8.15
This commit is contained in:
parent
edc63efa34
commit
f2968f6376
@ -1,9 +1,39 @@
|
|||||||
package com.raorao.java;
|
package com.raorao.java;
|
||||||
|
|
||||||
|
import com.google.common.collect.HashBasedTable;
|
||||||
|
import java.util.Enumeration;
|
||||||
|
import java.util.HashMap;
|
||||||
|
import java.util.Hashtable;
|
||||||
|
import java.util.Iterator;
|
||||||
|
import java.util.LinkedHashMap;
|
||||||
|
import java.util.LinkedHashSet;
|
||||||
|
import java.util.Map.Entry;
|
||||||
|
|
||||||
public class Test {
|
public class Test {
|
||||||
|
|
||||||
static int a;
|
static int a;
|
||||||
int b;
|
|
||||||
static int c;
|
static int c;
|
||||||
|
int b;
|
||||||
|
|
||||||
|
public static int cMethod() {
|
||||||
|
c++;
|
||||||
|
return c;
|
||||||
|
}
|
||||||
|
|
||||||
|
public static void main(String args[]) {
|
||||||
|
Hashtable<Integer, Integer> hashMap = new Hashtable<>();
|
||||||
|
hashMap.put(1, 10);
|
||||||
|
hashMap.put(2, 20);
|
||||||
|
hashMap.put(3, 30);
|
||||||
|
hashMap.put(19, 30);
|
||||||
|
hashMap.forEach((e1, e2)-> System.out.println( e1 + ":" + e2));
|
||||||
|
Iterator<Entry<Integer, Integer>> iterator = hashMap.entrySet().iterator();
|
||||||
|
Enumeration<Integer> enumeration = hashMap.elements();
|
||||||
|
while (enumeration.hasMoreElements()){
|
||||||
|
System.out.println(enumeration.nextElement());
|
||||||
|
}
|
||||||
|
|
||||||
|
}
|
||||||
|
|
||||||
public int aMethod() {
|
public int aMethod() {
|
||||||
a++;
|
a++;
|
||||||
@ -14,15 +44,4 @@ public class Test {
|
|||||||
b++;
|
b++;
|
||||||
return b;
|
return b;
|
||||||
}
|
}
|
||||||
|
|
||||||
public static int cMethod() {
|
|
||||||
c++;
|
|
||||||
return c;
|
|
||||||
}
|
|
||||||
|
|
||||||
public static void main(String args[]) {
|
|
||||||
String str = null;
|
|
||||||
|
|
||||||
System.out.println(str);
|
|
||||||
}
|
|
||||||
}
|
}
|
||||||
70
code/src/main/java/com/raorao/java/althorithm/HeapSort.java
Normal file
70
code/src/main/java/com/raorao/java/althorithm/HeapSort.java
Normal file
@ -0,0 +1,70 @@
|
|||||||
|
package com.raorao.java.althorithm;
|
||||||
|
|
||||||
|
import java.util.Arrays;
|
||||||
|
|
||||||
|
/**
|
||||||
|
* 堆排序.
|
||||||
|
*
|
||||||
|
* 参考链接:https://www.cnblogs.com/chengxiao/p/6129630.html
|
||||||
|
*
|
||||||
|
* @author Xiong Raorao
|
||||||
|
* @since 2018-08-15-19:19
|
||||||
|
*/
|
||||||
|
public class HeapSort {
|
||||||
|
|
||||||
|
public static void main(String[] args) {
|
||||||
|
int []arr = {4,6,8,5,9};
|
||||||
|
sort(arr);
|
||||||
|
System.out.println(Arrays.toString(arr));
|
||||||
|
}
|
||||||
|
|
||||||
|
public static void sort(int []arr){
|
||||||
|
//1.构建大顶堆
|
||||||
|
for(int i=arr.length/2-1;i>=0;i--){
|
||||||
|
//从第一个非叶子结点从下至上,从右至左调整结构
|
||||||
|
adjustHeap(arr,i,arr.length);
|
||||||
|
}
|
||||||
|
//2.调整堆结构+交换堆顶元素与末尾元素
|
||||||
|
