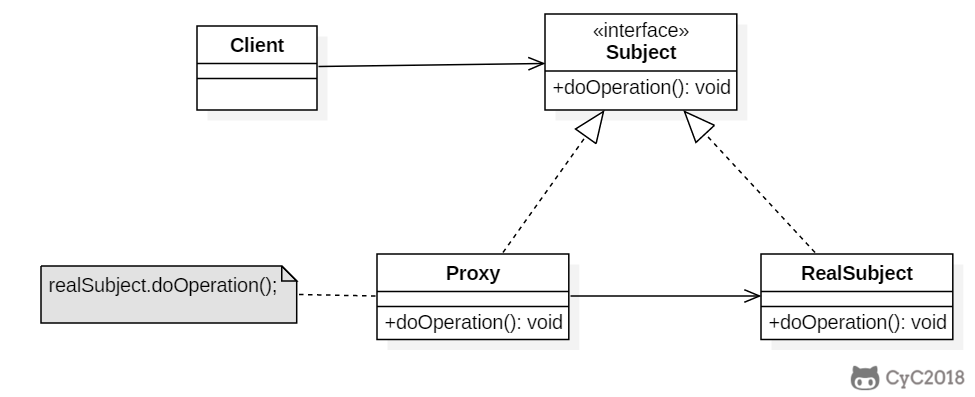\
|
||||
|
||||
### Implementation
|
||||
|
||||
## Implementation
|
||||
|
||||
以下是一个虚拟代理的实现,模拟了图片延迟加载的情况下使用与图片大小相等的临时内容去替换原始图片,直到图片加载完成才将图片显示出来。
|
||||
|
||||
@ -98,7 +99,7 @@ public class ImageViewer {
|
||||
}
|
||||
```
|
||||
|
||||
### JDK
|
||||
## JDK
|
||||
|
||||
- java.lang.reflect.Proxy
|
||||
- RMI
|
||||
* java.lang.reflect.Proxy
|
||||
* RMI
|
||||
|
||||
@ -1,14 +1,15 @@
|
||||
## 6. 原型模式(Prototype)
|
||||
# 6. 原型模式(Prototype)
|
||||
|
||||
### Intent
|
||||
## Intent
|
||||
|
||||
使用原型实例指定要创建对象的类型,通过复制这个原型来创建新对象。
|
||||
|
||||
### Class Diagram
|
||||
## Class Diagram
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/b8922f8c-95e6-4187-be85-572a509afb71.png"/> </div><br>
|
||||
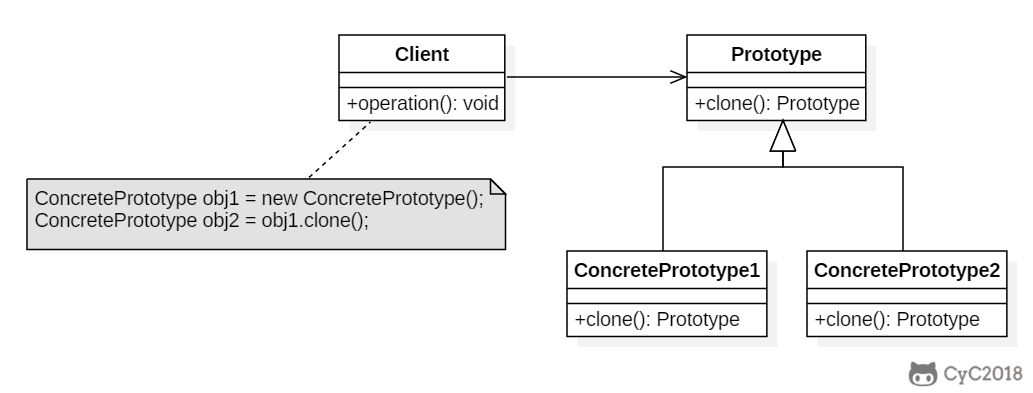\
|
||||
|
||||
### Implementation
|
||||
|
||||
## Implementation
|
||||
|
||||
```java
|
||||
public abstract class Prototype {
|
||||
@ -51,6 +52,6 @@ public class Client {
|
||||
abc
|
||||
```
|
||||
|
||||
### JDK
|
||||
## JDK
|
||||
|
||||
- [java.lang.Object#clone()](http://docs.oracle.com/javase/8/docs/api/java/lang/Object.html#clone%28%29)
|
||||
* [java.lang.Object#clone()](http://docs.oracle.com/javase/8/docs/api/java/lang/Object.html#clone%28%29)
|
||||
|
||||
@ -1,28 +1,30 @@
|
||||
## 2. 命令(Command)
|
||||
# 2. 命令(Command)
|
||||
|
||||
### Intent
|
||||
## Intent
|
||||
|
||||
将命令封装成对象中,具有以下作用:
|
||||
|
||||
- 使用命令来参数化其它对象
|
||||
- 将命令放入队列中进行排队
|
||||
- 将命令的操作记录到日志中
|
||||
- 支持可撤销的操作
|
||||
* 使用命令来参数化其它对象
|
||||
* 将命令放入队列中进行排队
|
||||
* 将命令的操作记录到日志中
|
||||
* 支持可撤销的操作
|
||||
|
||||
### Class Diagram
|
||||
## Class Diagram
|
||||
|
||||
- Command:命令
|
||||
- Receiver:命令接收者,也就是命令真正的执行者
|
||||
- Invoker:通过它来调用命令
|
||||
- Client:可以设置命令与命令的接收者
|
||||
* Command:命令
|
||||
* Receiver:命令接收者,也就是命令真正的执行者
|
||||
* Invoker:通过它来调用命令
|
||||
* Client:可以设置命令与命令的接收者