for(int j=arr.length-1;j>0;j--){
|
||||||
|
swap(arr,0,j);//将堆顶元素与末尾元素进行交换
|
||||||
|
adjustHeap(arr,0,j);//重新对堆进行调整,每调整好一个,length就减少一个。
|
||||||
|
}
|
||||||
|
|
||||||
|
}
|
||||||
|
|
||||||
|
/**
|
||||||
|
* 调整大顶堆(仅是调整过程,建立在大顶堆已构建的基础上)
|
||||||
|
* @param arr
|
||||||
|
* @param i
|
||||||
|
* @param length
|
||||||
|
*/
|
||||||
|
public static void adjustHeap(int []arr,int i,int length){
|
||||||
|
int temp = arr[i];//先取出当前元素i
|
||||||
|
for(int k=i*2+1;k<length;k=k*2+1){//从i结点的左子结点开始,也就是2i+1处开始
|
||||||
|
if(k+1<length && arr[k]<arr[k+1]){//如果左子结点小于右子结点,k指向右子结点
|
||||||
|
k++;
|
||||||
|
}
|
||||||
|
if(arr[k] >temp){//如果子节点大于父节点,将子节点值赋给父节点(不用进行交换)
|
||||||
|
arr[i] = arr[k];
|
||||||
|
i = k;
|
||||||
|
}else{
|
||||||
|
break;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
arr[i] = temp;//将temp值放到最终的位置
|
||||||
|
}
|
||||||
|
|
||||||
|
/**
|
||||||
|
* 交换元素
|
||||||
|
* @param arr
|
||||||
|
* @param a
|
||||||
|
* @param b
|
||||||
|
*/
|
||||||
|
public static void swap(int []arr,int a ,int b){
|
||||||
|
int temp=arr[a];
|
||||||
|
arr[a] = arr[b];
|
||||||
|
arr[b] = temp;
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
}
|
||||||
86
interview/answer.md
Normal file
86
interview/answer.md
Normal file
@ -0,0 +1,86 @@
|
|||||||
|
<!-- TOC -->
|
||||||
|
|
||||||
|
- [java基础](#java基础)
|
||||||
|
- [java 语言基础](#java-语言基础)
|
||||||
|
- [java自动拆装箱:](#java自动拆装箱)
|
||||||
|
- [java 四种引用及其应用场景](#java-四种引用及其应用场景)
|
||||||
|
- [foreach与正常for循环效率对比](#foreach与正常for循环效率对比)
|
||||||
|
- [java反射的作用于原理](#java反射的作用于原理)
|
||||||
|
- [数据库](#数据库)
|
||||||
|
- [truncate与 delete区别](#truncate与-delete区别)
|
||||||
|
- [B+树索引和哈希索引的区别](#b树索引和哈希索引的区别)
|
||||||
|
|
||||||
|
<!-- /TOC -->
|
||||||
|
|
||||||
|
# java基础
|
||||||
|
|
||||||
|
## java 语言基础
|
||||||
|
|
||||||
|
### java自动拆装箱:
|
||||||
|
|
||||||
|
自动装箱是将一个java定义的基本数据类型赋值给相应封装类的变量。 拆箱与装箱是相反的操作,自动拆箱则是将一个封装类的变量赋值给相应基本数据类型的变量。
|
||||||
|
|
||||||
|
### java 四种引用及其应用场景
|
||||||
|
|
||||||
|
1、强引用
|
||||||
|
最普遍的一种引用方式,如String s = "abc",变量s就是字符串“abc”的强引用,只要强引用存在,则垃圾回收器就不会回收这个对象。
|
||||||
|
|
||||||
|
2、软引用(SoftReference)
|
||||||
|
用于描述还有用但非必须的对象,如果内存足够,不回收,如果内存不足,则回收。一般用于实现内存敏感的高速缓存,软引用可以和引用队列ReferenceQueue联合使用,如果软引用的对象被垃圾回收,JVM就会把这个软引用加入到与之关联的引用队列中。
|
||||||
|
|
||||||
|
3、弱引用(WeakReference)
|
||||||
|
弱引用和软引用大致相同,弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。
|
||||||
|
|
||||||
|
4、虚引用(PhantomReference)
|
||||||
|
就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。 虚引用主要用来跟踪对象被垃圾回收器回收的活动。
|
||||||
|
|
||||||
|
|
||||||
|
虚引用与软引用和弱引用的一个区别在于:
|
||||||
|
虚引用必须和引用队列 (ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。
|
||||||
|
|
||||||
|
### foreach与正常for循环效率对比
|
||||||
|
|
||||||
|
用for循环arrayList 10万次花费时间:5毫秒。
|
||||||
|
用foreach循环arrayList 10万次花费时间:7毫秒。
|
||||||
|
用for循环linkList 10万次花费时间:4481毫秒。
|
||||||
|
用foreach循环linkList 10万次花费时间:5毫秒。
|
||||||
|
循环ArrayList时,普通for循环比foreach循环花费的时间要少一点。