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/c44a0342-f405-4f17-b750-e27cf4aadde2.png"/> </div><br>
|
||||
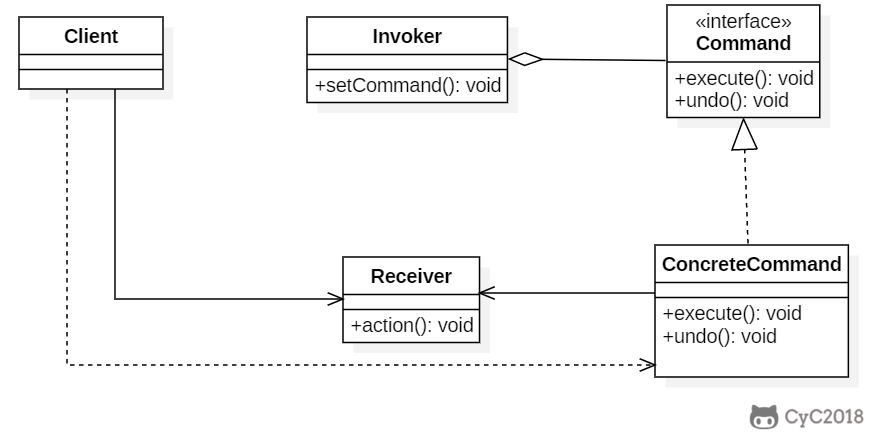\
|
||||
|
||||
### Implementation
|
||||
|
||||
## Implementation
|
||||
|
||||
设计一个遥控器,可以控制电灯开关。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/e6bded8e-41a0-489a-88a6-638e88ab7666.jpg"/> </div><br>
|
||||
\
|
||||
|
||||
|
||||
```java
|
||||
public interface Command {
|
||||
@ -120,8 +122,8 @@ public class Client {
|
||||
}
|
||||
```
|
||||
|
||||
### JDK
|
||||
## JDK
|
||||
|
||||
- [java.lang.Runnable](http://docs.oracle.com/javase/8/docs/api/java/lang/Runnable.html)
|
||||
- [Netflix Hystrix](https://github.com/Netflix/Hystrix/wiki)
|
||||
- [javax.swing.Action](http://docs.oracle.com/javase/8/docs/api/javax/swing/Action.html)
|
||||
* [java.lang.Runnable](http://docs.oracle.com/javase/8/docs/api/java/lang/Runnable.html)
|
||||
* [Netflix Hystrix](https://github.com/Netflix/Hystrix/wiki)
|
||||
* [javax.swing.Action](http://docs.oracle.com/javase/8/docs/api/javax/swing/Action.html)
|
||||
|
||||
@ -1,18 +1,19 @@
|
||||
## 备忘录(Memento)
|
||||
# 备忘录(Memento)
|
||||
|
||||
### Intent
|
||||
## Intent
|
||||
|
||||
在不违反封装的情况下获得对象的内部状态,从而在需要时可以将对象恢复到最初状态。
|
||||
|
||||
### Class Diagram
|
||||
## Class Diagram
|
||||
|
||||
- Originator:原始对象
|
||||
- Caretaker:负责保存好备忘录
|
||||
- Memento:备忘录,存储原始对象的状态。备忘录实际上有两个接口,一个是提供给 Caretaker 的窄接口:它只能将备忘录传递给其它对象;一个是提供给 Originator 的宽接口,允许它访问到先前状态所需的所有数据。理想情况是只允许 Originator 访问本备忘录的内部状态。
|
||||
* Originator:原始对象
|
||||
* Caretaker:负责保存好备忘录
|
||||
* Memento:备忘录,存储原始对象的状态。备忘录实际上有两个接口,一个是提供给 Caretaker 的窄接口:它只能将备忘录传递给其它对象;一个是提供给 Originator 的宽接口,允许它访问到先前状态所需的所有数据。理想情况是只允许 Originator 访问本备忘录的内部状态。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/50678f34-694f-45a4-91c6-34d985c83fee.png"/> </div><br>
|
||||
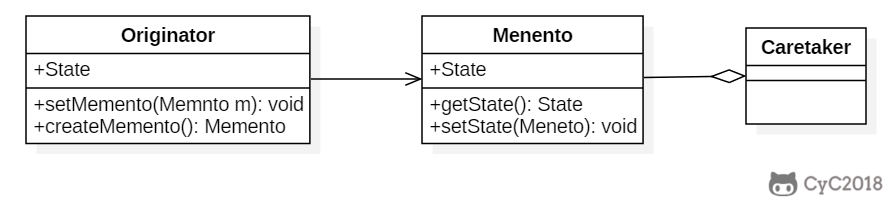\