|
||||||
|
循环LinkList时,普通for循环比foreach循环花费的时间要多很多。
|
||||||
|
当我将循环次数提升到一百万次的时候,循环ArrayList,普通for循环还是比foreach要快一点;但是普通for循环在循环LinkList时,程序直接卡死。
|
||||||
|
ArrayList:ArrayList是采用数组的形式保存对象的,这种方式将对象放在连续的内存块中,所以插入和删除时比较麻烦,查询比较方便。
|
||||||
|
LinkList:LinkList是将对象放在独立的空间中,而且每个空间中还保存下一个空间的索引,也就是数据结构中的链表结构,插入和删除比较方便,但是查找很麻烦,要从第一个开始遍历。
|
||||||
|
|
||||||
|
结论:
|
||||||
|
**需要循环数组结构的数据时,建议使用普通for循环,因为for循环采用下标访问,对于数组结构的数据来说,采用下标访问比较好。
|
||||||
|
需要循环链表结构的数据时,一定不要使用普通for循环,这种做法很糟糕,数据量大的时候有可能会导致系统崩溃。**
|
||||||
|
|
||||||
|
链表:使用foreach
|
||||||
|
数组:使用for循环
|
||||||
|
|
||||||
|
### java反射的作用于原理
|
||||||
|
|
||||||
|
Java 反射是可以让我们在运行时,通过一个类的Class对象来获取它获取类的方法、属性、父类、接口等类的内部信息的机制。
|
||||||
|
|
||||||
|
这种动态获取信息以及动态调用对象的方法的功能称为JAVA的反射。
|
||||||
|
|
||||||
|
# 数据库
|
||||||
|
|
||||||
|
## truncate与 delete区别
|
||||||
|
|
||||||
|
TRUNCATE TABLE 在功能上与不带 WHERE 子句的 DELETE 语句相同:二者均删除表中的全部行。但 TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少。 DELETE 语句每次删除一行,并在事务日志中为所删除的每行记录一项。
|
||||||
|
TRUNCATE TABLE 通过释放存储表数据所用的数据页来删除数据,并且只在事务日志中记录页的释放。 TRUNCATE,DELETE,DROP 放在一起比较:
|
||||||
|
TRUNCATE TABLE :删除内容、释放空间但不删除定义。
|
||||||
|
DELETE TABLE: 删除内容不删除定义,不释放空间。
|
||||||
|
DROP TABLE :删除内容和定义,释放空间
|
||||||
|
|
||||||
|
## B+树索引和哈希索引的区别
|
||||||
|
|
||||||
|
B+树是一个平衡的多叉树,从根节点到每个叶子节点的高度差值不超过1,而且同层级的节点间有指针相互链接,是有序的
|
||||||
|
|
||||||
|
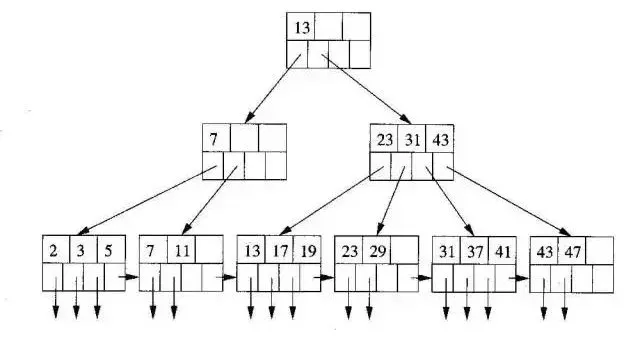
|
||||||
|
|
||||||
|
哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可,是无序的
|
||||||
|
|
||||||
|
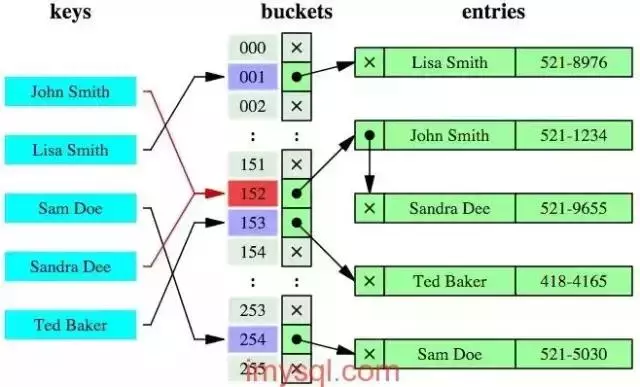
|
||||||
|
|
||||||
|
**优势对比:**
|
||||||
@ -1,11 +1,16 @@
|
|||||||
<!-- TOC -->
|
<!-- TOC -->
|
||||||
|
|
||||||
- [HashMap ConcurrentHashMap](#hashmap-concurrenthashmap)
|
- [HashMap ConcurrentHashMap Hashtable](#hashmap-concurrenthashmap-hashtable)
|
||||||
|
- [为什么HashMap线程不安全](#为什么hashmap线程不安全)
|
||||||
|
- [如何线程安全的使用hashmap](#如何线程安全的使用hashmap)
|
||||||
|
- [TreeMap、HashMap、LindedHashMap的区别](#treemaphashmaplindedhashmap的区别)
|
||||||
|
- [try?catch?finally,try里有return,finally还执行么](#trycatchfinallytry里有returnfinally还执行么)
|
||||||
- [java this 和 super的用法](#java-this-和-super的用法)
|
- [java this 和 super的用法](#java-this-和-super的用法)
|
||||||
- [this](#this)
|
- [this](#this)
|
||||||
- [super](#super)
|
- [super](#super)
|
||||||
- [super和this的异同:](#super和this的异同)
|
- [super和this的异同:](#super和this的异同)
|
||||||
- [抽象类和接口](#抽象类和接口)
|
- [抽象类和接口](#抽象类和接口)
|
||||||
|
- [java 重写和重载的区别](#java-重写和重载的区别)
|
||||||
- [Synchronized 和 volitate区别](#synchronized-和-volitate区别)
|
- [Synchronized 和 volitate区别](#synchronized-和-volitate区别)
|
||||||
- [异常](#异常)
|
- [异常](#异常)
|
||||||
- [String StringBuffer StringBuilder的区别](#string-stringbuffer-stringbuilder的区别)
|
- [String StringBuffer StringBuilder的区别](#string-stringbuffer-stringbuilder的区别)
|
||||||
@ -29,7 +34,7 @@
|
|||||||
|
|
||||||
<!-- /TOC -->
|
<!-- /TOC -->
|
||||||
|
|
||||||