|
||||
|
||||
### Implementation
|
||||
|
||||
## Implementation
|
||||
|
||||
以下实现了一个简单计算器程序,可以输入两个值,然后计算这两个值的和。备忘录模式允许将这两个值存储起来,然后在某个时刻用存储的状态进行恢复。
|
||||
|
||||
@ -171,6 +172,6 @@ public class Client {
|
||||
110
|
||||
```
|
||||
|
||||
### JDK
|
||||
## JDK
|
||||
|
||||
- java.io.Serializable
|
||||
* java.io.Serializable
|
||||
|
||||
@ -1,14 +1,15 @@
|
||||
## 外观(Facade)
|
||||
# 外观(Facade)
|
||||
|
||||
### Intent
|
||||
## Intent
|
||||
|
||||
提供了一个统一的接口,用来访问子系统中的一群接口,从而让子系统更容易使用。
|
||||
|
||||
### Class Diagram
|
||||
## Class Diagram
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/f9978fa6-9f49-4a0f-8540-02d269ac448f.png"/> </div><br>
|
||||
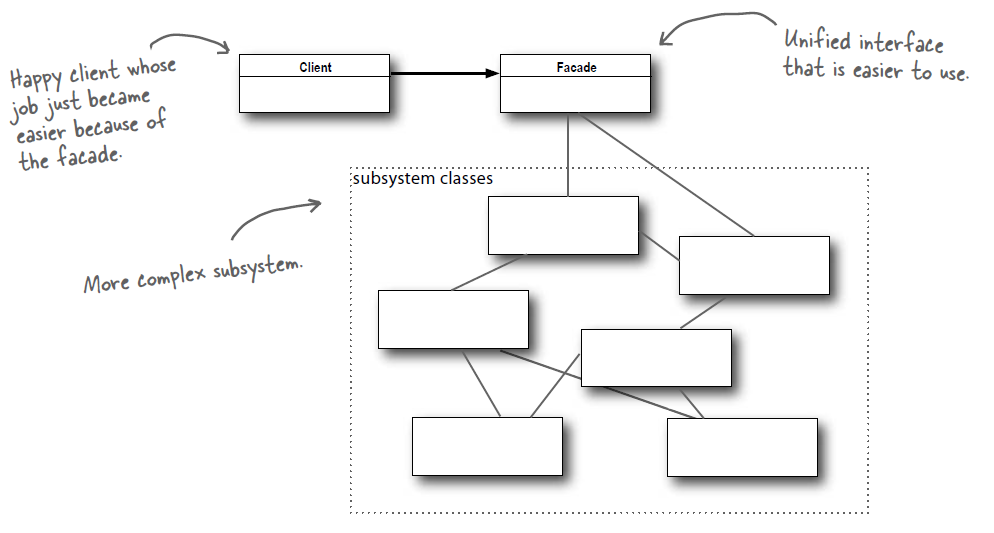\
|
||||
|
||||
### Implementation
|
||||
|
||||
## Implementation
|
||||
|
||||
观看电影需要操作很多电器,使用外观模式实现一键看电影功能。
|
||||
|
||||
@ -49,6 +50,6 @@ public class Client {
|
||||
}
|
||||
```
|
||||
|
||||
### 设计原则
|
||||
## 设计原则
|
||||
|
||||
最少知识原则:只和你的密友谈话。也就是说客户对象所需要交互的对象应当尽可能少。
|
||||
|
||||
@ -1,18 +1,19 @@
|
||||
## 工厂方法(Factory Method)
|
||||
# 工厂方法(Factory Method)
|
||||
|
||||
### Intent
|
||||
## Intent
|
||||
|
||||
定义了一个创建对象的接口,但由子类决定要实例化哪个类。工厂方法把实例化操作推迟到子类。
|
||||
|
||||
### Class Diagram
|
||||
## Class Diagram
|
||||
|
||||
在简单工厂中,创建对象的是另一个类,而在工厂方法中,是由子类来创建对象。
|
||||
|
||||
下图中,Factory 有一个 doSomething() 方法,这个方法需要用到一个产品对象,这个产品对象由 factoryMethod() 方法创建。该方法是抽象的,需要由子类去实现。
|
||||
|
||||
<div align="center"> <img src="https://cs-notes-1256109796.cos.ap-guangzhou.myqcloud.com/f4d0afd0-8e78-4914-9e60-4366eaf065b5.png"/> </div><br>
|
||||
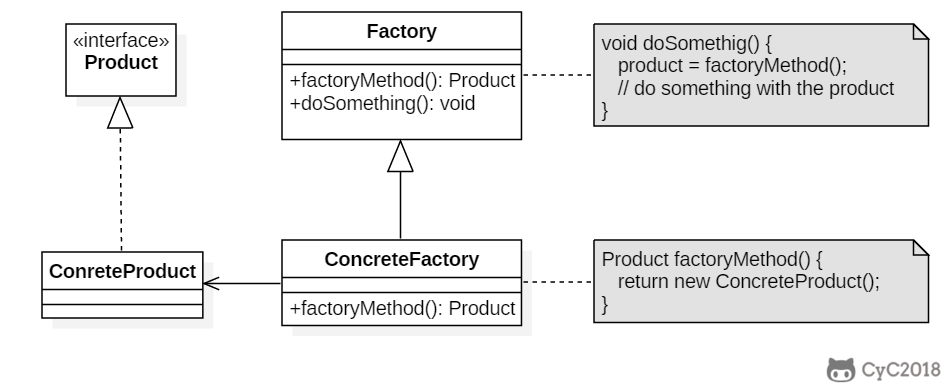\
|
||||
|
||||
### Implementation
|
||||
|
||||
## Implementation
|
||||
|
||||
```java
|
||||
public abstract class Factory {
|
||||
@ -48,12 +49,12 @@ public class ConcreteFactory2 extends Factory {
|
||||
}
|
||||
```
|
||||
|
||||
### JDK
|
||||
## JDK
|
||||
|
||||