# HashMap ConcurrentHashMap
|
# HashMap ConcurrentHashMap Hashtable
|
||||||
|
|
||||||
HashMap和ConcurrentHashMap的最主要的区别就是前者是线程不安全,后者是线程安全的。在不同的JDK版本中,区别也不一样
|
HashMap和ConcurrentHashMap的最主要的区别就是前者是线程不安全,后者是线程安全的。在不同的JDK版本中,区别也不一样
|
||||||
|
|
||||||
@ -45,6 +50,92 @@ ConcurrentHashMap 不用segment,改成CAS+synchronized方法实现。
|
|||||||
|
|
||||||
CAS 的含义是“我认为原有的值应该是什么,如果是,则将原有的值更新为新值,否则不做修改,并告诉我原来的值是多少”
|
CAS 的含义是“我认为原有的值应该是什么,如果是,则将原有的值更新为新值,否则不做修改,并告诉我原来的值是多少”
|
||||||
|
|
||||||
|
Hashtable 继承自陈旧的Directory,使用synchronized 同步,但是**不允许key和value为空**
|
||||||
|
|
||||||
|
Hashtable使用Enumeration,HashMap使用Iterator
|
||||||
|
|
||||||
|
HashMap 的迭代器:遍历的时候,根据Node数组的索引自然顺序,forEach
|
||||||
|
Hashtable 除了Iterator,自己实现了迭代器Enumeration,但是是从Node的**尾部到头部**开始遍历,不一样
|
||||||
|
|
||||||
|
hashtable elements() 方法获取的迭代器的下一个元素
|
||||||
|
|
||||||
|
``` java
|
||||||
|
@SuppressWarnings("unchecked")
|
||||||
|
public T nextElement() {
|
||||||
|
Entry<?,?> et = entry;
|
||||||
|
int i = index; // index 为元素的长度
|
||||||
|
Entry<?,?>[] t = table;
|
||||||
|
/* Use locals for faster loop iteration */
|
||||||
|
while (et == null && i > 0) {
|
||||||
|
et = t[--i];
|
||||||
|
}
|
||||||
|
entry = et;
|
||||||
|
index = i;
|
||||||
|
if (et != null) {
|
||||||
|
Entry<?,?> e = lastReturned = entry;
|
||||||
|
entry = e.next;
|
||||||
|
return type == KEYS ? (T)e.key : (type == VALUES ? (T)e.value : (T)e);
|
||||||
|
}
|
||||||
|
throw new NoSuchElementException("Hashtable Enumerator");
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
HashTable虽然性能上不如ConcurrentHashMap,但并不能完全被取代,两者的迭代器的一致性不同的,HashTable的迭代器是强一致性的,而ConcurrentHashMap是弱一致的。
|
||||||
|
|
||||||
|
ConcurrentHashMap的get,clear,iterator 都是弱一致性的。 Doug Lea 也将这个判断留给用户自己决定是否使用ConcurrentHashMap。
|
||||||
|
|
||||||
|
弱一致性的意思就是,put一个元素进去之后,不是马上对该元素可见。
|
||||||
|
|
||||||
|
## 为什么HashMap线程不安全
|
||||||
|
|
||||||
|
HashMap 在并发执行 put 操作时会引起死循环,导致 CPU 利用率接近100%。因为多线程会导致 HashMap 的 Node 链表形成环形数据结构,一旦形成环形数据结构,Node 的 next 节点永远不为空,就会在获取 Node 时产生死循环。
|
||||||
|
|
||||||
|
## 如何线程安全的使用hashmap
|
||||||
|
|
||||||
|
三种方法:
|
||||||
|
|
||||||
|
``` java
|
||||||
|
Map<String, String> hashtable = new Hashtable<>();
|
||||||
|
//synchronizedMap
|
||||||
|
Map<String, String> synchronizedHashMap = Collections.synchronizedMap(new HashMap<String, String>());
|
||||||
|
//ConcurrentHashMap
|
||||||
|
Map<String, String> concurrentHashMap = new ConcurrentHashMap<>();
|
||||||
|
```
|
||||||
|
|
||||||
|
## TreeMap、HashMap、LindedHashMap的区别
|
||||||
|
|
||||||
|
LinkedHashMap可以保证HashMap集合有序,存入的顺序和取出的顺序一致。LinekdHashMap的Entry继承自HashMap.Node, 提供了双向指针。
|
||||||
|
|
||||||
|
LinkedHashMap 继承了HashMap,hashmap预留了三个函数,便于linkedHashMap对元素进行后续操作,下面三个函数在LinkedHashMap都有实现。
|
||||||
|
|
||||||
|
``` java
|
||||||
|
// Callbacks to allow LinkedHashMap post-actions
|
||||||
|
void afterNodeAccess(Node<K,V> p) { }
|
||||||
|
void afterNodeInsertion(boolean evict) { }
|
||||||
|
void afterNodeRemoval(Node<K,V> p) { }
|
||||||
|
```
|
||||||
|
|
||||||
|
TreeMap实现SortMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。
|
||||||
|
|
||||||
|
HashMap不保证顺序,即为无序的,具有很快的访问速度。
|
||||||
|
HashMap最多只允许一条记录的键为Null;允许多条记录的值为 Null。
|
||||||
|
|
||||||
|
HashMap不支持线程的同步。
|
||||||
|
我们在开发的过程中使用HashMap比较多,在Map中在Map 中插入、删除和定位元素,HashMap 是最好的选择。
|
||||||
|
|
||||||
|
但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。
|
||||||
|
|
||||||
|
如果需要输出的顺序和输入的相同,那么用LinkedHashMap 可以实现,它还可以按读取顺序来排列。
|
||||||
|
|
||||||
|
总结:其实联系到三种hashmap的底层实现原理,很容易想到,TreeMap 的底层使用的是二叉堆来实现的,自然能够保证自动排序,HashMap底层使用数组实现,使用迭代器遍历的话,是根据key的hash值在存储表的索引来确定的,是无序的。LinkedHashMap底层使用的链表来存储数据,可根据插入的顺序来读取数据。
|
||||||
|
|
||||||
|
# try?catch?finally,try里有return,finally还执行么
|
||||||
|
|
||||||
|
肯定会执行。finally{}块的代码。 只有在try{}块中包含遇到System.exit(0)。 之类的导致Java虚拟机直接退出的语句才会不执行。
|
||||||
|
|
||||||
|
当程序执行try{}遇到return时,程序会先执行return语句,但并不会立即返回——也就是把return语句要做的一切事情都准备好,也就是在将要返回、但并未返回的时候,程序把执行流程转去执行finally块,当finally块执行完成后就直接返回刚才return语句已经准备好的结果。
|
||||||
|
|
||||||
# java this 和 super的用法
|
# java this 和 super的用法
|
||||||
|
|
||||||
## this
|
## this
|
||||||
@ -159,10 +250,6 @@ this和super不能同时出现在一个构造函数里面,因为this必然会
|
|||||||
this()和super()都指的是对象,所以,均不可以在static环境中使用。包括:static变量,static方法,static语句块。
|
this()和super()都指的是对象,所以,均不可以在static环境中使用。包括:static变量,static方法,static语句块。
|
||||||
从本质上讲,this是一个指向本对象的指针, 然而super是一个Java关键字。
|
从本质上讲,this是一个指向本对象的指针, 然而super是一个Java关键字。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
# 抽象类和接口
|
# 抽象类和接口
|
||||||
|
|
||||||
抽象类与接口:
|
抽象类与接口:
|
||||||
@ -198,6 +285,10 @@ this()和super()都指的是对象,所以,均不可以在static环境中使
|
|||||||
需要让不相关的类都实现一个方法,例如不相关的类都可以实现 Compareable 接口中的 compareTo() 方法;
|
需要让不相关的类都实现一个方法,例如不相关的类都可以实现 Compareable 接口中的 compareTo() 方法;
|
||||||
需要使用多重继承,例如Runnable接口实现线程类
|
需要使用多重继承,例如Runnable接口实现线程类
|
||||||
|
|
||||||
|
# java 重写和重载的区别
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
# Synchronized 和 volitate区别
|
# Synchronized 和 volitate区别
|
||||||
|
|
||||||
[volatile与synchronized的区别](https://www.cnblogs.com/tf-Y/p/5266710.html)
|
[volatile与synchronized的区别](https://www.cnblogs.com/tf-Y/p/5266710.html)
|
||||||
|
|||||||
32
interview/network/http.md
Normal file
32
interview/network/http.md
Normal file
@ -0,0 +1,32 @@
|
|||||||
|
<!-- TOC -->
|
||||||
|
|
||||||
|
- [Http常见状态码](#http常见状态码)
|
||||||
|
|
||||||
|
<!-- /TOC -->
|
||||||
|
# Http常见状态码
|
||||||
|
|
||||||
|
2XX 成功
|
||||||
|
|
||||||
|
200 OK,表示从客户端发来的请求在服务器端被正确处理
|
||||||
|
204 No content,表示请求成功,但响应报文不含实体的主体部分
|
||||||
|
206 Partial Content,进行范围请求
|
||||||
|
|
||||||
|
3XX 重定向
|
||||||
|
|
||||||
|
301 moved permanently,永久性重定向,表示资源已被分配了新的 URL
|
||||||
|
302 found,临时性重定向,表示资源临时被分配了新的 URL
|
||||||
|
303 see other,表示资源存在着另一个 URL,应使用 GET 方法丁香获取资源
|
||||||
|
304 not modified,表示服务器允许访问资源,但因发生请求未满足条件的情况
|
||||||
|
307 temporary redirect,临时重定向,和302含义相同