- [java.util.Calendar](http://docs.oracle.com/javase/8/docs/api/java/util/Calendar.html#getInstance--)
|
||||
- [java.util.ResourceBundle](http://docs.oracle.com/javase/8/docs/api/java/util/ResourceBundle.html#getBundle-java.lang.String-)
|
||||
- [java.text.NumberFormat](http://docs.oracle.com/javase/8/docs/api/java/text/NumberFormat.html#getInstance--)
|
||||
- [java.nio.charset.Charset](http://docs.oracle.com/javase/8/docs/api/java/nio/charset/Charset.html#forName-java.lang.String-)
|
||||
- [java.net.URLStreamHandlerFactory](http://docs.oracle.com/javase/8/docs/api/java/net/URLStreamHandlerFactory.html#createURLStreamHandler-java.lang.String-)
|
||||
- [java.util.EnumSet](https://docs.oracle.com/javase/8/docs/api/java/util/EnumSet.html#of-E-)
|
||||
- [javax.xml.bind.JAXBContext](https://docs.oracle.com/javase/8/docs/api/javax/xml/bind/JAXBContext.html#createMarshaller--)
|
||||
* [java.util.Calendar](http://docs.oracle.com/javase/8/docs/api/java/util/Calendar.html#getInstance--)
|
||||
* [java.util.ResourceBundle](http://docs.oracle.com/javase/8/docs/api/java/util/ResourceBundle.html#getBundle-java.lang.String-)
|
||||
* [java.text.NumberFormat](http://docs.oracle.com/javase/8/docs/api/java/text/NumberFormat.html#getInstance--)
|
||||
* [java.nio.charset.Charset](http://docs.oracle.com/javase/8/docs/api/java/nio/charset/Charset.html#forName-java.lang.String-)
|
||||
* [java.net.URLStreamHandlerFactory](http://docs.oracle.com/javase/8/docs/api/java/net/URLStreamHandlerFactory.html#createURLStreamHandler-java.lang.String-)
|
||||
* [java.util.EnumSet](https://docs.oracle.com/javase/8/docs/api/java/util/EnumSet.html#of-E-)
|
||||
* [javax.xml.bind.JAXBContext](https://docs.oracle.com/javase/8/docs/api/javax/xml/bind/JAXBContext.html#createMarshaller--)
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
x
Reference in New Issue
Block a user