|
||||||
|
|
||||||
|
4XX 客户端错误
|
||||||
|
|
||||||
|
400 bad request,请求报文存在语法错误
|
||||||
|
401 unauthorized,表示发送的请求需要有通过 HTTP 认证的认证信息
|
||||||
|
403 forbidden,表示对请求资源的访问被服务器拒绝
|
||||||
|
404 not found,表示在服务器上没有找到请求的资源
|
||||||
|
|
||||||
|
5XX 服务器错误
|
||||||
|
|
||||||
|
500 internal sever error,表示服务器端在执行请求时发生了错误
|
||||||
|
503 service unavailable,表明服务器暂时处于超负载或正在停机维护,无法处理请求
|
||||||
@ -63,6 +63,8 @@ Java后端开发(大数据、分布式应用等)
|
|||||||
|
|
||||||
> [计算机网络基础](network/base.md)
|
> [计算机网络基础](network/base.md)
|
||||||
|
|
||||||
|
> [Http](network/http.md)
|
||||||
|
|
||||||
## 项目技能
|
## 项目技能
|
||||||
|
|
||||||
> [分布式问题分析](../notes/分布式问题分析.md)
|
> [分布式问题分析](../notes/分布式问题分析.md)
|
||||||
|
|||||||
@ -10,6 +10,8 @@
|
|||||||
- [运输层](#运输层)
|
- [运输层](#运输层)
|
||||||
- [算法和数结构](#算法和数结构)
|
- [算法和数结构](#算法和数结构)
|
||||||
- [HTTP](#http)
|
- [HTTP](#http)
|
||||||
|
- [设计模式](#设计模式)
|
||||||
|
- [分布式](#分布式)
|
||||||
- [数据库](#数据库)
|
- [数据库](#数据库)
|
||||||
- [Linux](#linux)
|
- [Linux](#linux)
|
||||||
- [安全](#安全)
|
- [安全](#安全)
|
||||||
@ -40,6 +42,13 @@
|
|||||||
- @transactional注解在什么情况下会失效,为什么。
|
- @transactional注解在什么情况下会失效,为什么。
|
||||||
- java 基本类型的自动拆装箱的过程
|
- java 基本类型的自动拆装箱的过程
|
||||||
- 内部类与静态内部类的区别
|
- 内部类与静态内部类的区别
|
||||||
|
- foreach与正常for循环效率对比
|
||||||
|
- java 8 的新特性
|
||||||
|
- AOP和OOP的区别
|
||||||
|
- java 枚举
|
||||||
|
- Java的四种引用,强弱软虚,用到的场景
|
||||||
|
- foreach与正常for循环效率对比
|
||||||
|
- java反射的作用于原理
|
||||||
|
|
||||||
|
|
||||||
## IO
|
## IO
|
||||||
@ -82,7 +91,8 @@
|
|||||||
- 悲观锁,乐观锁,优缺点,CAS有什么缺陷,该如何解决。
|
- 悲观锁,乐观锁,优缺点,CAS有什么缺陷,该如何解决。
|
||||||
- 可重入锁的用处及实现原理,写时复制的过程,读写锁,分段锁(ConcurrentHashMap中的segment)。
|
- 可重入锁的用处及实现原理,写时复制的过程,读写锁,分段锁(ConcurrentHashMap中的segment)。
|
||||||
- ABC三个线程如何保证顺序执行。
|
- ABC三个线程如何保证顺序执行。
|
||||||
- 线程状态
|
- 线程状态以及状态之间的切换
|
||||||
|
- ThreadLocal的了解,实现原理
|
||||||
|
|
||||||
# 操作系统
|
# 操作系统
|
||||||
|
|
||||||
@ -99,6 +109,7 @@
|
|||||||
- TCP 洪泛攻击
|
- TCP 洪泛攻击
|
||||||
- OSI 五层网络协议
|
- OSI 五层网络协议
|
||||||
- TCP和UDP的区别
|
- TCP和UDP的区别
|
||||||
|
- 长连接和短连接。 连接池适合长连接还是短连接。
|
||||||
|
|
||||||
|
|
||||||
# 算法和数结构
|
# 算法和数结构
|
||||||
@ -108,17 +119,31 @@
|
|||||||
- Hash算法和二叉树算法分别什么时候用
|
- Hash算法和二叉树算法分别什么时候用
|
||||||
- 图的广度优先算法和深度优先算法:详见jvm中垃圾回收实现
|
- 图的广度优先算法和深度优先算法:详见jvm中垃圾回收实现
|
||||||
- B-树和B+树的原理和应用场景
|
- B-树和B+树的原理和应用场景
|
||||||
- 十大排序算法的原理和复杂度,最好能够手撕出来。
|
- 十大排序算法的原理和复杂度,最好能够手撕出来。(尤其是快排序和堆排序)
|
||||||
|
|
||||||
|
|
||||||
## HTTP
|
## HTTP
|
||||||
|
|
||||||
- cookie和session的区别,分布式环境怎么保存用户状态;
|
- cookie和session的区别,分布式环境怎么保存用户状态;
|
||||||
|
|
||||||
|
# 设计模式
|
||||||
|
|
||||||
|
- 观察者模式 代理模式 单例模式
|
||||||
|
|
||||||
|
# 分布式
|
||||||
|
|
||||||
|
- 分布式事务
|
||||||
|
- 分布式锁的设计
|
||||||
|
- 分布式session
|
||||||
|
|
||||||
# 数据库
|
# 数据库
|
||||||
|
|
||||||
- mysql 的索引分类
|
- mysql 的索引分类
|
||||||
|
- truncate与 delete区别
|
||||||
|
- B+树索引和哈希索引的区别
|
||||||
|
- 数据库事务
|
||||||
|
- 四大基本特性?什么是隔离性?数据库并发有几个隔离级别?
|
||||||
|
- MySQL默认级别?
|
||||||
|
|
||||||
# Linux
|
# Linux
|
||||||
|
|
||||||
|
|||||||
@ -0,0 +1,83 @@
|
|||||||
|
<!-- TOC -->
|
||||||
|
|
||||||
|
- [树](#树)
|
||||||
|
- [二叉树](#二叉树)
|
||||||
|
- [二叉树定义](#二叉树定义)
|
||||||
|
- [二叉树性质](#二叉树性质)
|
||||||
|
- [满二叉树](#满二叉树)
|
||||||
|
- [完全二叉树](#完全二叉树)
|
||||||
|
- [二叉查找树](#二叉查找树)
|
||||||
|
- [AVL树](#avl树)
|
||||||
|
- [参考链接](#参考链接)
|
||||||
|
|
||||||
|
<!-- /TOC -->
|
||||||
|
|
||||||
|
# 树
|
||||||
|
|
||||||
|
1. 树的定义
|
||||||
|
|
||||||
|
树是一种数据结构,它是由n(n>=1)个有限节点组成一个具有层次关系的集合。
|
||||||
|
|
||||||
|
2. 基本术语
|
||||||
|
|
||||||
|
若一个结点有子树,那么该结点称为子树根的"双亲",子树的根是该结点的"孩子"。有相同双亲的结点互为"兄弟"。一个结点的所有子树上的任何结点都是该结点的后裔。从根结点到某个结点的路径上的所有结点都是该结点的祖先。
|
||||||
|
|
||||||
|
结点的度:结点拥有的子树的数目。
|
||||||
|
叶子:度为零的结点。
|
||||||
|
分支结点:度不为零的结点。
|
||||||
|
树的度:树中结点的最大的度。
|
||||||
|
|
||||||
|
层次:根结点的层次为1,其余结点的层次等于该结点的双亲结点的层次加1。
|
||||||
|
树的高度:树中结点的最大层次。
|
||||||
|
无序树:如果树中结点的各子树之间的次序是不重要的,可以交换位置。
|
||||||
|
有序树:如果树中结点的各子树之间的次序是重要的, 不可以交换位置。
|
||||||
|
森林:0个或多个不相交的树组成。对森林加上一个根,森林即成为树;删去根,树即成为森林。
|
||||||
|
|
||||||
|
## 二叉树
|
||||||
|
|
||||||
|
### 二叉树定义
|
||||||
|
|
||||||
|
二叉树是每个节点最多有两个子树的树结构。它有五种基本形态:二叉树可以是空集;根可以有空的左子树或右子树;或者左、右子树皆为空。
|
||||||
|
|
||||||
|
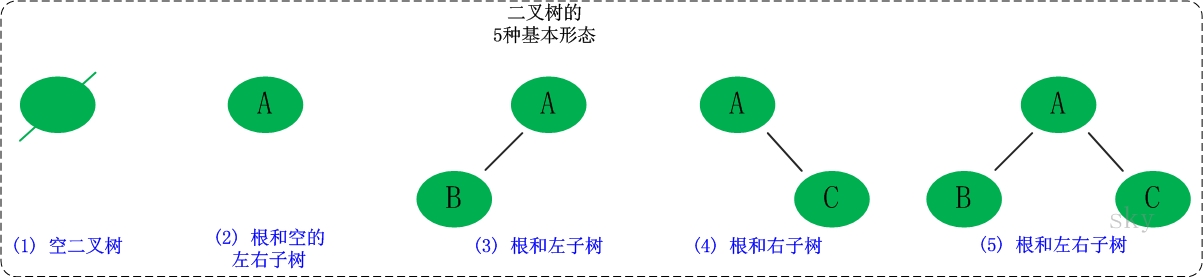
|
||||||
|
|
||||||
|
### 二叉树性质
|
||||||
|
|
||||||
|
性质1:二叉树第i层上的结点数目最多为 2^(k-1) (i≥1)。
|
||||||
|
性质2:深度为k的二叉树至多有2^k - 1个结点(k≥1)。
|
||||||
|
性质3:包含n个结点的二叉树的高度至少为log2 (n+1)。
|
||||||
|
性质4:在任意一棵二叉树中,若终端结点的个数为n0,度为2的结点数为n2,则n0=n2+1。
|
||||||
|
|
||||||
|
### 满二叉树
|
||||||
|
|
||||||
|
定义:高度为h,并且由2{h} –1个结点的二叉树,被称为满二叉树。
|
||||||
|
|
||||||
|
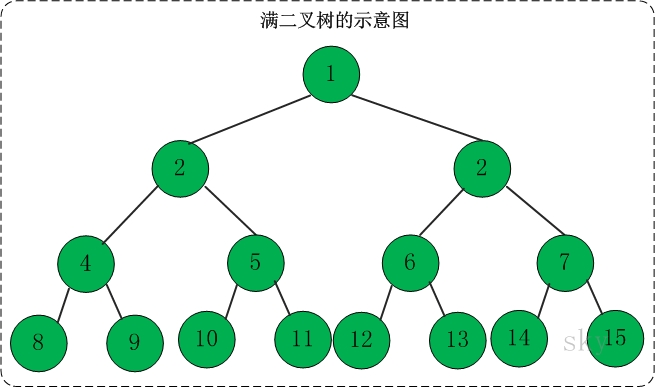
|
||||||
|
|
||||||
|
### 完全二叉树
|
||||||
|
|
||||||
|
定义:一棵二叉树中,只有最下面两层结点的度可以小于2,并且最下一层的叶结点集中在靠左的若干位置上。这样的二叉树称为完全二叉树。
|
||||||
|
特点:叶子结点只能出现在最下层和次下层,且最下层的叶子结点集中在树的左部。显然,一棵满二叉树必定是一棵完全二叉树,而完全二叉树未必是满二叉树。
|
||||||
|
|
||||||
|
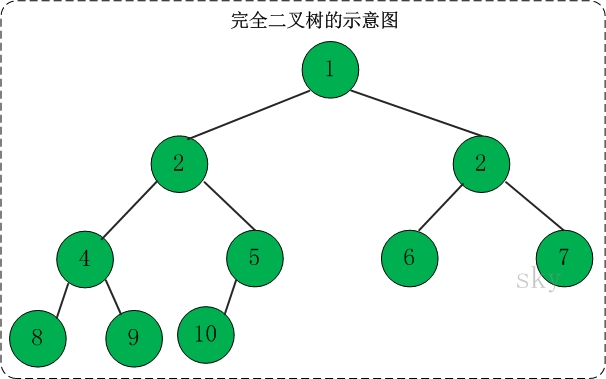
|
||||||
|
|
||||||
|
### 二叉查找树
|
||||||
|
|
||||||
|
定义:二叉查找树(Binary Search Tree),又被称为**二叉搜索树**。设x为二叉查找树中的一个结点,x节点包含关键字key,节点x的key值记为key[x]。如果y是x的左子树中的一个结点,则key[y] <= key[x];如果y是x的右子树的一个结点,则key[y] >= key[x]。
|
||||||
|
|
||||||
|
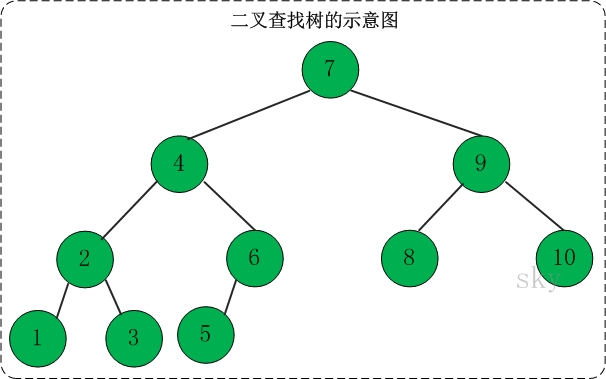
|
||||||
|
|
||||||
|
在二叉查找树中:
|
||||||
|
(01) 若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
|
||||||
|
(02) 任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
|
||||||
|
(03) 任意节点的左、右子树也分别为二叉查找树。
|
||||||
|
(04) **没有键值相等的节点(no duplicate nodes)。**
|
||||||
|
|
||||||
|
## AVL树
|
||||||
|
|
||||||
|
定义:自平衡二叉查找树
|
||||||
|
|
||||||
|
# 参考链接
|
||||||
|
|
||||||
|
- [数据结构](https://blog.csdn.net/qq_31196849/article/details/78529724)
|
||||||
|
- [数据结构全](https://blog.csdn.net/heyuchang666/article/details/49891635)
|
||||||
Loading…
x
Reference in New Issue
Block a user